TL;DR#
Current text-to-image models struggle to accurately generate images of ‘out-of-distribution’ (OOD) concepts (things not well-represented in their training data). This is because the quality of training data significantly affects how well an adapter module (like LoRA or DreamBooth) can generate details of these OOD concepts. Low-quality training data (with disruptive elements or small objects) leads to inaccurate and poor-looking results.
This paper introduces CATOD, a new framework that tackles this problem. CATOD uses active learning to iteratively improve both the quality of the training data and the adapter model. It does this by using a weighted scoring system that combines an aesthetic score and a concept-matching score to select the best training samples. Experiments show that CATOD substantially outperforms existing methods, improving the quality of generated images for OOD concepts.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in text-to-image generation because it directly addresses the challenge of adapting these models to out-of-distribution (OOD) concepts. The proposed CATOD framework offers a novel solution by combining active learning with a weighted scoring system, leading to significantly improved results. This work is highly relevant to the current trend of enhancing the versatility and robustness of generative models and provides new directions for research into data-efficient model adaptation and active learning strategies for generative AI.
Visual Insights#

🔼 This figure compares images generated before and after applying different adaptor modules (LoRA) to enhance the generation of out-of-distribution (OOD) concepts. The comparison highlights the challenge of accurately depicting visual details, especially for concepts with high CMMD (Maximum Mean Discrepancy) scores, which indicate a larger discrepancy between the model’s learned distribution and the distribution of the OOD concepts. It demonstrates that while adaptors can improve the overall representation of OOD concepts, they often struggle to accurately capture fine details like texture, contours, and patterns.
read the caption
Figure 1: Comparison of images generated before/after training adaptors over concepts with different CMMD scores. One observation is that concepts with higher CMMD scores are notably more challenging for the underlying model to generate (the second row). Additionally, we also notice that a higher CMMD value leads to a more notable loss of visual details when training adaptors (the third row).
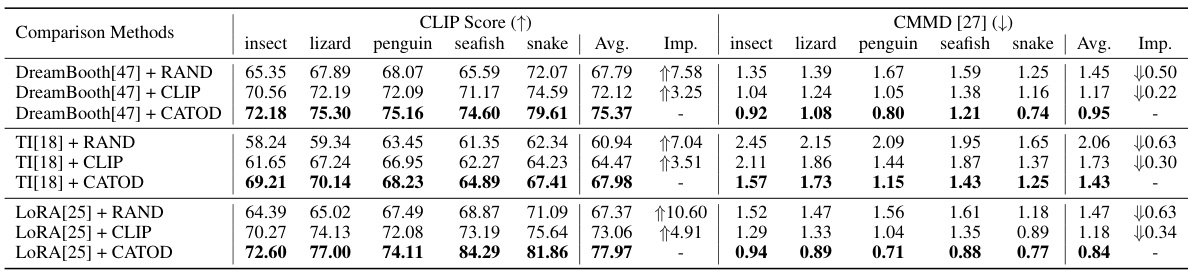
🔼 This table compares the performance of CATOD against several baseline methods across different OOD concepts. The metrics used are CLIP score (higher is better, indicating better image-text alignment) and CMMD score (lower is better, indicating less discrepancy between generated and real images). The table is broken down by concept category (insect, lizard, penguin, seafish, snake) and shows the average performance across five subclasses within each category. The ‘Imp.’ column shows the improvement achieved by CATOD relative to the baseline methods. The best-performing methods in each category are highlighted in bold.
read the caption
Table 1: A Comparison over the performance of CATOD, in terms of the CLIP score and CMMD score with 100 images sampled at last. This table shows the average result of 5 sub-classes within each category. The overall improvement of our proposed CATOD is provided by 'Imp.'. Methods with the best performance are bold-folded.
