TL;DR#
Large language models (LLMs) are computationally expensive, and protecting their output’s intellectual property is crucial. Existing acceleration techniques, like speculative sampling, and watermarking methods are typically developed separately. This creates a challenge: how to combine these two crucial aspects efficiently. This paper investigates this very problem and demonstrates that simultaneously achieving both high watermark strength and high sampling efficiency is theoretically impossible.
This research introduces a novel “two reweight framework” that allows for the integration of unbiased watermarking and speculative sampling techniques. The paper then goes on to propose two practical algorithms. The first maintains watermark strength, while the second preserves sampling efficiency, showcasing the inherent trade-off. Numerical experiments validate these theoretical findings and demonstrate the effectiveness of the proposed algorithms in real-world scenarios. The work provides a rigorous theoretical foundation for understanding and navigating this trade-off.
Key Takeaways#
Why does it matter?#
This paper is crucial because it rigorously examines the inherent trade-off between watermark strength and sampling efficiency in accelerating the generation of watermarked tokens for large language models. This is a critical area due to the increasing use of LLMs and growing concerns about intellectual property rights and cost-effective generation. The findings provide a strong theoretical foundation for future research in this field and guide the design of more efficient and effective watermarking techniques for LLMs. The proposed framework and algorithms also offer practical solutions for researchers.
Visual Insights#
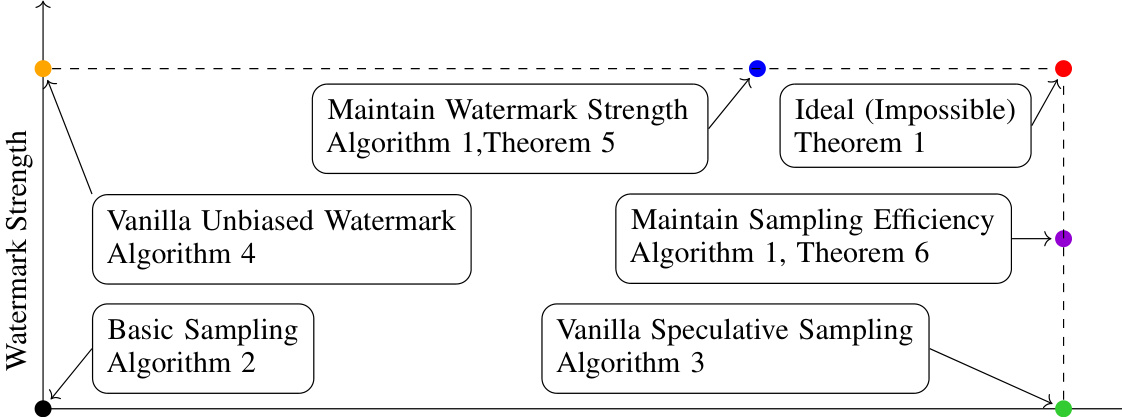
🔼 This figure illustrates the trade-offs between watermark strength and sampling efficiency when combining watermarking and speculative sampling techniques for language models. The ‘ideal’ point, representing high watermark strength and high sampling efficiency, is shown to be theoretically impossible (Theorem 1). The figure presents four algorithms: Basic Sampling, Vanilla Unbiased Watermark, Vanilla Speculative Sampling, and Algorithm 1 (which has two variants, one focusing on maintaining watermark strength and the other on sampling efficiency). Algorithm 1’s variants represent the practical trade-off achievable when trying to balance both objectives.
read the caption
Figure 1: Taxonomy of watermarking and speculative sampling trade-offs in language models. The ideal case of maintaining both watermark strength and sampling efficiency is proven to be impossible by the no-go theorem. The proposed algorithms focus on maintaining either watermark strength or sampling efficiency.
