TL;DR#
Traditional federated learning (FL) requires multiple communication rounds, leading to high costs and privacy risks. One-shot FL aims to solve this by completing training in a single round but often suffers from poor performance due to information loss and data heterogeneity. Data heterogeneity occurs when data distributions vary significantly across different clients, leading to inconsistent model predictions. Information loss occurs because information is lost during the transfer from local data to models and from models back to the data.
This paper introduces FedSD2C, a novel framework that addresses these issues. FedSD2C uses a distiller to directly synthesize informative distillates from local data, reducing information loss. It shares these synthetic distillates instead of local models, overcoming data heterogeneity. This two-step process, along with Fourier transform perturbation for enhanced privacy and pre-trained Autoencoders for efficient communication, results in improved accuracy and reduced costs. Experiments show FedSD2C significantly outperforms existing one-shot FL methods, especially on complex datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances one-shot federated learning, a crucial area for efficient and privacy-preserving machine learning. By addressing limitations in existing methods, particularly data heterogeneity and information loss, it opens new avenues for developing more accurate and scalable one-shot FL techniques. The proposed method achieves up to 2.6 times the performance of the best baseline and shows significant improvements on real-world datasets. This work has strong relevance for researchers working on resource-constrained environments, and the synthetic distillate communication is a novel approach with implications for other FL research.
Visual Insights#
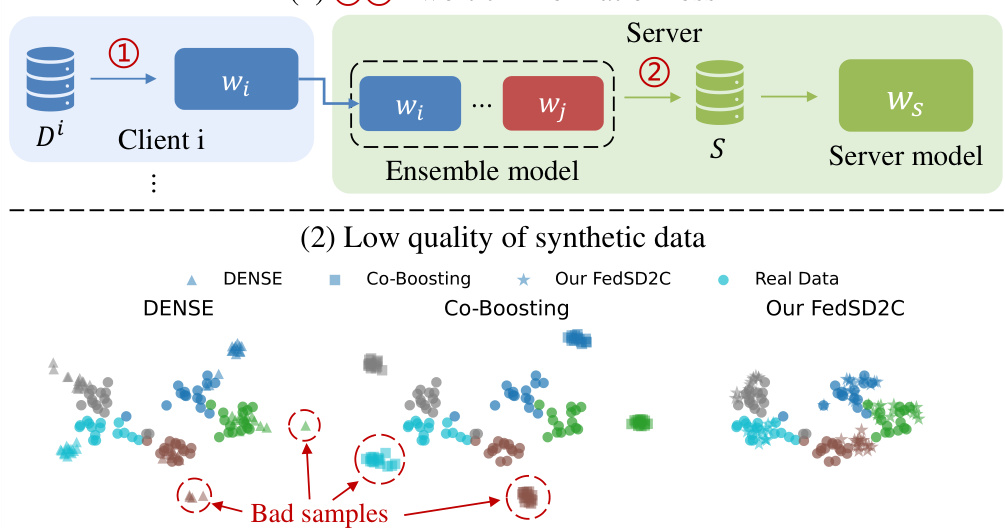
🔼 This figure illustrates two main challenges in one-shot federated learning (FL) using data-free knowledge distillation (DFKD). The top half shows a two-tier information loss: information is lost when local data is used to train a local model and again when the model’s knowledge is transferred to the server. The bottom half uses t-SNE plots to visually compare the feature distributions of synthetic data generated by three different methods (DENSE, Co-Boosting, and FedSD2C) against real data. It highlights how FedSD2C generates synthetic data that better matches the distribution of real data, unlike the other methods which produce some ‘bad samples’ deviating significantly from the real data distribution.
read the caption
Figure 1: Illustration of issues in one-shot FL based on DFKD: (1) Information loss occurs during the transfer from local data to the model and from the model back to the inversed data. (2) t-SNE plots of feature distributions of data generated by DENSE(left ▲), Co-Boosting(middle), and our FedSD2C(right). We randomly select five different classes (indicated by different colors) of real and synthetic data from Tiny-ImageNet. Bad samples are data generated by the DFKD-based method that deviates from the distribution of local real data.
