TL;DR#
Current co-speech gesture generation methods, while showing progress, face challenges like high computational cost and unnatural results, especially when dealing with diverse body movements. These limitations hinder real-time applications. The research highlights the limitations of RNNs, transformers, and diffusion models, particularly concerning computational cost and long-term dependency issues.
This paper introduces MambaTalk, which leverages selective state space models (SSMs) and a two-stage approach (discrete motion priors followed by SSMs with hybrid fusion modules). This method significantly improves gesture quality and outperforms state-of-the-art models, demonstrating the potential of SSMs for efficient and high-quality co-speech gesture generation.
Key Takeaways#
Why does it matter?#
This paper is important because it presents MambaTalk, a novel and efficient approach to gesture synthesis that significantly outperforms existing methods. Its use of selective state space models and a two-stage modeling strategy addresses computational limitations and improves the quality of generated gestures. This opens new avenues for research in HCI and related fields where realistic and low-latency gesture generation is crucial, such as virtual reality and robotics.
Visual Insights#

🔼 This figure illustrates the two-stage process of the proposed MambaTalk model. Stage 1 involves learning discrete motion priors using VQ-VAEs to generate a codebook of holistic gestures. Stage 2 uses a speech-driven state space model with selective scanning (local and global) to refine the latent space representation and generate final co-speech gestures. The figure visually shows the input and output of each stage using stylized figures.
read the caption
Figure 1: Our two-stage method for co-speech gesture generation with selective state space models. In the first stage, we construct discrete motion spaces to learn specific motion codes. In the second stage, we develop a speech-driven model of the latent space using selective scanning mechanisms.
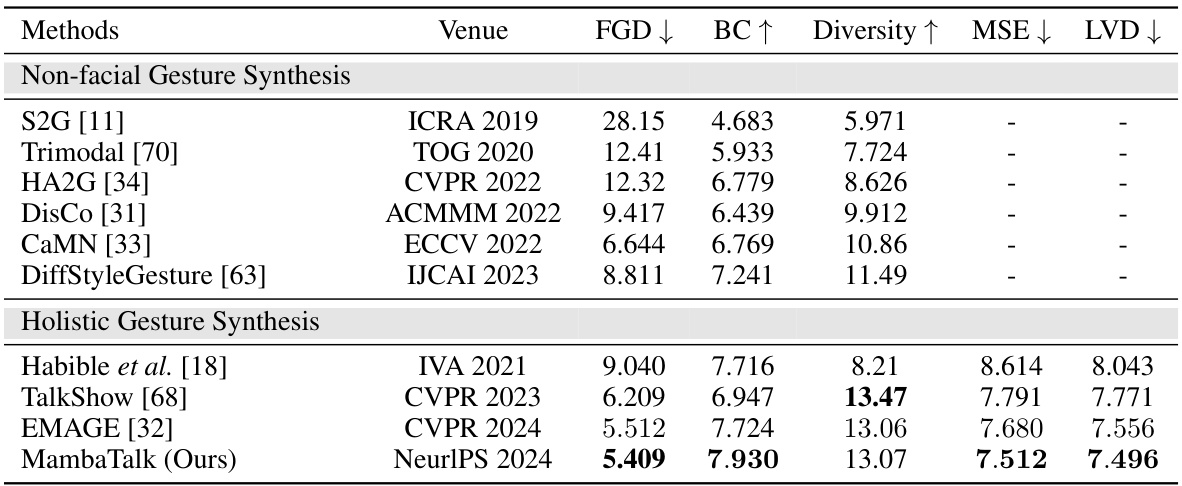
🔼 This table presents a quantitative comparison of the proposed MambaTalk method with several state-of-the-art co-speech gesture generation models on the BEATX benchmark dataset. The evaluation metrics include Fréchet Gesture Distance (FGD), which measures the similarity of gesture distributions; Beat Constancy (BC), which assesses the synchronization between gestures and speech rhythm; Diversity, which quantifies the variety of generated gestures; Mean Squared Error (MSE), which evaluates the accuracy of facial motion generation; and Learned Vector Distance (LVD), which measures the accuracy of facial landmark predictions. Lower FGD and MSE/LVD values, and higher BC and Diversity values indicate better performance. MambaTalk achieves the best results in BC and performs competitively with other state-of-the-art methods.
