TL;DR#
Generating high-quality dynamic 3D content from videos is challenging due to limitations in current approaches. Existing methods often struggle with spatial-temporal consistency and surface appearance, especially when using implicit neural representations or explicit Gaussian splatting. These limitations hinder the creation of realistic and visually appealing dynamic 3D models suitable for applications like gaming and film.
DreamMesh4D addresses these issues by introducing a novel framework that combines mesh representation with geometric skinning. Instead of relying on traditional texture maps, it binds Gaussian splats to the mesh’s faces. This hybrid approach allows for differentiable optimization of both texture and mesh vertices, resulting in improved quality and consistency. A novel skinning algorithm mitigates the drawbacks of existing methods, further enhancing the quality of the generated 4D objects. Extensive experiments demonstrate DreamMesh4D’s superiority in terms of rendering quality and spatial-temporal consistency, highlighting its potential in various industries.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer graphics and AI, bridging the gap between 2D video and high-quality 4D mesh generation. It introduces a novel approach, pushing the boundaries of video-to-4D modeling and opening new avenues for realistic 4D content creation in gaming, film, and AR/VR. The introduction of the hybrid Gaussian-mesh representation significantly improves rendering quality and spatial-temporal consistency. The method’s compatibility with modern graphic pipelines makes it highly impactful, offering a substantial improvement for many video-related applications.
Visual Insights#

🔼 This figure demonstrates the capabilities of the DreamMesh4D method. The top row shows a composite scene demo, created by integrating the generated dynamic 3D models into a larger virtual environment. The bottom row shows a sequence of generated dynamic objects (rabbits, goats, and Patrick Star) at different time steps (Time1, Time2, Time3, Time4). This visually showcases the method’s ability to generate high-fidelity, temporally consistent 4D models that are compatible with modern 3D graphics engines, suggesting potential use in gaming and film.
read the caption
Figure 1: Given monocular videos, our method is able to generate high-fidelity dynamic meshes. We also produce a composited scene demo (top bar and left side of the figure) with the generated dynamic meshes, showcasing our method's compatibility with modern 3D engines.

