TL;DR#
Zero-shot reinforcement learning (RL) aims to train agents on reward-free data to perform any downstream task. Existing methods require large, diverse datasets, which are often unavailable in practice. This limits the applicability of zero-shot RL to real-world problems where data is scarce and may not be heterogeneous. The paper identifies that the main issue lies in the overestimation of out-of-distribution state-action values. This leads to poor generalization to unseen tasks during the test phase.
This research proposes novel conservative zero-shot RL algorithms to address these shortcomings. The key idea is to incorporate conservatism, a technique commonly used in single-task offline RL, into zero-shot RL. The researchers introduce value-conservative and measure-conservative variations of the forward-backward algorithm, along with a mechanism for dynamically tuning the conservatism hyperparameter. Experiments show that these conservative algorithms outperform their non-conservative counterparts and even surpass baselines that have access to task information during training, particularly on low-quality datasets.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in reinforcement learning (RL) as it addresses the critical challenge of applying zero-shot RL to real-world scenarios. It directly tackles the problem of limited and low-quality data, a common constraint in practical RL applications. The proposed conservative methods improve zero-shot RL performance, paving the way for more robust and practical algorithms. Its findings inspire new research directions into efficient data usage and conservatism in offline RL.
Visual Insights#
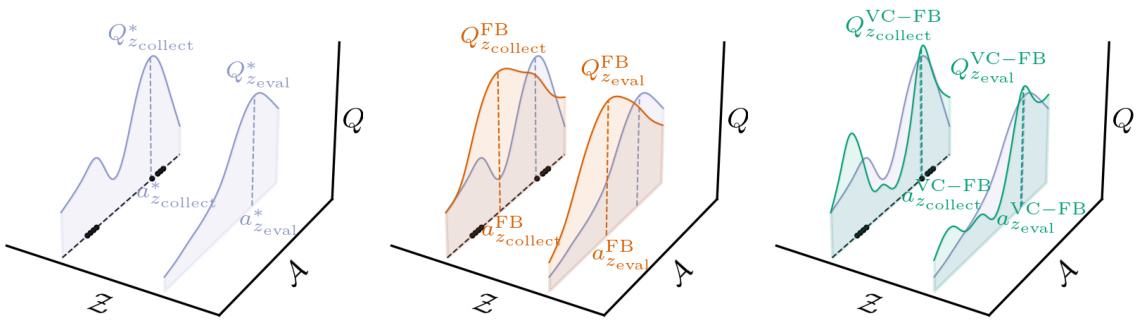
🔼 This figure illustrates the core concept of the paper. The left panel shows the standard zero-shot RL problem where a model trained on data from one task (zcollect) needs to generalize to a new task (zeval). The middle panel illustrates the overestimation problem of existing methods, such as FB, which overestimate the value of out-of-distribution (OOD) actions. The right panel introduces the solution of the paper, VC-FB, which mitigates this problem by suppressing the values of OOD actions.
read the caption
Figure 1: Conservative zero-shot RL. (Left) Zero-shot RL methods must train on a dataset collected by a behaviour policy optimising against task zcollect, yet generalise to new tasks zeval. Both tasks have associated optimal value functions Qcollect and Q*eval for a given marginal state. (Middle) Existing methods, in this case forward-backward representations (FB), overestimate the value of actions not in the dataset for all tasks. (Right) Value-conservative forward-backward representations (VC-FB) suppress the value of actions not in the dataset for all tasks. Black dots () represent state-action samples present in the dataset.
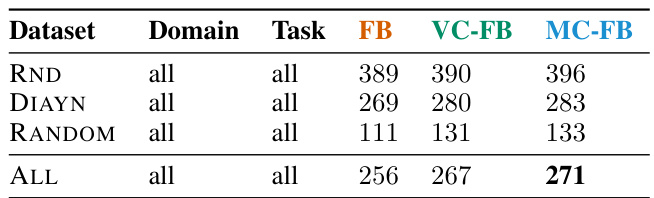
🔼 This table presents the average IQM (interquartile mean) scores across all domains and tasks in the ExORL benchmark for three different datasets (RND, DIAYN, and RANDOM) using three zero-shot reinforcement learning methods: FB (Forward-Backward), VC-FB (Value-Conservative Forward-Backward), and MC-FB (Measure-Conservative Forward-Backward). The results show the performance of VC-FB and MC-FB compared to the baseline FB method. The table also includes aggregate results across all datasets. The results indicate that VC-FB and MC-FB generally maintain or slightly improve upon FB’s performance, with the largest relative improvement seen on the RANDOM dataset.
read the caption
Table 1: Aggregate performance on full ExORL datasets. IQM scores aggregated over domains and tasks for all datasets, averaged across three seeds. Both VC-FB and MC-FB maintain the performance of FB; the largest relative performance improvement is on RANDOM.
In-depth insights#
Zero-Shot RL Limits#
Zero-shot reinforcement learning (RL) aims to train agents on reward-free data to perform various downstream tasks without further training. However, zero-shot RL’s success heavily relies on the diversity and size of the pre-training data. If the training data is limited, homogeneous, or collected by non-exploratory agents, the performance degrades significantly. This limitation stems from the tendency of zero-shot RL algorithms to overestimate the value of out-of-distribution (OOD) state-action pairs, leading to poor generalization. Addressing this requires methods that encourage conservatism, which involves penalizing or suppressing the predicted value of OOD actions. Conservative zero-shot RL algorithms have shown promise in mitigating this issue, achieving better performance on low-quality data while maintaining competitiveness on high-quality datasets. Future research needs to explore more robust methods for handling data scarcity and heterogeneity, making zero-shot RL more practical for real-world applications.
Conservative RL Fix#
The concept of a “Conservative RL Fix” addresses a critical weakness in standard reinforcement learning (RL) algorithms: overestimation of out-of-distribution (OOD) values. Standard RL agents, when trained on limited datasets, often predict unrealistically high rewards for unseen states or actions. This leads to poor generalization and unreliable performance on novel tasks. A conservative fix mitigates this by explicitly penalizing or downweighting the predicted values for OOD states and actions. This approach ensures that the agent does not overestimate its capabilities in unfamiliar situations. The effectiveness of this fix relies on carefully defining what constitutes an OOD state or action, which often involves techniques like density-based methods or using a pre-trained model to estimate the probability of encountering a given state or action. Conservative methods demonstrate improved robustness and generalization compared to standard approaches, particularly when dealing with limited or low-quality training data. The benefits might come at the cost of slightly reduced performance on well-explored states and actions, but that reduction is often a small price to pay for the substantially better reliability and safety.
Low-Quality Data#
The concept of ’low-quality data’ in the context of zero-shot reinforcement learning is crucial. It challenges the assumption of large, heterogeneous datasets typically used for pre-training. The paper investigates how zero-shot RL methods, which usually leverage successor representations, perform when trained on smaller, homogeneous datasets (low-quality data). This is a significant contribution because real-world scenarios often lack such ideal pre-training datasets. The degradation in performance observed when using low-quality data is thoroughly analyzed; it stems from overestimation of out-of-distribution state-action values. The core of the paper introduces fixes inspired by the concept of conservatism from single-task offline RL. This is achieved by introducing straightforward regularizers, resulting in algorithms that are demonstrably more robust to low-quality data without sacrificing performance on high-quality datasets. These conservative zero-shot RL methods outperform their non-conservative counterparts across varied datasets, domains, and tasks. The findings highlight the importance of addressing data limitations in zero-shot RL, paving the way for real-world applicability and pushing the boundaries of generalization in sequential decision-making.
Empirical Evaluation#
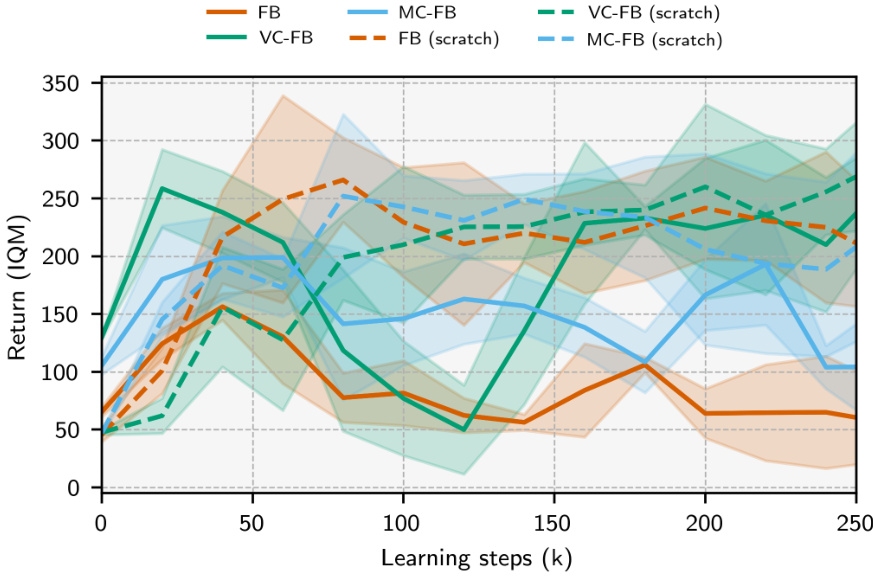
A robust empirical evaluation section should thoroughly investigate the proposed methods. It should compare against strong baselines, ideally including state-of-the-art techniques and simpler alternatives. Quantitative metrics should be clearly defined and consistently applied across all experiments. The choice of datasets is crucial; a diverse set, encompassing variations in size, complexity and data quality, will provide stronger evidence of generalizability. Careful attention to experimental setup is also needed, to ensure reproducibility and minimize confounding variables. Statistical significance of any observed differences should be demonstrated, using appropriate statistical tests. Finally, a thorough analysis of the results, beyond simply reporting numbers, is essential. This should involve exploring trends, relationships between variables, and potential reasons for observed successes and failures. Clear visualizations of the results enhance understanding and aid in identifying patterns.
