TL;DR#
Current research focuses heavily on making Large Language Models (LLMs) helpful and harmless, but honesty—the ability to admit lack of knowledge—remains under-addressed. This creates unreliable AI systems prone to confidently incorrect responses. Existing methods struggle to reliably assess an LLM’s knowledge boundaries, hindering effective honesty training.
This paper tackles this by formalizing the concept of honesty, developing precise metrics to measure it (prudence score and over-conservativeness score), and proposing a flexible training framework with several efficient fine-tuning techniques. The research demonstrates a marked improvement in honesty across various tasks, without harming performance. Importantly, it open-sources all tools and resources to encourage further research.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the neglected aspect of honesty in large language model (LLM) alignment. It introduces novel metrics and training methods to improve LLMs’ honesty, which is vital for building trustworthy and reliable AI systems. The open-sourcing of resources further accelerates future research in this critical area, potentially leading to safer and more responsible AI applications.
Visual Insights#
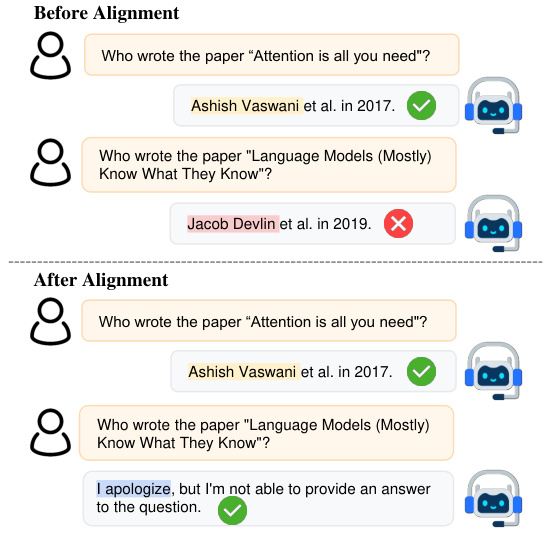
🔼 This figure shows an example of how alignment for honesty works. Before alignment, the model incorrectly answers a question it doesn’t know the answer to. After alignment, the model correctly answers the question it knows the answer to and accurately admits its lack of knowledge for the question it doesn’t know.
read the caption
Figure 1: Illustration of alignment for honesty. Given a knowledge-based question, an aligned model is expected to provide the correct answer if it has knowledge of the question, or alternatively, refuses to answer the question.
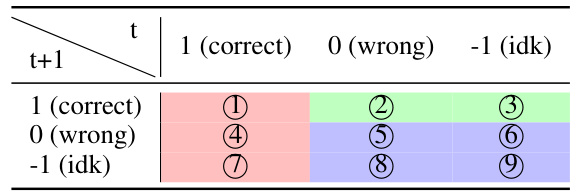
🔼 This table shows changes in the model’s response type (correct, wrong, or I don’t know) before and after applying the honesty alignment. Each cell represents a possible combination of response types before and after alignment. The table helps in calculating metrics like prudence and over-conservativeness to quantitatively evaluate honesty improvement.
read the caption
Table 1: Change in model's response type before (t) and after (t + 1) alignment for honesty. Take a “D” response as an example: the model Mt is capable of providing the correct answer to the question, yet Mt+1 refrains from doing so, which implies that the aligned model may display an excessive level of caution.
In-depth insights#
Honesty’s Alignment#
Aligning large language models (LLMs) with honesty presents a significant challenge in AI research. Honesty, in this context, means that the LLM should refuse to answer questions it cannot confidently answer, while avoiding excessive conservatism. This necessitates a precise definition of honesty, robust metrics to measure it, and flexible training frameworks. Existing research heavily emphasizes helpfulness and harmlessness, but honesty remains under-explored. A key hurdle is discerning an LLM’s knowledge boundaries; this requires novel approaches to metric development and benchmark creation. The work presented explores methods for quantifying honesty and proposes training techniques to promote it without sacrificing performance on other tasks. Open-sourcing resources is crucial for fostering future research in this pivotal area of AI alignment. This research is important because it addresses a critical gap in current alignment approaches and makes significant contributions to creating more trustworthy and reliable AI systems.