In-depth insights#
OOD Concept Adapt.#
The heading ‘OOD Concept Adapt.’ likely refers to the adaptation of models to handle Out-of-Distribution (OOD) concepts. This is a crucial area in machine learning, especially in the context of generative models, where unseen or unexpected inputs can lead to nonsensical outputs. The core challenge lies in how to effectively train models to generalize beyond their initial training data, which often limits their ability to accurately represent novel or rare concepts. Adaptive methods, like fine-tuning or employing adaptor modules such as LoRA, are common approaches, but their effectiveness often hinges on the quality of the available OOD data. Active learning techniques, which iteratively select and add high-quality data, are increasingly important for addressing the scarcity of OOD data and improving model robustness. The success of adapting to OOD concepts will involve developing effective scoring mechanisms that combine factors like aesthetic quality and semantic accuracy of generated outputs, allowing for a more targeted and controlled approach to model adaptation.
CATOD Framework#
The CATOD framework tackles the challenge of adapting large-scale text-to-image diffusion models to accurately generate images of out-of-distribution (OOD) concepts. It addresses the issue of low-quality training data that hinders the performance of existing adaptor modules like LoRA and DreamBooth. CATOD employs an active learning paradigm, iteratively improving both the quality of the training data and the adaptor itself. This is achieved through a weighted scoring system, balancing aesthetic and concept-matching scores to select high-quality training samples. The framework’s theoretical analysis provides insights into the importance of these scores in improving generative results. The iterative approach enhances the accuracy and fidelity of generated images, substantially outperforming prior methods in extensive experimental evaluations. By intelligently addressing data quality and adaptor training, CATOD demonstrates a significant improvement in generating realistic and detailed imagery for challenging, previously unseen concepts.
Active Data Acquisition#
Active data acquisition, in the context of adapting diffusion models to out-of-distribution (OOD) concepts, is a crucial strategy to overcome the limitations of relying solely on large, pre-trained models. The core idea is to iteratively select and incorporate high-quality training data that facilitates accurate generation of OOD concepts. This approach addresses the challenge of low-quality or irrelevant training data commonly found in existing datasets, which often leads to inaccurate or aesthetically unpleasing synthetic results. A key aspect is a weighted scoring system, combining aesthetic and concept-matching scores, to prioritize the most informative data points. This intelligent selection process avoids manual curation, significantly reducing the human effort involved and improving efficiency. The dynamic balancing of these scores adapts to the evolving needs of the model and the concept being adapted, leading to more accurate and aesthetically pleasing results. The active learning paradigm allows for iterative refinement of both the training data and the adaptor model, resulting in significant performance gains and robustness against the challenges posed by OOD concepts.
Theoretical Analysis#
A theoretical analysis section in a research paper would ideally delve into the underlying mathematical principles and assumptions supporting the paper’s claims. It should rigorously justify the proposed methods, ideally using established mathematical frameworks. For instance, it might demonstrate the convergence of an algorithm or provide error bounds for a prediction model. A strong theoretical analysis provides a deeper understanding of the method’s strengths and limitations, enabling a more informed interpretation of experimental results. It could also address aspects such as the algorithm’s computational complexity or the statistical properties of the data. The analysis should be clear, concise, and accessible to a knowledgeable reader, but also precise and rigorous enough to withstand scrutiny from experts in the field. In short, a compelling theoretical analysis section provides the crucial link between empirical observations and underlying principles, lending credibility and robustness to the overall research findings. It is essential to clearly state any assumptions made in the analysis and discuss their potential implications for the broader applicability of the results.
Multi-Concept Results#
The ‘Multi-Concept Results’ section would ideally delve into the model’s performance when adapting to multiple out-of-distribution (OOD) concepts simultaneously. A key aspect would be evaluating whether the model’s ability to accurately generate images of one concept is affected by the presence of other OOD concepts in the training data. Does the accuracy decrease significantly when multiple concepts are introduced, or does the model maintain a consistent level of performance? The analysis should also investigate whether the model effectively disentangles the concepts, meaning it can generate images that accurately reflect the requested concept without interference from others. The ideal discussion would include quantitative metrics such as CLIP scores and CMMD, assessing the effect of multiple concepts on both image quality and semantic accuracy. Furthermore, it would be insightful to explore how the model’s performance compares across various combinations of OOD concepts. Are some concept combinations more challenging than others? Finally, examining the computational overhead associated with handling multiple concepts would also enhance the analysis. It’s important to discuss whether training time or resource requirements increase significantly with the number of concepts.