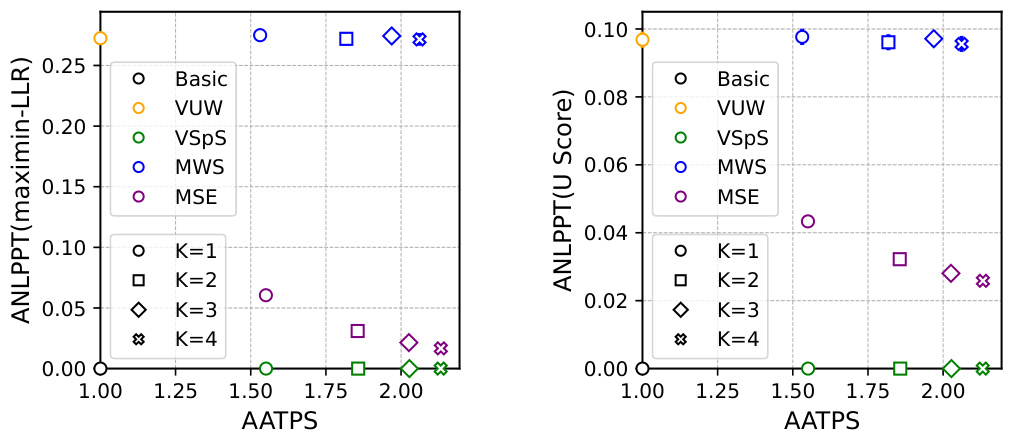
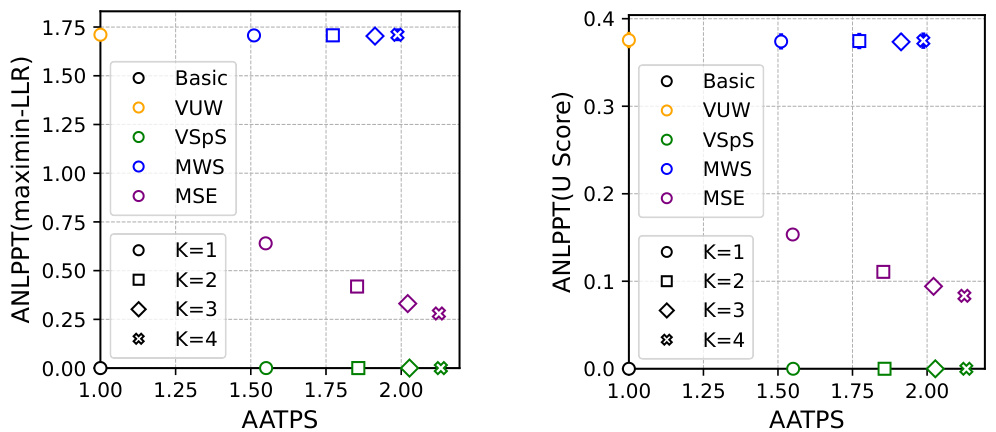
🔼 This table presents the results of a text summarization experiment using the Llama-7b model as the target and Llama-68m as the reference model. It compares several methods, including basic sampling, vanilla unbiased watermarking (VUW), vanilla speculative sampling (VSpS), maintaining watermark strength (MWS), and maintaining sampling efficiency (MSE). For each method, the table shows the average accepted tokens per step (AATPS), per token time (PTT), log perplexity (LOGPPL), average negative log p-value per token (ANLPPT) using the maximin-LLR score, and average negative log p-value per token (ANLPPT) using the U score. Different watermarking schemes (DeltaGumbel and Gamma) are evaluated and results are shown for different draft sequence lengths (K). The data shows the trade-offs between watermark strength and sampling efficiency.
read the caption
Table 1: Text summarization task with LLaMa-7b model [42] as target model and LLaMa-68m model [25] as reference model.
In-depth insights#
Watermark-Speed Tradeoff#
The Watermark-Speed Tradeoff in language models highlights an inherent conflict: stronger watermarks require more computational resources, thus impacting generation speed. Existing watermarking methods focus on embedding information without noticeably altering output quality. However, integrating these with acceleration techniques like speculative sampling presents a challenge. The paper’s core finding is a no-go theorem demonstrating the impossibility of simultaneously achieving maximal watermark strength and sampling efficiency, given a vocabulary size exceeding two. This necessitates a choice between prioritizing either robust watermarks or faster generation, demanding careful consideration of application needs and the potential for trade-offs. The proposed solutions offer methods to optimize either strength or speed but not both simultaneously, underlining the need for context-specific algorithm selection.
Two-Reweight Framework#
The proposed “Two-Reweight Framework” offers a novel approach to accelerate the generation of watermarked tokens in large language models (LLMs) by integrating unbiased watermarking and speculative sampling. Its core innovation lies in simultaneously reweighting both the target and draft models using the same watermark code, unlike naive approaches. This simultaneous reweighting aims to improve sampling efficiency by increasing the overlap between the watermarked target and draft distributions. The framework is theoretically grounded, and the authors provide a rigorous proof demonstrating an inherent trade-off between watermark strength and sampling efficiency when the vocabulary size exceeds two. This trade-off, detailed in a “no-go theorem,” highlights the non-trivial nature of combining these techniques. Despite this limitation, the framework suggests practical algorithms prioritizing either watermark strength or sampling efficiency, providing valuable insights into the achievable balance and facilitating further research in accelerating watermarked LLM output generation.