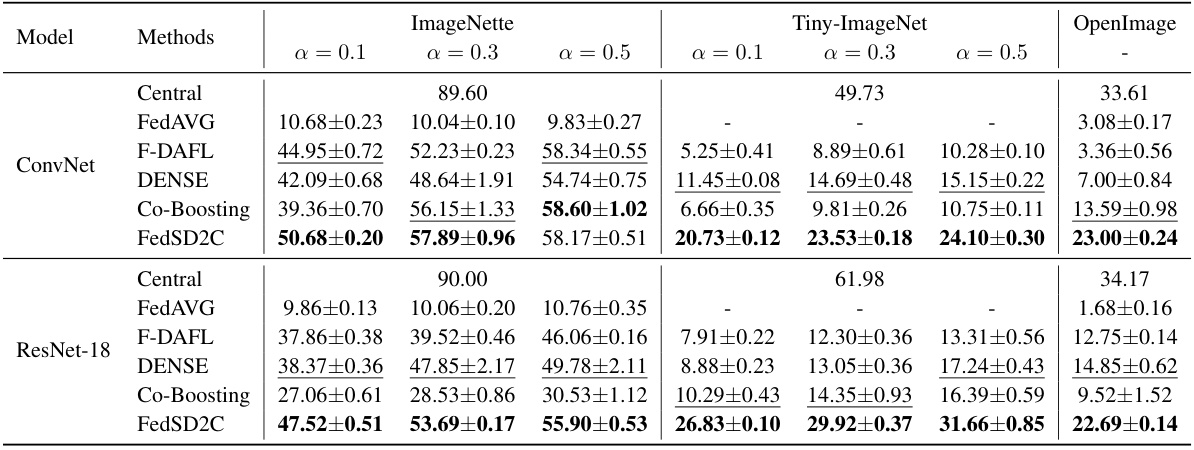
🔼 This table presents the accuracy results of several one-shot federated learning (FL) methods on three image datasets (ImageNette, Tiny-ImageNet, and OpenImage) using two different model architectures (ConvNet and ResNet-18). The level of data heterogeneity is varied (α = 0.1, 0.3, 0.5), simulating different degrees of non-IID data distribution across clients. The ‘Central’ column provides a baseline representing the performance achievable with centralized training (all data on the server). The table compares FedAVG, F-DAFL, DENSE, Co-Boosting, and the proposed FedSD2C methods.
read the caption
Table 1: Accuracy of different one-shot FL methods over three datasets with ConvNet and ResNet-18. We vary the α = {0.1, 0.3, 0.5} to simulate different levels of data heterogeneity for Tiny-ImageNet and Imagenette and use pre-defined splits for OpenImage. 'Central' means that clients send all their local data to the server for centralized training, representing the upper bound of model performance.
In-depth insights#
One-Shot FL Issues#
One-shot federated learning (FL), while attractive for its communication efficiency and privacy, suffers from significant performance limitations. Two-tier information loss is a major issue; knowledge is lost during local training (data to model) and again when transferring knowledge to the server (model to synthesized data). This is exacerbated by data heterogeneity, where inconsistent local data distributions lead to unreliable knowledge transfer from clients. Poor quality synthetic data generated by methods like knowledge distillation further compounds the problem, resulting in inaccurate server model updates. Addressing these challenges requires novel approaches that minimize information loss and handle data heterogeneity effectively to fully realize the potential of one-shot FL.
FedSD2C Framework#
The FedSD2C framework is a novel one-shot federated learning approach designed to overcome limitations of existing methods. It directly addresses the problem of two-tier information loss inherent in data-free knowledge distillation (DFKD) techniques by introducing a distiller to synthesize informative distillates directly from local data. This bypasses the inefficient two-step process (data-to-model and model-to-data) that leads to significant information loss. Further, FedSD2C tackles data heterogeneity by transmitting the synthesized distillates, rather than inconsistent local models, to the server, enhancing robustness. The framework also incorporates privacy-enhancing techniques using Fourier transform perturbation and a pre-trained autoencoder to minimize information leakage while reducing communication costs. This makes FedSD2C a particularly efficient and secure method for one-shot FL, especially suitable for high-resolution datasets and resource-constrained environments.
Synthetic Distillates#
The concept of “Synthetic Distillates” in the context of federated learning represents a novel approach to knowledge transfer. Instead of directly sharing potentially sensitive local model parameters or raw data, the approach distills the essence of local data into compact, synthetic representations called distillates. This process is designed to preserve crucial information while safeguarding privacy and reducing communication overhead. The creation of these distillates involves a two-step process: first, selecting a core subset of informative data points, and second, synthesizing these points into efficient representations using a pre-trained autoencoder. This strategy of creating synthetic distillates minimizes information loss and addresses data heterogeneity issues. By sending only these synthetic distillates to the central server, the risk of privacy violation is significantly reduced while still allowing for efficient global model training.
