TL;DR#
Multi-modal large language models (MLLMs) are powerful but computationally expensive, particularly due to the large number of visual tokens processed. Existing compression techniques primarily focus on text; efficient visual token handling remains a challenge. Simply reducing visual tokens often leads to minimal performance drop, indicating significant redundancy.
This paper introduces Visual Context Compressor, which effectively compresses visual tokens using average pooling, integrated into a novel staged training scheme called LLaVolta. LLaVolta progressively compresses visual tokens during training, minimizing information loss while significantly improving efficiency. Extensive experiments across various benchmarks demonstrate substantial improvements in training time and inference efficiency without sacrificing accuracy. This method is highly effective, and its simplicity makes it applicable to a variety of existing MLLMs.
Key Takeaways#
Why does it matter?#
This paper is highly important because it tackles the largely overlooked area of visual token compression in multi-modal LLMs. This is crucial for improving the efficiency and scalability of these models, which are increasingly important for various applications. The proposed methods offer significant improvements in training speed and inference efficiency without sacrificing performance, opening new avenues for research in efficient multi-modal learning and model optimization.
Visual Insights#
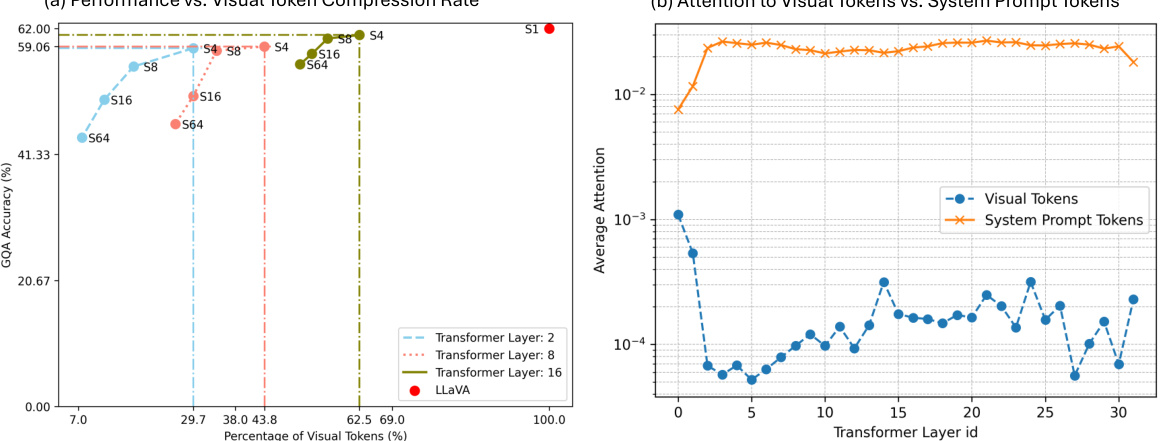
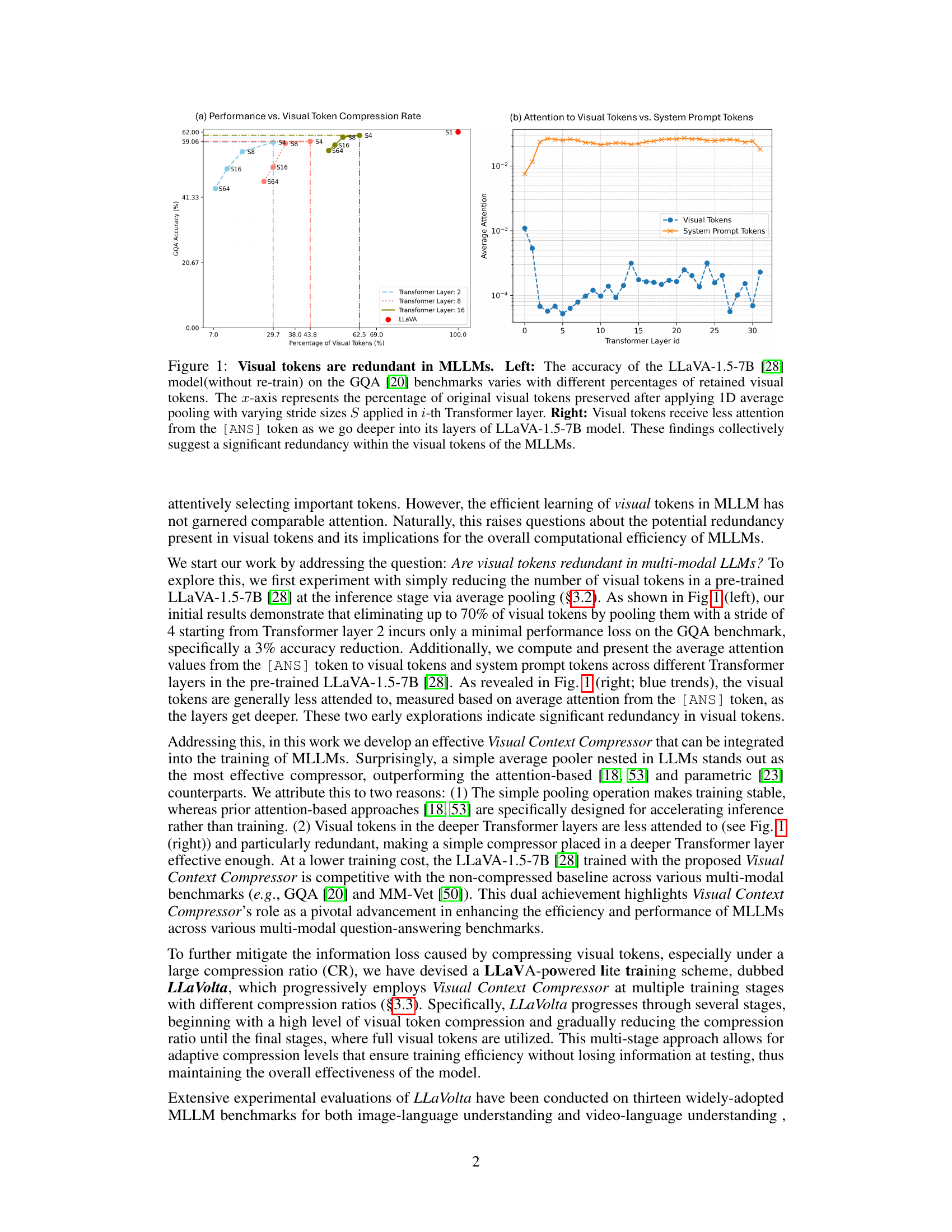
🔼 This figure shows experimental results supporting the claim that visual tokens are redundant in Multimodal Large Language Models (MLLMs). The left panel shows that reducing the number of visual tokens (up to 70%) at inference time by average pooling has minimal impact on the accuracy of visual question answering on the GQA benchmark. The right panel demonstrates that visual tokens receive progressively less attention from the system’s answer token as the model processes information through its layers. These findings collectively support the hypothesis of significant redundancy in visual tokens.
read the caption