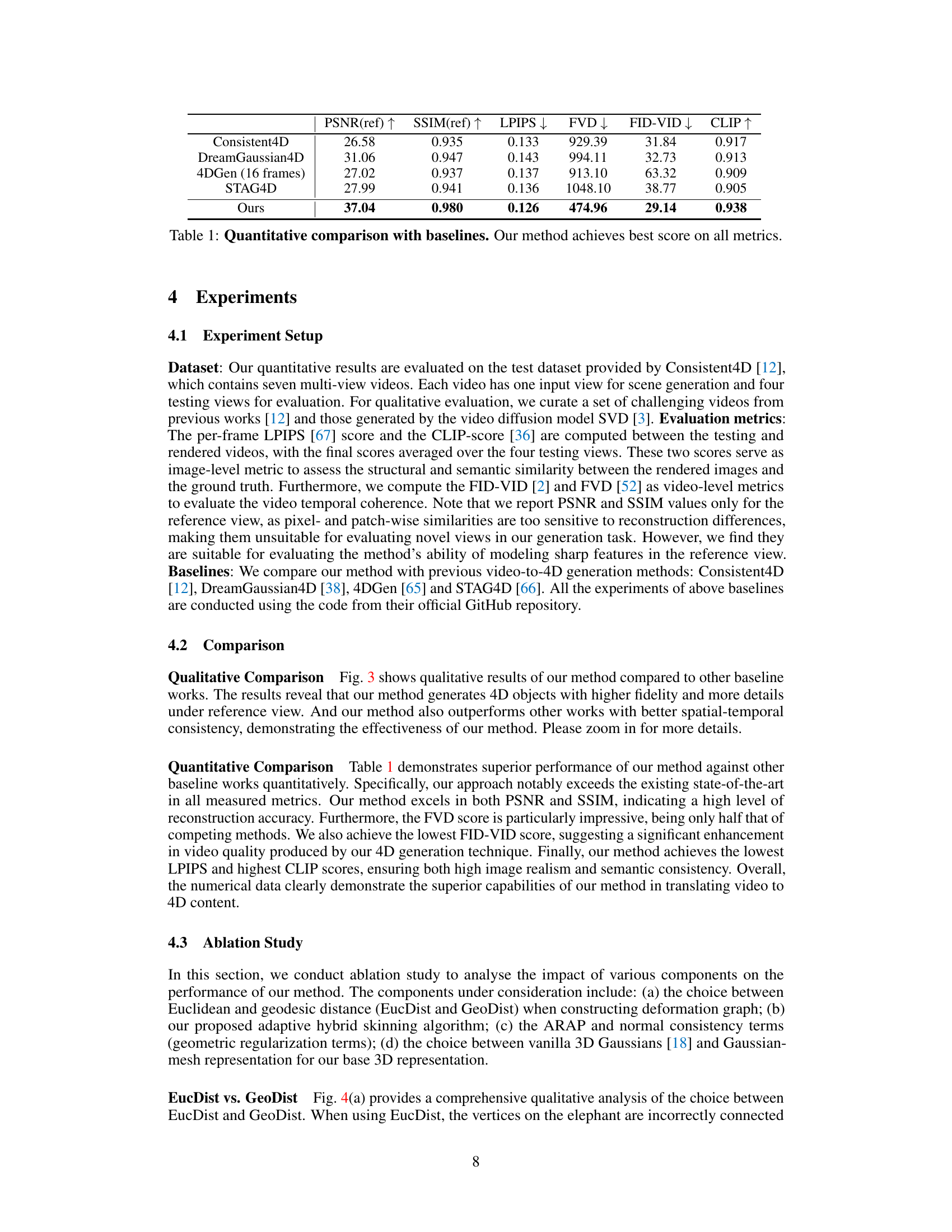
🔼 This table presents a quantitative comparison of the proposed DreamMesh4D method against four state-of-the-art video-to-4D generation baselines. The metrics used for comparison include PSNR, SSIM, LPIPS, FVD, FID-VID, and CLIP. Higher PSNR and SSIM scores indicate better reconstruction quality, while lower LPIPS, FVD, and FID-VID scores signify improved perceptual similarity and temporal consistency. A higher CLIP score implies better alignment with human perception. The results show that DreamMesh4D outperforms all baselines across all metrics.
read the caption
Table 1: Quantitative comparison with baselines. Our method achieves best score on all metrics.
In-depth insights#
4D Mesh Hybrid#
A hypothetical ‘4D Mesh Hybrid’ in a research paper likely refers to a novel representation for dynamic 3D objects. It would integrate the strengths of both mesh-based and implicit representations, possibly leveraging techniques like Gaussian splatting. The “4D” aspect implies the model captures temporal evolution, not just static 3D shapes. This hybrid approach aims to overcome limitations of existing methods. Mesh-based representations excel in geometric detail and editing, but often lack efficient rendering and smooth deformation. Implicit techniques, like NeRFs, offer smooth surfaces and efficient rendering, but can struggle with fine details and complex deformations. A 4D Mesh Hybrid could potentially combine the geometric precision of meshes with the rendering efficiency and temporal consistency of methods like Gaussian Splatting, leading to high-quality, temporally coherent dynamic 3D models. This could involve efficiently deforming a mesh over time while maintaining accurate surface detail by utilizing a hybrid representation combining mesh topology with properties of Gaussian splats. The resulting system might benefit from advancements in geometric skinning or other deformation techniques applied to both the mesh and the Gaussian splatting components. Efficient training and optimization strategies would be crucial for success, and possibly address issues of computational costs that often hinder dynamic 3D model generation. Ultimately, the success of a ‘4D Mesh Hybrid’ depends on balancing these conflicting properties to deliver high-fidelity, efficient, and editable 4D content suitable for applications like gaming or animation.
