TL;DR#
Federated learning, while designed for privacy, suffers from slow convergence due to a phenomenon called ’layer mismatch.’ This occurs when updating and averaging the entire model in each training round prevents effective cooperation between layers. The resulting mismatch reduces training efficiency and compromises final model accuracy.
To solve this, the paper introduces FedPart, a novel method that updates only a portion of the network’s layers per round. This strategic approach enhances layer cooperation by training only selected layers while keeping others fixed, acting as anchors for the updated layers. FedPart significantly outperforms traditional methods in terms of speed, accuracy, and resource efficiency, supported by theoretical analysis and extensive empirical validation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning because it addresses the critical issue of layer mismatch, which hinders model convergence and performance. By introducing the FedPart method and providing theoretical analysis and extensive experimental validation, the authors offer a significant improvement to existing federated learning approaches and open up new avenues for research in efficient and accurate model training.
Visual Insights#

🔼 This figure shows the update step sizes of a ResNet-8 model trained using traditional federated learning with full network updates (a) and compared to partial network updates (b). The x-axis represents the training iteration, and the y-axis represents the update step size. In (a), the step sizes increase significantly after each parameter averaging, indicating layer mismatch. (b) shows that partial network updates significantly reduce the increase in step size after averaging.
read the caption
Figure 1: Update step sizes for each iteration. The experiment uses the ResNet-8 model with 20,000 CIFAR-100 images distributed in an i.i.d. manner across 40 clients.

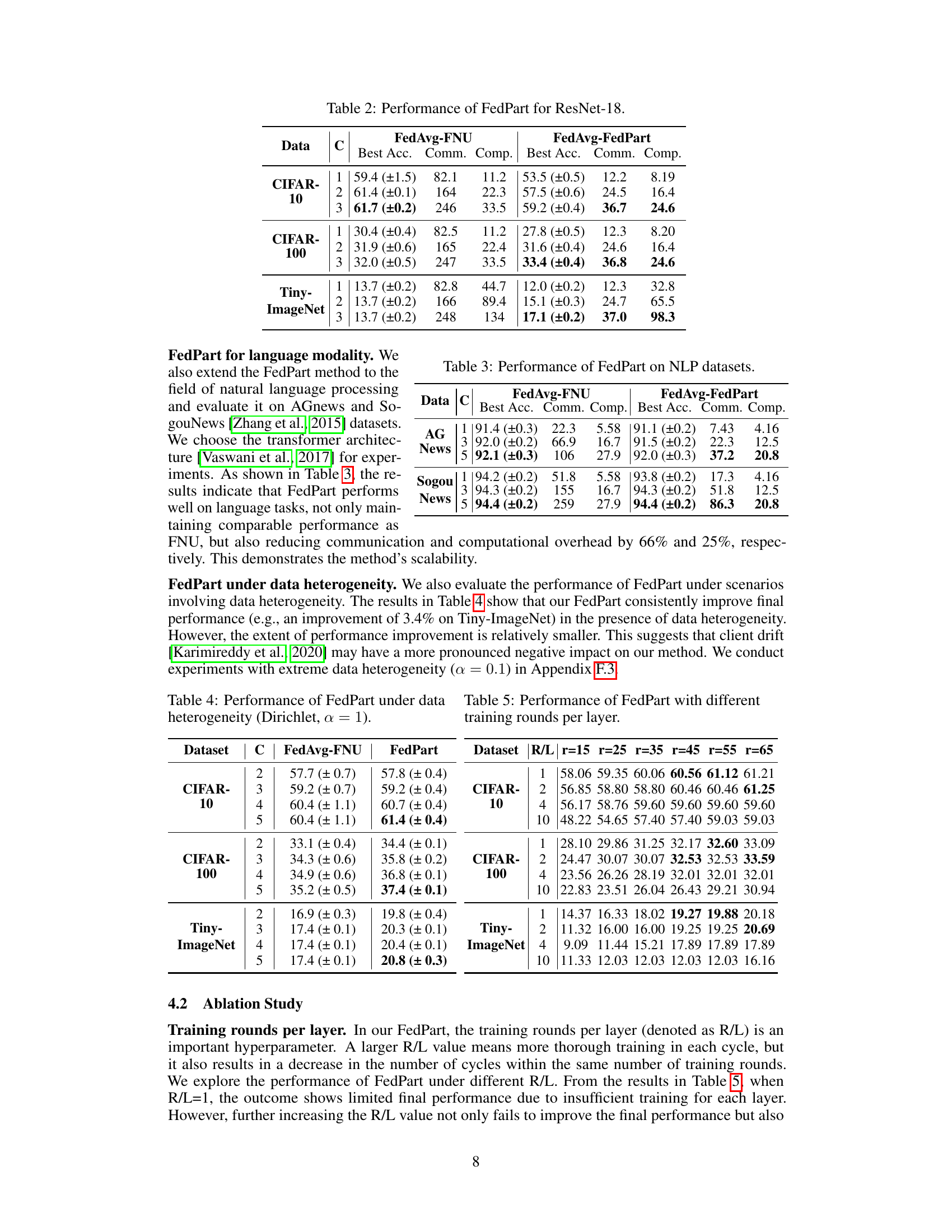
🔼 The table presents a comparison of the performance of three federated learning algorithms (FedAvg, FedProx, and FedMoon) using both full network updates (FNU) and partial network updates (PNU) proposed by the authors. The comparison is done across four different training cycles (C) on three datasets (CIFAR-10, CIFAR-100, and TinyImageNet). The metrics used for comparison include the best accuracy achieved (Best Acc.), communication cost (Comm.), and computation cost (Comp.).
read the caption
Table 1: Performance of FL algorithms with full network and partial network updates.
