TL;DR#
Existing contrastive image-to-LiDAR methods suffer from a ‘self-conflict’ issue where semantically similar features are treated as negative samples, hindering effective knowledge transfer. Also, imbalances in point cloud density and category frequency lead to skewed representation learning.
This paper introduces OLIVINE, which leverages visual foundation models to generate weak semantic labels, promoting more accurate positive sample selection and alleviating the self-conflict issue. Furthermore, OLIVINE incorporates a density and category-aware sampling strategy to balance learning across all classes. Extensive experiments show that OLIVINE outperforms existing methods, offering superior downstream performance in semantic segmentation and 3D object detection.
Key Takeaways#
Why does it matter?#
This paper is important because it presents OLIVINE, a novel approach that significantly improves the performance of image-to-LiDAR contrastive distillation. This method is relevant to current trends in self-supervised and weakly supervised learning for 3D data, and it could open up new avenues for research in 3D scene understanding, autonomous driving, and other applications that rely on LiDAR data. The technique’s effectiveness is demonstrated through extensive experiments and its impact is high due to its potential to reduce the cost and time required for annotating large 3D datasets.
Visual Insights#

🔼 This figure illustrates the ‘self-conflict’ problem in traditional contrastive image-to-LiDAR methods (a) where pixels of the same semantic class but not directly corresponding to an anchor point are treated as negative samples. This neglects the semantic relationships, hindering effective learning. In contrast, the proposed method (b) leverages Visual Foundation Models (VFMs) to generate weak semantic labels. These labels guide the contrastive learning process, ensuring that pixels sharing the same semantic class with the anchor point are treated as positive samples, overcoming the self-conflict issue. This leads to improved 3D representation learning by preserving semantic integrity.
read the caption
Figure 1: Illustration of (a) self-conflict that exists in conventional pixel-to-point contrastive distillation and (b) our weakly supervised contrastive distillation.

🔼 This table compares the performance of several self-supervised and contrastive learning methods for semantic segmentation on the nuScenes and SemanticKITTI datasets. It shows the mean Intersection over Union (mIoU) achieved by each method using different percentages (1%, 5%, 10%, 25%, 100%) of the annotated data for fine-tuning and linear probing. The results demonstrate the effectiveness of various pre-training approaches on different amounts of labeled data for improving the performance of semantic segmentation models.
read the caption
Table 1: Comparison of various pre-training techniques for semantic segmentation tasks using either finetuning or linear probing (LP). This evaluation uses different proportions of accessible annotations from the nuScenes or SemanticKITTI datasets and presents the mean Intersection over Union (mIoU) scores on the validation set.
In-depth insights#
Self-Conflict Issue#
The paper highlights a “self-conflict” problem in contrastive image-to-LiDAR distillation. Traditional methods treat (super)pixels of the same semantic class as negative samples if they don’t directly correspond to anchor points. This is counterintuitive as semantically similar features should be encouraged, not penalized. This self-conflict arises from the hardness-aware nature of contrastive losses, which heavily weigh negative samples that are actually semantically similar. The paper proposes using Visual Foundation Models (VFMs) to generate weak semantic labels, guiding the contrastive learning process and mitigating the self-conflict by pulling together semantically similar pixels and points, while pushing away dissimilar ones. This supervised approach tackles the inherent limitations of self-supervised methods by explicitly incorporating semantic information, allowing the model to better understand and leverage the relationships between different modalities. The problem is further exacerbated by imbalances in point density and class frequency in typical LiDAR datasets; this introduces further bias into the learning process, which is also tackled in the paper. Therefore, addressing the self-conflict through semantic guidance is crucial for improving the accuracy and robustness of image-to-LiDAR knowledge transfer.
VFM Integration#
The integration of Visual Foundation Models (VFMs) represents a significant advancement in the paper’s approach to contrastive image-to-LiDAR distillation. VFMs, pre-trained on massive datasets, offer the capability to generate high-quality semantic labels with minimal effort, a crucial step in addressing the “self-conflict” problem inherent in traditional contrastive methods. By leveraging these readily available semantic labels, the approach shifts from a purely self-supervised contrastive learning strategy towards a weakly supervised approach. This allows the model to better understand the relationships between image pixels and LiDAR points, particularly for those sharing the same semantic labels. The resulting improvement in feature space structuring leads to a more balanced and comprehensive learned representation. This is further enhanced by the incorporation of von Mises-Fisher distributions and a density-aware sampling strategy, ultimately leading to superior performance on downstream semantic segmentation and 3D object detection tasks.
Sampling Strategy#
The effectiveness of contrastive learning hinges significantly on the sampling strategy employed. A naive approach, randomly selecting point-pixel pairs, often leads to imbalanced representation, particularly affecting less frequent categories. The proposed density and category-aware sampling strategy directly addresses this issue, weighting samples inversely proportional to both point density (using kernel density estimation) and category frequency. This ensures that underrepresented spatial regions and rare classes receive appropriate attention during training, leading to a more balanced and comprehensive 3D feature representation. The strategy is particularly valuable when dealing with datasets exhibiting inherent class imbalances and non-uniform point distributions, making it crucial for robust and generalized model training. By dynamically adjusting sampling probabilities, the method mitigates biases associated with oversampling dominant categories or densely populated areas, leading to a more equitable learning process and ultimately improving model performance on downstream tasks.
Ablation Studies#
Ablation studies systematically investigate the contribution of individual components within a complex model. In this context, they would likely involve removing or altering specific elements (e.g., the weakly-supervised contrastive distillation, semantic-guided consistency regularization, or density-aware sampling) to determine their impact on the overall performance of the LiDAR-image fusion model. Key insights would emerge from comparing the performance of the full model to models with components removed. This allows researchers to identify essential components versus those that add minimal benefit, leading to a more streamlined and efficient model architecture. The results of such studies would provide quantitative evidence (mIoU scores, accuracy, etc.) illustrating how these components contribute individually and in combination to the model’s effectiveness. A well-conducted ablation study is crucial to validate the claims made in the paper about the various components, demonstrating the model’s performance gains are directly attributable to specific design decisions and not simply due to random factors or overall model complexity.
Future Directions#
Future research directions could explore several promising avenues. Improving the robustness of the weakly supervised contrastive distillation is crucial, as the accuracy of automatically generated semantic labels directly impacts performance. Investigating alternative methods for generating semantic labels, perhaps by leveraging multi-modal information or more advanced foundation models, would be beneficial. Addressing the class imbalance problem inherent in many LiDAR datasets remains a significant challenge. Advanced sampling strategies or loss functions could mitigate the bias introduced by this imbalance. Furthermore, research could focus on extending the framework to handle dynamic scenes and various weather conditions, increasing the practical applicability of the proposed method. Finally, exploring the integration with other perception modalities, such as radar or cameras, offers exciting possibilities for enhanced 3D understanding. The potential synergy of integrating visual and other sensor data warrants further investigation.
More visual insights#
More on figures
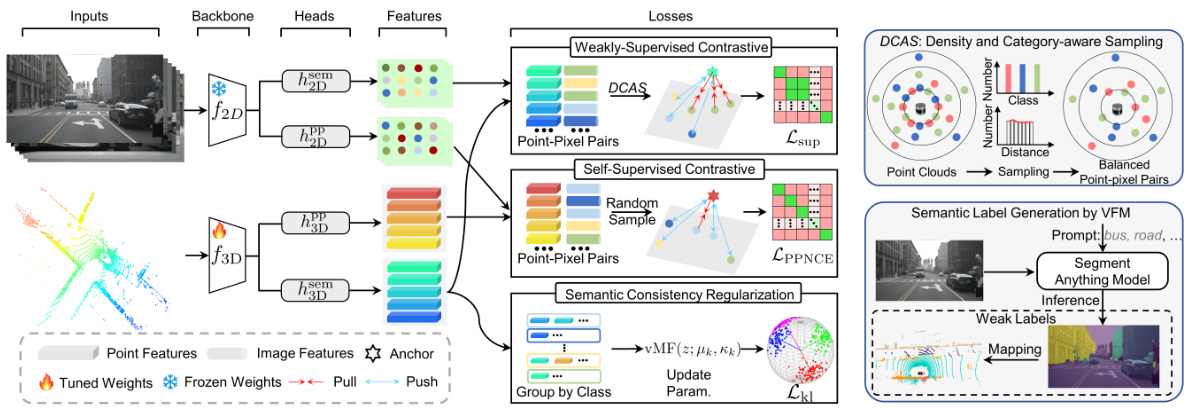
🔼 This figure presents a detailed overview of the OLIVINE pipeline, which consists of multiple stages. It begins with feature extraction from both point cloud and image inputs using separate backbones. These features are then aligned using projection heads. The learning process involves three key components: weakly supervised contrastive distillation using semantic labels from a Visual Foundation Model, self-supervised contrastive distillation with randomly sampled point-pixel pairs, and semantic consistency regularization with von Mises-Fisher distributions. A novel sampling strategy is implemented to address imbalances in spatial and category distributions.
read the caption
Figure 2: The overall pipeline of our proposed OLIVINE. The pipeline starts with feature extraction via a trainable 3D backbone and a pre-trained 2D backbone, followed by feature alignment in a common space. The learning is driven by weakly-supervised contrastive distillation with coarse semantic labels, self-supervised distillation of randomly sampled point-pixel pairs, and semantic consistency regularization through the von Mises-Fisher distribution. Besides, our approach is also characterized by the novel sampling strategy of point-pixel pairs addressing spatial and category distribution imbalances.