Adaptive Skinning#
Adaptive skinning, in the context of 3D animation and modeling, aims to seamlessly blend the advantages of different skinning techniques, such as Linear Blend Skinning (LBS) and Dual Quaternion Skinning (DQS), to mitigate their individual shortcomings. LBS is computationally efficient but suffers from artifacts like volume loss, while DQS handles complex deformations better but is computationally expensive. An adaptive approach would dynamically select or weight these methods based on the local geometry and deformation, achieving optimal visual quality with reasonable computational cost. The core challenge lies in devising a robust and efficient algorithm to determine the optimal blend at each vertex or control point, which often requires careful consideration of factors like local deformation, surface curvature, and mesh topology. A successful adaptive skinning method would offer a significant improvement in the quality and realism of animated 3D characters and objects, paving the way for more sophisticated and visually appealing animations in various applications.
Video-4D Pipeline#
A hypothetical ‘Video-to-4D Pipeline’ in a research paper would likely detail a multi-stage process for generating dynamic 3D models (4D) from video input. It would begin with video preprocessing, potentially including frame selection, noise reduction, and stabilization. This would feed into a 3D reconstruction module, possibly employing techniques like structure-from-motion or neural radiance fields (NeRFs) to create an initial 3D mesh or point cloud. The core of the pipeline would involve a temporal modeling component, crucial for capturing movement and deformation over time. This could involve techniques such as dynamic NeRFs, Gaussian splatting, or mesh deformation methods to create a sequence of consistent 3D models representing the object’s motion through time. Finally, a rendering or output module would generate final high-quality 4D representations, which could then be used for various applications like virtual reality or augmented reality. The pipeline’s success hinges on robustness, efficiency, and accuracy. Challenges could include handling occlusions in the video, dealing with noisy or low-resolution inputs, and ensuring temporal consistency. Optimizations may be employed to accelerate processing and reduce resource requirements.
Future 4D Works#
Future research in 4D generation could explore several promising avenues. Improving the efficiency of existing methods is crucial, particularly for real-time applications. This might involve exploring more efficient neural architectures, optimizing the training process, or developing novel data structures. Expanding the range of input modalities beyond monocular video is also important, potentially integrating multi-view video, depth information, or even point clouds to achieve more robust 4D reconstructions. Enhancing the fidelity and realism of generated 4D assets remains a significant challenge. This could involve incorporating advanced rendering techniques, such as ray tracing or path tracing, or developing novel methods for modeling complex materials and textures. Addressing challenges related to temporal consistency is another key area. Developing more sophisticated algorithms for modeling and predicting object motion would improve the smoothness and realism of generated dynamic scenes. Finally, exploring new applications of 4D generation is crucial for driving progress and impacting various fields, such as gaming, film, virtual and augmented reality. This might include developing methods for user interaction and manipulation of 4D objects or generating interactive 4D environments for immersive experiences.
Method Limits#
A hypothetical ‘Method Limits’ section for a video-to-4D generation paper like DreamMesh4D would delve into the inherent constraints of the approach. Data dependency is a primary concern; performance hinges heavily on the quality and characteristics of input videos. Blurry or poorly lit source videos will directly compromise the accuracy and visual fidelity of the generated 4D mesh. Computational cost is another significant limitation, especially considering high-resolution video input and the complexity of mesh deformation. The method’s reliance on a pre-trained image-to-3D model as a starting point introduces its limitations. Generalization capabilities to diverse object types and motion patterns beyond those in the training data might also be limited. The approach’s compatibility with varied video styles and its robustness to noise or artifacts within the input are other factors to explore under method limits. Finally, spatial-temporal consistency is a major challenge; ensuring accurate and smooth transitions between frames requires careful attention to the limitations of the mesh deformation techniques. While the study may showcase high-quality results, a thorough exploration of these limits would provide crucial context for understanding and appropriately applying the methodology.
More visual insights#
More on figures

🔼 This figure shows a pipeline overview of the DreamMesh4D method. The static stage involves generating a coarse mesh from a reference image, refining it using Gaussian splatting, and optimizing it with SuGaR. The dynamic stage builds a deformation graph using sparse control points, predicts control point transformations with an MLP, and applies these transformations to the mesh and Gaussian splatting using adaptive hybrid skinning.
read the caption
Figure 2: Overview of DreamMesh4D. In static stage shown in top left part, a reference image is picked from the input video from with we generate a Gaussian-mesh hybrid representation through a image-to-3D pipeline. As for dynamic stage, we build a deformation graph between mesh vertices and sparse control nodes, and then the mesh and surface Gaussians are deformed by fusing the deformation of control nodes predicted by a MLP through a novel adaptive hybrid skinning algorithm.

