TL;DR#
Vision-Language Models (VLMs) often fail to handle insufficient visual information when answering questions, unlike humans who seek additional data. This paper tackles this limitation by introducing a novel task: Directional Guidance. This task challenges VLMs to not only identify insufficient information but also suggest how to improve the image (e.g., move the camera) to obtain more relevant visual data.
To train VLMs for this task, the researchers propose a data augmentation method that uses synthetic data generated by simulating the “where to know” scenarios. They fine-tuned three popular VLMs on this synthetic data. Their experimental results show a significant increase in the performance of these models. This demonstrates the potential of this approach to narrow the gap between how humans and VLMs handle incomplete information, ultimately creating more robust and user-friendly AI systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and natural language processing. It addresses the critical limitations of current vision-language models (VLMs) in handling incomplete visual information, a significant issue in real-world applications. The proposed solution of using synthetic data generation to improve VLM’s ability to provide guidance on image adjustments is innovative and can inspire further research on multimodal interaction, potentially leading to more robust and user-friendly AI systems for applications like assistive technologies.
Visual Insights#

🔼 This figure shows three examples of the Directional Guidance task. The task challenges the model to determine if there is enough information in an image to answer a question, and if not, to provide guidance on how to improve the image by moving the camera. The examples highlight scenarios where the model successfully identifies information gaps and suggests appropriate camera adjustments (e.g., moving to the right), situations where the model correctly assesses sufficient information (no action needed), and cases where the model appropriately acknowledges that even with adjustments, the answer cannot be derived.
read the caption
Figure 1: The examples of the Directional Guidance task. The model utilizes self-knowledge to distinguish between known and unknown information and provides guidance on where to find more information.
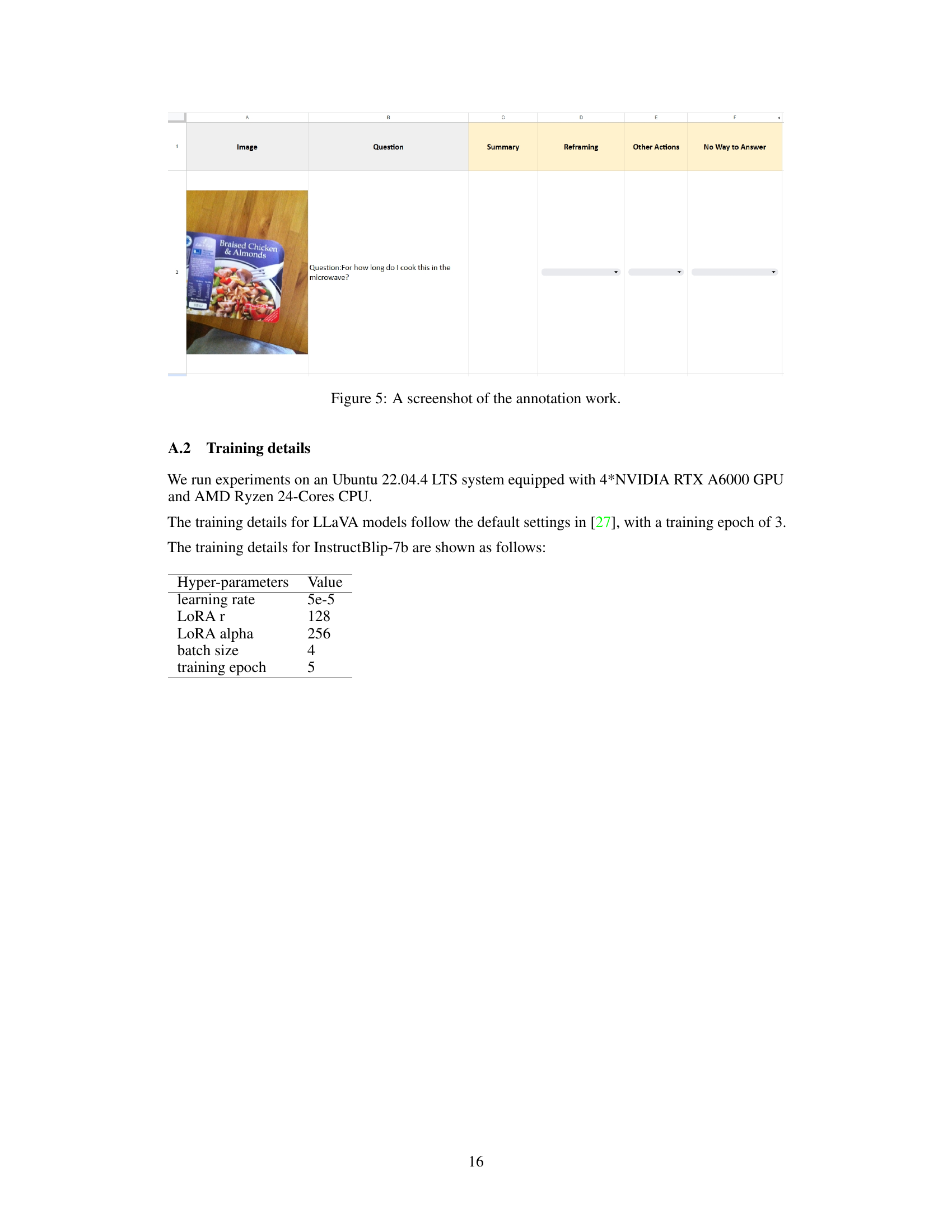