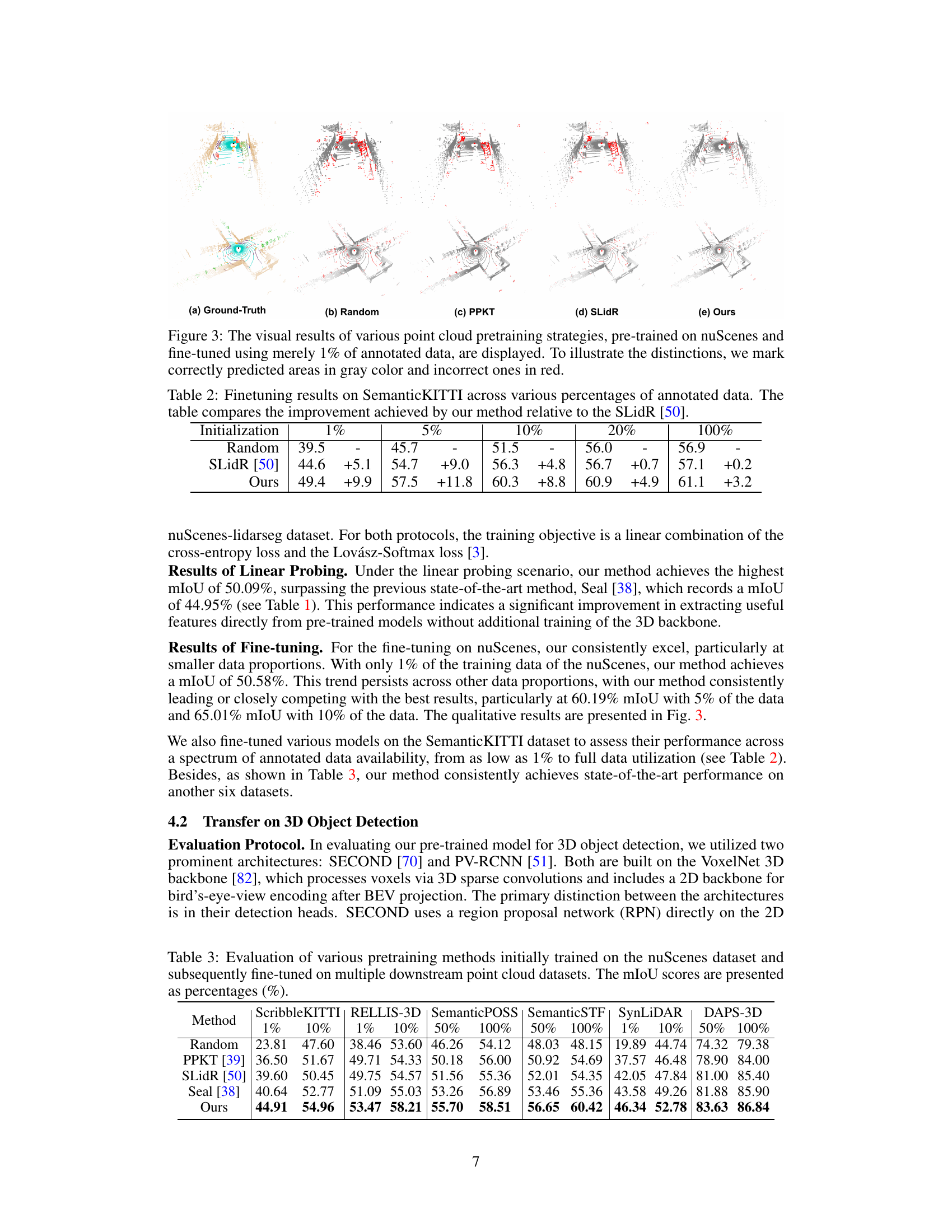
🔼 This figure displays a comparison of qualitative results from fine-tuning on 1% of the nuScenes-lidarseg dataset using different pre-training strategies (Random, PPKT, SLIDR, and the proposed OLIVINE method). The results are presented as point clouds, with color-coding indicating the predicted semantic classes. For each method, the ground truth semantic segmentation is shown alongside the predictions, and an error map highlights the differences between prediction and ground truth. The error map shows incorrect predictions in red, giving a visual representation of the accuracy of each method. The figure shows two distinct examples to better demonstrate the results in different scenes.
read the caption
Figure 8: Qualitative results of fine-tuning on 1% of the nuScenes-lidarseg dataset with different pre-training strategies. Note that the results are shown as error maps on the right, where red points indicate incorrect predictions. Best viewed in color and zoom in for more details.