Privacy & Efficiency#
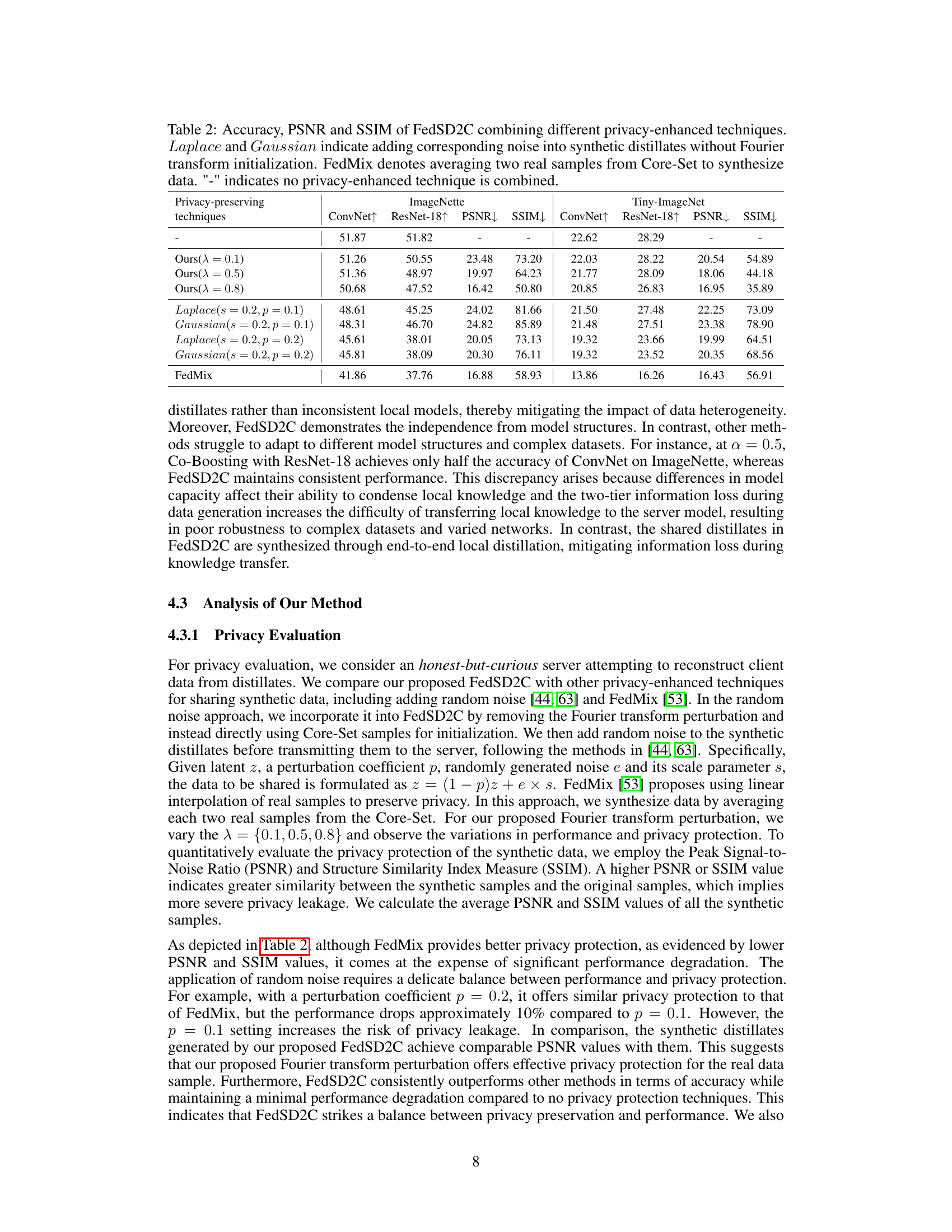
Balancing privacy and efficiency is crucial in federated learning (FL), especially in one-shot scenarios. The paper focuses on minimizing information loss during knowledge transfer, which directly improves efficiency. Reducing the data transmitted to a synthetic distillate instead of raw local model data is a significant efficiency gain. Further efficiency improvements are achieved by using a Core-Set selection to reduce data volume, but also introducing the Fourier transform perturbation technique, this minimizes information sent while preserving semantic content. The use of a pre-trained Autoencoder further aids efficiency by compressing data in the latent space, reducing communication overhead. Privacy is enhanced through various methods. The Fourier transform technique, focusing on preserving only high-level semantic information while reducing visual detail, limits sensitive data exposure. The Core-Set and distillate creation also reduce the volume of sensitive data exposed, improving privacy. Employing a pre-trained Autoencoder on the server-side further safeguards privacy by minimizing the reconstructability of original data from distillates. Though the methods present considerable privacy gains, the authors acknowledge that a fully adversarial attacker might still have some success. The Core-Set method, while protective, has limitations and could pose membership inference risks, which are partially mitigated by the perturbative method. Overall, the paper demonstrates a thoughtful trade-off between privacy and efficiency, using several innovative strategies to protect sensitive data while optimizing communication efficiency
Future Work#
Future research could explore several promising avenues. Improving the efficiency and scalability of the Core-Set selection method is crucial, perhaps through the development of more sophisticated algorithms or the incorporation of efficient data structures. Another direction is to investigate alternative methods for distillate synthesis, potentially leveraging advanced generative models or exploring different data augmentation techniques to create more robust distillates. Enhanced privacy techniques are also worth considering, especially for high-dimensional data where the risk of leakage is higher. Extending FedSD2C to handle more complex FL settings with greater data heterogeneity and more varied model architectures would greatly enhance its applicability. Finally, a thorough empirical comparison with other state-of-the-art one-shot FL methods on a broader range of datasets would be beneficial to solidify its place within the broader field.