In-depth insights#
FedPart: Core Idea#
FedPart’s core idea revolves around addressing layer mismatch in Federated Learning (FL). Traditional FL methods update and average the entire model parameters, leading to inconsistencies between how individual clients’ local models and the global model cooperate. FedPart innovates by performing partial network updates, training only a subset of layers in each round. This targeted approach mitigates layer mismatch by ensuring that updated layers align with the fixed parameters of other layers, thus promoting better overall model coherence and improving convergence. The selection of trainable layers is further refined via strategies like sequential updating (shallow to deep) and multi-round cyclical training, mimicking the natural learning progression of neural networks. Efficiency is also key; partial updates significantly reduce communication and computational overhead compared to full-network updates.
Layer Mismatch#
The concept of “Layer Mismatch” in federated learning, as described in the research paper, highlights a critical problem where the independent training of local models on clients leads to inconsistencies between layers when aggregated on the server. This mismatch arises because each client’s local model adapts to its unique data distribution, resulting in layer-wise gradients that differ significantly from the global model. The full-network update approach, while aiming for maximal knowledge sharing, exacerbates this issue. FedPart, a novel method proposed in the paper, addresses this by selectively updating only a portion of the network layers per round. This strategic approach facilitates better alignment between layers, enhancing cooperation and preventing the divergence of layers during parameter averaging. The selection of trainable layers is further refined using strategies like sequential updating and multi-round cycle training to ensure efficiency and knowledge retention. The layer mismatch problem is demonstrated through step size visualizations that highlight instability after averaging, whereas FedPart mitigates these effects and improves overall performance.
Partial Update#
Partial updates in federated learning aim to improve efficiency and communication costs by updating only a subset of model parameters during each round, instead of the entire model. This approach addresses the layer mismatch problem, where full updates hinder effective cooperation among layers. FedPart, a method utilizing partial updates, strategically selects trainable layers. Sequential updating trains layers from shallow to deep, aligning with natural convergence order, while multi-round cycle training repeats this process, preserving the learning of both low-level and high-level features. The theoretical analysis demonstrates a superior convergence rate compared to full updates under non-convex settings. Empirical evaluations show significantly faster convergence, increased accuracy, reduced communication, and computational overhead. Careful layer selection strategies are vital to maintaining knowledge acquisition and sharing efficiency. However, the approach’s effectiveness might be impacted by data heterogeneity, making further investigation in non-IID settings essential.
Convergence#
The concept of convergence in machine learning, particularly within the context of federated learning, is crucial. Convergence speed significantly impacts the practicality of a federated learning system. The paper highlights a common challenge: layer mismatch in traditional full-network federated learning methods, impeding convergence. The proposed FedPart method aims to improve convergence by employing partial network updates, focusing on specific layers in each training round. This approach addresses the layer mismatch problem directly. The analysis demonstrates a faster convergence rate for FedPart compared to traditional methods, supported by theoretical analysis and experimental results. Efficient communication and reduced computational overhead are further benefits that contribute to the improved convergence observed in FedPart. The selection strategy for trainable layers, incorporating sequential and cyclical training, plays a key role in achieving effective knowledge sharing and model convergence.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Extending the FedPart framework to handle non-independent and identically distributed (non-IID) data is crucial for real-world applicability, as data across clients is rarely uniform. Investigating different layer selection strategies, perhaps incorporating adaptive methods or reinforcement learning, could further improve efficiency and accuracy. A comprehensive theoretical analysis under non-convex settings is warranted to solidify the convergence rate guarantees. Beyond the theoretical analysis, empirical evaluations on a wider range of models and datasets are necessary to establish generalizability. Finally, studying the robustness of FedPart to adversarial attacks and developing techniques to enhance privacy further are critical next steps.
More visual insights#
More on figures

🔼 This figure shows a comparison of update step sizes during training between traditional federated learning with full network updates and the proposed FedPart method with partial network updates. The y-axis represents the magnitude of the update steps, and the x-axis represents the training iteration. The figure illustrates that full network updates cause larger fluctuations in update step sizes after each averaging step, suggesting a layer mismatch problem. In contrast, the partial network updates in FedPart lead to a smoother and more stable convergence process.
read the caption
Figure 1: Update step sizes for each iteration. The experiment uses the ResNet-8 model with 20,000 CIFAR-100 images distributed in an i.i.d. manner across 40 clients.
