TL;DR#
Pre-trained language models (PLMs) have shown impressive capabilities, but their performance is not solely determined by scale. Existing research primarily focuses on scaling up models, ignoring the significant influence of architecture. A notable issue is the decline in base capabilities observed in certain architectures like FFN-Wider Transformers, despite comparable pre-training performance to standard models. This highlights a gap in our understanding of how architecture impacts PLMs’ effectiveness.
This paper investigates the architectural influence on PLMs’ base capabilities. It introduces a novel Combination Enhanced Architecture (CEA) designed to address the performance drop in FFN-Wider Transformers. By analyzing the contribution ratio of different layers, the researchers identified Multi-Head Attention (MHA) as a critical component affecting base capabilities. CEA successfully improves the base capabilities by enhancing the MHA layer’s contribution. Moreover, the effectiveness of CEA is demonstrated by applying it to Mixture of Experts (MoE) transformers, showing substantial performance improvements. This work provides critical insights into architectural design for PLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it identifies a previously overlooked architectural factor affecting the base capabilities of pre-trained language models. It challenges the prevalent focus on scaling and offers a novel architectural enhancement (CEA) to improve model performance, providing valuable insights for researchers to design more efficient and effective models. Its application to MoE Transformers showcases its broader significance and opens new avenues for architectural improvement.
Visual Insights#
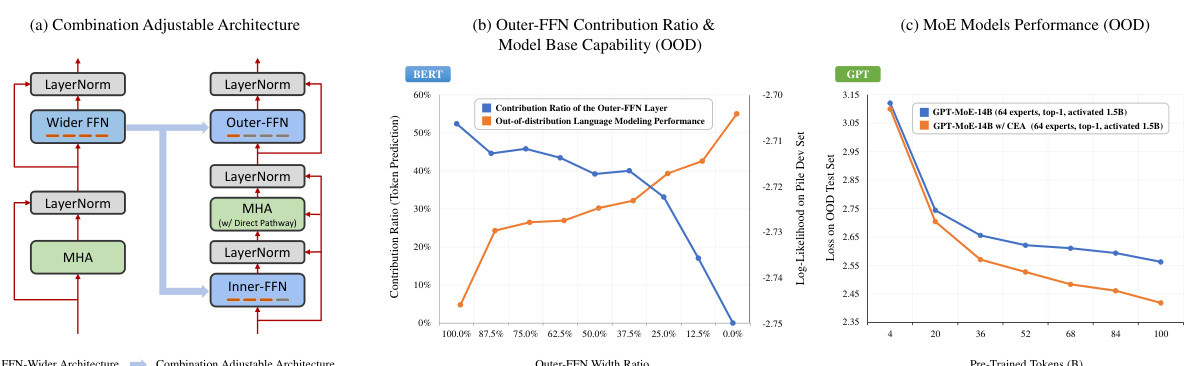
🔼 This figure illustrates the relationship between the contribution ratio of the Outer-FFN and MHA layers in a transformer model and its base capabilities. The left panel shows the Combination Adjustable Architecture (CAA), a modified transformer architecture used in the experiments. The middle panel (b) shows that as the contribution ratio of the Outer-FFN layer decreases (meaning the contribution ratio of the MHA layer increases), there’s a corresponding increase in model base capability, as measured by out-of-distribution language modeling performance. The right panel (c) demonstrates the effectiveness of the Combination Enhanced Architecture (CEA) on a Mixture of Experts (MoE) Transformer model, showing improved base capabilities compared to the standard MoE model.
read the caption
Figure 1: Illustration showing that: 1) the synchronous improvement in model base capability as the contribution ratio of the Outer-FFN layer (a transformation function) decreases, that is, the contribution ratio of the MHA layer (a combination function) increases. This reveals a key factor affecting model's base capabilities. 2) Combination Enhanced Architecture (CEA) was designed based on this factor and applied to MoE models, resulting in an improvement in base capability.
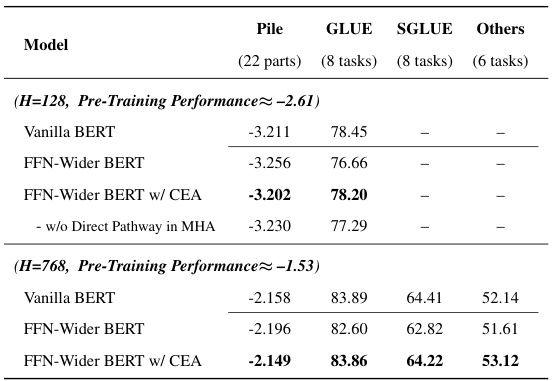
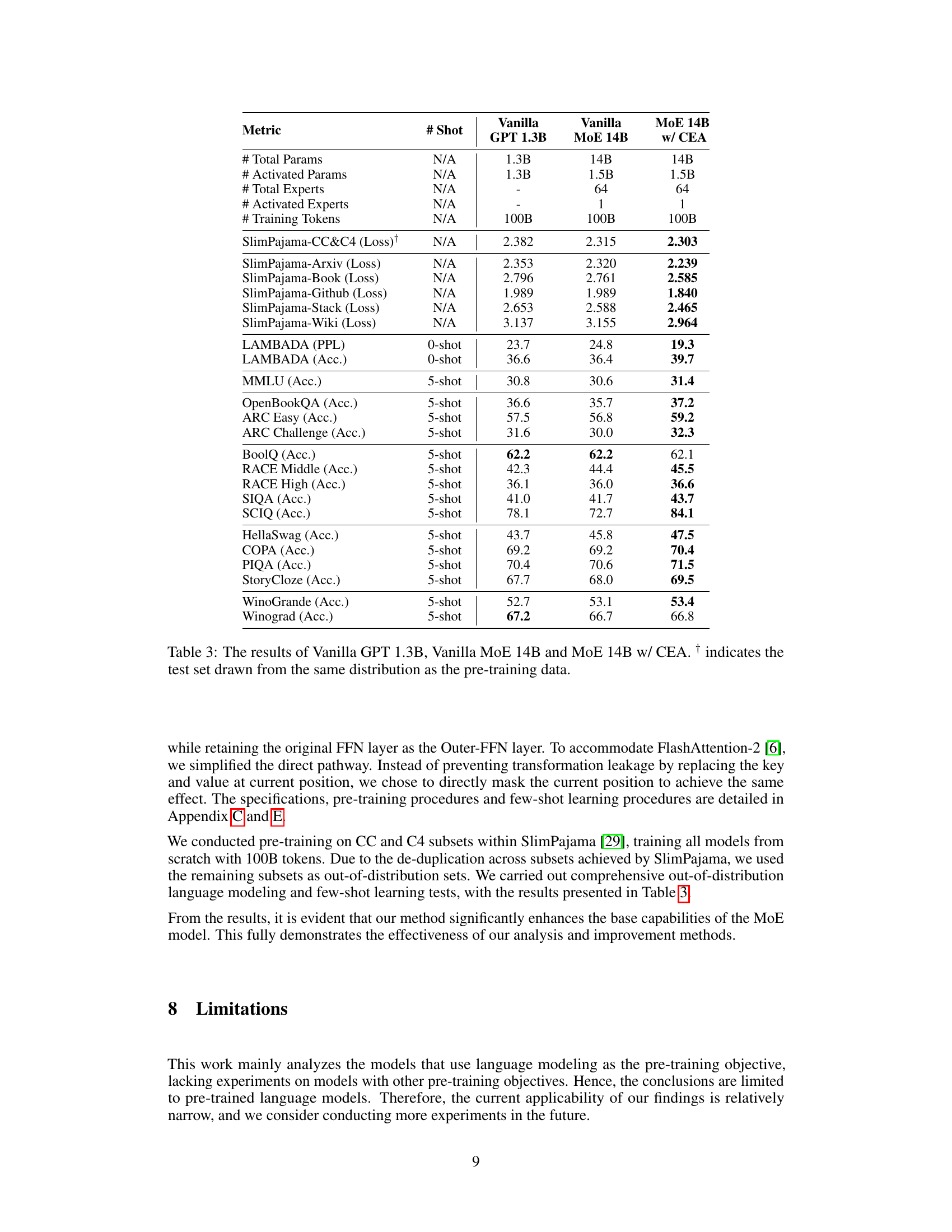
🔼 This table presents the results of various BERT models, comparing the performance of vanilla BERT, FFN-Wider BERT (a model with wider feed-forward networks), and FFN-Wider BERT with Combination Enhanced Architecture (CEA) across different tasks, including out-of-distribution language modeling (Pile), transfer learning (GLUE, SuperGLUE), and other tasks. The results are separated for models with hidden dimension (H) of 128 and 768, and pre-training performance is aligned across models to isolate the effects of architecture.
read the caption
Table 1: The results of various BERT models.
In-depth insights#
Arch. Impact on LMs#
The architectural impact on Large Language Models (LLMs) is a critical area of research, as it directly influences their capabilities. Scale isn’t the only factor determining performance: While increased scale often leads to better results, the underlying architecture significantly shapes how well an LLM utilizes its size and training data. The study of architectural impact on LMs goes beyond simply modifying existing structures; it delves into understanding how design choices affect the contribution of different model components. This involves analyzing the interplay of components like Multi-Head Attention (MHA) and Feed-Forward Networks (FFN), specifically examining their respective roles in language modeling (combination vs. transformation) and how modifications like wider FFNs unexpectedly decrease base capabilities. Ultimately, a key finding is that architectures must carefully balance the interplay of combination and transformation functions to optimize the base capabilities of LLMs.
