TL;DR#
Multi-view clustering (MVC) is a powerful technique for analyzing data from multiple sources. However, existing contrastive MVC methods often suffer from the Dual Noisy Correspondence (DNC) problem, where noise corrupts both positive and negative data pairs. This leads to inaccurate clustering results. The DNC problem arises from the complexity of data collection and the inherent one-to-many nature of contrastive MVC.
The proposed method, CANDY, tackles the DNC problem by using a two-pronged approach. First, it employs Context-based Semantic Mining to identify and correct false negative correspondences using inter-view similarities. Second, it uses Spectral-based Correspondence Denoising to filter out false positive correspondences. Extensive experiments show that CANDY significantly outperforms existing MVC methods on various benchmark datasets, demonstrating its effectiveness in addressing the DNC problem and improving the overall accuracy and robustness of multi-view clustering.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation in contrastive multi-view clustering, a widely used technique in data analysis. By introducing a novel method to handle noisy correspondences, it enhances the robustness and accuracy of multi-view clustering algorithms, leading to improved results in various applications. The findings open new avenues for research into more robust and reliable multi-view learning methods. This work also highlights the importance of considering data quality issues in the design and evaluation of machine learning algorithms.
Visual Insights#
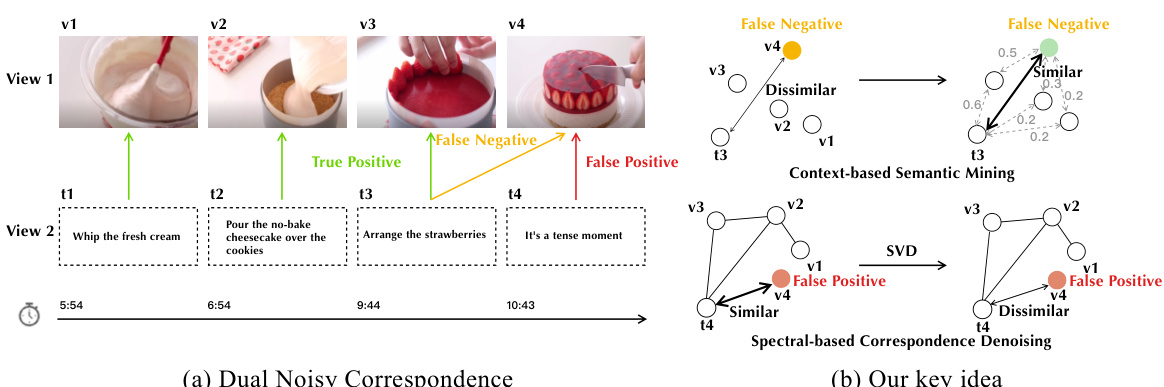