read the caption
Table 1: Quantitative results on BEATX. FGD (Frechet Gesture Distance) multiplied by 10-1, BC (Beat Constancy) multiplied by 10-1, Diversity, MSE (Mean Squared Error) multiplied by 10-7, and LVD (Learned Vector Distance) multiplied by 10-5. The best results are in bold.
In-depth insights#
Holistic Gesture Synth#
Holistic gesture synthesis aims to generate realistic and natural-looking full-body movements, encompassing facial expressions, hand gestures, and body postures. A key challenge lies in the complex interplay between different body parts and the need for synchronized and expressive motion. Successful methods often involve sophisticated modeling techniques such as deep neural networks, which capture the nuanced relationships between various modalities (e.g., audio, text, and visual input). The integration of diverse data sources and the use of advanced architectures such as transformers or diffusion models is crucial for achieving high-fidelity and diversity in the synthesized gestures. Moreover, efficient computational methods are important for practical applications, especially those that demand real-time performance such as virtual reality or robotics. Effective approaches frequently leverage discrete representations of motion, enabling efficient training and generation, and incorporating attention mechanisms to refine the details and temporal coherence of the output. In the future, research should focus on enhancing the naturalness and expressiveness of gestures, improving computational efficiency, and investigating the potential of novel architectures for more accurate and flexible movement modeling.
SSM-based Modeling#
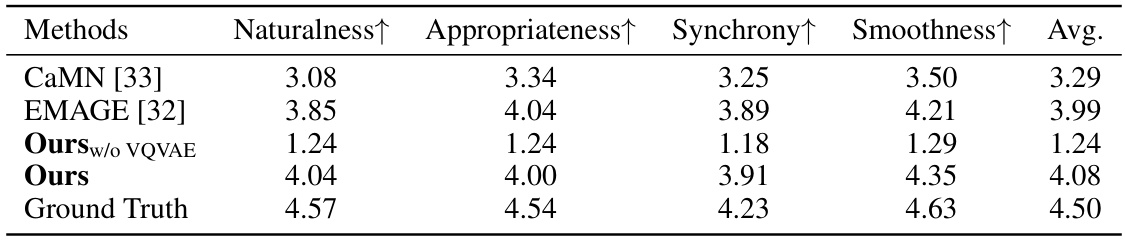
Employing state-space models (SSMs) for gesture synthesis presents a compelling approach due to SSM’s inherent capacity for efficient sequence modeling and low-latency generation. However, the diverse dynamics of human body parts pose a challenge. Direct application of SSMs may result in unnatural or jittery movements. A sophisticated strategy is needed to effectively leverage SSMs. A two-stage process, for instance, incorporating discrete motion priors from VQVAEs in the first stage to capture diverse movement patterns, and then using SSMs in the second stage for speech-driven latent space modeling. This strategy addresses the challenge of varied body dynamics. Selective scan mechanisms, like local and global scans, further enhance latent space representation refinement. This dual approach integrates hybrid fusion modules to generate more natural and rhythmic gestures with low latency, surpassing the performance of other models.
