TL;DR#
Current pose-guided person image generation methods struggle with generating multiple images with different poses or using multiple source images. These limitations restrict the flexibility and practical application of the technology. Existing methods often overlook critical texture details due to relying on generic image encoders, leading to less realistic results.
IMAGPose introduces a unified framework to address these limitations. It uses three key modules: Feature-Level Conditioning (FLC) to combine low-level texture with high-level semantic features for improved detail; Image-Level Conditioning (ILC) to handle flexible input (multiple images/poses); and Cross-View Attention (CVA) for image consistency. Extensive experiments demonstrate IMAGPose’s superiority over existing methods in terms of image quality and consistency across various user scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a unified framework for pose-guided person image generation, addressing limitations of existing methods and opening new avenues for research in image synthesis and related applications. Its unified approach, handling multiple poses and views, is particularly relevant to researchers working on person re-identification and other downstream tasks where image fidelity and consistency are crucial. The work also contributes new modules such as the Feature-Level Conditioning (FLC) module and the Cross-View Attention (CVA) module. The code and model will be publicly available.
Visual Insights#

🔼 This figure illustrates the limitations of existing pose-guided person generation methods. It shows that current techniques can only handle the scenario where a single target image is generated from a single source image and a single target pose. The figure visually contrasts this limitation with the capabilities of the proposed IMAGPose method, which can handle more complex scenarios (generating multiple target images or using multiple source images).
read the caption
Figure 1: Existing methods can only support generating a target image from one source image and one target pose.
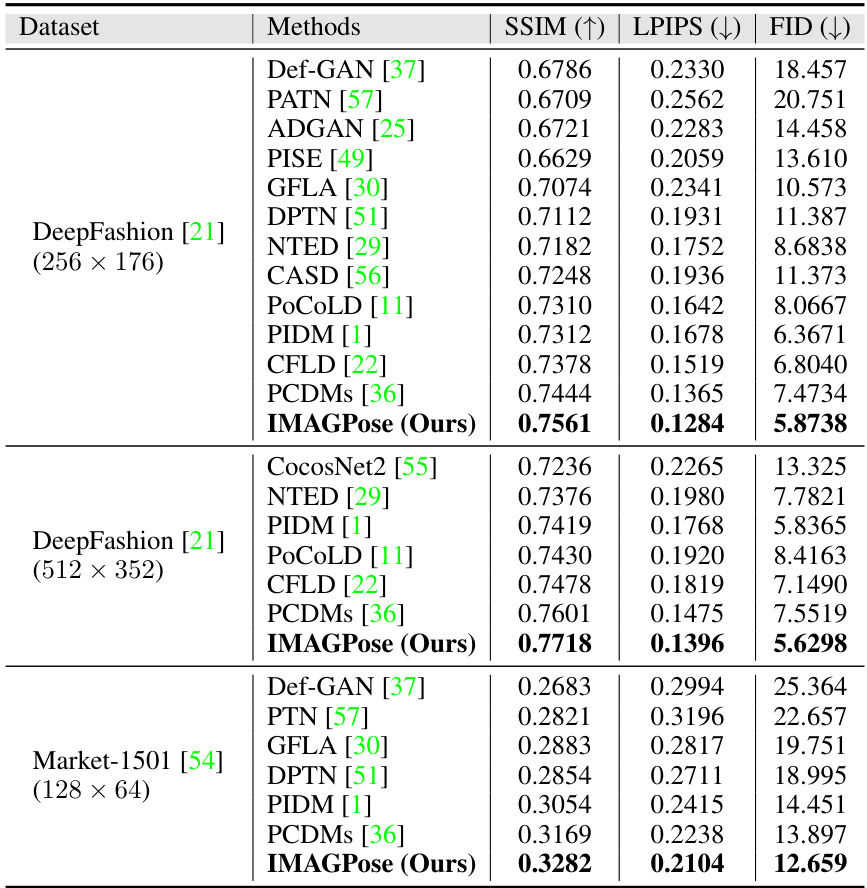
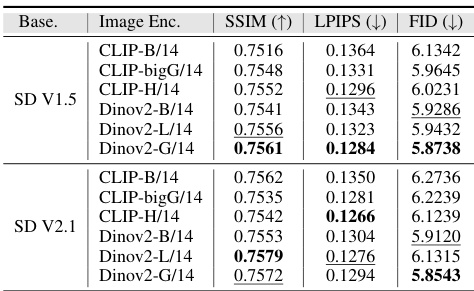
🔼 This table presents a quantitative comparison of the proposed IMAGPose model with several state-of-the-art models on three different datasets: DeepFashion (256x176), DeepFashion (512x352), and Market-1501 (128x64). The comparison is based on three metrics: Structural SIMilarity Index Measure (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and Fréchet Inception Distance (FID). Higher SSIM values indicate better structural similarity, lower LPIPS values indicate better perceptual similarity, and lower FID values indicate better overall image quality. The results show that IMAGPose outperforms other models on all three metrics across all datasets.
read the caption
Table 1: Quantitative comparison of the proposed IMAGPose with several state-of-the-art models.
In-depth insights#
Unified Pose Gen#
A hypothetical “Unified Pose Gen” framework in a research paper would likely address the limitations of current pose-guided person generation methods. Existing methods often struggle with generating diverse poses from a single image, handling multiple source images, and ensuring high-fidelity image generation. A unified approach would aim to solve these issues by incorporating multiple conditioning mechanisms, such as feature-level conditioning to incorporate low-level texture and high-level semantics, and image-level conditioning to leverage multiple source images or poses