Future Directions#
Future research could explore several promising avenues. Extending the conservative methods to other zero-shot RL frameworks, such as those using successor features, is crucial. This would broaden the applicability and impact of these techniques. Investigating the optimal balance between conservatism and exploration in zero-shot settings is important to avoid over-conservatism that hinders performance and under-conservatism leading to poor generalization. Developing better metrics for evaluating dataset quality in the context of zero-shot RL is vital for guiding data collection strategies and algorithm design. More sophisticated methods for handling the distribution shift between training and test data will likely improve robustness. Combining zero-shot learning with other RL paradigms, such as reinforcement learning from human feedback or model-based RL, could produce even more effective and adaptable agents. Finally, exploring real-world applications of zero-shot RL using these advanced techniques will be crucial for demonstrating practical impact and identifying further areas for improvement.
More visual insights#
More on figures
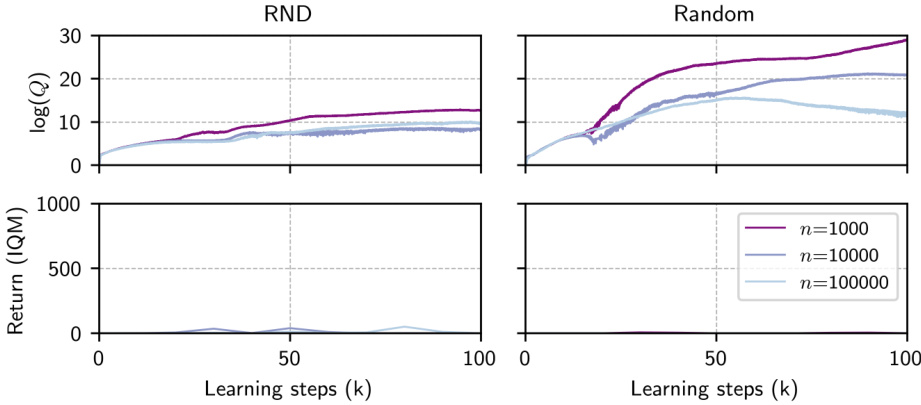
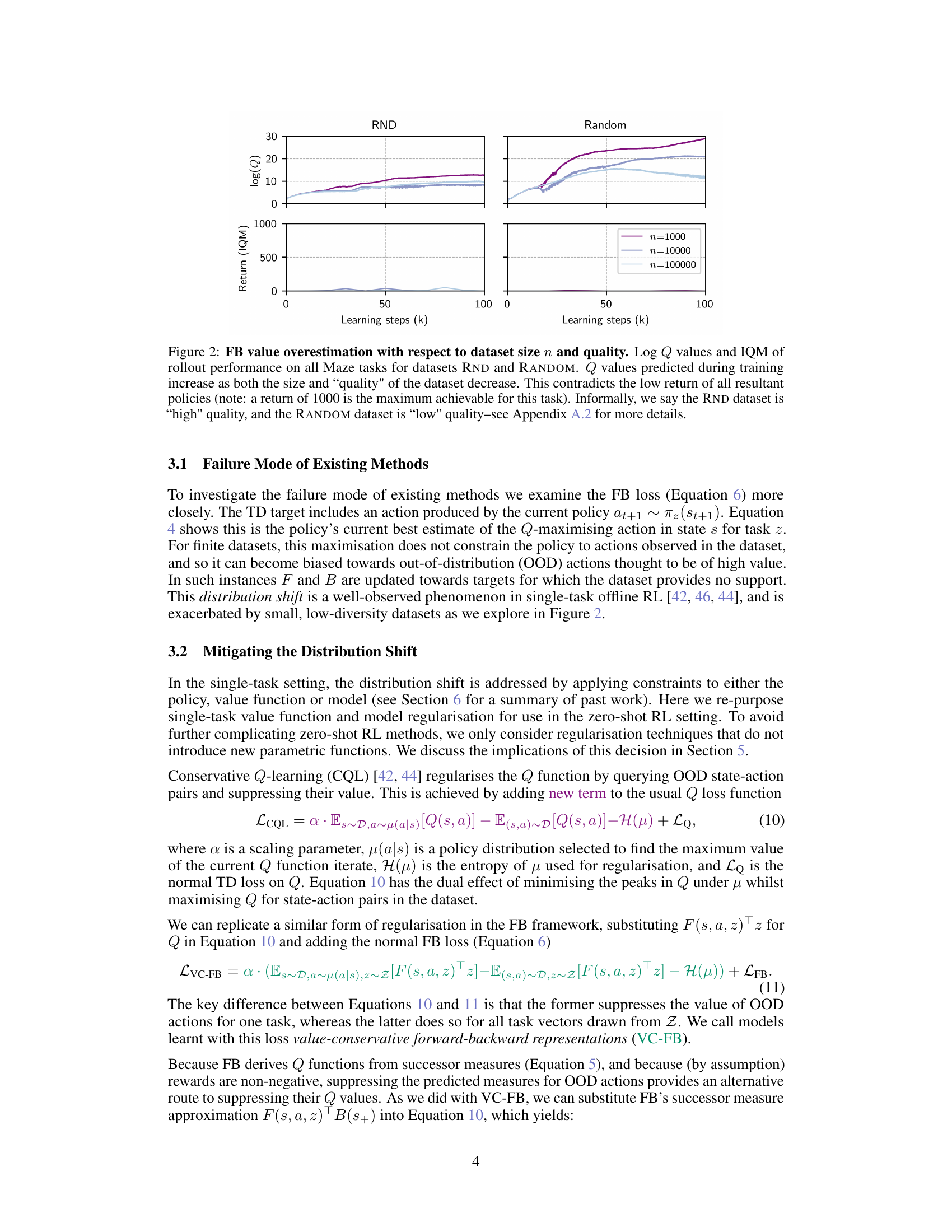
🔼 This figure shows how the performance of the Forward-Backward (FB) algorithm degrades when trained on small, low-quality datasets. The top panels show that the predicted Q-values during training increase as both the dataset size and quality decrease. This is unexpected, as it contradicts the low returns observed in the resultant policies. The bottom panels confirm this by visualizing the actual rollout returns obtained on various tasks across different dataset sizes. The plot clearly shows that FB’s performance drops significantly when trained on smaller and lower-quality datasets.
read the caption
Figure 2: FB value overestimation with respect to dataset size n and quality. Log Q values and IQM of rollout performance on all Maze tasks for datasets RND and RANDOM. Q values predicted during training increase as both the size and 'quality' of the dataset decrease. This contradicts the low return of all resultant policies (note: a return of 1000 is the maximum achievable for this task). Informally, we say the RND dataset is 'high' quality, and the RANDOM dataset is 'low' quality-see Appendix A.2 for more details.
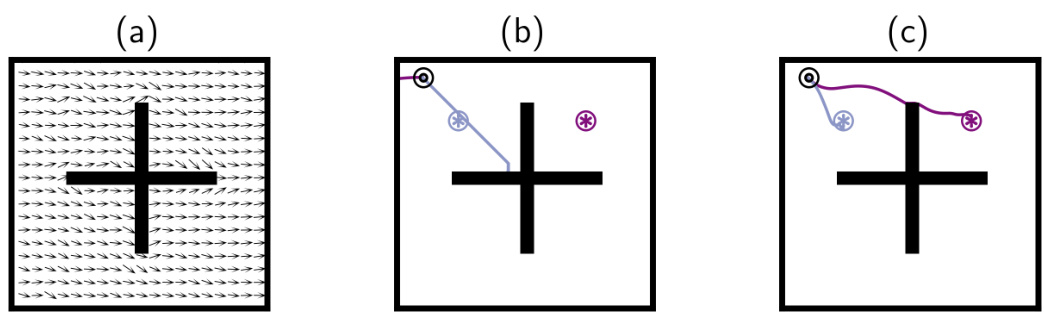
🔼 This figure shows how a conservative zero-shot RL method (VC-FB) outperforms a non-conservative method (FB) when trained on a dataset with missing actions. Panel (a) shows the dataset used for training, highlighting the removal of all left actions. Panel (b) shows the trajectory resulting from FB, demonstrating its failure to reach the goal because of overestimation of the value of out-of-distribution (OOD) actions. Panel (c) shows the trajectory from VC-FB, highlighting its success in reaching the goal due to its ability to synthesize information from the dataset and avoid overestimating OOD action values.
read the caption
Figure 3: Ignoring out-of-distribution actions. The agents are tasked with learning separate policies for reaching and . (a) RND dataset with all 'left' actions removed; quivers represent the mean action direction in each state bin. (b) Best FB rollout after 1 million learning steps. (c) Best VC-FB performance after 1 million learning steps. FB overestimates the value of OOD actions and cannot complete either task; VC-FB synthesises the requisite information from the dataset and completes both tasks.