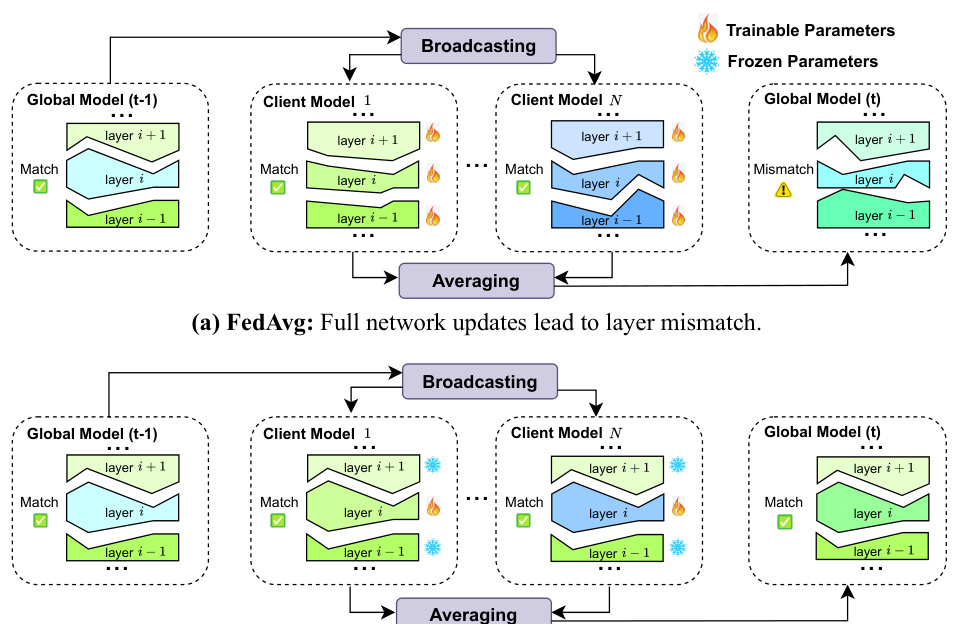
🔼 This figure illustrates the layer mismatch problem in federated learning. (a) shows how FedAvg (Federated Averaging), with full network updates, leads to layer mismatch. Local models on clients have layers that cooperate well, but after averaging parameters, the global model’s layers may not cooperate effectively due to differences in training on heterogeneous data. (b) demonstrates FedPart (Federated Partial), a proposed method using partial network updates, which helps mitigate this issue. By training only specific layers in each round, FedPart promotes better alignment between layers and reduces mismatch.
read the caption
Figure 2: Mechanism for layer mismatch in FedAvg and FedPart.

🔼 This figure illustrates the strategy used for selecting trainable layers in FedPart. It shows three approaches: Full Network Updates (all layers trained simultaneously), Sequential Training (one layer trained at a time, cycling through the layers), and Multi-round Cycle Training (repeating the sequential training process multiple times). The visual representation uses colored boxes to distinguish between trainable and untrainable layers at each round.
read the caption
Figure 3: Strategy for selecting trainable layers.
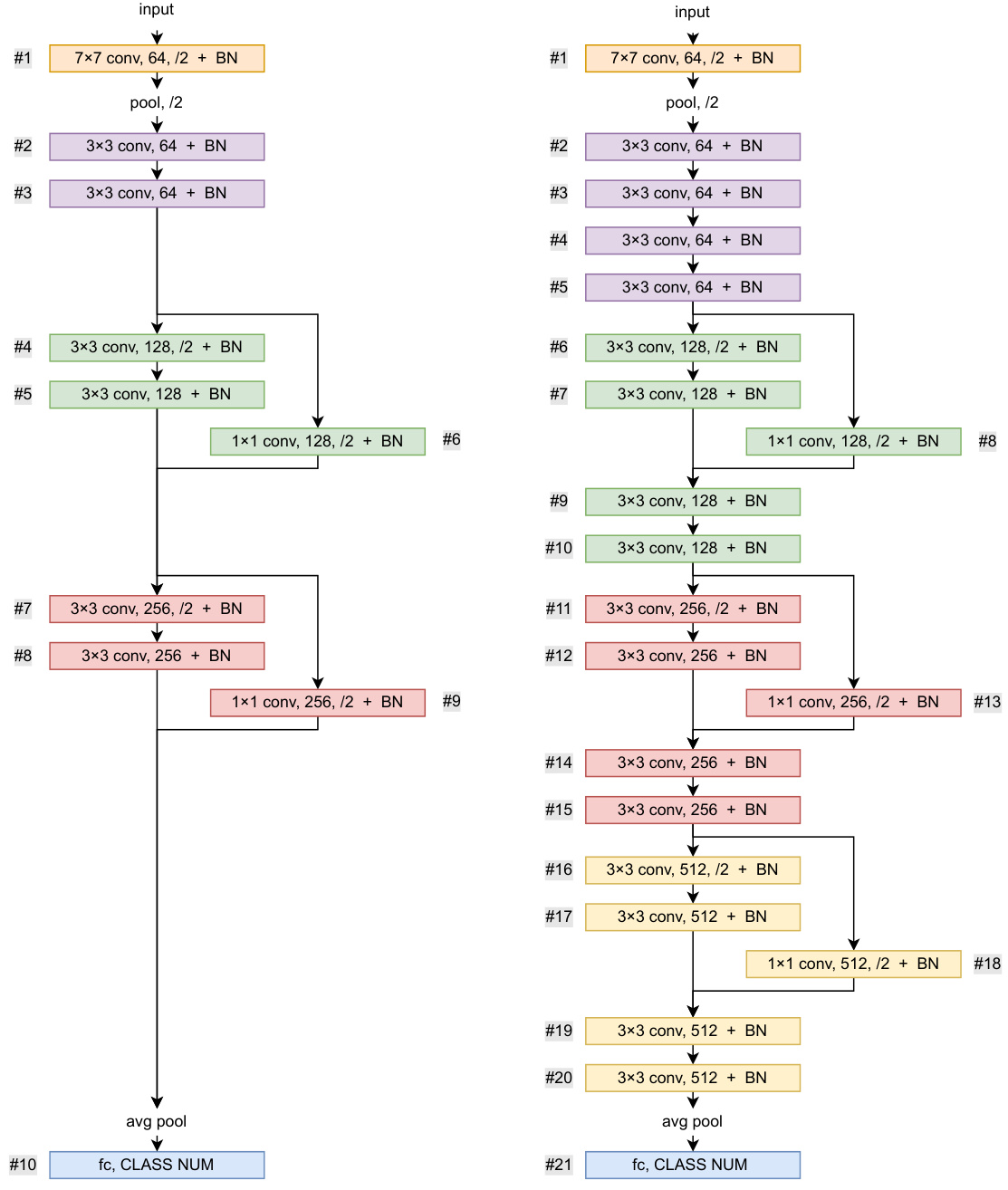
🔼 This figure shows the architecture of ResNet-8 and ResNet-18 models used in the experiments. It also illustrates how the layers are partitioned for partial network updates in the FedPart method. ResNet-8 is divided into 10 layers, with each layer containing trainable parameters (weights and biases of convolutional and BN layers). ResNet-18 has more layers, following a similar partitioning scheme. The figure helps visualize how the partial network updates are performed, focusing on selecting and training only a subset of layers during each training round. The numbering helps understand the order in which layers are trained sequentially in the FedPart approach.
