TL;DR#
Current LLM evaluation methods suffer from significant limitations. Traditional ground-truth methods lack real-world query diversity, while LLM-as-judge approaches introduce grading biases. User-facing evaluations are reliable but extremely expensive and slow. These issues hinder the impartial and efficient evaluation crucial for model development and user guidance.
MixEval offers a novel solution by strategically combining existing benchmark datasets with queries mined from the real world. This approach leverages the advantages of both existing datasets and real-world user queries resulting in impartial, efficient, and reproducible LLM evaluation. MixEval demonstrates high correlation with user preference leaderboards while significantly reducing costs and time. Its dynamic nature ensures continuous improvement and the prevention of data contamination. This advancement is highly valuable for the broader AI community.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces MixEval, a novel paradigm for LLM evaluation that significantly improves accuracy and efficiency. Addressing the limitations of existing benchmarks by combining real-world user queries with existing datasets, MixEval offers a fairer and more comprehensive assessment of LLMs. This promotes advancements in LLM research and offers researchers a new and valuable tool.
Visual Insights#

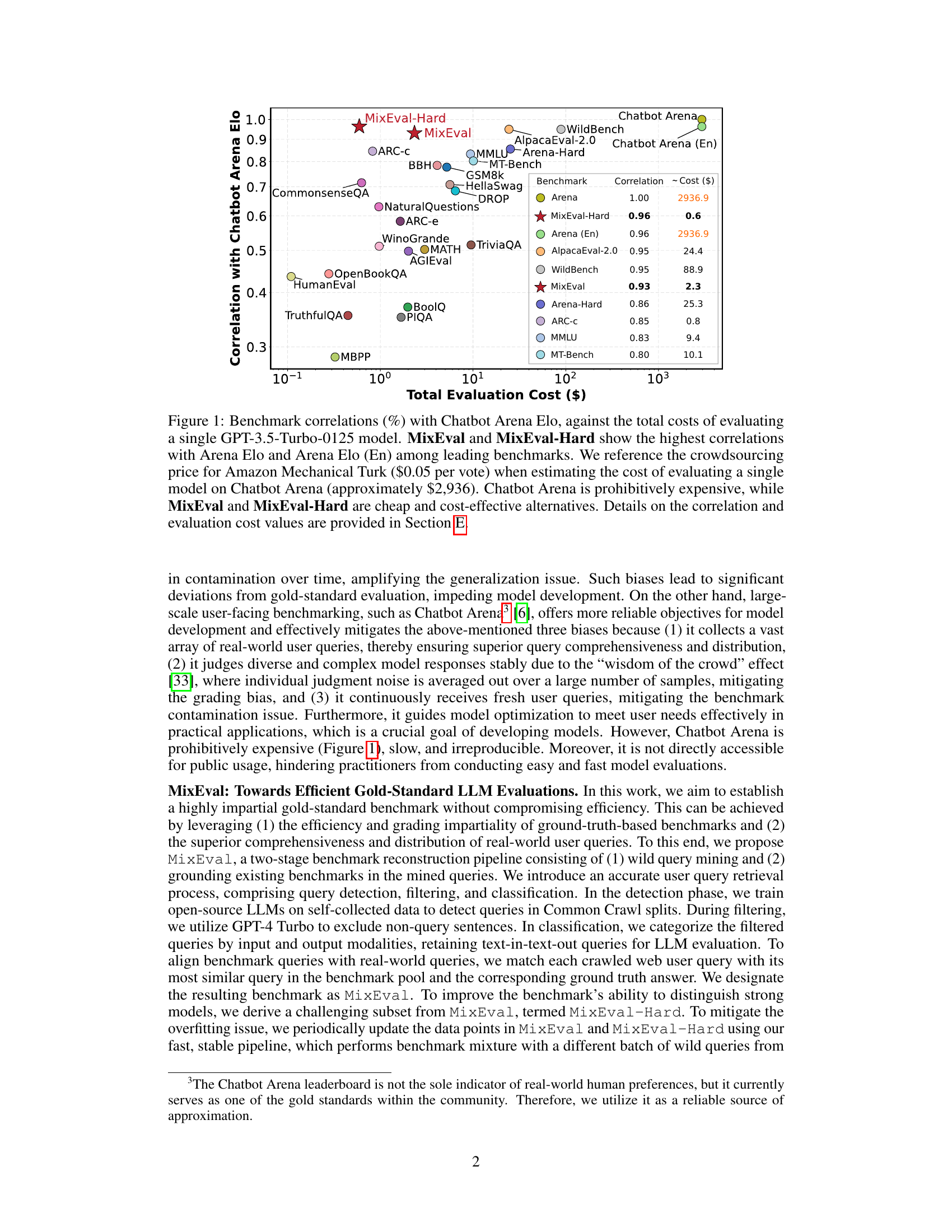
🔼 This figure shows the correlation of various benchmarks with Chatbot Arena Elo, plotted against their evaluation costs. MixEval and MixEval-Hard demonstrate the highest correlation with Chatbot Arena, indicating strong alignment with real-world human preferences, while being significantly more cost-effective than other benchmarks.
read the caption
Figure 1: Benchmark correlations (%) with Chatbot Arena Elo, against the total costs of evaluating a single GPT-3.5-Turbo-0125 model. MixEval and MixEval-Hard show the highest correlations with Arena Elo and Arena Elo (En) among leading benchmarks. We reference the crowdsourcing price for Amazon Mechanical Turk ($0.05 per vote) when estimating the cost of evaluating a single model on Chatbot Arena (approximately $2,936). Chatbot Arena is prohibitively expensive, while MixEval and MixEval-Hard are cheap and cost-effective alternatives. Details on the correlation and evaluation cost values are provided in Section E.

🔼 This table presents key statistics for the MixEval and MixEval-Hard benchmarks, including the number of queries, average number of tokens per query and input, average, minimum and maximum numbers of tokens per input, the percentage of English queries, and the evaluation type (ground truth). Note that because these benchmarks are dynamically updated, the numbers presented might vary slightly over time, but the total number of queries remains consistent.
read the caption
Table 1: The key statistics of MixEval and MixEval-Hard. With dynamic benchmarking, the numbers may vary slightly while the number of queries will not change.