🔼 This table presents the performance of different vision-language models (VLMs) under various settings. The settings involve two different perturbation ranges (0.3-0.7 and 0.1-0.9) and whether the option choices were shuffled during training or not. The models’ performance is evaluated using three metrics: F1-score (F1), overall accuracy (ACC), and accuracy specifically on reframing directions (ACC(F)). The baseline performance of each model without fine-tuning is also included. The table shows how different training strategies and model architectures affect the ability of the models to provide directional guidance for improving image framing in Visual Question Answering (VQA) tasks.
read the caption
Table 1: Model's performance with different settings. F1 and ACC denote the F1 score and accuracy score, respectively. ACC(F) refers to the accuracy of reframing directions, excluding the categories 'Leave it unchanged' and 'None of the other options.'N/A indicates not applicable experiments due to limitations on the model's accessibility or incompatibility with the experiment design.
In-depth insights#
VLM’s Visual Limits#
Vision-Language Models (VLMs), while rapidly advancing, exhibit significant limitations in their visual understanding capabilities. A section titled “VLM’s Visual Limits” would explore these shortcomings in depth. One key area would be the models’ struggles with nuanced visual details and context. Unlike humans, who effortlessly integrate contextual clues, VLMs often fail to properly interpret subtle visual cues, leading to inaccurate or incomplete answers to questions. This inability is especially pronounced in low-resolution or noisy images, and scenarios involving occlusions or complex scenes. Another crucial aspect would concern the models’ limited ability to reason spatially and temporally. While improvements are being made, VLMs still struggle with understanding relative directions, spatial relationships, or temporal changes within image sequences. The lack of common-sense reasoning also presents a major hurdle; VLMs often lack the general world knowledge and intuitive understanding that humans utilize to correctly interpret visual information. Finally, the ethical considerations regarding biased data and potential misinterpretations by VLMs would require careful examination. A robust exploration of “VLM’s Visual Limits” would thus highlight the current bottlenecks and guide future research toward developing more robust, reliable, and ethically sound vision-language models.