read the caption
Figure 4: Model architecture and layer partitioning about our ResNet-8 and ResNet-18 model.
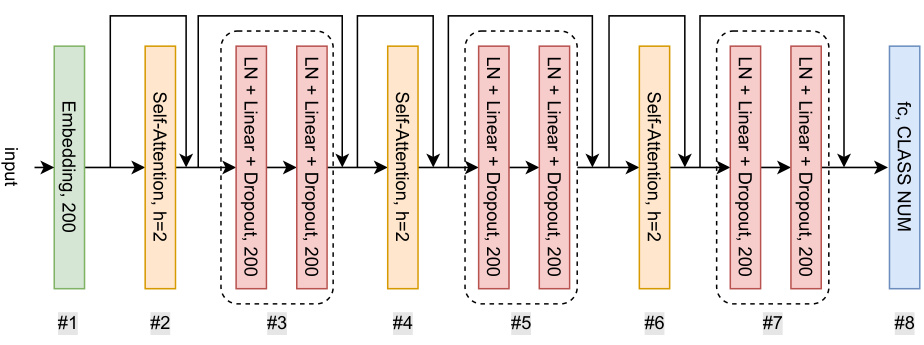
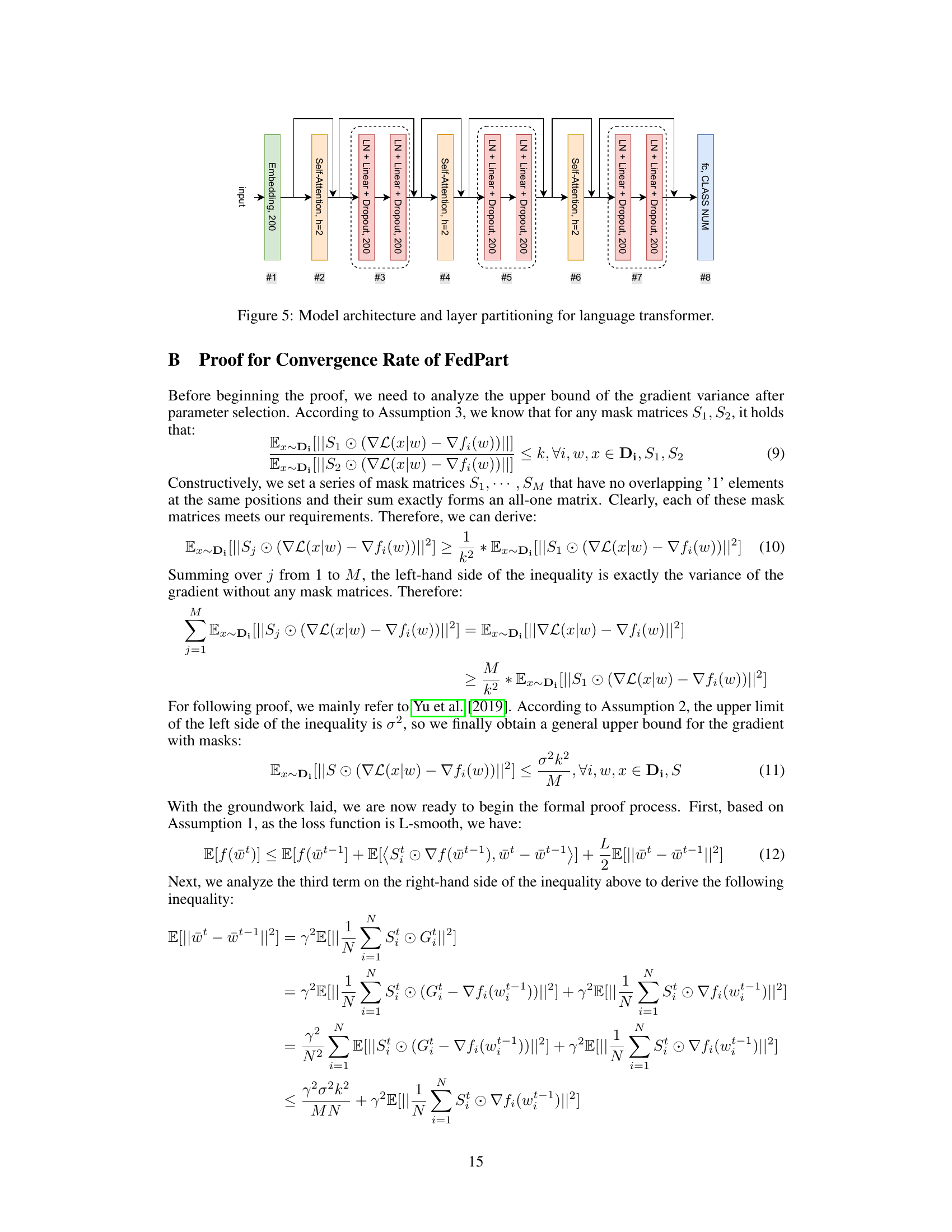
🔼 This figure illustrates the architecture of a language transformer model and how its layers are partitioned for partial network updates in the FedPart method. The model consists of an embedding layer followed by multiple encoder blocks, each composed of self-attention, layer normalization, linear transformation, and dropout layers. The partitioning scheme shows how these layers can be grouped and updated sequentially during each training round of FedPart, enhancing training efficiency and reducing communication overhead. The final layer is a fully-connected layer for classification.