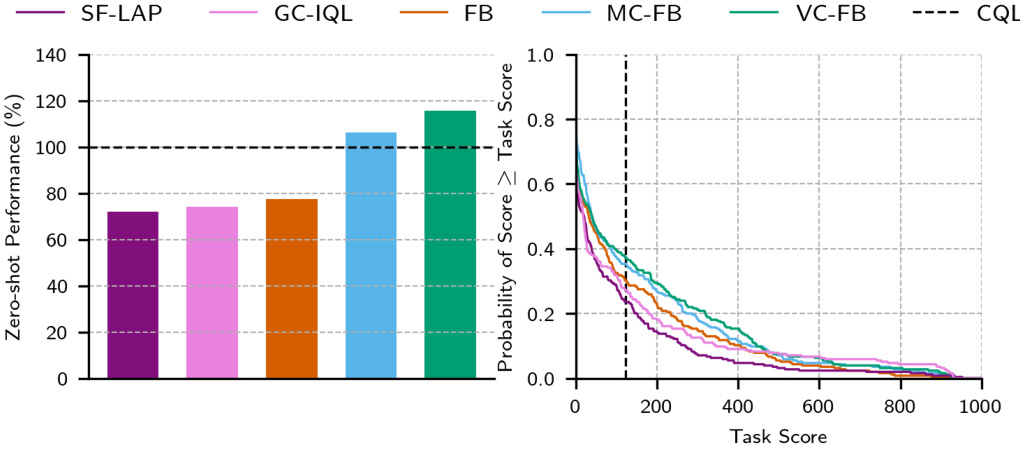
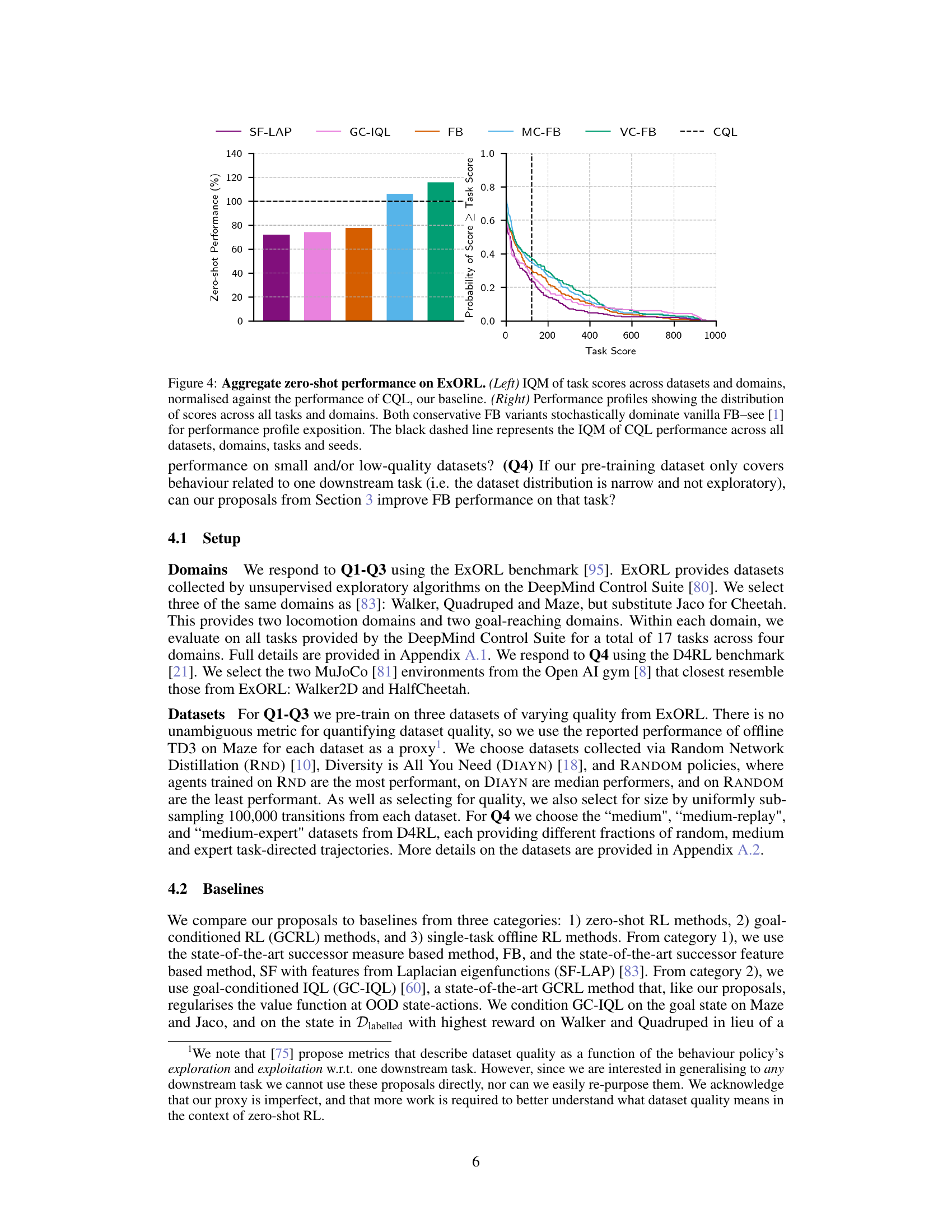
🔼 The left panel shows the IQM (interquartile mean) of zero-shot performance across different datasets and domains. The performance is normalized against that of CQL (Conservative Q-Learning), a strong baseline single-task offline RL algorithm. The right panel shows performance profiles, illustrating the cumulative distribution function of the task scores obtained by the various methods. The figure demonstrates the improved performance of the proposed conservative zero-shot RL methods (MC-FB and VC-FB) compared to the baseline methods and vanilla FB (Forward-Backward) on the ExORL benchmark.
read the caption
Figure 4: Aggregate zero-shot performance on ExORL. (Left) IQM of task scores across datasets and domains, normalised against the performance of CQL, our baseline. (Right) Performance profiles showing the distribution of scores across all tasks and domains. Both conservative FB variants stochastically dominate vanilla FB-see [1] for performance profile exposition. The black dashed line represents the IQM of CQL performance across all datasets, domains, tasks and seeds.
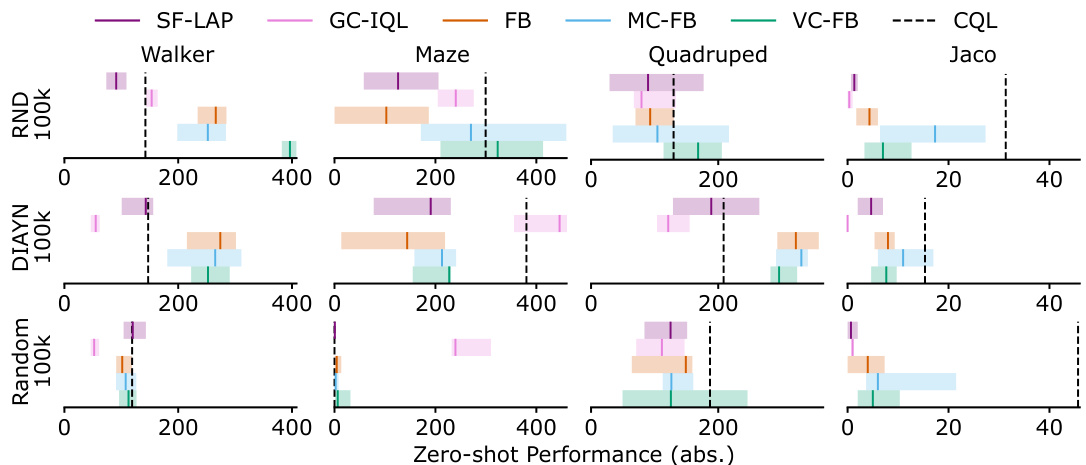
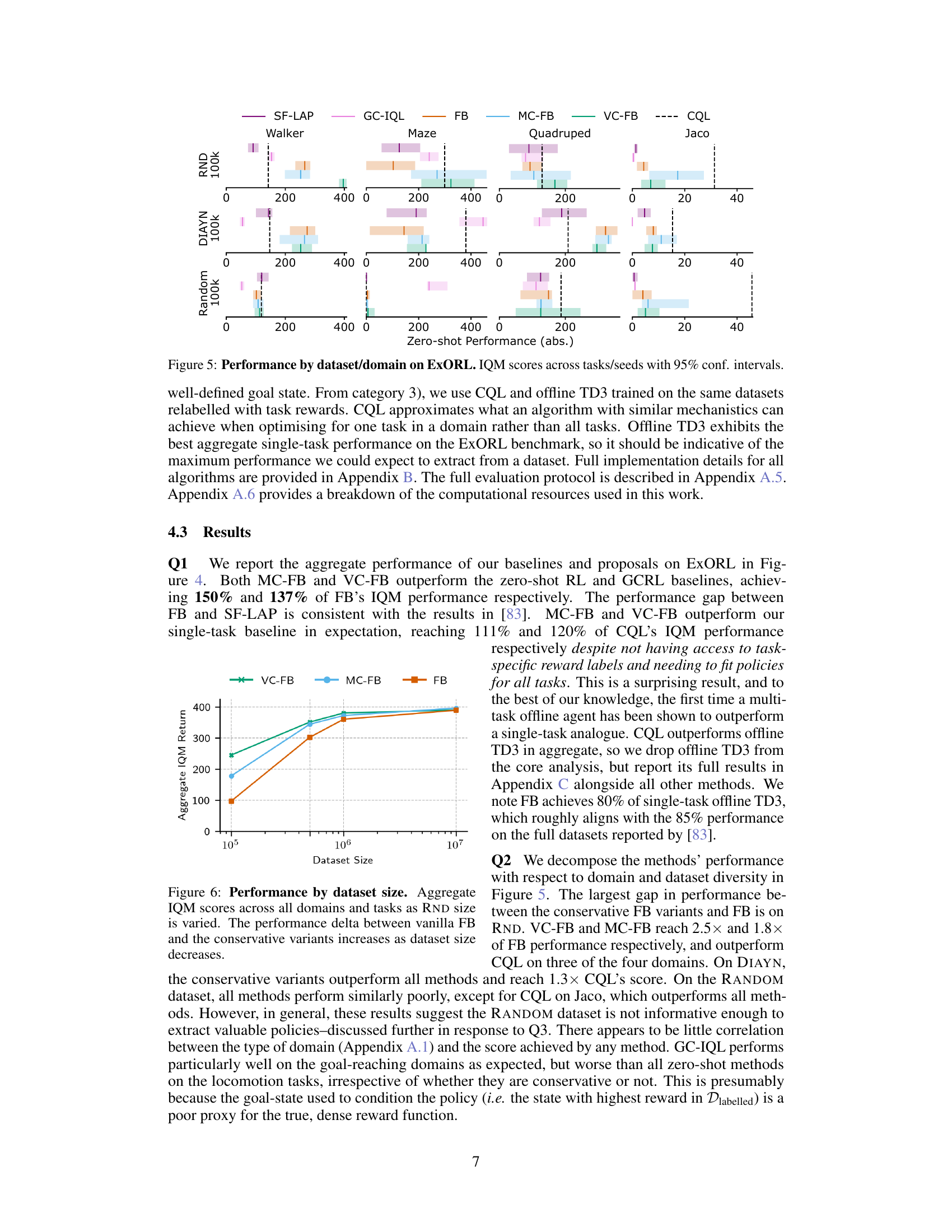
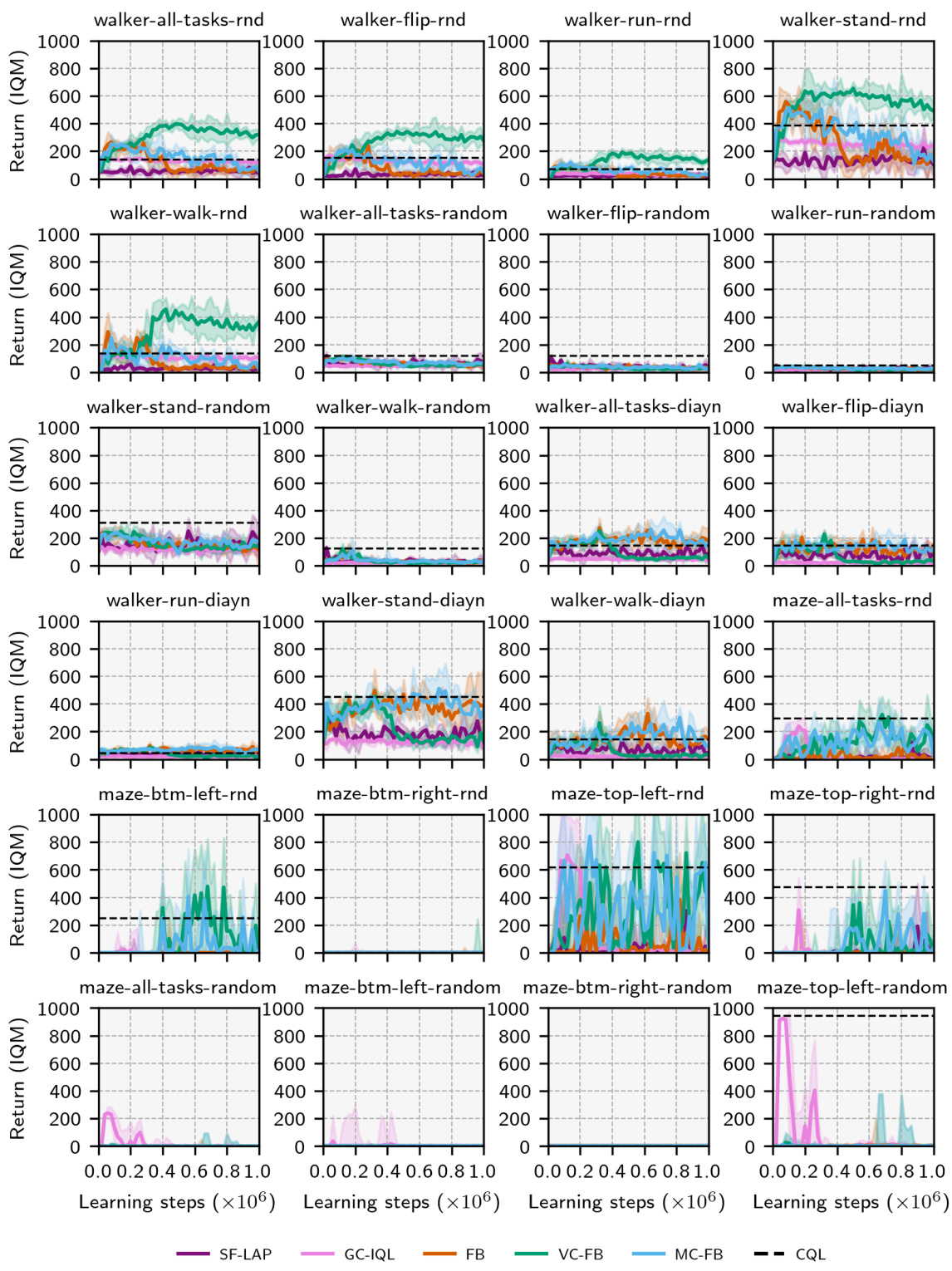
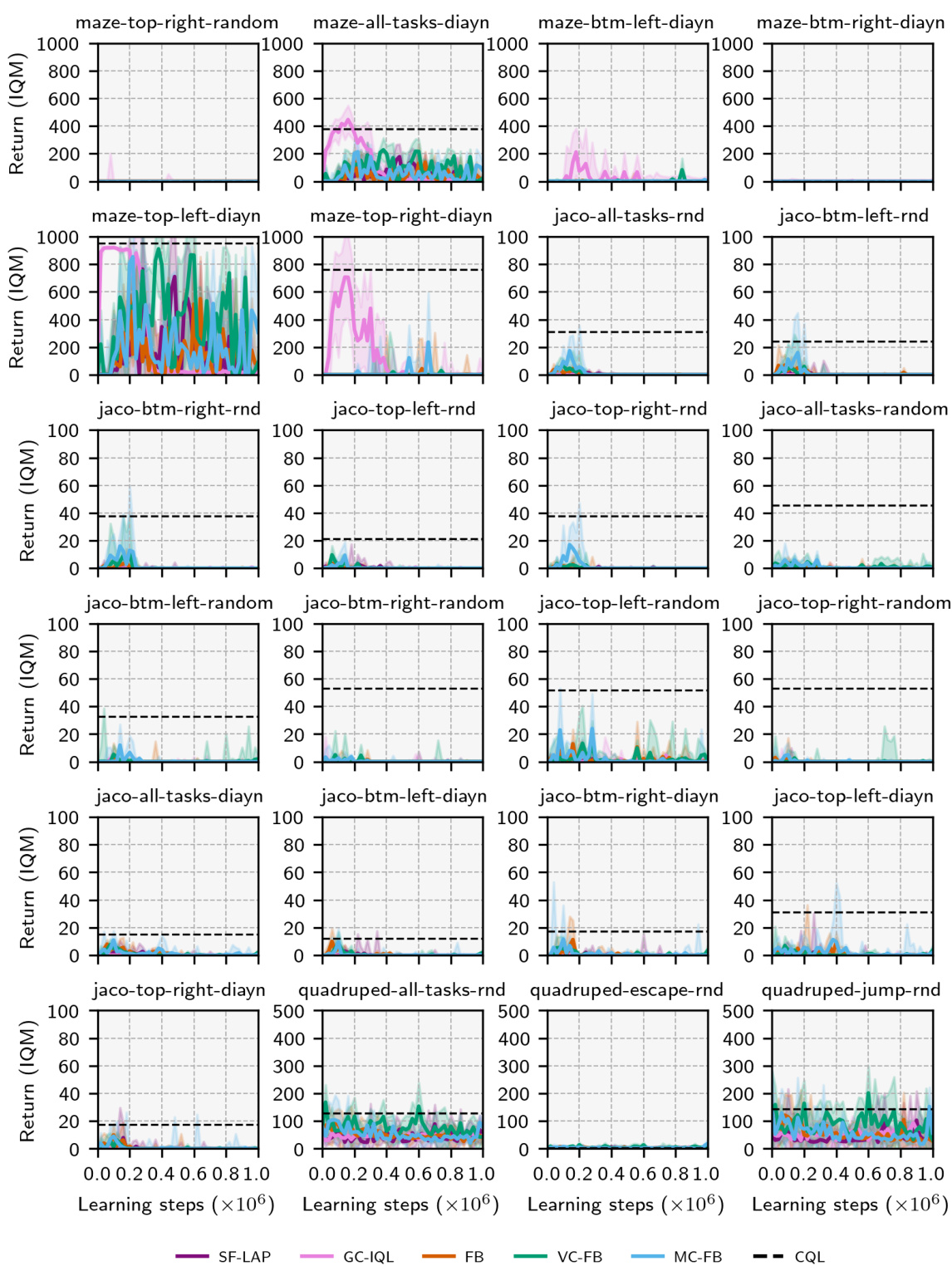
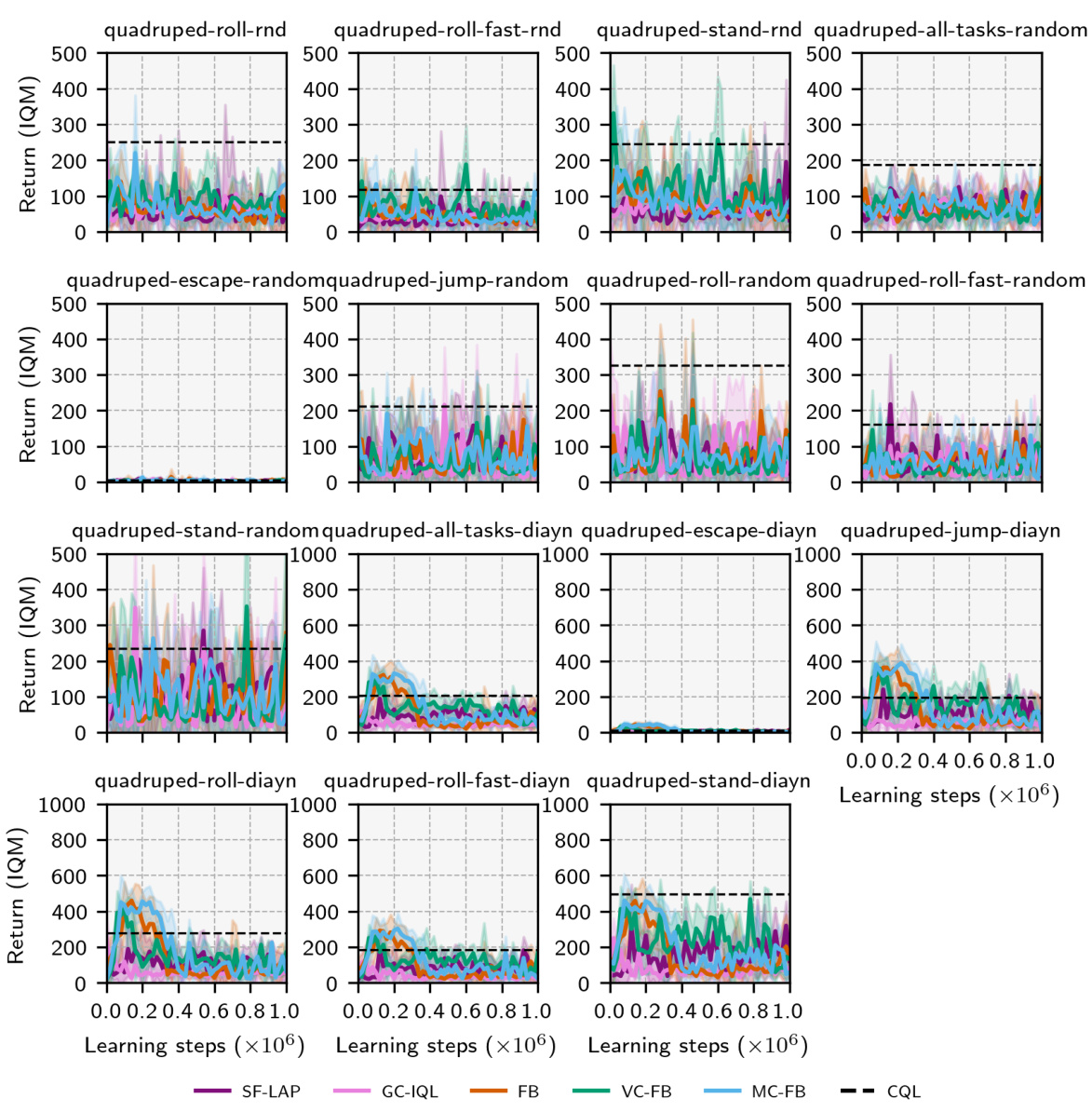
🔼 The figure shows the performance of different zero-shot RL methods (SF-LAP, GC-IQL, FB, MC-FB, VC-FB, and CQL) across various datasets (RND, DIAYN, RANDOM) and domains (Walker, Maze, Quadruped, Jaco) in the ExORL benchmark. The y-axis represents the Interquartile Mean (IQM) of zero-shot performance, while the x-axis is not explicitly labeled but represents the range of scores for each method and domain/dataset combination. Error bars show the 95% confidence intervals. The results highlight the varying performance of each method across different datasets and domains, demonstrating the impact of data quality and diversity on zero-shot RL performance.
read the caption
Figure 5: Performance by dataset/domain on ExORL. IQM scores across tasks/seeds with 95% conf. intervals.
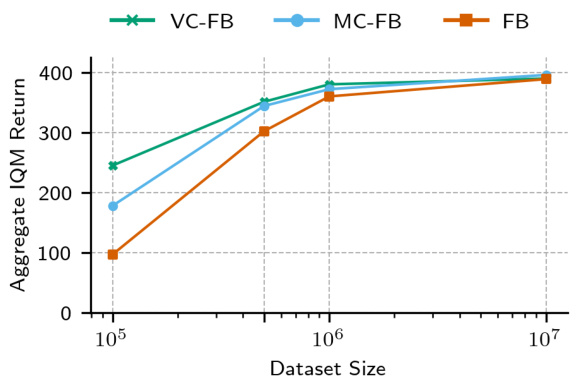
🔼 The figure shows how the performance of three different zero-shot RL algorithms (FB, VC-FB, and MC-FB) changes with the size of the training dataset. The training dataset is the RND dataset, and its size is varied from 100k to 10M. The y-axis represents the aggregate IQM score across all tasks and domains. The figure shows that the performance gap between vanilla FB and the conservative variants (VC-FB and MC-FB) increases as the dataset size decreases. This suggests that the conservative variants are more robust to the distribution shift that occurs when the training dataset is small. The figure supports the claim that conservative zero-shot RL algorithms are superior on low-quality datasets.