simultaneously. This would ideally improve both the realism and diversity of generated images, enabling flexible and consistent outputs across a wider range of user inputs. A key aspect would be the integration of advanced attention mechanisms, possibly cross-view attention, to resolve conflicts between the global structure and local details when using multiple sources. Ultimately, a successful “Unified Pose Gen” would provide a more robust and versatile tool for generating high-quality, diverse images from varied user input, leading to substantial improvements in applications such as virtual fashion, animation, and video game development.
FLC Module Design#
A thoughtfully designed Feature-Level Conditioning (FLC) module is crucial for high-quality pose-guided person generation. The core idea is to effectively combine low-level texture details with high-level semantic features, overcoming the limitations of existing methods that primarily rely on high-level features alone. A successful FLC module should leverage a pre-trained Variational Autoencoder (VAE) to extract fine-grained texture information from the source image. This ensures that detailed visual information is preserved, improving the realism of generated images. Furthermore, the integration of high-level semantic features (e.g., from a CLIP or image encoder) is essential to maintain the consistency of appearance and identity. The fusion of these features can take various forms, such as concatenation or attention-based mechanisms, with the optimal approach needing careful design and evaluation. Careful consideration must be given to the dimensionality and representation of the combined features before feeding them into the subsequent stages of the generation pipeline. A well-designed FLC module is not just about combining features, but about ensuring that these features contribute effectively to the generation process, producing visually compelling and consistent outputs that adhere to the specified pose and preserve source image identity.
Multi-view Handling#
Handling multi-view data in person image generation presents a significant challenge. A single viewpoint often limits detail and realism. Methods incorporating multiple views must efficiently fuse information from different perspectives, avoiding conflicts and preserving the integrity of the generated image. Strategies for feature fusion are critical, possibly leveraging attention mechanisms to weigh information from each viewpoint based on its relevance and quality. A robust model should gracefully handle missing or low-quality views, employing techniques like data augmentation or imputation to maintain performance. Furthermore, the computational cost of processing multiple views needs careful consideration; efficient architectures and algorithms are essential for real-time or near real-time applications. Successfully addressing these aspects can dramatically improve the quality and consistency of generated person images, enhancing realism and enabling richer, more complex visualizations.
IMAGPose Limits#
While IMAGPose demonstrates significant advancements in pose-guided person generation, certain limitations warrant consideration. The handling of complex clothing and accessories remains a challenge, potentially leading to artifacts or inconsistencies in the generated images. The model’s performance might degrade with highly unusual poses or significant variations in body shape or size deviating from the training data distribution. Furthermore, the computational cost associated with generating multiple images simultaneously can be substantial, potentially hindering real-time applications. The reliance on a frozen VAE and image encoder might restrict the model’s ability to learn highly person-specific features, potentially impacting the quality and fidelity of the generated imagery. Lastly, the lack of extensive analysis of ethical concerns and potential biases present in the generated data remains an open area requiring further investigation.
