TL;DR#
Current dynamic scene reconstruction methods often struggle with inaccurate object motion modeling, leading to suboptimal results. Many existing approaches lack explicit constraints on object movement, hindering optimization and performance. They often rely solely on appearance-based supervision for dynamic scene reconstruction. This makes them susceptible to optimization difficulties and degraded performance, especially when object movements are irregular or complex.
MotionGS tackles these challenges by incorporating explicit motion priors to guide 3D Gaussian deformation. It achieves this by decoupling optical flow into camera and object motion, allowing for precise motion guidance. Furthermore, a camera pose refinement module iteratively optimizes 3D Gaussians and camera poses, mitigating the impact of inaccurate initial camera estimates. Extensive experiments demonstrate that MotionGS significantly outperforms state-of-the-art methods in both qualitative and quantitative evaluations, showcasing its effectiveness and robustness in handling complex dynamic scenes. This approach offers a significant advancement in accurate and efficient dynamic scene reconstruction.
Key Takeaways#
Why does it matter?#
This paper is important because it presents MotionGS, a novel framework that significantly improves dynamic scene reconstruction. It addresses limitations of existing methods by explicitly incorporating motion priors, leading to more accurate and robust results, particularly for complex scenes. This work opens new avenues for research in real-time dynamic scene understanding and novel view synthesis, with potential applications in AR/VR, film, and robotics.
Visual Insights#