read the caption
Figure 6: Performance by dataset size. Aggregate IQM scores across all domains and tasks as RND size is varied. The performance delta between vanilla FB and the conservative variants increases as dataset size decreases.
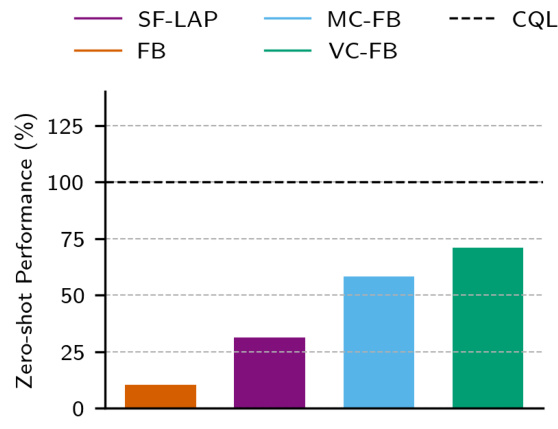
🔼 This figure presents a comparison of zero-shot performance across different reinforcement learning methods on the ExORL benchmark. The left panel shows the interquartile mean (IQM) of task scores for various methods, normalized against the performance of Conservative Q-learning (CQL), highlighting the improvement achieved by conservative forward-backward (FB) methods. The right panel shows performance profiles, illustrating the cumulative distribution function of task scores, visually demonstrating the stochastic dominance of conservative FB methods over the standard FB method.
read the caption
Figure 4: Aggregate zero-shot performance on ExORL. (Left) IQM of task scores across datasets and domains, normalised against the performance of CQL, our baseline. (Right) Performance profiles showing the distribution of scores across all tasks and domains. Both conservative FB variants stochastically dominate vanilla FB-see [1] for performance profile exposition. The black dashed line represents the IQM of CQL performance across all datasets, domains, tasks and seeds.

🔼 This figure shows the state coverage of three different datasets used in the paper: RANDOM, DIAYN, and RND. Each dataset was collected using a different unsupervised exploration method. The figure visualizes the state coverage in a 2D maze environment. The color intensity represents the density of state visits, darker colors indicating more frequent visits. The image demonstrates that the RND dataset (right) provides significantly better coverage than the other datasets, while the RANDOM dataset (left) shows very limited coverage. This highlights a key point of the paper about the differing quality of data used to train the reinforcement learning model.
read the caption
Figure 8: Maze state coverage by dataset. (left) RANDOM; (middle) DIAYN; (right) RND.
🔼 This figure shows how the performance of different zero-shot reinforcement learning (RL) methods, specifically Forward-Backward (FB) and its conservative variants, changes with respect to dataset size. The x-axis represents the dataset size (number of transitions), while the y-axis indicates the aggregate IQM (Interquartile Mean) return across multiple domains and tasks. It demonstrates that the performance gap between the vanilla FB method and its conservative counterparts increases as the dataset size decreases, highlighting the effectiveness of conservative approaches when dealing with smaller datasets.