More visual insights#
More on figures
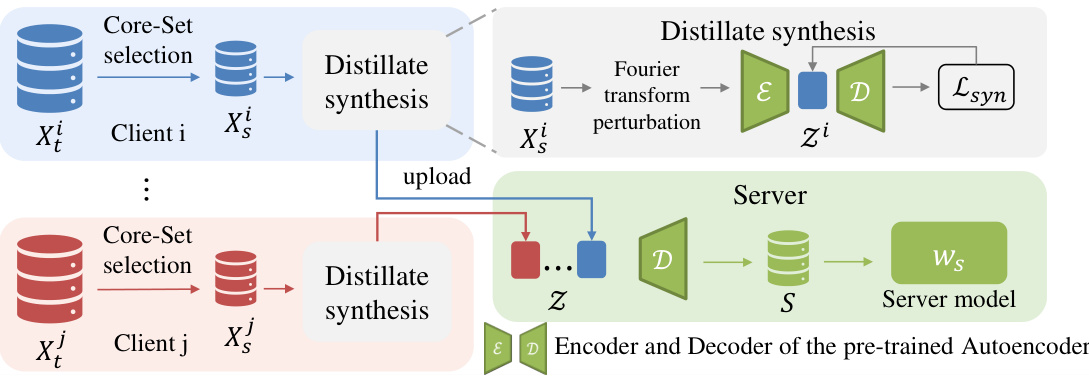
🔼 The framework illustrates the proposed FedSD2C’s process. Each client independently selects a core-set from its local data. This core-set undergoes distillate synthesis, involving Fourier transform perturbation to enhance privacy and a pre-trained autoencoder to generate compact, informative distillates that minimize information loss. These distillates are then uploaded to the server, which uses the pre-trained autoencoder’s decoder to reconstruct the information and train the global server model. The figure clearly shows the two-stage distillation process and the role of the pre-trained autoencoder as a distiller in improving efficiency and privacy.
read the caption
Figure 2: Framework of proposed FedSD2C.
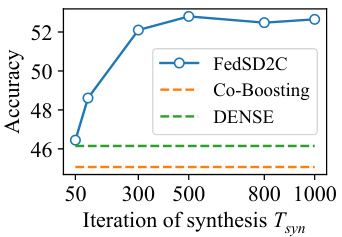
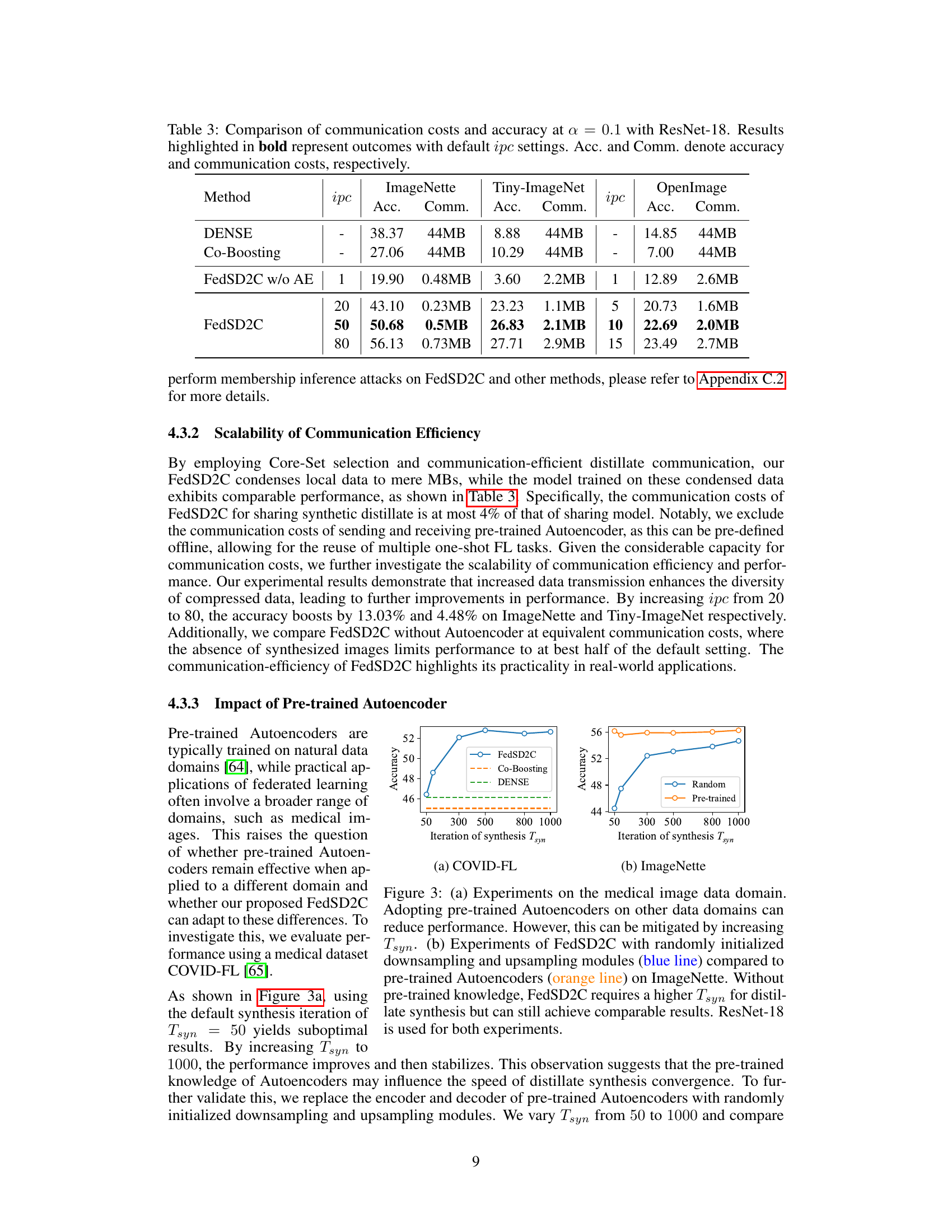
🔼 This figure shows the results of experiments conducted on a medical image dataset (COVID-FL) and ImageNette to evaluate the impact of pre-trained autoencoders on the performance of FedSD2C. Figure 3a demonstrates that using pre-trained autoencoders on a different data domain (medical images) initially reduces performance but this can be improved by increasing the number of synthesis iterations (Tsyn). Figure 3b compares the performance of FedSD2C using pre-trained autoencoders versus randomly initialized downsampling/upsampling modules on ImageNette, illustrating that while pre-trained autoencoders accelerate convergence, FedSD2C can still achieve comparable results with randomly initialized modules by increasing Tsyn.