Future Directions#
Future research directions for pose-guided person image generation should prioritize addressing limitations in handling complex scenarios. Improving the generation of high-fidelity details, especially in challenging poses and clothing textures, remains a key challenge. Furthermore, exploring methods that handle a larger number of simultaneous target image generations would significantly enhance practical usability. The current reliance on frozen encoders limits the potential for fine-grained control; therefore, investigating alternative strategies for incorporating source image information, such as integrating 3D pose estimation or other implicit representations, is essential. Finally, developing more robust evaluation metrics beyond existing metrics is crucial to accurately capture the multifaceted nature of image quality and overall consistency. Addressing these aspects would lead to more robust and versatile systems.
More visual insights#
More on figures
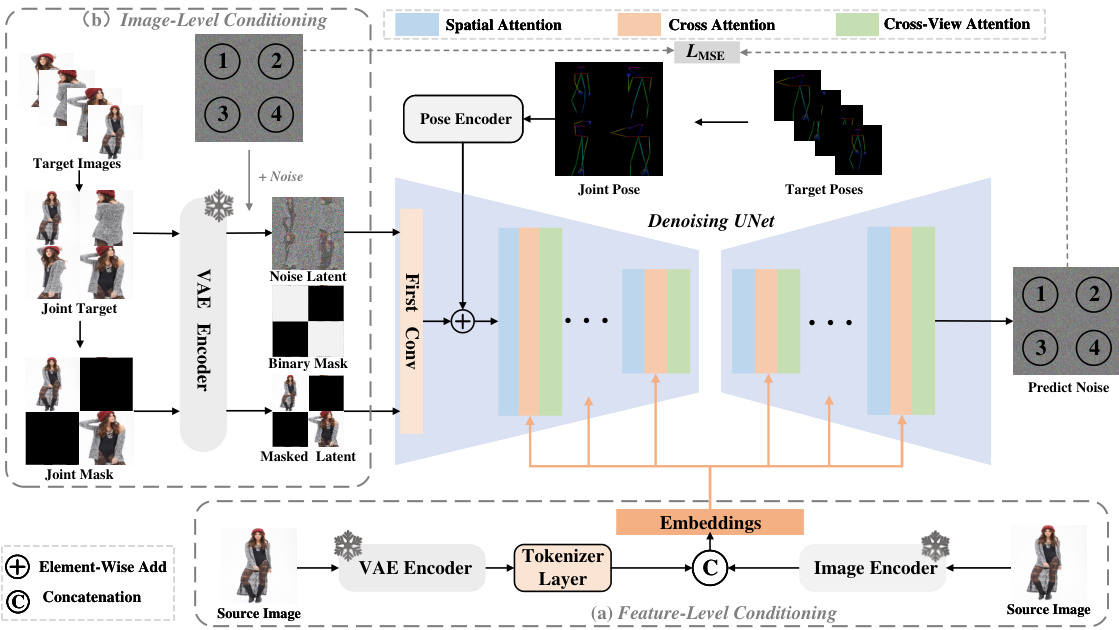
🔼 This figure illustrates the architecture of the IMAGPose model, a unified conditional framework for pose-guided person generation. It highlights the three main modules: Feature-Level Conditioning (FLC), Image-Level Conditioning (ILC), and Cross-View Attention (CVA). The FLC module addresses the issue of missing texture details by combining low-level and high-level features. The ILC module handles diverse user scenarios by injecting variable numbers of source images and using a masking strategy. The CVA module ensures image consistency by using a combination of global and local cross-attention. The figure shows the flow of data through these modules, starting from the source image and target pose(s) and culminating in the generation of high-quality target person images.
read the caption
Figure 2: The IMAGPose is a unified conditional framework designed to generate high-fidelity and high-quality target person images under various conditions. IMAGPose aims to address the issue of detail texture loss, achieve an alignment of person images and poses, and ensure the person images' local fidelity and global consistency.
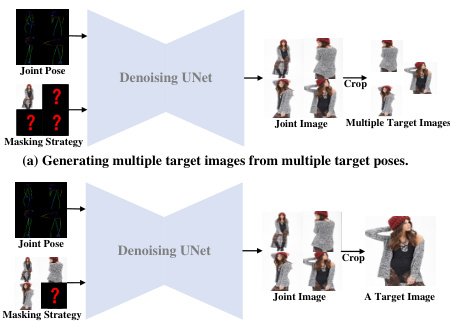
🔼 This figure illustrates how the masking strategy in the IMAGPose framework adapts to different user scenarios. Panel (a) shows the process of generating multiple target images from multiple target poses. The input includes multiple target poses and a single source image. The multiple target images are combined into a single ‘joint image’, then masked according to the masking strategy. A joint pose is also created. Panel (b) demonstrates the process of generating a single target image from multiple source images and a single target pose. This involves masking a single target image and combining it with multiple source images to create a ‘joint image’, along with the creation of a ‘joint pose’. The masking strategy ensures that the model can handle various inputs flexibly, allowing for different combinations of source images and target poses.
read the caption
Figure 3: The masking strategy flexibly unify different user scenarios.

