TL;DR#
Current OOD detection methods using CLIP often suffer from suboptimal performance due to domain gaps or risk disrupting intricate representations. Sparsification methods are limited by subtle activation differences in large-scale models. This paper introduces SeTAR, a training-free approach that leverages selective low-rank approximation of weight matrices to improve OOD detection.
SeTAR enhances OOD detection via post-hoc modification using a simple greedy search algorithm. SeTAR+FT, a finetuning extension, optimizes performance further. Experiments across ImageNet1K and Pascal-VOC benchmarks demonstrate superior performance compared to existing methods, specifically reducing false positives by a notable margin. Ablation studies confirm SeTAR’s efficiency, robustness, and generalizability.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and machine learning, particularly those working on out-of-distribution (OOD) detection. It offers a scalable and efficient solution for a critical problem in deploying AI systems in real-world settings, where unseen data is common. The training-free nature of the proposed method, SeTAR, is particularly attractive, making it widely applicable. The method’s state-of-the-art performance and generalizability across various model backbones make it a significant advancement in the field. Furthermore, the paper opens up new avenues for research in low-rank approximation techniques for improving model robustness and generalization.
Visual Insights#

🔼 This figure provides a visual overview of the SeTAR method. It shows the architecture of the CLIP image and text encoder, highlighting the feed-forward sublayer where the low-rank approximation is applied. Panel (c) illustrates the singular value decomposition (SVD) and how selective low-rank approximation modifies the weight matrix Wup. Finally, (d) visually demonstrates the effect of the low-rank approximation on the singular value matrix Σ.
read the caption
Figure 1: The overview of SeTAR. (a) The structure of the CLIP image and text encoder. (b) The details of the feed-forward sublayer. (c) For each encoder layer, we replace the Wup weight matrix with its low-rank approximation Wup. (d) The illustration of Σ before and after low-rank approximation.