Selective Scan Fusion#
Selective Scan Fusion, as a conceptual method, aims to improve the efficiency and quality of data processing by strategically focusing on the most relevant information. It likely involves a two-stage process: selection and fusion. The selection stage employs a mechanism to identify and isolate the most pertinent data points from a larger dataset. This could utilize attention mechanisms, or other techniques prioritizing information based on context or importance. The fusion stage combines the selected data from different sources or perspectives. This might involve techniques such as hybrid fusion modules that integrate local and global scans, combining both fine-grained details with broader context. The result would be an enhanced representation that is both detailed and comprehensive, while significantly reducing processing time and resource consumption. Overall, this approach shows great promise for improving model accuracy and reducing computational cost. This is particularly relevant in applications such as speech-driven gesture synthesis, where the high dimensionality of the data and the need for real-time processing present significant challenges. However, implementation details, such as the specific selection and fusion methods employed, remain crucial to evaluating the effectiveness and suitability of Selective Scan Fusion.
MambaTalk: A Deep Dive#
MambaTalk, as a hypothetical title suggesting a deep dive into a research paper, likely explores a novel speech-driven gesture synthesis system. The name itself hints at a sophisticated and efficient approach, perhaps leveraging state-space models, given the mention of “Mamba” which frequently alludes to optimized and scalable solutions. A deep dive would thoroughly dissect the system’s architecture, detailing the model’s construction, training methodology, and its performance metrics. Key insights would include its ability to generate high-quality, natural-looking, and synchronized gestures, potentially overcoming limitations of existing methods in handling long sequences and diverse body movements. The analysis would critically evaluate the efficiency of MambaTalk in terms of computation speed and memory usage, comparing favorably against prior approaches. A key aspect would involve discussing the innovative ways in which MambaTalk addresses common problems like jittering or unnatural movement and the novel solutions it introduces to generate more human-like and expressive gesture synthesis. Finally, a deeper examination could explore the model’s adaptability to various styles and emotional expressions, showcasing its potential in diverse applications such as filmmaking, virtual reality, and human-computer interaction. The deep dive would conclude with a perspective on its limitations and potential future research directions.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Improving the efficiency and reducing the latency of the gesture generation model is crucial for real-time applications. This might involve exploring more efficient architectures, optimization techniques, or perhaps leveraging hardware acceleration. Another key area is enhancing the model’s robustness to noisy or incomplete speech inputs, which is critical for real-world deployment. Research into advanced speech processing techniques could enhance the model’s ability to handle diverse accents, background noise, and varying speech qualities. Furthermore, investigating the incorporation of additional modalities like facial expressions, body language, or even emotional context alongside speech could enable the generation of even more realistic and expressive gestures. Finally, expanding the scope of the dataset used to train the model to include more diverse speakers, languages, and cultural contexts could significantly improve the model’s generalizability and reduce potential biases.
More visual insights#
More on figures

🔼 This figure illustrates the proposed two-stage method for co-speech gesture generation. The first stage uses multiple Vector Quantized Variational Autoencoders (VQ-VAEs) to learn discrete motion priors for different body parts (face, upper body, lower body, hands). These priors are represented as codebooks. The second stage employs a speech-driven model using selective state space models (SSMs). This stage incorporates local and global scan modules to refine latent space representations of the movements, improving gesture quality and synchronicity with speech. The model receives input from audio, text, and speaker embeddings, and generates 3D co-speech gestures.
read the caption
Figure 2: We propose a two-stage method for co-speech gesture generation. We first train multiple VQ-VAEs for face and different parts of body reconstruction. This step learns discrete motion priors through multiple codebooks. In the second stage, we train a speech-driven gesture generation model in the latent motion space with local and global scan modules.