🔼 This figure compares the performance of different point cloud pre-training methods on semantic segmentation using only 1% of the annotated data from the nuScenes dataset. The results are visualized using ground truth (a), random initialization (b), PPKT (c), SLidR (d) and the proposed OLIVINE method (e). Correctly predicted areas are shown in gray, while incorrectly predicted areas are in red, illustrating the differences in accuracy across different pre-training techniques.
read the caption
Figure 3: The visual results of various point cloud pretraining strategies, pre-trained on nuScenes and fine-tuned using merely 1% of annotated data, are displayed. To illustrate the distinctions, we mark correctly predicted areas in gray color and incorrect ones in red.
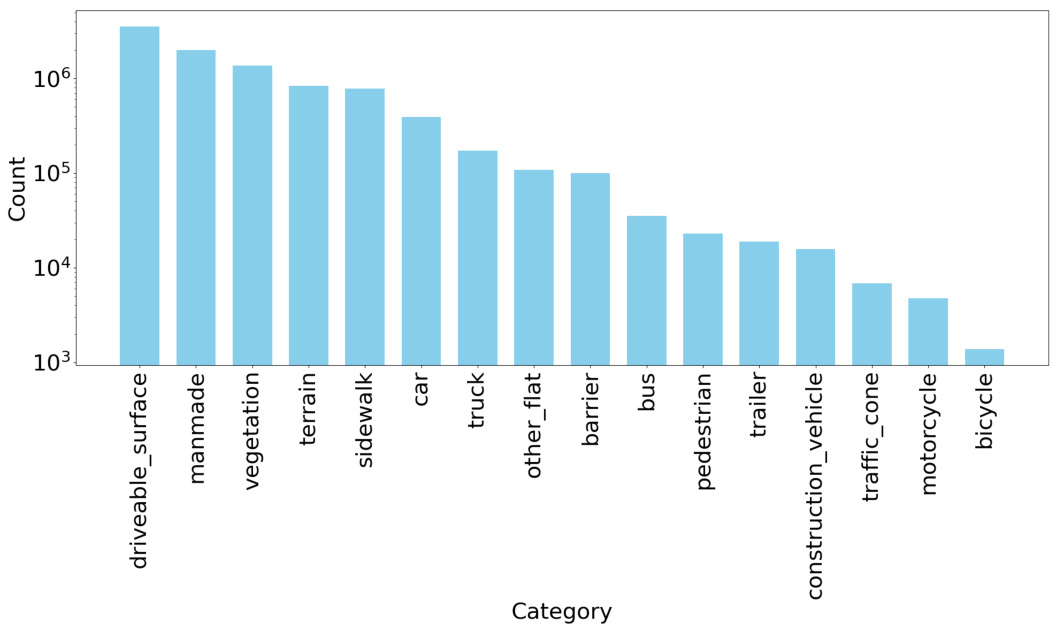
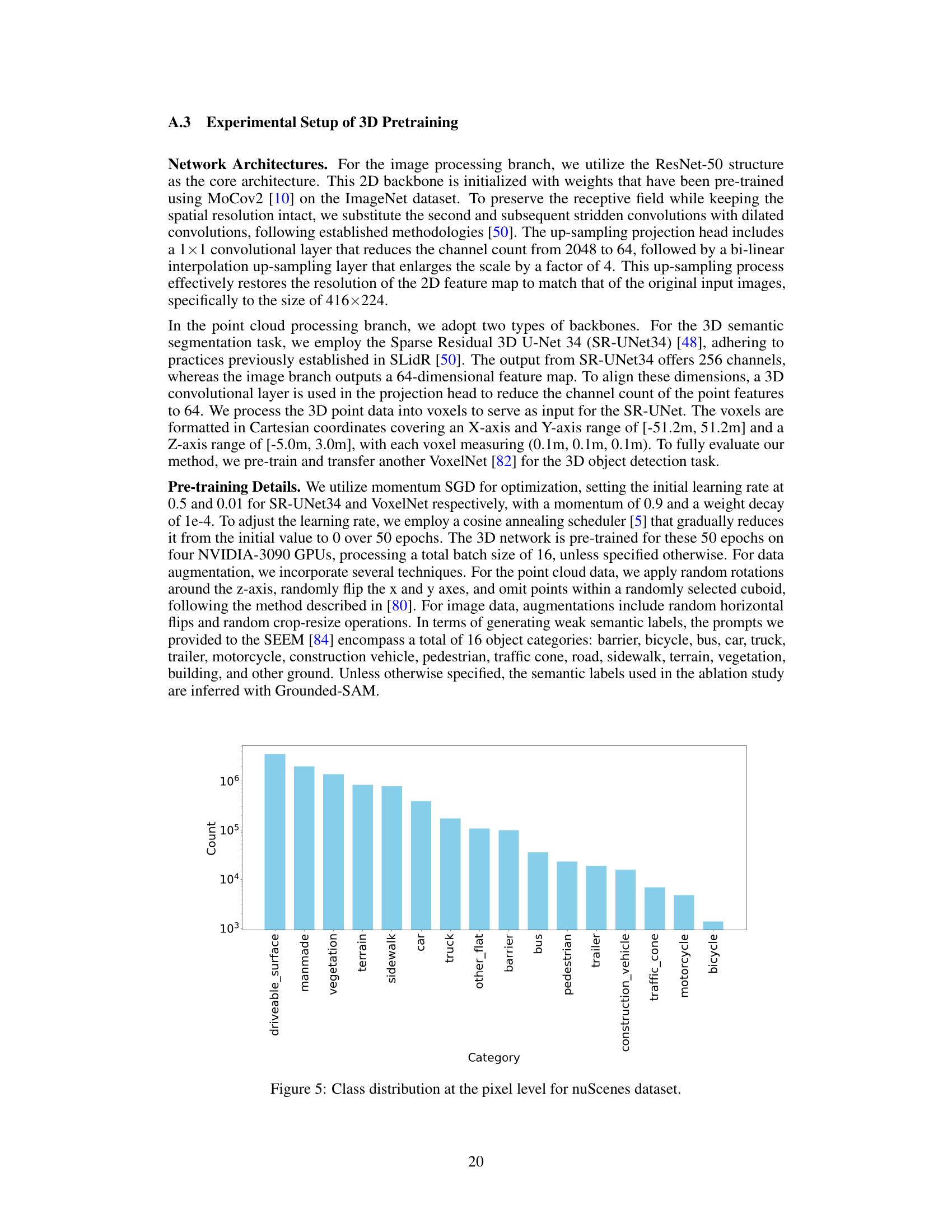
🔼 This figure shows the class distribution of the nuScenes dataset at the pixel level. The x-axis represents the different semantic categories present in the dataset, and the y-axis shows the count of pixels belonging to each category. The bar chart visually represents the class imbalance in the dataset, where some categories have significantly more pixel instances than others. This imbalance is a common characteristic in real-world datasets and can impact the performance of machine learning models that are trained using such data.
read the caption
Figure 5: Class distribution at the pixel level for nuScenes dataset.