read the caption
Figure 3: (a) Experiments on the medical image data domain. Adopting pre-trained Autoencoders on other data domains can reduce performance. However, this can be mitigated by increasing Tsyn. (b) Experiments of FedSD2C with randomly initialized downsampling and upsampling modules (blue line) compared to pre-trained Autoencoders (orange line) on ImageNette. Without pre-trained knowledge, FedSD2C requires a higher Tsyn for distillate synthesis but can still achieve comparable results. ResNet-18 is used for both experiments.
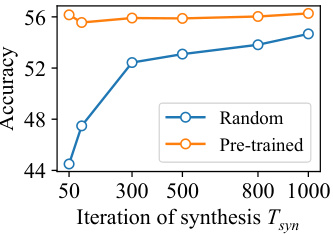
🔼 This figure shows the results of experiments conducted on a medical image dataset (COVID-FL) and ImageNette to evaluate the impact of pre-trained autoencoders on the performance of FedSD2C. The left subplot (a) demonstrates that using pre-trained autoencoders on a different data domain (medical images) initially reduces performance, but increasing the number of synthesis iterations (Tsyn) mitigates this. The right subplot (b) compares the performance of FedSD2C with pre-trained autoencoders versus using randomly initialized modules, revealing that while pre-trained autoencoders lead to faster convergence, FedSD2C can still achieve comparable results with randomly initialized modules given sufficient iterations.
read the caption
Figure 3: (a) Experiments on the medical image data domain. Adopting pre-trained Autoencoders on other data domains can reduce performance. However, this can be mitigated by increasing Tsyn. (b) Experiments of FedSD2C with randomly initialized downsampling and upsampling modules (blue line) compared to pre-trained Autoencoders (orange line) on ImageNette. Without pre-trained knowledge, FedSD2C requires a higher Tsyn for distillate synthesis but can still achieve comparable results. ResNet-18 is used for both experiments.

🔼 This figure illustrates two key challenges in one-shot federated learning (FL) using data-free knowledge distillation (DFKD). The first part shows a two-tier information loss: data to model, then model to synthetic data. The second part uses t-SNE plots to visualize the difference in feature distributions between synthetic data generated by three different methods (DENSE, Co-Boosting, and the proposed FedSD2C) and real data from Tiny-ImageNet. It highlights how FedSD2C better generates synthetic data that closely matches the real data distribution, addressing the issue of low-quality synthetic data common in DFKD.
read the caption
Figure 1: Illustration of issues in one-shot FL based on DFKD: (1) Information loss occurs during the transfer from local data to the model and from the model back to the inversed data. (2) t-SNE plots of feature distributions of data generated by DENSE(left ▲), Co-Boosting(middle), and our FedSD2C(right). We randomly select five different classes (indicated by different colors) of real and synthetic data from Tiny-ImageNet. Bad samples are data generated by the DFKD-based method that deviates from the distribution of local real data.
More on tables

🔼 This table presents a comparison of the performance (accuracy, PSNR, SSIM) of the FedSD2C model when different privacy-enhancing techniques are used. It shows how the model’s accuracy, peak signal-to-noise ratio (PSNR), and structural similarity index measure (SSIM) are affected by adding noise (Laplace and Gaussian) to the synthetic distillates, and by averaging real samples from the Core-Set (FedMix). The baseline is FedSD2C without any additional privacy-enhancing techniques.
read the caption
Table 2: Accuracy, PSNR and SSIM of FedSD2C combining different privacy-enhanced techniques. Laplace and Gaussian indicate adding corresponding noise into synthetic distillates without Fourier transform initialization. FedMix denotes averaging two real samples from Core-Set to synthesize data. '-' indicates no privacy-enhanced technique is combined.