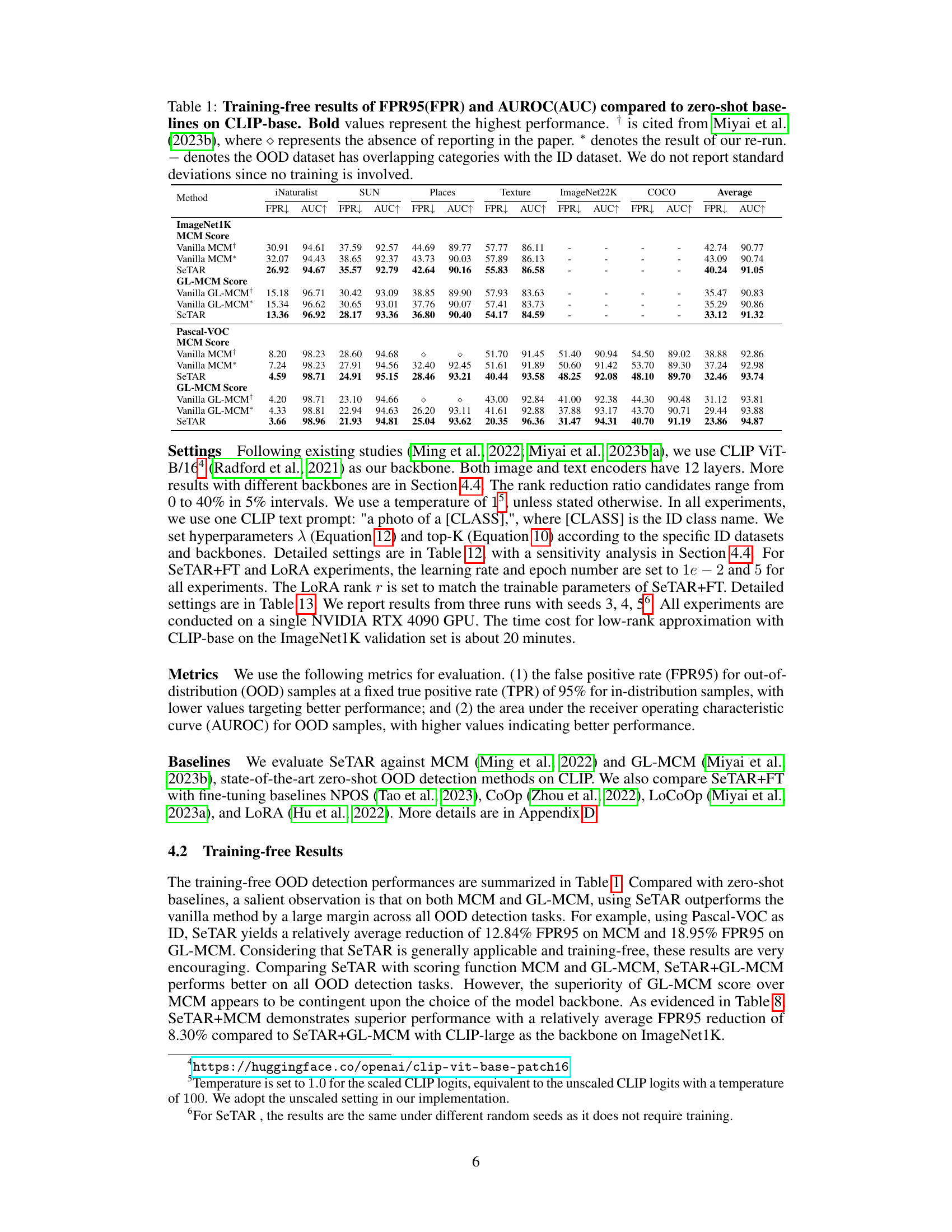
🔼 This table presents the training-free results of the proposed SeTAR model and compares its performance with zero-shot baselines (Vanilla MCM and Vanilla GL-MCM) on two benchmark datasets (ImageNet1K and Pascal VOC). The results are evaluated using two metrics: False Positive Rate at 95% True Positive Rate (FPR95) and Area Under the Receiver Operating Characteristic Curve (AUROC). Lower FPR95 and higher AUROC values indicate better performance. The table highlights SeTAR’s superior performance, achieving lower FPR95 and higher AUROC compared to the baselines across various OOD datasets, demonstrating the effectiveness of the proposed method for training-free OOD detection.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.
In-depth insights#
OOD Detection Methods#
Out-of-distribution (OOD) detection methods are crucial for the safe deployment of machine learning models. Many approaches exist, broadly categorized into zero-shot and finetuning-based methods. Zero-shot techniques leverage pre-trained models, avoiding the need for additional training data, but often suffer from suboptimal performance due to domain mismatch. Conversely, finetuning methods offer higher accuracy by adapting models to specific downstream tasks but risk deconstructing the intricate representations initially learned. A promising area involves sparsity-based methods which exploit differences in activation patterns between in-distribution (ID) and OOD samples. However, these methods’ effectiveness diminishes in larger, pre-trained models, limiting their applicability. Low-rank approximation techniques offer a unique approach: selectively manipulating weight matrices to enhance OOD detection, offering a scalable and efficient solution. This approach achieves state-of-the-art results and is complemented by further finetuning for even greater performance. The choice of scoring function (e.g., MCM, GL-MCM) also impacts performance. Ultimately, the ideal OOD detection method balances accuracy, efficiency, and generalizability across diverse model architectures and datasets.
SeTAR’s Mechanism#
SeTAR’s mechanism centers on selective low-rank approximation of weight matrices within pre-trained vision-language models like CLIP. Instead of uniformly reducing the rank of all matrices, SeTAR employs a greedy search algorithm to identify and selectively apply low-rank approximation to specific weight matrices (particularly, the Wup matrices in feed-forward layers), optimizing for improved OOD detection performance. This targeted approach enhances the model’s robustness to out-of-distribution inputs by preserving crucial singular components while discarding less critical ones that might contribute to overfitting or sensitivity to noise. The training-free nature is a key advantage, making SeTAR readily applicable to existing models without retraining. Post-hoc modification allows for seamless integration with various scoring functions and model backbones, demonstrating scalability and flexibility.
SeTAR+FT Extension#
The heading ‘SeTAR+FT Extension’ suggests an enhancement to the core SeTAR method for out-of-distribution (OOD) detection. SeTAR, likely a training-free approach, might be improved by incorporating fine-tuning (FT). This extension, SeTAR+FT, likely addresses SeTAR’s limitations by allowing for a fine-tuning stage. This could lead to improved accuracy, especially when dealing with subtle activation patterns between in-distribution and out-of-distribution data. However, fine-tuning introduces the risk of disrupting pre-trained representations within SeTAR, potentially negating its training-free advantage. Therefore, a key aspect of SeTAR+FT would be its strategy to mitigate this risk, perhaps by selectively fine-tuning only specific parameters or layers. The paper likely explores the trade-off between improved performance through fine-tuning and maintaining the efficiency and scalability of the original training-free method. Evaluations comparing SeTAR+FT against both zero-shot and other fine-tuning baselines would be crucial to assess the extension’s effectiveness and practical value.
Ablation Study Results#
An ablation study systematically removes components of a model to assess their individual contributions. In this context, an ‘Ablation Study Results’ section would detail the impact of removing specific elements on the overall performance, particularly regarding out-of-distribution (OOD) detection. Key insights would emerge from comparing the performance metrics (e.g., AUROC, FPR95) of the full model against variants with components removed. The analysis would illuminate the role of various aspects, such as different weighting schemes, specific layers or modules, and data types, in achieving the model’s OOD detection capabilities. A thorough ablation study provides strong evidence for the model’s design choices and helps validate its robustness by demonstrating that its core functionality isn’t overly reliant on any single component. Furthermore, the results might reveal unexpected interactions between parts of the model, leading to a more nuanced understanding of its underlying mechanisms and potential avenues for future improvement.
Future Research#
Future research directions stemming from this work on out-of-distribution (OOD) detection could explore several promising avenues. Improving the hyperparameter search algorithm is crucial; a more sophisticated method than the greedy approach used here could significantly enhance performance and generalizability. Investigating different low-rank approximation techniques beyond SVD is warranted, potentially leading to more efficient and effective OOD detection. Extending SeTAR to handle various modalities beyond images and text (e.g., audio, video) would broaden its applicability and impact. Finally, a deeper theoretical understanding of why selective low-rank approximation improves OOD detection is needed; this could unlock further advancements and help guide future algorithm designs. The current state-of-the-art results highlight the potential for significant progress in this area.
More visual insights#
More on figures
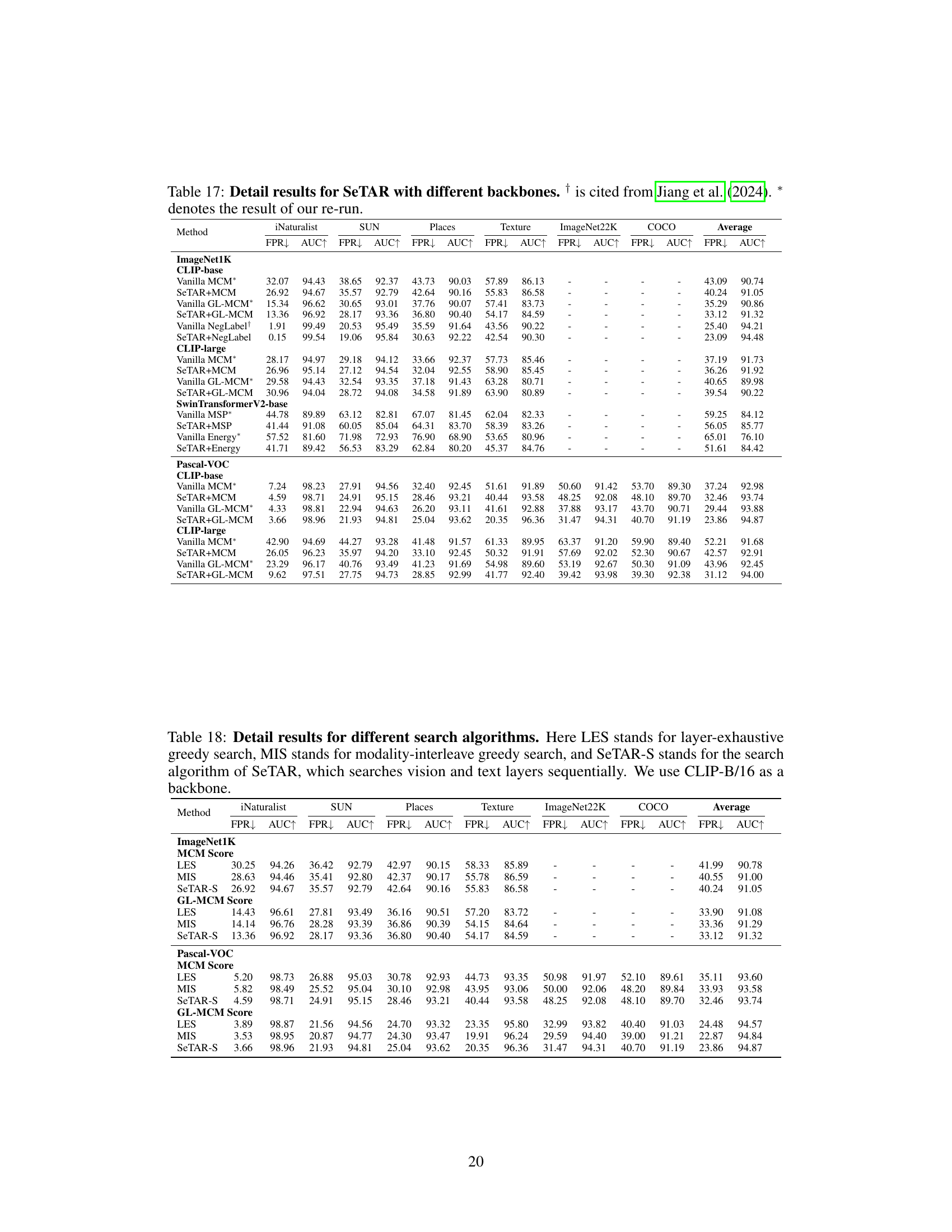
🔼 This figure shows the performance comparison of SeTAR when using different weight matrices (Wup, Wdown, Wq, Wk, Wv, Wout) in the CLIP model for out-of-distribution (OOD) detection on the ImageNet1K benchmark. The x-axis represents the number of encoder layers visited during the greedy search algorithm used by SeTAR. The y-axis shows the average AUROC (Area Under the Receiver Operating Characteristic curve) and average FPR95 (False Positive Rate at 95% True Positive Rate) across multiple OOD datasets. A higher AUROC indicates better performance, while a lower FPR95 also indicates better performance. The figure helps to determine which weight matrices are most effective for improving OOD detection performance using SeTAR, indicating the effectiveness of targeting the ‘Wup’ matrix.
read the caption
Figure 2: Average AUROC/FPR95 of different weight types on ImageNet1K benchmark. We use CLIP-B/16 as a backbone.
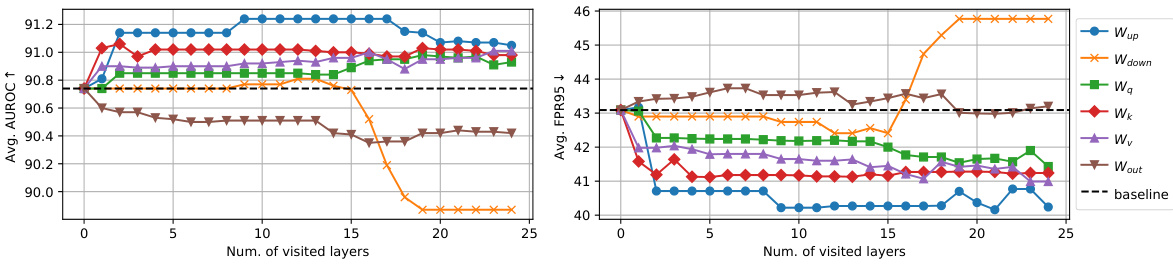
🔼 This figure shows the ablation study on different weight matrices in CLIP’s image and text encoders. It compares the performance of SeTAR when using different weight matrices (Wup, Wdown, Wq, Wk, Wv, and Wout) for low-rank approximation against a baseline without any modification. The results are presented in terms of average AUROC and average FPR95, indicating SeTAR’s performance using different weight matrices on the ImageNet1K benchmark. CLIP-B/16 is used as the backbone model.
read the caption
Figure 2: Average AUROC/FPR95 of different weight types on ImageNet1K benchmark. We use CLIP-B/16 as a backbone.
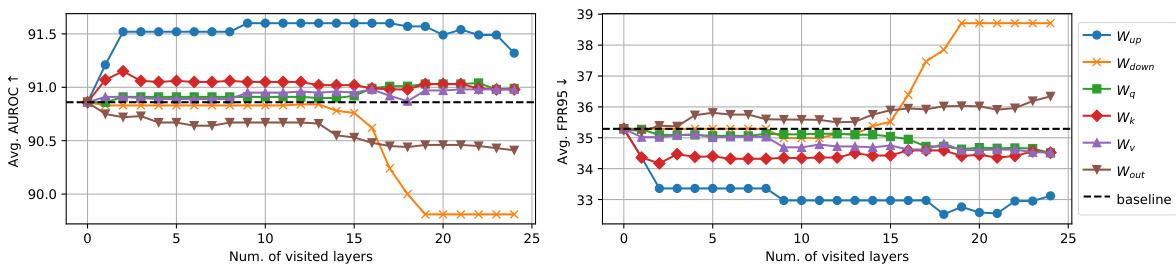
🔼 This figure shows the results of an ablation study comparing the performance of SeTAR when different weight matrices (Wup, Wdown, Wq, Wk, Wv, Wo, and Wout) are modified using low-rank approximation. The x-axis represents the number of layers visited by the greedy search algorithm used in SeTAR, and the y-axis shows the average AUROC and FPR95 across different OOD datasets. The figure helps to illustrate which weight matrix is most effective for improving OOD detection performance when using SeTAR.
read the caption
Figure 2: Average AUROC/FPR95 of different weight types on ImageNet1K benchmark. We use CLIP-B/16 as a backbone.
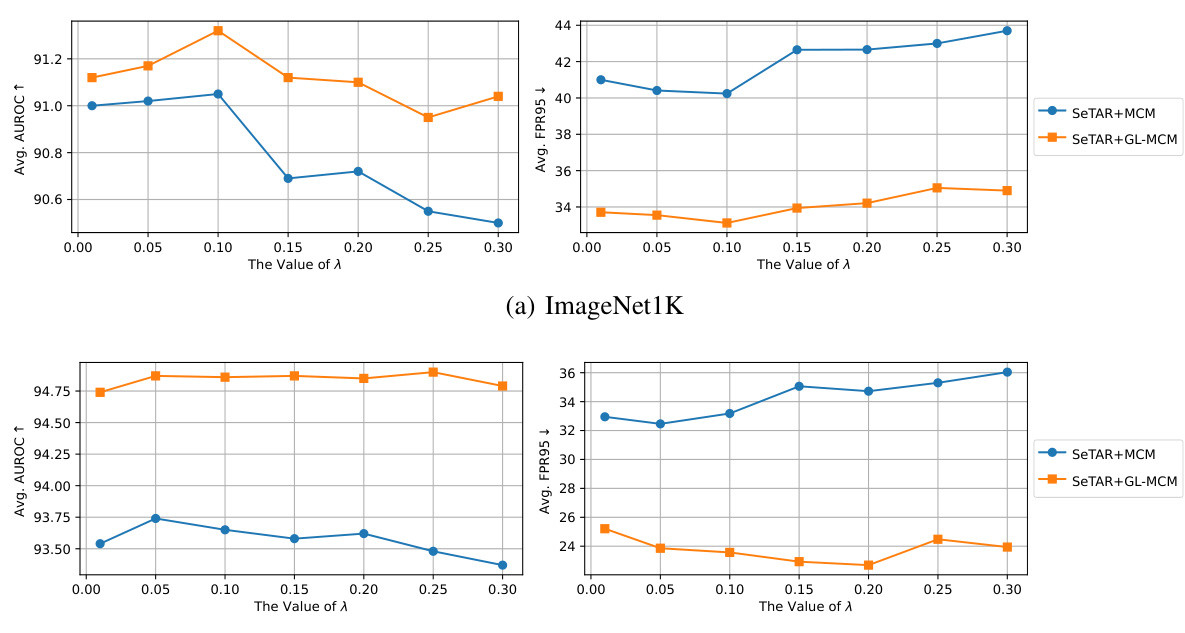
🔼 This figure presents the ablation study on the hyperparameter λ (lambda) across different datasets. The top two panels show the average AUROC (Area Under the Receiver Operating Characteristic curve) and average FPR95 (False Positive Rate at 95% True Positive Rate) on ImageNet1K, while the bottom two panels show the same metrics for Pascal VOC. The x-axis represents the value of λ, and the y-axis represents the AUROC and FPR95, respectively. Each line represents the performance with different combinations of SeTAR+MCM (SeTAR with the Maximum Class Mean scoring function) and SeTAR+GL-MCM (SeTAR with the Generalized Maximum Class Mean scoring function). The purpose of this ablation is to determine the optimal value of λ for various datasets and scoring functions by analyzing the trade-off between AUROC and FPR95.
read the caption
Figure 4: Ablation studies on λ on different ID datasets. We use CLIP-B/16 as a backbone.