No-Go Theorem Proof#
A No-Go Theorem in the context of watermarking and speculative sampling for large language models (LLMs) rigorously demonstrates the inherent limitations of simultaneously achieving high watermark strength and high sampling efficiency. The proof likely leverages information theory or probability arguments to establish an upper bound, showing that perfect watermarking (complete preservation of watermark strength) is incompatible with perfect efficiency (no loss of speed due to the watermark). The theorem is a critical finding, highlighting a fundamental trade-off in the design of LLM watermarking systems. This trade-off forces system designers to make crucial decisions: prioritize either robust watermarking at the cost of slower generation or speed improvements with a potential reduction in watermark robustness. The vocabulary size plays a central role in the proof, suggesting that the trade-off becomes increasingly pronounced with larger vocabularies, underscoring the challenges in securing LLMs in practice.
Algorithm Performance#
Analyzing algorithm performance requires a multifaceted approach. It’s crucial to define clear metrics reflecting the goals; for example, in watermarking, watermark strength and sampling efficiency are key. Benchmarking against existing methods provides context, highlighting improvements or inherent trade-offs. Scalability analysis, examining performance with increasing data size or model complexity, is essential. Furthermore, robustness testing evaluates performance under various conditions (e.g., noisy data, adversarial attacks). Finally, a thorough analysis should consider resource consumption (time and memory) and their implications for practical deployment. The effectiveness of an algorithm is not solely determined by raw speed; all these factors contribute to a complete performance evaluation.
Future Research#
Future research directions stemming from this work on watermarking and speculative sampling for large language models could explore refined theoretical frameworks beyond the two-reweight model, potentially leading to less restrictive trade-offs between watermark strength and sampling efficiency. Investigating alternative watermarking techniques less susceptible to attacks or better aligned with the specifics of speculative sampling would also be valuable. Empirical studies focusing on a wider array of LLMs, tasks, and datasets, using the latest speculative sampling advancements, are needed to fully validate the findings and assess the practical impact of proposed methods. Finally, researching robustness against adversarial attacks and the development of user-friendly tools and guidelines for responsible watermarking implementation in LLMs is crucial for ethical and effective deployment of this technology.
More visual insights#
More on figures
🔼 This figure presents a taxonomy illustrating the trade-offs between watermark strength and speculative sampling efficiency in language models. It shows that simultaneously achieving the highest watermark strength and highest sampling efficiency is impossible, as proven by a theoretical ’no-go’ theorem within the paper. The figure highlights two proposed algorithmic approaches: one prioritizing watermark strength and another prioritizing sampling efficiency, representing the practical trade-offs inherent in the problem.
read the caption
Figure 1: Taxonomy of watermarking and speculative sampling trade-offs in language models. The ideal case of maintaining both watermark strength and sampling efficiency is proven to be impossible by the no-go theorem. The proposed algorithms focus on maintaining either watermark strength or sampling efficiency.
🔼 This figure presents a taxonomy showing the trade-offs between watermark strength and speculative sampling efficiency in language models. The central point is a theoretical result (no-go theorem) proving it’s impossible to simultaneously maximize both. The figure illustrates this trade-off and shows how two proposed algorithms prioritize either watermark strength or sampling efficiency.
read the caption
Figure 1: Taxonomy of watermarking and speculative sampling trade-offs in language models. The ideal case of maintaining both watermark strength and sampling efficiency is proven to be impossible by the no-go theorem. The proposed algorithms focus on maintaining either watermark strength or sampling efficiency.

