TL;DR#
Federated learning (FL) faces challenges from data heterogeneity and model poisoning attacks. Knowledge distillation (KD), a common technique to address heterogeneity, unfortunately amplifies the effects of poisoning attacks, reducing global model accuracy. This is because KD aligns benign local models with a poisoned global model.
The paper introduces HYDRA-FL, a hybrid KD approach that addresses this issue. HYDRA-FL reduces attack amplification by applying KD loss at both a shallow layer (via an auxiliary classifier) and the final layer, decreasing the negative effect of the poisoned global model. Evaluation demonstrates that HYDRA-FL significantly improves accuracy in attack scenarios while maintaining comparable performance to existing methods in benign settings, showcasing its effectiveness in improving the robustness of FL.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning because it identifies and addresses a critical vulnerability in knowledge distillation (KD)-based FL techniques. It reveals how KD, while improving accuracy in benign settings, can amplify the impact of poisoning attacks. The proposed solution, HYDRA-FL, offers a practical and effective approach to enhance the robustness and accuracy of KD-based FL systems, paving the way for more secure and reliable collaborative learning.
Visual Insights#
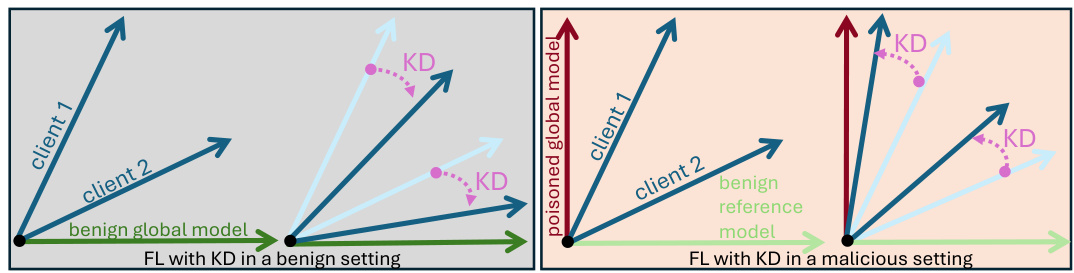
🔼 This figure illustrates how knowledge distillation (KD) can exacerbate the effects of model poisoning attacks in federated learning (FL). In a benign setting (a), KD helps align benign local models with the global model, reducing the effect of data heterogeneity. However, in a malicious setting (b), where a poisoned global model is present, KD inadvertently aligns benign local models with this poisoned model, amplifying the attack’s impact and degrading overall performance. The arrows represent the drift of local models, and their convergence towards a global model shows the effect of KD.
read the caption
Figure 1: Overview of attack amplification through knowledge distillation. a) In the benign setting, KD reduces drift and brings benign local models closer to the benign global model. b) In the malicious setting, KD unknowingly reduces drift between benign local models and the poisoned global model.

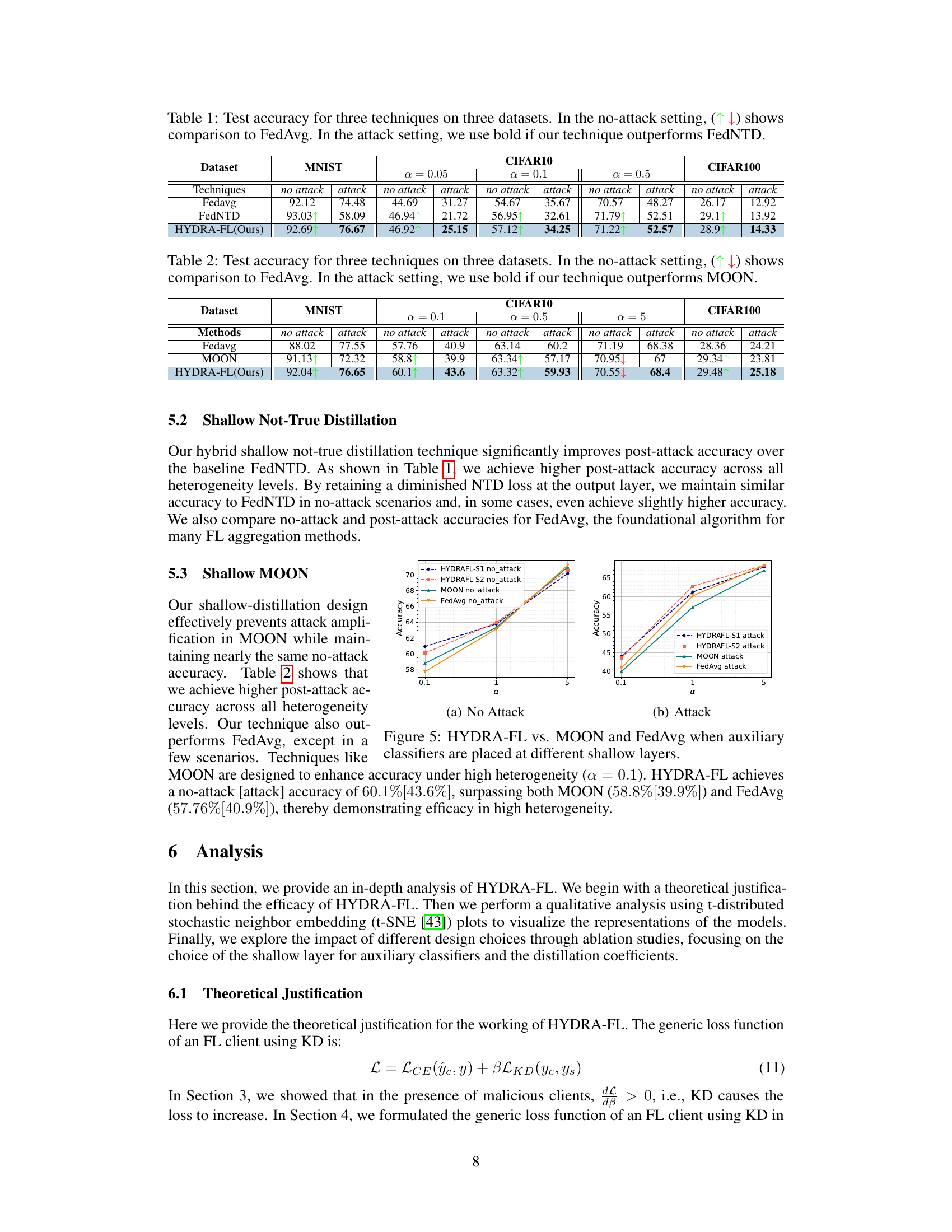
🔼 This table presents the test accuracy results for three different federated learning techniques (FedAvg, FedNTD, and HYDRA-FL) across three benchmark datasets (MNIST, CIFAR10, and CIFAR100). The accuracy is evaluated under two scenarios: no attack (benign setting) and attack (malicious setting with model poisoning). The up and down arrows in the no-attack column indicate whether the performance is improved or degraded compared to FedAvg. Bold numbers in the attack column highlight cases where HYDRA-FL surpasses FedNTD’s performance.