🔼 This bar chart visualizes the frequency distribution of different semantic classes within the nuScenes dataset at the pixel level. The x-axis lists the various semantic categories present in the dataset, while the y-axis represents the count of pixels belonging to each category. The chart clearly shows an imbalanced class distribution, with some categories having significantly more pixels than others. This highlights the challenge of class imbalance in the dataset, which the paper addresses with its proposed density and category-aware sampling strategy.
read the caption
Figure 5: Class distribution at the pixel level for nuScenes dataset.
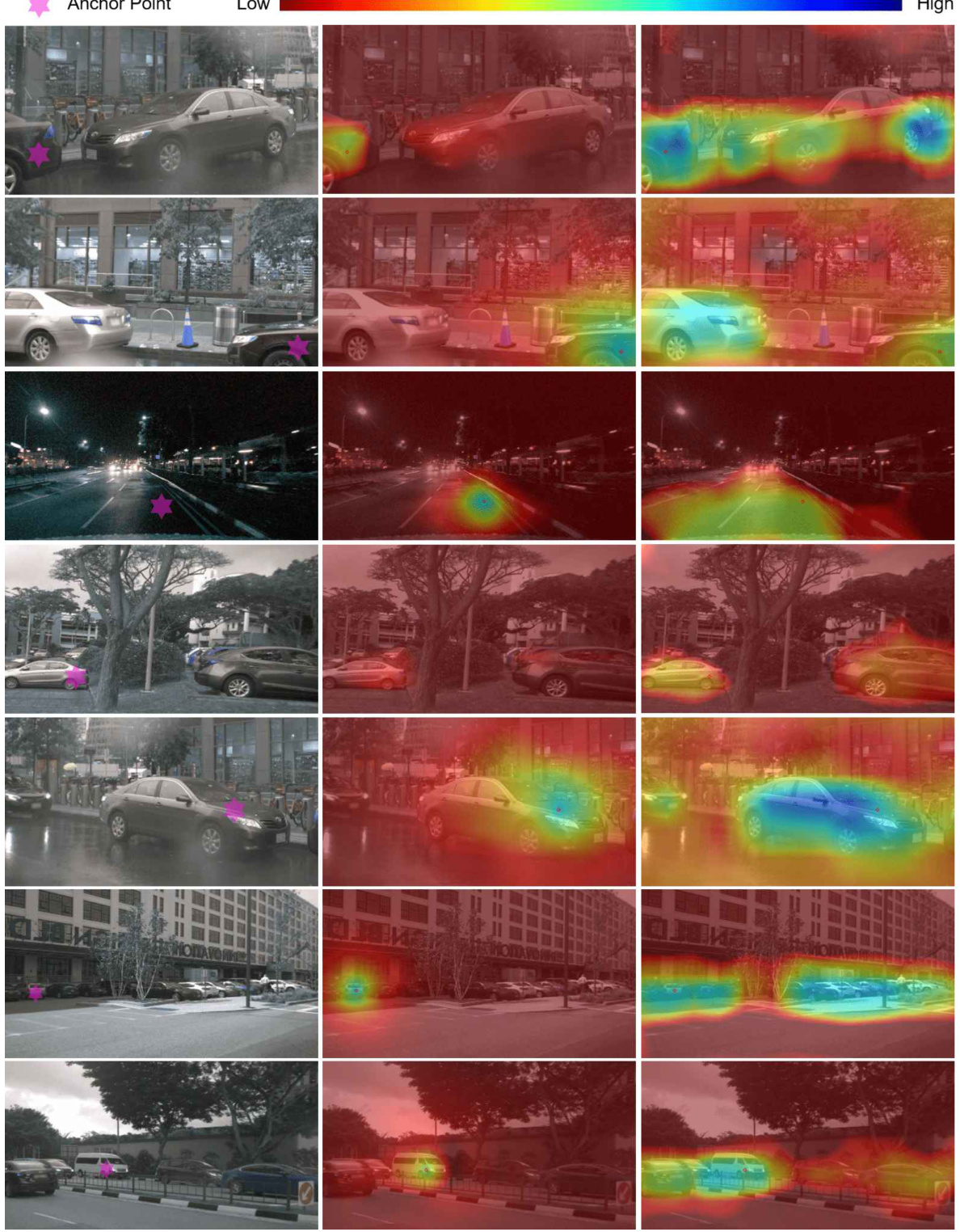
🔼 This figure visualizes the similarities between image and point cloud features using different projection heads. The first column shows the raw image and the location of an anchor point. The second column displays feature similarities from conventional projection heads used for point-pixel contrastive distillation (only directly corresponding pixels show high similarity). The third column shows feature similarities from additional projection heads designed for weakly-supervised (category-aware) contrastive distillation, where points and pixels of the same semantic category exhibit higher similarity.
read the caption