🔼 This figure compares the results of the proposed DreamMesh4D method against four other state-of-the-art video-to-4D generation methods. It shows the generated 3D models of three different objects (rabbit, skull, panda) at two different time steps (t1, t2), viewed from both the reference camera angle and a novel view. The comparison highlights DreamMesh4D’s ability to produce sharper, more detailed 3D models, particularly in the novel view, suggesting superior spatial-temporal consistency and rendering quality.
read the caption
Figure 3: Qualitative comparison with baselines. We compare our method with 4 previous video-to-4D methods. The first row provides two ground truth frames for each case. For each compared method, we render each case under reference view and another novel view at the two timestamps. The result demonstrates that our method is able to generate sharper 4D content with rich details, especially for the novel views.
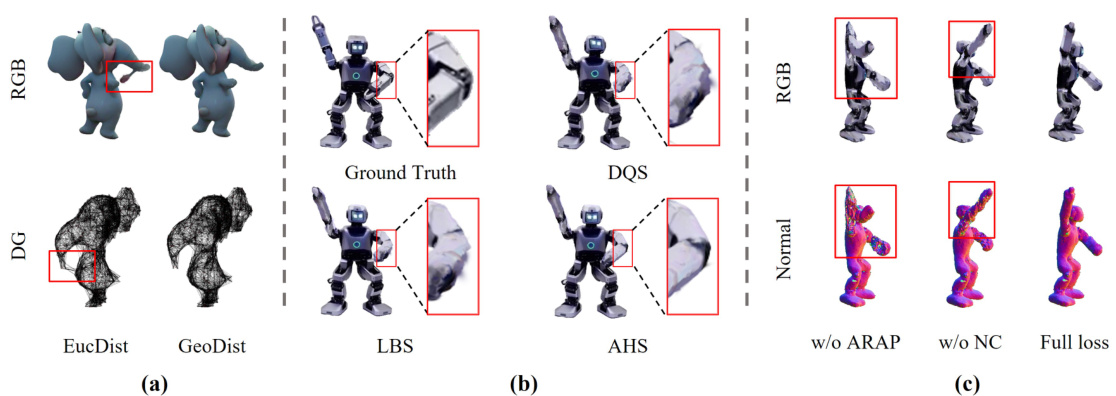
🔼 This figure presents ablation studies to analyze the impact of different components on the performance of the proposed method. It shows a qualitative comparison and visualizes the impact of choosing GeoDist over EucDist for deformation graph construction, using adaptive hybrid skinning (AHS) instead of LBS or DQS, and the effects of ARAP and normal consistency loss. The results demonstrate the benefits of the proposed choices and techniques on generating high-quality dynamic meshes.
read the caption
Figure 4: Qualitative evaluation of ablation studies on: (a) choice between GeoDist and EucDist for deformation graph (DG) construction; (b) our proposed adaptive hybrid skinning (AHS) against LBS and DQS; (c) effects of ARAP and normal consistency (NC) loss.

🔼 This figure compares the visual quality of 3D object generation using two different representations: 3D Gaussians and the Gaussian-mesh hybrid. The results show that the Gaussian-mesh hybrid representation produces significantly better texture quality, especially for parts of the object not directly visible in the reference image.
read the caption
Figure 5: Qualitative comparison on 3D representation between 3D Gaussians and Gaussian-mesh hybrid representation. When utilizing 3D Gaussians as our base 3D representation, the texture is blurry on the parts unseen in reference image. As a comparison, the texture is clean and of high quality under every view when employing the Gaussian-mesh hybrid representation.