read the caption
Table 1: Test accuracy for three techniques on three datasets. In the no-attack setting, (↑↓) shows comparison to FedAvg. In the attack setting, we use bold if our technique outperforms FedNTD.
In-depth insights#
Attack Amplification#
The research reveals a critical vulnerability in knowledge distillation (KD)-based federated learning (FL) systems, specifically attack amplification. KD techniques, while improving accuracy under high data heterogeneity, inadvertently amplify the impact of model poisoning attacks. This occurs because KD aligns benign local models with a poisoned global model, effectively reducing the diversity that might otherwise mitigate malicious influence. The analysis focuses on two KD-based FL algorithms, FedNTD and MOON, demonstrating that increased KD strength (higher loss coefficients) correlates with improved benign accuracy but significantly worsened performance under attack. This counterintuitive tradeoff highlights a fundamental risk of relying solely on KD for robustness in FL. The core finding motivates the development of HYDRA-FL, a hybrid approach aiming to mitigate attack amplification while preserving the benefits of KD in benign scenarios.
HYDRA-FL Design#
The HYDRA-FL design cleverly addresses the vulnerability of knowledge distillation (KD) in federated learning (FL) to model poisoning attacks. Its core innovation is a hybrid approach, combining traditional KD at the final layer with a novel shallow KD mechanism utilizing an auxiliary classifier. This hybrid strategy mitigates the amplification of poisoning attacks by offloading some of the KD loss to a shallow layer, where it’s less susceptible to manipulation by malicious clients. By reducing the reliance on final layer alignment, HYDRA-FL prevents benign clients from inadvertently aligning with poisoned global models. The framework’s adaptability is highlighted by its generic loss function, easily integrated into existing KD-based FL algorithms like FedNTD and MOON, enhancing robustness without sacrificing accuracy in benign settings. The use of an auxiliary classifier is critical, acting as a filter against poisoned information, and the introduction of a diminishing factor further balances the contributions of the KD loss components. This sophisticated design ensures improved security and accuracy in diverse and challenging FL scenarios.