In-depth insights#
LLM Benchmarking#
LLM Benchmarking is a crucial aspect of large language model (LLM) development and evaluation. Existing methods often fall short due to inherent biases. Ground-truth based benchmarks lack real-world query comprehensiveness. LLM-as-judge benchmarks suffer from grading biases and limited query quantities. User-facing evaluations offer more reliable signals but are costly and slow. Therefore, creating efficient, impartial, and scalable LLM benchmarks is vital. This involves considering diverse query distributions to reflect real-world user preferences, minimizing grading biases, and addressing the issue of benchmark contamination over time to prevent overfitting and ensure continued efficacy.
MixEval Pipeline#
The MixEval pipeline represents a novel approach to LLM benchmarking. It cleverly combines the strengths of existing ground-truth benchmarks and the rich, diverse queries found in real-world user interactions. The two-stage process first involves mining a large corpus of user queries from the web, carefully filtering and classifying them to ensure high quality. Secondly, it strategically matches these real-world queries with similar queries from existing benchmarks, creating a hybrid dataset. This hybrid dataset is crucial as it provides both the efficiency and impartiality of ground-truth evaluation with the comprehensiveness and distribution of real user queries. MixEval’s dynamic nature ensures that the benchmark remains current and unbiased over time. This innovative methodology effectively addresses limitations of traditional LLM evaluations, paving the way for more realistic and robust model assessment.
Bias Mitigation#
Mitigating bias in large language model (LLM) evaluation is crucial for ensuring fair and reliable benchmark results. The paper likely addresses this by employing several strategies. MixEval’s core approach cleverly combines the strengths of existing, potentially biased benchmarks with a large corpus of real-world user queries. This helps to reduce query bias by incorporating a wider range of prompts that better reflect actual user needs and behavior. Further, the methodology may employ a robust grading mechanism, potentially involving human evaluation or ensemble methods, to reduce grading bias. Another important point is benchmark dynamism. Regularly updating the benchmark dataset with new queries can help prevent overfitting and contamination by outdated or skewed data, thus mitigating generalization bias. The success of these strategies in reducing bias depends on the quality and diversity of the real-world data, the sophistication of the grading scheme, and the frequency and effectiveness of the benchmark updates. Careful analysis and meta-evaluation are key to determining MixEval’s actual success in bias reduction.
Dynamic Eval#
The concept of “Dynamic Eval” in the context of LLM evaluation is crucial for addressing the limitations of static benchmarks. Static benchmarks become outdated quickly as models evolve, leading to overfitting and inaccurate assessments. A dynamic evaluation system continuously updates its datasets and evaluation metrics, reflecting current LLM capabilities and real-world user needs. This approach ensures the benchmark remains relevant and challenging, preventing models from merely optimizing for a specific, outdated snapshot. Data augmentation techniques, such as incorporating web-mined queries, are vital for maintaining a diverse and representative dataset, preventing query bias and improving the evaluation’s generalizability. Regular updates are essential to mitigate contamination and maintain the impartiality of the evaluation process. Furthermore, the cost-effectiveness of the dynamic evaluation system needs to be carefully considered; while high-quality evaluation is paramount, it must remain practically feasible for broad adoption and utilization in the AI community. Therefore, a well-designed dynamic evaluation system will be both robust and cost-effective, providing reliable and up-to-date insights into model performance and accelerating LLM development.
Future Works#
The research paper’s ‘Future Works’ section could explore several avenues. Extending MixEval to encompass more diverse LLM capabilities beyond text-in-text-out is crucial. This involves handling various input/output modalities, such as images and audio, to reflect a broader spectrum of real-world LLM applications. Investigating the impact of query characteristics on model performance is key; analyzing the influence of query length, complexity, ambiguity, and topical distribution on model rankings will provide valuable insights for benchmark design. Developing advanced methods for dynamically updating MixEval is important to counter benchmark contamination and ensure ongoing relevance to evolving LLM capabilities. This could involve advanced techniques for query selection, bias detection, and data augmentation. Investigating the relationship between benchmark diversity and evaluation accuracy would enhance the understanding of how diverse benchmarks contribute to a robust assessment. Finally, exploring the use of MixEval for evaluating different aspects of LLM performance, such as fairness, robustness, and reasoning capabilities, is critical for a holistic evaluation framework.
More visual insights#
More on figures
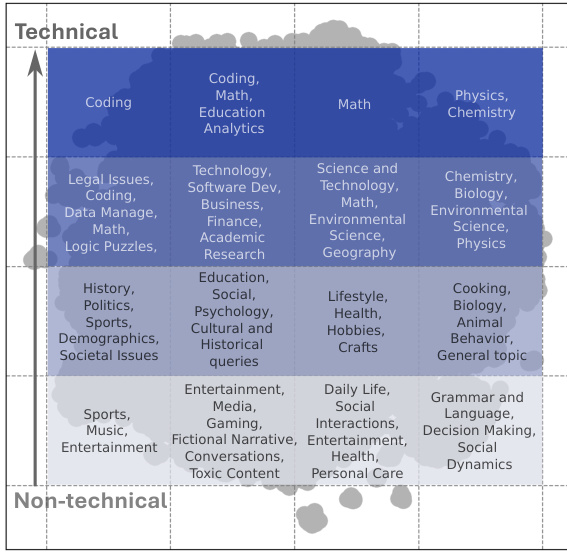
🔼 This figure visualizes the topic distributions of various LLM benchmarks and compares them to the distribution of real-world web queries. It uses a 2D embedding to show how different benchmarks cluster together, revealing the relative balance between technical and non-technical topics in each. The distribution of web queries serves as a baseline for comparison, highlighting the degree to which different benchmarks align with actual user query topics.
read the caption
Figure 2: Query Topic Distribution of the Benchmarks. Ground-truth-based benchmarks are represented by orange dots, wild datasets by yellow dots, and LLM-judged benchmarks (MT-Bench and Arena-Hard) by yellow dots, all plotted against our detected web queries shown as blue dots. Query sentence embeddings were dimensionally reduced to map them onto a unified 2-D space, facilitating direct comparisons of topic distributions across benchmarks. As we move from the bottom to the top of the figure, query topics transition from non-technical to technical. Topic summaries for each region are detailed in Figure 3.