More visual insights#
More on figures

🔼 This figure demonstrates how the quality of training data impacts the results of generating images of out-of-distribution (OOD) concepts using different adaptation methods. The left column shows examples where disruptive elements in the training data lead to similar artifacts in the generated images. The middle column shows that training data with small or vague instances of the concept result in low-quality generated images. In contrast, the right column illustrates how high-quality training data (clear, single object, distinct from the background) leads to accurate and high-fidelity generated images.
read the caption
Figure 2: Comparison of synthetic results on data with different quality. Generated images are significantly influenced by the quality of training data. If the training data includes disruptive objects, the generative images may include disruptive visual details (Left). When an object within the image is too small, the results may not accurately represent the intended concepts (Middle). In contrast, if the image contains a high-fidelity object without disruptive elements (Right), the model is more likely to generate the desired result accurately.
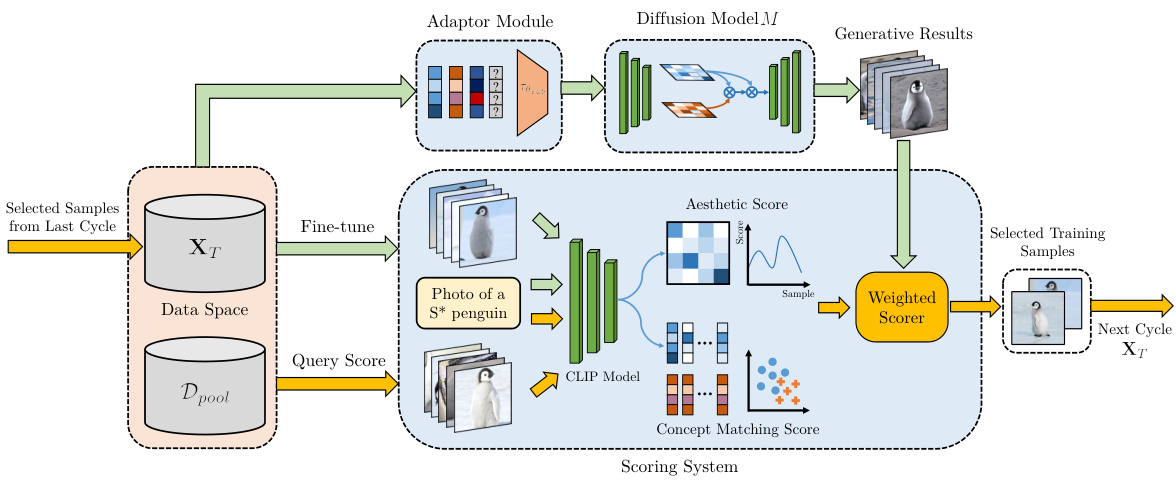
🔼 The figure illustrates the iterative process of the CATOD framework. It starts by generating OOD concepts using the current adaptor, then calculating weighted scores (combining aesthetic and concept-matching scores) to select high-quality training samples. These samples are added to the training pool, and the adaptor and scoring system are fine-tuned. This cycle repeats until convergence, improving the generation of OOD concepts.
read the caption
Figure 3: The overall pipeline of CATOD. In brief, CATOD alternatively performs data selection and scheduled OOD concept adaption. In each training cycle, we first generate OOD concepts according to the current adaptor and calculate the weights for the aesthetic score and concept-matching score. Then, we calculate the weighted score for each sample within the data pool Dpool, select the top images accordingly, and add them to the training pool. At last, CATOD fine-tunes the scoring system and training adaptors according to the updated data pool, and proceed to the next cycle. The above three steps alternatively proceed until convergence.

🔼 This figure compares the image generation results of three different sampling methods (random sampling, top CLIP score sampling, and CATOD) when using the LoRA adapter. It visually demonstrates how CATOD outperforms the other methods by producing images that accurately depict the target concepts while avoiding the addition of unwanted details often present in the other sampling methods.
read the caption
Figure 4: A comparison of different sampling strategies with LoRA. Specifically, we compare three lines of works: (1) RAND, in which the model is trained with 100 randomly selected samples; (2) with samples of the highest CLIP scores (100 samples); (3) 100 samples with CATOD. The model trained with randomly sampled data fails to capture the features of out-of-distribution (OOD) concepts, while the ones trained with top CLIP scores contain necessary details but also include disruptive elements.