Directional Guidance#
The concept of “Directional Guidance” in the context of Visual Question Answering (VQA) systems is a novel approach to address the limitations of current models in handling situations with insufficient visual information. Instead of simply providing an answer or declaring a question unanswerable, the Directional Guidance task focuses on empowering the VQA system to actively guide the user towards acquiring the missing information. This is achieved by having the model identify the insufficiency and suggest a direction (e.g., left, right, up, down) for the user to adjust their camera or viewpoint to capture a more informative image. This human-like approach significantly improves the user experience, particularly for visually impaired individuals. A key aspect of this methodology is the development of a new benchmark dataset and a synthetic data generation framework. This framework augments existing datasets by introducing simulated scenarios where information is partially missing or inadequately framed. Fine-tuning models on this augmented data leads to significant performance improvement, highlighting the effectiveness of the Directional Guidance approach in bridging the gap between information assessment and acquisition capabilities of VQA systems and human capabilities. The work presented makes a significant contribution by proposing a new task and evaluation method, contributing to a more interactive and user-friendly VQA experience.
Synthetic Data Aug#
Synthetic data augmentation is a crucial technique in machine learning, especially when dealing with limited or imbalanced datasets. In the context of a research paper focusing on vision-language models (VLMs), synthetic data augmentation would likely involve generating artificial image-question pairs to address specific challenges. This could include creating images with varying levels of clarity or noise, or manipulating the framing to simulate real-world scenarios where image quality impacts a VLM’s ability to answer a question accurately. The goal is to enhance the model’s robustness and generalization abilities by exposing it to a wider range of data than what is typically available in real-world datasets. A well-designed synthetic augmentation strategy would involve carefully considering factors such as the type of perturbations introduced, the distribution of augmented samples, and the balance between realism and diversity. Careful evaluation of the effectiveness of synthetic augmentation is essential, comparing the performance of VLMs trained with and without synthetic data. The paper should also analyze the impact of synthetic data on different VLM architectures and their ability to handle ambiguous or incomplete information. The success of this approach hinges on the ability to create synthetic data that genuinely reflects the challenges of real-world data, while avoiding the introduction of artifacts or biases that might negatively impact model performance.
Model Fine-tuning#
Model fine-tuning is a crucial aspect of adapting pre-trained vision-language models (VLMs) to specific tasks. In this research, fine-tuning plays a pivotal role in bridging the gap between the model’s inherent capabilities and its ability to provide directional guidance in visual question answering (VQA). The paper introduces a novel method of synthetic data generation to augment the training data. This involves perturbing existing images to simulate scenarios where visual information is insufficient. The subsequent fine-tuning process leverages this synthetic data to improve the model’s accuracy in identifying ill-framed images and suggesting corrective camera movements. This approach demonstrates a data-efficient way of improving the model’s performance compared to relying solely on real-world data. Significant improvements in performance metrics, including F1-score and accuracy are observed across multiple mainstream VLMs after fine-tuning, showcasing the effectiveness of the methodology. The findings highlight the importance of fine-tuning strategies for enhancing the cognitive capabilities of VLMs, especially in the context of visually impaired individuals requiring accurate navigational assistance.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Expanding the types of visual adjustments beyond simple directional guidance is crucial; incorporating zoom, rotation, and exposure adjustments would significantly enhance real-world applicability. Developing more sophisticated methods for identifying and generating synthetic training data is also important; exploring different perturbation techniques and strategies for data augmentation will be key. Furthermore, investigating the generalizability of the proposed framework across diverse VQA datasets and language models is necessary to establish its robustness. Finally, a key area for future work involves addressing the ethical implications of employing this technology, particularly focusing on how to mitigate the risk of potential biases and ensure fair and responsible use, especially in assistive technologies for visually impaired individuals.
More visual insights#
More on figures

🔼 The figure illustrates the process of generating the training dataset for the Directional Guidance task. It starts with an image and a question from the VizWiz-grounding dataset. The image is then perturbed by applying predefined rules that crop relevant visual information. This is done by identifying the bounding box surrounding the target object and dividing it into 10 zones, horizontally and vertically. The specific zone for cropping is chosen. This results in an image with missing information that is then fed to a pretrained VLM along with the original question. The VLM is prompted to provide the corresponding answer, and the consistency of the model’s response is evaluated. The cases where ill-framing impacts the question-answering are captured. The synthetic training data is generated by these steps, paired with their corresponding guidance. The purpose is to simulate ill-framed scenarios and enhance the model’s ability to provide directional guidance when faced with insufficient visual information.
read the caption
Figure 2: The training set generation framework.

