TL;DR#
Federated learning (FL) faces challenges with heterogeneous models and non-IID data. Existing methods struggle to effectively transfer knowledge between diverse client and server models, leading to performance limitations and high resource consumption. This often results in suboptimal model performance, especially when dealing with variations in client model structures and data distributions.
The proposed FedMRL framework overcomes these issues by introducing adaptive representation fusion and multi-granularity representation learning. It adds a shared, homogeneous auxiliary model to each client’s heterogeneous model; their features are fused and used to build Matryoshka representations which are then learned by the shared and local models respectively. This approach greatly improves knowledge transfer. Experimental results show FedMRL achieves significantly higher accuracy than existing methods with reduced communication and computational overheads, showcasing its potential for efficient and privacy-preserving FL in diverse settings.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning, particularly those working on model heterogeneity. It presents a novel approach, FedMRL, that significantly improves accuracy while addressing communication and computational limitations inherent in existing methods. The theoretical analysis and experimental results provide strong evidence of its effectiveness, thus opening exciting avenues for future research in this area.
Visual Insights#
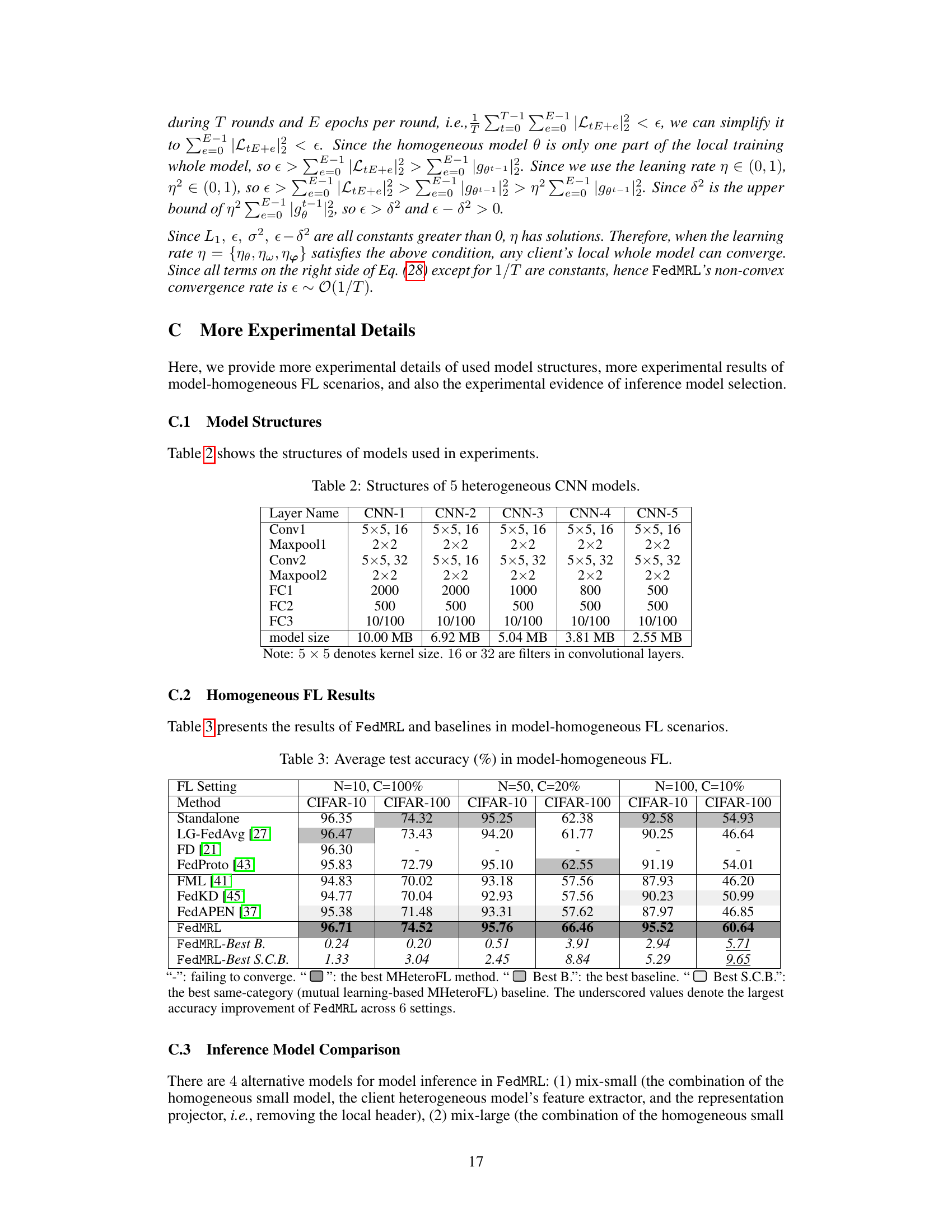
🔼 This figure illustrates the Matryoshka Representation Learning (MRL) architecture. The left panel shows the overall MRL process: a feature extractor takes an input (x) and produces Matryoshka representations (different colors and sizes) from which multiple predictions (ŷ) are derived. Each prediction is associated with a loss (l), and the losses are aggregated. The right panel shows the architecture of both the feature extractor and prediction header components, which include convolutional layers (Conv), fully connected layers (FC), and a final output layer for the prediction (ŷ). The figure helps explain how MRL learns multi-granular representations.