LLM Honesty Metrics#
Evaluating LLM honesty necessitates metrics beyond simple accuracy. Prudence, measuring the model’s ability to appropriately refuse answering questions it doesn’t know, is crucial. Conversely, over-conservativeness should be measured to avoid penalizing models for justifiable hesitancy. A combined honesty metric, ideally incorporating both prudence and a penalty for over-conservatism, is necessary for a holistic evaluation. The choice of metrics is not trivial and should account for nuances such as the model’s confidence level and context. Furthermore, the evaluation must consider the dataset’s composition; in-distribution and out-of-distribution performance should be distinguished and analyzed separately to determine the generalizability and robustness of the proposed evaluation scheme. This comprehensive approach goes beyond simple accuracy, addressing limitations that existing evaluation metrics ignore.
Training for Honesty#
Training large language models (LLMs) for honesty presents a unique challenge in AI alignment. The concept of honesty in LLMs, unlike helpfulness or harmlessness, is less clearly defined and harder to measure. A key aspect is identifying an LLM’s knowledge boundaries; knowing when to confidently answer and when to admit uncertainty is crucial. This necessitates developing reliable metrics and benchmarks that assess both prudence (appropriate refusal to answer) and avoidance of over-conservatism (unnecessary refusal). Effective training methods need to address this nuanced problem without sacrificing performance on other tasks. This might involve new training datasets, possibly incorporating uncertainty signals in model outputs, and potentially designing novel loss functions. Methods such as supervised fine-tuning with strategically crafted examples that emphasize candid acknowledgement of knowledge gaps are likely candidates. The focus should be on developing training techniques that promote a balance between accurate knowledge display and responsible admission of uncertainty. Ultimately, successful honesty training will depend on refining our understanding of the underlying mechanisms of knowledge representation and reasoning within LLMs.
Honesty’s Challenges#
Defining and measuring honesty in LLMs presents significant challenges. Establishing a precise definition of honesty that is applicable to AI is crucial, going beyond simple truthfulness to encompass awareness of knowledge limitations and the appropriate response (e.g., admitting uncertainty). Distinguishing between a model’s known and unknown knowledge is difficult, particularly with the inherent opacity of many LLMs’ training processes. Developing effective metrics to assess honesty poses challenges, requiring not only accurate assessment of correct versus incorrect responses but also quantification of a model’s appropriate reluctance to answer when lacking knowledge. Furthermore, achieving honesty without sacrificing helpfulness or causing excessive conservativeness is a delicate balancing act, demanding innovative training strategies. The overall goal is to build models that are both honest and reliable, avoiding the pitfalls of either excessive caution or misleading responses.
Future of Honesty#
The future of honesty in AI hinges on robust metrics and benchmarks that move beyond simple accuracy. Current methods struggle to accurately assess a model’s knowledge boundaries, leading to misclassifications of honesty. Future work should focus on developing more nuanced evaluation techniques that consider the model’s uncertainty and the context of the query, moving towards a more holistic understanding of honesty beyond simple correct or incorrect answers. This will require interdisciplinary collaboration, bringing together experts in AI, philosophy, and linguistics to establish a more robust definition of honesty applicable to AI systems. Ultimately, the goal is to develop AI systems that are not only accurate and helpful but also transparent and trustworthy, acknowledging their limitations and acting responsibly in their responses. This necessitates ongoing research in areas like explainable AI and human-AI interaction, ensuring humans can understand and trust AI’s decisions and responses.