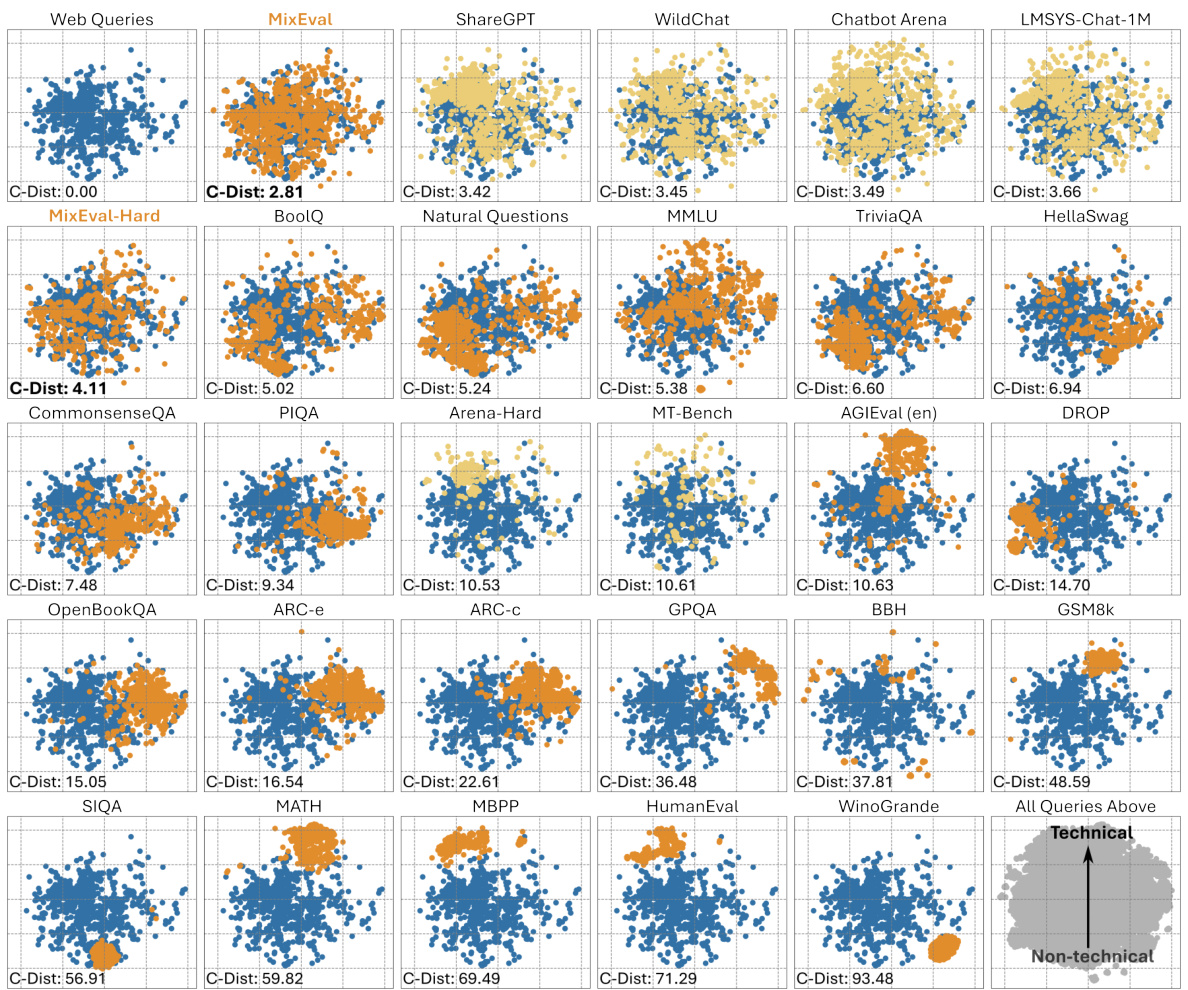
🔼 This figure visualizes the topic distribution of various benchmarks, including ground-truth, wild datasets, and LLM-judged ones, compared to web queries. It uses a 2D embedding to represent query topics, showing a transition from non-technical to technical topics as you move from the bottom to the top of the figure. Each point represents a query, and the color indicates the benchmark it originated from.
read the caption
Figure 2: Query Topic Distribution of the Benchmarks. Ground-truth-based benchmarks are represented by orange dots, wild datasets by yellow dots, and LLM-judged benchmarks (MT-Bench and Arena-Hard) by yellow dots, all plotted against our detected web queries shown as blue dots. Query sentence embeddings were dimensionally reduced to map them onto a unified 2-D space, facilitating direct comparisons of topic distributions across benchmarks. As we move from the bottom to the top of the figure, query topics transition from non-technical to technical. Topic summaries for each region are detailed in Figure 3.
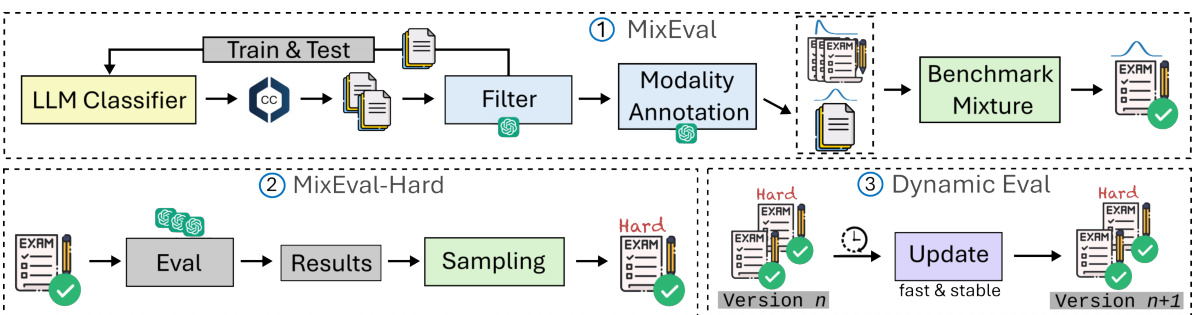
🔼 The figure illustrates the MixEval pipeline, which consists of two main stages: web query detection and benchmark mixture. The pipeline starts with mining user queries from Common Crawl, filtering them and creating a benchmark pool. These user queries are then grounded in existing benchmarks by finding the most similar benchmark questions to create MixEval. To further enhance the model ranking capability, MixEval-Hard, a challenging subset of MixEval, is generated. Furthermore, a dynamic evaluation component ensures ongoing data updates to mitigate overfitting issues.
read the caption
Figure 4: MixEval, a two-stage benchmark reconstruction pipeline, comprises (1) web query detection and (2) benchmark mixture. We further introduce MixEval-Hard to enhance model separability, alongside a dynamic updating mechanism to mitigate contamination risk.