🔼 The figure illustrates the Cross-View Attention (CVA) module’s architecture. The input feature is first split into four smaller local features. Each local feature then undergoes a projection, self-attention, and another projection before being joined back together to form a single output feature. This process allows the CVA module to capture both global and local relationships within the image.
read the caption
Figure 4: Illustration of the CVA module.

🔼 This figure presents a qualitative comparison of IMAGPose with other state-of-the-art models on the DeepFashion dataset. Each row shows the ground truth (GT), source image, target pose, and the results generated by various models including ADGAN, PISE, GFLA, DPTN, CASD, NTED, PIDM, PoCoLD, CFLD, PCDMs, and IMAGPose. The figure allows for visual evaluation of the different models’ performance in terms of image quality, clothing details, and pose accuracy.
read the caption
Figure 5: Qualitative comparisons with several state-of-the-art models on the DeepFashion dataset.

🔼 This figure presents a bar chart summarizing the results of a user study conducted on the DeepFashion dataset to evaluate the performance of IMAGPose and other state-of-the-art methods. The chart displays the percentage of images misclassified as real (G2R), the percentage of real images misclassified as generated (R2G), and the percentage of times a method’s generated images were judged as superior (Jab). Higher values in all three metrics indicate better performance. The results show that IMAGPose significantly outperforms other methods across all three metrics.
read the caption
Figure 6: User study results on DeepFashion in terms of R2G, G2R and Jab metric. Higher values in these three metrics indicate better performance.

🔼 This figure shows the quantitative comparison results of IMAGPose under three different user scenarios on the DeepFashion dataset. Scenario T1 replicates the target pose in the joint pose; T2 replicates the source image in the joint image; and T3 uses multiple different source images. The graph plots SSIM, LPIPS, and FID scores against training steps for each scenario. This demonstrates IMAGPose’s ability to adapt and maintain competitive performance across diverse user inputs.
read the caption
Figure 7: Quantitative comparison of IMAGPose under different user scenarios on the DeepFashion dataset.

