TL;DR#
Current methods for point cloud understanding struggle with adapting to continuously changing target domains, suffering from catastrophic forgetting and error accumulation. This is especially challenging in multi-task scenarios where models need to handle multiple tasks simultaneously. This paper tackles these challenges by introducing PCoTTA.
PCoTTA employs three key modules: Automatic Prototype Mixture (APM) to prevent catastrophic forgetting, Gaussian Splatted Feature Shifting (GSFS) to dynamically align testing samples with source data, and Contrastive Prototype Repulsion (CPR) to improve prototype distinctiveness. Experiments show that PCoTTA significantly outperforms state-of-the-art methods across multiple tasks and domains, setting a new benchmark for continual test-time adaptation in point cloud understanding.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in point cloud understanding and continual learning. It introduces a novel framework for handling multi-task continual test-time adaptation, a significant challenge in the field. The proposed approach addresses catastrophic forgetting and error accumulation, paving the way for more robust and adaptable models in dynamic environments. This research opens new avenues for developing AI systems that can effectively adapt to continuously evolving data streams, which is highly relevant for real-world applications.
Visual Insights#

🔼 This figure compares previous Unsupervised Domain Adaptation (UDA) approaches with the proposed PCoTTA framework. (a) illustrates the limitations of previous UDA methods in handling continually changing target domains, such as catastrophic forgetting and error accumulation. (b) shows the proposed PCoTTA framework which addresses these limitations by enhancing the model’s transferability. The key difference is that PCoTTA utilizes a prototype bank to effectively manage continual adaptation, avoiding the issues present in previous methods.
read the caption
Figure 1: (a) Previous UDA approaches on point cloud suffer from catastrophic forgetting and error accumulation toward the continually changing target domains. (b) In contrast, we present an innovative framework PCOTTA to address these issues, enhancing the model's transferability.

