TL;DR#
The research explores the differences in how Transformers and Recurrent Neural Networks (RNNs) represent information, particularly focusing on the size of the model needed to perform different tasks. It highlights the existing debate in the field about the practical tradeoffs between these architectures in building large language models. The study identifies a significant issue: Transformers are computationally expensive for large-scale applications, leading researchers to explore more efficient RNN alternatives. However, there’s a lack of understanding about the relative representational power of each architecture.
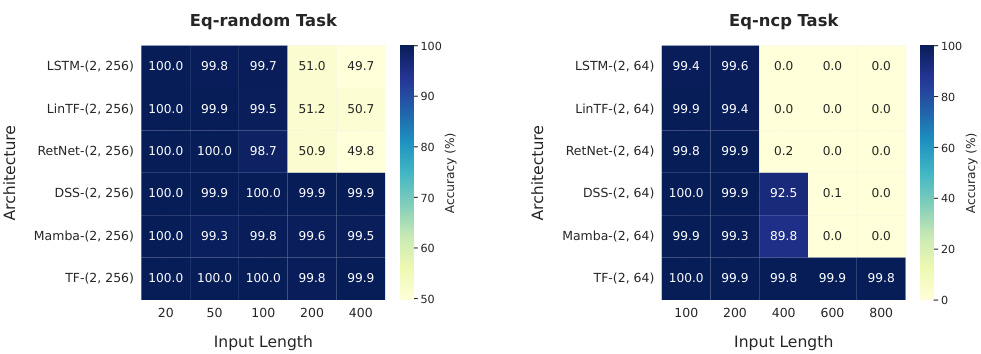
The paper addresses this gap by analyzing the performance of Transformers and RNNs on various tasks including index lookup, nearest neighbor search, Dyck language recognition and string equality. It establishes theoretical lower bounds on model size for RNNs and one-layer Transformers on specific tasks and provides explicit constructions of two-layer Transformers with polylogarithmic sizes to achieve the same. Experiments show a consistent gap between the performance of the two models supporting the theoretical results.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI researchers as it provides a theoretical understanding of the representational capabilities of Transformers and RNNs, offering insights into their relative strengths and weaknesses on various tasks. This directly impacts the design and application of these architectures in real-world problems, particularly in the development of efficient and effective large language models. The lower bounds and theoretical results will guide future work in optimizing the size and efficiency of these models.
Visual Insights#

🔼 This figure shows three tasks that are considered in the paper. (a) Index Lookup Task: A model receives a sequence of tokens, then an index, and must output the token at that index. (b) Bounded Dyck-2 with depth ≤ 2: The model must decide if a sequence of parentheses is well-balanced, with a maximum nesting depth of 2. (c) Nearest Neighbor Task: The model receives a sequence of input-label pairs, then a query input, and must predict the closest matching label using the nearest-neighbor algorithm.
read the caption
Figure 1: Illustration of a few key tasks considered in our work.
In-depth insights#
Transformer Limits#
The heading ‘Transformer Limits’ suggests an exploration of the boundaries of transformer models’ capabilities. A thoughtful analysis would likely cover several key aspects. Computational cost is a major concern; transformers’ quadratic complexity in sequence length renders them impractical for extremely long sequences. Theoretical limitations concerning expressivity and the types of problems transformers can efficiently solve (e.g., compared to RNNs) would be crucial. Architectural constraints inherent in the attention mechanism (like difficulty in handling long-range dependencies effectively or limitations on memory) are worth examining. Finally, a discussion on practical limitations would address issues like data requirements for training massive models, and the environmental impact of their significant energy consumption. A comprehensive examination would combine theoretical analyses with empirical evidence, highlighting both the impressive achievements and inherent challenges posed by these powerful, but resource-intensive models.
RNN Capacity#
Recurrent Neural Networks (RNNs), while celebrated for their ability to process sequential data, possess inherent limitations in their representational capacity. The fundamental constraint lies in their reliance on a fixed-size hidden state vector to encode information from the entire input sequence. As the length of the sequence grows, the RNN’s capacity to distinguish between different inputs can quickly saturate. This leads to a critical limitation: RNNs struggle to learn tasks that necessitate remembering long-range dependencies or maintaining a large number of distinct states. This is in sharp contrast to Transformers, which can leverage attention mechanisms to relate any two tokens in the sequence regardless of their distance, overcoming RNNs’ short-term memory bottleneck. However, RNNs also exhibit strengths: their capacity scales linearly with their hidden state size, allowing for straightforward scaling of memory capacity. This contrasts with Transformers, where the quadratic dependency on sequence length of the attention mechanism poses scaling challenges. While the theoretical capacity of RNNs is well understood, the practical implications of the fixed-size hidden state remain a significant obstacle for complex, long-range dependencies. Research in state-space models aims to address some of these issues by cleverly managing memory usage, highlighting an ongoing exploration of overcoming these inherent representational limitations.