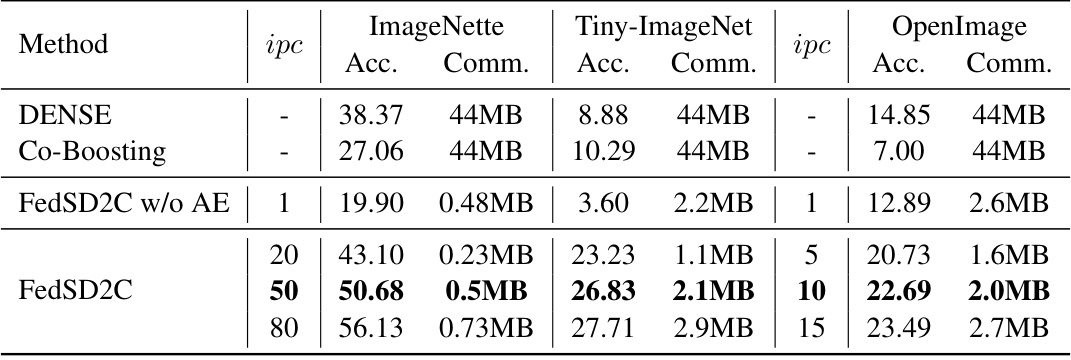
🔼 This table presents the accuracy results of several one-shot federated learning methods on three image datasets (ImageNette, Tiny-ImageNet, and OpenImage) using two different model architectures (ConvNet and ResNet-18). The accuracy is shown for different levels of data heterogeneity (α = 0.1, 0.3, 0.5). A ‘Central’ training result is included as an upper performance bound, representing the ideal scenario where all client data is available to the server. The table allows for a comparison of the performance of different one-shot methods under varying conditions.
read the caption
Table 1: Accuracy of different one-shot FL methods over three datasets with ConvNet and ResNet-18. We vary the α = {0.1, 0.3, 0.5} to simulate different levels of data heterogeneity for Tiny-ImageNet and Imagenette and use pre-defined splits for OpenImage. 'Central' means that clients send all their local data to the server for centralized training, representing the upper bound of model performance.
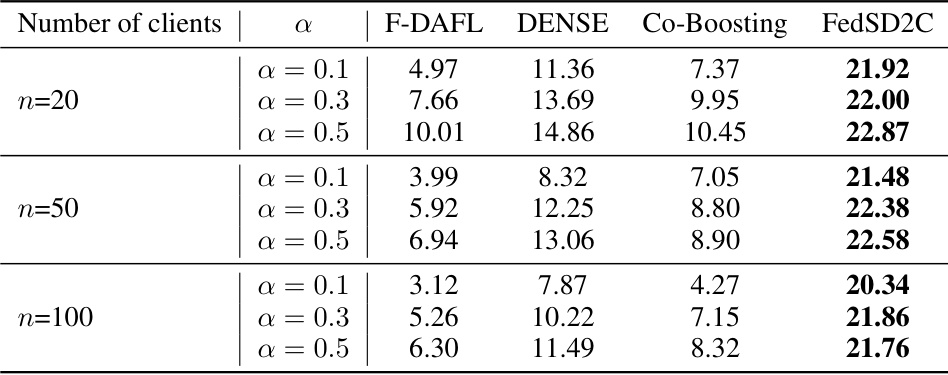
