TL;DR#
Many applications, such as reinforcement learning and financial engineering, utilize overparameterized stochastic differential equation (SDE) models. However, computing gradients for these high-dimensional models poses a significant challenge due to computational complexity. Existing methods, like pathwise differentiation, suffer from computation times that scale poorly with the dimensionality of the parameter space, making optimization difficult and resource intensive. This research directly addresses this computational bottleneck.
This paper introduces a novel unbiased gradient estimator, the “generator gradient estimator.” It demonstrates significantly improved computational efficiency compared to pathwise differentiation. The key advantage is the stable computation time, which remains nearly constant even when the dimensionality of the parameter space is very high. Numerical experiments verify these findings, showcasing improved efficiency and robustness in high-dimensional scenarios, without compromising estimation variance. This work offers a significant advancement in tackling the computational challenges in optimizing complex SDE models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with high-dimensional stochastic differential equations (SDEs). It offers a novel, efficient gradient estimation method that significantly improves computational efficiency compared to existing techniques, opening up new possibilities for optimizing complex SDE models used in various fields like reinforcement learning and financial engineering. The near-constant computation time of the proposed method, even with very large model dimensions, makes it particularly relevant for modern applications with deep neural networks.
Visual Insights#
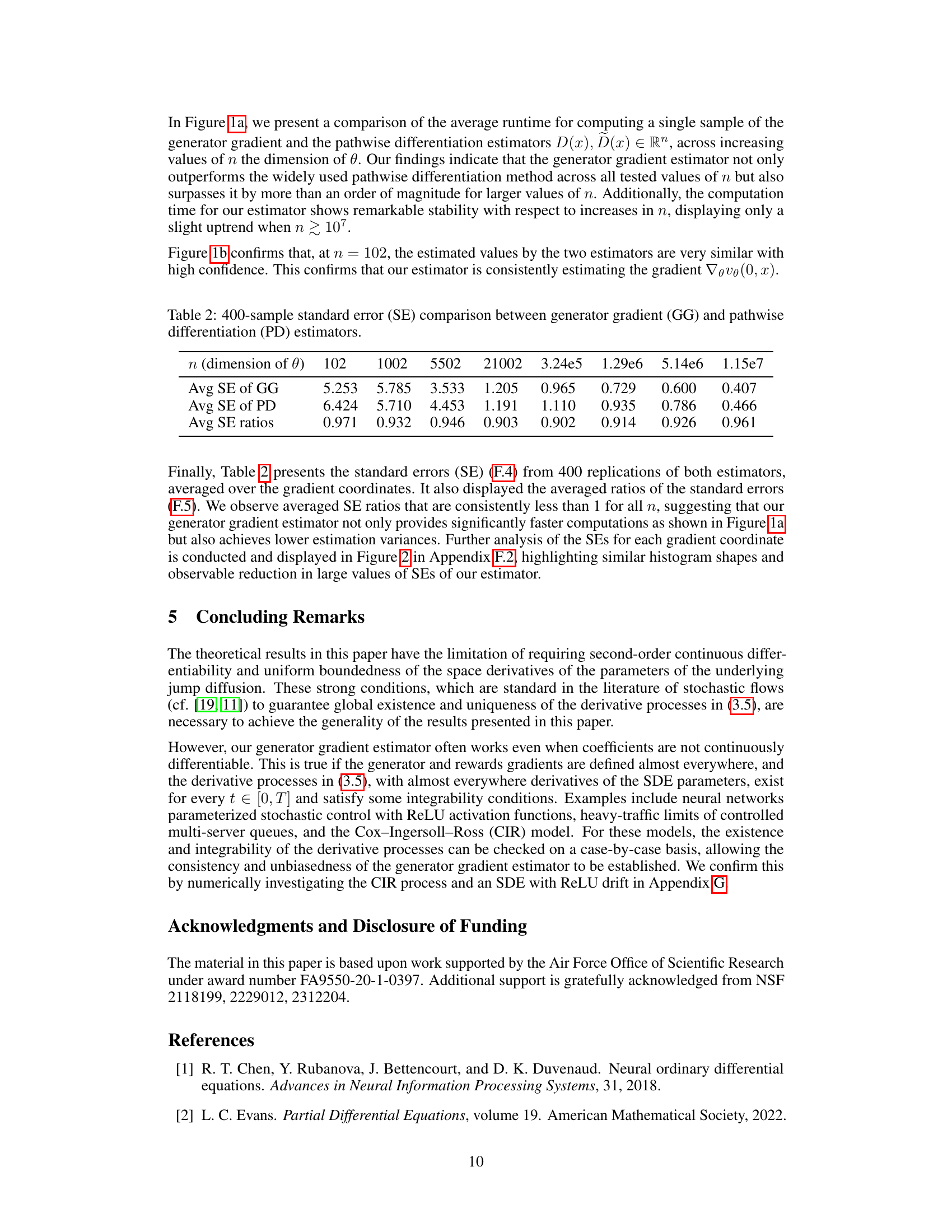
🔼 This figure consists of two subfigures. Subfigure (a) shows the average runtime for different dimensions of θ (n). The generator gradient estimator shows near-constant computation times while the pathwise differentiation method’s runtime increases significantly with n. Subfigure (b) displays the estimation statistics for n = 102, showing that both estimators achieve similar results with high confidence. The computation time of the generator gradient estimator remains stable even with high-dimensional scenarios (n approaching 10^8).