read the caption
Figure 1: Left: Matryoshka Representation Learning. Right: Feature extractor and prediction header.

🔼 This table presents the average test accuracy achieved by different federated learning methods (including FedMRL and several baselines) on CIFAR-10 and CIFAR-100 datasets under various settings. The settings vary the number of clients (N) and the client participation rate (C). The results show FedMRL’s superior performance compared to the baselines, especially in terms of accuracy improvement.
read the caption
Table 1: Average test accuracy (%) in model-heterogeneous FL.
In-depth insights#
MHeteroFL Landscape#
The landscape of Model Heterogeneous Federated Learning (MHeteroFL) is complex and rapidly evolving. Early approaches focused on adapting a single global model to diverse client devices and data distributions, often through techniques like subnetwork adaptation or model splitting. However, these methods often struggle with knowledge transfer between heterogeneous clients and the server, leading to suboptimal performance. More recent methods leverage knowledge distillation or mutual learning to facilitate this knowledge sharing, but still face challenges in handling significant data or model heterogeneity. Future directions in MHeteroFL research should explore more sophisticated representation learning techniques, perhaps inspired by multi-task learning or transfer learning, to better leverage shared information across heterogeneous models. Furthermore, robust aggregation methods are needed to handle the varying model structures and training dynamics arising from diverse client environments. Addressing these challenges will be crucial to unlocking the full potential of MHeteroFL and enabling truly collaborative learning in heterogeneous settings.
FedMRL Approach#
The FedMRL approach tackles the challenges of model heterogeneity in federated learning by introducing a novel framework. Central to this approach is the use of a global homogeneous small model alongside each client’s heterogeneous local model. This design allows for knowledge sharing between the models without directly exposing the clients’ private model structures. FedMRL employs adaptive representation fusion, combining generalized and personalized representations from both models, and multi-granularity representation learning to enhance model learning capability. The framework achieves superior accuracy with low communication and computational overhead compared to existing methods. A key innovation is the use of a lightweight representation projector, allowing for adaptation to diverse local data distributions and efficient knowledge transfer between the global and local models. This combination of techniques addresses data, system, and model heterogeneity effectively. Theoretical analysis provides a convergence rate guarantee, supporting the approach’s robustness and practical feasibility.
Adaptive Fusion#
Adaptive fusion, in the context of a federated learning system, is a crucial mechanism for effectively combining data from multiple heterogeneous sources. It addresses the challenge of integrating information from clients with varying data distributions and model architectures, a common issue in federated learning. A successful adaptive fusion method must be flexible enough to handle the non-IID nature of client data, avoiding bias and ensuring fair aggregation. This typically involves techniques that adjust the fusion process based on the characteristics of each client’s data or model. One approach might involve personalized weighting schemes, where each client’s contribution is weighted differently based on factors like data quality, model accuracy, or data distribution similarity. The ideal adaptive fusion strategy would minimize information loss and maintain model accuracy while also ensuring the privacy of individual client data remains protected. This requires a careful balance between personalization (to account for client heterogeneity) and generalization (to maintain a robust global model). Ultimately, the effectiveness of an adaptive fusion strategy is determined by its ability to leverage the strengths of diverse client data while mitigating weaknesses, leading to an improved global model with enhanced performance and robustness.