Figure 1: Visual tokens are redundant in MLLMs. Left: The accuracy of the LLaVA-1.5-7B [28] model(without re-train) on the GQA [20] benchmarks varies with different percentages of retained visual tokens. The x-axis represents the percentage of original visual tokens preserved after applying 1D average pooling with varying stride sizes S applied in i-th Transformer layer. Right: Visual tokens receive less attention from the [ANS] token as we go deeper into its layers of LLaVA-1.5-7B model. These findings collectively suggest a significant redundancy within the visual tokens of the MLLMs.
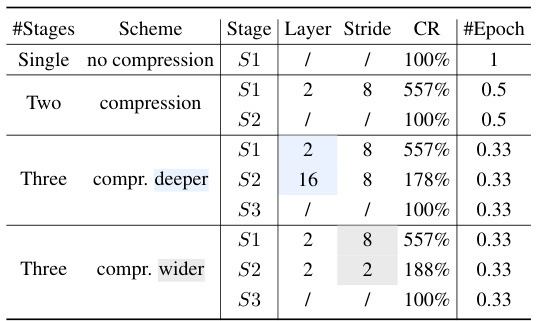
🔼 This table presents different instantiations of the LLaVolta training scheme. It shows variations in the number of training stages, the layer where the visual context compressor is applied, the stride of the compressor, the compression ratio, and the number of epochs. The variations illustrate different approaches to progressively reduce compression during training, aiming for optimal training efficiency and performance.
read the caption
Table 1: Instantiations of LLaVolta schemes. deeper indicates that the compressor's position in the LLM shifts from the shallow layer (e.g., 2) to a deeper layer (e.g., 16). wider indicates that the compressor's stride decreases while the number of visual tokens increases. Last stage compression refers to using compressor at last stage for efficient inference.
In-depth insights#
Visual Redundancy#
The concept of “Visual Redundancy” in the context of large multi-modal language models (MLLMs) is explored. The core idea revolves around the inefficiency of processing redundant visual information within these models. Initial experiments reveal significant redundancy; even with substantial visual token reduction (up to 70%), minimal performance loss is observed in tasks like visual question answering. This suggests that MLLMs often incorporate more visual details than is computationally necessary. Addressing this redundancy is crucial for improving MLLM efficiency. Therefore, techniques like Visual Context Compression, such as those involving average pooling, offer a way to enhance both training and inference speeds without major performance degradation. The effectiveness of this approach is demonstrated in improving inference and reducing training costs while maintaining accuracy, showcasing the potential of optimized visual token processing to drastically improve the efficiency of MLLMs.