FFN-Wider Analysis#
An FFN-Wider analysis would delve into the impact of increasing the feed-forward network (FFN) layer’s width in transformer-based language models. A key question is whether this architectural change improves model performance, and if so, under what conditions. Wider FFNs might enhance the model’s capacity to process complex information, but this advantage may be offset by other factors. The analysis would likely investigate the trade-off between increased computational cost and potential performance gains. A crucial aspect would be to examine how wider FFNs affect the interaction between FFNs and the multi-head attention (MHA) mechanism, perhaps revealing a shift in their contribution ratios to the overall model’s capability. The study should carefully consider whether increased FFN width improves in-distribution or out-of-distribution performance, and it should also address the effects on downstream tasks to get a complete picture of the impact. The findings will help researchers understand the role of FFN width in base capabilities and guide the design of more efficient and powerful transformer architectures. Ultimately, the analysis aims to determine if and when increasing FFN width is a beneficial architectural modification.
CEA: Comb. Enhance#
The heading ‘CEA: Comb. Enhance’ likely refers to a proposed Combination Enhanced Architecture within a research paper on pre-trained language models. The core idea revolves around improving base capabilities of such models by carefully adjusting the contribution ratio between transformation and combination functions within the model’s architecture. Standard Transformer models use feed-forward networks (FFNs) for transformation and multi-head attention (MHA) for combination; this method likely seeks to improve the balance, potentially mitigating performance drops seen when using FFNs. A key insight is that MHA acts as a combination function, capturing the inter-relationship of word tokens, whereas FFNs perform isolated transformations. By strategically enhancing the combination function (likely through modifications to the MHA), the CEA architecture aims to improve generalization and few-shot learning abilities—important aspects of base capabilities. This approach highlights that focusing solely on scale (model size) may overlook crucial architectural considerations in pre-trained language model optimization.
MoE Extension & CEA#
The section ‘MoE Extension & CEA’ would logically delve into adapting the Combination Enhanced Architecture (CEA) to Mixture-of-Experts (MoE) models. Given CEA’s success in mitigating the negative impact of wider FFN layers by adjusting the contribution ratio of combination and transformation functions, its extension to MoE would be a significant step. The core challenge lies in how the CEA’s principles translate into the MoE framework, where gating networks determine expert activation. The analysis would likely explore how the gating mechanism might interfere with or complement the intended effects of CEA. Successfully applying CEA to MoE would demonstrate its generalizability and broad applicability, potentially highlighting the fundamental role of balancing combination and transformation in achieving strong base capabilities across diverse model architectures. The experimental results would be crucial, showcasing whether CEA-enhanced MoE models outperform standard MoE models in various downstream tasks while maintaining efficiency. A key finding might be an optimal balance between the number of experts activated and the contribution ratio adjustments made by CEA, demonstrating that the architecture improvement offered by CEA transcends specific model designs and is potentially beneficial for various architectures which struggle with similar balance issues.