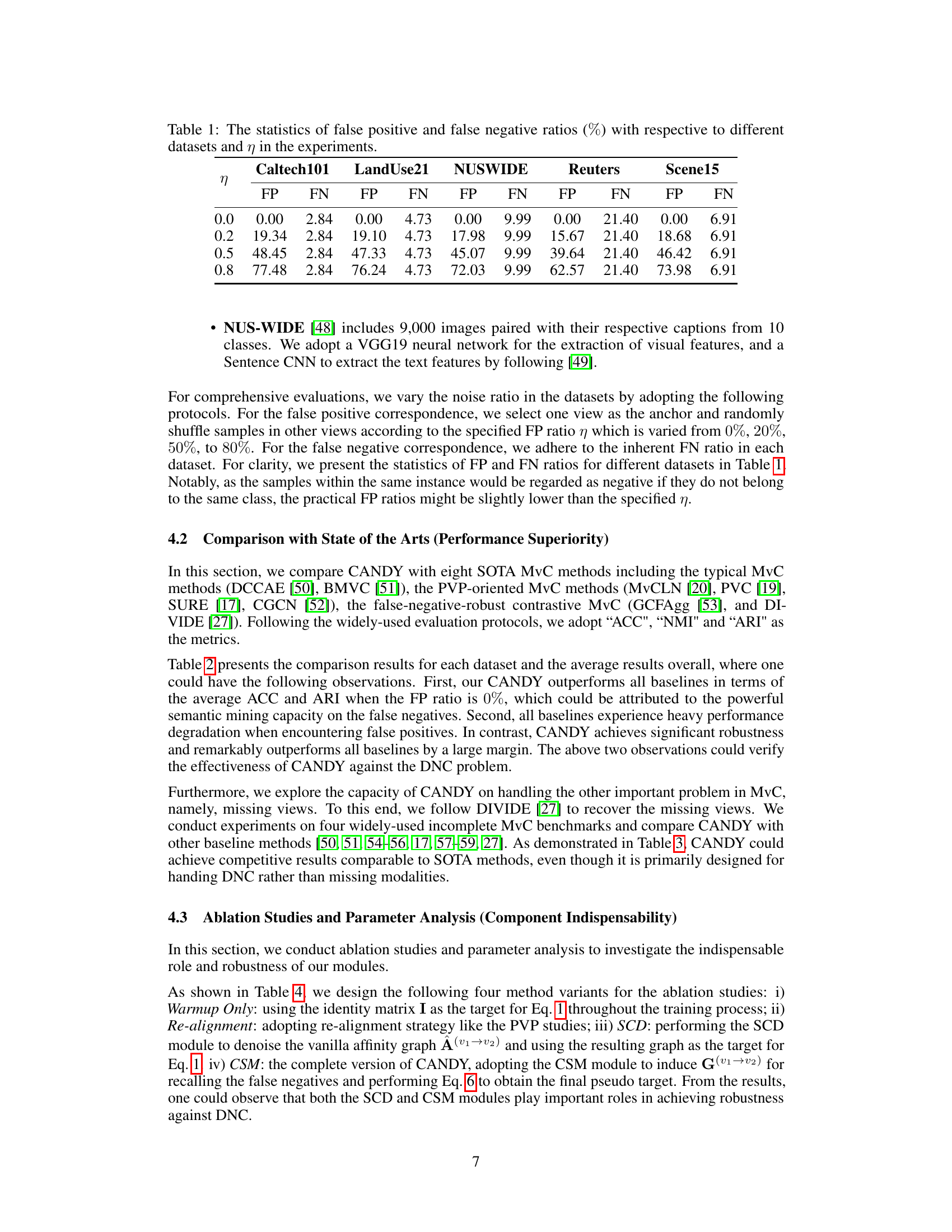
🔼 This figure illustrates the problem of Dual Noisy Correspondence (DNC) in contrastive multi-view clustering and the proposed solution. (a) shows how noise contaminates both positive and negative cross-view data pairs, leading to false positives and false negatives. (b) illustrates the CANDY method’s two modules: Context-based Semantic Mining to identify false negatives using contextual information, and Spectral-based Correspondence Denoising to remove false positives using spectral decomposition. The thickness of arrows represents the strength of association between data points.
read the caption
Figure 1: The motivation and key idea. (a) Dual noisy correspondence. The cross-view data pairs are contaminated by both false positive and negative correspondences, and the clean and noisy correspondence is mixed. (b) Top: Context-based Semantic Mining. The existing studies estimate the data affinity based on the data representation and might neglect the out-of-neighborhood yet semantically-associated false negatives. In contrast, we formulate the affinity from one data point to all the others as the context and use them for similarity induction, thus benefiting the false negative uncovering in a global manner; Bottom: Spectral-based Correspondence Denoising. Borrowing from spectral decomposition for signal denoising, we employ spectral denoising on the contextual affinity graph to prevent false positives from dominating the model optimization. In the figure, the thickness of the black arrows represents the association strength between two data points.