Convergence Rate#
The convergence rate analysis is crucial for evaluating the efficiency and effectiveness of an iterative algorithm. A fast convergence rate indicates that the algorithm approaches the optimal solution quickly, reducing computational costs and time. In this context, a convergence rate of O(1/T) for a non-convex function is noteworthy. This implies that the error decreases proportionally to the inverse of the number of iterations (T). While O(1/T) might not be the fastest rate achievable in all scenarios, it demonstrates a reasonable level of efficiency, especially considering the complexity of the non-convex optimization problem addressed. The theoretical analysis provides a valuable guarantee, ensuring that the algorithm will eventually converge to a solution, even though it might not reach the exact optimum. However, the practicality of the theoretical analysis depends heavily on the validity of the assumptions made during the derivation of the convergence rate. It’s also important to consider the actual observed convergence behavior in experiments, and how the empirical results corroborate with theoretical predictions. Only a comprehensive analysis, combining theoretical and empirical findings, can provide a complete understanding of the algorithm’s performance.
Future of FedMRL#
The future of FedMRL hinges on addressing its current limitations and exploring new avenues for improvement. Reducing computational costs is crucial, potentially through more efficient model architectures or optimized training strategies. Improving scalability to accommodate more clients and diverse data distributions is also vital. Enhanced privacy mechanisms are needed to further protect sensitive client data beyond current techniques. Research into adaptive parameter fusion could lead to improved knowledge transfer between heterogeneous models, resulting in better overall performance. Finally, exploration into novel applications of FedMRL to diverse domains like healthcare and IoT could unlock its full potential. Addressing these areas will transform FedMRL from a promising technique into a robust and widely applicable solution for federated learning.
More visual insights#
More on figures

🔼 This figure illustrates the workflow of the Federated Model Heterogeneous Matryoshka Representation Learning (FedMRL) approach. It shows how a global homogeneous small model interacts with heterogeneous local models at each client. The process involves adaptive representation fusion, where generalized and personalized representations are combined and projected into a fused representation. This fused representation then undergoes multi-granular representation learning, generating Matryoshka representations processed by both the global and local model headers. The final outputs and losses are used to update all model parameters, promoting effective knowledge interaction and personalized model training.
read the caption
Figure 2: The workflow of FedMRL.
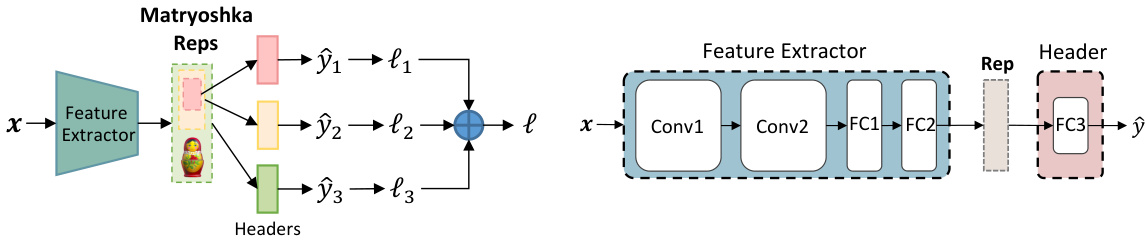
🔼 This figure presents the results of the FedMRL algorithm compared to the FedProto algorithm. The left six plots show the average test accuracy versus the number of communication rounds for different datasets and settings (CIFAR-10 and CIFAR-100 with varying numbers of clients). The right two plots show the difference in test accuracy between FedMRL and FedProto for each individual client in the N=100, C=10% settings. These results highlight FedMRL’s superior performance and consistent faster convergence speed compared to FedProto.
read the caption
Figure 3: Left six: average test accuracy vs. communication rounds. Right two: individual clients' test accuracy (%) differences (FedMRL - FedProto).