🔼 This figure demonstrates the concept of Gaussian flow and how it’s used to guide the deformation of 3D Gaussians in MotionGS. (a) shows that using motion flow directly as supervision (right) gives better deformation results than using overall optical flow (left) because the motion flow isolates object movement from camera movement. (b) illustrates how MotionGS decouples the optical flow into camera flow (due to camera movement) and motion flow (due to object motion). This separation is crucial for isolating and accurately representing object motion, which is then used to guide the deformation of Gaussians, leading to more accurate motion representation in dynamic scene reconstruction.
read the caption
Figure 1: (a) Gaussian flow under different supervision. We model Gaussian flow under the supervision of optical flow and motion flow respectively. The latter can produce a more direct description of object motion, thereby effectively guiding the deformation of 3D Gaussians. (b) The decoupling of optical flow. We decouple the optical flow into motion flow which is only related to object motion and camera flow which is only related to camera motion.
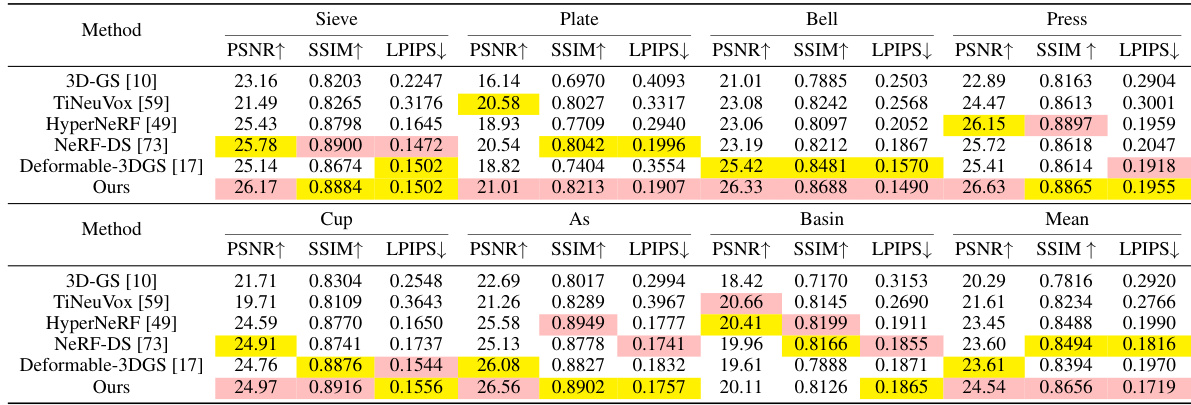
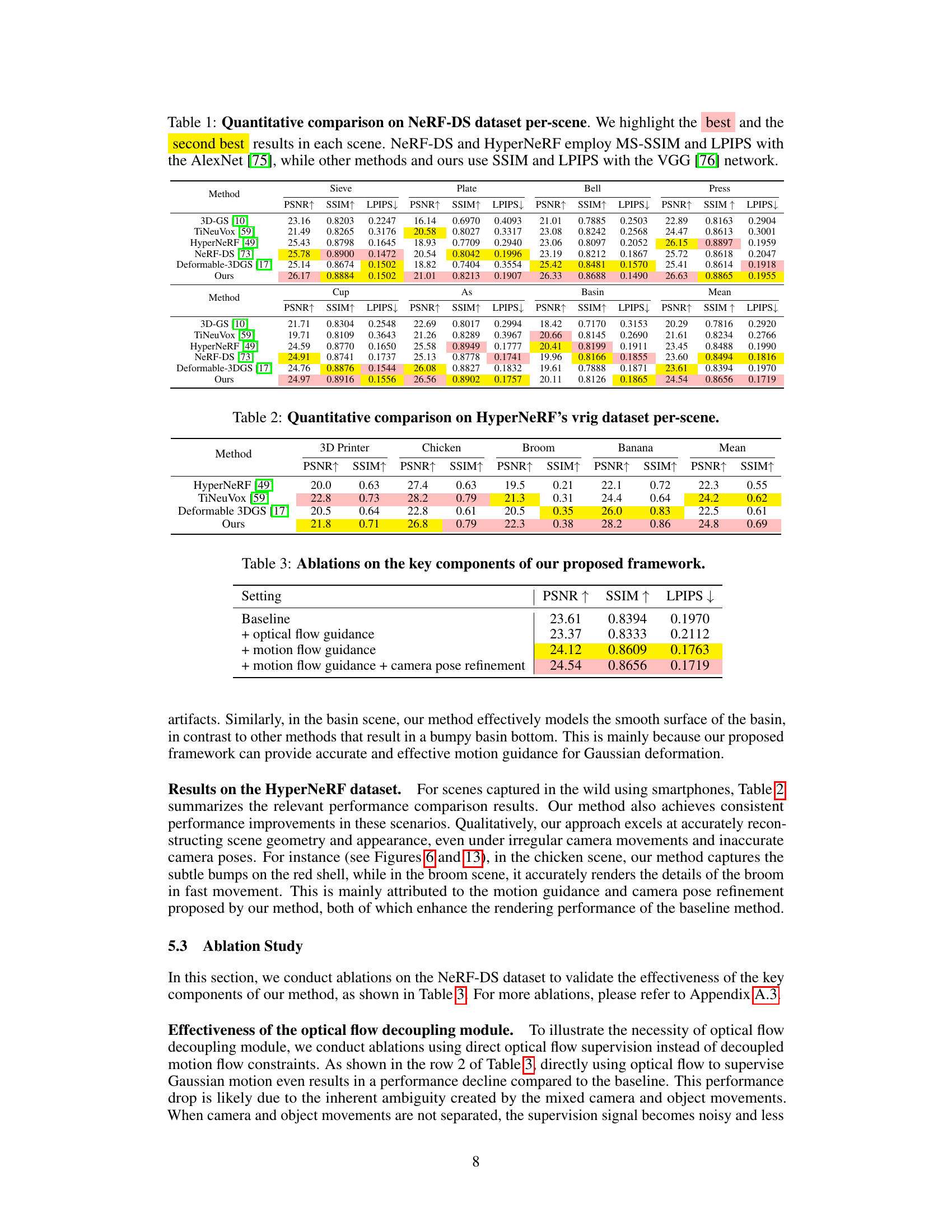
🔼 This table presents a quantitative comparison of different methods on the NeRF-DS dataset for dynamic scene reconstruction. It shows the PSNR, SSIM, and LPIPS scores for each scene and method, highlighting the best and second-best performing methods. Note that different metrics and network backbones were used for HyperNeRF and the other methods.
read the caption
Table 1: Quantitative comparison on NeRF-DS dataset per-scene. We highlight the best and the second best results in each scene. NeRF-DS and HyperNeRF employ MS-SSIM and LPIPS with the AlexNet [75], while other methods and ours use SSIM and LPIPS with the VGG [76] network.
In-depth insights#
Motion Guidance#
The concept of ‘Motion Guidance’ in the context of dynamic scene reconstruction using 3D Gaussian splatting is crucial for achieving accurate and realistic results. It tackles the challenge of effectively representing and rendering the movement of objects within a scene. A key aspect is the decoupling of optical flow into camera motion and object motion, which allows for more precise isolation of the object’s movement. By using this motion flow, the deformation of 3D Gaussians is directly constrained, leading to a more accurate simulation of object dynamics. Explicit motion guidance helps overcome difficulties arising from irregular or sudden movements that could otherwise lead to optimization issues or suboptimal results. Further, a camera pose refinement module, working in conjunction with motion guidance, helps to mitigate errors arising from inaccurate camera pose estimates. This combined approach yields superior performance in dynamic scene reconstruction, exhibiting significant improvements over methods lacking explicit motion constraints, both qualitatively and quantitatively.
Optical Flow#