read the caption
Figure 6: Performance by dataset size. Aggregate IQM scores across all domains and tasks as RND size is varied. The performance delta between vanilla FB and the conservative variants increases as dataset size decreases.
🔼 This figure illustrates the core idea of the paper. Zero-shot reinforcement learning aims to train an agent on a dataset of reward-free transitions, so it can perform any downstream task without further training. The left panel shows the training and testing setting. The middle panel shows how existing methods overestimate the value of out-of-distribution actions that were not seen in the dataset. The right panel presents the paper’s proposed solution: to suppress the overestimation of unseen actions, which improves the agent’s performance on downstream tasks when trained on low-quality data.
read the caption
Figure 1: Conservative zero-shot RL. (Left) Zero-shot RL methods must train on a dataset collected by a behaviour policy optimising against task zcollect, yet generalise to new tasks zeval. Both tasks have associated optimal value functions Qcollect and Q*eval for a given marginal state. (Middle) Existing methods, in this case forward-backward representations (FB), overestimate the value of actions not in the dataset for all tasks. (Right) Value-conservative forward-backward representations (VC-FB) suppress the value of actions not in the dataset for all tasks. Black dots () represent state-action samples present in the dataset.
🔼 This figure shows how the performance of the Forward-Backward (FB) algorithm in zero-shot reinforcement learning is affected by the size and quality of the training dataset. It demonstrates that as the dataset size decreases and quality reduces (fewer and less diverse state-action pairs), the predicted Q-values during training become overly optimistic, even though the resulting policies yield poor returns. This highlights a significant challenge in zero-shot RL when dealing with limited data.
read the caption
Figure 2: FB value overestimation with respect to dataset size n and quality. Log Q values and IQM of rollout performance on all Maze tasks for datasets RND and RANDOM. Q values predicted during training increase as both the size and 'quality' of the dataset decrease. This contradicts the low return of all resultant policies (note: a return of 1000 is the maximum achievable for this task). Informally, we say the RND dataset is 'high' quality, and the RANDOM dataset is 'low' quality-see Appendix A.2 for more details.