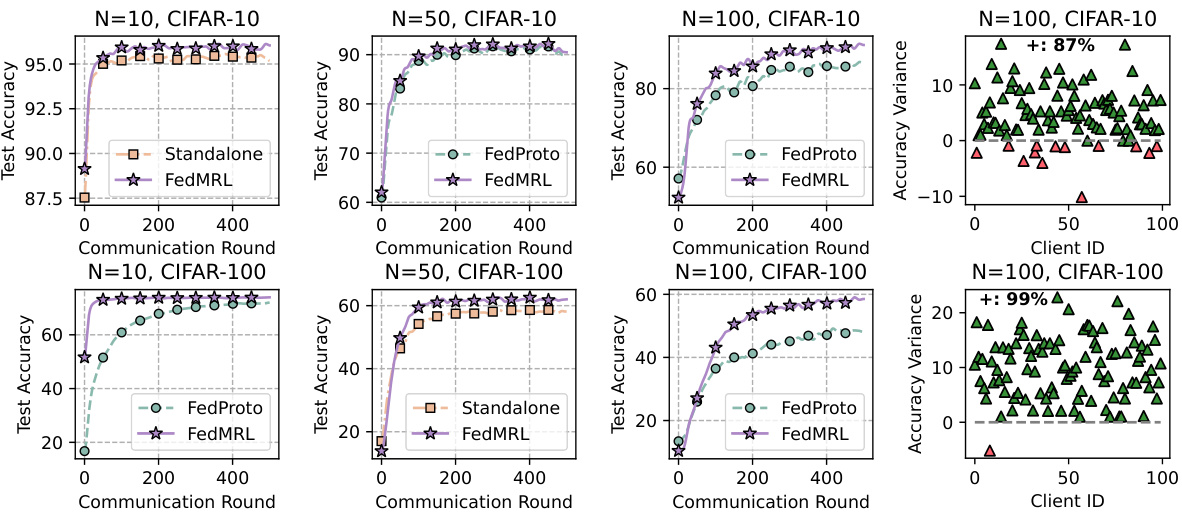
🔼 This figure compares FedProto and FedMRL in terms of communication rounds, number of communicated parameters, and computation FLOPs needed to achieve 90% and 50% average test accuracy on CIFAR-10 and CIFAR-100 datasets. It demonstrates the efficiency of FedMRL in terms of communication and computation costs compared to FedProto, highlighting its advantage in faster convergence and lower resource consumption.
read the caption
Figure 4: Communication rounds, number of communicated parameters, and computation FLOPS required to reach 90% and 50% average test accuracy targets on CIFAR-10 and CIFAR-100.

🔼 This figure displays the robustness of FedMRL and FedProto to different levels of Non-IID data. The left two subfigures show the results for varying numbers of classes assigned to each client (class-based non-IIDness), while the right two subfigures show the results for varying Dirichlet parameters (Dirichlet-based non-IIDness). FedMRL consistently outperforms FedProto across different Non-IID settings, demonstrating its robustness.
read the caption
Figure 5: Robustness to non-IIDness (Class & Dirichlet).
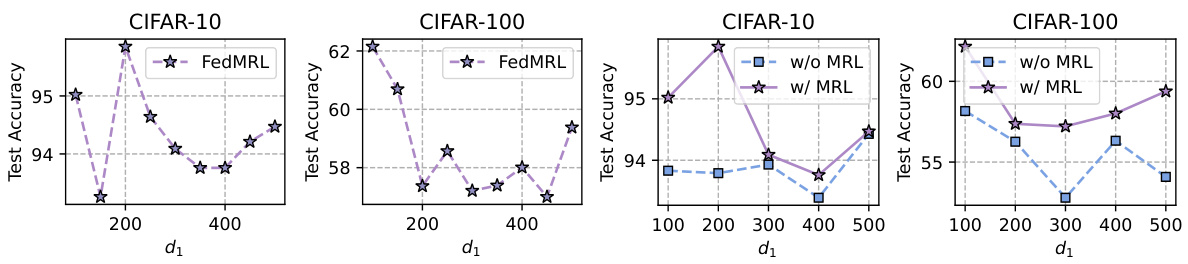
🔼 This figure presents the results of sensitivity analysis and ablation study on the hyperparameter d1 (representation dimension of the homogeneous small model). The left two subfigures show the impact of d1 on the average test accuracy for CIFAR-10 and CIFAR-100 datasets. It indicates that smaller d1 values generally lead to higher accuracy. The right two subfigures compare the performance of FedMRL with and without the Matryoshka Representation Learning (MRL) module. FedMRL with MRL consistently outperforms FedMRL without MRL, demonstrating the benefit of incorporating MRL. The accuracy gap between the two decreases as d1 increases, suggesting that the benefits of MRL reduce when the global and local headers learn increasingly similar information.
read the caption
Figure 6: Left two: sensitivity analysis results. Right two: ablation study results.