🔼 This figure shows a comparison of the speed and performance (SSIM) of IMAGPose and several other state-of-the-art methods. IMAGPose demonstrates significantly faster generation speeds while maintaining competitive SSIM scores compared to methods like PoCoLD, PIDM, CFLD, and PCDMs. The results highlight the efficiency gains achieved by IMAGPose’s architecture.
read the caption
Figure 8: Results of speed and performance.

🔼 This figure shows visual results comparing the performance of IMAGPose across three different user scenarios. The first three columns demonstrate the generation of a single target image from a single source image and a single target pose, with variations in the way the input data is handled (T1, T2, T3). The last column (IMAGPose*) shows the generation of multiple target images with different poses simultaneously, from a single source image. The figure visually demonstrates the model’s ability to maintain consistency and photorealism across the different conditions.
read the caption
Figure 12: More visual comparison of our model’s uniformity across different user scenarios.

🔼 This figure shows a qualitative comparison of IMAGPose against several state-of-the-art methods on the DeepFashion dataset. Each row presents a different example, showing the ground truth (GT) image and the results generated by PoCoLD, CFLD, PCDMs, and IMAGPose. The comparison highlights the differences in clothing detail, pose accuracy, and overall image quality between the different models, demonstrating IMAGPose’s superior performance in generating high-fidelity and detailed person images.