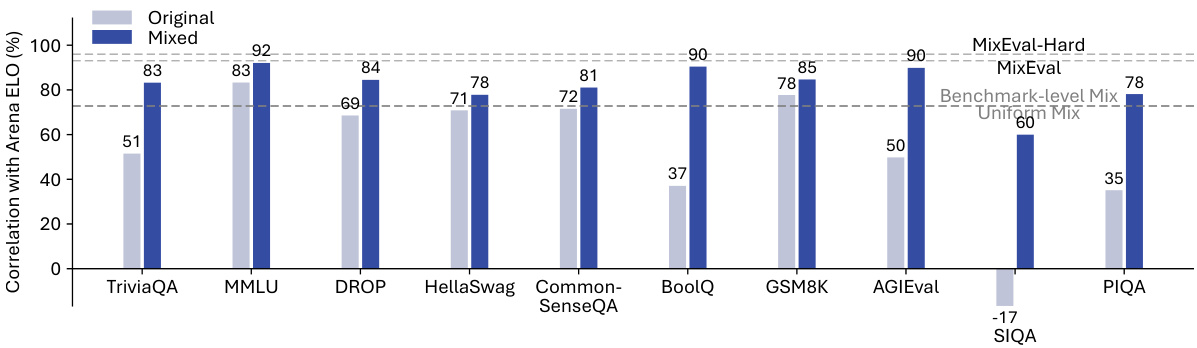
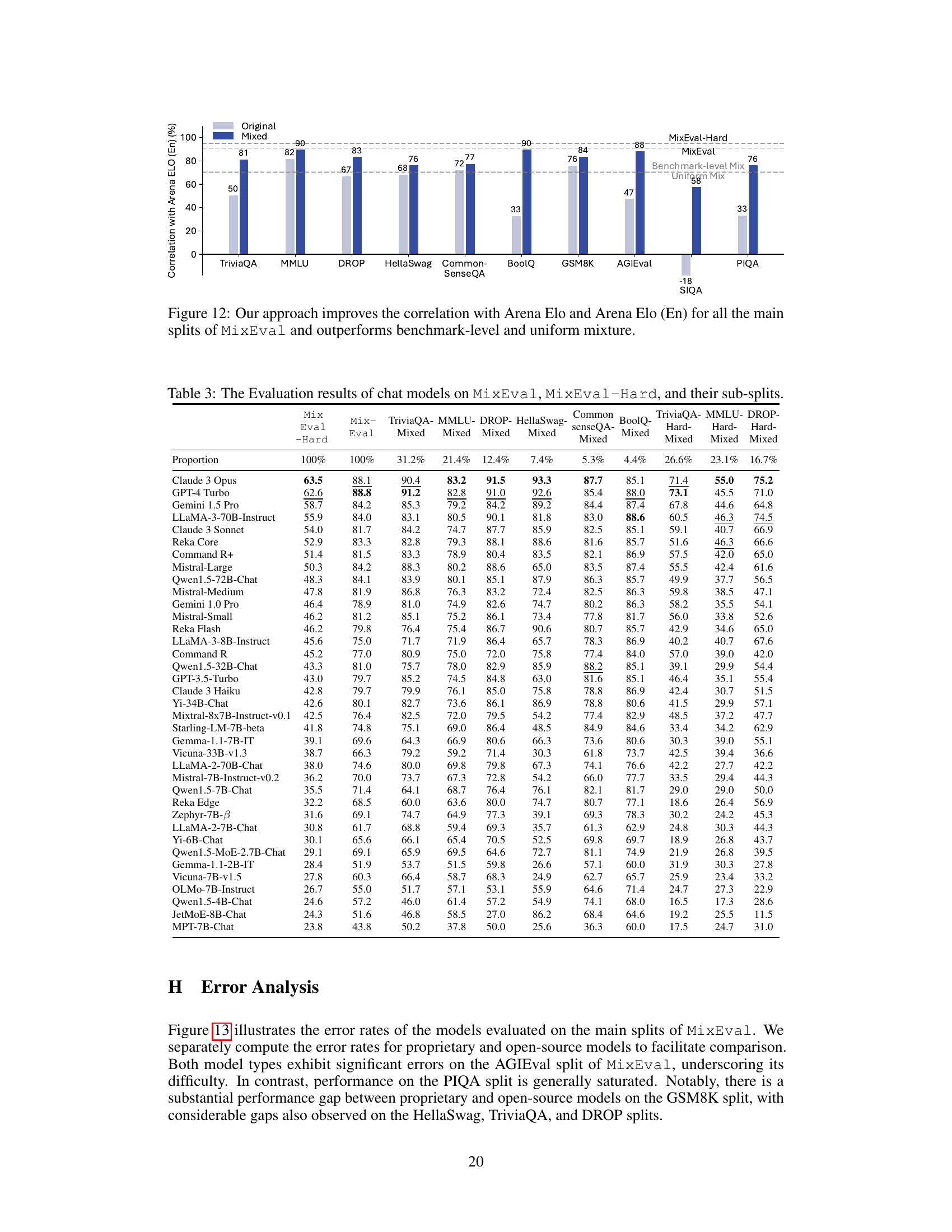
🔼 This figure shows the improvement in correlation with Arena Elo and Arena Elo (En) achieved by using the MixEval approach compared to benchmark-level and uniform mixture methods. The x-axis represents different benchmark datasets (TriviaQA, MMLU, etc.), while the y-axis shows the correlation with Arena Elo. The bars are grouped into pairs, with the light gray bars showing the original correlation before MixEval and the dark blue bars indicating the correlation after applying MixEval. The figure demonstrates that the MixEval method significantly improves correlations across all benchmarks, highlighting its effectiveness in aligning benchmark query distributions with real-world user queries.
read the caption
Figure 5: Our approach improves the correlation with Arena Elo and Arena Elo (En) (Figure 12) for all the main splits of MixEval and outperforms benchmark-level and uniform mixture.