🔼 This figure illustrates the core concept of the paper. Zero-shot reinforcement learning aims to train an agent on a dataset of reward-free transitions to perform any downstream task without further learning. Panel (a) shows the general problem: training on zcollect data to predict Q*eval values for unseen tasks. Panel (b) illustrates existing methods (Forward-Backward representations) that tend to overestimate the value of unseen actions, while (c) demonstrates the proposed conservative approach (Value-Conservative Forward-Backward representations) which suppresses the estimated value of unseen actions. This correction improves performance, particularly on low-quality data.
read the caption
Figure 1: Conservative zero-shot RL. (Left) Zero-shot RL methods must train on a dataset collected by a behaviour policy optimising against task zcollect, yet generalise to new tasks zeval. Both tasks have associated optimal value functions Qcollect and Q*eval for a given marginal state. (Middle) Existing methods, in this case forward-backward representations (FB), overestimate the value of actions not in the dataset for all tasks. (Right) Value-conservative forward-backward representations (VC-FB) suppress the value of actions not in the dataset for all tasks. Black dots () represent state-action samples present in the dataset.
🔼 This figure shows how the performance of Forward-Backward (FB) zero-shot reinforcement learning degrades with smaller and lower-quality datasets. It plots the predicted Q-values during training and the actual rollout performance on Maze tasks using two datasets: RND (high-quality) and RANDOM (low-quality). The key takeaway is that FB overestimates the value of actions not seen during training, leading to poor performance, especially with smaller, lower-quality datasets.
read the caption
Figure 2: FB value overestimation with respect to dataset size n and quality. Log Q values and IQM of rollout performance on all Maze tasks for datasets RND and RANDOM. Q values predicted during training increase as both the size and 'quality' of the dataset decrease. This contradicts the low return of all resultant policies (note: a return of 1000 is the maximum achievable for this task). Informally, we say the RND dataset is 'high' quality, and the RANDOM dataset is 'low' quality-see Appendix A.2 for more details.
🔼 This figure shows how the performance of the Forward-Backward (FB) algorithm in zero-shot reinforcement learning is affected by the size and quality of the training dataset. It demonstrates that as the dataset size decreases and quality diminishes (fewer and less diverse state-action pairs), the predicted Q-values during training become overestimated. This overestimation is paradoxical because the resulting policies achieve far lower actual returns than expected, highlighting a critical failure mode of FB methods when trained on low-quality data.
read the caption
Figure 2: FB value overestimation with respect to dataset size n and quality. Log Q values and IQM of rollout performance on all Maze tasks for datasets RND and RANDOM. Q values predicted during training increase as both the size and 'quality' of the dataset decrease. This contradicts the low return of all resultant policies (note: a return of 1000 is the maximum achievable for this task). Informally, we say the RND dataset is 'high' quality, and the RANDOM dataset is 'low' quality-see Appendix A.2 for more details.
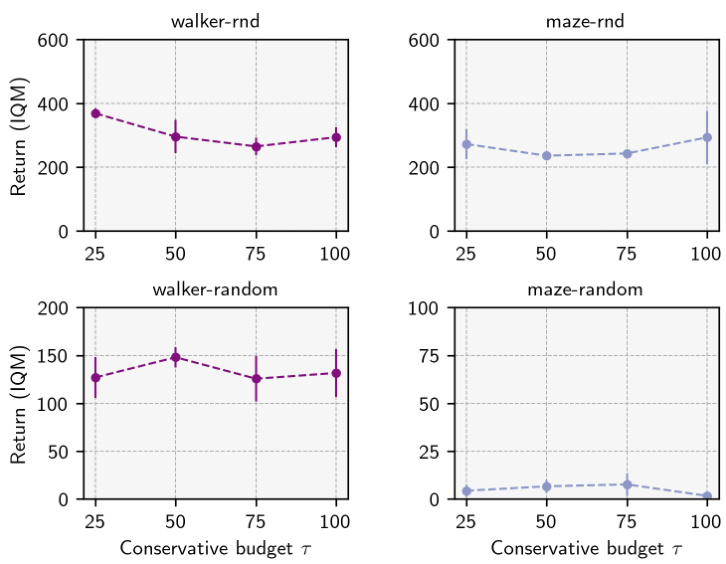
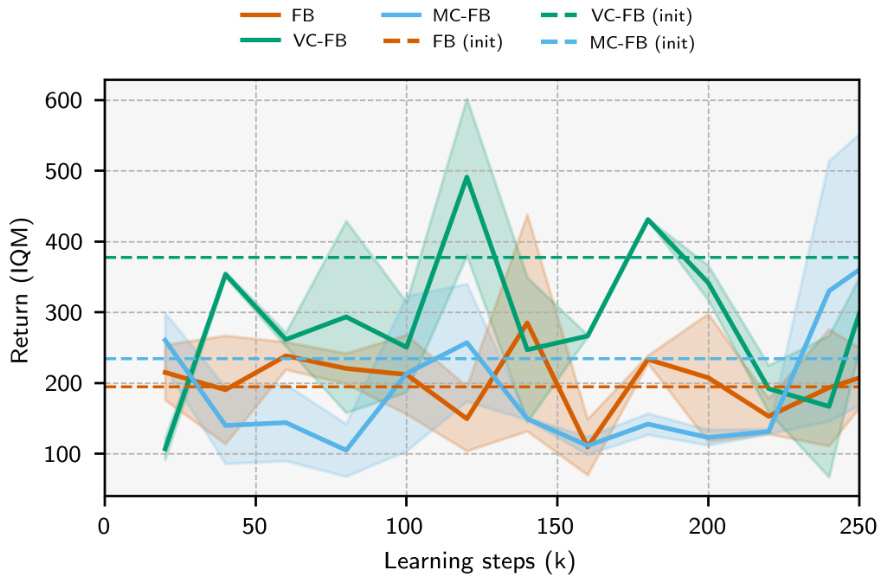
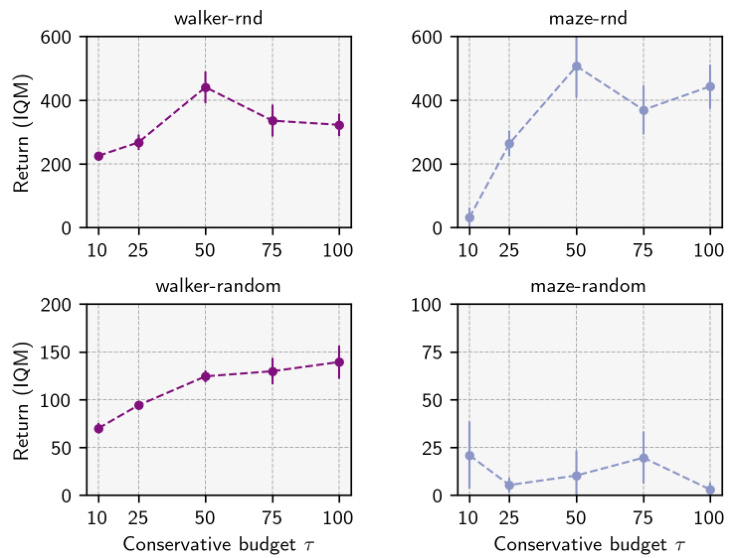
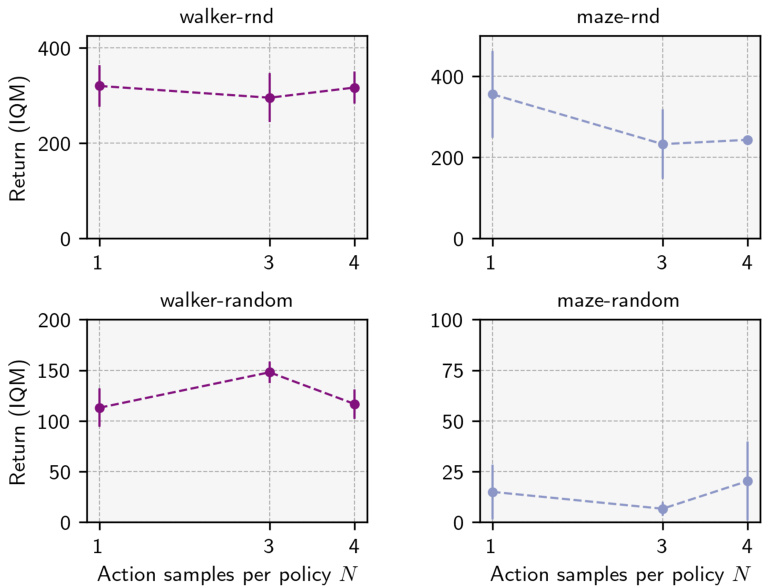
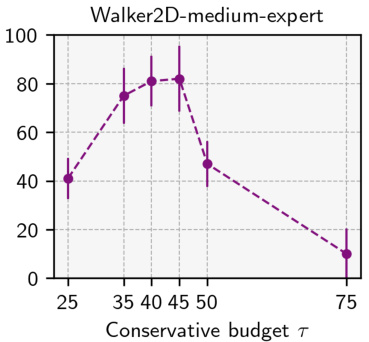
🔼 The figure shows the sensitivity analysis of the Value-Conservative Forward-Backward (VC-FB) method to the hyperparameter τ (conservative budget). It presents the maximum Interquartile Mean (IQM) return achieved during training on two different environments, Walker and Maze, using two datasets: RND (high quality) and RANDOM (low quality). The results show the impact of various values of τ on the algorithm’s performance in these different experimental setups. The top half illustrates results using the RND dataset and the bottom half shows the results using the RANDOM dataset.
read the caption
Figure 14: VC-FB sensitivity to conservative budget τ on Walker and Maze. Top: RND dataset; bottom: RANDOM dataset. Maximum IQM return across the training run averaged over 3 random seeds
🔼 The figure shows how the performance of forward-backward (FB) representations in zero-shot reinforcement learning degrades as the size and quality of the training dataset decrease. It highlights the issue of out-of-distribution (OOD) state-action value overestimation, where the model predicts high values for actions not seen during training, leading to poor actual performance.
read the caption
Figure 2: FB value overestimation with respect to dataset size n and quality. Log Q values and IQM of rollout performance on all Maze tasks for datasets RND and RANDOM. Q values predicted during training increase as both the size and 'quality' of the dataset decrease. This contradicts the low return of all resultant policies (note: a return of 1000 is the maximum achievable for this task). Informally, we say the RND dataset is 'high' quality, and the RANDOM dataset is 'low' quality-see Appendix A.2 for more details.