🔼 This figure shows the iterative process of generating images of emperor penguin chicks and axolotls using the CATOD method. Each column represents a different cycle of the process, with 20 high-quality samples added in each cycle. The images become increasingly realistic and accurately represent the target concepts over time, highlighting the effectiveness of the method’s iterative refinement process.
read the caption
Figure 5: Generative results as cycle proceeds. Samples are generated with CATOD on cycles from 1 to 7. To better observe how generated images change as the cycle proceeds, we conduct another 2 cycles here. In each cycle, we select and add 20 high-quality samples. Generative samples start to converge and contain the right details within the original concept after cycle 4 or 5. We can also see that those generative results contain diverse contents within the background based on the few images given.
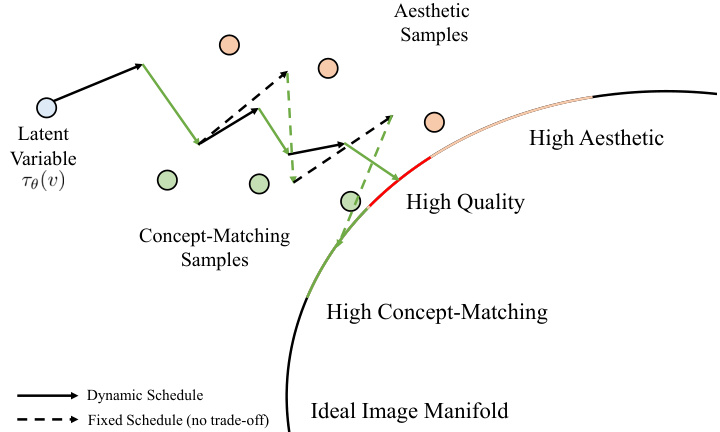
🔼 This figure provides an intuitive comparison between fixed and dynamic schedules in active learning. The x-axis represents the latent variable, while the y-axis shows the embedding quality. The dynamic schedule shows an iterative approach where the learning process adapts to newly added samples, resulting in a smoother and more consistent approach towards achieving high embedding quality. In contrast, the fixed schedule demonstrates a lack of adaptation and results in an imbalanced and fluctuating path to high embedding quality. The ideal image manifold, presented as a curve, represents the desired quality of embeddings. The figure illustrates how a dynamic schedule, by adapting to newly added samples, progresses more efficiently towards the ideal image manifold, compared to a fixed schedule that shows heavier bias and performance fluctuation.
read the caption
Figure 6: An intuitive comparison for fixed/dynamic schedules. The active learning paradigm can be viewed as guiding the iterative embedding updating through newly added samples. We can see that a fixed schedule makes the learned embedding heavily biased, which in turn leads to performance fluctuation.

🔼 This figure shows the results of generating images with two concepts combined in a single image. The model used a LORA adaptor trained on ‘Frilled Lizard’ and ‘Emperor Penguin Chick’. The images demonstrate the model’s ability to generate high-quality images with minimal artifacts, even when combining multiple concepts, including background elements, in-distribution concepts, and out-of-distribution concepts from other adaptors.
read the caption
Figure 7: Generative results with 2 concepts within one image. Experiments are conducted based on the LORA adaptor fully trained on concepts 'Frilled Lizard' and 'Emperor Penguin Chick'. We try to compose these creatures with background elements, in-distribution concepts, and out-of-distribution concepts learned by other adaptors. The final results show high quality with minimal disruptive details.