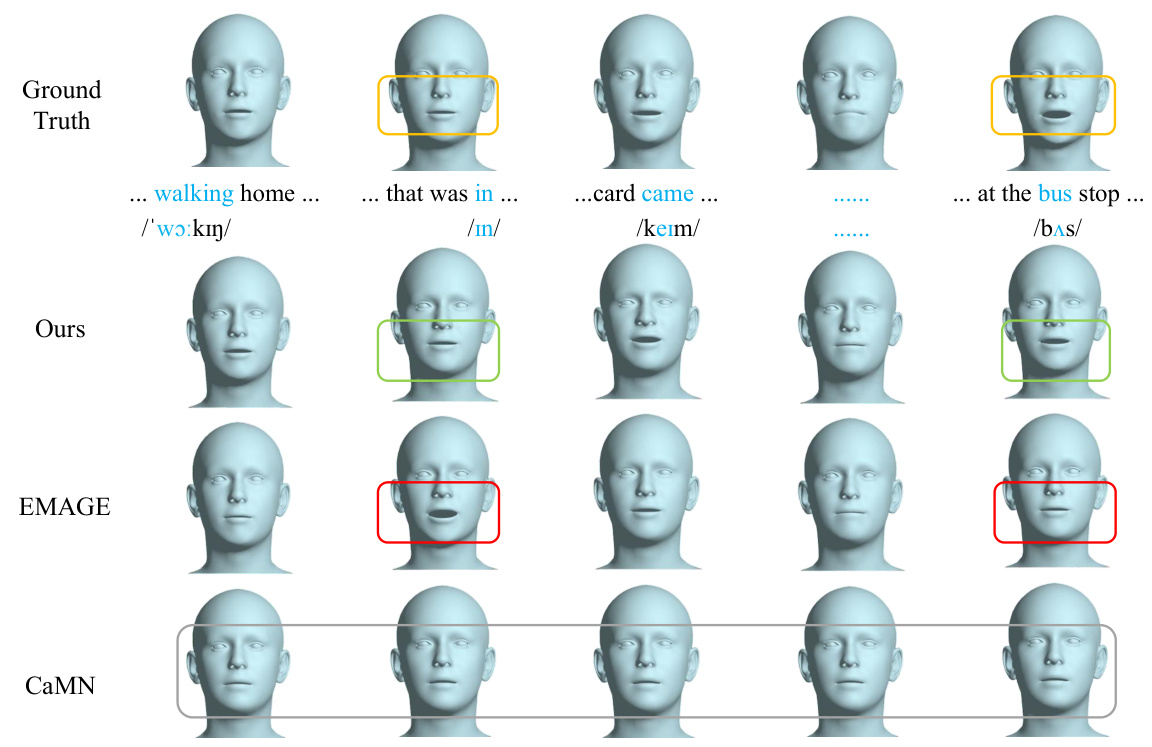
🔼 This figure compares the facial motion generation results of three methods: CaMN, EMAGE, and the proposed MambaTalk. It visually demonstrates the alignment between generated facial expressions and phonetic articulation in speech. The results show that MambaTalk’s approach better captures the subtle movements and nuances of mouth closure and opening required for different sounds, aligning closely with the ground truth. In contrast, the other two methods show less accuracy in aligning facial movements with the phonetic content and often lack variations in facial expressions, especially in silent segments.
read the caption
Figure 4: Visualization of the facial motions generated by CaMN, EMAGE and our method. Unreasonable results are indicated by red and gray boxes and reasonable ones by green boxes.

🔼 This figure compares the gesture generation results of three different methods: CaMN, EMAGE, and the proposed method (MambaTalk). It visually demonstrates how each method generates gestures for specific phrases, highlighting the differences in realism and accuracy. The red boxes indicate instances where the generated gestures deviate significantly from the expected natural movements, showing limitations in the other two methods. The green boxes highlight instances where the generated gestures closely align with the ground truth. This figure is crucial to illustrate the quality and naturalness of the proposed MambaTalk method compared to existing state-of-the-art approaches.
read the caption
Figure 5: Visualization of the gestures generated by CaMN, EMAGE and our method. Unreasonable results are indicated by red boxes and reasonable ones by green boxes.