🔼 This figure presents the results of ablation studies conducted to evaluate the impact of the hyperparameter top-K on the performance of the SeTAR model across different in-distribution (ID) datasets (ImageNet1K and Pascal VOC). The plots show the average AUROC (Area Under the Receiver Operating Characteristic Curve) and average FPR95 (False Positive Rate at 95% True Positive Rate) for various values of top-K using both MCM and GL-MCM scoring functions. The x-axis represents the value of top-K, and the y-axis represents the performance metrics (AUROC and FPR95). The goal of this analysis is to determine the optimal top-K value that balances model performance and robustness.
read the caption
Figure 5: Ablation studies on top-K on different ID datasets. We use CLIP-B/16 as a backbone.
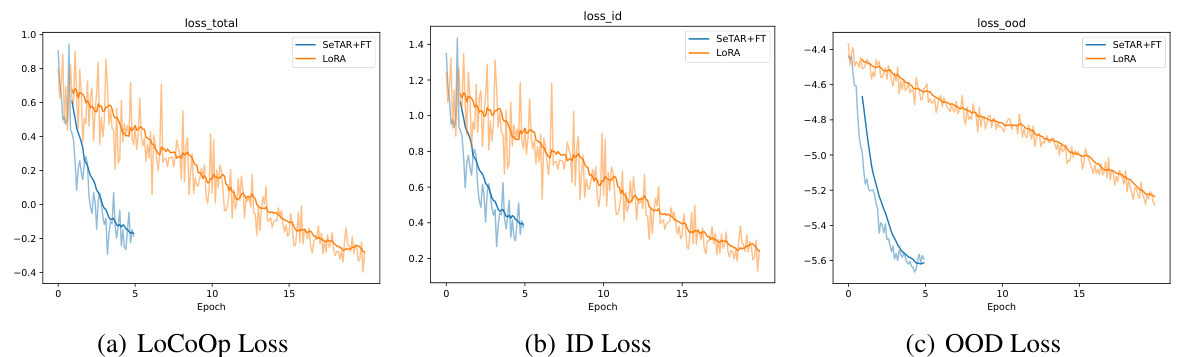
🔼 This figure compares the training loss curves of SeTAR+FT and LoRA on the ImageNet1K dataset using the CLIP-B/16 backbone. Three loss curves are shown: the total loss (LoCoOp Loss), the in-distribution (ID) loss, and the out-of-distribution (OOD) loss. SeTAR+FT demonstrates faster convergence than LoRA, achieving lower losses in fewer epochs, especially for the OOD loss. This indicates that SeTAR+FT is more efficient in adapting the pre-trained model for OOD detection than LoRA. The FPR (False Positive Rate) at epoch 5 for SeTAR+FT is also provided as a point of reference, showing its superior performance over LORA’s results at epochs 1, 5, and 15.
read the caption
Figure 6: Loss plots of SeTAR+FT v.s. LoRA on ImageNet1K. We use CLIP-B/16 as a backbone. SeTAR+FT demonstrates faster convergence across all losses, especially in the OOD loss. For reference, with MCM score, SeTAR+FT achieves an average FPR of 38.77 at epoch 5. While LORA achieves an average FPR of 42.88, 39.92 and 42.23 at epoch 1, 5 and 15, respectively.