Optical flow, the apparent motion of objects in a visual field, plays a crucial role in the paper. The authors cleverly decouple optical flow into camera flow and object motion flow, overcoming the limitations of prior methods that used total optical flow without distinguishing between camera movement and object movement. This decoupling is achieved using depth information, enabling precise modeling of object movement independent of camera motion. The resulting motion flow directly guides the deformation of 3D Gaussians, providing explicit constraints and significantly enhancing the accuracy and quality of dynamic scene reconstruction. This strategy is particularly beneficial for handling irregular object movements, where reliance solely on appearance-based methods leads to optimization difficulties. The precise modeling of motion, facilitated by the refined optical flow method, is a key contribution to the paper’s state-of-the-art performance. The results highlight the superiority of using explicitly motion-guided deformation over methods that rely solely on appearance-based supervision for dynamic scene reconstruction.
Deformable 3DGS#
Deformable 3D Gaussian Splatting (Deformable 3DGS) represents a significant advancement in dynamic scene reconstruction. It leverages the efficiency and high-quality rendering capabilities of 3D Gaussian Splatting, extending its application to time-varying scenes. The core idea revolves around modeling the temporal evolution of 3D Gaussian primitives, effectively representing object motion and deformations. Unlike earlier approaches that lacked explicit motion guidance, Deformable 3DGS often incorporates techniques like optical flow estimation or deformation fields to capture and constrain object movements, resulting in improved accuracy and robustness. However, challenges remain, particularly in handling complex, irregular motions and achieving robustness to inaccurate camera pose estimations. Future research might focus on more sophisticated motion modeling, better handling of occlusion and other artifacts, and more efficient optimization techniques to fully unlock the potential of deformable 3DGS in various real-world applications.
Pose Refinement#
The concept of pose refinement in the context of dynamic scene reconstruction using 3D Gaussian Splatting is crucial for enhancing accuracy and robustness. Initial camera pose estimations, often obtained through methods like COLMAP, can be inaccurate, especially in complex dynamic scenes. Pose refinement modules iteratively optimize camera poses alongside 3D Gaussian parameters, mitigating the effects of these initial errors. This iterative approach, often alternating between optimizing Gaussian positions and camera poses, leverages photometric consistency loss to refine camera parameters. By decoupling optical flow into camera and object motion, the pose refinement process becomes more targeted, reducing reliance on potentially erroneous camera motion estimates. This process significantly improves rendering quality, generating more visually consistent and accurate reconstructions, particularly in challenging scenarios with significant object movement or sudden changes in camera viewpoint. The key is the interplay between accurate motion guidance from decoupled optical flow and iterative pose optimization. This approach tackles a major limitation of earlier 3D Gaussian Splatting methods that extended to dynamic scenes, significantly increasing performance in both quantitative and qualitative evaluations.