Figure 7: Visualization of the similarities between image and point cloud feature. In the first column, we show the raw image and the projection of anchor point in the image. In second columns, we illustrate the similarities between 3D query and 2D features extracted by the conventional projection heads hp and hD for point-pixel level contrastive distillation. In third columns, we illustrate the similarities between 3D query and 2D features extracted by the extra projection heads him and hom for weakly-supervised (category-aware) contrastive distillation.
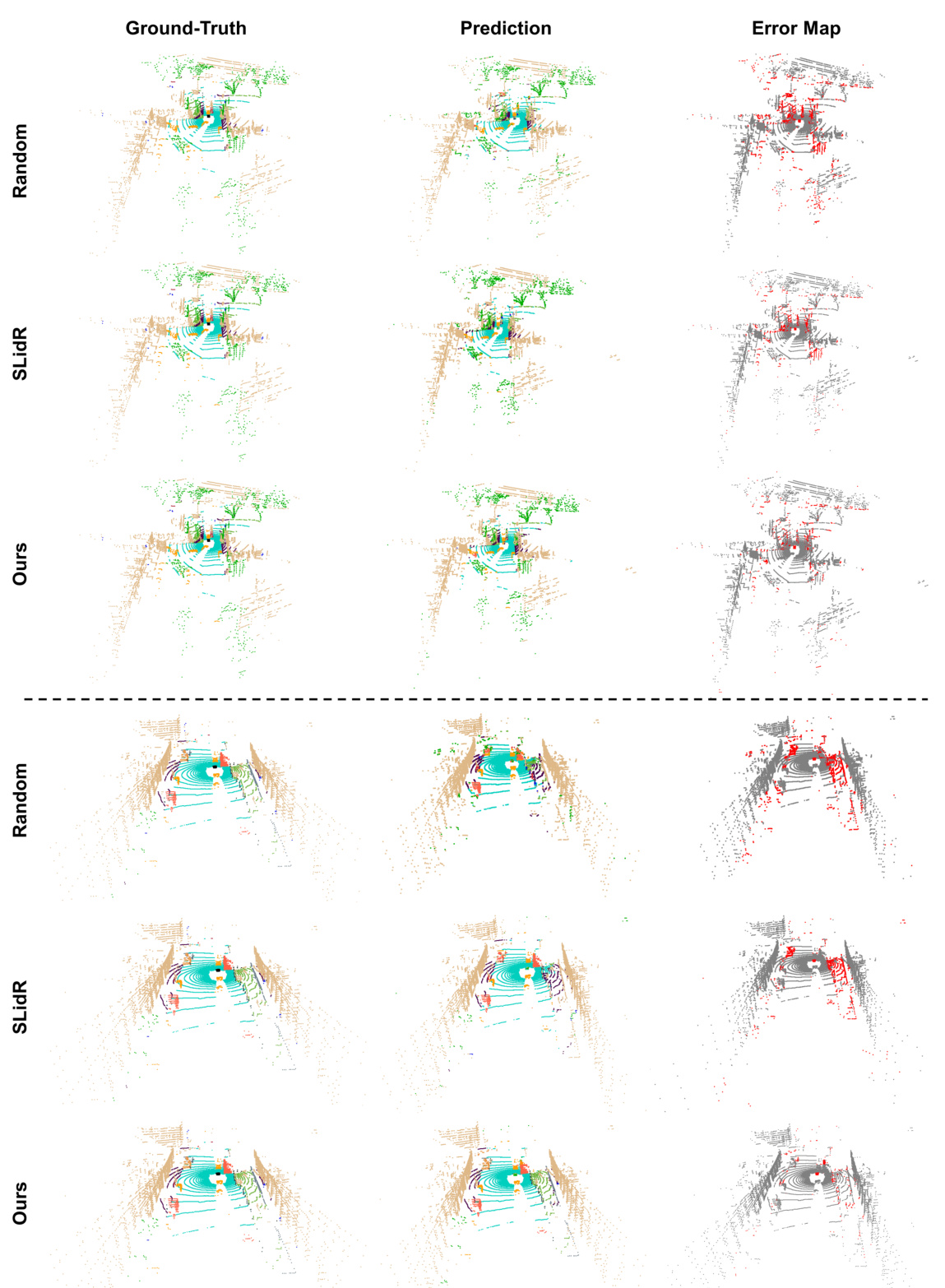
🔼 This figure presents a qualitative comparison of the results obtained from fine-tuning on 1% of the nuScenes-lidarseg dataset using different pre-training methods. The image shows the ground truth, the model predictions, and an error map highlighting incorrect predictions (red). The comparison includes results using random initialization, the SLidR method, and the proposed OLIVINE method. The results are best viewed in color and zoomed in for more details.
read the caption
Figure 8: Qualitative results of fine-tuning on 1% of the nuScenes-lidarseg dataset with different pre-training strategies. Note that the results are shown as error maps on the right, where red points indicate incorrect predictions. Best viewed in color and zoom in for more details.