Future Work & Limits#
Future work could explore applying the Combination Enhanced Architecture (CEA) to other large language model (LLM) architectures beyond FFN-Wider and Mixture of Experts (MoE) models, and investigate its impact on various downstream tasks. A critical limitation is the current study’s focus on models using language modeling as the sole pre-training objective; future research should explore LLMs with different pre-training tasks and objectives to broaden the applicability and robustness of the findings. Another limitation involves the scale of models investigated, which were relatively small compared to the largest models; replicating this research with even larger models would be valuable. Finally, a deeper investigation into the interplay between architecture and model scaling laws is needed. While the current work highlights architectural effects, a unified understanding of how these effects interact with scaling laws is crucial for optimal LLM design.
More visual insights#
More on figures
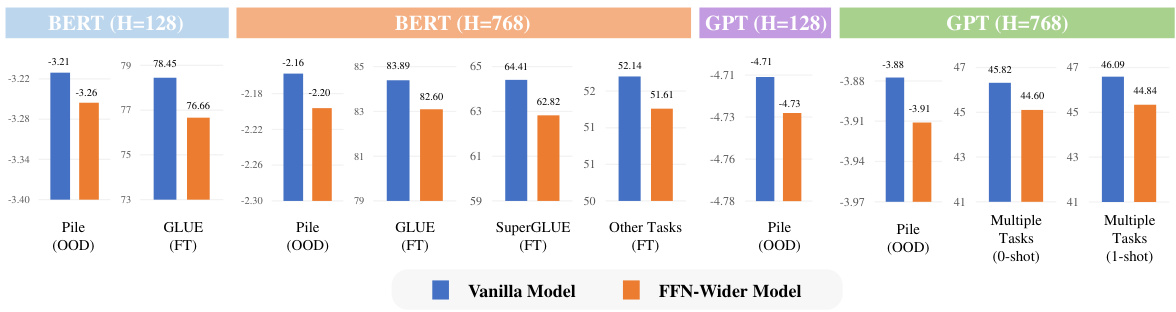
🔼 This figure compares the base capabilities (out-of-distribution language modeling, transfer learning, and few-shot learning) of FFN-Wider Transformers and Vanilla Transformers. The models were trained with similar pre-training performance (aligned pre-training loss). The results show that under similar pre-training performance, FFN-Wider models demonstrate a significant decline in base capabilities compared to Vanilla Transformers. This highlights the influence of architecture on the base capabilities of pre-trained language models, even when pre-training performance is similar.
read the caption
Figure 2: Comparison of the base capabilities between FFN-Wider and Vanilla Transformers.

🔼 This figure shows the contribution ratio analysis based on Mutual Information (MI) for various transformers. It displays the cumulative MI increment contributions of the Block, MHA layer, and FFN layer for four different models: Vanilla BERT (H=128), FFN-Wider BERT (H=128), Vanilla GPT (H=128), and FFN-Wider GPT (H=128). The graphs visually represent how the contribution of each layer changes across different layers of the transformer network, highlighting the differences between vanilla and FFN-Wider models. This analysis helps in understanding the impact of the FFN-Wider architecture on the contribution ratio of the MHA (combination function) compared to the FFN (transformation function).
read the caption
Figure 3: Contribution ratio analysis based on Mutual Information(MI) for various transformers.
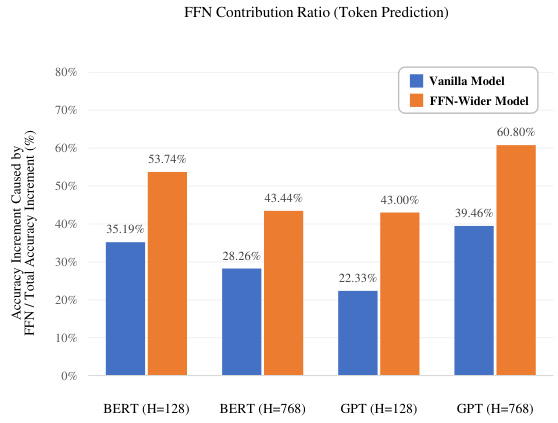
🔼 This figure shows the contribution ratio of the FFN layer (Feed-Forward Network) to the overall model accuracy, as determined by the Token Prediction method. The x-axis represents different models (BERT and GPT with different hidden dimensions, H=128 and H=768). The y-axis shows the percentage of the total accuracy increase attributed to the FFN layer. The bars are grouped in pairs: vanilla models (blue) and FFN-Wider models (orange). The figure illustrates that the FFN-Wider models consistently have a higher FFN contribution ratio than their vanilla counterparts. This supports the hypothesis that widening the FFN layer disproportionately increases its contribution, potentially at the expense of the MHA (Multi-Head Attention) layer’s contribution and the model’s overall base capabilities.
read the caption
Figure 4: Contribution ratio analysis based on Token Prediction (TP) for various transformers.

🔼 This figure illustrates the Combination Adjustable Architecture (CAA), a novel architecture designed to investigate the impact of the contribution ratios of transformation and combination functions on the base capabilities of pre-trained language models. The CAA modifies the FFN-Wider Transformer architecture by splitting the wider FFN layer into two parts: an Outer-FFN (transformation function) and an Inner-FFN (integrated into the MHA layer, serving as part of the combination function). A direct pathway within the MHA bypasses the Inner-FFN, allowing for a controlled adjustment of the contribution ratio of each function, ultimately revealing how this balance impacts model performance.
read the caption
Figure 5: Overview of our proposed Combination Adjustable Architecture (CAA).