Future Work#
The paper’s conclusion suggests avenues for future research. Developing a 3D Gaussian Splatting method independent of camera pose inputs is a significant goal, promising robustness in dynamic scenes. This would address current limitations where inaccuracies in initial pose estimates hinder performance. Another area for exploration is handling complex dynamic scenes with more robust motion models and improved handling of occlusion and rapid motion. The current method struggles in scenarios with extremely rapid changes or significant occlusions, making improvements in these areas crucial for broader applicability. Further investigation into optimizing training efficiency is also warranted. While the paper demonstrates real-time capability, efficiency improvements will allow scaling to even larger or more complex datasets. Finally, exploring the application of the proposed optical flow decoupling and motion guidance techniques to other 3D scene representation methods beyond Gaussian splatting holds potential for broader impact. This would demonstrate the generality and utility of the central idea, moving beyond a specific implementation.
More visual insights#
More on figures
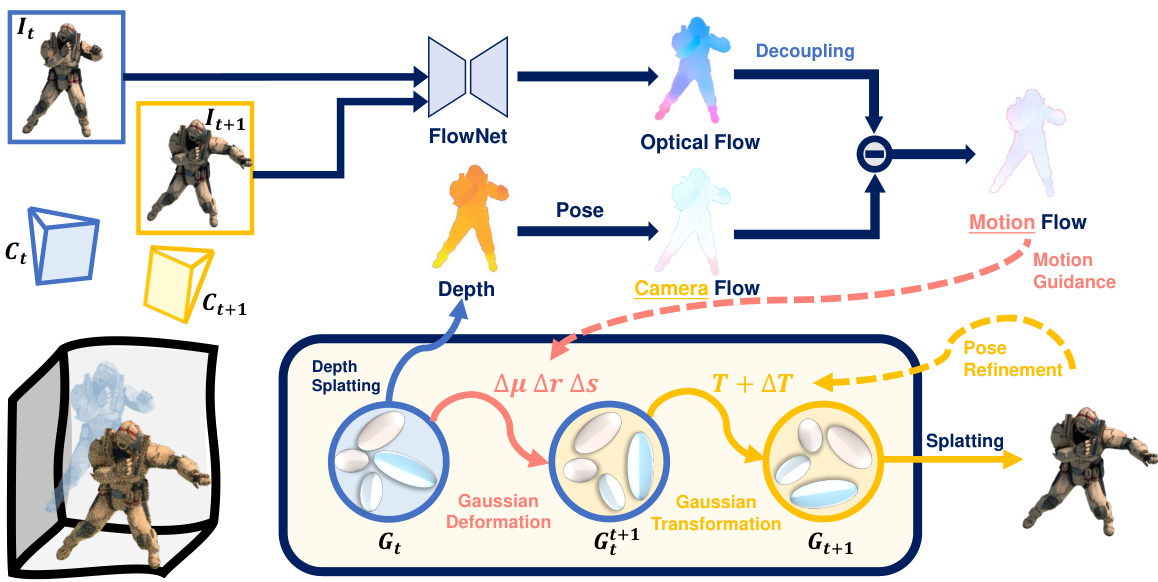
🔼 This figure illustrates the MotionGS framework’s architecture. It shows two main data streams: a 2D stream processing optical flow to extract motion information for guiding Gaussian deformation and a 3D stream handling the deformation and rendering of 3D Gaussians. The figure highlights the optical flow decoupling module, which separates camera and object motion, and the camera pose refinement module, which iteratively optimizes camera poses and 3D Gaussians for improved accuracy.
read the caption
Figure 2: The overall architecture of MotionGS. It can be viewed as two data streams: (1) The 2D data stream utilizes the optical flow decoupling module to obtain the motion flow as the 2D motion prior; (2) The 3D data stream involves the deformation and transformation of Gaussians to render the image for the next frame. During training, we alternately optimize 3DGS and camera poses through the camera pose refinement module.
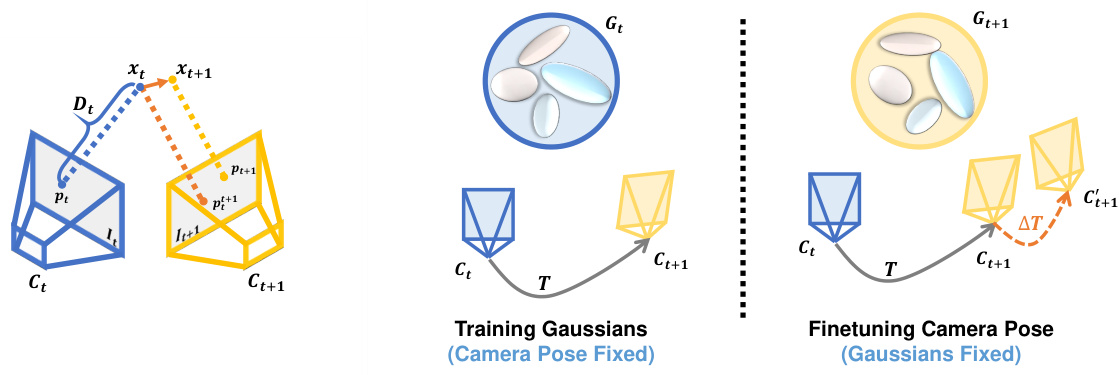
🔼 This figure shows two subfigures. The left subfigure (Figure 3) illustrates the calculation of camera flow and motion flow from optical flow. It shows how camera poses and depth are used to calculate camera flow, and how object motion is extracted to obtain motion flow. The right subfigure (Figure 4) illustrates the camera pose refinement module, showing how camera poses are optimized iteratively with 3D Gaussians fixed, and then 3D Gaussians are optimized with camera poses fixed, enhancing the rendering quality and robustness. This iterative process refines camera poses by alternating between optimizing 3D Gaussians while keeping camera poses fixed and optimizing camera poses while keeping 3D Gaussians fixed.
read the caption
Figure 3: Flow calculation. Figure 4: Pose refinement on iterative training.