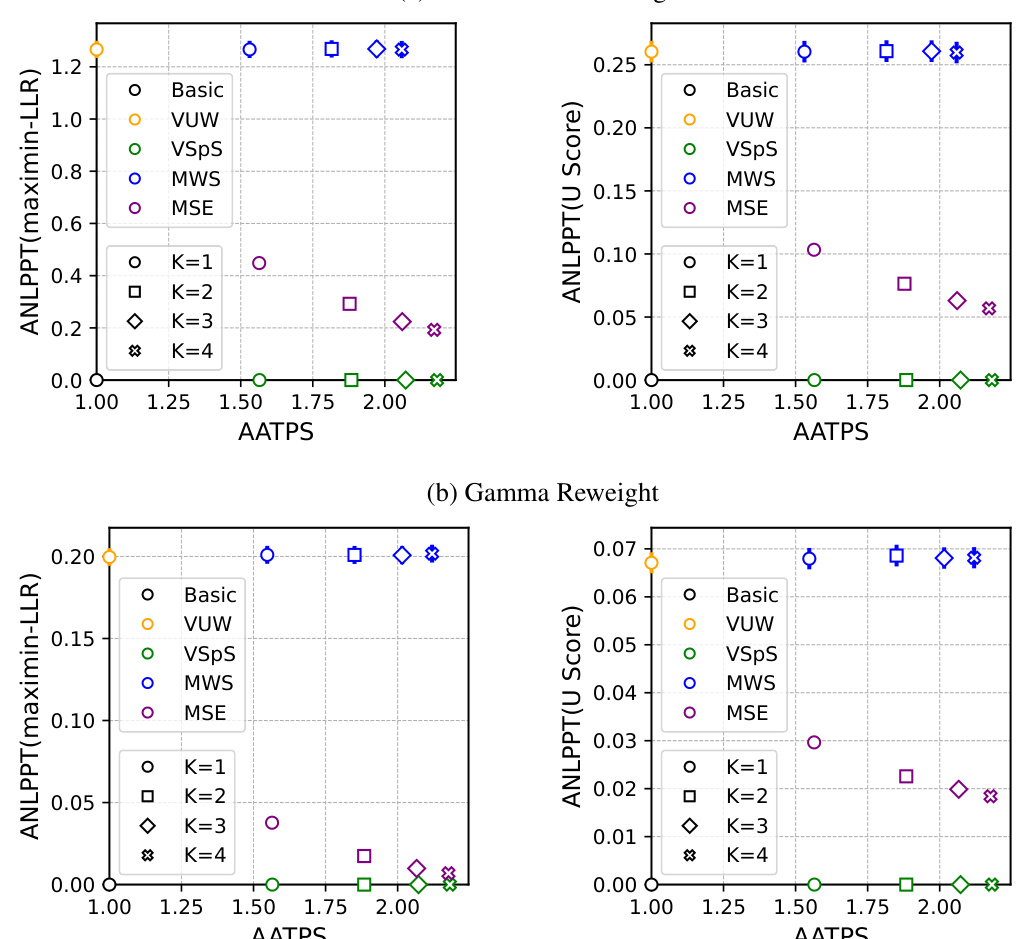
🔼 This figure compares several methods for watermarking and speculative sampling of large language models using two metrics: Average Accepted Tokens Per Step (AATPS) for sampling efficiency, and Average Negative Log P-value Per Token (ANLPPT) for watermark strength. The results are shown for different watermarking schemes (DeltaGumbel and Gamma reweight) and different watermark strength measurement methods (maximin-LLR and U score).
read the caption
Figure 2: Comparison of different methods. The x-axis shows the Average Accepted Tokens Per Step (AATPS) as a measure of speculative sampling efficiency, while y-axis shows the Average Negative Log P-value Per Token (ANLPPT) as a measure of watermark strength. The P-value is computed based on either a likelihood-based test using the maximin-LLR score (left) or a likelihood-agnostic test using the U score (right). Watermarking is performed using either the DeltaGumbel reweight (top) or the Gamma reweight (bottom). Error bars represent 30 confidence intervals.

🔼 This figure presents a taxonomy that visualizes the trade-offs between watermark strength and speculative sampling efficiency in language models. The central point is a theoretical result showing that it’s impossible to simultaneously maximize both watermark strength and sampling efficiency. The taxonomy then branches out to illustrate two proposed algorithmic approaches: one prioritizing watermark strength, and the other prioritizing sampling efficiency. Each approach represents a practical strategy for navigating the inherent trade-off identified by the no-go theorem.
read the caption
Figure 1: Taxonomy of watermarking and speculative sampling trade-offs in language models. The ideal case of maintaining both watermark strength and sampling efficiency is proven to be impossible by the no-go theorem. The proposed algorithms focus on maintaining either watermark strength or sampling efficiency.