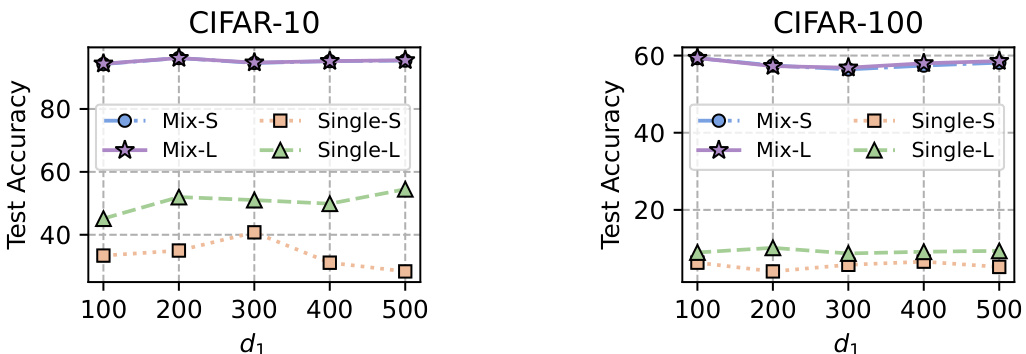
🔼 This figure compares the performance of four different inference models on CIFAR-10 and CIFAR-100 datasets. The models tested are: mix-small (combining the homogeneous small model, client’s heterogeneous model feature extractor, and representation projector), mix-large (combining the homogeneous small model feature extractor, client’s heterogeneous model, and representation projector), single-small (only using the homogeneous small model), and single-large (only using the client’s heterogeneous model). The x-axis represents the representation dimension (d1) of the homogeneous small model, while the y-axis shows the test accuracy. The results indicate that mix-small and mix-large models generally achieve similar and higher accuracy compared to using only the homogeneous small model or the client’s heterogeneous model alone.
read the caption
Figure 7: Accuracy of four optional inference models: mix-small (the whole model without the local header), mix-large (the whole model without the global header), single-small (the homogeneous small model), single-large (the client heterogeneous model).
More on tables
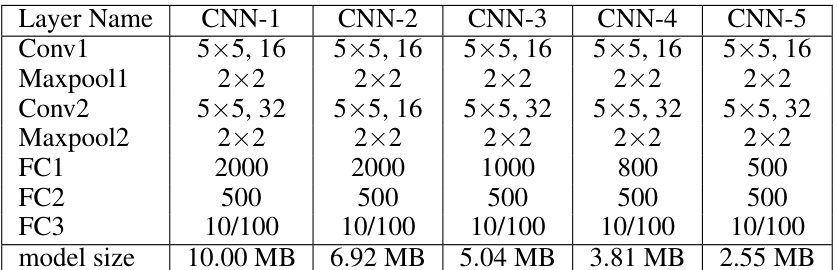
🔼 This table presents the architecture details for five different heterogeneous Convolutional Neural Networks (CNNs) used in the experiments. Each row represents a layer type (Convolutional layer, Maxpooling layer, or Fully Connected layer), and each column represents a specific CNN model (CNN-1 through CNN-5). The specifications provided include kernel size (for convolutional layers), pooling size (for max-pooling layers), number of neurons (for fully connected layers), and the total model size in MB. The model sizes decrease from CNN-1 to CNN-5, indicating a reduction in model complexity.
read the caption
Table 2: Structures of 5 heterogeneous CNN models.
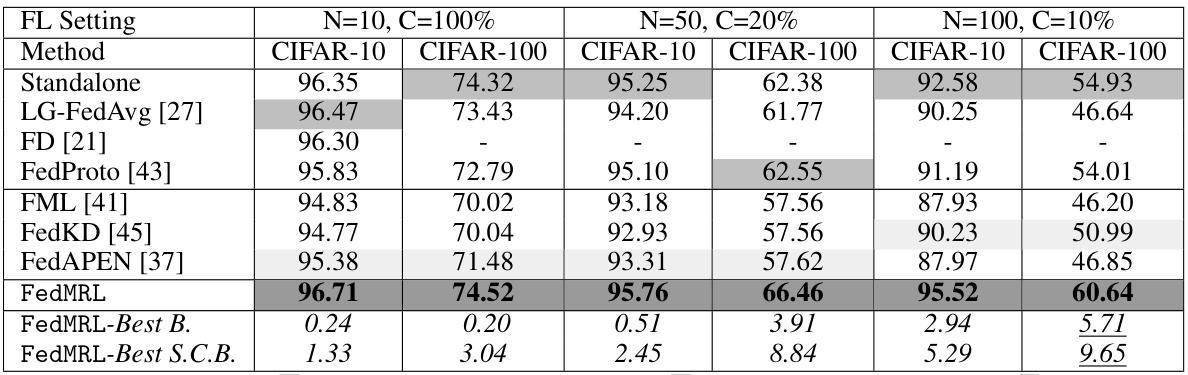
🔼 This table presents the average test accuracy achieved by FedMRL and seven other state-of-the-art MHeteroFL methods on CIFAR-10 and CIFAR-100 datasets under three different settings of the number of clients and client participation rates. The results demonstrate the superior performance of FedMRL across various scenarios in terms of model accuracy, communication costs, and computation overhead.
read the caption
Table 1: Average test accuracy (%) in model-heterogeneous FL.
Full paper#