LLaVolta Training#
LLaVolta’s training methodology is a key innovation for efficient multi-modal learning. It cleverly addresses the redundancy in visual tokens by progressively compressing them throughout training. The method starts with heavy compression in early stages, gradually reducing this compression as training advances. This approach minimizes information loss, which is a critical concern when dealing with visual compression. The staged approach allows the model to learn robust representations initially with less data and refine the representations in later stages. This progressive approach allows the model to focus on learning with more compressed visual data, only gradually increasing the visual token complexity, which significantly improves training efficiency and avoids early overfitting issues. Finally, the light and staged training paradigm ensures that LLaVolta maintains competitive performance while utilizing fewer visual tokens at inference time, thereby achieving the dual goals of efficiency and accuracy.
Compression Impact#
Analyzing the ‘Compression Impact’ section of a research paper requires a nuanced understanding of the trade-offs involved. A key consideration is the impact on model accuracy. Does compression significantly reduce the performance of the model on downstream tasks? The paper should quantify this with rigorous experimentation across multiple metrics. Another crucial aspect is the impact on computational resources. A successful compression strategy should demonstrate considerable savings in terms of memory usage, training time, and inference speed. The paper needs to provide clear benchmarks comparing compressed and uncompressed models. It’s important to examine the impact on various model components, such as the encoder and decoder. Does the compression disproportionately affect one component over another? Finally, generalizability is a key concern. The paper needs to demonstrate that the compression technique remains effective across various datasets and model architectures, indicating its wider applicability.
Efficient MLLMs#
Efficient Multi-modal Large Language Models (MLLMs) are crucial for practical applications due to the high computational cost of processing both textual and visual data. Strategies to enhance efficiency include optimizing visual token representation, exploring redundancy within visual contexts, and developing efficient training paradigms. Visual context compression emerges as a key technique, aiming to reduce the number of visual tokens without sacrificing accuracy. This can be achieved through various methods like average pooling, attention mechanisms, or more sophisticated compression schemes, each with trade-offs in performance and efficiency. Progressive compression during training helps in information preservation, where the model is initially trained with heavy compression and gradually transitions to less compressed data. This staged approach aims to balance efficiency and accuracy, mitigating potential information loss due to aggressive compression. The success of such methods heavily depends on the careful consideration of factors like the choice of compression method, its placement within the model architecture, and the design of a suitable training schedule. Future research should focus on developing more sophisticated compression techniques that dynamically adapt to the complexity of visual inputs, exploring novel architectural designs that better handle compressed visual representations, and evaluating the effectiveness of these methods across diverse multi-modal tasks and datasets.
Future Directions#
Future research could explore more sophisticated visual context compression techniques beyond simple average pooling, potentially leveraging attention mechanisms or learned representations to minimize information loss while maximizing compression. Investigating the interplay between compression ratios and model performance across various model architectures and datasets is crucial to establish optimal strategies for different scenarios. Furthermore, extending these methods to other multi-modal tasks beyond image-language understanding, such as video understanding, audio-visual processing, and even more complex multi-modal interactions involving touch or other modalities, presents exciting possibilities. A deeper understanding of the relationship between visual redundancy, attention mechanisms, and the inherent information content of visual data is needed. Finally, investigating the impact of different training schemes, such as incorporating progressive compression during training, on model robustness and generalization remains a key area for future exploration.
More visual insights#
More on figures
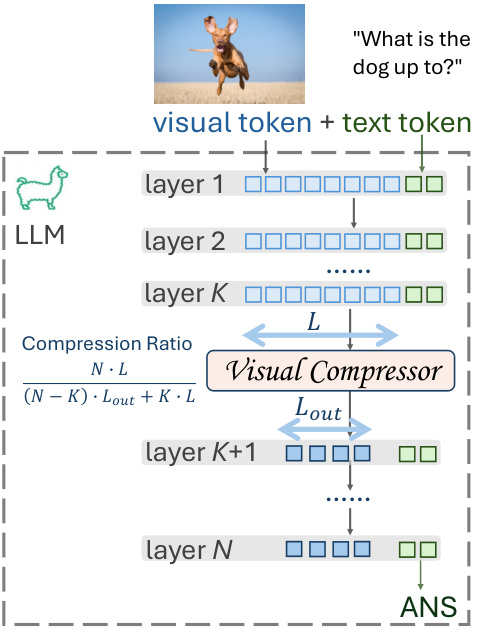
🔼 This figure illustrates how the Visual Context Compressor is integrated into a multi-modal large language model (MLLM). The compressor is applied to the visual tokens at the k-th transformer layer, reducing their length from L to Lout. This reduces the number of visual tokens processed by the subsequent layers, improving efficiency. The compression ratio is calculated as N*L/((N-K)Lout + KL), where N is the total number of transformer layers, K is the layer at which the compressor is applied, L is the initial length of visual tokens and Lout is the length after compression.
read the caption
Figure 2: Example of Visual Context Compressor in a multi-modal LLM.