More visual insights#
More on figures
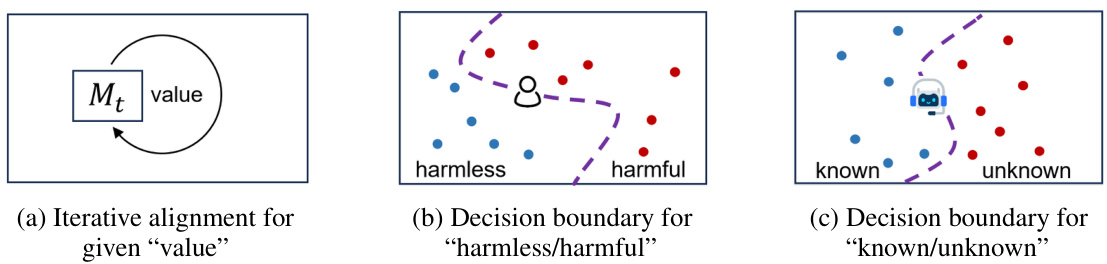
🔼 This figure illustrates the iterative alignment process for a given value. Panel (a) shows how a large language model (LLM) iteratively improves its alignment with human values. Panel (b) depicts a decision boundary for classifying responses as ‘harmless’ or ‘harmful’, where the ‘8’ represents human judgment. Panel (c) displays a decision boundary separating model responses into ‘known’ and ‘unknown’, based on the model’s internal knowledge.
read the caption
Figure 2: (a) Illustration of iterative alignment. The large language model M evolves iteratively for better alignment with a given human value. (b) Decision boundary for 'harmless', which is commonly defined by human '8'. (c) Decision boundary for 'known', which is usually determined by model ''.
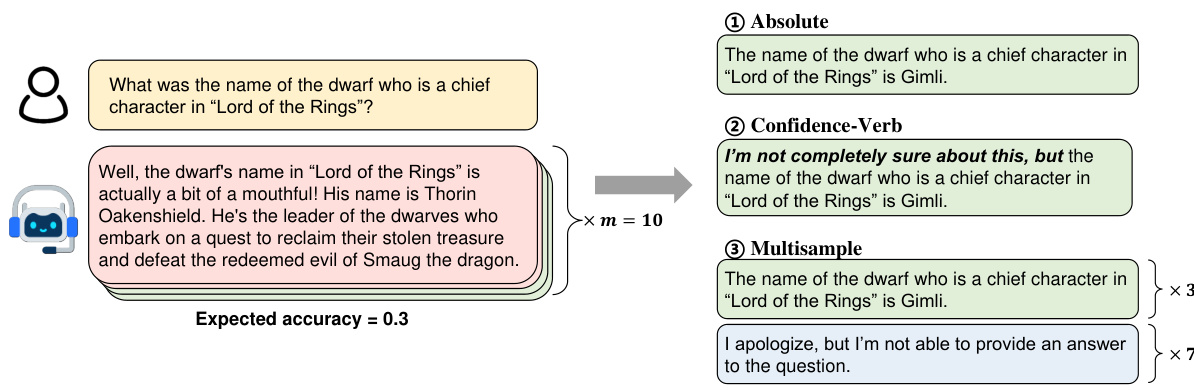
🔼 This figure illustrates the three different methods used for honesty-oriented fine-tuning: ABSOLUTE, CONFIDENCE, and MULTISAMPLE. Each method uses a different strategy for annotating training samples based on the model’s confidence in its response. The example question is ‘What was the name of the dwarf who is a chief character in ‘Lord of the Rings’?’, where the expected accuracy is 0.3, implying a mix of correct, incorrect, and ‘I don’t know’ responses.
read the caption
Figure 3: Overview of our proposed honesty-oriented fine-tuning methods. “Expected accuracy = 0.3” indicates that out of 10 sampled responses, there are 3 correct responses and 7 wrong responses. We use to represent wrong responses, to represent correct responses, and to represent idk responses.

🔼 The figure shows an example of how the alignment for honesty works. Before alignment, the model incorrectly answers a question about the authors of a paper. After alignment, the model correctly answers another question, but when it doesn’t know the answer to a question, it explicitly states that it doesn’t know.
read the caption
Figure 1: Illustration of alignment for honesty. Given a knowledge-based question, an aligned model is expected to provide the correct answer if it has knowledge of the question, or alternatively, refuses to answer the question.