🔼 The figure illustrates the process of generating synthetic training data for the Directional Guidance task. It starts with selecting answerable questions and their corresponding images from an existing VQA dataset. These images are then perturbed by applying predefined cropping rules, simulating real-world scenarios with insufficient visual information. A pretrained VLM is used to assess the model’s ability to answer the questions correctly before and after these perturbations. Based on the model’s performance, corresponding guidance labels (’leave it unchanged’, ’left’, ‘right’, ‘up’, ‘down’) are generated, creating the training data. This process ensures that the synthetic data effectively reflects the challenge of identifying information insufficiency and providing directional guidance.
read the caption
Figure 2: The training set generation framework.

🔼 This figure shows the distribution of the four directions (up, down, left, right) in the benchmark dataset created for evaluating the Directional Guidance task. The pie chart (a) visually represents the percentage of each direction in the dataset. The images (b-e) provide example questions and the corresponding Directional Guidance labels. These examples showcase the varying scenarios in which directional guidance might be necessary to improve image quality for a visually impaired user.
read the caption
Figure 3: The distribution of four directions in our benchmark dataset (a) and examples (b-e). The upper caption is the Directional Guidance label and the lower caption is the original question.
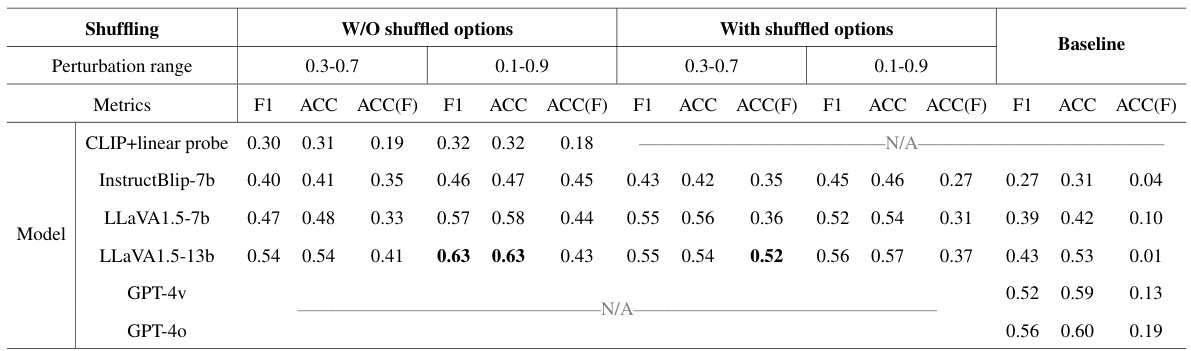
🔼 This figure presents heatmaps visualizing the performance of four different vision-language models (LLaVA-1.5 7B, LLaVA-1.5 13B, InstructBlip 7B, and CLIP with linear probing) on a directional guidance task in a visual question answering setting. The heatmaps compare the models’ performance before (zero-shot, a1-a4) and after (fine-tuned, b1-b4) being fine-tuned using a synthetic training dataset. Each heatmap shows the confusion matrix for the models’ predictions, illustrating the model’s ability to accurately predict the necessary direction to adjust camera framing to better answer unanswerable questions. The ‘O’ in the heatmaps indicates the model correctly identified the question as answerable without reframing and ‘X’ represents cases where the model determined that even reframing would not resolve the issue. The differences in heatmap patterns between the zero-shot baseline and fine-tuned models highlight the effectiveness of the proposed fine-tuning strategy in improving directional guidance prediction.
read the caption
Figure 4: The heatmaps of the model's prediction. (a1)-(a4) shows the baseline performance under zero-shot setting, and (b1)-(b4) shows the performances of fine-tuned models. 'O' denotes the class leave it unchanged, and 'X' denotes the class none of the other options.