🔼 This figure illustrates the difference between the traditional approach of training and inference for multi-modal LLMs and the proposed LLaVolta method. The traditional approach uses full visual tokens throughout the process. In contrast, LLaVolta introduces a three-stage training scheme with progressively decreasing compression ratios. Stage I starts with heavy compression, Stage II uses light compression in deeper layers, and Stage III uses subtle compression with a wider token window during inference, aiming to improve efficiency without sacrificing performance.
read the caption
Figure 3: Training & inference paradigm comparison for conventional setting (A) and LLaVolta (B). Meta framework of LLaVolta consists three training stages: Stage I with heavy visual compression; Stage II with light visual compression in deeper layer; Stage III with subtle compression with wider token window without loss of performance. This can accelerate the training and inference by 18+% while maintaining performance.
More on tables

🔼 This table presents various instantiations of the LLaVolta training schemes. It shows different configurations for the number of stages, the layer at which the compressor is applied, the stride of the compressor, the compression ratio (CR), and the number of epochs for each stage. The table illustrates how different approaches to applying visual context compression during training can lead to various training efficiency and performance tradeoffs.
read the caption
Table 1: Instantiations of LLaVolta schemes. deeper indicates that the compressor's position in the LLM shifts from the shallow layer (e.g., 2) to a deeper layer (e.g., 16). wider indicates that the compressor's stride decreases while the number of visual tokens increases. Last stage compression refers to using compressor at last stage for efficient inference.

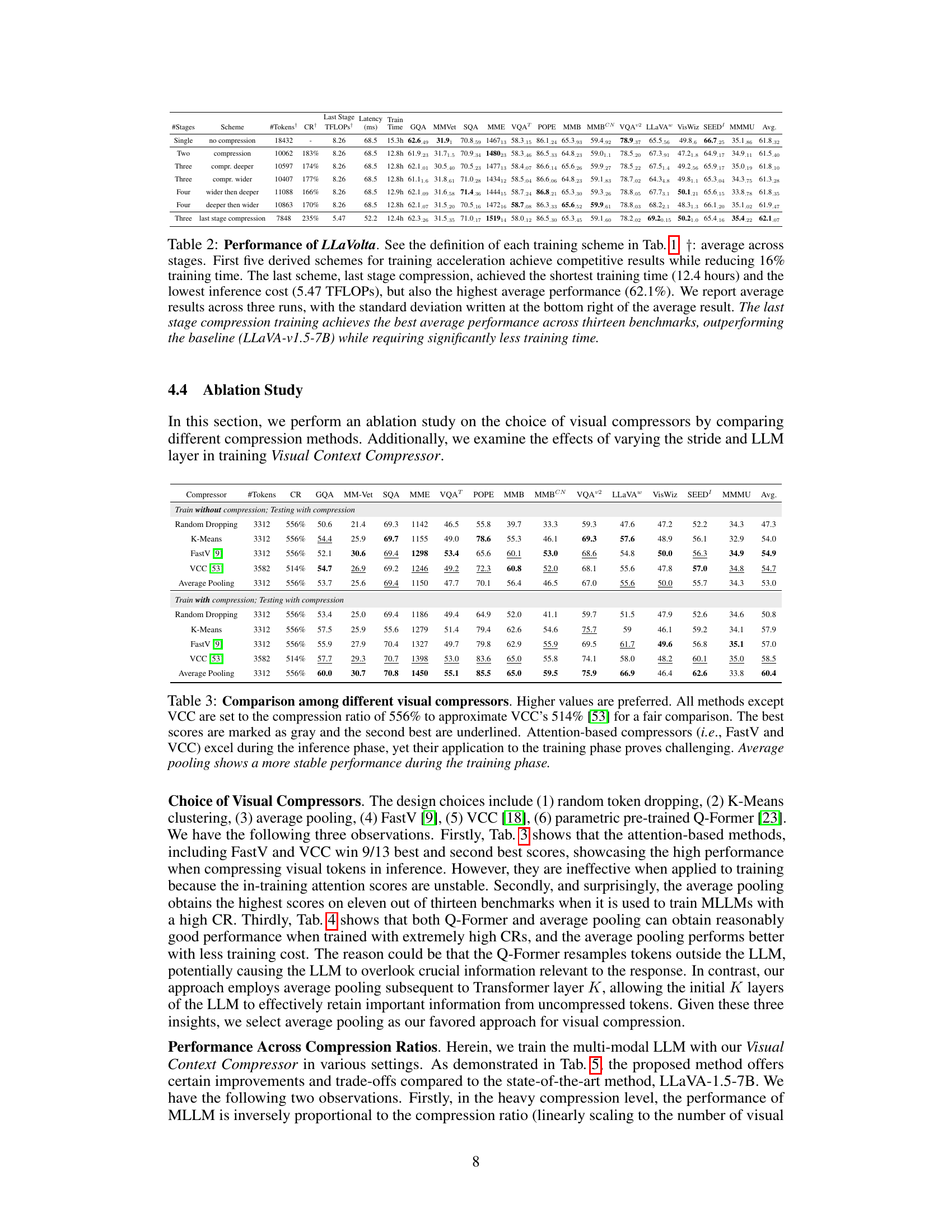
🔼 This table presents the performance of different LLaVolta training schemes across thirteen benchmarks. It shows that several schemes achieve competitive results while reducing training time significantly. The best performing scheme is ’last stage compression’, which achieves the highest average performance while requiring the shortest training time and lowest inference cost.