🔼 This figure shows a qualitative comparison of the results from different methods on the NeRF-DS dataset, focusing on the ‘basin’ and ‘plate’ scenes. It visually demonstrates the performance differences between the proposed MotionGS method, the Deformable 3DGS baseline, NeRF-DS, and the original 3DGS. The ground truth is also included for each scene to provide a direct comparison.
read the caption
Figure 5: Qualitative comparison on NeRF-DS dataset. Refer to Figure 12 for more scenes.

🔼 This figure shows a qualitative comparison of the results from different methods on the HyperNeRF dataset. The top row shows the ground truth frames of two scenes (Chicken and Broom). Subsequent rows compare the reconstructions produced by the proposed MotionGS method against the baseline deformable 3DGS method and the original 3DGS method. This visual comparison aims to demonstrate the superior quality of the MotionGS reconstructions in terms of detail, accuracy, and artifact reduction, especially in dynamic scenes with complex movements and irregular motion patterns.
read the caption
Figure 6: Qualitative comparison on HyperNeRF dataset. Refer to Figure 13 for more scenes.

🔼 This figure visualizes the data flow in MotionGS. It shows two examples, each occupying two rows. The top row of each example displays (from left to right): the current frame’s image; the next frame’s image; the rendered image (output of MotionGS); and the rendered depth map. The bottom row of each example shows (from left to right): the calculated optical flow; the camera flow (optical flow caused by camera movement only); the motion flow (optical flow caused by object movement only); and the Gaussian flow (the 2D projection of Gaussian deformation). This helps to illustrate how MotionGS decouples optical flow into camera and object motion, using the latter to guide the deformation of 3D Gaussians.
read the caption
Figure 7: Visualization of all data flows. Each example corresponds to two rows.