🔼 This figure presents a qualitative comparison of the semantic segmentation results obtained using three different pre-training strategies (Random, SLidR, and OLIVINE) on the nuScenes-lidarseg dataset. Only 1% of the annotated data was used for fine-tuning. The results are visualized using error maps, where red points highlight incorrect predictions. The figure showcases the improved accuracy of the OLIVINE method compared to the baseline methods.
read the caption
Figure 8: Qualitative results of fine-tuning on 1% of the nuScenes-lidarseg dataset with different pre-training strategies. Note that the results are shown as error maps on the right, where red points indicate incorrect predictions. Best viewed in color and zoom in for more details.
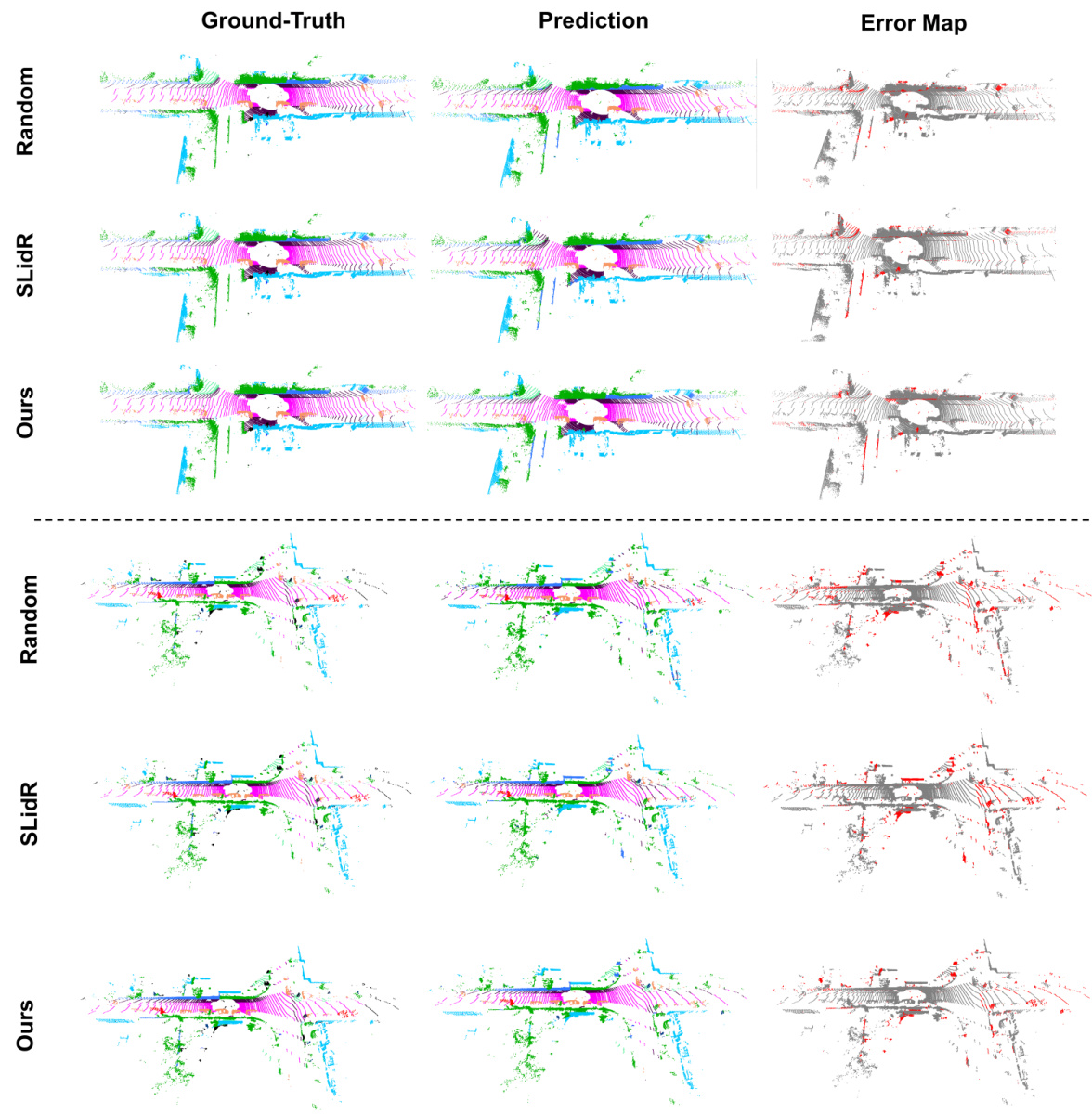
🔼 This figure shows a qualitative comparison of semantic segmentation results on the nuScenes-lidarseg dataset using different pre-training strategies (Random, SLidR, and OLIVINE). The results are displayed in three columns: ground truth, prediction, and an error map. The error map highlights incorrect predictions in red, allowing for a visual assessment of the effectiveness of each pre-training method. The image is best viewed in color and zoomed in for detailed examination.
read the caption
Figure 8: Qualitative results of fine-tuning on 1% of the nuScenes-lidarseg dataset with different pre-training strategies. Note that the results are shown as error maps on the right, where red points indicate incorrect predictions. Best viewed in color and zoom in for more details.