🔼 This table presents a comparison of the proposed PCoTTA method against other state-of-the-art approaches on the continual test-time adaptation (CoTTA) setting. The comparison considers three tasks (Reconstruction, Denoising, Registration) and two target domains (ModelNet40 and ScanObjectNN) across multiple rounds of testing. Chamfer Distance (CD) is used as a performance metric, with lower CD values indicating better performance. The results showcase the superiority of PCoTTA in terms of lower CD values, signifying better performance across all tasks and domains.
read the caption
Table 1: Comparisons with the state-of-the-art approaches on the CoTTA setting. We report the Chamfer Distance (CD, ×10−3) for different tasks. The lower CD denotes the better performance.
In-depth insights#
CoTTA Framework#
A CoTTA (Continual Test-Time Adaptation) framework is designed to enhance a model’s adaptability to continuously evolving target domains. This is achieved by enabling the model to learn and adapt incrementally at the testing stage, without the need for retraining on the entire dataset. A key feature would be its capacity to handle multi-task settings, where the model addresses multiple tasks within the same framework. Catastrophic forgetting is mitigated through innovative techniques like prototype mixing or other memory management strategies. Online adaptation mechanisms ensure that the model efficiently learns from incoming data streams without significant computational burden. Transfer learning plays a crucial role, leveraging pre-trained knowledge from source domains to facilitate adaptation to new domains. The framework would likely include mechanisms for dynamically updating model parameters and integrating novel information in an efficient manner, and be evaluated on its ability to avoid error accumulation and retain transferability.
Prototype Mixture#
Prototype mixture, in the context of continual test-time adaptation for multi-task point cloud understanding, is a crucial technique to mitigate catastrophic forgetting. It elegantly addresses the challenge of adapting to continually changing target domains without losing knowledge gained from previously seen source domains. By intelligently combining source prototypes (from pre-trained models) with learnable prototypes (representing the current target domain), a dynamic and robust adaptation is achieved. The method effectively balances the preservation of source domain knowledge with the acquisition of new knowledge, preventing the model from straying too far from its initial training and maintaining transferability. A key aspect is the automatic weighting or mixing of these prototypes, often guided by similarity measures between the prototypes and the target data. This ensures that relevant knowledge from the source is prioritized during adaptation, preventing catastrophic forgetting. The result is a model capable of seamlessly transitioning between tasks and domains, demonstrating superior performance in continual learning settings.
GSFS Adaptation#
Gaussian Splatted Feature Shifting (GSFS) adaptation is a crucial component in continual test-time adaptation for multi-task point cloud understanding. GSFS dynamically shifts testing samples towards the source domain, mitigating error accumulation during online adaptation. This is achieved by leveraging the distance between testing features and shared prototypes in a prototype bank. A Gaussian weighted graph attention mechanism further refines this process, adaptively scheduling the shifting amplitude based on sample similarity to prototypes. This clever design helps to maintain a balance between leveraging source domain knowledge and adapting to target domain characteristics, ultimately improving model transferability and robustness in continually evolving environments. Key to GSFS is its dynamic nature; it doesn’t statically shift features but rather adjusts based on the sample’s context within the prototype bank. This adaptive mechanism prevents the model from catastrophic forgetting and ensures that the adaptation is both effective and efficient. The interplay between GSFS and other components such as APM and CPR is vital for the overall success of the continual test-time adaptation framework.