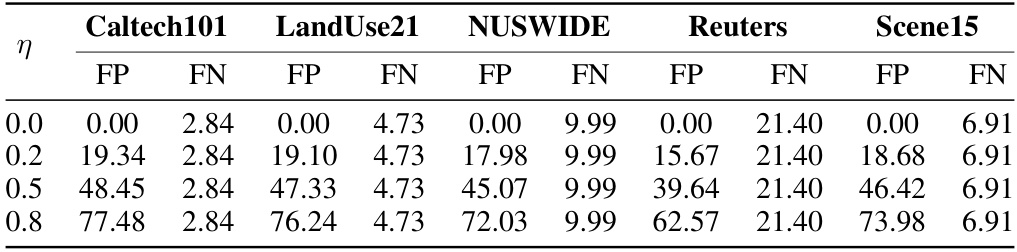
🔼 This table shows the ratio of false positives and false negatives for five different datasets used in the experiments. The false positive ratio (FP) is varied (η = 0.0, 0.2, 0.5, 0.8), while the false negative ratio (FN) remains constant for each dataset. These ratios represent the noise level in the cross-view correspondence data used for training the model, simulating the dual noisy correspondence (DNC) problem.
read the caption
Table 1: The statistics of false positive and false negative ratios (%) with respective to different datasets and η in the experiments.
In-depth insights#
Dual Noisy Corr#
The concept of “Dual Noisy Correspondence” (DNC) introduces a novel challenge to contrastive multi-view clustering. It highlights the realistic scenario where the data, used to build positive and negative sample pairs for contrastive learning, is inherently noisy. False positive correspondences arise from mismatched pairs wrongly labeled as similar, while false negative correspondences occur when genuinely similar pairs are incorrectly identified as dissimilar. This dual noise significantly degrades the effectiveness of standard contrastive learning techniques. The complexity of data collection and processing often contributes to these inaccuracies. Addressing DNC necessitates sophisticated methods, moving beyond simply assuming clean correspondence. The proposed approach, therefore, aims to refine and denoise the correspondence data before applying contrastive learning, mitigating the negative impact of both false positives and negatives. This is crucial for robust and accurate multi-view clustering in real-world applications where noisy correspondence is the norm rather than the exception.
CANDY Method#
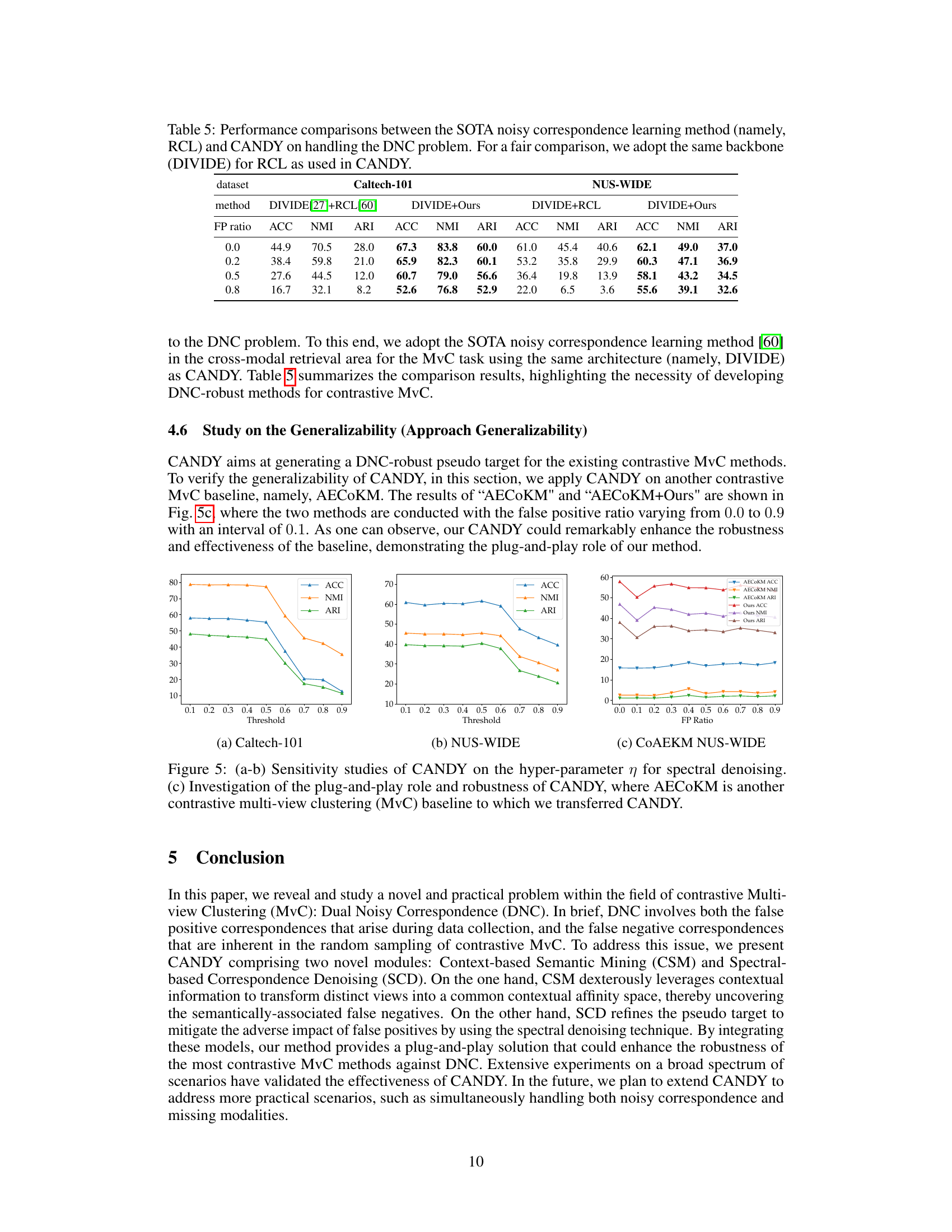
The CANDY method tackles the Dual Noisy Correspondence (DNC) problem in contrastive multi-view clustering. CANDY cleverly uses inter-view similarities as context to identify false negatives, which are instances mistakenly labeled as dissimilar. This context-based semantic mining helps to capture relationships otherwise missed by traditional methods. Furthermore, CANDY incorporates a spectral-based denoising module to mitigate the effects of false positives, which are incorrectly labeled as similar. This is done via singular value decomposition to remove noise from the affinity graph. By combining these two modules, CANDY constructs a refined pseudo-target for contrastive learning, improving robustness against noise and achieving better clustering performance. The method’s plug-and-play design allows it to be readily integrated with various contrastive multi-view clustering methods, enhancing their resilience to the DNC problem. The effectiveness of CANDY is demonstrated through extensive experimental results on multiple benchmarks, showcasing its superiority over existing techniques.