More on tables
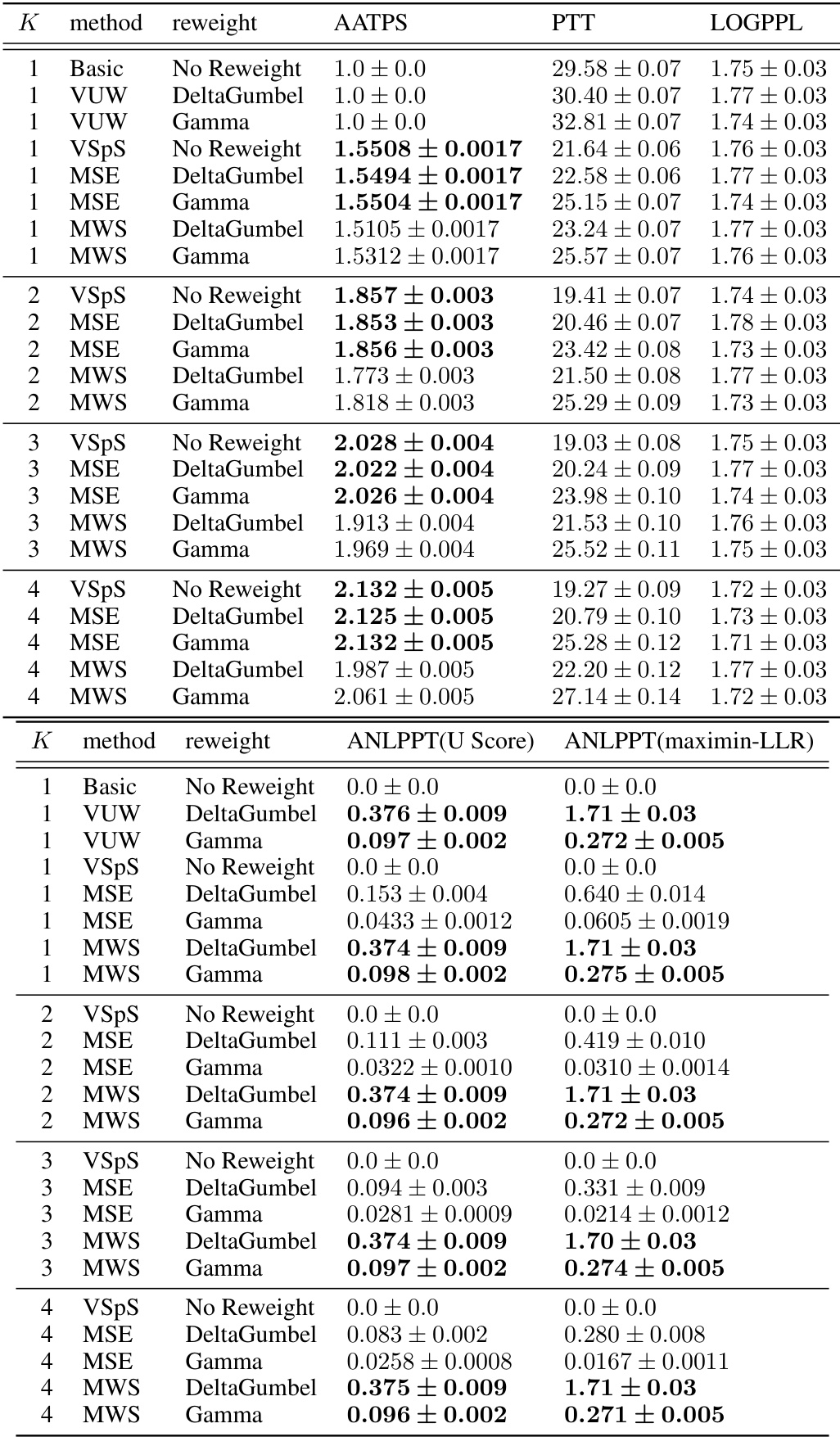
🔼 This table presents the results of a text summarization experiment using the Llama-7b model as the target and Llama-68m as the reference model. Different watermarking and speculative sampling methods are compared across various metrics. The metrics include Average Accepted Tokens Per Step (AATPS) to measure sampling efficiency, Per Token Time (PTT) for inference speed, Log Perplexity (LOGPPL) to evaluate output quality, and Average Negative Log P-value Per Token (ANLPPT) for watermark strength, using both maximin-LLR and U scores for different reweighting schemes (DeltaGumbel and Gamma). The results are shown for different draft sequence lengths (K=1,2,3,4) for each method.
read the caption
Table 1: Text summarization task with LLaMa-7b model [42] as target model and LLaMa-68m model [25] as reference model.