🔼 This figure compares the camera trajectories estimated by the proposed MotionGS method and the COLMAP method. The red lines represent the camera trajectories optimized by MotionGS, demonstrating its ability to refine camera poses. The blue dotted lines show the camera trajectories estimated by COLMAP. The comparison visually highlights the improvement in accuracy and robustness achieved by MotionGS, particularly in complex dynamic scenes where COLMAP might struggle due to rapid movements and inaccurate initialization.
read the caption
Figure 8: Visualization of the camera trajectories optimized by our method and COLMAP.
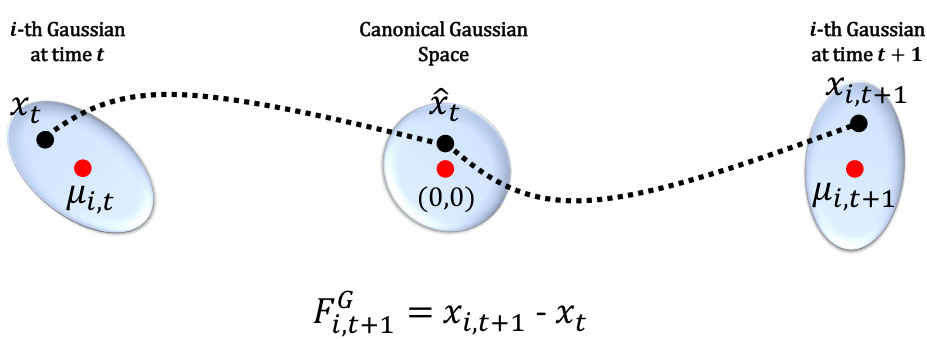
🔼 This figure illustrates the process of calculating Gaussian flow. First, a point representing the i-th Gaussian at time t is projected into a canonical Gaussian space (centered at (0,0)). Then, this point is reprojected from the canonical space to the location of the i-th Gaussian at time t+1. The difference between these two projected points ( ) represents the Gaussian flow for the i-th Gaussian, indicating its movement between the two time steps.
read the caption
Figure 9: The formulation of Gaussian flow. We first project the point corresponding to the i-th Gaussian at time t into the canonical Gaussian space, and then reproject this point from the canonical Gaussian space to the i-th Gaussian at time t + 1.

🔼 This figure compares the rendered depth maps generated by the proposed method and an off-the-shelf monocular depth estimator (MiDaS). The top row shows the depth maps produced by the proposed method, highlighting richer details and better scale alignment with the actual scene. The bottom row displays the depth maps from MiDaS, which appear smoother but suffer from scale ambiguity, indicating less accurate depth estimation.
read the caption
Figure 10: Rendered depth from 3D Gaussian splatting (ours) and off-the-shelf monocular depth estimator (MiDas). Our rendered depth has richer details and is scale-aligned with the scene. MiDas rendered depth is usually more smooth and suffers from scale ambiguity.

🔼 This figure shows a failure case of the MotionGS method on the DyNeRF dataset. The DyNeRF dataset uses fixed and sparsely sampled viewpoints, which means there is less information available for accurate depth and motion estimation. Because of this, neither using motion flow nor optical flow as supervision is able to prevent floating artifacts (visual distortions where objects appear to be slightly detached from the background). This highlights a limitation of MotionGS in scenes with limited viewpoints.
read the caption
Figure 11: Failure case in DyNeRF dataset. Since the viewpoints are fixed and sparse, neither motion flow nor optical flow can help our method avoid floating artifacts.

🔼 This figure compares the visual results of the proposed MotionGS method with several other state-of-the-art methods on the NeRF-DS dataset. It shows a qualitative comparison, focusing on several different scenes involving dynamic objects. Each row represents a different scene from the dataset. The columns showcase the Ground Truth, the results from the proposed MotionGS method, the results from Deformable 3DGS, the results from NeRF-DS and finally, the results from 3DGS. The comparison highlights the superior visual quality and detail preservation of the MotionGS method, particularly when rendering dynamic elements in the scene.
read the caption
Figure 12: Qualitative comparison on NeRF-DS dataset per-scene. Compared with the state-of-the-art methods, our method can render more reasonable details, especially on dynamic objects.