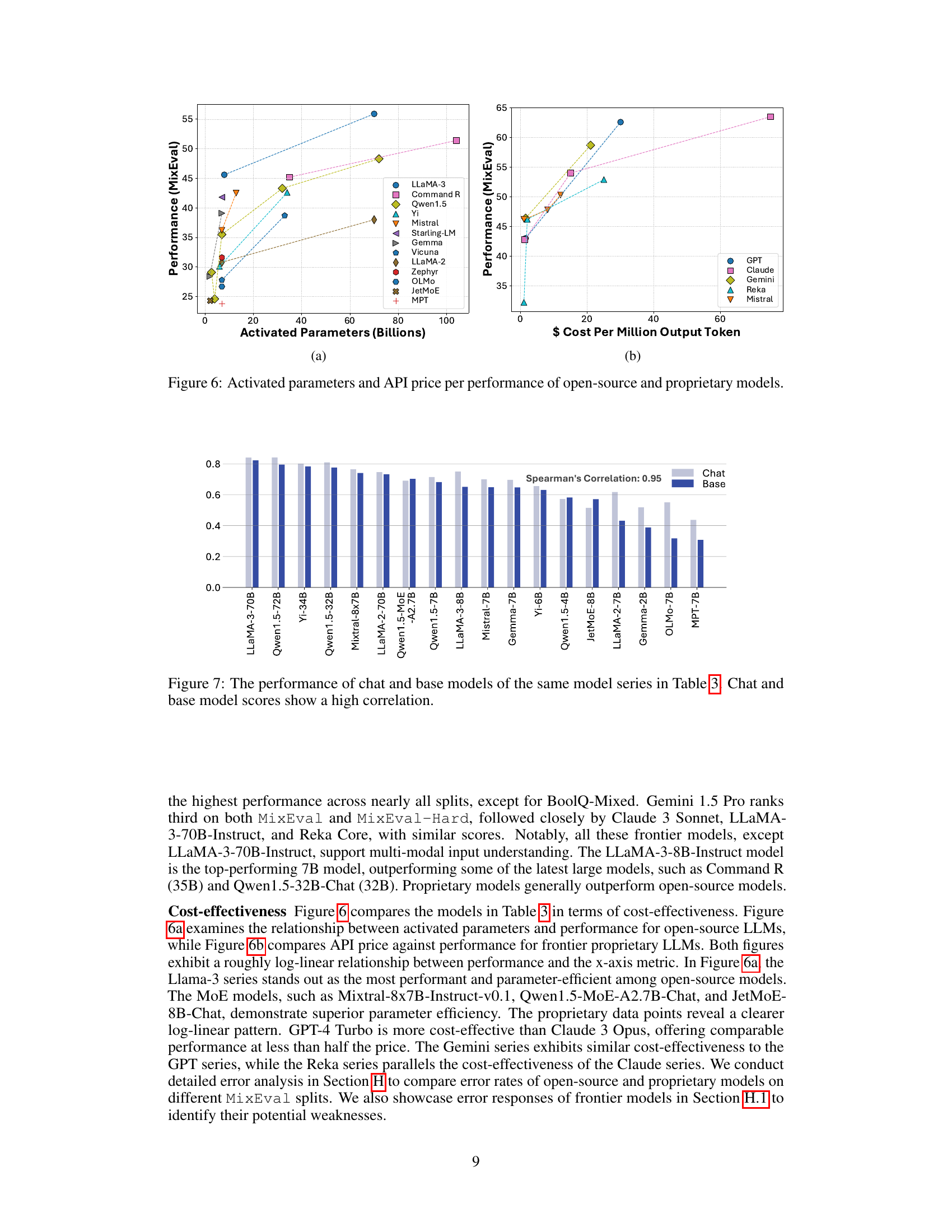
🔼 This figure compares the performance of various open-source and proprietary large language models (LLMs) across two key metrics: activated parameters (a proxy for model size and computational cost) and API price per million output tokens (a proxy for cost-effectiveness). Panel (a) shows a positive correlation between activated parameters and performance on MixEval, suggesting that larger models tend to perform better. However, the relationship isn’t perfectly linear, indicating that parameter efficiency varies across different model architectures. Panel (b) shows a similar positive correlation between API cost and MixEval performance, again demonstrating that more expensive models generally perform better, but with variations in cost-effectiveness among different models. The figure highlights the trade-off between model size/computational cost and performance, with some models demonstrating better cost-effectiveness than others.
read the caption
Figure 6: Activated parameters and API price per performance of open-source and proprietary models.
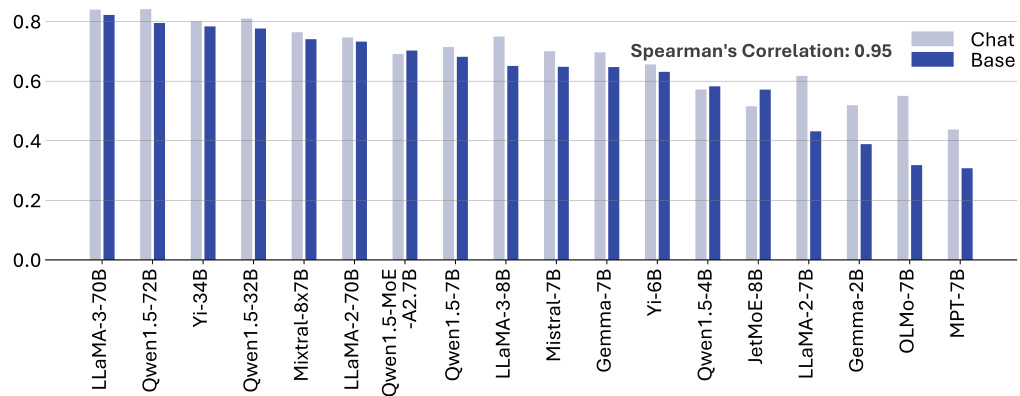
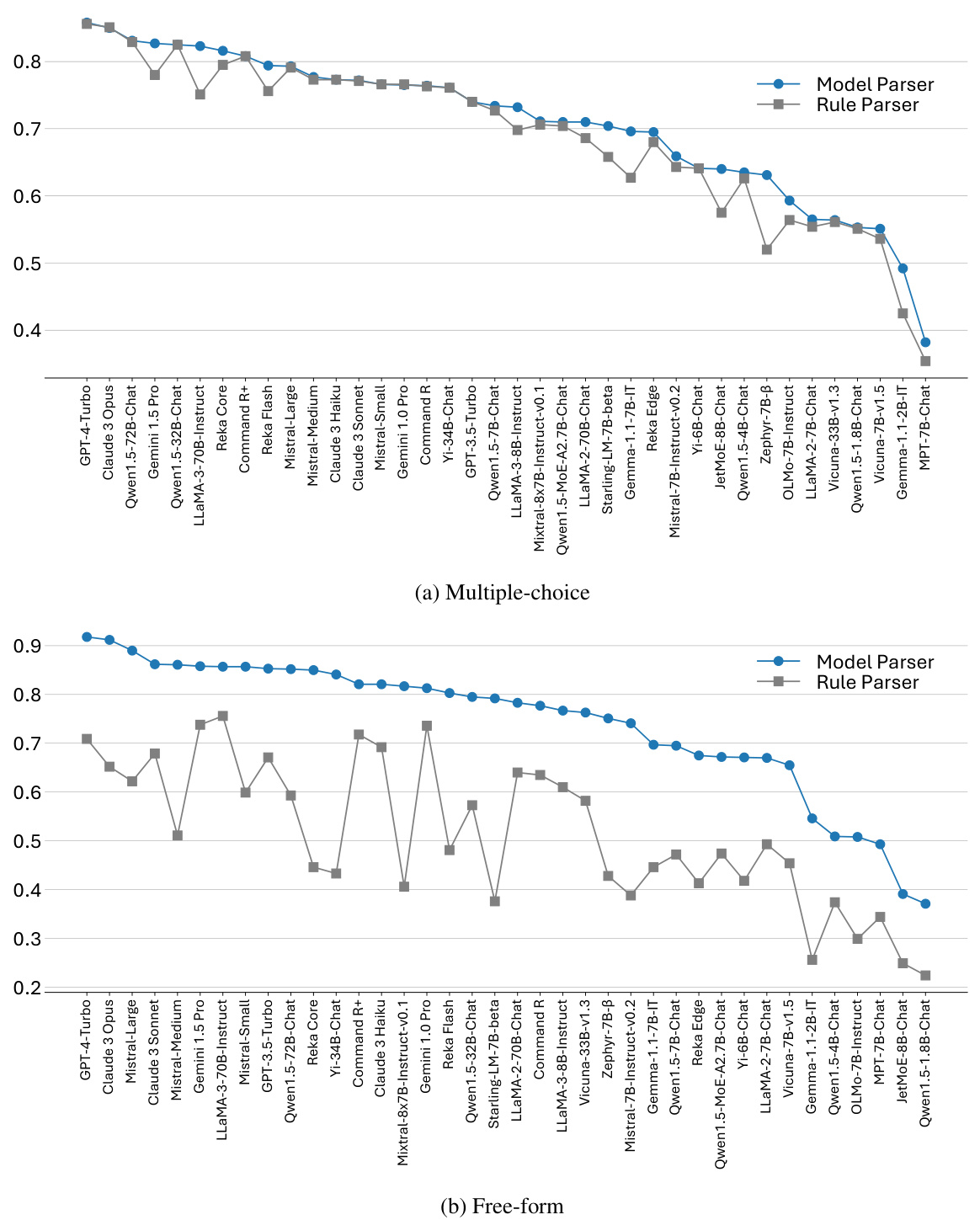
🔼 This figure shows a bar chart comparing the performance of chat models and base models from the same series. The data is taken from Table 3 in the paper. A high Spearman correlation (0.95) is noted, indicating that the performance of chat models and base models are strongly related. This suggests that the improvements in capabilities observed between the base and chat versions of these models are consistent across different model series.
read the caption
Figure 7: The performance of chat and base models of the same model series in Table 3. Chat and base model scores show a high correlation.