Robust Contrastive#
The concept of “Robust Contrastive” methods in machine learning, particularly within the context of multi-view clustering, points towards a significant advancement in handling noisy data. Traditional contrastive learning methods often struggle when presented with inconsistencies or errors in the data, leading to unreliable or inaccurate results. Robustness, in this context, implies the ability of the algorithm to produce reliable results even with noisy data, while Contrastive refers to the method’s core mechanism of learning by comparing and contrasting similar and dissimilar data points. The combination of these two concepts highlights a critical need to address the challenges posed by real-world datasets, which are rarely clean and complete. The focus lies on developing algorithms that can effectively distinguish between true similarities and false positives/negatives, leading to more accurate and reliable clustering results. This is achieved by incorporating mechanisms that explicitly account for noise in the data, making the learning process less sensitive to erroneous information and producing more reliable models. The development of robust contrastive techniques is a crucial step toward the broader adoption of machine learning in real-world applications, which are rarely characterized by idealized data conditions.
Limitations of CANDY#
A crucial aspect to consider when evaluating CANDY is its limitations. While effective in mitigating dual noisy correspondence (DNC) in contrastive multi-view clustering, CANDY’s performance hinges on the accuracy of the initial view-specific encoders. Poorly learned embeddings will propagate noise despite CANDY’s denoising efforts. Additionally, the computational cost of CANDY is relatively high due to the complexity of its two core modules, making it potentially unsuitable for datasets with exceptionally large numbers of samples or views. The effectiveness of CANDY’s context-based semantic mining module also depends on the existence of semantically related samples, which may not always hold. The choice of hyperparameters, especially the denoising parameter (η), is critical and might require careful tuning for optimal performance on specific datasets. Finally, CANDY’s generalizability across diverse multi-view data types requires further investigation. Although the plug-and-play design is beneficial, its efficacy may vary depending on the specific characteristics of each dataset and contrastive learning method it is applied to.