🔼 This figure visualizes the rank reduction ratios obtained by SeTAR for different layers in the CLIP image and text encoders, using ImageNet1K and Pascal VOC as the ID datasets. Different backbones (CLIP-base, CLIP-large, and Swin-base) are shown. The heatmap shows that SeTAR adaptively adjusts the rank reduction ratio depending on the layer and backbone architecture, highlighting the method’s adaptability and efficiency. The visual and text modalities are represented as ‘V’ and ‘T’, respectively.
read the caption
Figure 7: Visualization of SeTAR rank reduction ratio distribution on different ID datasets with different backbones. IN1K, VOC stand for ImageNet1K and Pascal-VOC. And V, T stand for visual modality and text modality of the CLIP model.
More on tables
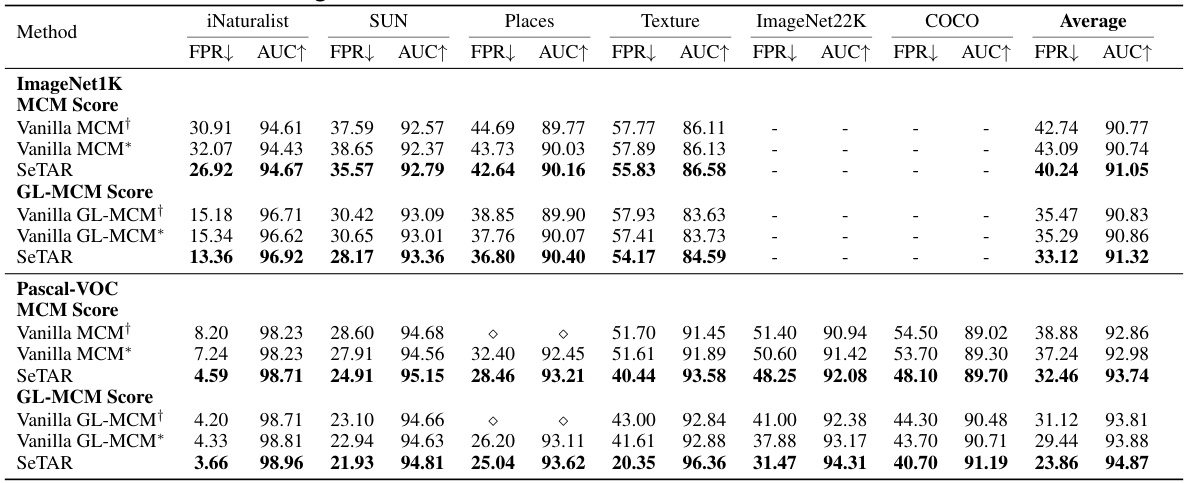
🔼 This table presents the training-free results of the proposed SeTAR method and compares its performance with existing zero-shot baselines (Vanilla MCM and Vanilla GL-MCM) on two benchmark datasets (ImageNet1k and Pascal VOC). The metrics used are FPR95 (False Positive Rate at 95% True Positive Rate) and AUROC (Area Under the Receiver Operating Characteristic curve). Lower FPR95 and higher AUROC indicate better performance. The results are shown separately for MCM and GL-MCM scoring functions and for various OOD datasets. The table highlights SeTAR’s superior performance in reducing the false positive rate compared to the baselines, indicating its effectiveness in identifying out-of-distribution samples without the need for training.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.
🔼 This table presents the training-free performance of SeTAR and baselines on various OOD detection tasks using the CLIP-base model. It compares the False Positive Rate at 95% True Positive Rate (FPR95) and the Area Under the Receiver Operating Characteristic curve (AUROC) across different OOD datasets. The results demonstrate SeTAR’s improved performance compared to existing zero-shot methods.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ⋄ represents the absence of reporting in the paper. * denotes the result of our re-run. − denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.
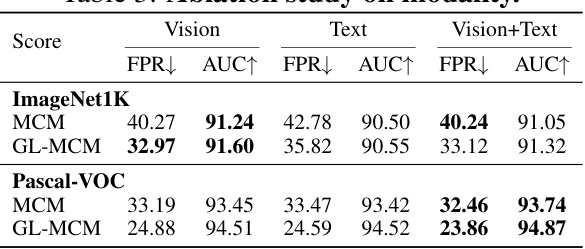
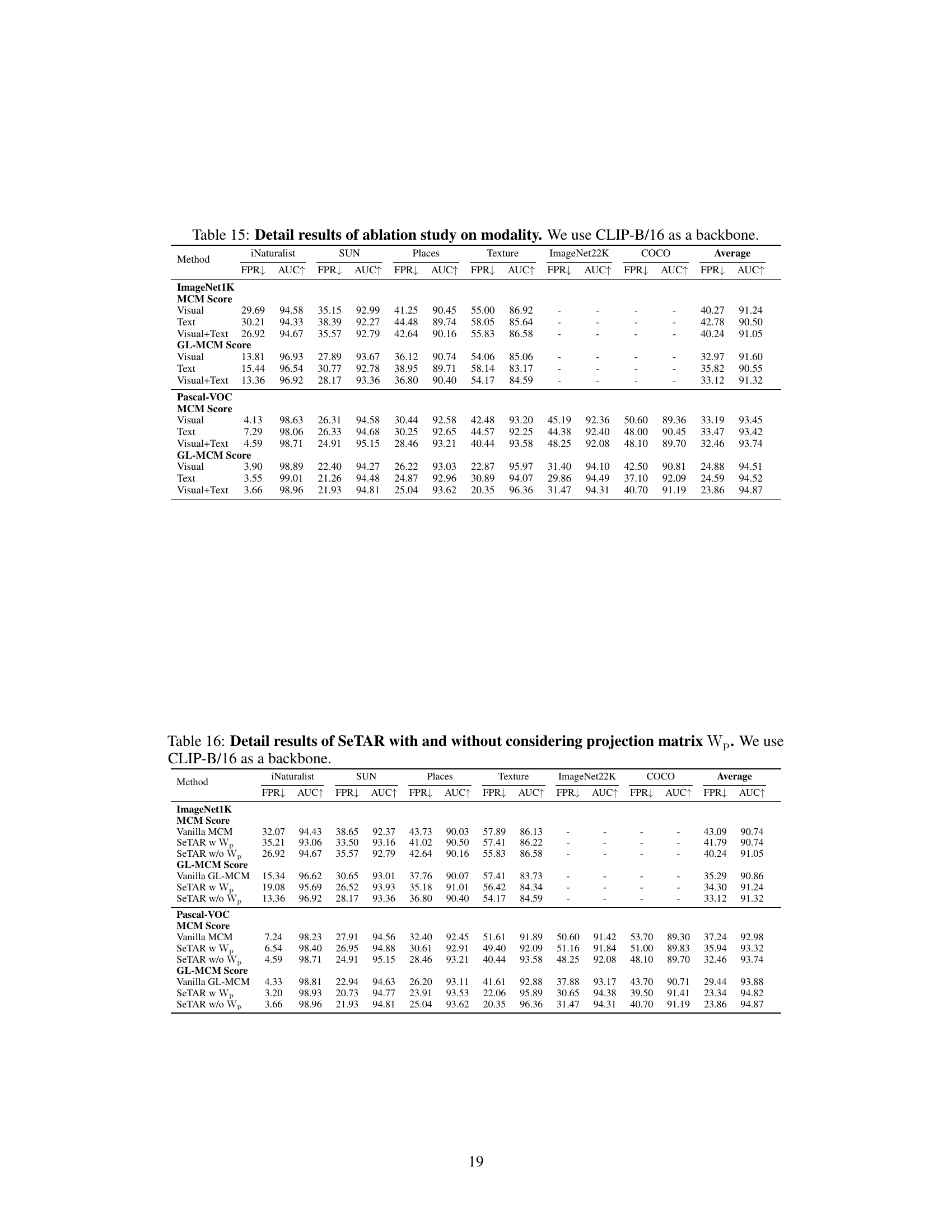
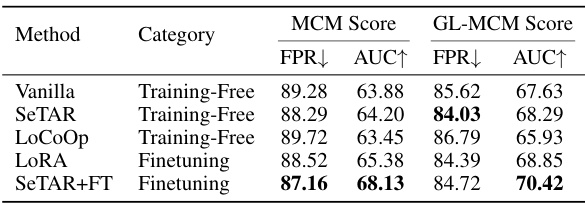
🔼 This table presents the results of an ablation study conducted to evaluate the impact of different modalities (vision, text, and vision+text) on the performance of the SeTAR model for out-of-distribution (OOD) detection. The study uses two benchmark datasets, ImageNet1K and Pascal-VOC, and two scoring functions (MCM and GL-MCM) to measure performance using FPR and AUROC metrics.
read the caption
Table 3: Ablation study on modality.
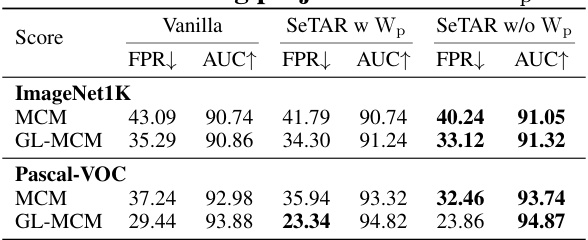
🔼 This table presents the training-free performance of SeTAR and compares it against existing zero-shot baselines (Vanilla MCM, Vanilla GL-MCM) on the ImageNet1k and Pascal-VOC datasets. The results are shown in terms of False Positive Rate at 95% True Positive Rate (FPR95) and Area Under the ROC Curve (AUROC). The table highlights SeTAR’s superior performance in reducing the false positive rate compared to the baselines without requiring any training.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.