Heterogeneity Impact#
The impact of data heterogeneity on federated learning (FL) is a critical aspect explored in the research. Non-IID data distributions across clients lead to significant performance degradation because local models trained on diverse datasets may diverge substantially. This divergence hinders the effectiveness of model aggregation, resulting in a global model that struggles to generalize well. The paper investigates how knowledge distillation (KD) techniques, while improving accuracy in homogeneous settings, exacerbate the negative effects of heterogeneity under attack. Specifically, KD’s inherent tendency to align local models with the global model inadvertently aligns benign models with poisoned ones during malicious attacks, reducing the overall robustness. This phenomenon, termed ‘attack amplification’, demonstrates the tradeoff between improving accuracy in benign scenarios and increasing vulnerability in adversarial ones. The study therefore emphasizes the need for robust FL techniques that can mitigate this amplification, particularly when confronted with heterogeneous data and malicious actors. The research highlights the critical vulnerability of using KD in FL without adequate safeguards and underscores the importance of developing strategies that enhance both accuracy and security in real-world, diverse FL environments.
Future Work#
The authors acknowledge the limitations of their current work, particularly the exploration of a limited subset of FL settings and adversarial scenarios. Future research should broaden the scope to encompass a wider range of aggregation rules, attacks, defenses, datasets, and data modalities, including multimodal data. The current study’s reliance on image datasets is a limitation, and expanding to other modalities, like language or combined modalities, would enhance generalizability. Extending the HYDRA-FL framework to other state-of-the-art KD techniques beyond FedNTD and MOON is also vital for validating the framework’s adaptability and effectiveness. Investigating the impact of model heterogeneity, both in benign and adversarial settings, warrants further attention, potentially uncovering more nuanced interactions. Finally, a deeper theoretical understanding of the attack amplification phenomenon in KD-based FL is needed to develop more robust and targeted mitigation techniques. A thorough analysis comparing the performance of HYDRA-FL against other robust FL defenses, under various attack scenarios, is essential to establish its overall efficacy and identify its specific strengths and weaknesses.
Limitations#
The research paper acknowledges inherent limitations within the scope of its investigation. Data heterogeneity in federated learning presents a considerable challenge, and the study’s focus on specific KD-based algorithms (FedNTD and MOON) might not fully generalize to all FL techniques. The empirical analysis, while comprehensive, is restricted to a specific set of datasets and attack settings, potentially limiting the generalizability of findings. Adversarial scenarios were simulated, but the complexity of real-world attacks is not fully captured. Furthermore, the scalability and computational cost of the proposed HYDRA-FL technique across diverse datasets and architectures remains unexplored. Therefore, while the findings are valuable, they should be viewed within the context of these limitations and further research is needed to expand the understanding of HYDRA-FL’s efficacy and adaptability.
More visual insights#
More on figures
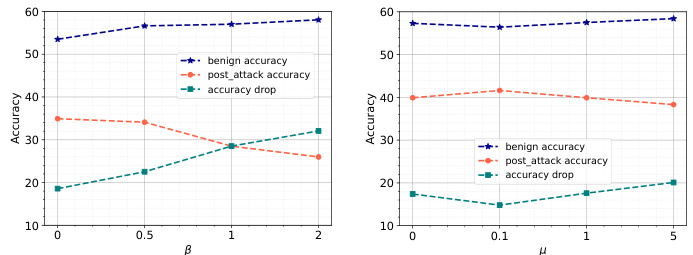
🔼 This figure shows the impact of increasing the KL-divergence loss (for FedNTD) and contrastive loss (for MOON) on accuracy in both benign and adversarial settings. It presents three key results: benign accuracy (blue), post-attack accuracy (orange), and the accuracy drop (green). The results demonstrate that increasing the loss improves global model accuracy in benign settings but simultaneously increases the accuracy drop after a model poisoning attack, highlighting the trade-off between performance in benign and adversarial conditions. The x-axis represents the hyperparameter values (β for FedNTD and μ for MOON), and the y-axis represents the accuracy.
read the caption
Figure 2: Impact of increasing KL-divergence loss for Fed-NTD and contrastive loss for MOON on accuracy.