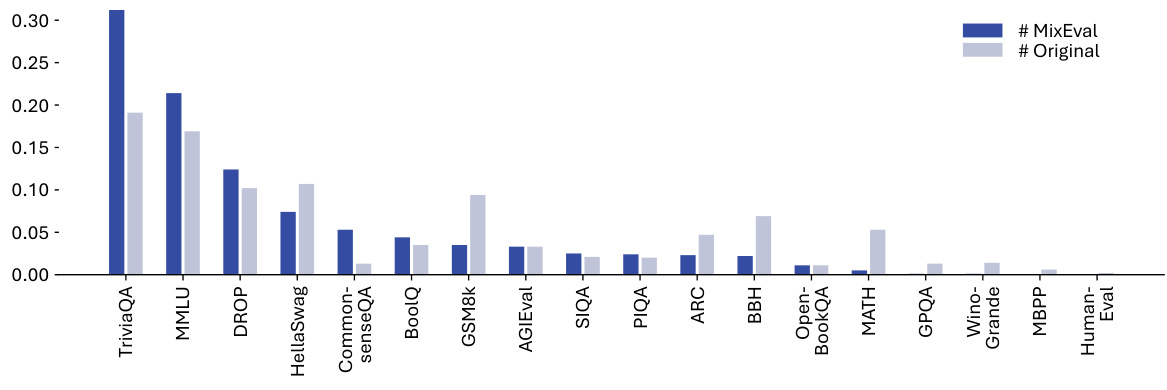
🔼 This figure shows a bar chart comparing the normalized number of queries used in MixEval versus the original benchmarks. The height of each bar represents the proportion of queries from each benchmark in MixEval. It illustrates how the query distribution in MixEval differs from the original benchmarks, showing that some benchmarks are more heavily represented in MixEval than others. This is related to the benchmark mixture technique used to create MixEval, which strategically mixes queries from multiple benchmarks to achieve a more representative and unbiased query distribution.
read the caption
Figure 8: The normalized number of queries in MixEval and the original benchmarks.
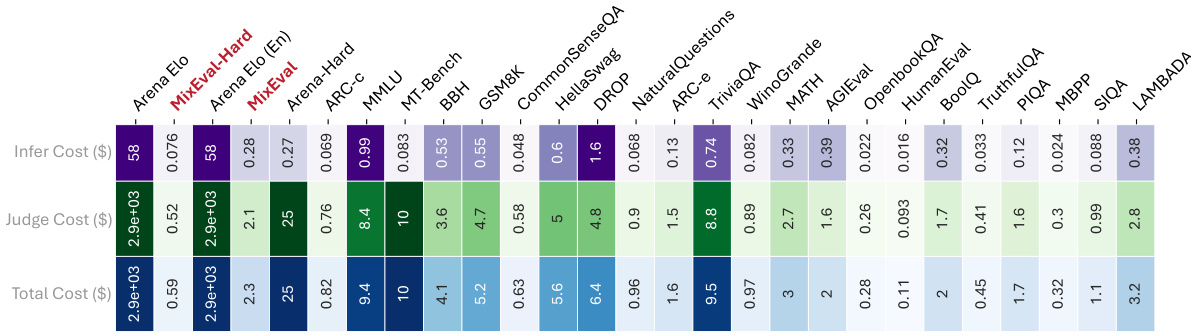
🔼 This figure shows the correlation between different benchmarks and Chatbot Arena Elo, plotted against their respective evaluation costs. MixEval and MixEval-Hard demonstrate the highest correlation with Chatbot Arena Elo at a significantly lower cost compared to other benchmarks, highlighting their efficiency and cost-effectiveness as LLM evaluation methods.
read the caption
Figure 1: Benchmark correlations (%) with Chatbot Arena Elo, against the total costs of evaluating a single GPT-3.5-Turbo-0125 model. MixEval and MixEval-Hard show the highest correlations with Arena Elo and Arena Elo (En) among leading benchmarks. We reference the crowdsourcing price for Amazon Mechanical Turk ($0.05 per vote) when estimating the cost of evaluating a single model on Chatbot Arena (approximately $2,936). Chatbot Arena is prohibitively expensive, while MixEval and MixEval-Hard are cheap and cost-effective alternatives. Details on the correlation and evaluation cost values are provided in Section E.