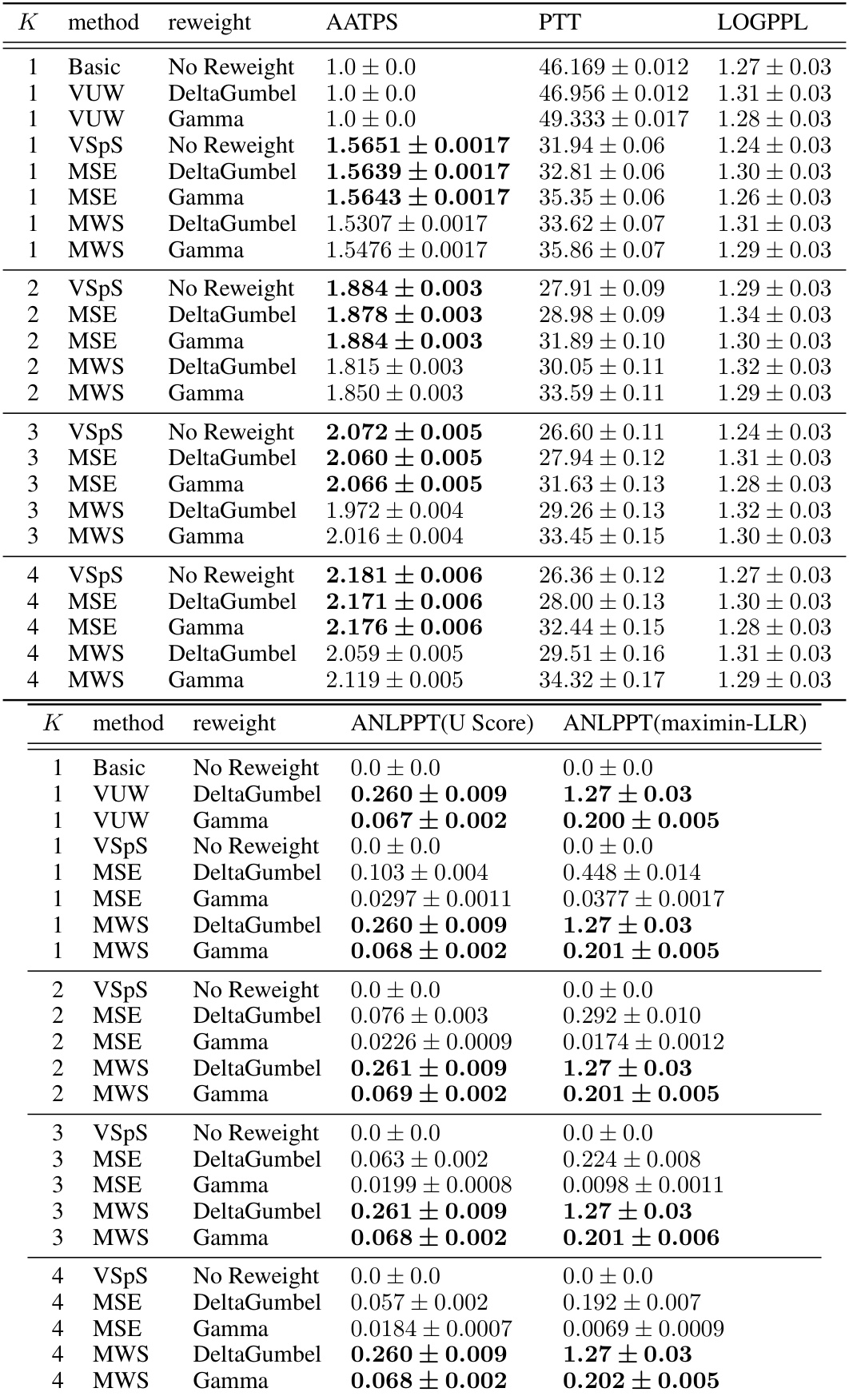
🔼 This table presents the results of a text summarization task using different methods. It compares basic sampling, vanilla unbiased watermarking (VUW), vanilla speculative sampling (VSpS), methods that maintain watermark strength (MWS), and methods that maintain sampling efficiency (MSE). For each method, the table shows the average accepted tokens per step (AATPS) as a measure of sampling efficiency, the per-token time (PTT) as a measure of computational efficiency, the log perplexity (LOGPPL) as a measure of output quality, and the average negative log P-value per token (ANLPPT) as a measure of watermark strength. Different reweighting schemes (DeltaGumbel and Gamma) are used to evaluate the watermarking strength and the P-value is computed based on likelihood-based tests (maximin-LLR) and likelihood-agnostic tests (U Score). The experiment is conducted with different draft sequence lengths (K=1,2,3,4).
read the caption
Table 1: Text summarization task with LLaMa-7b model [42] as target model and LLaMa-68m model [25] as reference model.