Multi-Task Learning#
Multi-task learning (MTL) in the context of point cloud understanding presents a powerful paradigm shift. Instead of training separate models for individual tasks like reconstruction, denoising, and registration, MTL advocates for a unified architecture capable of handling multiple objectives simultaneously. This approach offers several key advantages: improved efficiency by leveraging shared representations, reduced computational costs, and enhanced generalization due to the model’s exposure to diverse data modalities during training. However, MTL also faces challenges. Negative transfer can occur when tasks interfere with each other, hindering performance. Catastrophic forgetting becomes a concern in continual learning scenarios, where the model is sequentially exposed to new tasks and struggles to retain knowledge of previously learned tasks. Addressing these challenges requires careful consideration of model architecture, loss function design, and regularization strategies. Effective MTL in point cloud processing often involves addressing the unique challenges posed by 3D data, including sparsity and irregularity, by leveraging techniques such as graph neural networks or attention mechanisms to capture spatial relationships effectively. The success of MTL hinges on the careful selection of tasks, ensuring that they are related but not excessively overlapping to avoid negative transfer, and robust training methods to mitigate catastrophic forgetting.
Future of CoTTA#
The future of Continual Test-Time Adaptation (CoTTA) appears bright, driven by several key trends. Multi-modality will become increasingly important, enabling CoTTA systems to integrate and adapt from diverse data sources (images, text, sensor data). This will require sophisticated fusion techniques and robust adaptation strategies. Increased efficiency is crucial; current methods are computationally expensive, hindering real-time applications. Future research will focus on lightweight architectures, efficient optimization algorithms, and adaptive resource allocation. Handling catastrophic forgetting remains a significant challenge. More effective techniques that preserve knowledge from previous experiences, perhaps inspired by biological memory systems, are necessary. More realistic evaluation benchmarks are needed, reflecting the complexities of real-world continual learning scenarios. These benchmarks should assess generalizability, robustness, and efficiency under diverse conditions. Finally, greater focus on ethical considerations will be vital as CoTTA systems are increasingly deployed in high-stakes applications. Addressing issues of fairness, bias, and transparency will be critical to ensure responsible innovation.
More visual insights#
More on figures
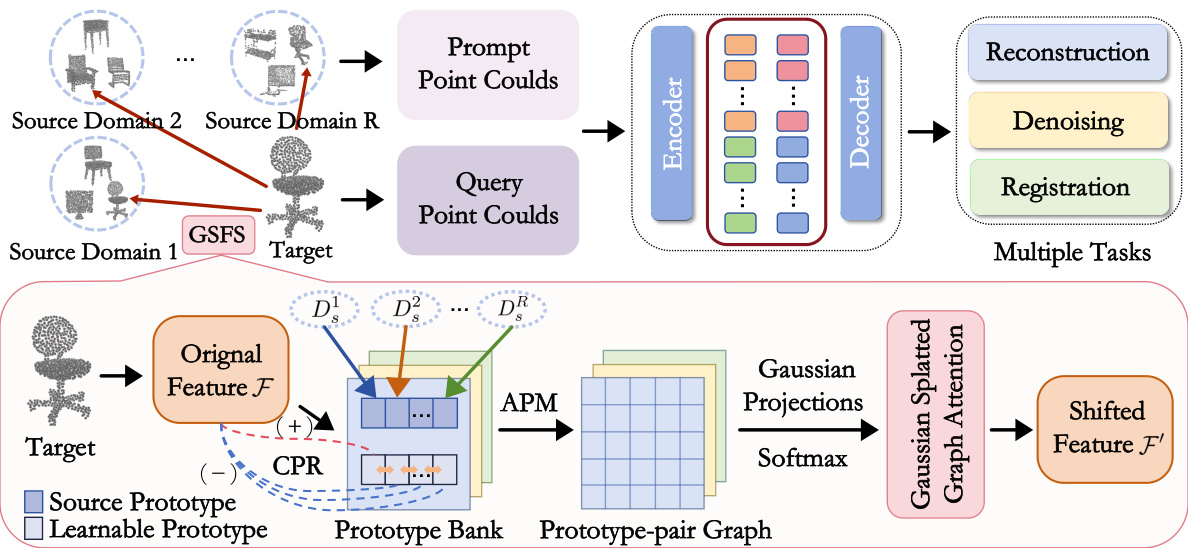
🔼 This figure illustrates the PCoTTA framework. It shows how a unified model handles multiple tasks (reconstruction, denoising, registration) and continually changing target domains by using a source domain as a prompt, aligning unknown targets with known sources via Gaussian Splatted Feature Shifting (GSFS), managing prototypes via Automatic Prototype Mixture (APM) and Contrastive Prototype Repulsion (CPR) to avoid catastrophic forgetting and enhance adaptability.
read the caption
Figure 2: Our PCoTTA. It addresses continually changing targets by using their nearest source sample as a prompt for multi-task learning within a unified model. We introduce Gaussian Splatted Feature Shifting (GSFS) to align unknown targets with sources, improving transferability. Source prototypes from different domains and learnable prototypes form a prototype bank. The Automatic Prototype Mixture (APM) pairs these prototypes based on the similarity to the target, preventing catastrophic forgetting. We project these prototypes as Gaussian distributions onto the feature plane, with larger weights assigned to more relevant ones. Our graph attention updates these weights dynamically to mitigate error accumulation. Additionally, our Contrastive Prototype Repulsion (CPR) ensures that learnable prototypes are distinguishable for different targets, enhancing adaptability.