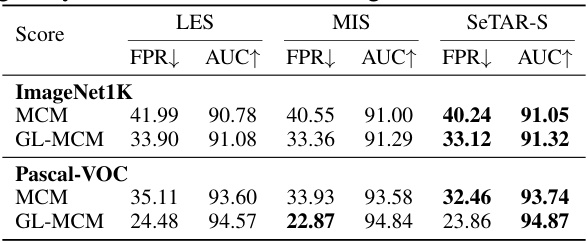
🔼 This table compares three different search algorithms used in the SeTAR model for OOD detection. The algorithms differ in how they traverse the layers of the image and text encoders in CLIP: LES (Layer-Exhaustive Search) checks all layers exhaustively, MIS (Modality-Interleaved Search) alternates between image and text layers, and SeTAR-S (the SeTAR search algorithm) searches the layers sequentially from top to bottom, image then text. The table shows the FPR (False Positive Rate) and AUROC (Area Under the Receiver Operating Characteristic curve) for each algorithm on ImageNet1k and Pascal-VOC datasets using both MCM and GL-MCM scores. SeTAR-S achieves the best overall performance.
read the caption
Table 5: Results for different search algorithms. Here LES, MIS and SeTAR-S stand for layer-exhaustive search, modality-interleave greedy search, and the search algorithm of SeTAR.
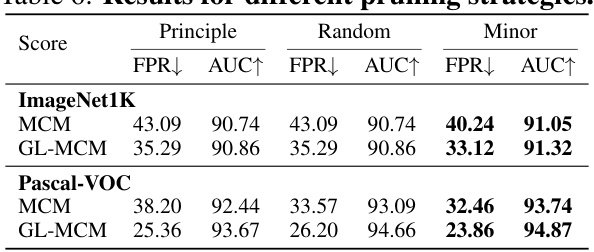
🔼 This table presents a comparison of SeTAR’s performance against two alternative pruning strategies: principal component pruning and random pruning. It shows the False Positive Rate (FPR) at 95% True Positive Rate (TPR) and the Area Under the Receiver Operating Characteristic Curve (AUROC) for both the MCM and GL-MCM scoring functions, on ImageNet1K and Pascal-VOC datasets. The results demonstrate that SeTAR’s strategy of selectively pruning minor singular components significantly outperforms both principal component pruning and random pruning.
read the caption
Table 6: Results for different pruning strategies. We use CLIP-B/16 as a backbone.
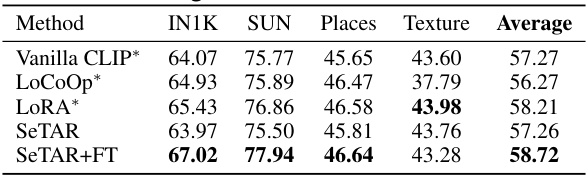
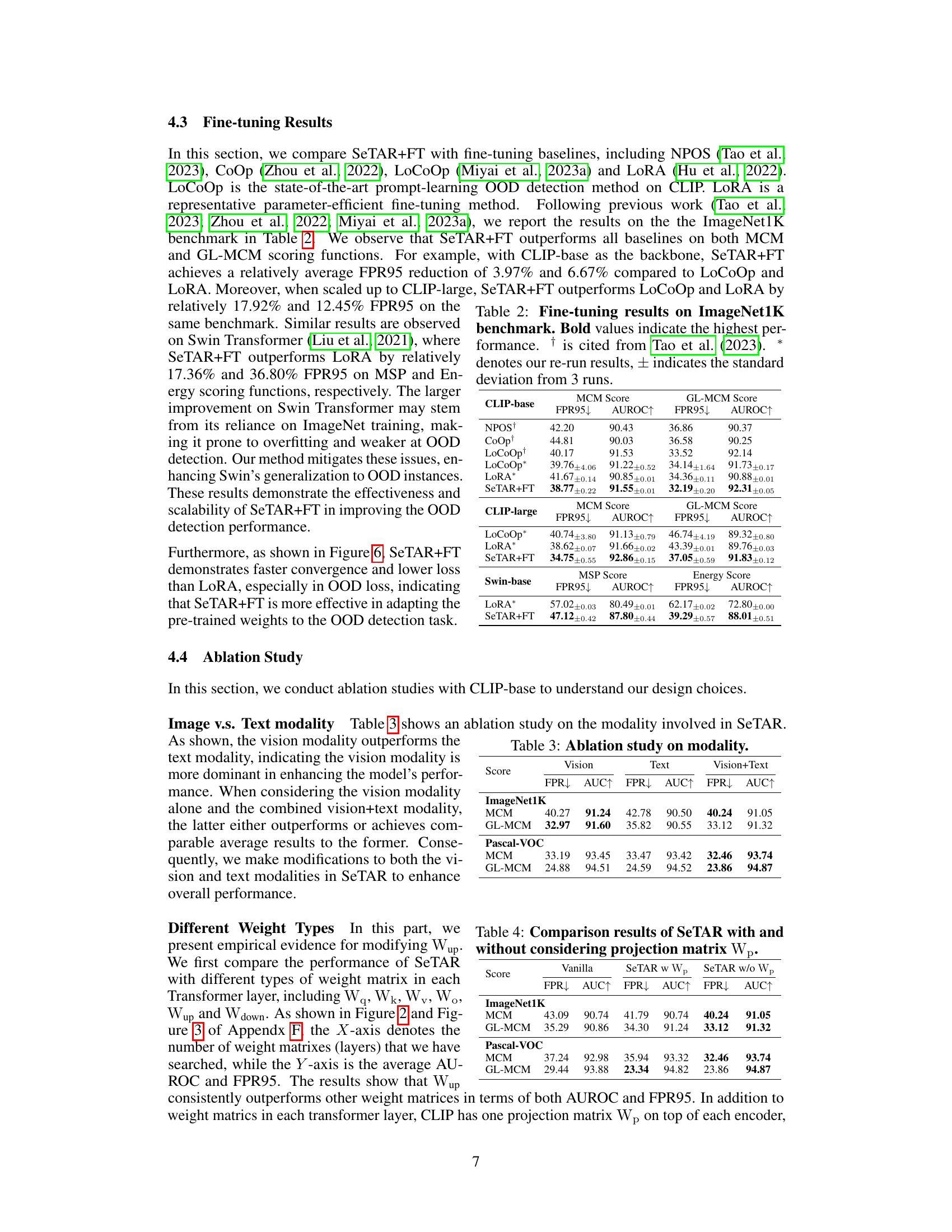
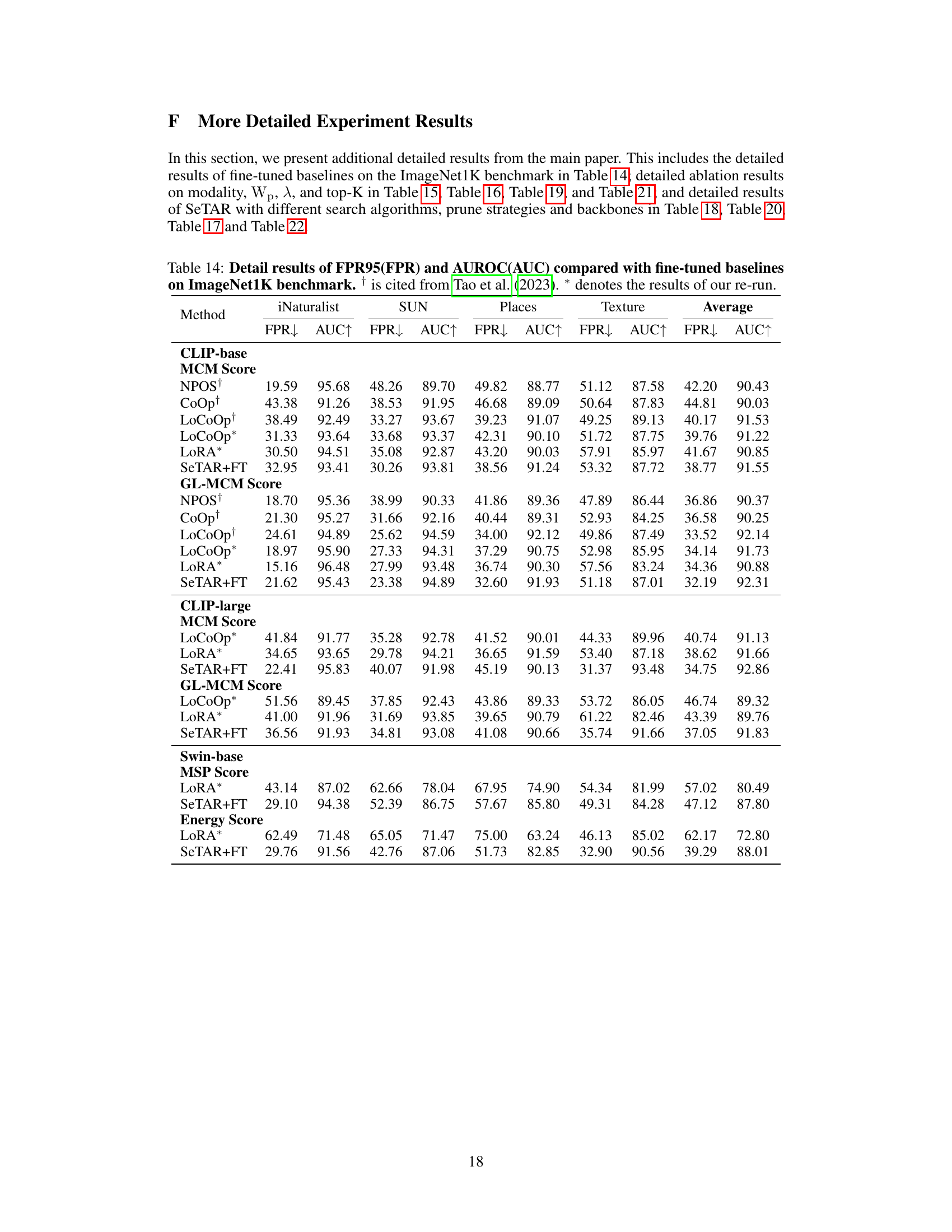
🔼 This table presents the image classification results obtained using different methods. The ImageNet1K dataset is used as the in-distribution (ID) dataset. The results from running the Vanilla CLIP model, as well as the LoCoOp and LoRA finetuning-based approaches are compared against the proposed SeTAR and SeTAR+FT methods. The average accuracy across multiple OOD datasets (SUN, Places, and Texture) is reported for each method. The results show that SeTAR+FT outperforms all baseline models. The ‘*’ indicates that the results are from re-running the experiments.
read the caption
Table 7: Image classification results with different methods. We use ImageNet1K (IN1K) as ID dataset. * denotes the results of our re-run. The results are averaged over 3 runs.
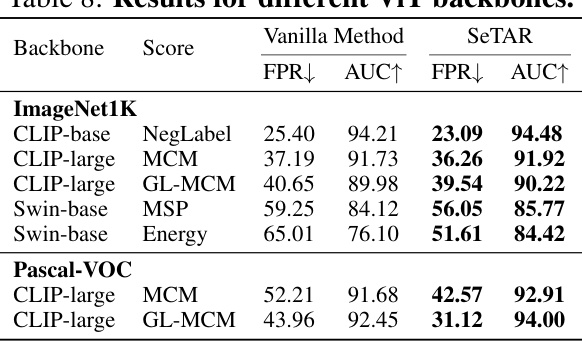
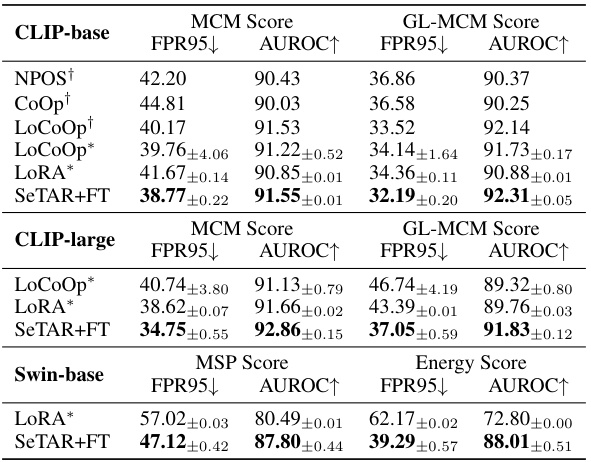
🔼 This table presents the training-free results of False Positive Rate at 95% true positive rate (FPR95) and Area Under the Receiver Operating Characteristic curve (AUROC) for out-of-distribution (OOD) detection on ImageNet1K and Pascal-VOC datasets using different Vision Transformer (ViT) backbones (CLIP-base, CLIP-large, and Swin-base) and various scoring functions (NegLabel, MCM, GL-MCM, MSP, and Energy). It compares the performance of the vanilla methods (without SeTAR) to the SeTAR method. Lower FPR95 and higher AUROC values indicate better performance.
read the caption
Table 8: Results for different ViT backbones.