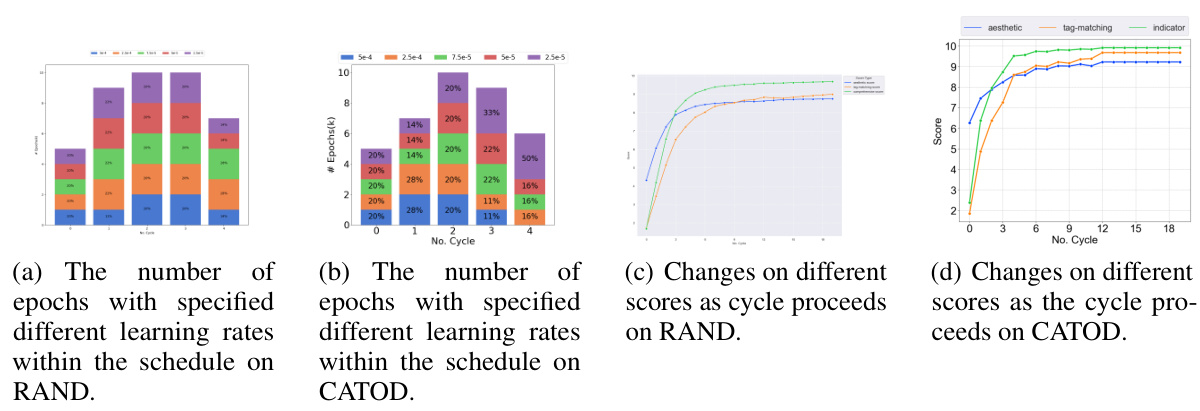
🔼 This figure compares the training schedule and score changes between RAND and CATOD for the ’emperor penguin (chick)’ concept. Panels (a) and (b) show how the number of epochs used for different learning rates in the training schedule changes across cycles. Panels (c) and (d) illustrate the changes in aesthetic, concept-matching, and comprehensive scores across cycles for RAND and CATOD respectively. The results demonstrate that CATOD’s schedule stabilizes earlier than RAND’s, indicating more efficient training.
read the caption
Figure 8: A comparison on how the schedule and scores change on RAND(scheduled) and CATOD as cycle proceeds on concept emperor penguin(chick). (a),(b) show how the #epochs for each learning rate in the schedule change as the cycle proceeds, when (c), (d) show how aesthetic/concept-matching/comprehensive score change on RAND (scheduled) and CATOD. The scores for CATOD stop changing at cycle 12 since more added samples do not help boost adaptor quality.

🔼 This figure compares the performance of three different sampling strategies when training a LoRA adapter for out-of-distribution (OOD) concepts: random sampling (RAND), top CLIP score sampling, and the proposed CATOD method. The results show that random sampling fails to capture the essential visual details of OOD concepts, while top CLIP score sampling, although capturing some details, still includes disruptive elements. In contrast, CATOD effectively selects high-quality samples, leading to improved generative results.
read the caption
Figure 4: A comparison of different sampling strategies with LoRA. Specifically, we compare three lines of works: (1) RAND, in which the model is trained with 100 randomly selected samples; (2) with samples of the highest CLIP scores (100 samples); (3) 100 samples with CATOD. The model trained with randomly sampled data fails to capture the features of out-of-distribution (OOD) concepts, while the ones trained with top CLIP scores contain necessary details but also include disruptive elements.

🔼 This figure compares the image generation results of three different sampling strategies for training LoRA adaptors on out-of-distribution (OOD) concepts. The strategies are random sampling (RAND), top CLIP score sampling, and the proposed CATOD method. The results show that CATOD produces higher-quality images with accurate visual details and fewer disruptive elements compared to the other two methods.
read the caption
Figure 4: A comparison of different sampling strategies with LoRA. Specifically, we compare three lines of works: (1) RAND, in which the model is trained with 100 randomly selected samples; (2) with samples of the highest CLIP scores (100 samples); (3) 100 samples with CATOD. The model trained with randomly sampled data fails to capture the features of out-of-distribution (OOD) concepts, while the ones trained with top CLIP scores contain necessary details but also include disruptive elements.

🔼 This figure shows a comparison of the image selection and generation results for different combinations of methods (LoRA + CLIP vs. LoRA + CATOD) and concepts (Axolotl and Emperor Penguin Chick). The ‘Selection’ column displays the training samples selected by each method, highlighting that CATOD selects samples with varied angles. The ‘Generation’ column shows the generated images resulting from those selections. The results demonstrate that using CATOD in the training process leads to generated images with more diverse angles, showcasing the method’s effectiveness in capturing diversity.
read the caption
Figure 9: A comparison of selected and generate samples on different combinations of methods and concepts. We can observe that training samples with different angles selected by CATOD also lead to diverse angle in their generative results.