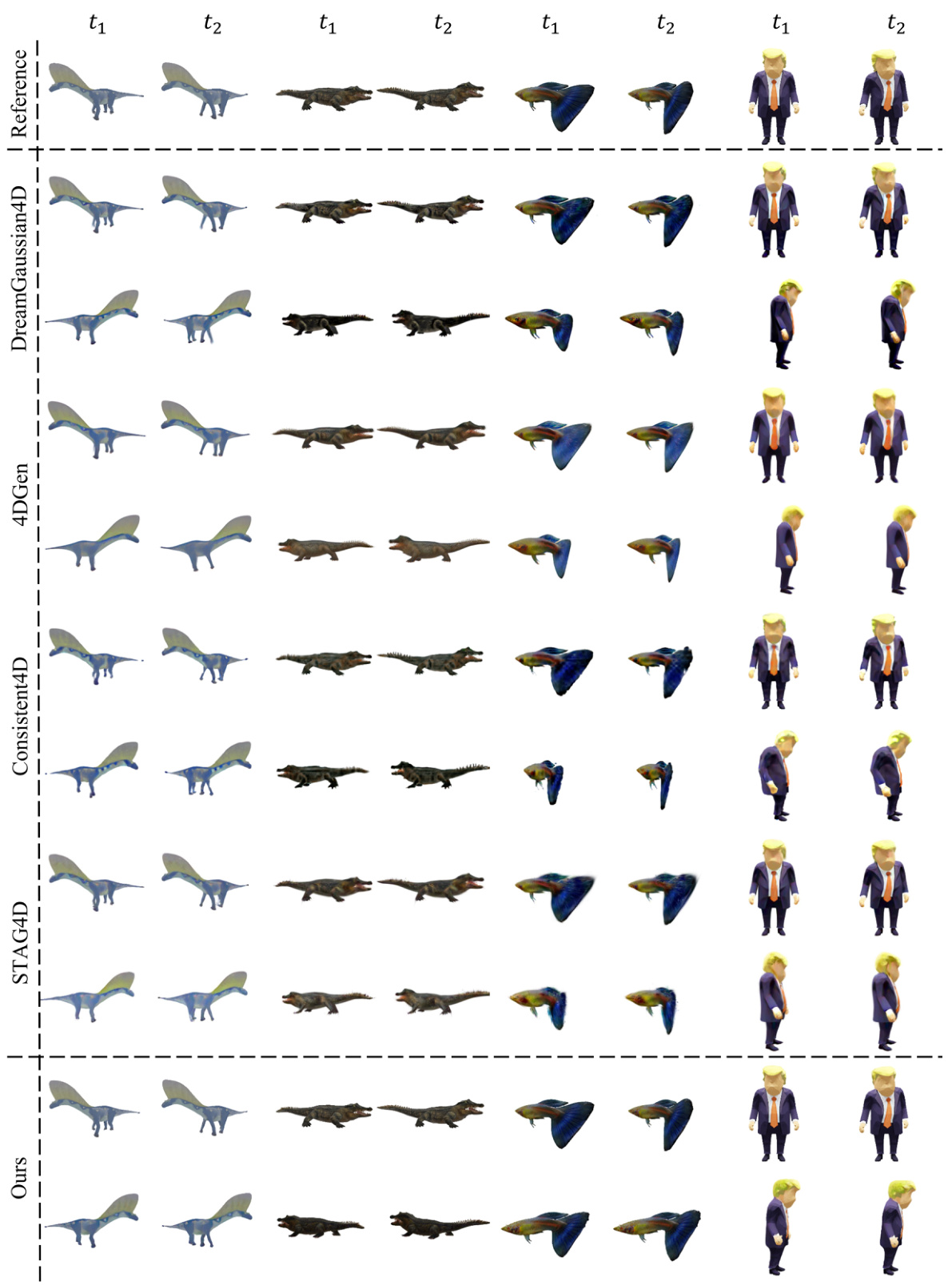
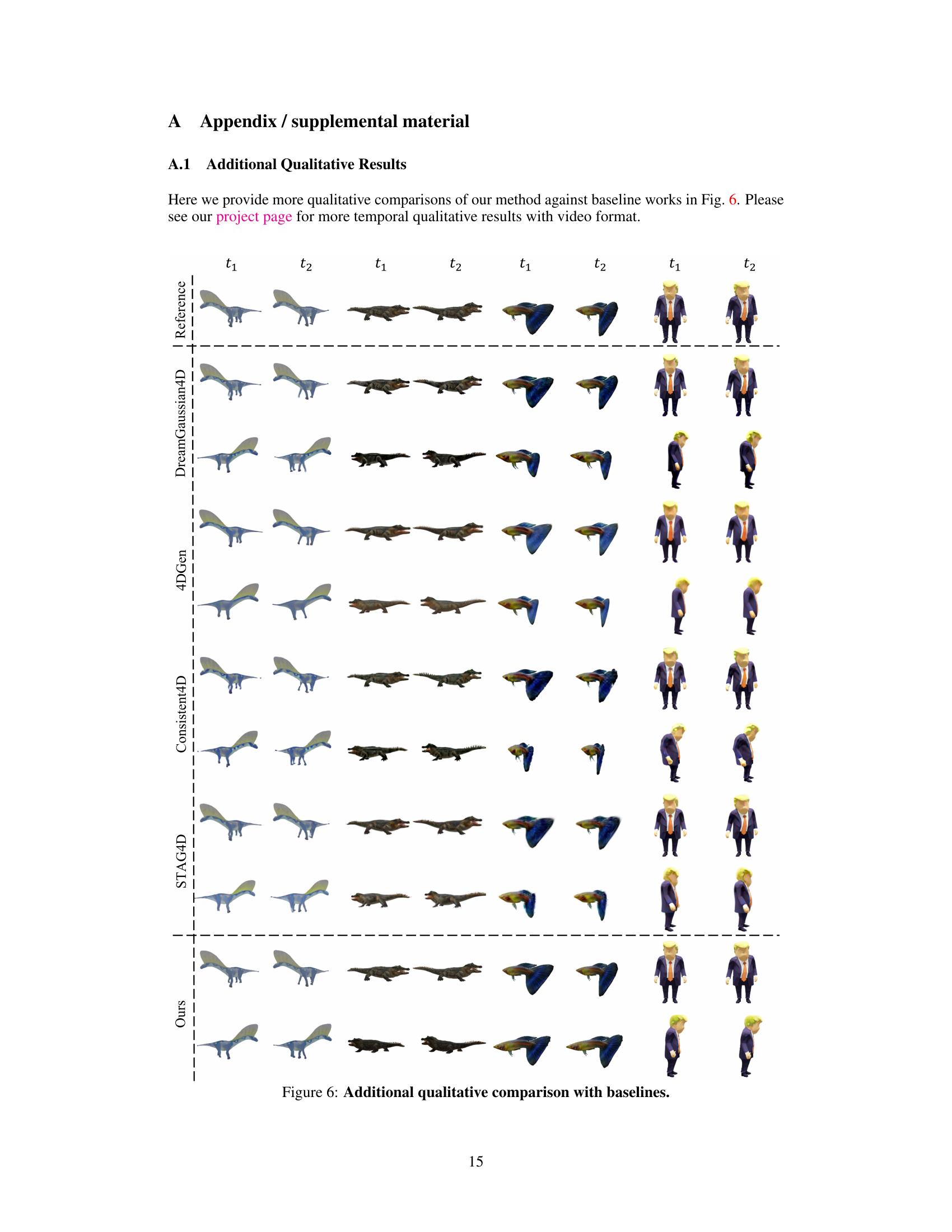
🔼 This figure provides additional qualitative comparisons of the proposed method against four baseline video-to-4D methods. It shows the generated results for four different objects (dinosaur, alligator, fish, and a person) at two different timestamps (t1 and t2). The reference images are provided in the top row. The goal is to visually demonstrate the improved rendering quality and detail preservation offered by the proposed method compared to existing approaches.
read the caption
Figure 6: Additional qualitative comparison with baselines.