read the caption
Table 2: Performance of LLaVolta. See the definition of each training scheme in Tab. 1. †: average across stages. First five derived schemes for training acceleration achieve competitive results while reducing 16% training time. The last scheme, last stage compression, achieved the shortest training time (12.4 hours) and the lowest inference cost (5.47 TFLOPs), but also the highest average performance (62.1%). We report average results across three runs, with the standard deviation written at the bottom right of the average result. The last stage compression training achieves the best average performance across thirteen benchmarks, outperforming the baseline (LLaVA-v1.5-7B) while requiring significantly less training time.

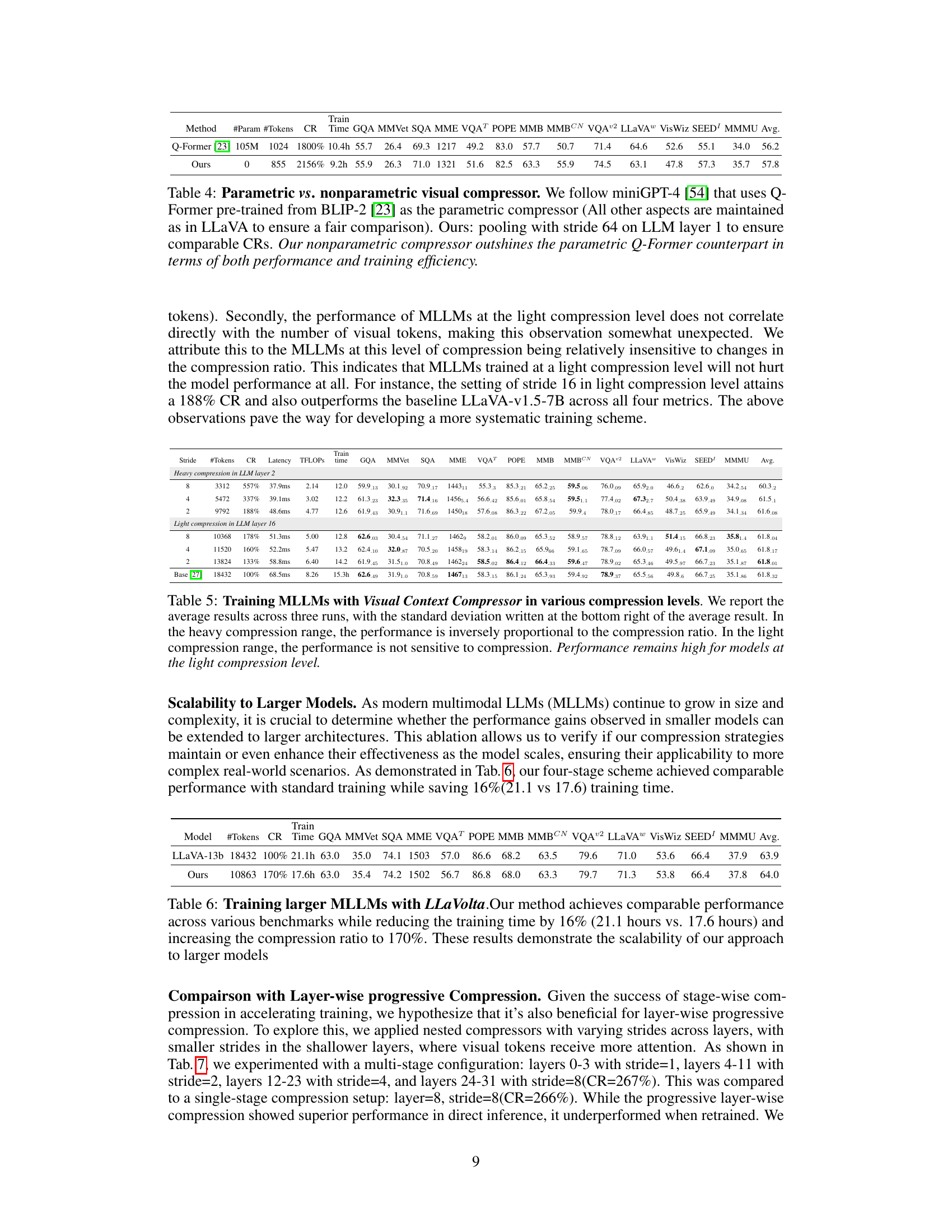
🔼 This table compares the performance of different visual compression methods (random dropping, K-Means, FastV, VCC, and average pooling) used within a multi-modal language model (MLLM). The comparison includes both inference and training phases. It highlights the trade-offs between attention-based methods (generally better inference, but unstable training) and average pooling (more stable training, competitive inference).