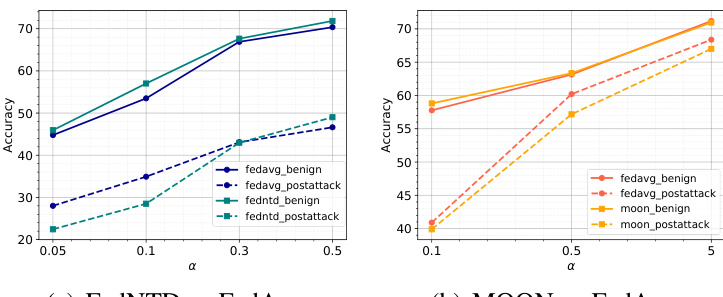
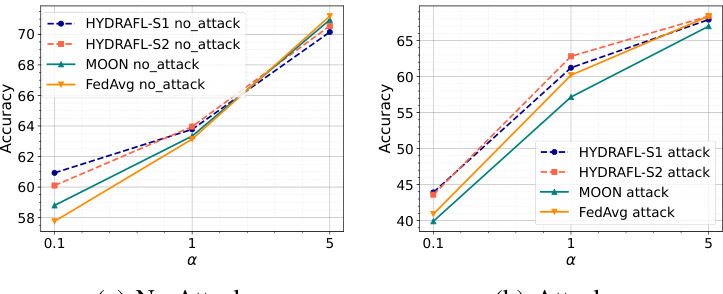
🔼 This figure compares the performance of FedNTD, MOON, and FedAvg under different levels of data heterogeneity (α values) in both benign (no attack) and adversarial (model poisoning attack) settings. The results show the tradeoff between accuracy in benign settings and robustness to attacks. FedNTD and MOON initially exhibit higher accuracy than FedAvg under benign conditions, particularly at lower α values (higher heterogeneity). However, in the presence of attacks, their performance degrades significantly more than FedAvg. The higher the heterogeneity (lower α), the more the accuracy drops under attacks for both FedNTD and MOON, highlighting the vulnerability of these KD-based FL techniques to model poisoning attacks when heterogeneity is high.
read the caption
Figure 3: Impact of the heterogeneity parameter, α in benign and adversarial settings. We use the Dirichlet distribution where a higher α means lower heterogeneity.
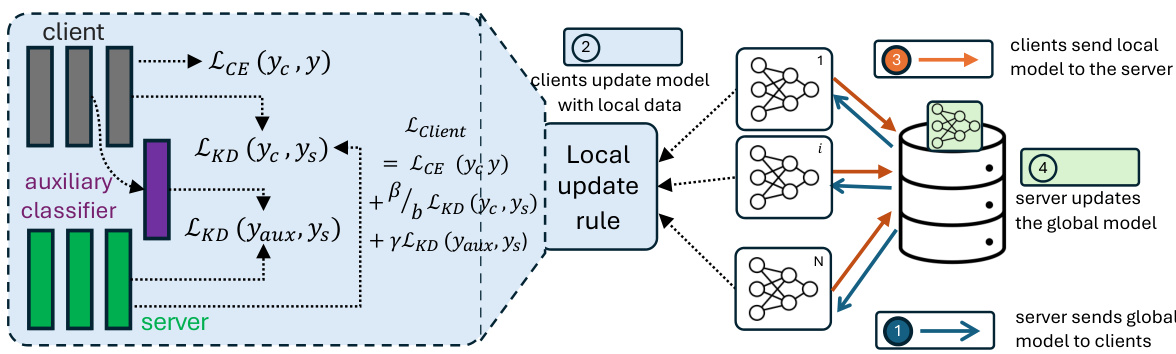
🔼 The figure illustrates the HYDRA-FL framework, a hybrid knowledge distillation method for robust and accurate federated learning. It shows how client model training is refined by reducing the knowledge distillation (KD) loss at the final layer and incorporating a shallow KD loss at an earlier layer using an auxiliary classifier. This approach helps mitigate the amplification of poisoning attacks while maintaining good performance in benign settings. The diagram details the interaction between clients, an auxiliary classifier, and the server during the model training process.
read the caption
Figure 4: HYDRA-FL framework: we refine client model training by reducing the final layer's KD-loss and incorporating shallow KD-loss at an earlier shallow layer via an auxiliary classifier.