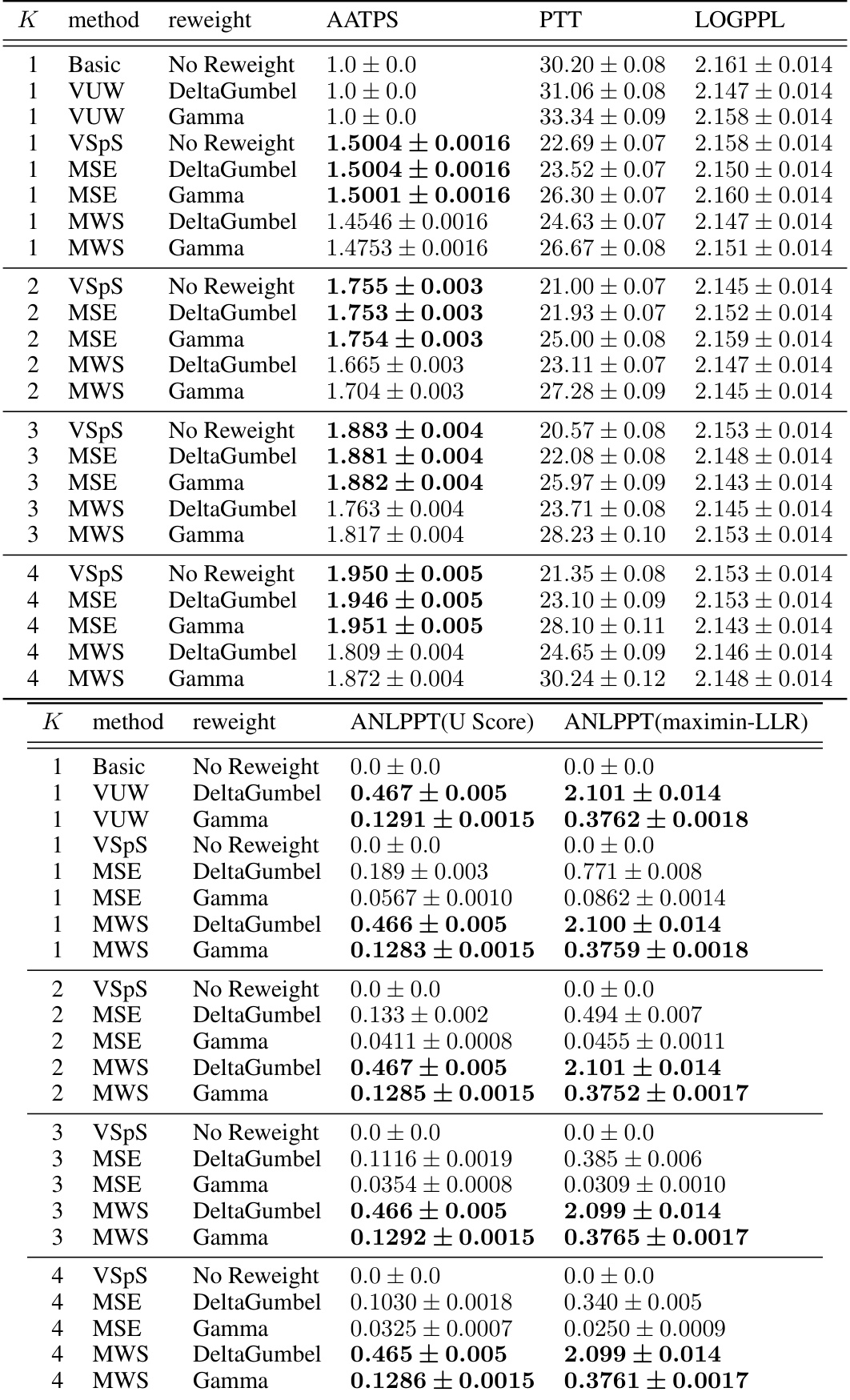
🔼 This table presents the results of text summarization experiments using different methods. The methods are compared across several metrics, including Average Accepted Tokens Per Step (AATPS) representing sampling efficiency, Per Token Time (PTT) representing inference latency, and Log Perplexity (LOGPPL) representing the quality of generated text. Additionally, watermark strength is measured using the Average Negative Log P-value Per Token (ANLPPT), calculated via both maximin-LLR score and U score, for different watermarking schemes (DeltaGumbel and Gamma reweight). The table shows results for different draft sequence lengths (K).
read the caption
Table 1: Text summarization task with LLaMa-7b model [42] as target model and LLaMa-68m model [25] as reference model.