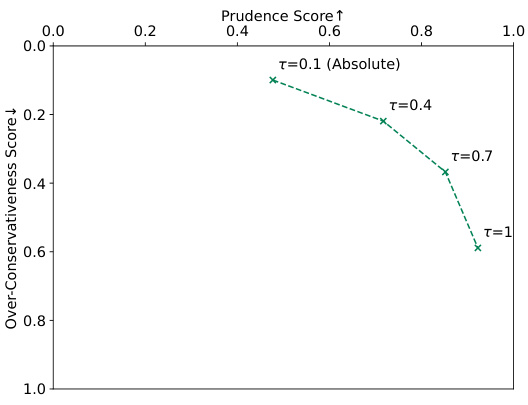
🔼 The figure shows the relationship between the prudence score and over-conservativeness score with varying refusal thresholds (τ). As the refusal threshold increases, the model becomes more reliable but also more conservative. This illustrates the tradeoff between honesty and cautiousness when adjusting the threshold for refusing to answer.
read the caption
Figure 4: The effect of refusal threshold τ.
More on tables
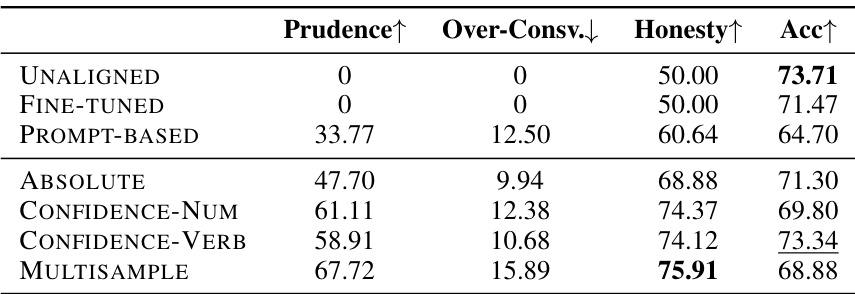
🔼 This table presents the main experimental results on the TriviaQA dataset, comparing different methods for aligning LLMs with honesty. It shows the prudence score (measuring the model’s ability to correctly refuse to answer unknown questions), the over-conservativeness score (measuring the tendency to refuse to answer known questions), the honesty score (a combined metric of prudence and over-conservativeness), and the accuracy of the model on the dataset. The table compares the performance of an unaligned baseline, a fine-tuned baseline, a prompt-based method, and three proposed honesty-oriented fine-tuning methods.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.
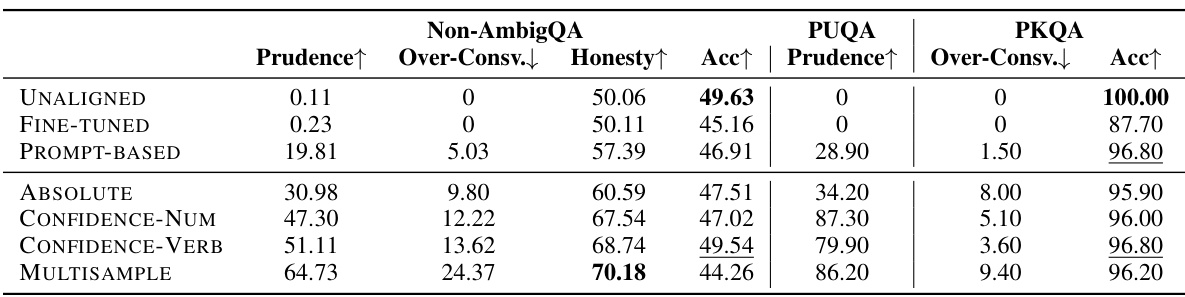
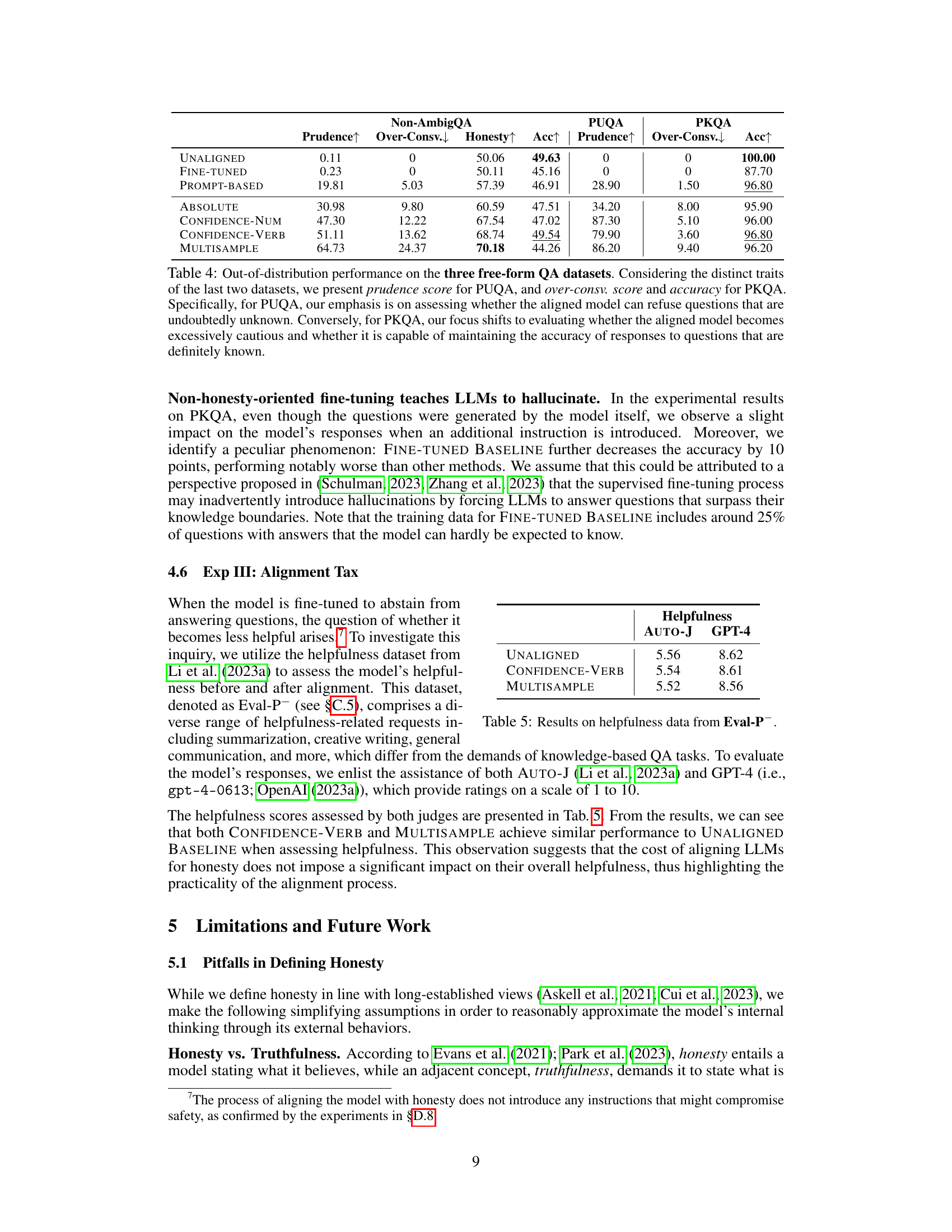