🔼 This figure presents a qualitative comparison of semantic segmentation results on the nuScenes-lidarseg dataset using different pre-training methods. The top row shows the ground truth, the middle row shows the predictions, and the bottom row shows the error maps. The error maps highlight the incorrect predictions in red. The comparison showcases the improvements achieved by the proposed OLIVINE method compared to baseline methods (Random and SLidR) when fine-tuned with limited data (1%).
read the caption
Figure 8: Qualitative results of fine-tuning on 1% of the nuScenes-lidarseg dataset with different pre-training strategies. Note that the results are shown as error maps on the right, where red points indicate incorrect predictions. Best viewed in color and zoom in for more details.

🔼 This figure shows a comparison between raw data (RGB images and LiDAR point clouds) and the semantic segmentation results produced by the Grounded-SAM model. The top half displays the original data, while the bottom half shows the semantic segmentation, where each segment is color-coded for easy identification. The alignment of the labels highlights how the model associates image regions with corresponding LiDAR points.
read the caption
Figure 12: Illustration of the weak semantic labels predicted by Grounded-SAM. The top half of the figure displays the raw RGB images and LiDAR point clouds, while the bottom half presents the corresponding weak semantic labels applied to both images and point clouds, aligned using camera parameters. Each distinct segment is represented by a unique color. Best viewed in color.

🔼 This figure shows the weak semantic labels generated by the Grounded SAM model applied to both RGB images and LiDAR point clouds. The top half displays the original data; the bottom half shows the corresponding semantic segmentation, where each segment is color-coded for easy identification. The alignment of the labels with the images and point clouds is based on camera parameters.
read the caption
Figure 12: Illustration of the weak semantic labels predicted by Grounded SAM. The top half of the figure displays the raw RGB images and LiDAR point clouds, while the bottom half presents the corresponding weak semantic labels applied to both images and point clouds, aligned using camera parameters. Each distinct segment is represented by a unique color. Best viewed in color.
More on tables

🔼 This table presents the results of fine-tuning a semantic segmentation model on the SemanticKITTI dataset using different percentages of annotated data (1%, 5%, 10%, 20%, and 100%). The results are shown for three different initialization methods: Random, SLidR [50] (a state-of-the-art method), and the proposed OLIVINE method. The table highlights the improvement in mIoU achieved by OLIVINE compared to SLidR for each data percentage, showing consistent gains across various data amounts.
read the caption
Table 2: Finetuning results on SemanticKITTI across various percentages of annotated data. The table compares the improvement achieved by our method relative to the SLidR [50].

🔼 This table compares different pre-training methods on semantic segmentation tasks using both finetuning and linear probing. It shows the mean Intersection over Union (mIoU) scores achieved on the validation sets of the nuScenes and SemanticKITTI datasets when using varying percentages (1%, 5%, 10%, 25%, and 100%) of labeled data for training. The methods compared include random initialization, PointContrast, DepthContrast, PPKT, SLidR, ST-SLidR, Seal, and the authors’ proposed OLIVINE method.
read the caption
Table 1: Comparison of various pre-training techniques for semantic segmentation tasks using either finetuning or linear probing (LP). This evaluation uses different proportions of accessible annotations from the nuScenes or SemanticKITTI datasets and presents the mean Intersection over Union (mIoU) scores on the validation set.
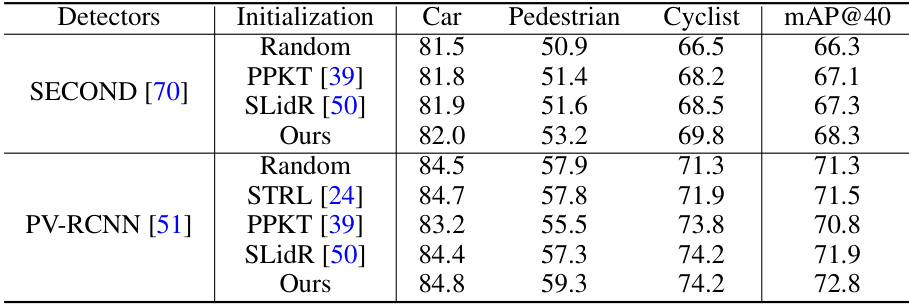
🔼 This table compares the performance of different pre-training methods (Random, PPKT, SLIDR, and the proposed OLIVINE method) on the KITTI dataset for 3D object detection. The results are broken down by object category (Car, Pedestrian, Cyclist) and overall mean Average Precision (mAP) at an IoU threshold of 40%. It demonstrates the improvement achieved by OLIVINE compared to other baseline methods.
read the caption
Table 4: Comparison of our method with other pre-training techniques through fine-tuning on the KITTI dataset. The results reflect the 3D object detection performance under moderate difficulty on the validation set.

🔼 The table compares different pre-training methods (Random, PointContrast, DepthContrast, PPKT, SLidR, ST-SLidR, Seal, and OLIVINE - the proposed method) on their performance in semantic segmentation tasks. The performance is evaluated using two protocols: finetuning and linear probing. Different percentages of annotated data (1%, 5%, 10%, 25%, 100%) are used for evaluation on both the nuScenes and SemanticKITTI datasets. The mean Intersection over Union (mIoU) is reported as the performance metric on the validation set for each method, dataset, and data percentage.
read the caption
Table 1: Comparison of various pre-training techniques for semantic segmentation tasks using either finetuning or linear probing (LP). This evaluation uses different proportions of accessible annotations from the nuScenes or SemanticKITTI datasets and presents the mean Intersection over Union (mIoU) scores on the validation set.