read the caption
Figure 5: Model architecture and layer partitioning for language transformer.
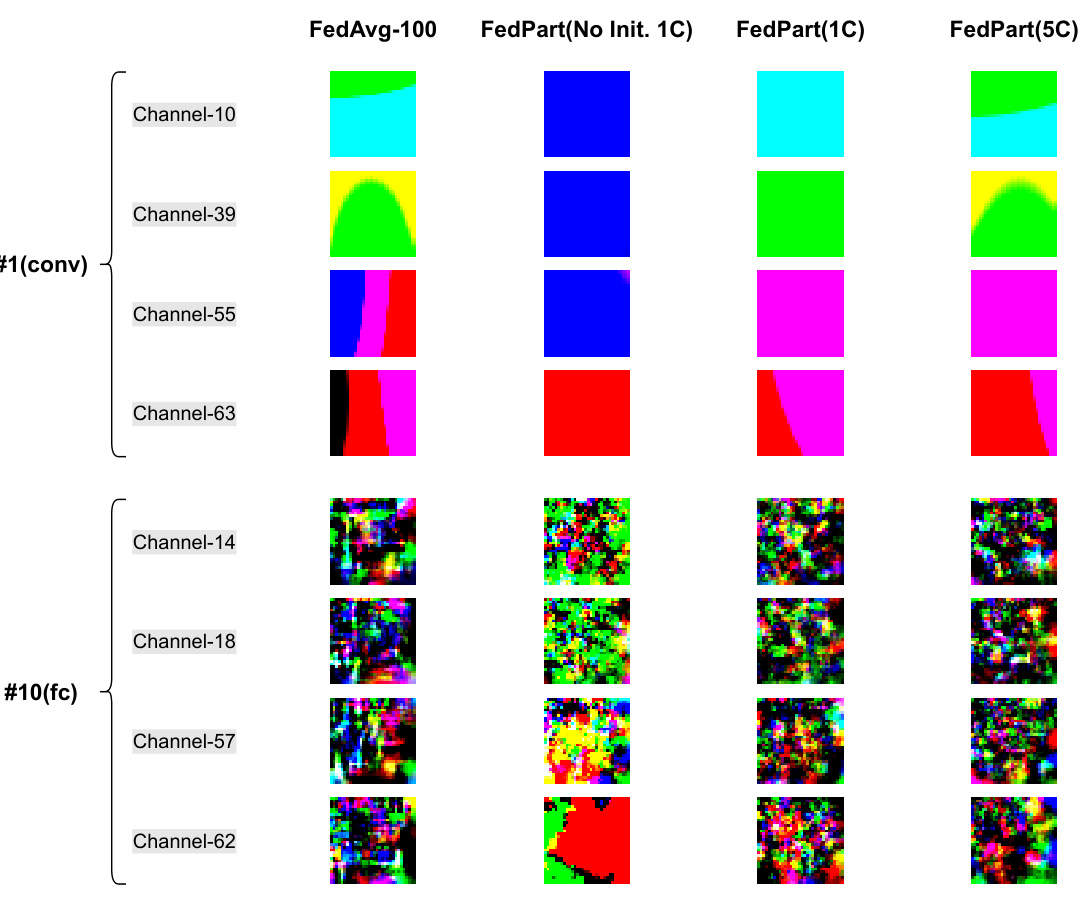
🔼 This figure visualizes the results of activation maximization on different channels within different layers of the ResNet-8 model trained using four different methods: FedAvg-100 (full network training), FedPart(No Init. 1C) (partial network updates without initial full network training), FedPart(1C) (partial network updates with one cycle of initial full network training), and FedPart(5C) (partial network updates with five cycles of initial full network training). The visualization demonstrates how different training methods affect the semantic information captured by different layers. It shows that FedAvg-100 captures low-level semantic features in shallower layers and higher-level features in deeper layers. In contrast, FedPart(No Init. 1C) shows disrupted features, whereas FedPart(1C) and FedPart(5C) progressively recover the hierarchical information extraction capability of FedAvg-100.
read the caption
Figure 6: Activation maximization images of different channels within different layers.

🔼 This figure visualizes the convolutional kernels in the first convolutional layer of four different models: FedAvg-100 (full network training), FedPart(No Init. 1C) (partial network training without initial full network updates), FedPart(1C) (partial network training with one cycle of initial full network updates), and FedPart(5C) (partial network training with five cycles of initial full network updates). It shows how the kernel characteristics change depending on the training approach. FedAvg-100 shows kernels primarily functioning as edge/corner detectors. In contrast, the FedPart models without initial full network updates show more random and irregular patterns. With the inclusion of initial full network updates and multiple cycles, the FedPart kernels gradually begin to resemble those in FedAvg-100, indicating improved coordination and function.
read the caption
Figure 7: Convolutional kernel visualization results of 5 planes in the first convolutional layer. Each plane include three color channels of image.