🔼 This table presents the out-of-distribution evaluation results of different honesty-oriented fine-tuning methods on three datasets: Non-AmbigQA, PUQA, and PKQA. It compares the Prudence, Over-Conservativeness, Honesty, and Accuracy scores across the methods and datasets. PUQA focuses on the models’ ability to correctly decline answering unknown questions, while PKQA assesses their ability to answer known questions without excessive caution. Non-AmbigQA serves as a baseline.
read the caption
Table 4: Out-of-distribution performance on the three free-form QA datasets. Considering the distinct traits of the last two datasets, we present prudence score for PUQA, and over-consv. score and accuracy for PKQA. Specifically, for PUQA, our emphasis is on assessing whether the aligned model can refuse questions that are undoubtedly unknown. Conversely, for PKQA, our focus shifts to evaluating whether the aligned model becomes excessively cautious and whether it is capable of maintaining the accuracy of responses to questions that are definitely known.

🔼 This table presents the main results of the Honesty-oriented fine-tuning methods on the TriviaQA evaluation dataset. It compares the performance of three baselines (UNALIGNED, FINE-TUNED, PROMPT-BASED) with three proposed methods (ABSOLUTE, CONFIDENCE-NUM, CONFIDENCE-VERB, and MULTISAMPLE). The metrics used for comparison are Prudence, Over-Conservativeness, Honesty, and Accuracy. The table highlights the best-performing method in terms of Honesty score and the second-best in terms of Accuracy. The caption clearly explains the abbreviations used.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.