🔼 This figure illustrates the core concept of the paper. Zero-shot RL methods are trained on a dataset from one task (zcollect), and then they must generalize to new tasks (zeval) without additional training. Existing methods (FB) tend to overestimate the value of actions not seen during training. The paper proposes a solution (VC-FB) that addresses this overestimation by suppressing the value of out-of-distribution actions. The figure shows the effect of this conservative approach.
read the caption
Figure 1: Conservative zero-shot RL. (Left) Zero-shot RL methods must train on a dataset collected by a behaviour policy optimising against task zcollect, yet generalise to new tasks zeval. Both tasks have associated optimal value functions Qcollect and Q*eval for a given marginal state. (Middle) Existing methods, in this case forward-backward representations (FB), overestimate the value of actions not in the dataset for all tasks. (Right) Value-conservative forward-backward representations (VC-FB) suppress the value of actions not in the dataset for all tasks. Black dots () represent state-action samples present in the dataset.
More on tables

🔼 This table presents the aggregated performance results from experiments conducted on the EXORL benchmark. It specifically compares three variants of conservative forward-backward (FB) representations, varying how the task vectors (z) are sampled. DVC-FB samples z exclusively from the backward model, VC-FB samples z exclusively from a distribution over tasks, and MC-FB combines these two approaches. The results show a clear correlation between the sampling method and the overall performance, with VC-FB, which uses samples from the task distribution, achieving the best results.
read the caption
Table 2: Aggregated performance of conservative variants employing differing z sampling procedures on EXORL. DVC-FB derives all zs from the backward model; VC-FB derives all zs from Z; and MC-FB combines both. Performance correlates with the degree to which z ~ Z.

🔼 This table presents the results of experiments conducted using 100,000 data points from three different datasets (RND, DIAYN, and RANDOM) on four different domains (Walker, Quadruped, Maze, and Jaco) within the ExORL benchmark. The table shows the performance of various algorithms (including the proposed VC-FB and MC-FB) on each task within each domain-dataset pair. The scores reported are the interquartile mean (IQM) values obtained at the learning step where the overall performance is best, averaged across 5 seeds. 95% confidence intervals are provided for better statistical reliability.
read the caption
Table 6: 100k dataset experimental results on ExORL. For each dataset-domain pair, we report the score at the step for which the all-task IQM is maximised when averaging across 5 seeds, and the constituent task scores at that step. Bracketed numbers represent the 95% confidence interval obtained by a stratified bootstrap.
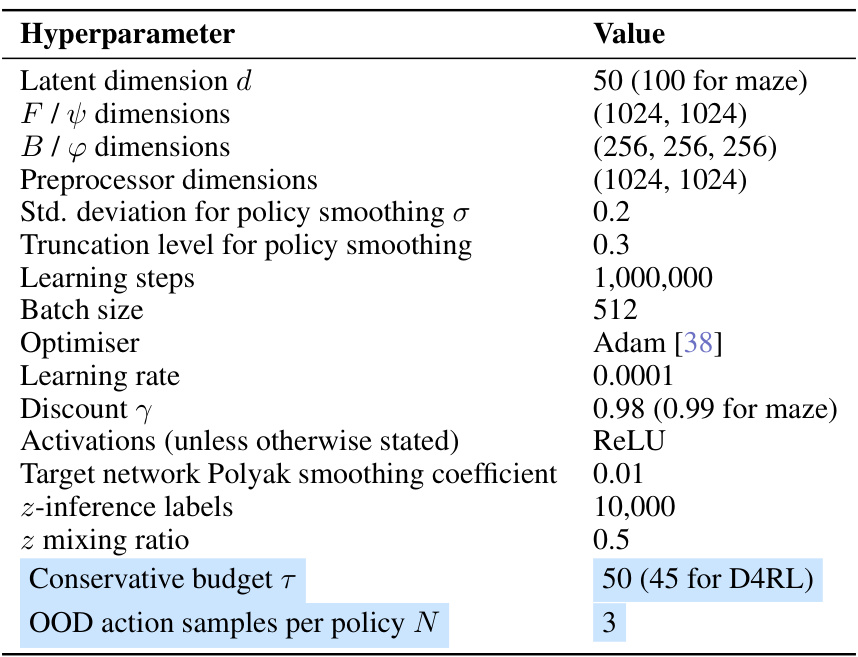
🔼 This table lists the hyperparameters used in the zero-shot RL methods discussed in the paper. It shows the values used for parameters like latent dimension, network layer dimensions, learning rate, discount factor etc. The hyperparameters specific to the conservative variants of the FB method are highlighted in blue.
read the caption
Table 4: Hyperparameters for zero-shot RL methods. The additional hyperparameters for Conservative FB representations are highlighted in blue
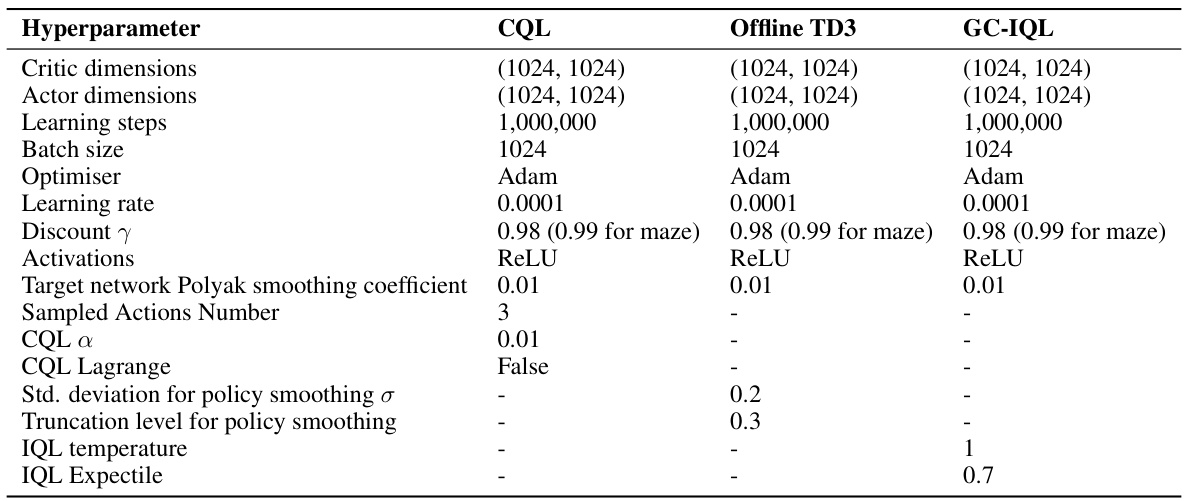
🔼 This table lists the hyperparameters used for the non-zero-shot reinforcement learning methods (CQL, Offline TD3, and GC-IQL) in the paper’s experiments. It shows the architecture details (critic and actor dimensions), training parameters (learning steps, batch size, optimizer, learning rate, discount factor), and activation functions. It also specifies hyperparameters specific to CQL (alpha, Lagrange, sampled actions number) and GC-IQL (IQL temperature, IQL Expectile) and Offline TD3 (standard deviation for policy smoothing, truncation level for policy smoothing).
read the caption
Table 5: Hyperparameters for Non-zero-shot RL.