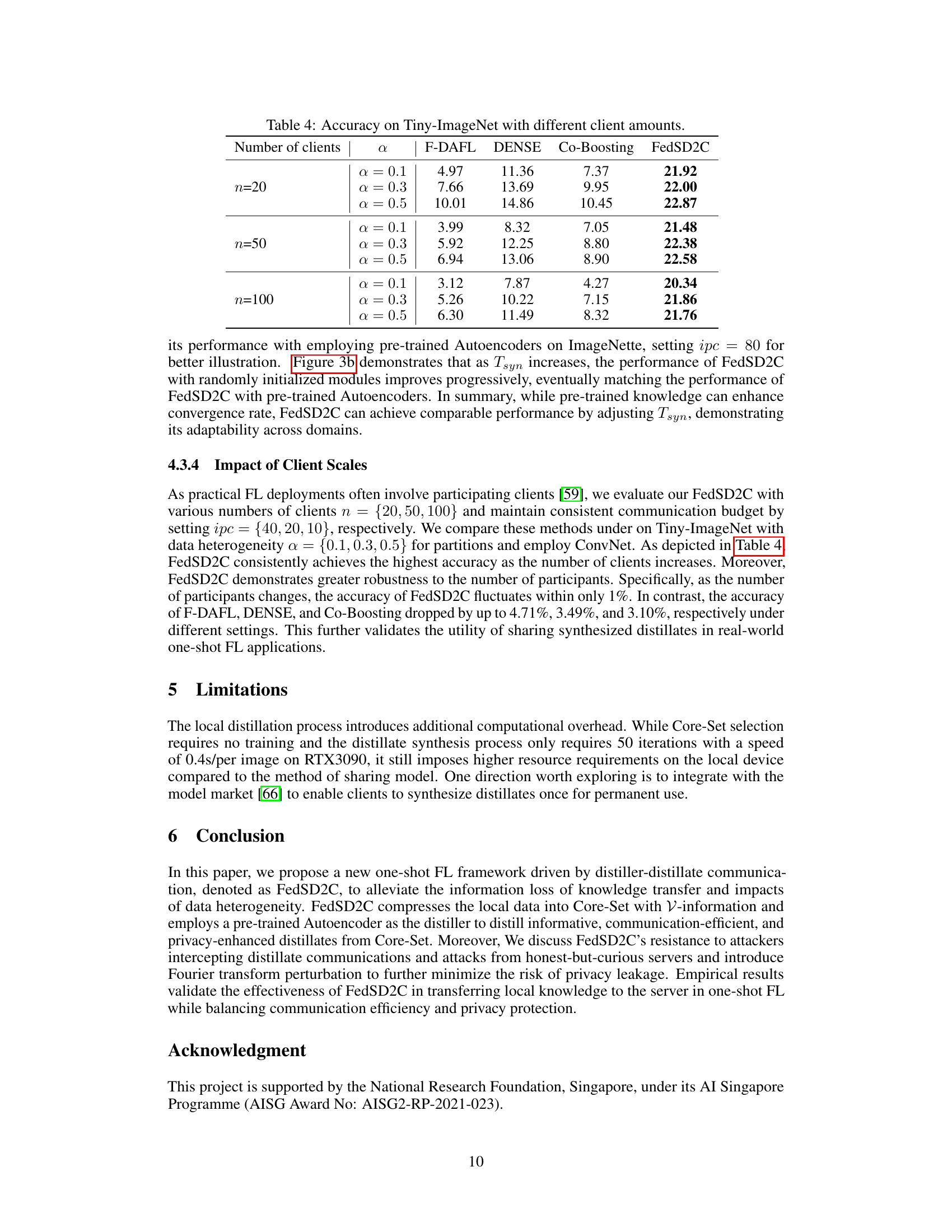
🔼 This table shows the accuracy achieved by four different one-shot federated learning methods (F-DAFL, DENSE, Co-Boosting, and FedSD2C) on the Tiny-ImageNet dataset. The results are broken down by the number of clients (20, 50, and 100) and the level of data heterogeneity (α = 0.1, 0.3, 0.5). Higher accuracy values indicate better performance of the model.
read the caption
Table 4: Accuracy on Tiny-ImageNet with different client amounts.

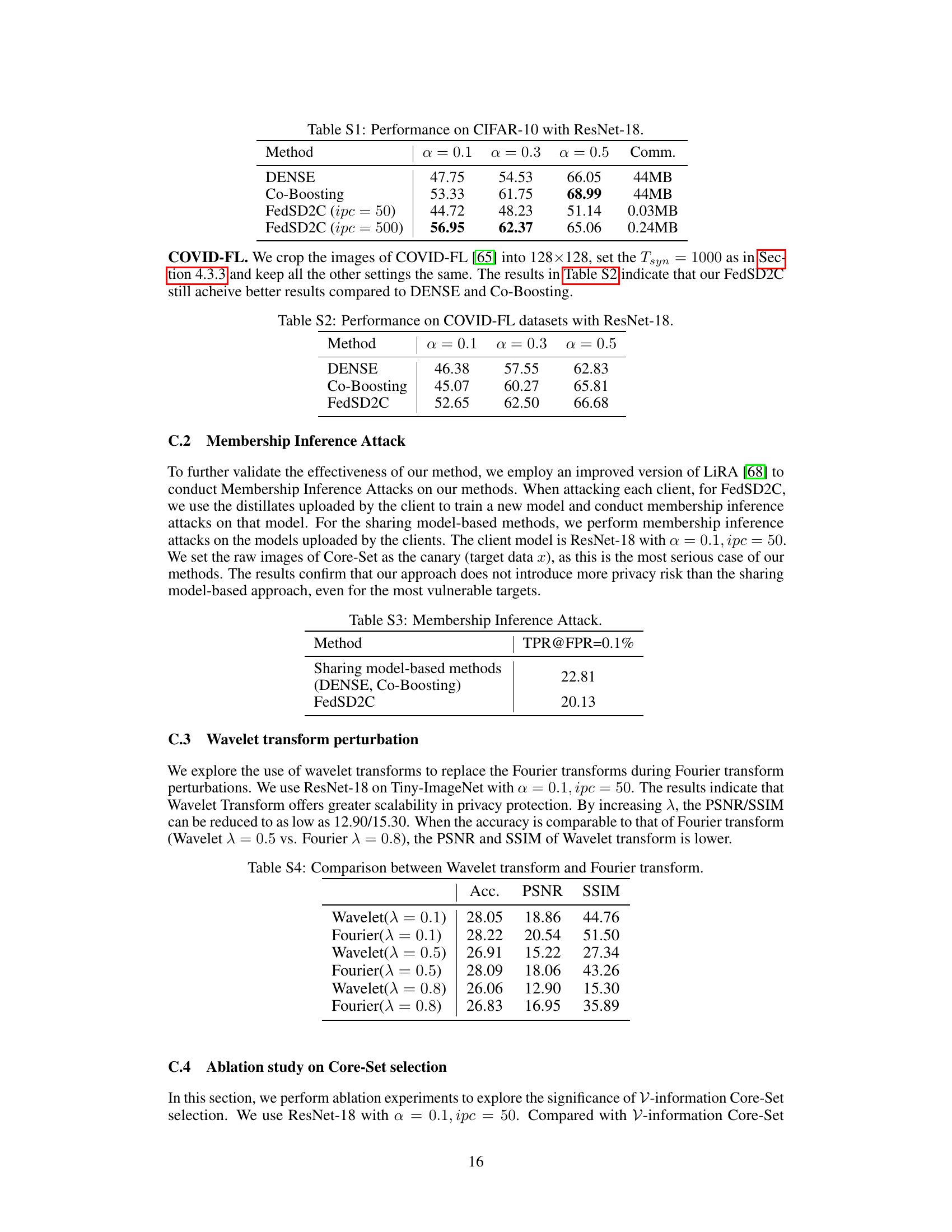
🔼 This table presents the performance comparison of different one-shot federated learning methods (DENSE, Co-Boosting, and FedSD2C) on the CIFAR-10 dataset using ResNet-18 as the model architecture. The results are categorized by different levels of data heterogeneity (α = 0.1, 0.3, 0.5) and include the communication cost (Comm.) for each method. The table shows that FedSD2C with a larger number of images per class (ipc = 500) achieves better performance compared to other methods, especially with lower heterogeneity levels.