🔼 This figure compares the performance of HYDRA-FL with different placements of auxiliary classifiers (HYDRA-FL-S1 and HYDRA-FL-S2), MOON, and FedAvg under both benign (no attack) and malicious (attack) conditions. The x-axis represents the Dirichlet distribution parameter (α), indicating the level of data heterogeneity, with higher values indicating lower heterogeneity. The y-axis represents the test accuracy. The plot reveals how HYDRA-FL consistently maintains comparable performance to FedAvg and MOON in benign scenarios while significantly outperforming both algorithms in attack settings across various heterogeneity levels. The placement of the auxiliary classifier impacts performance, suggesting optimal positioning for robust defense against model poisoning attacks.
read the caption
Figure 5: HYDRA-FL vs. MOON and FedAvg when auxiliary classifiers are placed at different shallow layers.
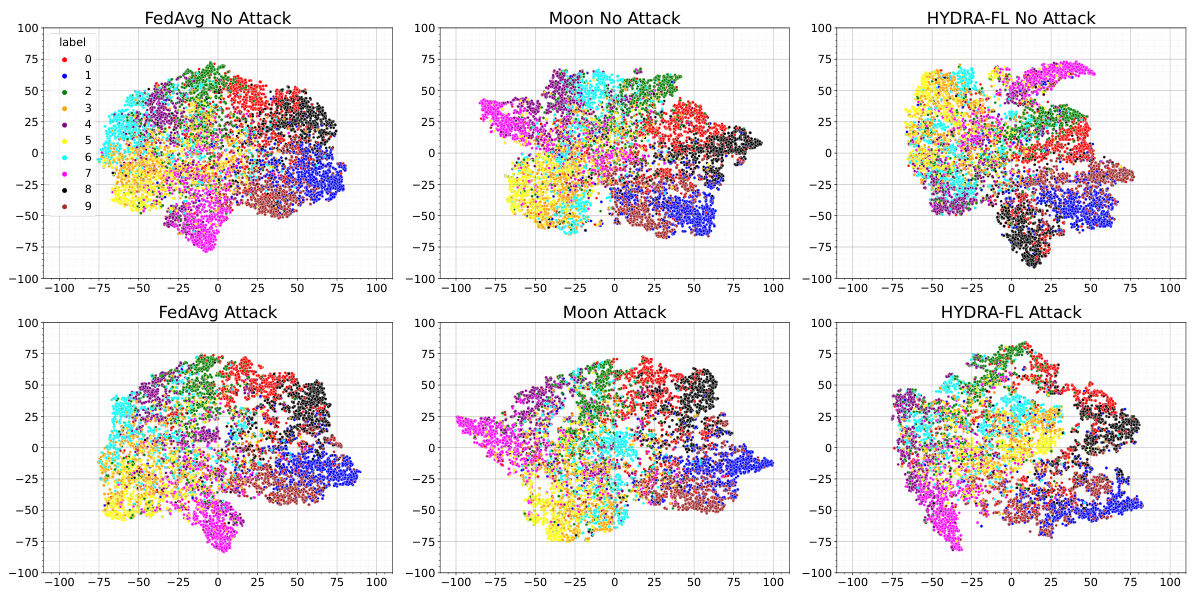
🔼 This figure illustrates the effect of knowledge distillation (KD) on federated learning (FL) models under benign and malicious (attack) conditions. In the benign setting (Figure 1a), KD successfully reduces the differences between the local models trained on diverse data and the global model, thus improving model performance. In contrast, in the malicious setting (Figure 1b), where some malicious local models are introduced, KD causes the benign local models to align with the poisoned global model (the poisoned global model is not depicted explicitly in the figure). This phenomenon, known as ‘attack amplification’, results in a significant performance degradation. The figure highlights the vulnerability of KD-based FL techniques to model poisoning attacks.
read the caption
Figure 1: Overview of attack amplification through knowledge distillation. a) In the benign setting, KD reduces drift and brings benign local models closer to the benign global model. b) In the malicious setting, KD unknowingly reduces drift between benign local models and the poisoned global model.