🔼 This figure illustrates the two-stage process of the proposed MambaTalk model. The first stage involves training multiple Vector Quantized-Variational Autoencoders (VQ-VAEs) to learn discrete motion priors for different body parts (face, hands, upper body, lower body). The second stage uses these learned priors in a speech-driven model, incorporating local and global scan modules to refine latent space representations for more natural and diverse gesture synthesis. The figure shows the data flow in each stage, highlighting the various components and their interconnections.
read the caption
Figure 2: We propose a two-stage method for co-speech gesture generation. We first train multiple VQ-VAEs for face and different parts of body reconstruction. This step learns discrete motion priors through multiple codebooks. In the second stage, we train a speech-driven gesture generation model in the latent motion space with local and global scan modules.
More on tables
🔼 This table presents a quantitative comparison of the proposed MambaTalk model with several state-of-the-art methods for co-speech gesture synthesis on the BEATX dataset. The performance is evaluated across multiple metrics: Fréchet Gesture Distance (FGD), Beat Constancy (BC), Diversity, Mean Squared Error (MSE) for hand and body, and Learned Vector Distance (LVD) for facial motion. Lower FGD and MSE values are better, while higher BC and Diversity are preferred. The table highlights the superior performance of MambaTalk in terms of Beat Constancy, and competitive performance in other metrics, indicating its ability to generate more realistic and diverse co-speech gestures.
read the caption
Table 1: Quantitative results on BEATX. FGD (Frechet Gesture Distance) multiplied by 10-1, BC (Beat Constancy) multiplied by 10-1, Diversity, MSE (Mean Squared Error) multiplied by 10-7, and LVD (Learned Vector Distance) multiplied by 10-5. The best results are in bold.

🔼 This table presents a quantitative comparison of the proposed MambaTalk model against several state-of-the-art methods for co-speech gesture generation on the BEATX dataset. The evaluation metrics include Fréchet Gesture Distance (FGD), Beat Constancy (BC), Diversity, Mean Squared Error (MSE), and Learned Vector Distance (LVD). Lower FGD and MSE values are better, indicating higher realism and accuracy; higher BC, Diversity, and LVD values are preferable, representing better synchronization, variation, and detail in the generated gestures.