Future Directions#
Future research could explore several promising avenues. Improving the robustness of CANDY to even more extreme noise levels is crucial; real-world data often presents far greater challenges than those addressed in this study. Developing more sophisticated context modeling techniques within CSM could further enhance the ability to uncover false negatives. Investigating the applicability of CANDY to other multi-view learning tasks beyond clustering, such as classification and regression, is a logical next step. Additionally, exploring different loss functions and optimizing the architecture of the neural networks could boost performance. Finally, a comprehensive theoretical analysis of CANDY’s convergence properties and generalization capabilities would strengthen the paper’s contributions. A key focus should be placed on understanding the trade-offs between computational complexity and performance gains, particularly with regard to high-dimensional data sets. Furthermore, evaluating its performance on larger and more diverse datasets would validate its broader applicability and robustness.
More visual insights#
More on figures
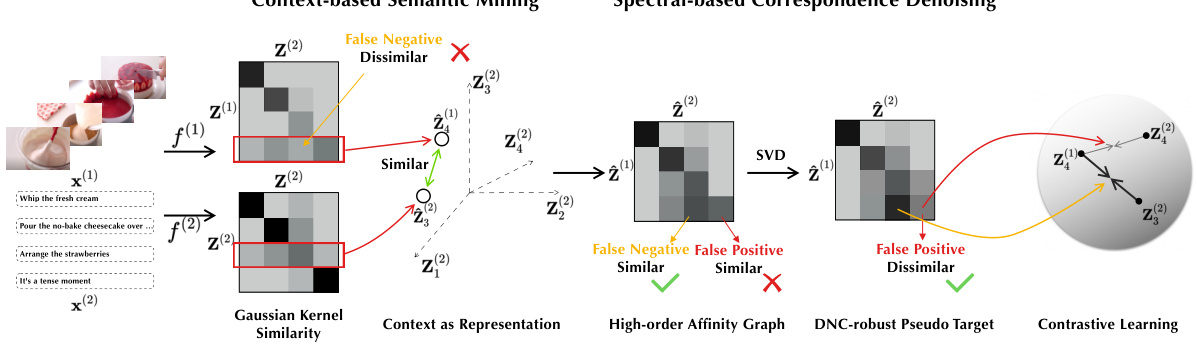
🔼 This figure illustrates the CANDY model’s architecture, detailing its two core modules: Context-based Semantic Mining (CSM) and Spectral-based Correspondence Denoising (SCD). CSM uses inter-view similarities to identify false negatives, while SCD uses spectral decomposition to filter out false positives from the affinity graph. The output is a refined pseudo target for contrastive learning, improving robustness against dual noisy correspondence.
read the caption
Figure 2: Overview of CANDY. First, each view is fed into a view-specific encoder to generate the embeddings. These embeddings are adopted to construct both inter- and intra-view affinity graphs, with edges weighted by Gaussian kernel similarity. The context-based semantic mining module dexterously reformulates inter-view similarities as “context”, employing this context as a set of bases to induce a new contextual affinity space. In this space, the rooted/dissimilar false negatives could be brought to light. Second, the spectral-based correspondence denoising module steps in to alleviate the adverse impacts of noisy correspondence on positive pairs, thus obtaining a low-noise pseudo target. Finally, this pseudo target steers the contrastive learning process, enhancing robustness against DNC in MvC. For the sake of brevity, this figure only presents a simplified depiction involving two views, and the robust contrastive MVC from view 1 to view 2.