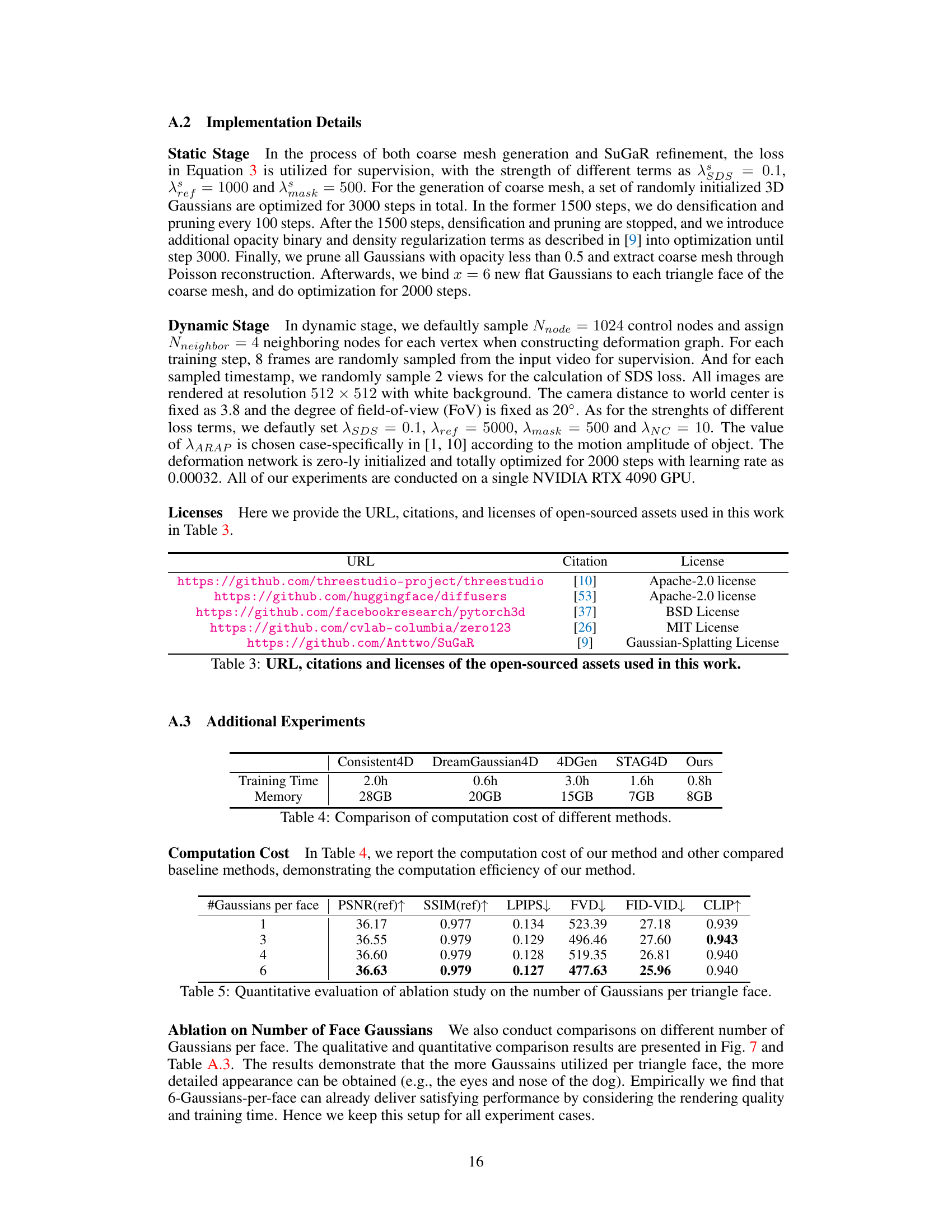
🔼 This figure shows the effect of using different numbers of Gaussians per triangle face on the quality of the generated mesh. The results demonstrate that increasing the number of Gaussians improves the detail and sharpness of the generated mesh, especially for fine details like the eyes and nose. The top row presents the reference images, while the bottom row shows zoomed-in views of the eyes and nose region under different Gaussian configurations.
read the caption
Figure 7: Qualitative comparison on the number of Gaussians per face. The appearance quality of details (e.g., the eyes and nose) is getting better when binding more number of Gaussians on triangle face.
More on tables

🔼 This table presents a quantitative comparison of the proposed DreamMesh4D method against four baseline video-to-4D generation methods: Consistent4D, DreamGaussian4D, 4DGen, and STAG4D. The comparison is based on several metrics evaluating different aspects of the generated 4D content including: PSNR(ref) and SSIM(ref) which measure the quality of the reference view reconstruction; LPIPS which quantifies perceptual differences; FVD and FID-VID which assess video-level temporal consistency; and CLIP which evaluates the semantic similarity. DreamMesh4D outperforms all baselines on all metrics, demonstrating its superior performance in terms of both rendering quality and spatial-temporal consistency.
read the caption
Table 1: Quantitative comparison with baselines. Our method achieves best score on all metrics.