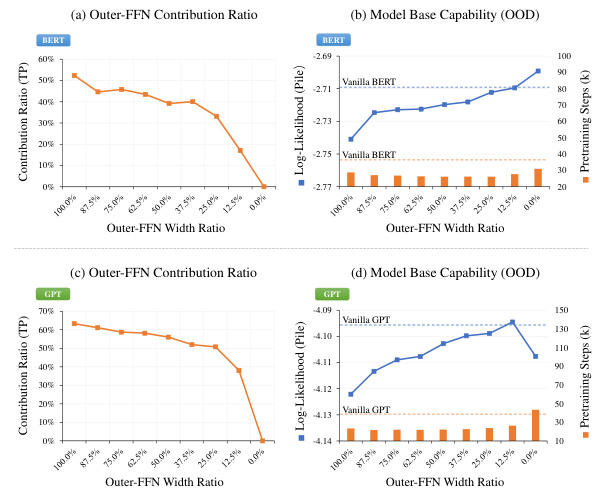
🔼 This figure shows the relationship between the contribution ratio of different layers in Transformer models and their base capabilities. Specifically, it demonstrates that increasing the contribution of the Multi-Head Attention (MHA) layer, a combination function, improves base capabilities, while increasing the contribution of the Feed-Forward Network (FFN) layer, a transformation function, reduces them. The Combination Enhanced Architecture (CEA) is introduced as a method to improve base capabilities by adjusting the contribution ratio of these layers, and its effectiveness is shown on both FFN-Wider and MoE Transformer models.
read the caption
Figure 1: Illustration showing that: 1) the synchronous improvement in model base capability as the contribution ratio of the Outer-FFN layer (a transformation function) decreases, that is, the contribution ratio of the MHA layer (a combination function) increases. This reveals a key factor affecting model's base capabilities. 2) Combination Enhanced Architecture (CEA) was designed based on this factor and applied to MoE models, resulting in an improvement in base capability.
More on tables
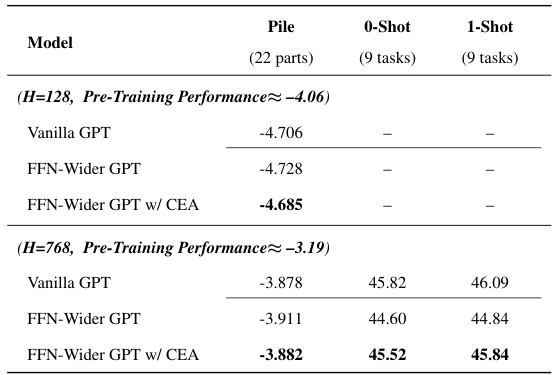
🔼 This table shows the results of various GPT models with different architectures (Vanilla, FFN-Wider, and FFN-Wider with CEA) evaluated on various downstream tasks. The results are categorized by model size (H=128 and H=768), and include the Pile (out-of-distribution language modeling) performance, as well as 0-shot and 1-shot performance on 9 downstream tasks.
read the caption
Table 5: The results of various GPT models.

🔼 This table presents the results of three different models: Vanilla GPT 1.3B, Vanilla MoE 14B, and MoE 14B with the Combination Enhanced Architecture (CEA). It compares their performance across various metrics, including loss on different subsets of the SlimPajama dataset, perplexity and accuracy on LAMBADA, accuracy on MMLU, OpenBookQA, ARC, BoolQ, RACE, SIQA, SCIQ, HellaSwag, COPA, PIQA, StoryCloze, Winograd, and WinoGrande. The † symbol indicates that the test set for the SlimPajama dataset is from the same distribution as the pre-training data.
read the caption
Table 3: The results of Vanilla GPT 1.3B, Vanilla MoE 14B and MoE 14B w/ CEA. † indicates the test set drawn from the same distribution as the pre-training data.
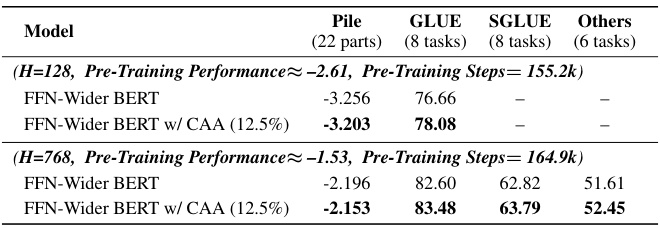
🔼 This table presents the results of various BERT models, comparing the base capabilities of vanilla BERT, FFN-Wider BERT, and FFN-Wider BERT with Combination Enhanced Architecture (CEA). The results are shown across multiple evaluation tasks, including out-of-distribution language modeling on Pile, and fine-tuning performance on GLUE and SuperGLUE benchmarks. The table demonstrates the impact of the FFN-Wider architecture and the effectiveness of CEA in improving base capabilities.
read the caption
Table 1: The results of various BERT models.
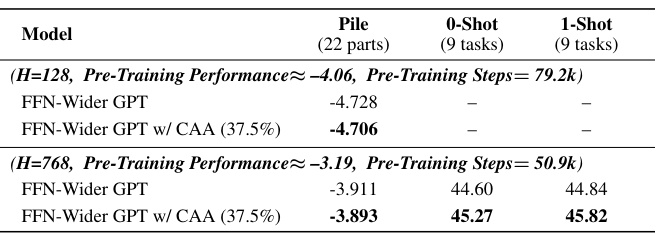
🔼 This table presents the results of various GPT models, comparing the base capabilities of vanilla GPT models against FFN-Wider GPT models and their counterparts enhanced with the Combination Enhanced Architecture (CEA). It shows the performance on Pile (an out-of-distribution language modeling benchmark) and other tasks with 0-shot and 1-shot learning settings. The results illustrate the impact of the FFN-Wider architecture and the effectiveness of CEA in improving base capabilities.
read the caption
Table 5: The results of various GPT models.