2-Layer Boost#
A hypothetical ‘2-Layer Boost’ heading in a research paper likely refers to a method or architecture involving two layers to enhance performance. This could manifest in several ways. It might describe a two-stage boosting algorithm, where the first layer trains a base model, and a second layer refines its predictions based on the errors of the first. Alternatively, it could detail a neural network architecture with two distinct layers designed for a specific task, perhaps each with different functionalities or activation functions. The second layer could be a form of ‘boosting’ compared to the first. The ‘boost’ could refer to increased accuracy, speed, or efficiency—a significant improvement over a single-layer approach. The exact nature of this boost and its underlying mechanisms would depend heavily on the specific context within the paper. For instance, it might involve an innovative approach to combining predictions from different models, or it could leverage advanced training techniques to achieve better generalization. Analyzing the ‘2-Layer Boost’ section would require close attention to the techniques used, the specific task addressed, and the metrics employed to measure the boost—understanding these details is key to interpreting the overall contribution.
Empirical Tests#
An Empirical Tests section in a research paper would ideally present experimental results that corroborate the theoretical claims made earlier. It should begin by clearly describing the experimental setup, including the datasets used, model architectures, training parameters, and evaluation metrics. Detailed methodology is key to reproducibility. The presentation of results should be clear and concise, likely using tables and figures to showcase performance across different tasks or model variations. The choice of statistical tests to determine significance should be justified, and error bars or confidence intervals would bolster the reliability of the findings. A discussion comparing performance across different models or hyperparameter settings is crucial; it should carefully assess whether observed differences are statistically significant and align with the theoretical expectations. Finally, any unexpected findings or limitations in the experimental results should be frankly acknowledged and discussed to add nuance to the conclusions. The core aim is to offer robust and transparent evidence supporting or challenging the study’s main claims.
Future Work#
Future research directions stemming from this work could involve several key areas. Extending the theoretical analysis to encompass more complex architectures, such as multi-layer Transformers with more than two layers, is crucial for a complete understanding of representational capabilities. Investigating the impact of different attention mechanisms and their effect on task performance would provide further insights into the strengths and weaknesses of various Transformer designs. Empirical studies focusing on larger-scale datasets and real-world applications are needed to validate the theoretical findings and assess practical implications. Finally, a deeper exploration of the relationship between model size, input length, and task complexity across different architectures may uncover additional fundamental trade-offs, leading to improved model designs and training strategies. In particular, it would be important to investigate ways of bridging the gap between theoretical model size and the practical realities of model deployment, considering factors such as memory constraints and inference time.
More visual insights#
More on figures
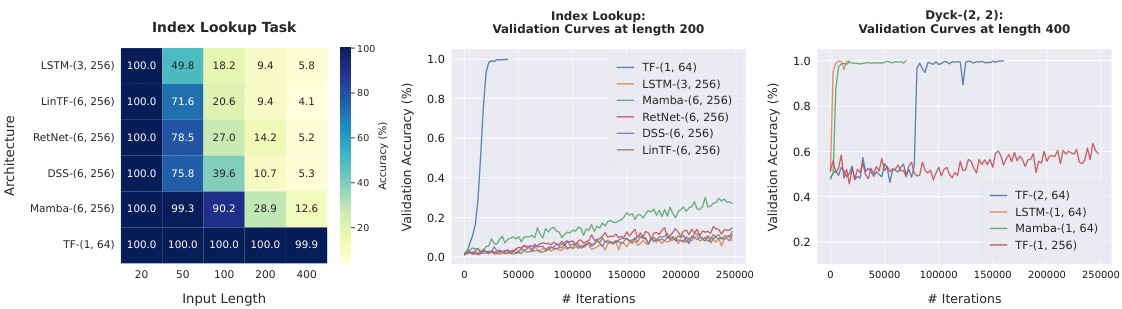
🔼 This figure presents the performance of different recurrent neural network architectures and transformer models on two tasks: Index Lookup and recognizing bounded Dyck languages. The Index Lookup task involves predicting a token at a given index in a sequence. The bounded Dyck language task involves determining whether a sequence of parentheses is correctly balanced. The heatmaps show the accuracy of different models at various sequence lengths. The line graphs showcase the validation accuracy during training on specific sequence lengths.
read the caption
Figure 2: Performance of models on the Index Lookup and bounded Dyck task. Labels such as TF-(1, 64) denote Transformers with 1 layer and 64 widths. See Section 6 for more details.

🔼 This figure shows the performance of the Mamba recurrent model on the Index Lookup task for various sequence lengths (20, 50, 75, 100, 200, 400) and hidden state sizes (32, 64, 256, 512, 1024). The heatmap on the left displays the accuracy for each length and width combination. The line graph on the right shows the validation accuracy curves during training, highlighting the learning progress for different model sizes. The results indicate that Mamba’s performance on the Index Lookup task improves with increasing width, but still significantly lags behind the performance of one-layer Transformers.
read the caption
Figure 3: Performance of Mamba on the Index Lookup task across various lengths and widths. See Section H.1 for more details.
🔼 The figure displays the performance of various recurrent neural network models (LSTMs, DSS, RetNet, Mamba) and transformer models (one-layer and two-layer) on the Index Lookup and bounded Dyck tasks. The left panel shows validation accuracy at different input sequence lengths. The center and right panels present the validation accuracy curves across training iterations for the Index Lookup and Dyck tasks respectively. The results highlight the performance differences between the models across different tasks and sequence lengths.
read the caption
Figure 2: Performance of models on the Index Lookup and bounded Dyck task. Labels such as TF-(1, 64) denote Transformers with 1 layer and 64 widths. See Section 6 for more details.
Full paper#



