🔼 This figure visualizes the results of a Deep Leakage from Gradients (DLG) attack on different model settings. The leftmost column shows the original images used in the attack. The subsequent columns show reconstructed images generated by DLG using gradient information from: (1) FedAvg-100 (full network updates), (2) FedPart(5C) with only layer #1 (convolutional) updated, (3) FedPart(5C) with only layer #9 (convolutional) updated, and (4) FedPart(5C) with only layer #10 (fully connected) updated. The quality of the reconstructed images reflects the amount of information leaked during the training process. The goal is to show that FedPart (partial network updates) reduces the information leakage and thus improves privacy protection compared to FedAvg (full network updates).
read the caption
Figure 8: The reconstructed images from DLG attacks on full network of FedAvg-100 and different partial network of FedPart(5C).
More on tables
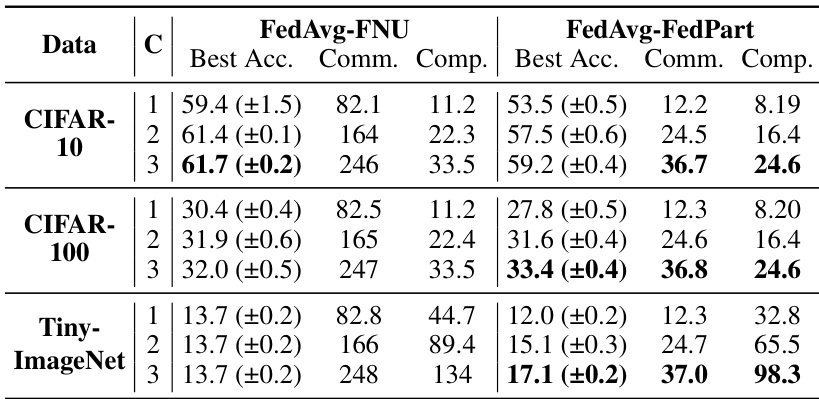
🔼 This table presents a comparison of the performance of three classic federated learning algorithms (FedAvg, FedProx, and FedMoon) using both full network updates (FNU) and partial network updates (PNU) introduced by the FedPart method. The results are shown across three datasets (CIFAR-10, CIFAR-100, and TinyImageNet) and four training cycles. For each algorithm and update method, the table reports best achieved accuracy, communication cost (in GB), and computational cost (in TFLOPs). This allows for a comprehensive comparison of the effectiveness and efficiency of FedPart compared to traditional methods.
read the caption
Table 1: Performance of FL algorithms with full network and partial network updates.

🔼 This table compares the performance of three classic federated learning algorithms (FedAvg, FedProx, and FedMoon) using both full network updates (FNU) and partial network updates (PNU) with the proposed FedPart method. The comparison is made across three datasets (CIFAR-10, CIFAR-100, and TinyImageNet) and considers several metrics: Best Accuracy, Communication Cost, and Computation Cost. The results demonstrate the performance improvement and efficiency gains achieved with FedPart.
read the caption
Table 1: Performance of FL algorithms with full network and partial network updates.
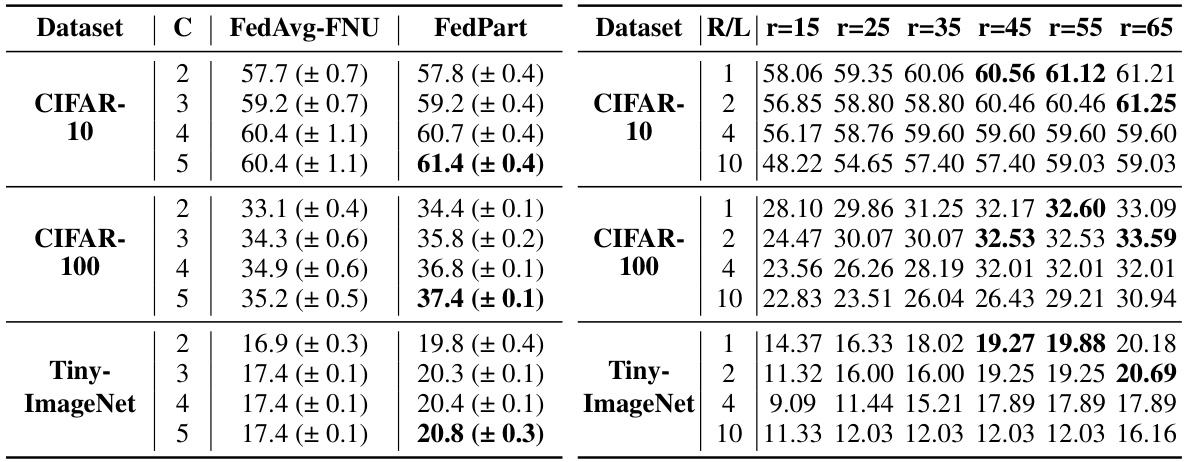
🔼 The table compares the performance of three classic federated learning algorithms (FedAvg, FedProx, and FedMoon) using both full network updates (FNU) and partial network updates (PNU) with the proposed FedPart method. The results show the best accuracy, communication cost, and computation cost for different datasets (CIFAR-10, CIFAR-100, TinyImageNet) and training cycles (C). FedPart consistently outperforms FNU across all algorithms and datasets, demonstrating significant improvements in accuracy and reductions in communication and computation costs.
read the caption
Table 1: Performance of FL algorithms with full network and partial network updates.