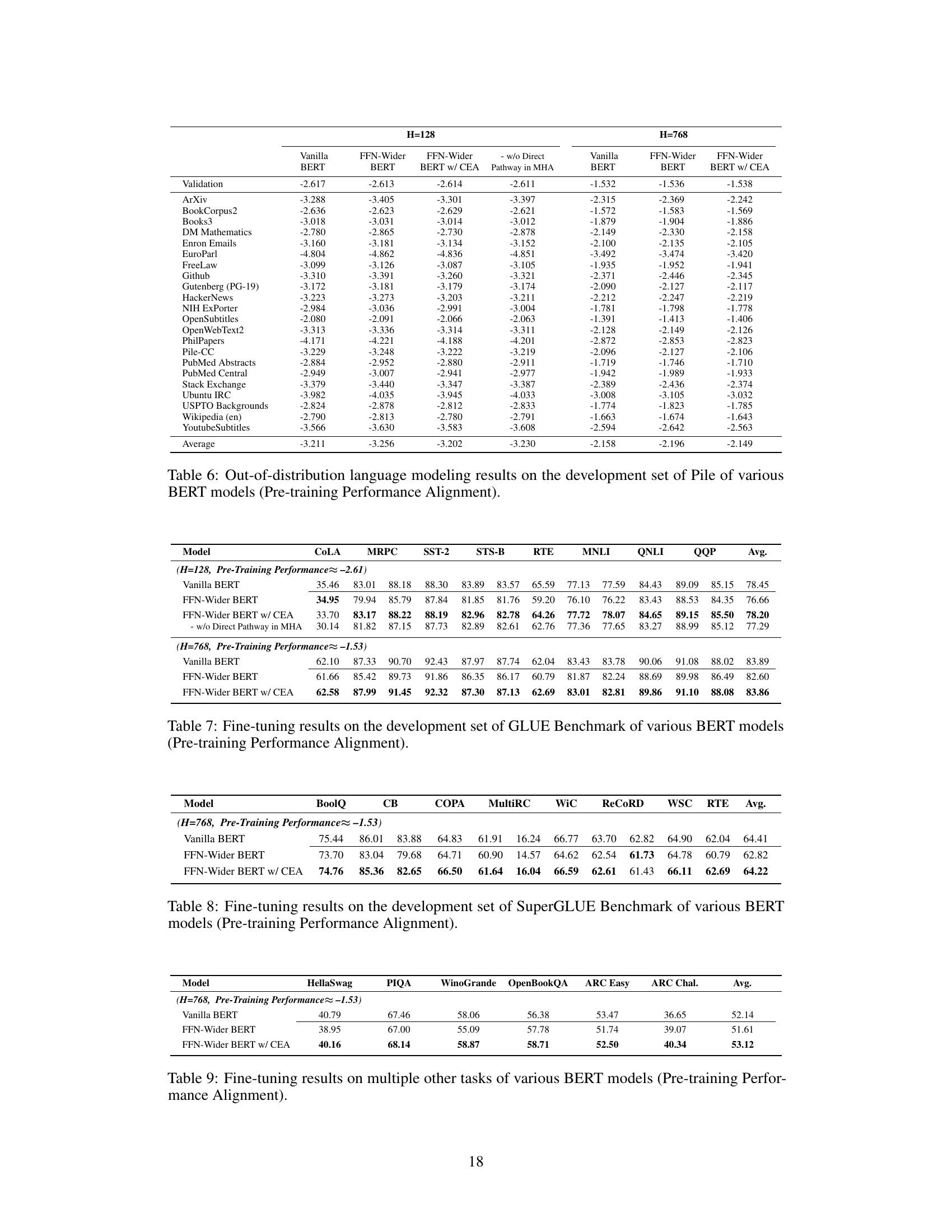
🔼 This table presents the out-of-distribution language modeling results on the Pile development set for various BERT models. The results are broken down by model type (Vanilla BERT, FFN-Wider BERT, FFN-Wider BERT w/ CEA, FFN-Wider BERT w/o Direct Pathway in MHA) and hidden dimension size (H=128, H=768). Each row represents a specific dataset within Pile, and the values show the log-likelihood scores achieved by each model on that dataset. The table highlights the impact of the FFN-Wider architecture and the proposed Combination Enhanced Architecture (CEA) on the models’ ability to generalize to out-of-distribution data.
read the caption
Table 6: Out-of-distribution language modeling results on the development set of Pile of various BERT models (Pre-training Performance Alignment).
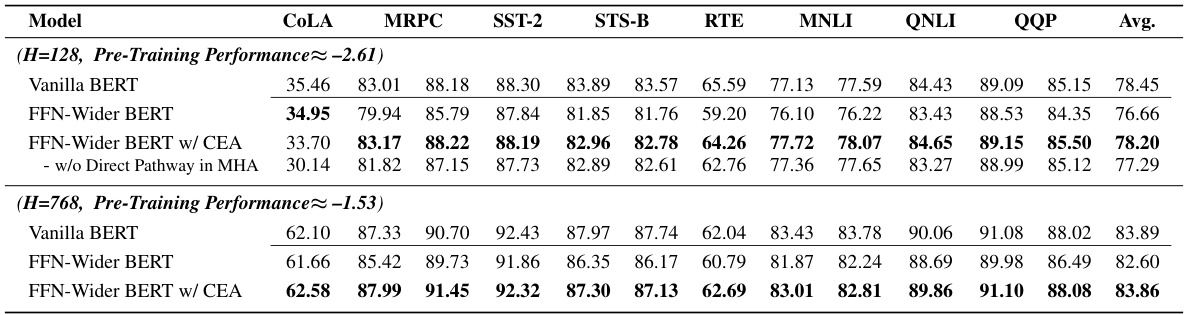
🔼 This table presents the results of various BERT models on several downstream tasks, comparing the performance of Vanilla BERT, FFN-Wider BERT, and FFN-Wider BERT with CEA (Combination Enhanced Architecture). The tasks include out-of-distribution language modeling on the Pile dataset, and fine-tuning on GLUE and SuperGLUE benchmarks. The results demonstrate the impact of the FFN-Wider architecture and the effectiveness of the proposed CEA modification.
read the caption
Table 1: The results of various BERT models.

🔼 This table presents the fine-tuning results on the SuperGLUE benchmark for various BERT models. The results are categorized by model type (Vanilla BERT, FFN-Wider BERT, and FFN-Wider BERT with CEA), and performance metrics are shown for eight different tasks: BoolQ, CB, COPA, MultiRC, WiC, ReCoRD, WSC, and RTE. The pre-training performance was aligned across models for fair comparison. This comparison helps analyze how the FFN-Wider architecture affects performance and the improvement brought by the proposed CEA.
read the caption
Table 8: Fine-tuning results on the development set of SuperGLUE Benchmark of various BERT models (Pre-training Performance Alignment).