read the caption
Figure 10: More qualitative comparisons between IMAGPose and SOTA methods on the DeepFashion dataset.
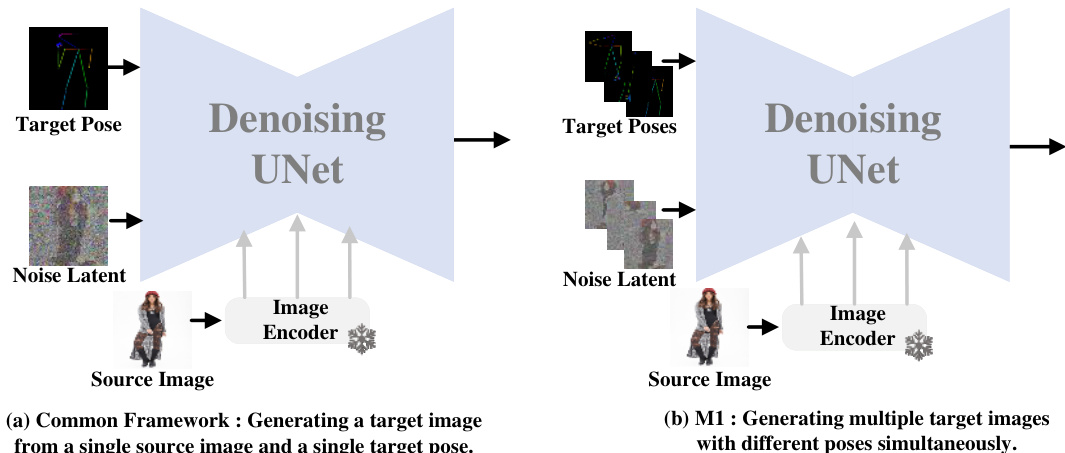
🔼 This figure illustrates the limitation of existing diffusion models for image generation and how IMAGPose addresses it. (a) shows the standard approach of existing models that only generates a single image using one source image and one target pose. (b) shows how IMAGPose can generate multiple images from a single source image with multiple target poses simultaneously.
read the caption
Figure 11: (a) The schematic diagram of the common frameworks based on existing diffusion models can only support generating a target image from a single source image and a single target pose. (b) During the development of IMAGPose, we devised a proprietary model to address the scenarios of generating multiple target images with different poses simultaneously.
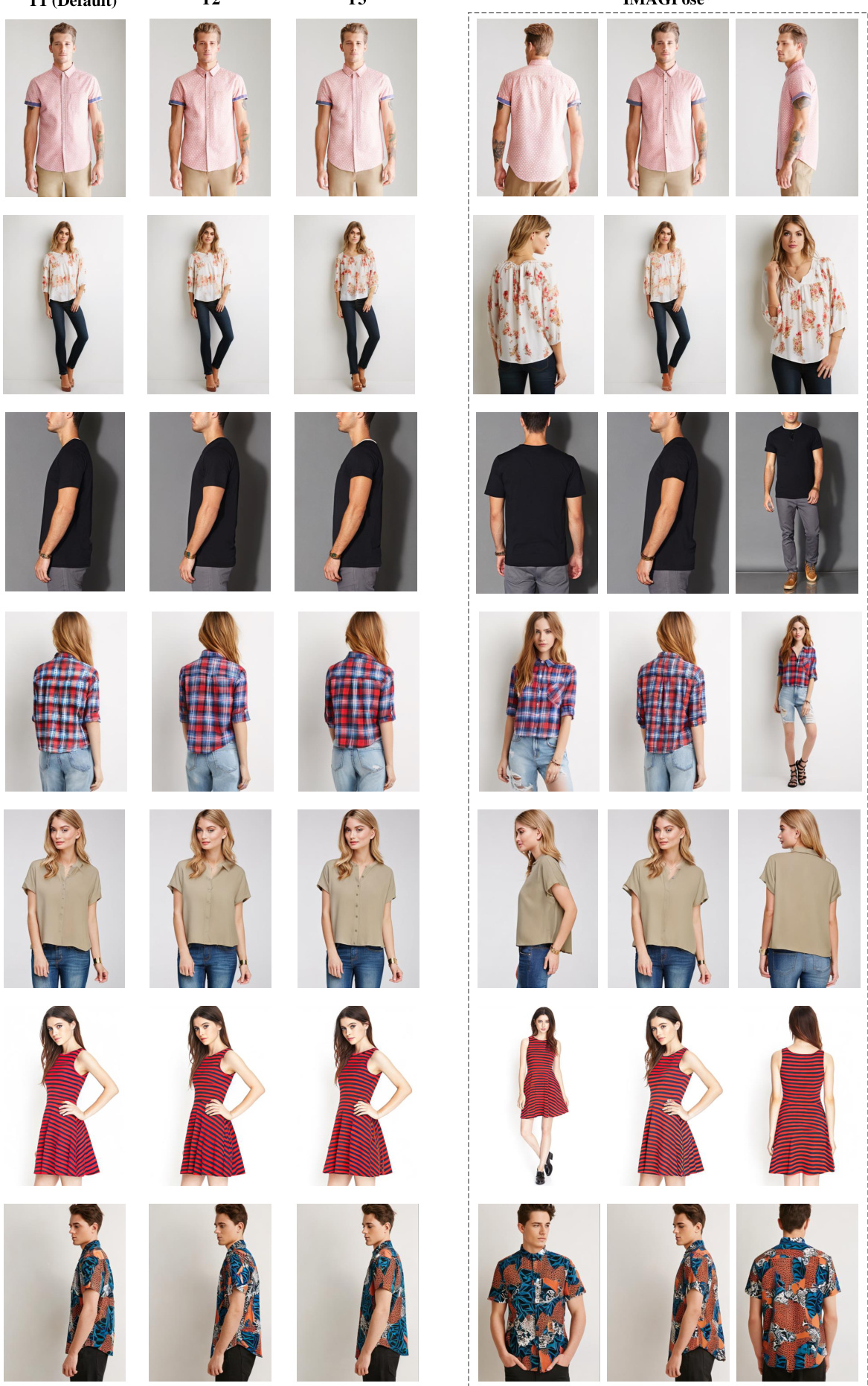
🔼 This figure shows a visual comparison of IMAGPose’s performance across three different user scenarios. The first column shows the results for the default setting (one source image and one target pose), the second column shows results for generating a target image from multiple source images, and the third column shows results for generating multiple target images from a single source image. The results demonstrate the model’s consistency and ability to generate high-quality images across various scenarios.
read the caption
Figure 12: More visual comparison of our model's uniformity across different user scenarios.