read the caption
Table 3: Comparison among different visual compressors. Higher values are preferred. All methods except VCC are set to the compression ratio of 556% to approximate VCC's 514% [53] for a fair comparison. The best scores are marked as gray and the second best are underlined. Attention-based compressors (i.e., FastV and VCC) excel during the inference phase, yet their application to the training phase proves challenging. Average pooling shows a more stable performance during the training phase.

🔼 This table compares the performance of different visual compressors, including a parametric compressor (Q-Former) and a non-parametric compressor (average pooling). The results demonstrate that the proposed non-parametric approach outperforms the parametric method in terms of both performance and training efficiency, even when using a higher compression ratio.
read the caption
Table 4: Parametric vs. nonparametric visual compressor. We follow miniGPT-4 [54] that uses Q-Former pre-trained from BLIP-2 [23] as the parametric compressor (All other aspects are maintained as in LLaVA to ensure a fair comparison). Ours: pooling with stride 64 on LLM layer 1 to ensure comparable CRs. Our nonparametric compressor outshines the parametric Q-Former counterpart in terms of both performance and training efficiency.
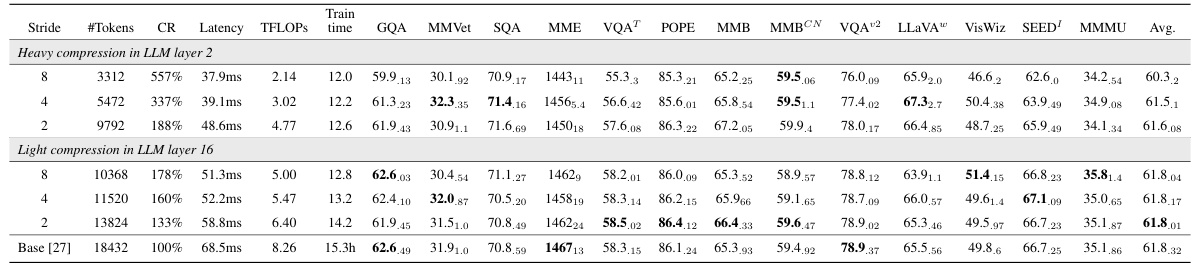
🔼 This table presents the performance of different LLaVolta training schemes across various benchmarks. It highlights the trade-off between training time, inference cost, and model performance, showcasing the effectiveness of the proposed LLaVolta approach in achieving competitive results with significantly reduced training time and cost.
read the caption
Table 2: Performance of LLaVolta. See the definition of each training scheme in Tab. 1. †: average across stages. First five derived schemes for training acceleration achieve competitive results while reducing 16% training time. The last scheme, last stage compression, achieved the shortest training time (12.4 hours) and the lowest inference cost (5.47 TFLOPs), but also the highest average performance (62.1%). We report average results across three runs, with the standard deviation written at the bottom right of the average result. The last stage compression training achieves the best average performance across thirteen benchmarks, outperforming the baseline (LLaVA-v1.5-7B) while requiring significantly less training time.

🔼 This table presents the performance of different LLaVolta training schemes on thirteen benchmark datasets. It compares metrics like training time, inference cost (TFLOPs), and accuracy across various multi-modal understanding tasks. The table highlights the trade-off between training efficiency and performance, showcasing the superior performance of the ’last stage compression’ scheme which achieves the highest average performance with significantly reduced training time and inference cost.
read the caption
Table 2: Performance of LLaVolta. See the definition of each training scheme in Tab. 1. †: average across stages. First five derived schemes for training acceleration achieve competitive results while reducing 16% training time. The last scheme, last stage compression, achieved the shortest training time (12.4 hours) and the lowest inference cost (5.47 TFLOPs), but also the highest average performance (62.1%). We report average results across three runs, with the standard deviation written at the bottom right of the average result. The last stage compression training achieves the best average performance across thirteen benchmarks, outperforming the baseline (LLaVA-v1.5-7B) while requiring significantly less training time.