🔼 The figure shows the correlation between different benchmarks and Chatbot Arena Elo, plotted against their respective evaluation costs. MixEval and MixEval-Hard exhibit the highest correlation with Chatbot Arena Elo while having significantly lower costs compared to other benchmarks. This highlights the cost-effectiveness and accuracy of MixEval and MixEval-Hard as LLM evaluation methods.
read the caption
Figure 1: Benchmark correlations (%) with Chatbot Arena Elo, against the total costs of evaluating a single GPT-3.5-Turbo-0125 model. MixEval and MixEval-Hard show the highest correlations with Arena Elo and Arena Elo (En) among leading benchmarks. We reference the crowdsourcing price for Amazon Mechanical Turk ($0.05 per vote) when estimating the cost of evaluating a single model on Chatbot Arena (approximately $2,936). Chatbot Arena is prohibitively expensive, while MixEval and MixEval-Hard are cheap and cost-effective alternatives. Details on the correlation and evaluation cost values are provided in Section E.
🔼 This figure shows the correlation between various LLM benchmarks and Chatbot Arena Elo, plotted against their respective evaluation costs. MixEval and MixEval-Hard demonstrate the highest correlation with Chatbot Arena Elo, indicating strong alignment with human preferences, while being significantly more cost-effective than other benchmarks. The high cost of Chatbot Arena is highlighted, emphasizing the advantage of MixEval and MixEval-Hard.
read the caption
Figure 1: Benchmark correlations (%) with Chatbot Arena Elo, against the total costs of evaluating a single GPT-3.5-Turbo-0125 model. MixEval and MixEval-Hard show the highest correlations with Arena Elo and Arena Elo (En) among leading benchmarks. We reference the crowdsourcing price for Amazon Mechanical Turk ($0.05 per vote) when estimating the cost of evaluating a single model on Chatbot Arena (approximately $2,936). Chatbot Arena is prohibitively expensive, while MixEval and MixEval-Hard are cheap and cost-effective alternatives. Details on the correlation and evaluation cost values are provided in Section E.
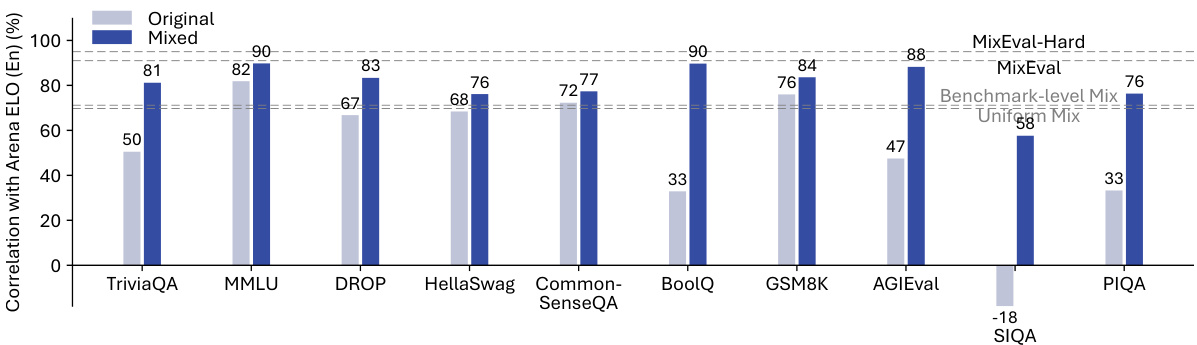
🔼 This figure shows the improvement in correlation with Arena Elo and Arena Elo (En) achieved by MixEval compared to the original benchmarks. It demonstrates that MixEval and MixEval-Hard significantly outperform both benchmark-level and uniform mixtures, highlighting the effectiveness of the proposed benchmark mixture technique in aligning with real-world user preferences. The figure presents bar charts showing correlations for various benchmark splits, with MixEval and MixEval-Hard consistently showing higher correlations than the other methods.
read the caption
Figure 5: Our approach improves the correlation with Arena Elo and Arena Elo (En) (Figure 12) for all the main splits of MixEval and outperforms benchmark-level and uniform mixture.
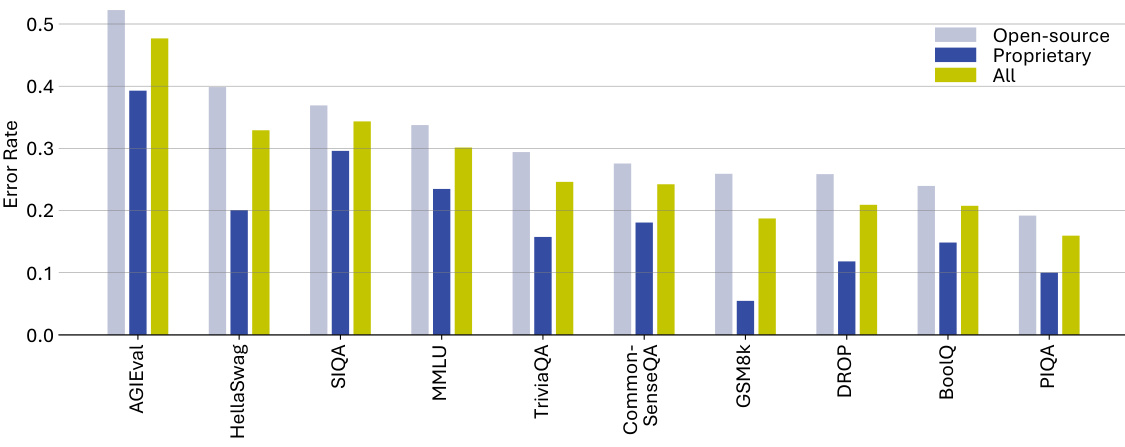
🔼 This figure shows the average error rates achieved by open-source, proprietary, and all models across different splits of the MixEval benchmark. The x-axis represents the different benchmark splits (AGIEval, HellaSwag, SIQA, MMLU, TriviaQA, CommonSenseQA, GSM8k, DROP, BoolQ, PIQA), and the y-axis represents the average error rate. Three bars are presented for each split, indicating the performance of open-source models, proprietary models, and the overall average error rate across all models.
read the caption
Figure 13: Averaged error rates of open-source, proprietary, and all models on MixEval splits.