🔼 This figure displays a qualitative comparison of the results obtained using different methods on the HyperNeRF dataset. The ground truth frames are compared with the results generated by the proposed MotionGS method, the Deformable 3DGS method, and the 3DGS method. It visually demonstrates the improved accuracy and details captured by MotionGS, especially in handling complex and dynamic movements. More detailed comparisons for additional scenes are available in Figure 13.
read the caption
Figure 6: Qualitative comparison on HyperNeRF dataset. Refer to Figure 13 for more scenes.

🔼 This figure shows a visualization of the data flows used in MotionGS. The first two columns show the ground truth images at time t and t+1. The next two columns are the rendered image and depth map at time t, which are inputs to the model. The remaining four columns show the optical flow, camera flow, motion flow, and Gaussian flow. The figure visually demonstrates the steps involved in decoupling the optical flow into camera and object motion, and how the motion flow is used to guide the deformation of 3D Gaussians.
read the caption
Figure 14: Visualization of all data flows. In order: ground truth of It, ground truth of It+1, rendered image of It, rendered depth of frame It, optical flow, camera flow, motion flow, Gaussian flow.
More on tables

🔼 This table presents a quantitative comparison of different methods on the HyperNeRF’s vrig dataset. It shows the PSNR and SSIM scores for each method across four different scenes within the dataset. Higher PSNR and SSIM values indicate better performance in terms of image quality and similarity to the ground truth.
read the caption
Table 2: Quantitative comparison on HyperNeRF's vrig dataset per-scene.

🔼 This table presents the ablation study results, comparing the performance of the proposed MotionGS framework with different components. It shows the impact of adding optical flow guidance, using motion flow instead of optical flow, and finally incorporating camera pose refinement. The metrics used for evaluation are PSNR, SSIM, and LPIPS.
read the caption
Table 3: Ablations on the key components of our proposed framework.