🔼 This table presents the results of near-out-of-distribution (near-OOD) detection experiments using the CLIP-base model. It compares the performance of SeTAR and SeTAR+FT against several baseline methods on the task of identifying near-OOD samples, specifically using ImageNet1K as the in-distribution (ID) dataset and SSB-Hard as the near-OOD dataset. The metrics used are False Positive Rate (FPR) at a True Positive Rate (TPR) of 95% and Area Under the Receiver Operating Characteristic curve (AUROC). Lower FPR and higher AUROC values indicate better performance.
read the caption
Table 10: Near-OOD results on CLIP-base.
🔼 This table presents a comparison of the training-free out-of-distribution (OOD) detection performance of SeTAR against existing zero-shot baselines (Vanilla MCM, Vanilla GL-MCM) on two benchmark datasets (ImageNet1K and Pascal VOC). The results are evaluated using two metrics: False Positive Rate at 95% True Positive Rate (FPR95) and Area Under the Receiver Operating Characteristic curve (AUROC). Lower FPR95 and higher AUROC indicate better performance. The table highlights SeTAR’s superior performance in reducing the false positive rate compared to the baselines, demonstrating its effectiveness as a training-free OOD detection method.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.
🔼 This table presents the training-free performance of the proposed SeTAR model and compares it against several zero-shot baselines (Vanilla MCM, Vanilla GL-MCM) on two common OOD detection benchmarks (ImageNet1K and Pascal-VOC). The results are shown in terms of FPR95 (False Positive Rate at 95% True Positive Rate) and AUROC (Area Under the Receiver Operating Characteristic curve). Lower FPR95 and higher AUROC values are better. The table highlights the superior performance of SeTAR in reducing the false positive rate, particularly on the GL-MCM scoring metric, indicating its effectiveness in improving OOD detection without requiring any training.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.