read the caption
Table S1: Performance on CIFAR-10 with ResNet-18.

🔼 This table presents the accuracy results of DENSE, Co-Boosting, and FedSD2C on the COVID-FL dataset using ResNet-18 as the model architecture. The results are broken down by different levels of data heterogeneity (α = 0.1, α = 0.3, α = 0.5). This allows for a comparison of the methods’ performance under varying levels of data non-IIDness.
read the caption
Table S2: Performance on COVID-FL datasets with ResNet-18.

🔼 This table compares the performance (accuracy, PSNR, SSIM) of FedSD2C using various privacy-preserving techniques. It shows that incorporating Fourier transform perturbation strikes a balance between privacy and performance, outperforming methods that add noise or average real samples.
read the caption
Table 2: Accuracy, PSNR and SSIM of FedSD2C combining different privacy-enhanced techniques. Laplace and Gaussian indicate adding corresponding noise into synthetic distillates without Fourier transform initialization. FedMix denotes averaging two real samples from Core-Set to synthesize data. '-' indicates no privacy-enhanced technique is combined.
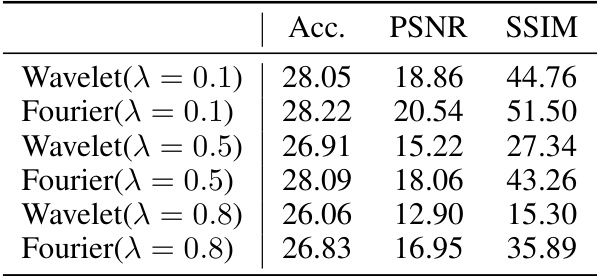
🔼 This table compares the performance (accuracy, PSNR, and SSIM) of FedSD2C using different privacy-preserving techniques. It shows that while methods like FedMix offer stronger privacy (lower PSNR and SSIM), they come at a cost of reduced accuracy. The Fourier Transform perturbation method used in FedSD2C shows a good balance between privacy and performance.
read the caption
Table 2: Accuracy, PSNR and SSIM of FedSD2C combining different privacy-enhanced techniques. Laplace and Gaussian indicate adding corresponding noise into synthetic distillates without Fourier transform initialization. FedMix denotes averaging two real samples from Core-Set to synthesize data. '-' indicates no privacy-enhanced technique is combined.
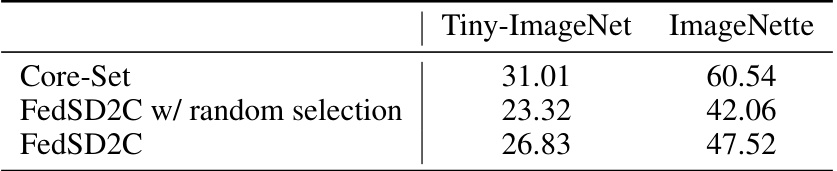
🔼 This table compares the performance of three different Core-Set selection methods: directly uploading the Core-Set, using random selection, and using the proposed V-information based selection method within the FedSD2C framework. It highlights the impact of the proposed method on accuracy and the trade-off between accuracy and privacy/communication efficiency.
read the caption
Table 5: Performance of different selection strategy. Core-Set denotes that clients directly upload their local Core-Set, which leads to privacy issue. FedSD2C w/ random selection denotes replacing V-information-based Core-Set selection with random selection.
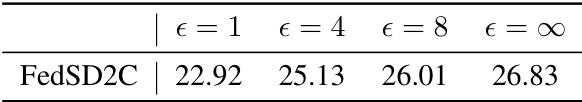
🔼 This table presents the results of experiments evaluating the performance of FedSD2C when integrated with Differential Privacy using DP-SGD, demonstrating the trade-off between privacy and accuracy at different privacy levels. The performance (accuracy) of the model is shown for various values of epsilon (ε), representing the privacy budget. A higher epsilon value indicates less privacy protection and potentially higher accuracy. The table showcases how increasing the epsilon value corresponds to a higher accuracy, indicating the tradeoff inherent in balancing privacy with performance.
read the caption
Table S6: Performance of integrating DP-SGD
Full paper#