🔼 This figure shows an example question from a user study evaluating the realism of images generated by the IMAGPose model. Participants were asked to determine if the shown image of a woman was real or fake. This is one example from a larger set of questions used to assess the model’s performance compared to other models and human perception.
read the caption
Figure 13: An example question used in our user study for pose-guided person image synthesis.
More on tables

🔼 This table presents a quantitative comparison of the proposed IMAGPose model against several other state-of-the-art models on the DeepFashion and Market-1501 datasets. The comparison uses three metrics: Structural Similarity Index Measure (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and Fréchet Inception Distance (FID). Higher SSIM values indicate better image quality, while lower LPIPS and FID values suggest better perceptual similarity and better overall image quality, respectively. The results show that IMAGPose outperforms other models across all three metrics on both datasets.
read the caption
Table 1: Quantitative comparison of the proposed IMAGPose with several state-of-the-art models.
🔼 This table presents a quantitative comparison of the proposed IMAGPose model with several state-of-the-art models on two benchmark datasets: DeepFashion and Market-1501. The comparison uses three metrics: SSIM (Structural Similarity Index), LPIPS (Learned Perceptual Image Patch Similarity), and FID (Fréchet Inception Distance). Higher SSIM values indicate better structural similarity, while lower LPIPS and FID values suggest better perceptual similarity and better overall image quality, respectively. The table shows that IMAGPose outperforms other methods across both datasets and metrics, demonstrating its improved performance in pose-guided person image generation.
read the caption
Table 1: Quantitative comparison of the proposed IMAGPose with several state-of-the-art models.

🔼 This table presents a quantitative comparison of the proposed IMAGPose model with several state-of-the-art models on the DeepFashion and Market-1501 datasets. The comparison is based on three metrics: Structural Similarity Index Measure (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and Fréchet Inception Distance (FID). Higher SSIM values indicate better image quality, lower LPIPS values indicate better perceptual similarity, and lower FID values indicate better model performance. The table allows for a direct comparison of IMAGPose against existing methods and highlights its performance advantages.
read the caption
Table 1: Quantitative comparison of the proposed IMAGPose with several state-of-the-art models.

🔼 This table presents a quantitative comparison of the proposed IMAGPose model against several state-of-the-art models on three different datasets: DeepFashion (256x176 and 512x352 resolutions), and Market-1501 (128x64 resolution). The comparison uses three standard metrics for evaluating image generation quality: Structural Similarity Index Measure (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and Fréchet Inception Distance (FID). Higher SSIM values indicate better structural similarity, lower LPIPS values indicate better perceptual similarity, and lower FID values indicate better overall image quality. The table allows for a direct comparison of IMAGPose’s performance relative to other existing methods on these datasets.
read the caption
Table 1: Quantitative comparison of the proposed IMAGPose with several state-of-the-art models.
🔼 This table presents a quantitative comparison of the proposed IMAGPose model against several state-of-the-art models on different datasets. The comparison uses three metrics: SSIM (Structural Similarity Index Measure), LPIPS (Learned Perceptual Image Patch Similarity), and FID (Fréchet Inception Distance). Higher SSIM values indicate better structural similarity, while lower LPIPS and FID values indicate better perceptual similarity and better overall image quality. The results show IMAGPose’s superior performance compared to existing methods.
read the caption
Table 1: Quantitative comparison of the proposed IMAGPose with several state-of-the-art models.

🔼 This table presents a quantitative comparison of the proposed IMAGPose model against several state-of-the-art models on the DeepFashion and Market-1501 datasets. The comparison uses three metrics: SSIM (structural similarity index), LPIPS (learned perceptual image patch similarity), and FID (Fréchet inception distance). Higher SSIM values indicate better image quality, while lower LPIPS and FID values represent better perceptual similarity and better overall image generation, respectively. The results show that IMAGPose outperforms other models across various metrics and datasets.
read the caption
Table 1: Quantitative comparison of the proposed IMAGPose with several state-of-the-art models.
Full paper#



