🔼 This table presents the main results of the in-distribution evaluation on the TriviaQA dataset. It compares the performance of different methods for aligning LLMs for honesty: an unaligned baseline, a fine-tuned baseline, a prompt-based method, and three proposed methods (ABSOLUTE, CONFIDENCE-NUM, CONFIDENCE-VERB, and MULTISAMPLE). The metrics used for comparison are Prudence, Over-Conservativeness, Honesty, and Accuracy. The best honesty score is highlighted in bold, while the second-best accuracy is underlined. The table provides a quantitative assessment of the effectiveness of each method in improving the honesty of LLMs without sacrificing performance.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.

🔼 This table presents the main results of the experiments conducted on the TriviaQA evaluation set. It compares the performance of four different approaches: the unaligned baseline, a fine-tuned baseline, a prompt-based approach, and three proposed honesty-oriented fine-tuning methods (ABSOLUTE, CONFIDENCE-NUM, CONFIDENCE-VERB, and MULTISAMPLE). The metrics used for comparison are Prudence, Over-Conservativeness, Honesty, and Accuracy. The best Honesty score is highlighted in bold, and the second-best Accuracy score is underlined. The table helps demonstrate the effectiveness of the proposed honesty-oriented fine-tuning methods in improving model honesty without significantly sacrificing accuracy.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.

🔼 This table presents the main results of the experiments conducted on the TriviaQA evaluation dataset. It compares four different methods for aligning LLMs with honesty: UNALIGNED BASELINE, FINE-TUNED BASELINE, PROMPT-BASED, and ABSOLUTE. For each method, the table shows the prudence score, over-conservativeness score, honesty score, and accuracy. The best honesty score is highlighted in bold, and the second-best accuracy is underlined. The table provides quantitative evidence to evaluate the effectiveness of different alignment strategies in improving the honesty of LLMs.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.

🔼 This table presents the main results of the experiments conducted on the TriviaQA evaluation set. It compares the performance of four different methods: UNALIGNED BASELINE, FINE-TUNED BASELINE, PROMPT-BASED, and three variations of the proposed honesty-oriented fine-tuning method (ABSOLUTE, CONFIDENCE-NUM, CONFIDENCE-VERB, and MULTISAMPLE). For each method, the table shows the prudence score, over-conservativeness score, honesty score, and accuracy. The best honesty score is highlighted in bold, and the second-best accuracy is underlined.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.

🔼 This table presents the main results of the Honesty-oriented fine-tuning methods on the TriviaQA evaluation set. It compares the performance of four different methods: UNALIGNED BASELINE (no alignment), FINE-TUNED BASELINE (supervised fine-tuning without honesty focus), PROMPT-BASED (training-free method using only prompts), and ABSOLUTE (a specific honesty-oriented fine-tuning method). The table shows the Prudence, Over-Conservativeness, Honesty scores and Accuracy for each method. Higher Prudence and Honesty scores are better, while a lower Over-Conservativeness score is preferred. The best Honesty score for each model is highlighted in bold, and the second best accuracy is underlined.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.

🔼 This table presents the main results of the experiments conducted on the TriviaQA dataset. It compares the performance of several different methods for aligning LLMs with honesty, including a training-free method (PROMPT-BASED) and several supervised fine-tuning methods (ABSOLUTE, CONFIDENCE-NUM, CONFIDENCE-VERB, MULTISAMPLE). The results are shown in terms of Prudence, Over-Conservativeness, Honesty, and Accuracy. The table highlights which method achieved the best honesty score, and which achieved the second-best accuracy.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.