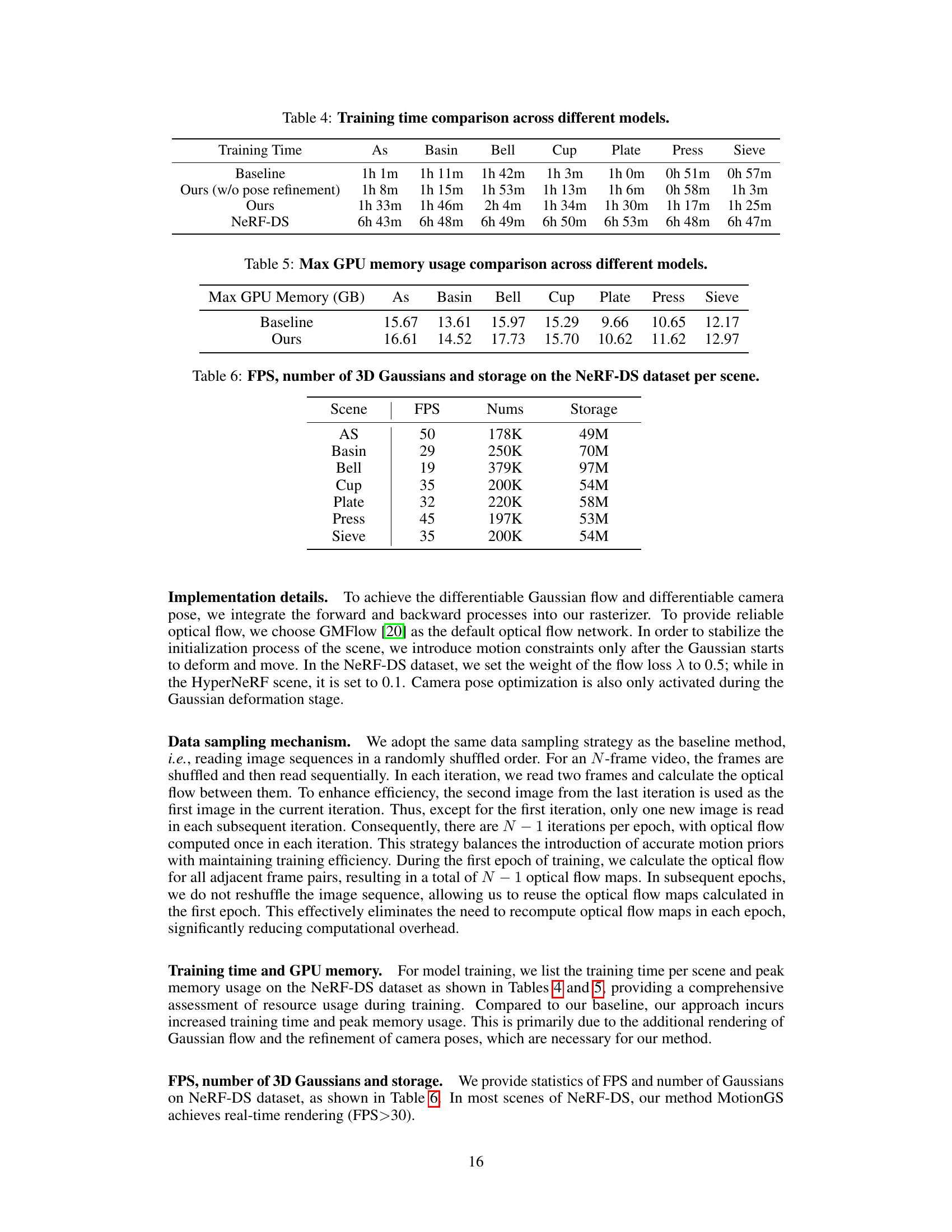
🔼 This table presents a comparison of the training time required for different models, including the baseline and the proposed methods with and without pose refinement, across various scenes from the NeRF-DS dataset. The results showcase the computational efficiency of the models and provide insights into the impact of model components (like pose refinement) on training time.
read the caption
Table 4: Training time comparison across different models.

🔼 This table compares the maximum GPU memory usage (in GB) required by the baseline method and the proposed MotionGS method for each scene in the NeRF-DS dataset. It provides insights into the computational cost and resource requirements of both approaches for different scene complexities.
read the caption
Table 5: Max GPU memory usage comparison across different models.
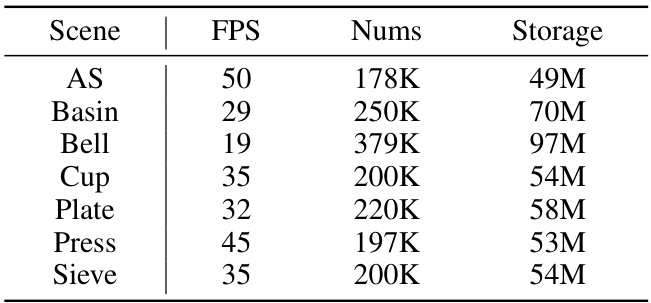
🔼 This table presents a quantitative evaluation of the MotionGS model on the NeRF-DS dataset. It shows the frames per second (FPS), the number of 3D Gaussians used in the model’s representation, and the total storage required for each scene in the dataset. This allows for a comparison of the model’s efficiency and performance across different scene complexities.
read the caption
Table 6: FPS, number of 3D Gaussians and storage on the NeRF-DS dataset per scene.

🔼 This table presents ablation studies on different components of the MotionGS framework. It shows the impact of removing the motion mask, using different depth estimation methods, different optical flow networks, a self-supervised flow supervision loss, and varying the weight of the flow loss. The results highlight the importance of each component in achieving optimal performance.
read the caption
Table 7: Ablations on other choices of our proposed framework. For fair comparison, we do not activate the proposed camera pose refinement module during training.
Full paper#