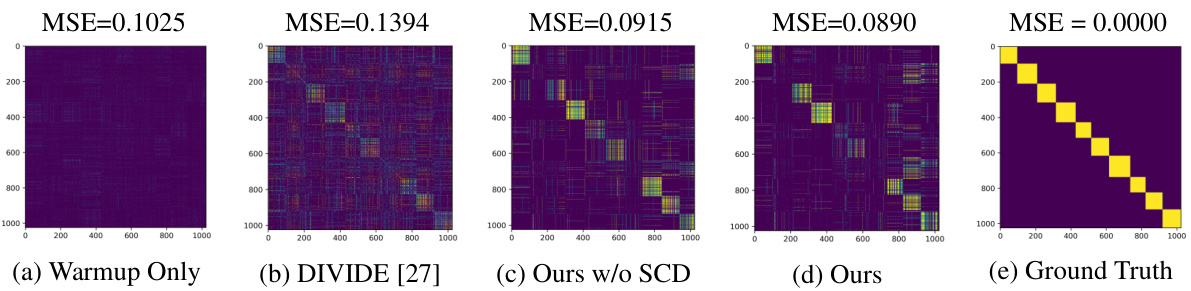
🔼 This figure shows a schematic overview of the CANDY model’s architecture. It illustrates the two main modules, context-based semantic mining and spectral-based correspondence denoising. The process starts with view-specific encoders generating embeddings used to create affinity graphs. Contextual semantic mining refines inter-view similarities, revealing false negatives. Spectral denoising then cleans up the positive pairs, resulting in a refined pseudo target for contrastive learning, ultimately improving robustness against Dual Noisy Correspondence (DNC).
read the caption
Figure 2: Overview of CANDY. First, each view is fed into a view-specific encoder to generate the embeddings. These embeddings are adopted to construct both inter- and intra-view affinity graphs, with edges weighted by Gaussian kernel similarity. The context-based semantic mining module dexterously reformulates inter-view similarities as “context”, employing this context as a set of bases to induce a new contextual affinity space. In this space, the rooted/dissimilar false negatives could be brought to light. Second, the spectral-based correspondence denoising module steps in to alleviate the adverse impacts of noisy correspondence on positive pairs, thus obtaining a low-noise pseudo target. Finally, this pseudo target steers the contrastive learning process, enhancing robustness against DNC in MvC. For the sake of brevity, this figure only presents a simplified depiction involving two views, and the robust contrastive MVC from view 1 to view 2.

🔼 This figure illustrates the CANDY architecture, which consists of two main modules: Context-based Semantic Mining (CSM) and Spectral-based Correspondence Denoising (SCD). CSM uses inter-view similarities to identify false negatives, while SCD uses spectral decomposition to reduce the impact of false positives. The resulting denoised pseudo-target is then used to improve the robustness of contrastive multi-view clustering.
read the caption
Figure 2: Overview of CANDY. First, each view is fed into a view-specific encoder to generate the embeddings. These embeddings are adopted to construct both inter- and intra-view affinity graphs, with edges weighted by Gaussian kernel similarity. The context-based semantic mining module dexterously reformulates inter-view similarities as “context”, employing this context as a set of bases to induce a new contextual affinity space. In this space, the rooted/dissimilar false negatives could be brought to light. Second, the spectral-based correspondence denoising module steps in to alleviate the adverse impacts of noisy correspondence on positive pairs, thus obtaining a low-noise pseudo target. Finally, this pseudo target steers the contrastive learning process, enhancing robustness against DNC in MvC. For the sake of brevity, this figure only presents a simplified depiction involving two views, and the robust contrastive MVC from view 1 to view 2.