🔼 This figure illustrates the two core modules of PCoTTA: Automatic Prototype Mixture (APM) and Gaussian Splatted-based Graph Attention. APM combines source and learnable prototypes based on their similarity to the target, preventing catastrophic forgetting. The Gaussian Splatted-based Graph Attention dynamically adjusts weights based on Gaussian projections of prototype pairs, adapting to continually changing target domains.
read the caption
Figure 3: (a) Automatic Prototype Mixture (APM) considers both source and learnable prototypes with their similarities to the target, mitigating catastrophic forgetting by preserving source information. (b) Gaussian Spaltted-based Graph Attention enables dynamic updating weights among all prototype-pair nodes based on the Gaussian projections splatted onto the feature plane.

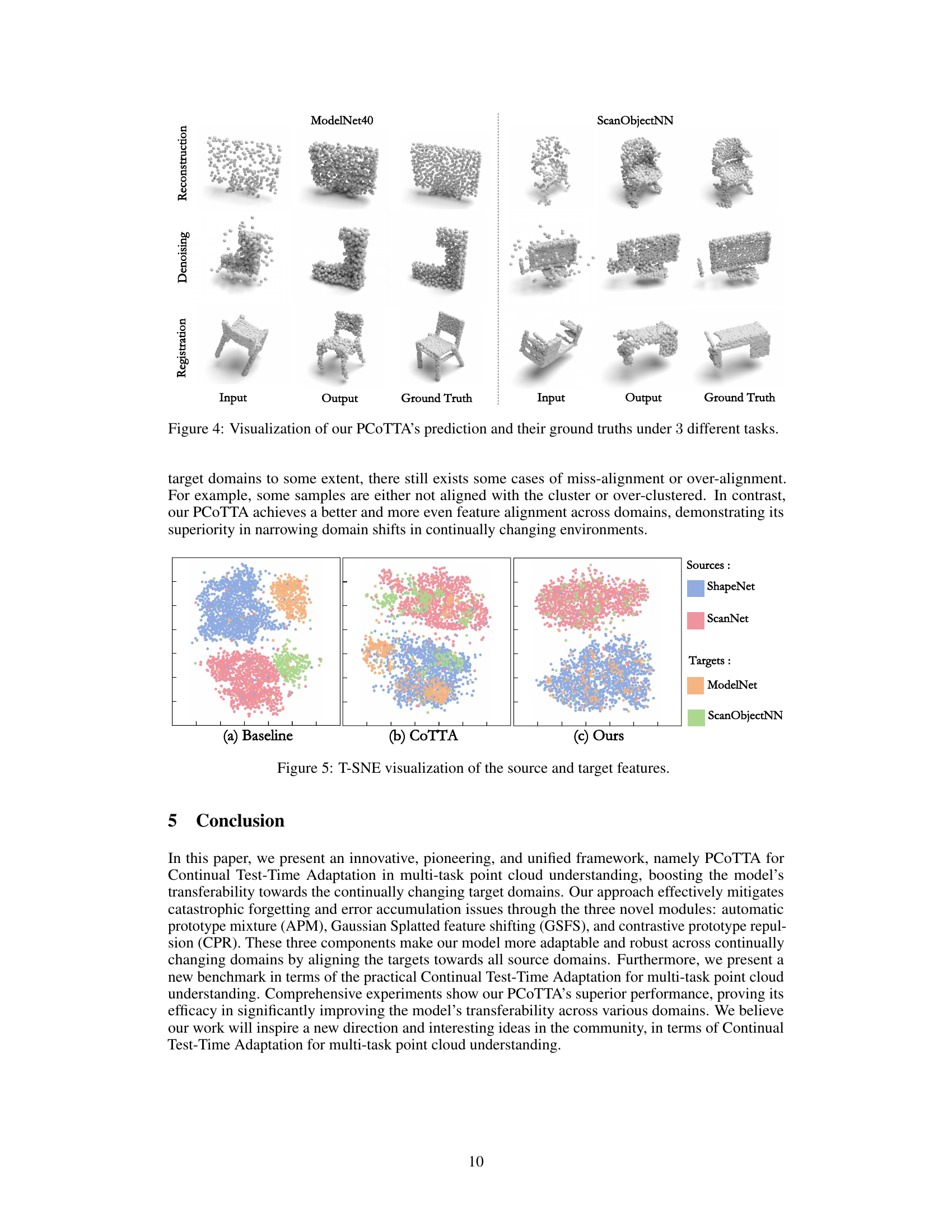
🔼 This figure visualizes the results of the PCoTTA model on three different tasks: reconstruction, denoising, and registration. It shows the input point clouds, the model’s output, and the ground truth for both ModelNet40 and ScanObjectNN datasets. The visualization helps to understand the model’s performance in handling various challenges related to point cloud data, including reconstructing incomplete shapes, removing noise, and aligning point clouds.
read the caption
Figure 4: Visualization of our PCoTTA's prediction and their ground truths under 3 different tasks.
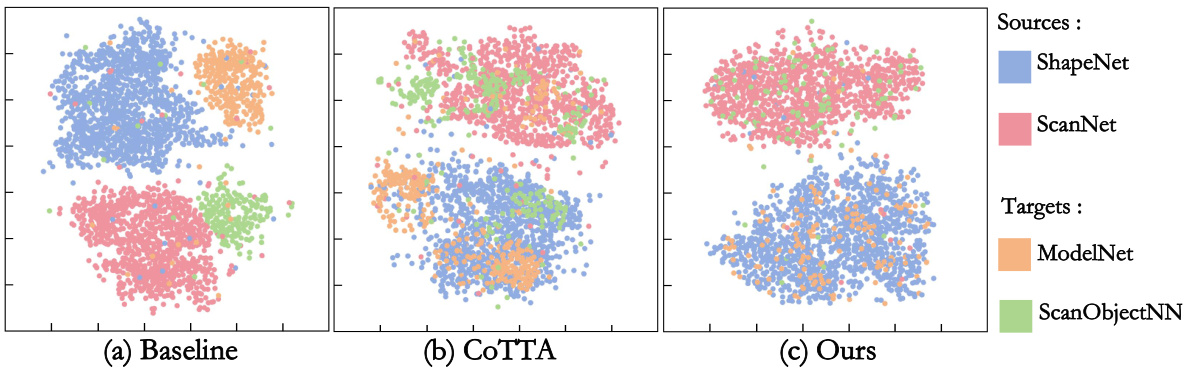
🔼 This figure visualizes the feature distributions of source and target domains using t-SNE. It compares the feature alignment of three different methods: the baseline, CoTTA, and the proposed method (Ours). The baseline shows poor alignment, while CoTTA exhibits improved alignment but still shows some mis-alignments or over-alignments. The proposed method demonstrates superior feature alignment across domains, highlighting its effectiveness in narrowing the domain shifts in continually changing environments.
read the caption
Figure 5: T-SNE visualization of the source and target features.