🔼 This table compares the performance of three classic federated learning algorithms (FedAvg, FedProx, and FedMoon) using both full network updates (FNU) and partial network updates (PNU) with the FedPart method. The results are shown for four different training cycles (C) on three datasets: CIFAR-10, CIFAR-100, and TinyImageNet. Metrics include best accuracy, communication cost (Comm.), and computation cost (Comp.). The table highlights the superior performance of FedPart, achieving higher accuracy while significantly reducing both communication and computation overhead.
read the caption
Table 1: Performance of FL algorithms with full network and partial network updates.
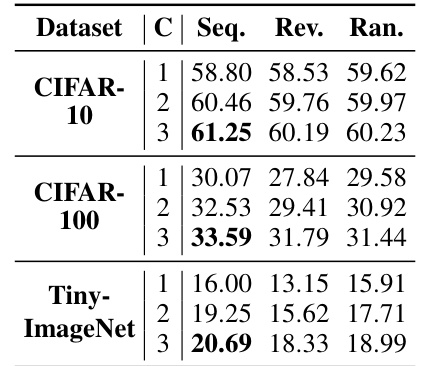
🔼 This table presents the performance comparison of three Federated Learning (FL) algorithms (FedAvg, FedProx, and FedMoon) using both full network updates (FNU) and the proposed partial network updates (PNU) method (FedPart). The results are shown across different datasets (CIFAR-10, CIFAR-100, and Tiny-ImageNet), with each algorithm evaluated over five training cycles (C). For each algorithm and cycle, the table displays the best accuracy achieved (Best Acc.), communication cost (Comm.), and computational cost (Comp.). This table demonstrates the superior performance of FedPart compared to FNU, achieving higher accuracy with significantly reduced communication and computational overheads.
read the caption
Table 1: Performance of FL algorithms with full network and partial network updates.
🔼 This table compares the performance of three classic federated learning algorithms (FedAvg, FedProx, and FedMoon) using both full network updates (FNU) and partial network updates (PNU) with the FedPart method. The comparison is done across four different training cycles (C) and three benchmark datasets (CIFAR-10, CIFAR-100, and Tiny-ImageNet). Metrics include the best accuracy achieved (Best Acc.), total upstream transmission volume required (Comm.), and total floating-point computation required (Comp.).
read the caption
Table 1: Performance of FL algorithms with full network and partial network updates.
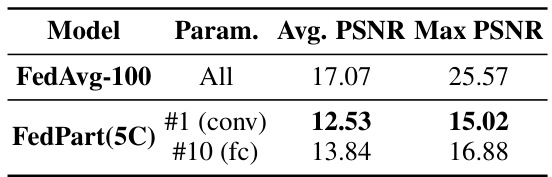
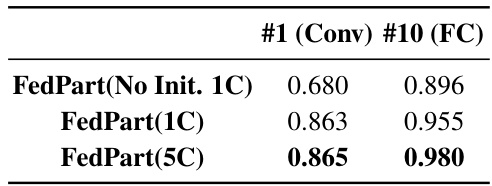
🔼 This table presents the average and maximum Peak Signal-to-Noise Ratio (PSNR) values obtained from reconstructing images using the Deep Leakage from Gradients (DLG) attack. The results are compared between the FedAvg-100 model (full network updates) and the FedPart(5C) model (partial network updates). The comparison is made using all parameters for FedAvg-100, and only a subset of parameters (#1 (conv) and #10 (fc)) for FedPart(5C). Lower PSNR values indicate better privacy protection.
read the caption
Table 9: Average and Max PSNRs of reconstructed images for FedAvg and FedPart models.
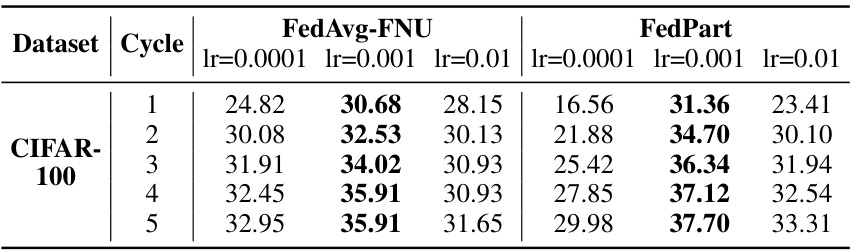
🔼 This table compares the performance of three classic federated learning algorithms (FedAvg, FedProx, and FedMoon) using both full network updates (FNU) and the proposed partial network updates (PNU) method (FedPart). It shows the best accuracy achieved, communication cost (in GB), and computation cost (in TFLOPs) for each algorithm and update strategy across four training cycles on three different datasets (CIFAR-10, CIFAR-100, and TinyImageNet). The results demonstrate the effectiveness of FedPart in improving convergence speed and accuracy while reducing communication and computational overhead.
read the caption
Table 1: Performance of FL algorithms with full network and partial network updates.

🔼 This table presents a comparison of the performance of three Federated Learning (FL) algorithms (FedAvg, FedProx, and FedMoon) using both full network updates (FNU) and partial network updates (PNU). The table shows the best accuracy achieved, the communication cost (in GB), and the computation cost (in TFLOPs) for each algorithm and update method across four different training cycles (C) on three benchmark datasets (CIFAR-10, CIFAR-100, and TinyImageNet). It demonstrates the performance improvements and efficiency gains achieved by the proposed FedPart method with partial network updates.
read the caption
Table 1: Performance of FL algorithms with full network and partial network updates.