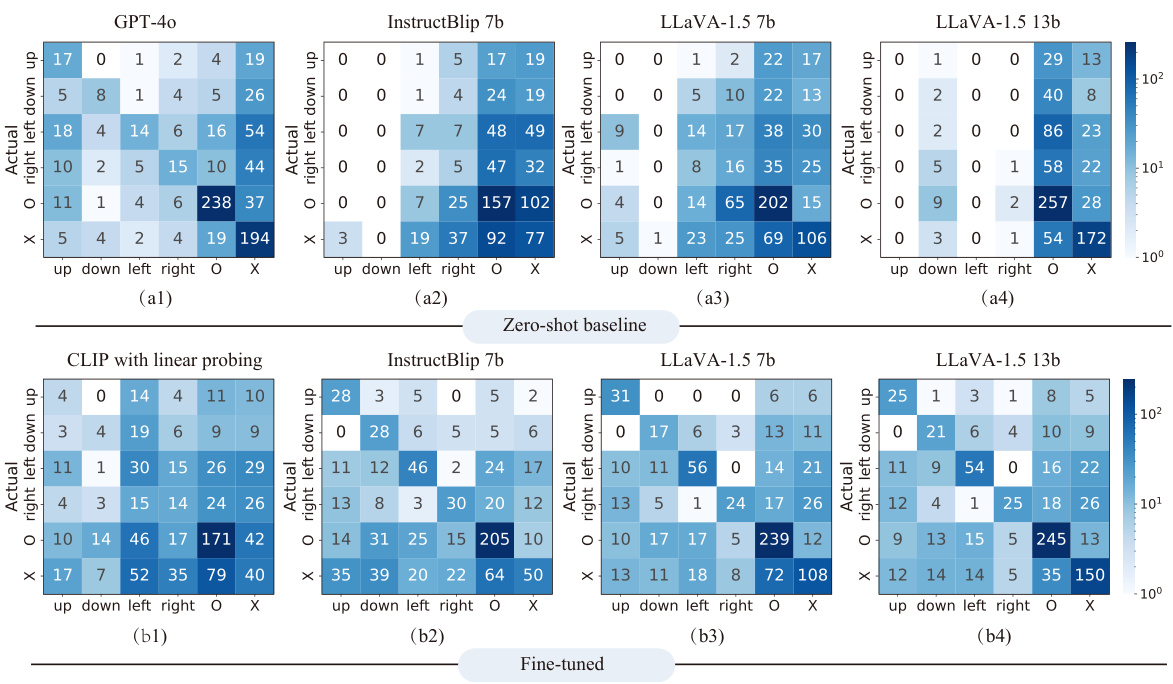
🔼 This figure shows a screenshot of the annotation interface used in the study. The interface presents an image and a question to the annotators, and it asks them to choose from several options to indicate if any adjustments or guidance could potentially make the question answerable. The options include reframing the image by moving the camera (left, right, up, or down), taking other actions (like zooming in/out, rotating, or adjusting exposure), or indicating that there is no way to answer the question.
read the caption
Figure 5: A screenshot of the annotation work.

🔼 This figure presents heatmaps illustrating the performance of four different vision-language models (LLaVA-1.5 7B, LLaVA-1.5 13B, InstructBlip 7B, and CLIP with linear probing) on a directional guidance task. The heatmaps show the model’s predictions for directional guidance (up, down, left, right, leave unchanged, or none of the other options) under two settings: zero-shot and fine-tuned. The zero-shot setting represents the model’s performance without any fine-tuning, while the fine-tuned setting demonstrates the improvement after training with synthetic data generated by the proposed framework. Each cell in the heatmap represents the number of times a particular prediction was made for a given actual label. The darker the color, the higher the frequency of that prediction.
read the caption
Figure 4: The heatmaps of the model's prediction. (a1)-(a4) shows the baseline performance under zero-shot setting, and (b1)-(b4) shows the performances of fine-tuned models. 'O' denotes the class leave it unchanged, and 'X' denotes the class none of the other options.