read the caption
Table 1: Quantitative results on BEATX. FGD (Frechet Gesture Distance) multiplied by 10-1, BC (Beat Constancy) multiplied by 10-1, Diversity, MSE (Mean Squared Error) multiplied by 10-7, and LVD (Learned Vector Distance) multiplied by 10-5. The best results are in bold.

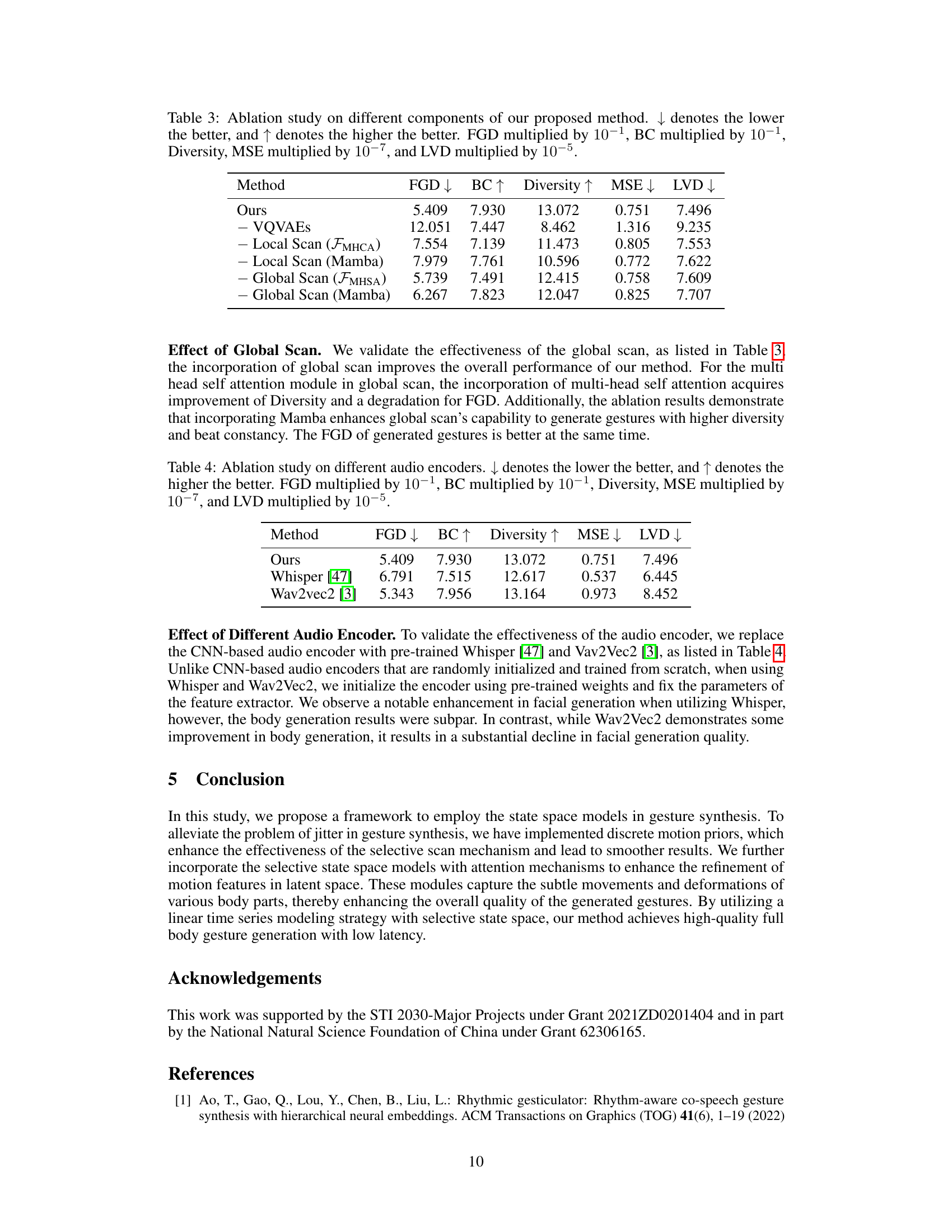
🔼 This table presents the results of an ablation study conducted to evaluate the impact of different components of the proposed MambaTalk model on its performance. The study systematically removes individual components (VQVAEs, Local Scan, Global Scan) and assesses their influence on key metrics: Fréchet Gesture Distance (FGD), Beat Constancy (BC), Diversity, Mean Squared Error (MSE), and Learned Vector Distance (LVD). Lower FGD and MSE values, along with higher BC and Diversity, indicate superior performance. The results highlight the relative contributions of each component to the overall effectiveness of the MambaTalk model.
read the caption
Table 3: Ablation study on different components of our proposed method. ↓ denotes the lower the better, and ↑ denotes the higher the better. FGD multiplied by 10-1, BC multiplied by 10-1, Diversity, MSE multiplied by 10-7, and LVD multiplied by 10-5.
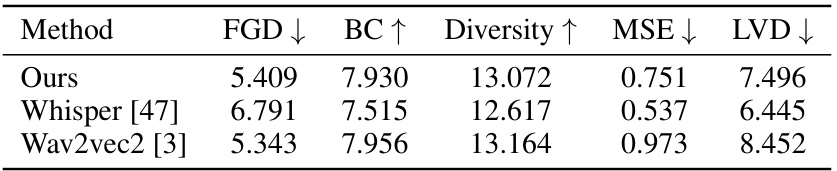
🔼 This table presents a quantitative comparison of the proposed MambaTalk model with other state-of-the-art methods for co-speech gesture synthesis on the BEATX dataset. The performance is evaluated using four metrics: Fréchet Gesture Distance (FGD), Beat Constancy (BC), Diversity, Mean Squared Error (MSE), and Learned Vector Distance (LVD). Lower values of FGD and MSE, and higher values of BC and Diversity indicate better performance. The best results for each metric are highlighted in bold, demonstrating MambaTalk’s superiority.
read the caption
Table 1: Quantitative results on BEATX. FGD (Frechet Gesture Distance) multiplied by 10-1, BC (Beat Constancy) multiplied by 10-1, Diversity, MSE (Mean Squared Error) multiplied by 10-7, and LVD (Learned Vector Distance) multiplied by 10-5. The best results are in bold.