🔼 This table presents the fine-tuning results on several downstream tasks for various BERT models. The models were trained with the pre-training performance alignment scheme. The results showcase the performance of Vanilla BERT, FFN-Wider BERT, and FFN-Wider BERT with Combination Enhanced Architecture (CEA). The tasks include HellaSwag, PIQA, WinoGrande, OpenBookQA, ARC Easy, and ARC Challenge, providing a comprehensive evaluation of model performance across diverse tasks.
read the caption
Table 9: Fine-tuning results on multiple other tasks of various BERT models (Pre-training Performance Alignment).
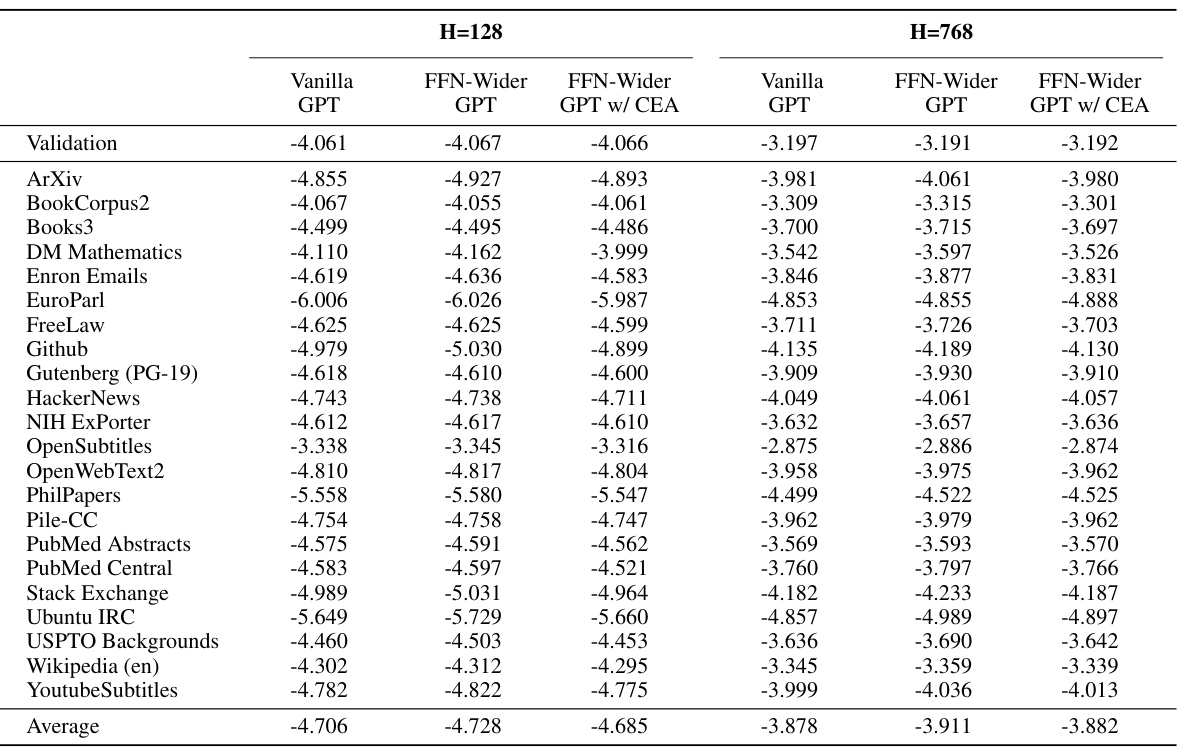
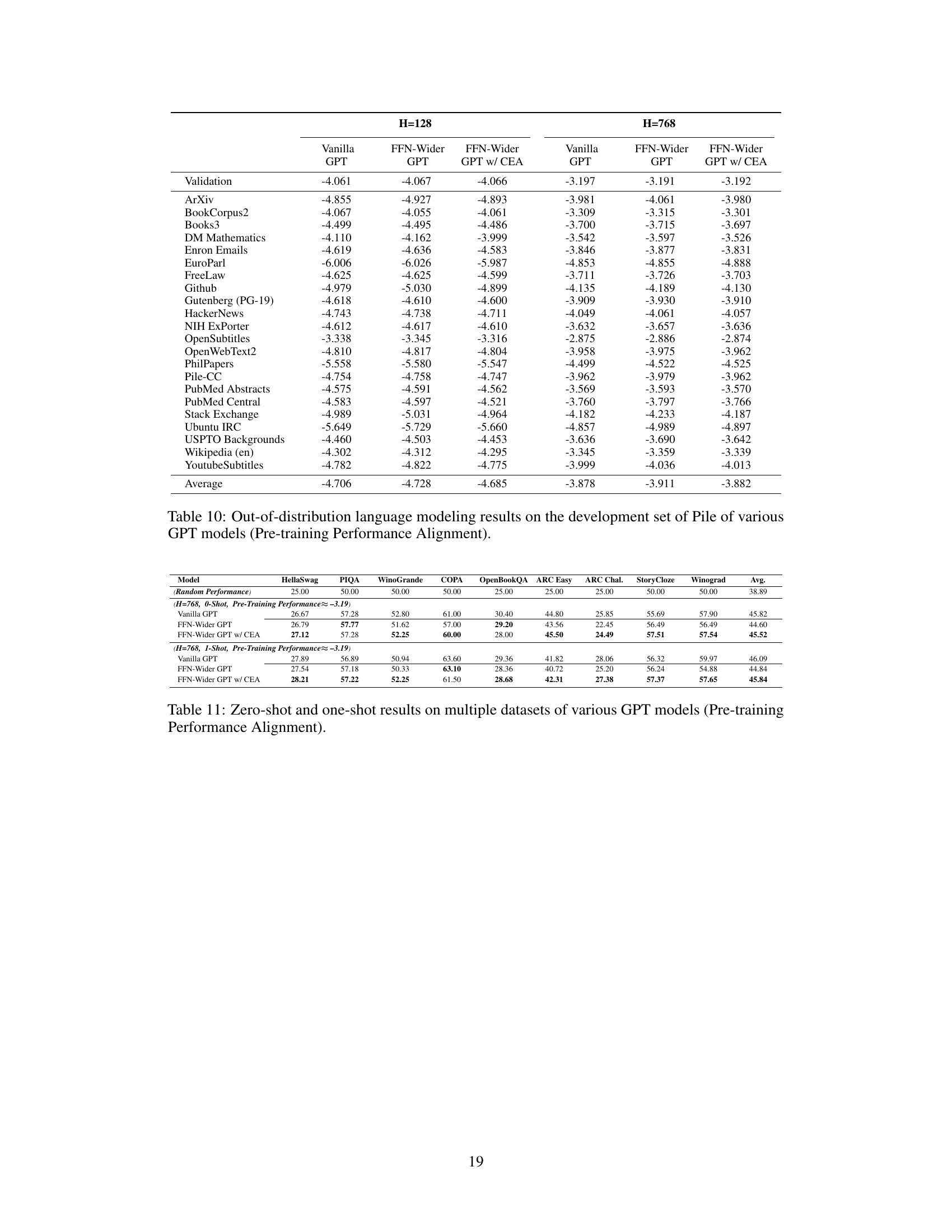
🔼 This table shows the out-of-distribution language modeling performance on the Pile development set for various GPT models. The models are categorized by size (H=128 and H=768), and include vanilla GPT, FFN-Wider GPT, and FFN-Wider GPT with the Combination Enhanced Architecture (CEA). The results are presented to demonstrate the impact of the FFN-Wider architecture and the effectiveness of CEA in mitigating the negative effects on out-of-distribution performance. The pre-training performance is aligned for fair comparison.