🔼 This figure shows three examples of the Directional Guidance task. The task involves a Vision-Language Model (VLM) assessing whether it has enough information to answer a question. If not, it must provide guidance on how to adjust the image (e.g., move the camera) to get more information. The examples illustrate different scenarios: a question about a room number that’s partially visible; a question about an object where the image is not sufficient to provide an answer; and a question about the color of a shirt that is difficult to ascertain from the given image. The VLM provides a text response suggesting how to improve the image in order to give an answer or states that it cannot answer the question.
read the caption
Figure 1: The examples of the Directional Guidance task. The model utilizes self-knowledge to distinguish between known and unknown information and provides guidance on where to find more information.

🔼 This figure shows the distribution of directional guidance labels in the benchmark dataset, illustrating the frequency of each direction (left, right, up, down). It also provides example images (b-e) representing each direction, with the original question posed to the visually impaired user and the corresponding Directional Guidance given by a human annotator. This demonstrates the real-world scenarios and the task challenge.
read the caption
Figure 3: The distribution of four directions in our benchmark dataset (a) and examples (b-e). The upper caption is the Directional Guidance label and the lower caption is the original question.

🔼 This figure presents the distribution of directional guidance labels in the benchmark dataset, showing that ’left’ and ‘right’ are the most common directions. It also includes example image-question pairs to illustrate different scenarios and the corresponding Directional Guidance labels given by human annotators. The examples highlight the varying image qualities and the challenges associated with capturing clear and appropriately framed images for visually impaired individuals.
read the caption
Figure 3: The distribution of four directions in our benchmark dataset (a) and examples (b-e). The upper caption is the Directional Guidance label and the lower caption is the original question.

🔼 This figure shows the distribution of the four directions (left, right, up, down) in the Directional Guidance benchmark dataset. The pie chart (a) visualizes the proportion of each direction. The images (b-e) provide examples of real-world VQA queries from visually impaired individuals, showcasing scenarios where image reframing is necessary to provide accurate answers. Each image is accompanied by the original question and its corresponding Directional Guidance label, indicating the optimal direction for camera adjustment.
read the caption
Figure 3: The distribution of four directions in our benchmark dataset (a) and examples (b-e). The upper caption is the Directional Guidance label and the lower caption is the original question.
More on tables
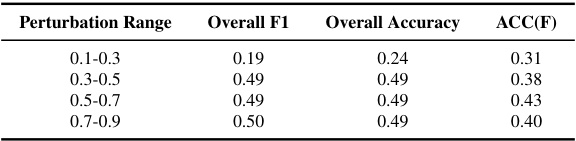
🔼 This table presents the performance of the LLaVA-1.5 7b model under different perturbation ranges. The perturbation range determines the cropping ratios used to generate the training samples. It shows the overall F1 score, overall accuracy and accuracy on reframing cases (ACC(F)) for each perturbation range. The results demonstrate the impact of the perturbation range on model performance.
read the caption
Table 2: Model's performance under different perturbation ranges with LLaVA-1.5 7b.

🔼 This table presents the performance of four different vision-language models (LLaVA-1.5 7B, LLaVA-1.5 13B, InstructBlip 7B, and GPT-4) under various settings. The metrics used are F1 score, overall accuracy (ACC), and accuracy specifically on reframing directions (ACC(F)). The settings compared include the use of shuffled options during training and different perturbation ranges for data augmentation. ‘N/A’ indicates where a model could not be tested under a particular setting.
read the caption
Table 1: Model's performance with different settings. F1 and ACC denote the F1 score and accuracy score, respectively. ACC(F) refers to the accuracy of reframing directions, excluding the categories 'Leave it unchanged' and 'None of the other options'.N/A indicates not applicable experiments due to limitations on the model's accessibility or incompatibility with the experiment design.
Full paper#