🔼 This figure uses t-SNE to visualize the feature distributions of the source and target domains for the point cloud reconstruction task. It compares three different methods: a baseline (no adaptation), COTTA, and the proposed PCoTTA. The visualization shows how well each method aligns the features of the source and target domains. PCoTTA demonstrates superior alignment compared to the other methods, indicating better domain adaptation and transferability.
read the caption
Figure 5: T-SNE visualization of the source and target features.

🔼 This figure visualizes the results of three different tasks (Reconstruction, Denoising, and Registration) performed by the proposed PCoTTA model. It shows the input point cloud, the model’s output (prediction), and the corresponding ground truth for each task across three different datasets (ModelNet40, ScanObjectNN). The figure demonstrates PCoTTA’s ability to handle various point cloud tasks while adapting to different data distributions. The visual comparison allows assessing the model’s accuracy and generalization capabilities in a multi-task and multi-domain scenario.
read the caption
Figure 4: Visualization of our PCoTTA's prediction and their ground truths under 3 different tasks.

🔼 This figure visualizes the results of different methods (PointNet, DGCNN, PointCutMix, CoTTA, and the proposed PCOTTA) on three tasks: reconstruction, denoising, and registration. For each task, the input point cloud and the outputs of each method are shown, alongside the ground truth. This allows a visual comparison of the performance of various methods in handling different point cloud processing tasks.
read the caption
Figure C: Visualization of our PCOTTA and state-of-the-art methods under 3 different tasks.
More on tables

🔼 This table presents the ablation study results of the proposed three modules: Automatic Prototype Mixture (APM), Gaussian Splatted Feature Shifting (GSFS), and Contrastive Prototype Repulsion (CPR). It shows the Chamfer Distance (CD) values, a measure of reconstruction error, across three different point cloud understanding tasks (Reconstruction, Denoising, and Registration) on the ModelNet40 dataset. Each row represents a model variant; Baseline is the model without any of the proposed modules, while A, B, and Ours incrementally add APM, GSFS, and CPR, respectively. Lower CD values indicate better performance.
read the caption
Table 2: Ablation studies on our proposed three modules. We report the CD (×10−3) for three different tasks on ModelNet40.
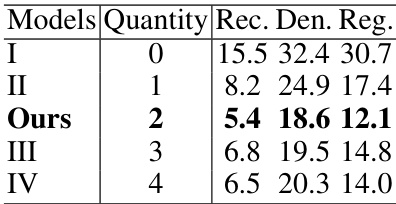
🔼 This table presents the results of ablation studies conducted to evaluate the impact of varying the number of learnable prototypes on the performance of the proposed model. The model’s performance is measured across three different tasks (Reconstruction, Denoising, and Registration) using the Chamfer Distance (CD) metric. The results show that using two learnable prototypes yields the best performance, suggesting an optimal balance between model complexity and adaptation capability.
read the caption
Table 3: Ablation studies on the quantity of learnable prototypes.

🔼 This table presents the cross-validation results of the proposed method (PCoTTA) and the baseline method (CoTTA) on different datasets. It demonstrates the model’s ability to generalize across different data types, including synthetic and real-world scan data. The Chamfer Distance (CD) is used to evaluate the performance of each task (Reconstruction, Denoising, and Registration). The results show that PCoTTA significantly outperforms CoTTA in all scenarios, indicating that PCoTTA demonstrates better transferability and robustness compared to CoTTA.
read the caption
Table 4: Cross validation with synthetic data: ShapeNet (SP), ModelNet40 (MN), and real scan data: ScanNet (SN), ScanObjectNN (SO).

🔼 This table compares the runtime, floating point operations (FLOPs), and number of parameters for different continual test-time adaptation (CoTTA) methods. The results show that the proposed PCoTTA method is significantly more efficient than existing methods, requiring less computation time and fewer parameters while achieving comparable or better performance.
read the caption
Table 5: Comparison of model efficiency. We report the Runtime (s), Flops (G), and Parameters (M) as metrics.

🔼 This table presents the ablation study results for the three modules of PCOTTA: Automatic Prototype Mixture (APM), Gaussian Splatted Feature Shifting (GSFS), and Contrastive Prototype Repulsion (CPR). It shows the Chamfer Distance (CD) scores for Reconstruction, Denoising, and Registration tasks on the ModelNet40 dataset, comparing the performance of the full model against versions with only one or two of the modules enabled. The results demonstrate the incremental contribution of each module to the overall performance and the effectiveness of combining all three.
read the caption
Table A: Ablation studies on the individual use of our three proposed modules in PCOTTA.
Full paper#