More on tables

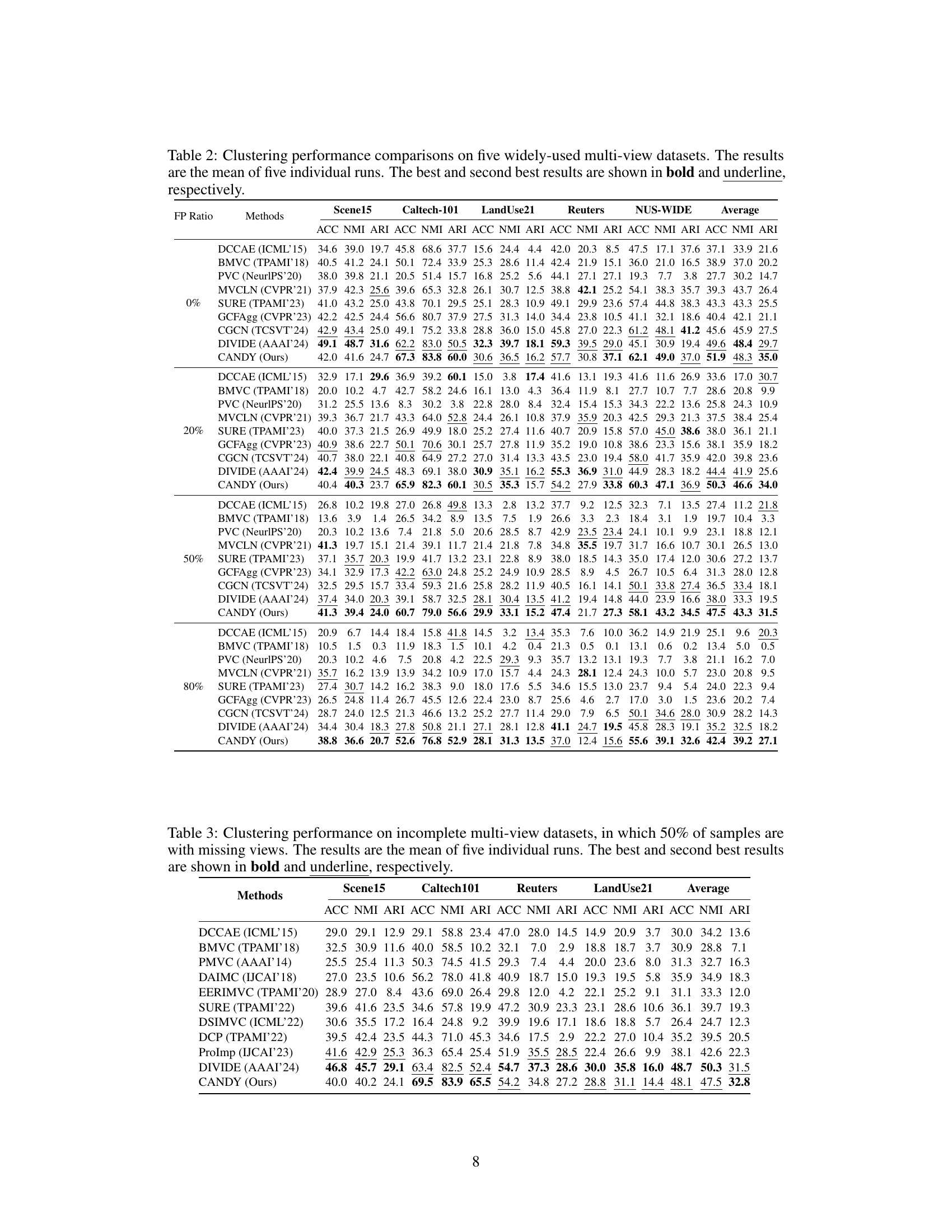
🔼 This table presents a comparison of clustering performance across five different multi-view datasets using various methods. The performance metrics used are Accuracy (ACC), Normalized Mutual Information (NMI), and Adjusted Rand Index (ARI). The table shows results for different false positive (FP) ratios (0%, 20%, 50%, 80%), illustrating the robustness of various methods to noise in the data. The best and second-best performing methods for each dataset and metric are highlighted.
read the caption
Table 2: Clustering performance comparisons on five widely-used multi-view datasets. The results are the mean of five individual runs. The best and second best results are shown in bold and underline, respectively.