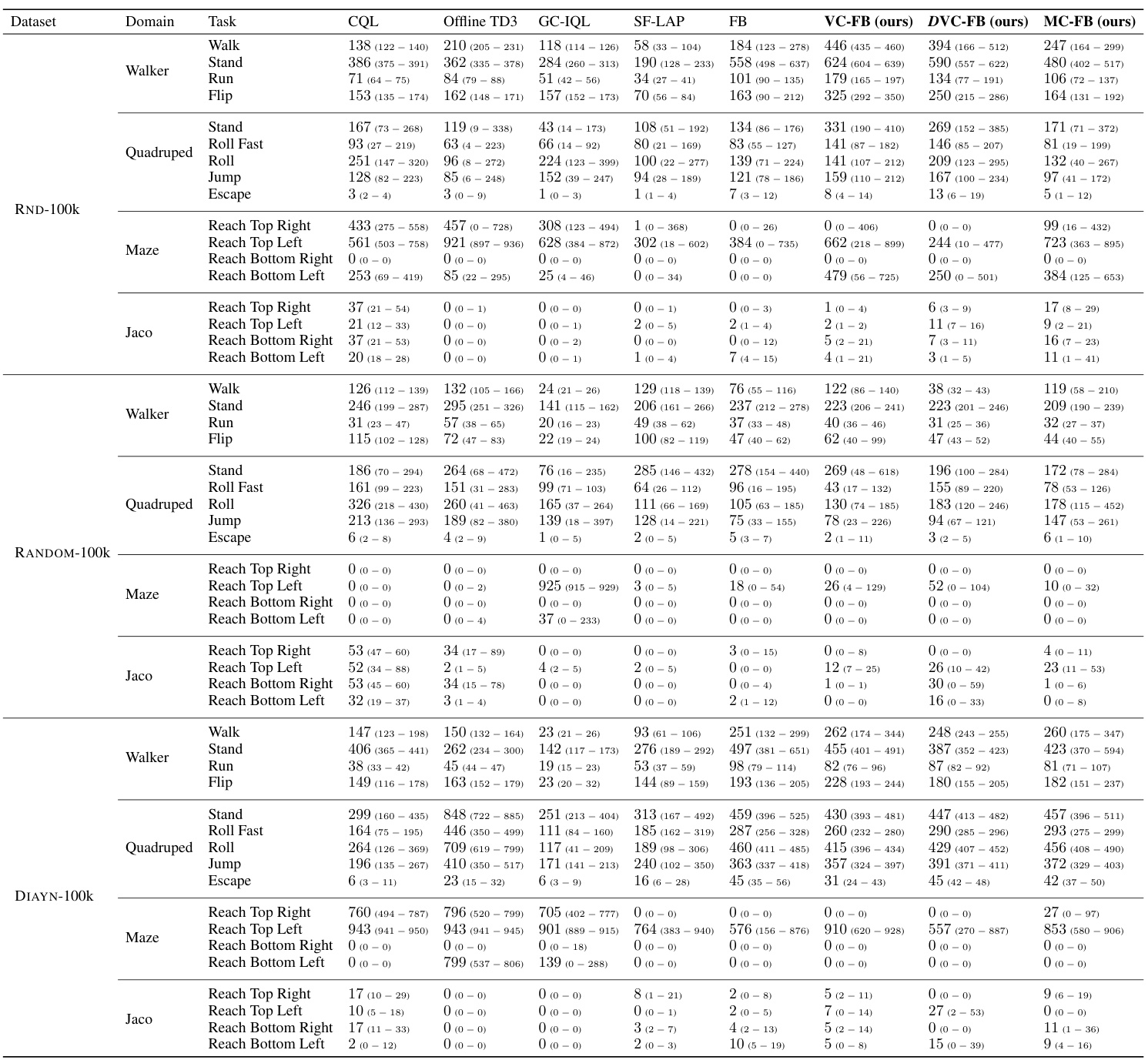
🔼 This table presents the results of experiments conducted on the ExORL benchmark using datasets with 100,000 samples. For each combination of dataset and domain, the table shows the cumulative reward (score) achieved at the learning step where the average performance across all tasks is maximized, along with the individual task scores. The scores are averages across five separate experimental runs. Confidence intervals (95%) are included to show the variability in the results.
read the caption
Table 6: 100k dataset experimental results on ExORL. For each dataset-domain pair, we report the score at the step for which the all-task IQM is maximised when averaging across 5 seeds, and the constituent task scores at that step. Bracketed numbers represent the 95% confidence interval obtained by a stratified bootstrap.
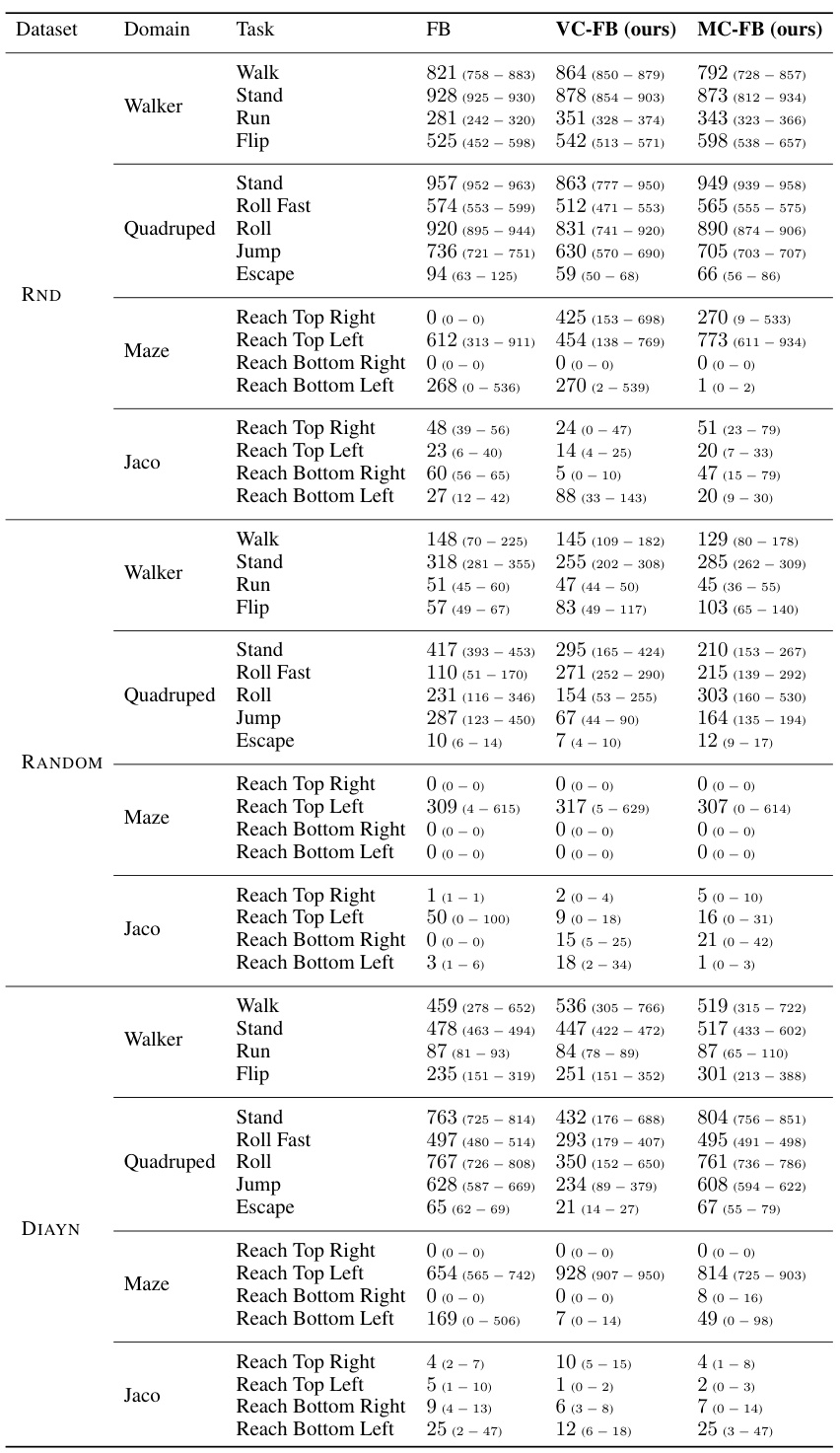
🔼 This table presents the results of experiments performed using datasets with 100,000 transitions. The table shows the performance of different zero-shot RL methods across various tasks and domains in the ExORL benchmark. The reported scores represent the interquartile mean (IQM) of cumulative rewards, averaged across five different random seeds. Confidence intervals are also given.
read the caption
Table 6: 100k dataset experimental results on ExORL. For each dataset-domain pair, we report the score at the step for which the all-task IQM is maximised when averaging across 5 seeds, and the constituent task scores at that step. Bracketed numbers represent the 95% confidence interval obtained by a stratified bootstrap.

🔼 This table shows the performance of different zero-shot reinforcement learning methods (SF-LAP, GC-IQL, FB, CQL, MC-FB, and VC-FB) on the ExORL benchmark. The results are evaluated using multiple metrics (IQM, Mean, Median, and Optimality Gap) recommended by Agarwal et al. [1]. The table highlights that the proposed VC-FB method outperforms all other methods across all evaluation metrics. The large optimality gap is noted to be due to the setting of the discount factor (γ) to 1000, which is not representative of the actual maximum achievable scores in many cases.
read the caption
Table 8: Aggregate zero-shot performance on ExORL for all evaluation statistics recommended by [1]. VC-FB outperforms all methods across all evaluation statistics. ↑ means a higher score is better; ↓ means a lower score is better. Note that the optimality gap is large because we set y = 1000 and for many dataset-domain-tasks the maximum achievable score is far from 1000.
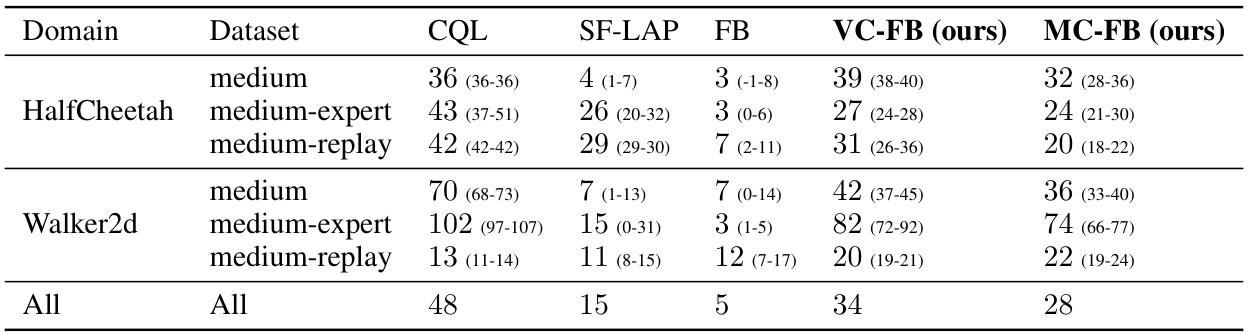
🔼 This table presents the results of experiments conducted using the D4RL benchmark. It shows the interquartile mean (IQM) scores achieved by several reinforcement learning algorithms across different tasks and datasets. The scores are the maximum IQM obtained during training, averaged across three different random seeds, and confidence intervals are provided to indicate the variability of the results.
read the caption
Table 9: D4RL experimental results. For each dataset-domain pair, we report the score at the step for which the IQM is maximised when averaging across 3 seeds. Bracketed numbers represent the 95% confidence interval obtained by a stratified bootstrap.
Full paper#