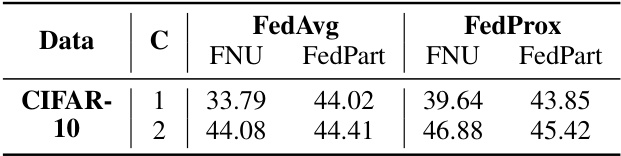
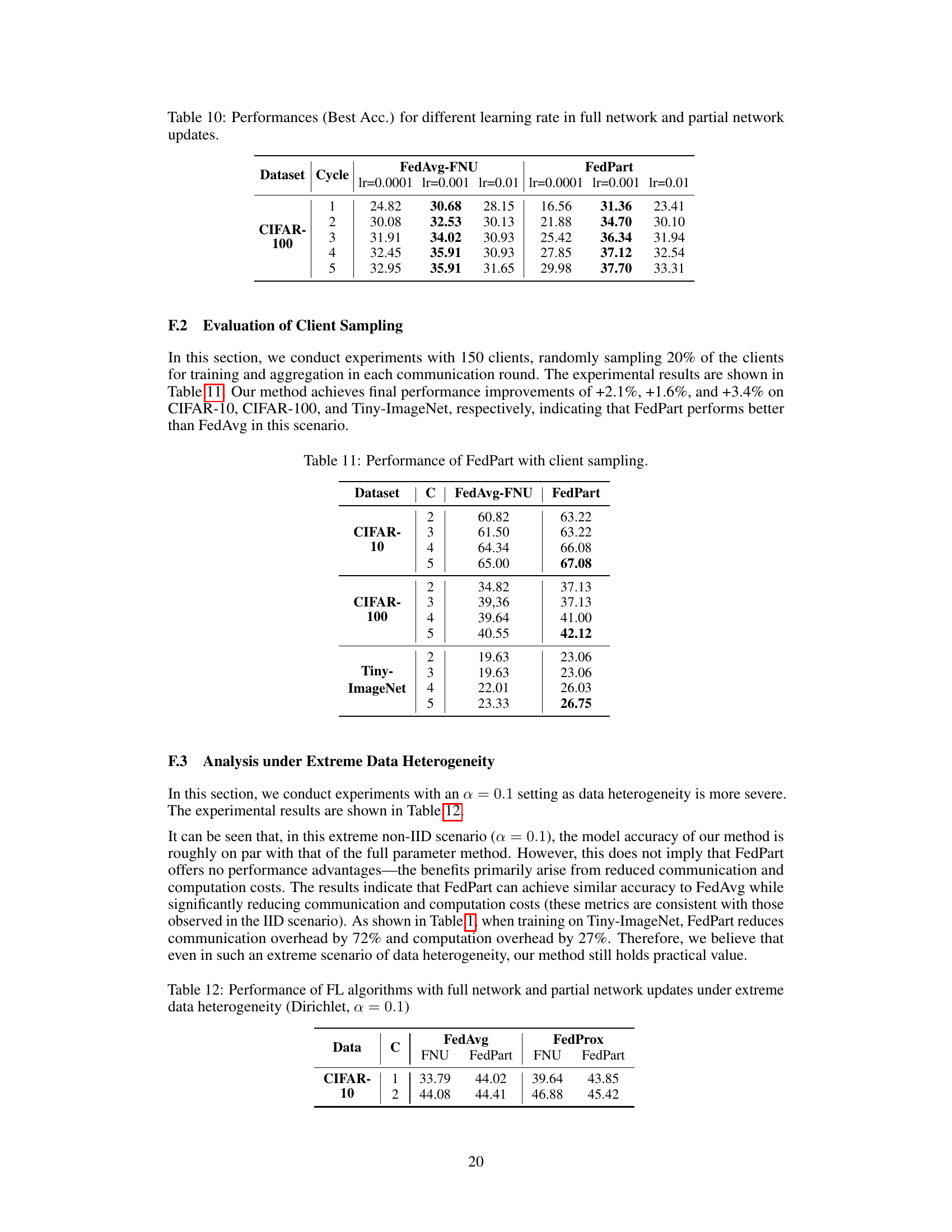
🔼 This table presents the performance of federated learning algorithms (FedAvg and FedProx) with full network updates (FNU) and partial network updates (using the FedPart method) under extreme data heterogeneity (Dirichlet distribution with parameter α = 0.1). It shows the best accuracy achieved for each algorithm and update method across different numbers of training rounds (C). The results demonstrate the performance of FedPart, particularly considering its computational and communication efficiency improvements, even under the challenging non-IID data distribution.
read the caption
Table 12: Performance of FL algorithms with full network and partial network updates under extreme data heterogeneity (Dirichlet, a = 0.1)
🔼 This table compares the performance of three classic federated learning algorithms (FedAvg, FedProx, and FedMoon) using both full network updates (FNU) and partial network updates (PNU) with the proposed FedPart method. The comparison is done across three datasets (CIFAR-10, CIFAR-100, and TinyImageNet) and considers various metrics: Best Accuracy (Best Acc.), Communication cost (Comm.), and Computation cost (Comp.). The results showcase FedPart’s superior performance in terms of accuracy, communication efficiency, and computational efficiency compared to traditional FNU methods.
read the caption
Table 1: Performance of FL algorithms with full network and partial network updates.
Full paper#