More on tables
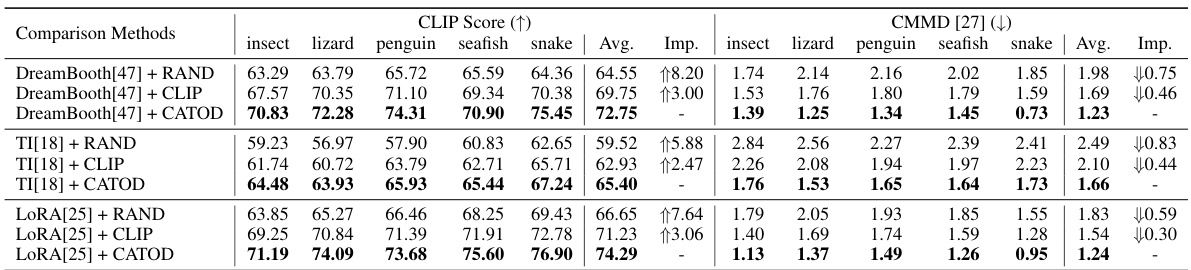
🔼 This table compares the performance of CATOD against several baseline methods across various metrics. Specifically, it shows the average CLIP and CMMD scores for different methods (DreamBooth, Textual Inversion, LoRA) combined with different sampling strategies (RAND, CLIP, CATOD) on five insect sub-categories. The ‘Imp.’ column highlights the performance improvement achieved by CATOD. The best performing methods for each sub-category are highlighted in bold.
read the caption
Table 1: A Comparison over the performance of CATOD, in terms of the CLIP score and CMMD score with 100 images sampled at last. This table shows the average result of 5 sub-classes within each category. The overall improvement of our proposed CATOD is provided by 'Imp.'. Methods with the best performance are bold-folded.
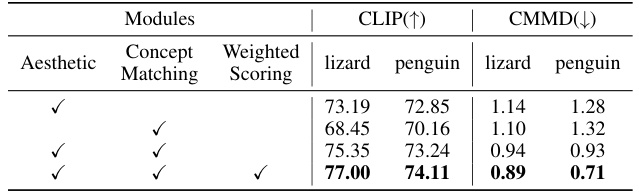
🔼 This table presents the ablation study results for the CATOD model. By removing either the aesthetic scoring module, the concept-matching scoring module, or the weighted scoring system, the impact on the model’s performance in terms of CLIP score and CMMD score is evaluated. The results are shown separately for the ‘penguin’ and ’lizard’ categories, using LoRA as the adaptor module. This allows for a clear understanding of the individual contributions and interplay of each component within the CATOD framework.
read the caption
Table 3: Results of Ablating Aesthetic, Concept-Matching Scorer and Weighted Scoring on CATOD. We show the average results conducted on the categories 'penguin' and 'lizard' with LoRA.
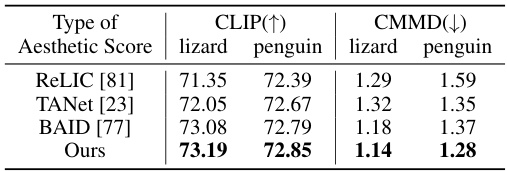
🔼 This table presents a comparison of the performance of the CATOD framework using different aesthetic scoring models. The experiment focuses on the ‘penguin’ and ’lizard’ categories, utilizing the LoRA adaptor. The table shows the average CLIP score (higher is better) and CMMD score (lower is better) for each aesthetic scorer. The ‘Ours’ row represents the performance of the proposed aesthetic scorer within the CATOD framework.
read the caption
Table 4: Results of CATOD with different types of aesthetic scorers. We show the average results conducted on the categories 'penguin' and 'lizard' with LoRA.