🔼 This table presents a quantitative comparison of the proposed DreamMesh4D method against four state-of-the-art video-to-4D generation baselines across multiple metrics. The metrics used assess both per-frame image quality (PSNR, SSIM, LPIPS) and video-level temporal consistency (FVD, FID-VID, CLIP). The results demonstrate that DreamMesh4D outperforms all baselines in all metrics, achieving the highest scores for PSNR, SSIM, CLIP, and the lowest scores for LPIPS, FVD, and FID-VID.
read the caption
Table 1: Quantitative comparison with baselines. Our method achieves best score on all metrics.

🔼 This table presents a quantitative comparison of the proposed DreamMesh4D method against four existing video-to-4D generation baselines (Consistent4D, DreamGaussian4D, 4DGen, and STAG4D) across various metrics. These metrics evaluate different aspects of the generated 4D content, such as rendering quality (PSNR, SSIM, LPIPS), temporal consistency (FVD), and overall fidelity (FID-VID, CLIP). The results demonstrate that DreamMesh4D outperforms the baselines in all metrics, indicating its superior performance in generating high-fidelity and temporally consistent dynamic meshes from monocular videos.
read the caption
Table 1: Quantitative comparison with baselines. Our method achieves best score on all metrics.

🔼 This table presents a quantitative comparison of the proposed DreamMesh4D method against four baseline video-to-4D generation methods (Consistent4D, DreamGaussian4D, 4DGen, and STAG4D) across several metrics. The metrics used include PSNR(ref) and SSIM(ref) (for the reference view only), LPIPS (a perceptual dissimilarity metric), FVD (a video quality metric), FID-VID (another video quality metric), and CLIP (a metric of similarity to ground truth). The results demonstrate that DreamMesh4D outperforms all baseline methods on all these metrics.
read the caption
Table 1: Quantitative comparison with baselines. Our method achieves best score on all metrics.
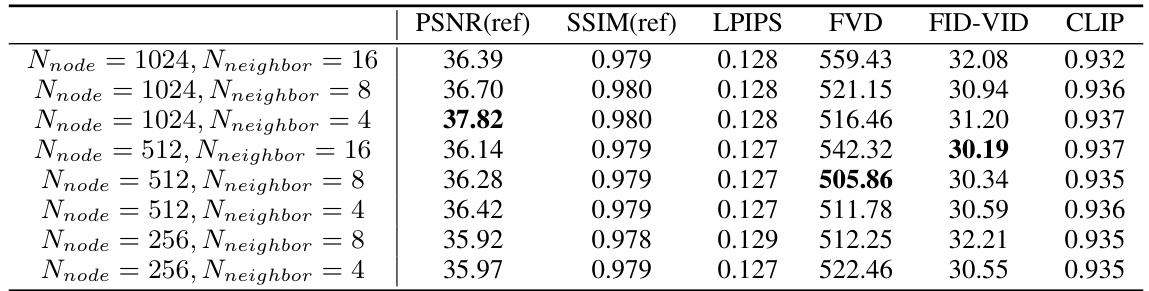
🔼 This table presents a quantitative comparison of the proposed DreamMesh4D method against several state-of-the-art video-to-4D generation baselines. The metrics used for comparison include PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), LPIPS (Learned Perceptual Image Patch Similarity), FVD (Fréchet Video Distance), FID-VID (Fréchet Inception Distance for Videos), and CLIP (Contrastive Language–Image Pre-training) score. Higher PSNR and SSIM values indicate better reconstruction quality, while lower LPIPS, FVD, and FID-VID scores represent better perceptual similarity and temporal consistency. A higher CLIP score suggests better alignment between generated visuals and textual descriptions. The table shows that DreamMesh4D outperforms all baselines across all metrics.
read the caption
Table 1: Quantitative comparison with baselines. Our method achieves best score on all metrics.
Full paper#