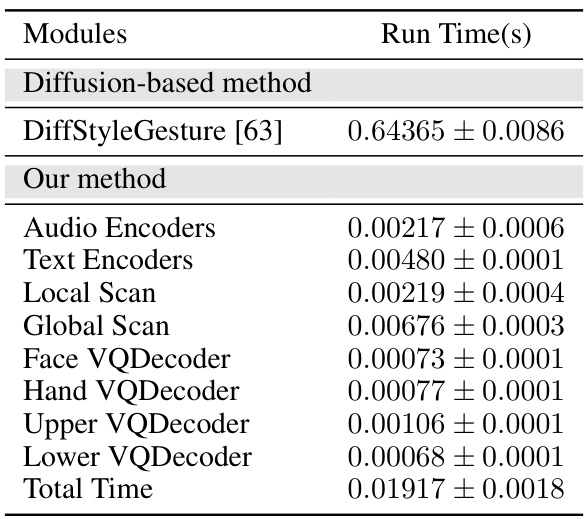
🔼 This table presents a quantitative comparison of the proposed MambaTalk model with several state-of-the-art methods for co-speech gesture synthesis. The evaluation is performed on the BEATX dataset, and the metrics used are Fréchet Gesture Distance (FGD), Beat Constancy (BC), Diversity, Mean Squared Error (MSE), and Learned Vector Distance (LVD). Lower values for FGD and MSE, and higher values for BC and Diversity, indicate better performance. The table highlights the superior performance of MambaTalk in terms of Beat Constancy, indicating strong synchronization between generated gestures and the rhythm of speech.
read the caption
Table 1: Quantitative results on BEATX. FGD (Frechet Gesture Distance) multiplied by 10-1, BC (Beat Constancy) multiplied by 10-1, Diversity, MSE (Mean Squared Error) multiplied by 10-7, and LVD (Learned Vector Distance) multiplied by 10-5. The best results are in bold.
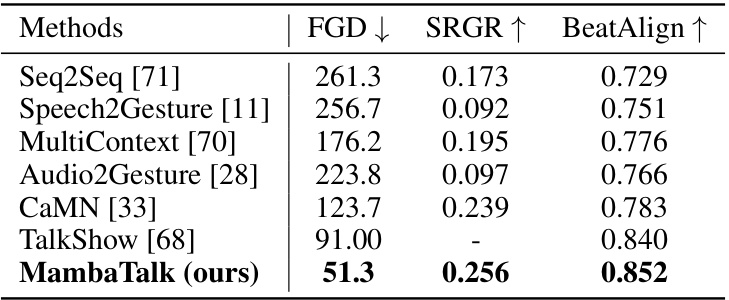
🔼 This table compares the performance of the proposed method, MambaTalk, with other state-of-the-art methods on the BEAT dataset. It shows the Fréchet Gesture Distance (FGD), which measures the realism of generated body gestures (lower is better); the SRGR (Synchrony Rate of Gesture and Rhythm), which assesses the synchronization between gestures and speech rhythm (higher is better); and the BeatAlign metric, which evaluates the alignment of gesture beats with speech beats (higher is better). The results demonstrate MambaTalk’s superior performance in terms of both gesture realism and synchronization with speech.
read the caption
Table 6: Comparison with state-of-the-art method in the term of FGD, SRGR and BeatAlign. All methods are trained on BEAT datasets. ↓ denotes the lower the better while ↑ denotes the higher the better. The best results are in bold.
Full paper#