read the caption
Figure 1: Comparisons of 100-sample estimation statistics and averaged runtime.

🔼 This table compares the dimensions of stochastic differential equations (SDEs) that need to be simulated for two different gradient estimation methods: Pathwise Differentiation and Generator Gradient. It shows how the dimensionality scales with the dimension of the parameter vector (n) and the dimension of the state space (d), differentiating between cases where the volatility of the SDE depends on the parameter and when it does not. The Generator Gradient method is shown to be significantly more computationally efficient for high-dimensional parameter spaces.
read the caption
Table 1: Comparison of the dimensions of SDEs needed to be simulated.
In-depth insights#
High-Dim Gradient#
The concept of “High-Dim Gradient” in the context of stochastic differential equations (SDEs) points to a crucial challenge in modern machine learning applications involving complex systems. High dimensionality of the parameter space (e.g., neural network weights) leads to computationally expensive gradient estimation, hindering efficient optimization through gradient ascent. The paper tackles this by introducing a novel gradient estimator — the generator gradient estimator — that offers a significant computational advantage. Unlike existing methods like pathwise differentiation that suffer from complexity scaling linearly with the dimensionality, the proposed method maintains near-constant computational time. This efficiency is achieved by exploiting a clever mathematical representation of the gradient, leveraging the generator of the SDE and its properties. The estimator’s unbiasedness and finite variance are formally established, demonstrating its theoretical soundness. Empirical results showcase its superior performance against existing methods in high-dimensional scenarios, establishing the practical benefits of this new approach for optimizing complex SDE models.
Generator Estimator#
The core idea behind the “Generator Gradient Estimator” is to leverage the generator of the stochastic differential equation (SDE) to create an efficient gradient estimator. Instead of directly calculating gradients through pathwise differentiation, which can be computationally expensive for high-dimensional problems, this method utilizes the generator’s properties to derive an unbiased estimator with computational complexity relatively insensitive to the dimension of the parameter space. This is achieved by cleverly linking the gradient estimation to the solution of a PDE related to the expected cumulative reward of the SDE. The generator gradient estimator is shown to be unbiased and to exhibit near-constant computation times even as the dimensionality of the parameter space increases, significantly outperforming the pathwise differentiation method in numerical experiments. The key advantage is its efficiency in handling high-dimensional SDEs, a frequent challenge in modern applications of SDEs in machine learning and control.
Jump Diffusion SDE#
Jump diffusion stochastic differential equations (SDEs) are powerful tools for modeling systems with both continuous and discontinuous changes. The inclusion of jumps allows for capturing sudden, unexpected shifts in the system’s state, which is crucial in various applications, including finance, epidemiology, and neural networks. In contrast to pure diffusion SDEs, which only model continuous changes through Brownian motion, jump diffusion SDEs incorporate a jump process, often a Poisson process or a Lévy process, to model the discontinuous jumps. This makes them far more versatile and realistic for modeling real-world phenomena where abrupt events significantly impact the system’s trajectory. Parameter estimation and efficient gradient computation for jump diffusion SDEs are challenging due to the complexity introduced by the jumps and the often high-dimensional parameter space. Advanced techniques like the generator gradient estimator are essential for addressing these computational hurdles and making the models practically applicable for learning and optimization. The theoretical underpinnings of these estimators, often involving stochastic flows and infinitesimal perturbation analysis, are central to ensuring their validity and accuracy.