🔼 This figure compares the correlation of various LLM benchmarks with Chatbot Arena Elo against their evaluation costs. MixEval and MixEval-Hard demonstrate the highest correlation while having significantly lower costs compared to other benchmarks like MMLU and Chatbot Arena.
read the caption
Figure 1: Benchmark correlations (%) with Chatbot Arena Elo, against the total costs of evaluating a single GPT-3.5-Turbo-0125 model. MixEval and MixEval-Hard show the highest correlations with Arena Elo and Arena Elo (En) among leading benchmarks. We reference the crowdsourcing price for Amazon Mechanical Turk ($0.05 per vote) when estimating the cost of evaluating a single model on Chatbot Arena (approximately $2,936). Chatbot Arena is prohibitively expensive, while MixEval and MixEval-Hard are cheap and cost-effective alternatives. Details on the correlation and evaluation cost values are provided in Section E.
More on tables

🔼 This table presents the results of a stability test for the dynamic benchmarking approach used in MixEval. Five different LLMs were evaluated across five different versions of the MixEval benchmark. The table shows the average score and standard deviation for each model across the versions, demonstrating high stability. It also shows the percentage of unique web queries and benchmark queries across the different versions, highlighting the significant changes in data between versions despite model score stability. This demonstrates the effectiveness of the dynamic updating mechanism in mitigating benchmark contamination.
read the caption
Table 2: Stability test for dynamic benchmarking. Five models tested across five updated versions of MixEval show an average mean of 77.64 and a Std. of 0.36, validating the stability of model scores over versions. The unique web query ratio, averaged across all version pairs, is 99.71%, and the unique benchmark query ratio is 85.05%, indicating significant differences between versions.
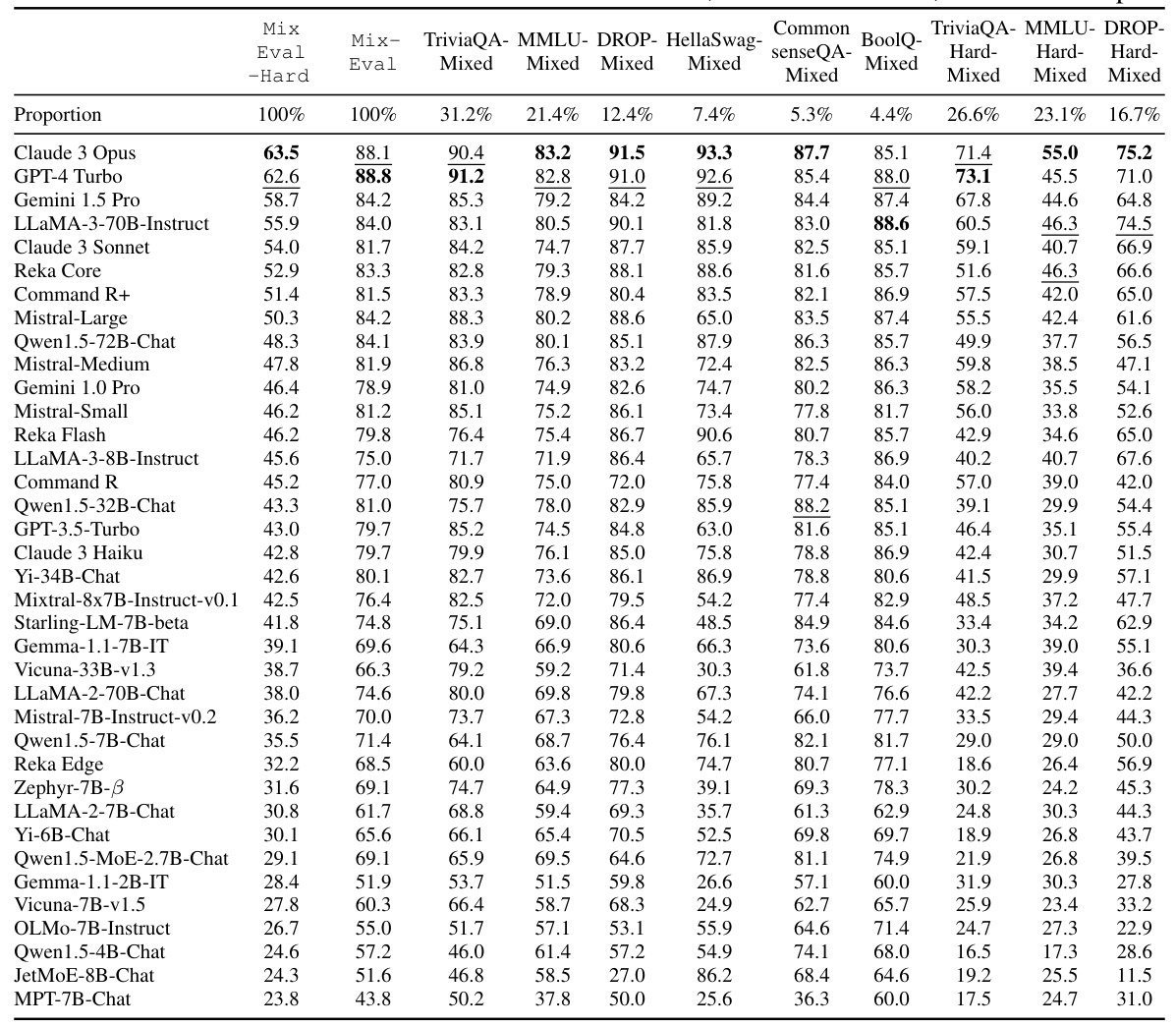
🔼 This table presents the detailed evaluation results of various chat models on MixEval, MixEval-Hard, and their main subsets. It shows the performance scores of each model across different subsets of the benchmarks, allowing for a comparison of model capabilities across various task complexities and distributions. The proportion of each benchmark included in each subset is also shown.
read the caption
Table 3: The Evaluation results of chat models on MixEval, MixEval-Hard, and their sub-splits.
Full paper#