🔼 This table presents the ablation study results for the key components of the proposed method. It shows the fine-tuned results on the nuScenes-lidarseg and SemanticKITTI datasets using only 1% of the labeled data for each component (different types of supervision, architectures of projection heads, different distributions to model semantic features, and different sampling strategies). The results highlight the contribution of each component to the overall performance.
read the caption
Table 6: Comprehensive ablation studies for the key components. We report the fine-tuned results on nuScenes-lidarseg and SemanticKITTI (S.K.) datasets with 1% of the labeled data.
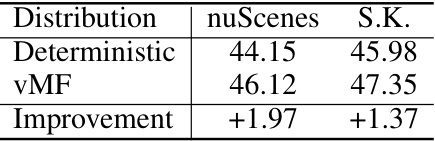
🔼 This table presents the ablation study results on nuScenes-lidarseg and SemanticKITTI datasets using only 1% of the labeled data for fine-tuning. It shows the impact of different components in the proposed OLIVINE method. The components analyzed include: different types of supervision (weak labels vs ground truth), different architectures of projection heads (decoupled vs not decoupled), different distributions for modeling semantic features (deterministic vs vMF), and different sampling strategies (random, density-aware, category-aware, and the proposed density and category-aware sampling). For each setting, the mIoU scores are reported for both datasets. The ‘Improvement’ row shows the difference in mIoU between the baseline and the variant.
read the caption
Table 6: Comprehensive ablation studies for the key components. We report the fine-tuned results on nuScenes-lidarseg and SemanticKITTI (S.K.) datasets with 1% of the labeled data.
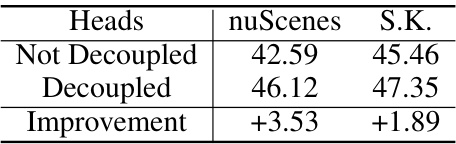
🔼 This table presents the ablation study results of the key components of OLIVINE using 1% of labeled data for fine-tuning on nuScenes-lidarseg and SemanticKITTI datasets. It shows the impact of different types of supervision, architectures of projection heads, distributions to model semantic features, and sampling strategies. The results demonstrate the effectiveness of using decoupled heads, vMF distribution, and density and category-aware sampling. The improvements are shown in terms of mIoU scores.
read the caption
Table 6: Comprehensive ablation studies for the key components. We report the fine-tuned results on nuScenes-lidarseg and SemanticKITTI (S.K.) datasets with 1% of the labeled data.
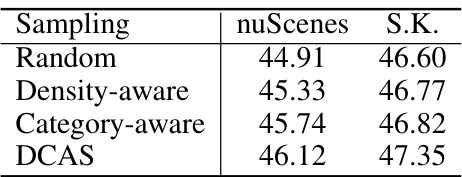
🔼 This table presents the ablation study results for the key components of the proposed method OLIVINE. It shows the fine-tuned performance on nuScenes-lidarseg and SemanticKITTI datasets when using only 1% of labeled data for training. The table compares results under different settings of supervision, architecture, distribution, and sampling strategy. This allows to quantify the impact of each component on the overall performance.
read the caption
Table 6: Comprehensive ablation studies for the key components. We report the fine-tuned results on nuScenes-lidarseg and SemanticKITTI (S.K.) datasets with 1% of the labeled data.

🔼 This table compares the performance of random initialization versus the proposed OLIVINE method using the WaffleIron 3D backbone. The results show mIoU scores for semantic segmentation with 1%, 10%, and 100% of the training data. The results demonstrate that the benefits of pre-training are more significant with smaller amounts of labeled data.
read the caption
Table 7: Performance for 3D backbone WaffleIron.
🔼 This table compares the performance of different pre-training methods on semantic segmentation tasks using two different evaluation protocols: finetuning and linear probing. The results are presented for various percentages of labeled data used for training, showing the mIoU scores achieved on the validation sets of both the nuScenes and SemanticKITTI datasets. The table allows for a comparison of the effectiveness of different pre-training strategies under varying data conditions.
read the caption
Table 1: Comparison of various pre-training techniques for semantic segmentation tasks using either finetuning or linear probing (LP). This evaluation uses different proportions of accessible annotations from the nuScenes or SemanticKITTI datasets and presents the mean Intersection over Union (mIoU) scores on the validation set.

🔼 This table compares the GPU memory usage and training time of the proposed OLIVINE method against two other state-of-the-art methods, PPKT and SLidR, highlighting the computational efficiency of OLIVINE.
read the caption
Table 9: Comparison with other methods regarding the computational cost during pre-training.

🔼 This table compares different pre-training methods for semantic segmentation on the nuScenes and SemanticKITTI datasets. It shows the mean Intersection over Union (mIoU) achieved by each method when using different percentages of labeled data (1%, 5%, 10%, 25%, and 100%) for fine-tuning and linear probing. The results are presented to highlight the impact of different pre-training strategies on the downstream semantic segmentation task.
read the caption
Table 1: Comparison of various pre-training techniques for semantic segmentation tasks using either finetuning or linear probing (LP). This evaluation uses different proportions of accessible annotations from the nuScenes or SemanticKITTI datasets and presents the mean Intersection over Union (mIoU) scores on the validation set.

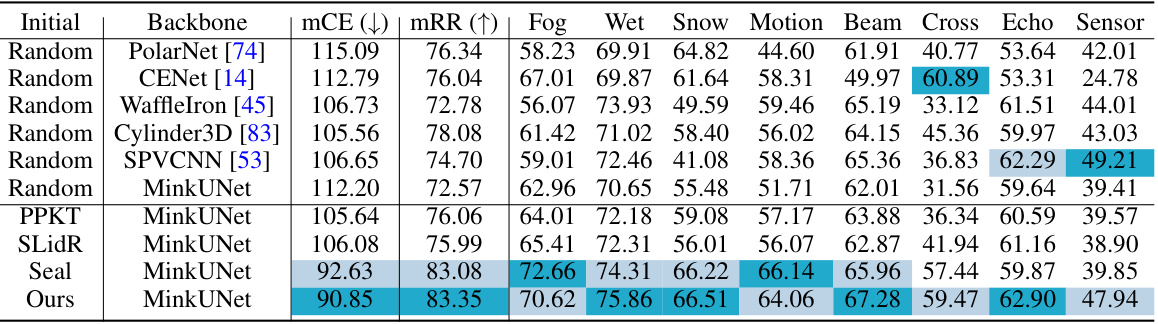
🔼 This table presents a detailed breakdown of the Intersection over Union (IoU) scores achieved by different methods on the nuScenes-lidarseg dataset when only 1% of the labeled data is used for fine-tuning. The results are broken down by semantic class (e.g., barrier, bicycle, bus, car, etc.), offering a granular view of model performance for each object category. The highest and second-highest IoU scores for each class are highlighted for easy comparison.
read the caption
Table 10: Per-class results on the nuScenes-lidarseg dataset using only 1% of the labeled data for fine-tuning. This chart displays the IoU scores for each category, with the highest and second-highest scores marked in dark blue and light blue, respectively.

🔼 This table presents the ablation study results on nuScenes and SemanticKITTI datasets using only 1% of labeled data for fine-tuning. It systematically analyzes the impact of different components in the proposed method, including different types of supervision, architectures of projection heads, distributions to model semantic features, and sampling strategies. Each row in the table corresponds to a specific experimental setup, and the columns present the mIoU scores obtained on nuScenes and SemanticKITTI datasets.
read the caption
Table 6: Comprehensive ablation studies for the key components. We report the fine-tuned results on nuScenes-lidarseg and SemanticKITTI (S.K.) datasets with 1% of the labeled data.
Full paper#