🔼 This table presents the performance comparison of different LLaVolta training schemes (single-stage, two-stage, three-stage, etc.) across various multi-modal benchmarks. It shows that the last-stage compression training scheme achieves the best performance with the lowest training time and inference cost, outperforming the baseline while reducing training time by 16%.
read the caption
Table 2: Performance of LLaVolta. See the definition of each training scheme in Tab. 1. †: average across stages. First five derived schemes for training acceleration achieve competitive results while reducing 16% training time. The last scheme, last stage compression, achieved the shortest training time (12.4 hours) and the lowest inference cost (5.47 TFLOPs), but also the highest average performance (62.1%). We report average results across three runs, with the standard deviation written at the bottom right of the average result. The last stage compression training achieves the best average performance across thirteen benchmarks, outperforming the baseline (LLaVA-v1.5-7B) while requiring significantly less training time.
🔼 This table presents the performance comparison of different LLaVolta training schemes across 13 benchmarks. It shows that LLaVolta significantly reduces training time and inference costs while improving or maintaining performance compared to the baseline LLaVA-v1.5-7B model.
read the caption
Table 2: Performance of LLaVolta. See the definition of each training scheme in Tab. 1. †: average across stages. First five derived schemes for training acceleration achieve competitive results while reducing 16% training time. The last scheme, last stage compression, achieved the shortest training time (12.4 hours) and the lowest inference cost (5.47 TFLOPs), but also the highest average performance (62.1%). We