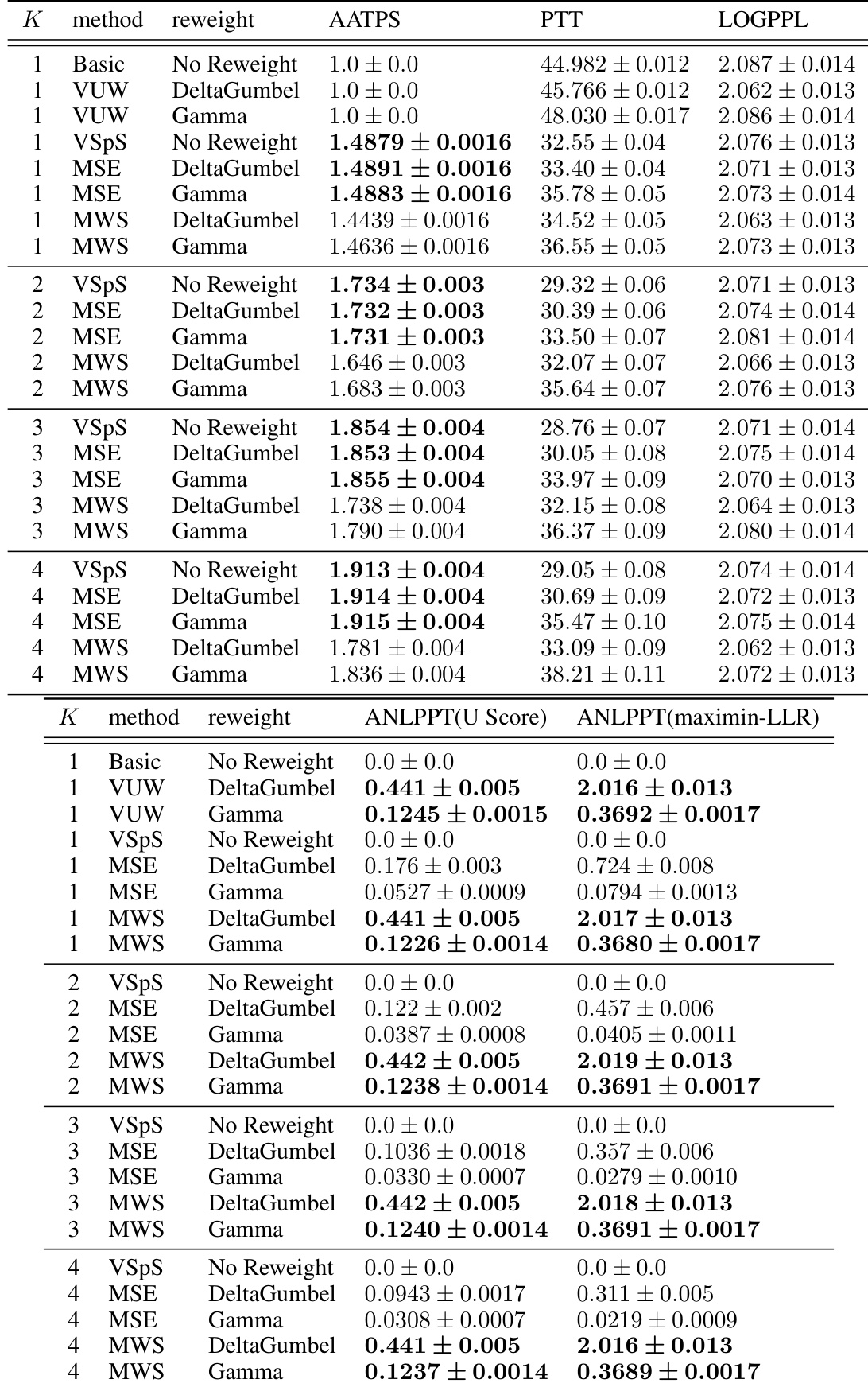
🔼 This table presents the results of a text summarization experiment using two language models: LLaMa-7b as the target and LLaMa-68m as the reference. It compares various methods (Basic Sampling, VUW, VSpS, MSE, and MWS) across different draft sequence lengths (K=1, 2, 3, 4) and reweighting techniques (No Reweight, DeltaGumbel, Gamma). For each method and configuration, it reports the Average Accepted Tokens Per Step (AATPS), Per Token Time (PTT), Log Perplexity (LOGPPL), Average Negative Log P-value Per Token (ANLPPT) using the U score and the maximin-LLR score. The AATPS indicates the efficiency of the speculative sampling method, the PTT is the average time taken per token, the LOGPPL measures the quality of the generated text, while the ANLPPT (using U score and maximin-LLR score) reflects the watermark strength.
read the caption
Table 1: Text summarization task with LLaMa-7b model [42] as target model and LLaMa-68m model [25] as reference model.
Full paper#



