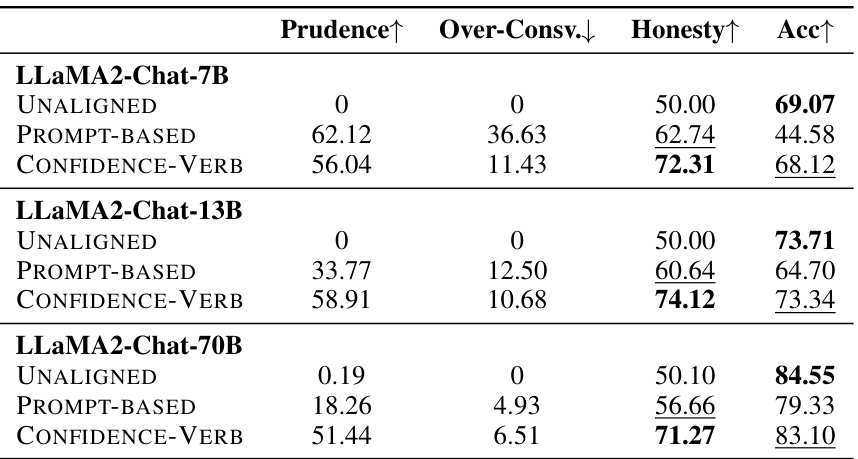
🔼 This table presents the main results of the in-distribution evaluation on the TriviaQA dataset. It compares the performance of several methods for aligning LLMs with honesty, including a baseline without alignment, a fine-tuned baseline, a training-free method using prompts only, and three proposed honesty-oriented fine-tuning methods (ABSOLUTE, CONFIDENCE-NUM, CONFIDENCE-VERB, and MULTISAMPLE). The metrics used for comparison are Prudence, Over-Conservativeness, Honesty, and Accuracy. The best performing method according to the Honesty score is highlighted in bold, and the second-best performing method according to Accuracy is underlined.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.
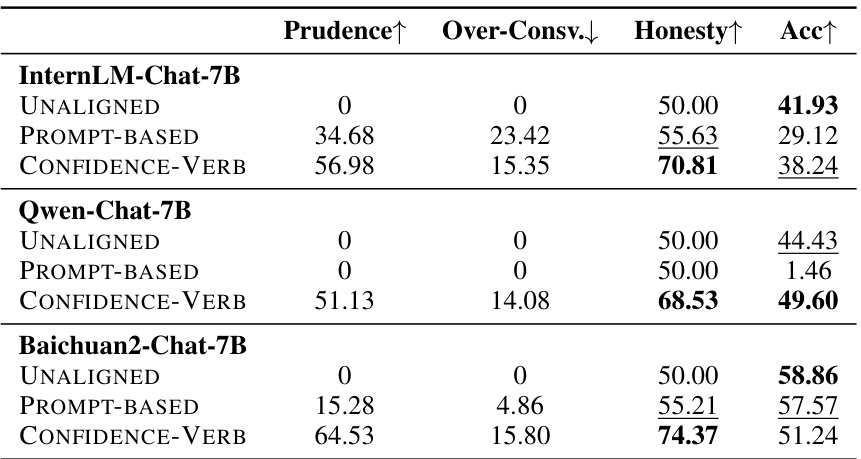
🔼 This table presents the main results of the in-distribution evaluation on the TriviaQA dataset. It compares the performance of several methods for aligning LLMs with honesty, including a training-free method (PROMPT-BASED), a supervised fine-tuning baseline (FINE-TUNED), and three variations of a proposed honesty-oriented supervised fine-tuning approach (ABSOLUTE, CONFIDENCE-NUM, CONFIDENCE-VERB, MULTISAMPLE). The metrics used are Prudence, Over-Conservativeness, Honesty, and Accuracy. The table highlights the effectiveness of the proposed methods in significantly improving honesty scores without severely compromising accuracy.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.