report average results across three runs, with the standard deviation written at the bottom right of the average result. The last stage compression training achieves the best average performance across thirteen benchmarks, outperforming the baseline (LLaVA-v1.5-7B) while requiring significantly less training time.
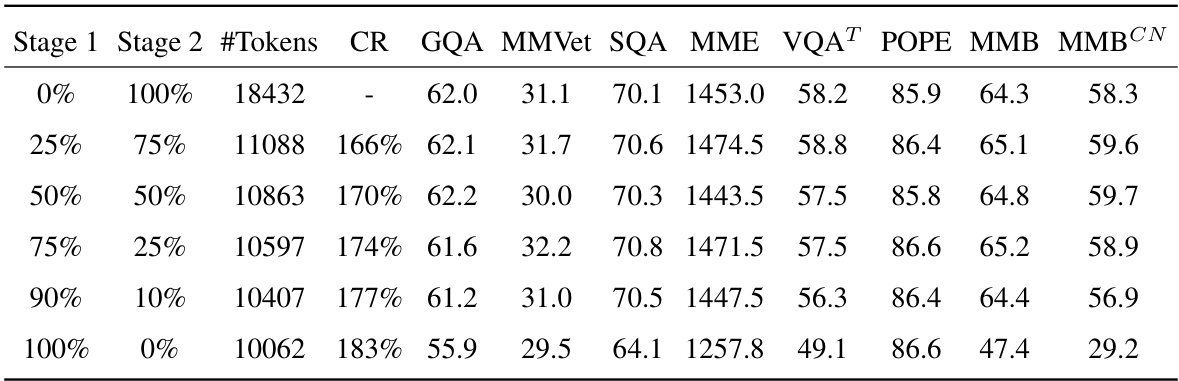
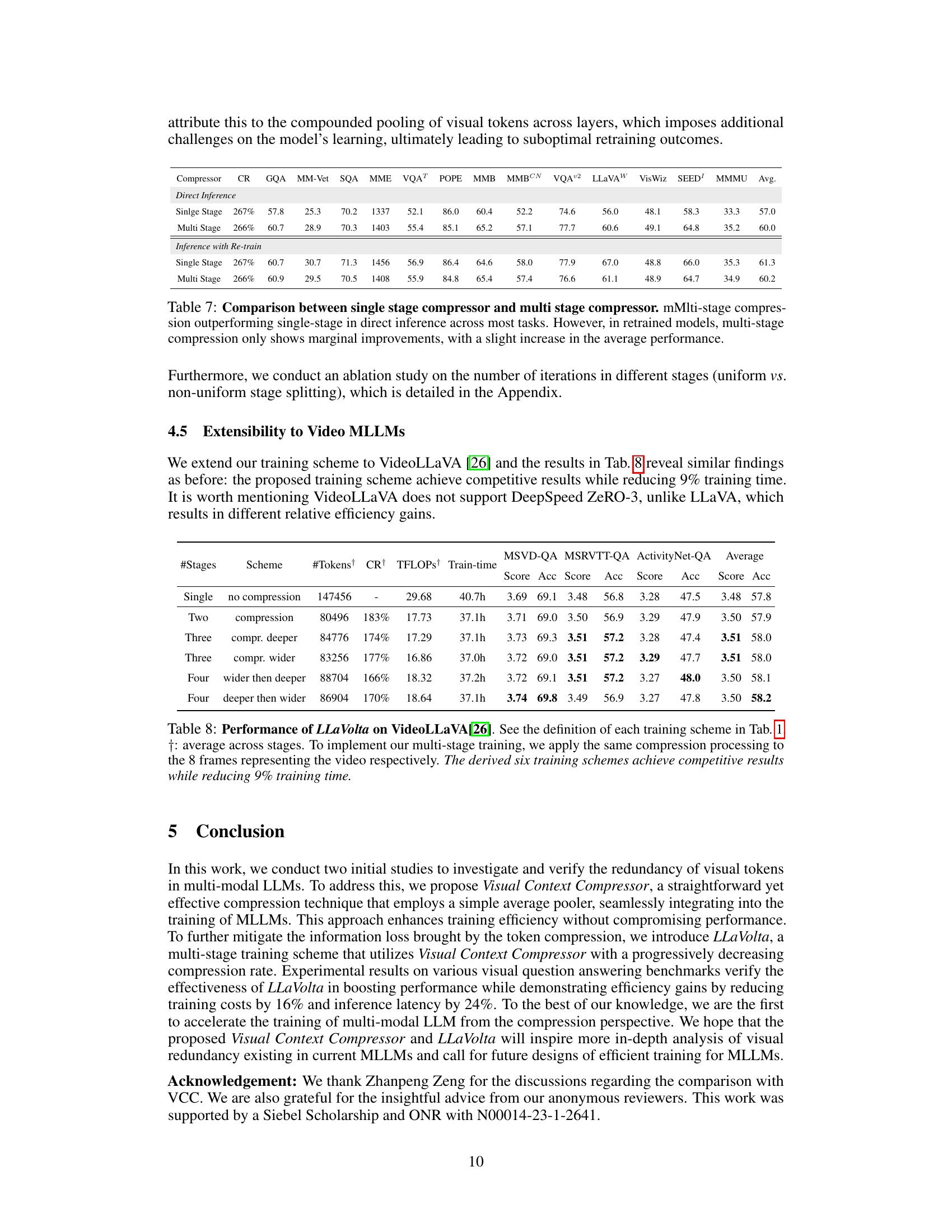
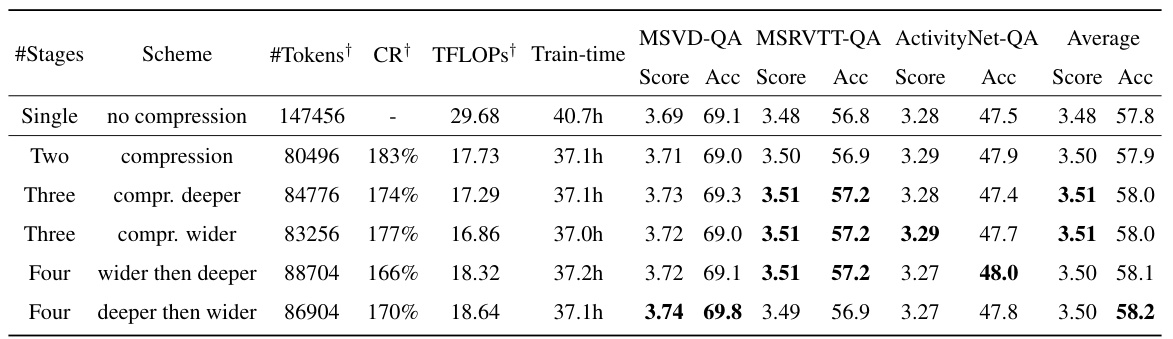
🔼 This table shows the results of experiments using a two-stage training scheme with varying proportions of training time allocated to each stage. The results demonstrate that model performance decreases as the proportion of training time dedicated to the second stage (which uses a lower compression ratio) decreases. This suggests a trade-off between training efficiency and performance.
read the caption
Table 9: Effects of non-uniform stage splitting at the two-stage set-up. Performance decreases as the proportion of Stage 2 decreases, albeit at the expense of lower compression ratios.

🔼 This table compares the performance of the proposed LLaVolta method against a Mini-Gemini baseline on various multi-modal benchmarks. It highlights the ability of LLaVolta to achieve comparable or even better results with reduced training time, demonstrating its adaptability to different model architectures.
read the caption
Table 10: Training struturally distinct MLLMs with LLaVolta.Comparison of our method with the Mini-Gemini (MGM-2B) baseline, which uses a multi-resolution visual encoding strategy. Our approach demonstrates competitive performance while reducing training time by 18% (18.1 hours vs. 14.8 hours) and achieving higher scores. This ablation highlights LLaVolta's ability to adapt to different model structures and sophisticated visual encoding strategies.
Full paper#