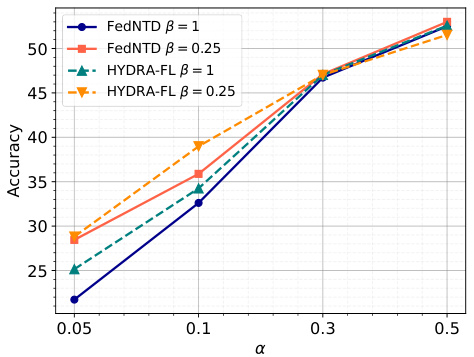
🔼 This figure shows the impact of varying the diminishing factor (β) on the post-attack accuracy of FedNTD with shallow distillation (FedNTD-S) and HYDRA-FL across different levels of data heterogeneity (α). It demonstrates that reducing β, which effectively reduces the weight of the knowledge distillation loss at the output layer, significantly improves the post-attack accuracy, especially at high heterogeneity levels (small α). This highlights the effectiveness of HYDRA-FL’s approach in mitigating the attack amplification problem caused by over-reliance on final-layer alignment in knowledge distillation.
read the caption
Figure 7: Comparison of performance of FedNTD-S with different values of β
More on tables

🔼 This table presents the test accuracy results for three different federated learning techniques (FedAvg, MOON, and HYDRA-FL) across three datasets (MNIST, CIFAR10, and CIFAR100) under both no-attack and attack scenarios. The (↑↓) symbols indicate whether the accuracy is higher or lower compared to FedAvg in the no-attack setting. Bold numbers highlight cases where HYDRA-FL outperforms MOON in the attack setting. Different levels of data heterogeneity (controlled by the α parameter) are considered for CIFAR10 and CIFAR100.
read the caption
Table 2: Test accuracy for three techniques on three datasets. In the no-attack setting, (↑↓) shows comparison to FedAvg. In the attack setting, we use bold if our technique outperforms MOON.
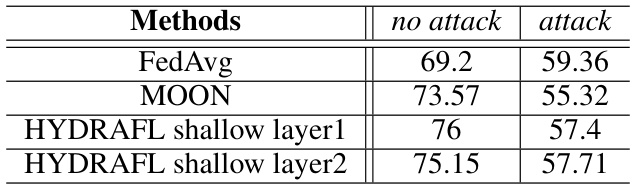
🔼 This table presents the MNIST test accuracy results for three different methods: FedAvg, MOON, and HYDRA-FL (with shallow layers 1 and 2) under both no-attack and attack scenarios, using a heterogeneity level of 0.05. It demonstrates the performance comparison in terms of accuracy under benign and adversarial conditions for the different methods, specifically highlighting the impact of the proposed HYDRA-FL approach and the placement of the shallow layer on its effectiveness against model poisoning attacks.
read the caption
Table 3: MNIST test accuracy with 0.05 heterogeneity for MOON

🔼 This table presents a comparison of the test accuracy achieved by three different federated learning techniques (FedAvg, FedNTD, and HYDRA-FL) on three benchmark datasets (MNIST, CIFAR10, and CIFAR100) under both benign (no-attack) and malicious (attack) conditions. The results show the impact of data heterogeneity and model poisoning attacks. The arrows (↑↓) indicate whether the accuracy of a technique is higher or lower than FedAvg’s accuracy in a benign setting, while bold font highlights cases where HYDRA-FL outperforms FedNTD in the malicious setting.
read the caption
Table 1: Test accuracy for three techniques on three datasets. In the no-attack setting, (↑↓) shows comparison to FedAvg. In the attack setting, we use bold if our technique outperforms FedNTD.
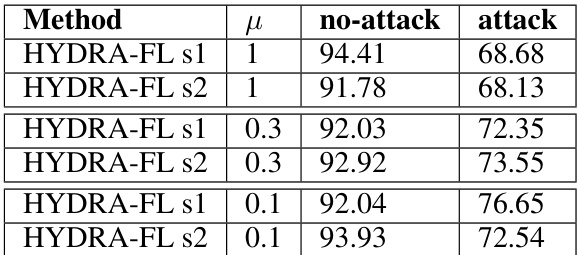
🔼 This table presents the results of ablation studies on the impact of different shallow layer choices and distillation coefficients in HYDRA-FL for MOON. It shows the no-attack and attack accuracy for HYDRA-FL models with auxiliary classifiers placed after either the first or second convolutional layers (s1, s2). The results are shown for different values of the contrastive loss coefficient μ (1, 0.3, 0.1). This allows for an analysis of the impact of the choice of shallow layer and strength of the contrastive loss on the model’s performance in both benign and adversarial settings.
read the caption
Table 5: Comparison of HYDRA-FL for MOON with different distillation coefficients.
Full paper#