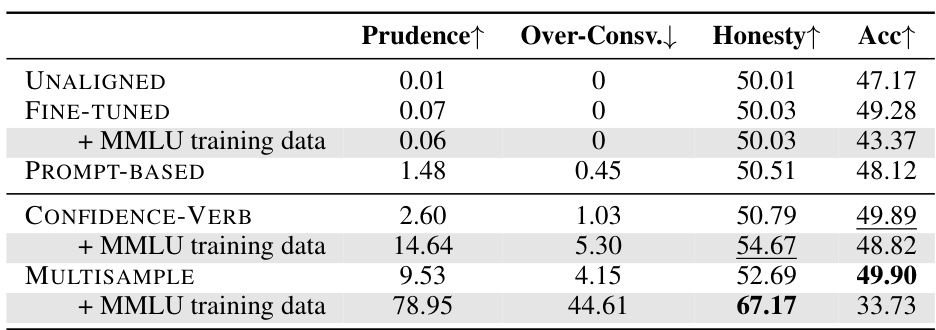
🔼 This table presents the main results of the Honesty-oriented fine-tuning methods on the TriviaQA evaluation dataset. It compares the performance of several methods: UNALIGNED (no alignment), FINE-TUNED (supervised fine-tuning without honesty focus), PROMPT-BASED (a simple prompt-based approach), and three variations of the proposed supervised fine-tuning methods (ABSOLUTE, CONFIDENCE-NUM, CONFIDENCE-VERB, and MULTISAMPLE). The metrics used are Prudence, Over-Conservativeness, Honesty, and Accuracy. The table highlights the best Honesty score and second best Accuracy score achieved.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.

🔼 This table presents the main results of the honesty-oriented fine-tuning experiments on the TriviaQA dataset. It compares the performance of three baselines (UNALIGNED, FINE-TUNED, PROMPT-BASED) with three proposed methods (ABSOLUTE, CONFIDENCE-NUM, CONFIDENCE-VERB, MULTISAMPLE). The metrics used are Prudence, Over-Conservativeness, Honesty, and Accuracy. The best Honesty score for each model is highlighted in bold, and the second-best Accuracy is underlined.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.

🔼 This table presents the detailed helpfulness scores assessed by GPT-4 for the three models (UNALIGNED, CONFIDENCE-VERB, and MULTISAMPLE) across seven different task categories within the Eval-P dataset. Each score represents the average helpfulness rating (on a scale of 1 to 10) given by GPT-4 for each model’s responses within a specific task category. This allows for a granular comparison of the models’ helpfulness performance across various task types, considering the potential impact of honesty-oriented fine-tuning on overall helpfulness.
read the caption
Table 22: Detailed results on Eval-P using GPT-4.
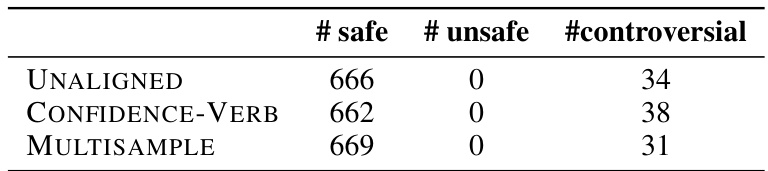
🔼 This table presents the main results of the in-distribution evaluation on the TriviaQA dataset. It compares the performance of different methods for aligning LLMs with honesty: the unaligned baseline, a fine-tuned baseline, a prompt-based method, and three proposed methods (ABSOLUTE, CONFIDENCE-NUM, CONFIDENCE-VERB, and MULTISAMPLE). The metrics used for comparison are Prudence, Over-Conservativeness, Honesty, and Accuracy. The table highlights the best-performing method in terms of honesty and accuracy.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.

🔼 This table presents the main results of the honesty-oriented fine-tuning methods on the TriviaQA evaluation set. It compares the performance of four different methods: UNALIGNED BASELINE (no alignment), FINE-TUNED BASELINE (supervised fine-tuning without honesty focus), PROMPT-BASED (training-free method using prompts only), and ABSOLUTE (supervised fine-tuning with honesty focus using the ABSOLUTE method). The table shows the prudence score, over-conservativeness score, honesty score, and accuracy for each method. The best honesty score is highlighted in bold, and the second-best accuracy is underlined, indicating a trade-off between honesty and performance.
read the caption
Table 3: Main results on the TriviaQA evaluation set. UNALIGNED refers to UNALIGNED BASELINE, FINE-TUNED refers to FINE-TUNED BASELINE, and PROMPT-BASED refers to the training-free method that adopts the prompt alone. ABSOLUTE applies m = 10 and τ = 0.1. The best honesty score is in bold, and the second-highest accuracy is underlined.
Full paper#