🔼 This table compares the performance of CATOD against several baseline methods (DreamBooth, TI, and LoRA) across five different concept categories (insect, lizard, penguin, seafish, snake). Each category contains five sub-classes, and the average CLIP score (a measure of image-text similarity) and CMMD score (a measure of the discrepancy between generated and real images) are reported for each method. The ‘Imp.’ column shows the improvement achieved by CATOD compared to the baselines.
read the caption
Table 1: A Comparison over the performance of CATOD, in terms of the CLIP score and CMMD score with 100 images sampled at last. This table shows the average result of 5 sub-classes within each category. The overall improvement of our proposed CATOD is provided by 'Imp.'. Methods with the best performance are bold-folded.
🔼 This table compares the performance of CATOD against other methods (DreamBooth, TI, and LORA) using two metrics: CLIP score (higher is better) and CMMD score (lower is better). It shows the average performance across five sub-categories for each of five main categories of images. The ‘Imp.’ column indicates the improvement achieved by CATOD over the best-performing baseline method for each metric and sub-category.
read the caption
Table 1: A Comparison over the performance of CATOD, in terms of the CLIP score and CMMD score with 100 images sampled at last. This table shows the average result of 5 sub-classes within each category. The overall improvement of our proposed CATOD is provided by 'Imp.'. Methods with the best performance are bold-folded.

🔼 This table compares the performance of CATOD using different initial training data pools (high-quality vs. random samples, with varying sample sizes) and evaluates the CLIP score and CMMD score. The ‘Imp.’ column shows the improvement of CATOD compared to baselines. Bold values indicate the best-performing methods in each category.
read the caption
Table 7: A Comparison over the performance of CATOD on different types of the initial training data pool, in terms of the CLIP score and CMMD score with 100 images sampled at last. This table shows the average result of 5 sub-classes within each category. The overall improvement of our proposed CATOD is provided by 'Imp.'. Methods with the best performance are bold-folded.

🔼 This table compares the performance of CATOD against several baseline methods (DreamBooth, TI, and LoRA) across different sampling strategies (RAND, CLIP, and CATOD) for 25 OOD concepts grouped into five categories (insect, lizard, penguin, seafish, snake). The evaluation metrics are CLIP score (higher is better, measuring image-text alignment) and CMMD score (lower is better, measuring the discrepancy between generated and real images). The ‘Imp.’ column shows the improvement achieved by CATOD compared to each baseline method. The best performing methods in each category are bolded.
read the caption
Table 1: A Comparison over the performance of CATOD, in terms of the CLIP score and CMMD score with 100 images sampled at last. This table shows the average result of 5 sub-classes within each category. The overall improvement of our proposed CATOD is provided by 'Imp.'. Methods with the best performance are bold-folded.
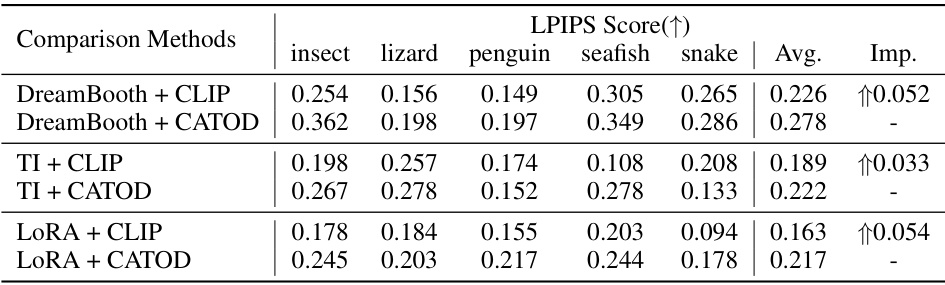
🔼 This table compares the performance of CATOD against several baseline methods (DreamBooth, Textual Inversion, and LoRA) across various metrics, including CLIP score (higher is better) and CMMD score (lower is better). The results are averaged across five sub-categories for each concept, and the improvement achieved by CATOD is explicitly shown. The table highlights the best-performing method for each metric.
read the caption
Table 1: A Comparison over the performance of CATOD, in terms of the CLIP score and CMMD score with 100 images sampled at last. This table shows the average result of 5 sub-classes within each category. The overall improvement of our proposed CATOD is provided by 'Imp.'. Methods with the best performance are bold-folded.
Full paper#



