🔼 This table presents a comparison of clustering performance across five benchmark datasets using nine different multi-view clustering methods, including the proposed CANDY method. It shows the Accuracy (ACC), Normalized Mutual Information (NMI), and Adjusted Rand Index (ARI) for each method at different false positive ratios (0%, 20%, 50%, and 80%). The best and second-best performing methods are highlighted for each metric and dataset.
read the caption
Table 2: Clustering performance comparisons on five widely-used multi-view datasets. The results are the mean of five individual runs. The best and second best results are shown in bold and underline, respectively.
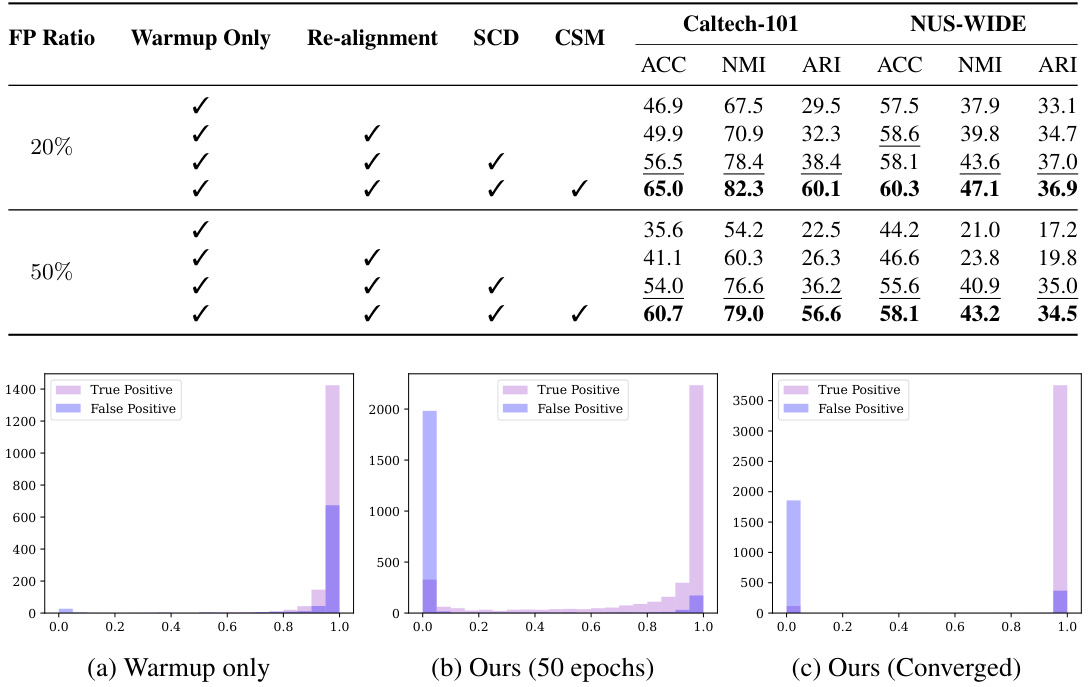
🔼 This table presents a comparison of the clustering performance of CANDY against eight other state-of-the-art multi-view clustering methods across five benchmark datasets. The comparison uses three metrics: Accuracy (ACC), Normalized Mutual Information (NMI), and Adjusted Rand Index (ARI). The results are averaged over five independent runs. The table is organized to show results for different false positive ratios (FP Ratio) in the data, demonstrating CANDY’s robustness to noisy data.
read the caption
Table 2: Clustering performance comparisons on five widely-used multi-view datasets. The results are the mean of five individual runs. The best and second best results are shown in bold and underline, respectively.

🔼 This table compares the performance of CANDY against 8 state-of-the-art multi-view clustering methods across five benchmark datasets. The comparison uses three metrics: ACC (accuracy), NMI (normalized mutual information), and ARI (adjusted rand index). Results are shown for different false positive (FP) ratios (0%, 20%, 50%, 80%) to demonstrate CANDY’s robustness to noise in positive correspondence. The best and second-best results for each metric are highlighted.
read the caption
Table 2: Clustering performance comparisons on five widely-used multi-view datasets. The results are the mean of five individual runs. The best and second best results are shown in bold and underline, respectively.
Full paper#