🔼 This table presents the training-free performance of the proposed SeTAR model and compares it with several zero-shot baselines on two benchmark datasets, ImageNet1K and Pascal-VOC. The results are evaluated using two metrics: FPR95 (False Positive Rate at 95% True Positive Rate) and AUROC (Area Under the Receiver Operating Characteristic Curve). Lower FPR95 and higher AUROC values indicate better performance. The table shows that SeTAR consistently outperforms the baseline methods across various OOD datasets.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.

🔼 This table presents the training-free results of the proposed SeTAR method for out-of-distribution (OOD) detection. It compares SeTAR’s performance (measured by FPR95 and AUROC) against two zero-shot baselines (Vanilla MCM and Vanilla GL-MCM) on six different OOD datasets using the CLIP-base model. The table shows that SeTAR significantly outperforms the baselines, particularly in reducing the false positive rate (FPR95). The asterisk (*) indicates results obtained by rerunning the baselines, and the symbol ◇ denotes the absence of results reported in the cited paper. Note that standard deviations aren’t reported because the methods are training-free.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.
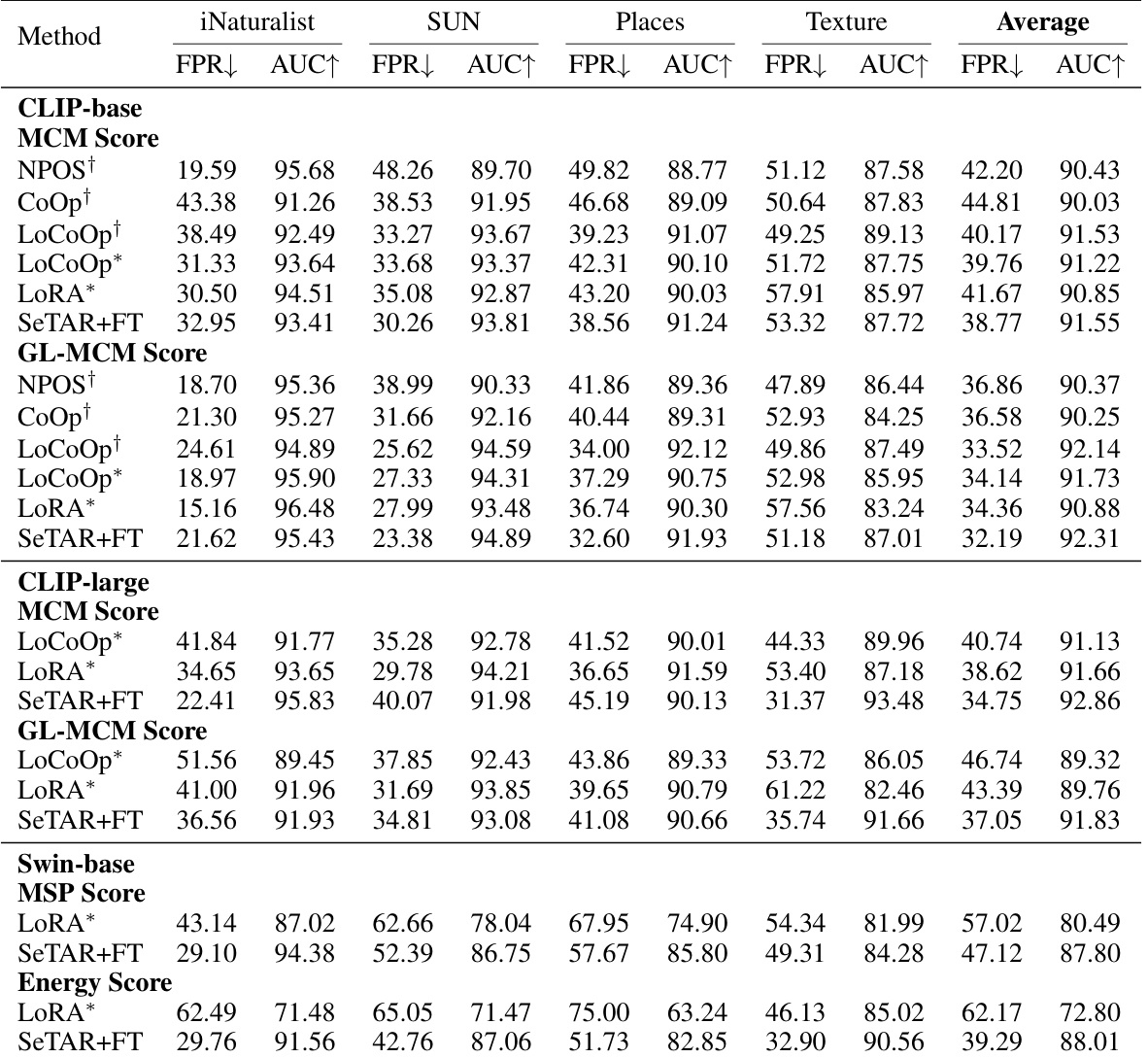
🔼 This table presents a comparison of the training-free performance of different OOD detection methods on two benchmark datasets (ImageNet1K and Pascal VOC). It compares the proposed SeTAR method against several zero-shot baselines (Vanilla MCM, Vanilla GL-MCM) across six OOD datasets. The results are shown in terms of FPR95 (false positive rate at 95% true positive rate) and AUROC (area under the receiver operating characteristic curve). The table highlights SeTAR’s superior performance in reducing false positives compared to existing methods. Note that standard deviations are not reported due to the training-free nature of the methods.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.
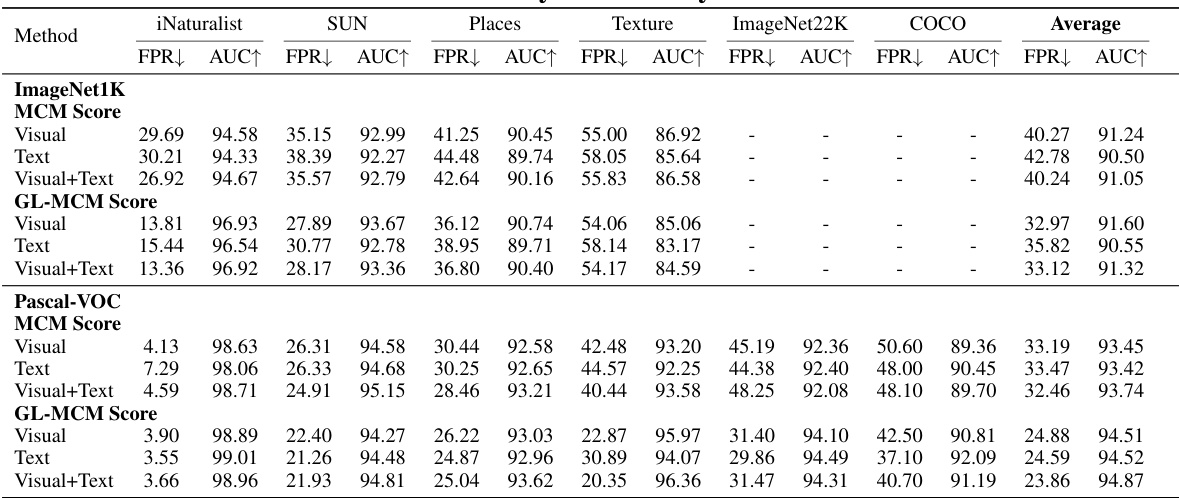
🔼 This table presents a comparison of the training-free performance of SeTAR against existing zero-shot baselines for out-of-distribution (OOD) detection using the CLIP model. The table shows the False Positive Rate at 95% True Positive Rate (FPR95) and the Area Under the Receiver Operating Characteristic curve (AUROC) for several OOD datasets and two different scoring functions (MCM and GL-MCM). The results demonstrate SeTAR’s superior performance in reducing false positives compared to the baseline methods. The absence of standard deviation is due to the training-free nature of the method.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.

🔼 This table presents a comparison of the training-free performance of SeTAR against existing zero-shot baselines (Vanilla MCM and Vanilla GL-MCM) on two common OOD detection benchmarks using the CLIP-ViT-B/16 model. The results are shown for both MCM and GL-MCM scoring functions and across various OOD datasets (iNaturalist, SUN, Places, Texture, ImageNet22K, and COCO). The metrics used are FPR95 (False Positive Rate at 95% True Positive Rate) and AUROC (Area Under the Receiver Operating Characteristic curve). Bold values indicate the best performance for each metric and dataset.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.

🔼 This table presents the training-free performance of SeTAR and several zero-shot baselines on two benchmark datasets (ImageNet1K and Pascal-VOC). The table compares the False Positive Rate at 95% True Positive Rate (FPR95) and the Area Under the Receiver Operating Characteristic curve (AUROC) for various Out-of-Distribution (OOD) datasets against different methods. Lower FPR95 and higher AUROC values indicate better performance. The results demonstrate SeTAR’s superior performance compared to the zero-shot baselines, particularly in reducing the false positive rate.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.