read the caption
Table 10: Out-of-distribution language modeling results on the development set of Pile of various GPT models (Pre-training Performance Alignment).

🔼 This table presents the results of three different models: Vanilla GPT 1.3B, Vanilla MoE 14B, and MoE 14B with the Combination Enhanced Architecture (CEA). It compares their performance across various metrics, including loss on different subsets of the SlimPajama dataset, as well as few-shot learning performance on several downstream tasks like LAMBADA, MMLU, and OpenBookQA. The results demonstrate the improvement in base capabilities achieved by incorporating the CEA into the MoE model.
read the caption
Table 3: The results of Vanilla GPT 1.3B, Vanilla MoE 14B and MoE 14B w/ CEA. † indicates the test set drawn from the same distribution as the pre-training data.

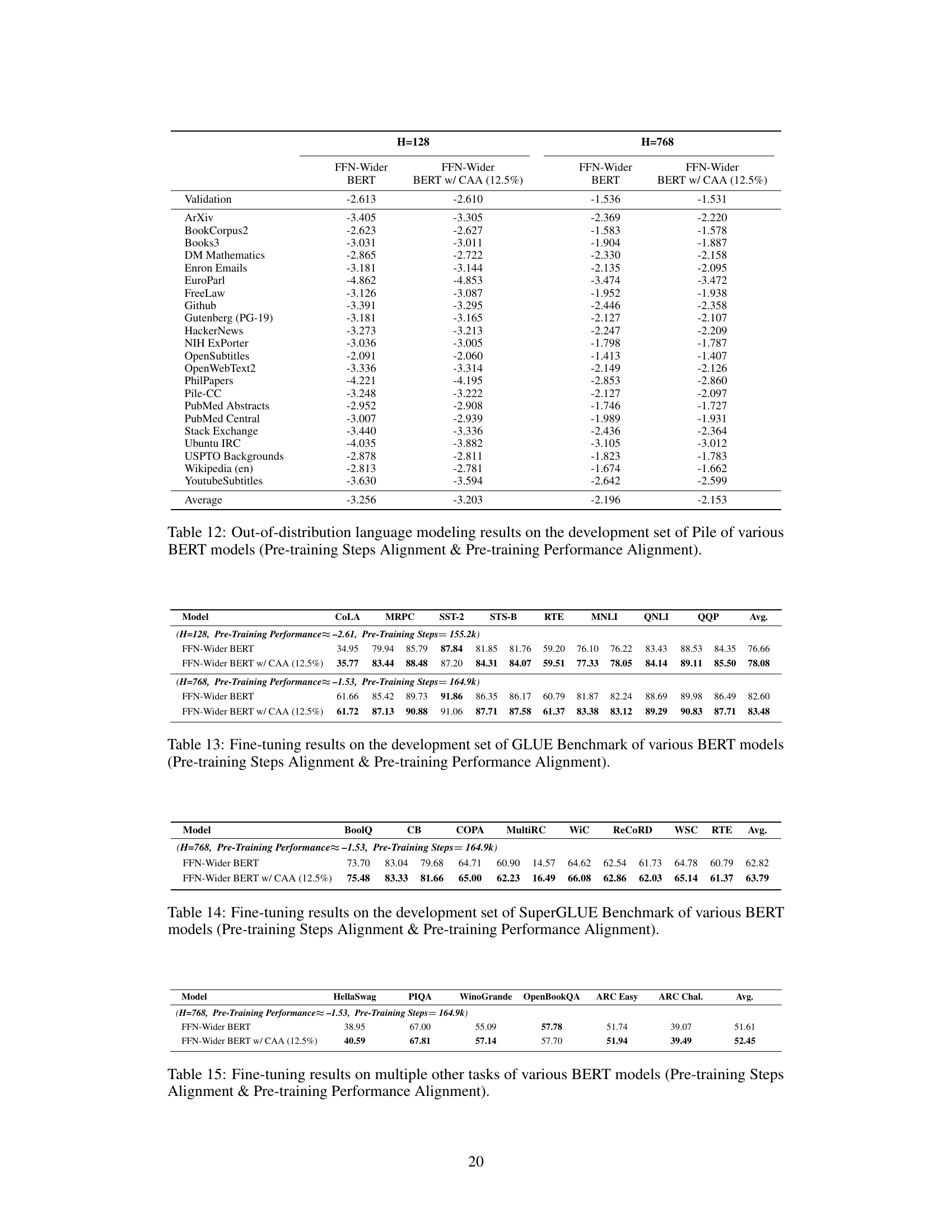
🔼 This table presents the out-of-distribution language modeling results on the Pile development set for various BERT models. The results are broken down by model type (Vanilla BERT, FFN-Wider BERT, and FFN-Wider BERT with CEA), hidden dimension size (H=128 and H=768), and the specific subset of the Pile dataset being evaluated. The table shows that the FFN-Wider BERT models with the Combination Enhanced Architecture (CEA) generally improve upon the performance of FFN-Wider BERT models without CEA, often approaching the performance of vanilla BERT models in some cases. The results highlight the positive impact of CEA on improving the base capabilities of FFN-Wider Transformer models, especially when both pre-training performance and steps are aligned.
read the caption
Table 12: Out-of-distribution language modeling results on the development set of Pile of various BERT models (Pre-training Steps Alignment & Pre-training Performance Alignment).