Empirical Efficiency#
An empirical efficiency analysis of a new gradient estimator for stochastic differential equations (SDEs) would involve comparing its performance against existing methods, such as pathwise differentiation, across various dimensions of the problem. Key metrics would include computational time, measured in terms of runtime or FLOPs, and estimation variance, often quantified by the standard error. The analysis should cover a range of problem sizes, parameterized by the dimensionality of the neural network or the number of SDE parameters, to demonstrate scalability. A crucial aspect is showing that the proposed estimator’s computational cost remains relatively stable as the dimensionality of the problem grows, unlike pathwise differentiation. The comparison should also consider the trade-off between computational cost and estimation accuracy. Ideally, the new method should demonstrate improved efficiency without significantly increasing variance. Visualizations, such as plots showing runtime and variance against problem size, would greatly enhance the clarity and impact of the analysis. Ultimately, a successful analysis would clearly show the new estimator’s superior empirical efficiency for high-dimensional SDE problems in a range of scenarios.
Future Directions#
Future research could explore extensions to more complex SDE models, such as those with time-varying coefficients or non-Markovian structures. Investigating the impact of different numerical methods on the efficiency and accuracy of the generator gradient estimator is also crucial. The application to a wider range of problems in areas like reinforcement learning, PDE-constrained optimization, and financial modeling should be further investigated, potentially by developing specialized versions of the estimator for specific problem structures. Theoretical analysis could focus on refining the assumptions, improving the variance bounds, and extending the framework to handle high-dimensional jump diffusions more effectively. Finally, comparing the proposed method against alternative techniques, like likelihood ratio methods, in a variety of settings would provide a comprehensive understanding of its strengths and weaknesses. Scalability and robustness testing across different hardware architectures and dataset sizes is important for practical applications.
More visual insights#
More on tables

🔼 This table compares the dimensions of stochastic differential equations (SDEs) that need to be simulated for two different gradient estimators: pathwise differentiation and the generator gradient. It shows how the dimensionality of the SDEs scales with the dimension of the parameter vector (n) and the dimension of the state space (d) for both estimators, in cases where the volatility depends on the parameter or not. The generator gradient estimator is significantly more efficient as its computation time is insensitive to the dimension of the parameter space (n).
read the caption
Table 1: Comparison of the dimensions of SDEs needed to be simulated.
🔼 This table compares the dimensions of stochastic differential equations (SDEs) that need to be simulated for two different gradient estimators: pathwise differentiation and the generator gradient estimator. It shows how the dimensionality of the SDEs scales with the dimension of the parameter vector (n) and the dimension of the state vector (d), depending on whether or not the volatility of the SDE depends on the parameter. The generator gradient estimator is shown to have a significantly lower computational cost as it requires simulating fewer SDEs, especially when n is large.
read the caption
Table 1: Comparison of the dimensions of SDEs needed to be simulated.

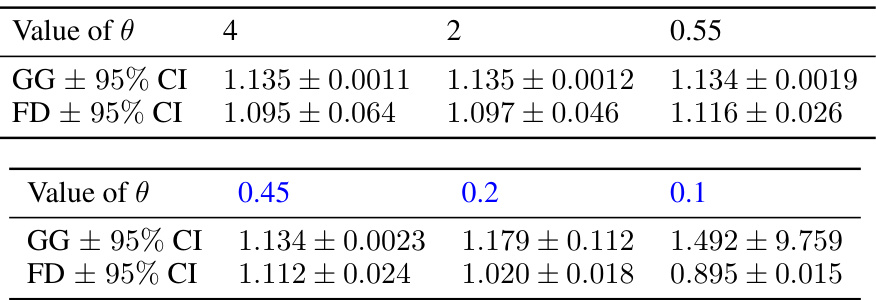
🔼 This table presents the estimated values and 95% confidence intervals for both the generator gradient (GG) and finite difference (FD) estimators for different values of theta in the SDE with ReLU drift experiment. The FD estimator has a bias of O(h²), and the results are used to compare the GG estimator’s performance to a standard benchmark.
read the caption
Table 4: Statistics for 106-sample averaged GG and FD estimators. For the FD estimator, we choose h = 0.05 in (G.3), resulting in a bias of O(h²).
Full paper#