🔼 This table presents the training-free performance of the proposed SeTAR method and compares it to several zero-shot baselines on two benchmark datasets (ImageNet1K and Pascal-VOC). The metrics used are False Positive Rate at 95% True Positive Rate (FPR95) and Area Under the Receiver Operating Characteristic curve (AUROC). Lower FPR95 values and higher AUROC values indicate better performance. The table shows that SeTAR consistently outperforms the zero-shot baselines across various OOD datasets for both MCM and GL-MCM scoring functions. The asterisk (*) indicates re-run results and the dagger (†) indicates results cited from Miyai et al (2023b).
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.

🔼 This table presents the training-free performance of SeTAR and compares it against several zero-shot baselines on the CLIP-base model for out-of-distribution (OOD) detection. The results are shown for various metrics (FPR95 and AUROC) and across different OOD datasets (iNaturalist, SUN, Places, Texture, ImageNet22K, COCO). The table highlights SeTAR’s superior performance in reducing the false positive rate and improving the overall accuracy compared to existing zero-shot methods.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.

🔼 This table presents the training-free performance of the proposed SeTAR model on out-of-distribution (OOD) detection tasks, compared to existing zero-shot baselines. The results are shown for different OOD datasets (iNaturalist, SUN, Places, Texture, ImageNet22K, COCO) and using two metrics: FPR95 (False Positive Rate at 95% True Positive Rate) and AUROC (Area Under the Receiver Operating Characteristic curve). Lower FPR95 and higher AUROC values indicate better performance. The table highlights that SeTAR consistently achieves superior results, reducing the false positive rate significantly compared to existing methods. The absence of standard deviation is due to the method being training free.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.

🔼 This table presents the training-free performance of SeTAR and several baseline methods on the ImageNet1K and Pascal-VOC datasets. The metrics used are FPR95 (False Positive Rate at 95% True Positive Rate) and AUROC (Area Under the Receiver Operating Characteristic curve). Lower FPR95 values and higher AUROC values indicate better performance. The table compares SeTAR’s performance to two zero-shot baselines (MCM and GL-MCM) and their variations with and without the use of a star (*) denoting re-run results to ensure consistency. The results are categorized by the OOD datasets used for evaluation and the scoring function used (MCM or GL-MCM), providing a comprehensive view of SeTAR’s effectiveness across different tasks and scenarios. The symbol ◇ indicates when results were not available in the original paper. The absence of standard deviations is explicitly noted because the methods used are training-free.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.

🔼 This table presents the training-free performance of the proposed SeTAR model compared to existing zero-shot baselines (MCM and GL-MCM) on two benchmark datasets (ImageNet1K and Pascal-VOC). The results are reported in terms of FPR95 (false positive rate at 95% true positive rate) and AUROC (area under the receiver operating characteristic curve), which are common metrics for evaluating the performance of OOD detection methods. The table highlights the improvement achieved by SeTAR over the baselines, showcasing its effectiveness in reducing false positives without the need for any training.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.
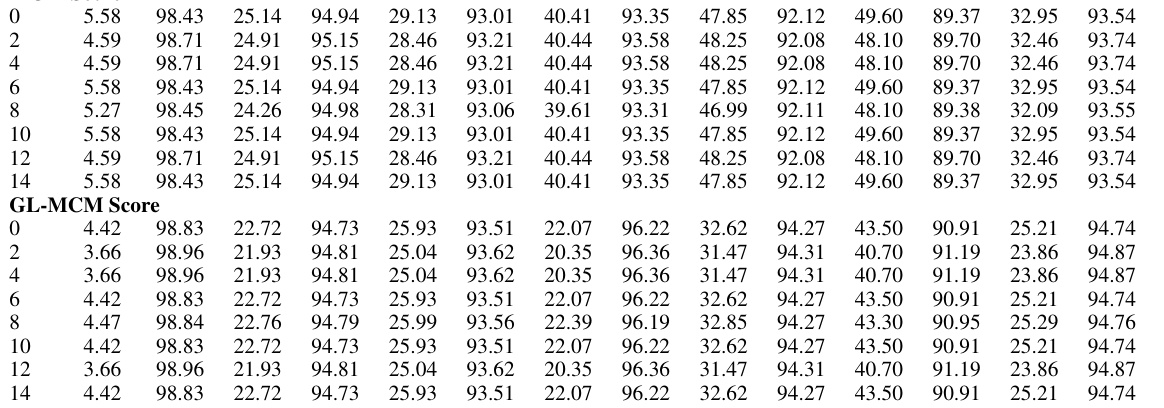
🔼 This table presents the training-free performance of the proposed SeTAR model and several zero-shot baselines on the ImageNet1K and Pascal-VOC datasets. The metrics used are FPR95 (False Positive Rate at 95% True Positive Rate) and AUROC (Area Under the Receiver Operating Characteristic Curve). Lower FPR95 and higher AUROC values indicate better performance. The table compares SeTAR’s performance to vanilla MCM and GL-MCM methods, showing improvements in both metrics.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.

🔼 This table presents the training-free performance of the proposed SeTAR method on the ImageNet1K and Pascal-VOC datasets for OOD detection. It compares SeTAR’s performance against several zero-shot baselines (Vanilla MCM, Vanilla GL-MCM) using different scoring functions (MCM and GL-MCM). The table shows the False Positive Rate at 95% True Positive Rate (FPR95) and the Area Under the Receiver Operating Characteristic curve (AUROC) for various OOD datasets (iNaturalist, SUN, Places, Texture, ImageNet22K, COCO). Bold values indicate the best performance achieved by SeTAR.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.
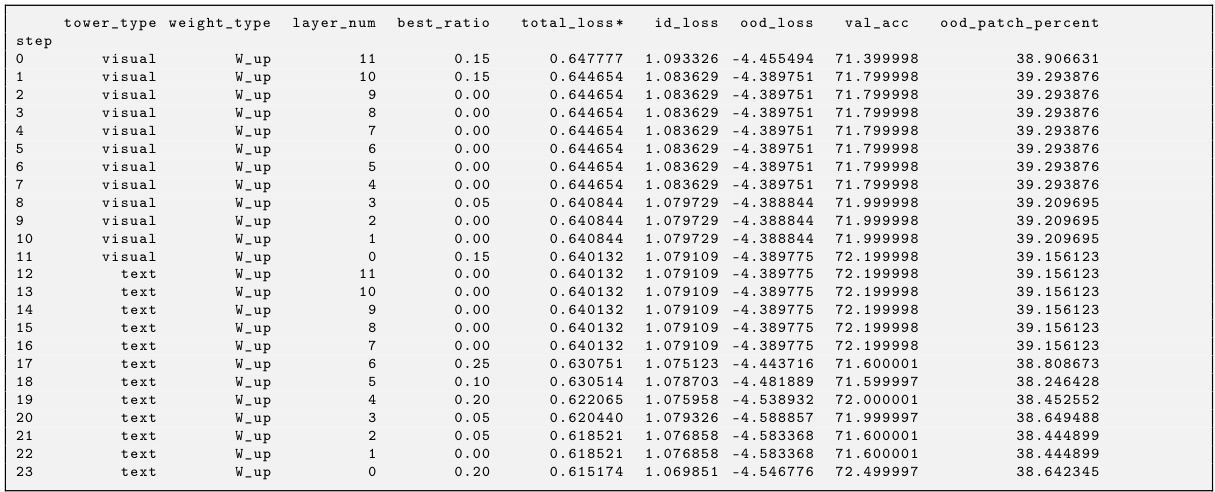
🔼 This table presents the training-free performance of the proposed SeTAR model and several zero-shot baselines on CLIP-based OOD detection tasks. The results are compared using two metrics: FPR95 (false positive rate at 95% true positive rate) and AUROC (area under the receiver operating characteristic curve). Lower FPR95 and higher AUROC values indicate better performance. The table shows that SeTAR outperforms the zero-shot baselines on both ImageNet1K and Pascal-VOC datasets across multiple OOD datasets. Results are shown without standard deviation because no training is involved.
read the caption
Table 1: Training-free results of FPR95(FPR) and AUROC(AUC) compared to zero-shot baselines on CLIP-base. Bold values represent the highest performance. † is cited from Miyai et al. (2023b), where ◇ represents the absence of reporting in the paper. * denotes the result of our re-run. denotes the OOD dataset has overlapping categories with the ID dataset. We do not report standard deviations since no training is involved.
Full paper#