🔼 This table presents the performance comparison of different BERT models across various tasks, including out-of-distribution (OOD) language modeling on the Pile dataset, and fine-tuning performance on GLUE and SuperGLUE benchmarks. It compares the vanilla BERT model, the FFN-Wider BERT model (which has wider FFN layers), and the FFN-Wider BERT model with the proposed Combination Enhanced Architecture (CEA). The results show that CEA improves the FFN-Wider BERT’s performance, often reaching or surpassing the vanilla BERT’s scores.
read the caption
Table 1: The results of various BERT models.

🔼 This table presents the results of fine-tuning various BERT models on the SuperGLUE benchmark. The models were pre-trained with performance alignment, meaning their pre-training performance was matched before the fine-tuning task. The table shows the performance (accuracy) of each model on various subtasks of SuperGLUE, including BoolQ, CB, COPA, MultiRC, WiC, ReCoRD, WSC, and RTE. The results highlight the impact of the FFN-Wider architecture and its improvement (CEA) on downstream task performance.
read the caption
Table 8: Fine-tuning results on the development set of SuperGLUE Benchmark of various BERT models (Pre-training Performance Alignment).

🔼 This table presents the fine-tuning results of various BERT models on multiple downstream tasks. The models are compared based on their performance after pre-training with the same level of performance on the language modeling task. The results include metrics such as accuracy or precision, and showcase the impact of the FFN-Wider architecture and the proposed Combination Enhanced Architecture (CEA) on model generalization ability across different tasks.
read the caption
Table 9: Fine-tuning results on multiple other tasks of various BERT models (Pre-training Performance Alignment).
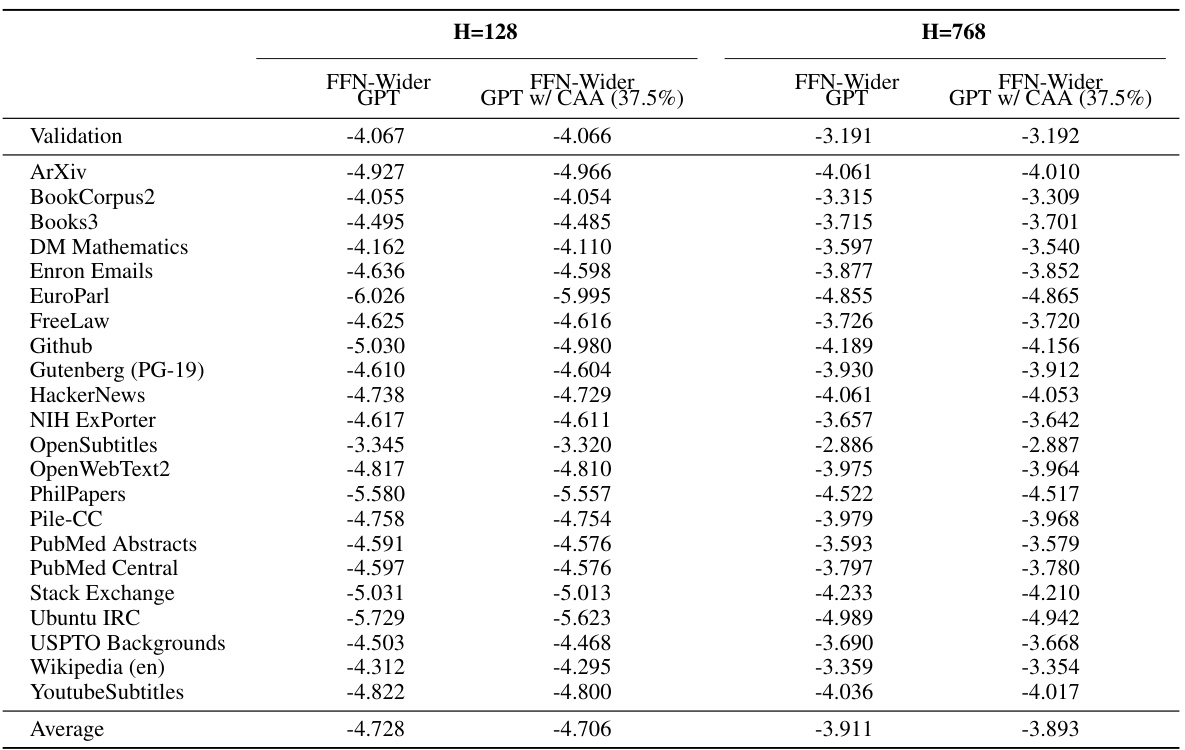
🔼 This table shows the out-of-distribution language modeling performance on the Pile development set for various GPT models. The models are grouped by size (H=128 and H=768), and further categorized by model type: Vanilla GPT, FFN-Wider GPT, and FFN-Wider GPT with the Combination Enhanced Architecture (CEA). The results demonstrate the impact of the FFN-Wider architecture and the effectiveness of the CEA modification on improving out-of-distribution generalization.
read the caption
Table 10: Out-of-distribution language modeling results on the development set of Pile of various GPT models (Pre-training Performance Alignment).

🔼 This table presents the results of three different models: Vanilla GPT 1.3B, Vanilla MoE 14B, and MoE 14B with Combination Enhanced Architecture (CEA). It compares their performance across various metrics, including loss on different datasets (SlimPajama), perplexity and accuracy on LAMBADA, and accuracy on other benchmarks (MMLU, OpenBookQA, etc.). The results highlight the improvement achieved by incorporating CEA into the MoE model, demonstrating its effectiveness.
read the caption
Table 3: The results of Vanilla GPT 1.3B, Vanilla MoE 14B and MoE 14B w/ CEA. † indicates the test set drawn from the same distribution as the pre-training data.
Full paper#