TL;DR#
Large language models (LLMs) often struggle to accurately use contextual information, leading to unreliable or inaccurate outputs. Existing citation methods primarily focus on teaching models to explicitly cite sources, failing to address the underlying issue of how models actually utilize the context. This paper tackles the problem of ‘context attribution’ – identifying the specific parts of the context that influence a model’s generation. The issue of correctly identifying the contextual information used by LLMs is important as it impacts reliability, quality, and security.
The paper introduces CONTEXTCITE, a novel and scalable method for context attribution. CONTEXTCITE learns a surrogate model to approximate how a model’s response changes when parts of the context are removed. The model’s weights directly provide attribution scores. The researchers demonstrate CONTEXTCITE’s effectiveness in three key applications: verifying the accuracy of generated statements, improving response quality by pruning contexts, and detecting malicious context poisoning attacks. CONTEXTCITE provides a valuable tool for researchers to better understand and improve LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models because it introduces a novel method for understanding how these models use contextual information. It offers practical applications for improving model reliability, enhancing output quality, and detecting malicious attacks, thereby advancing the field of trustworthy AI. The insights provided are relevant across diverse research areas, including model interpretability, data attribution, and adversarial robustness.
Visual Insights#

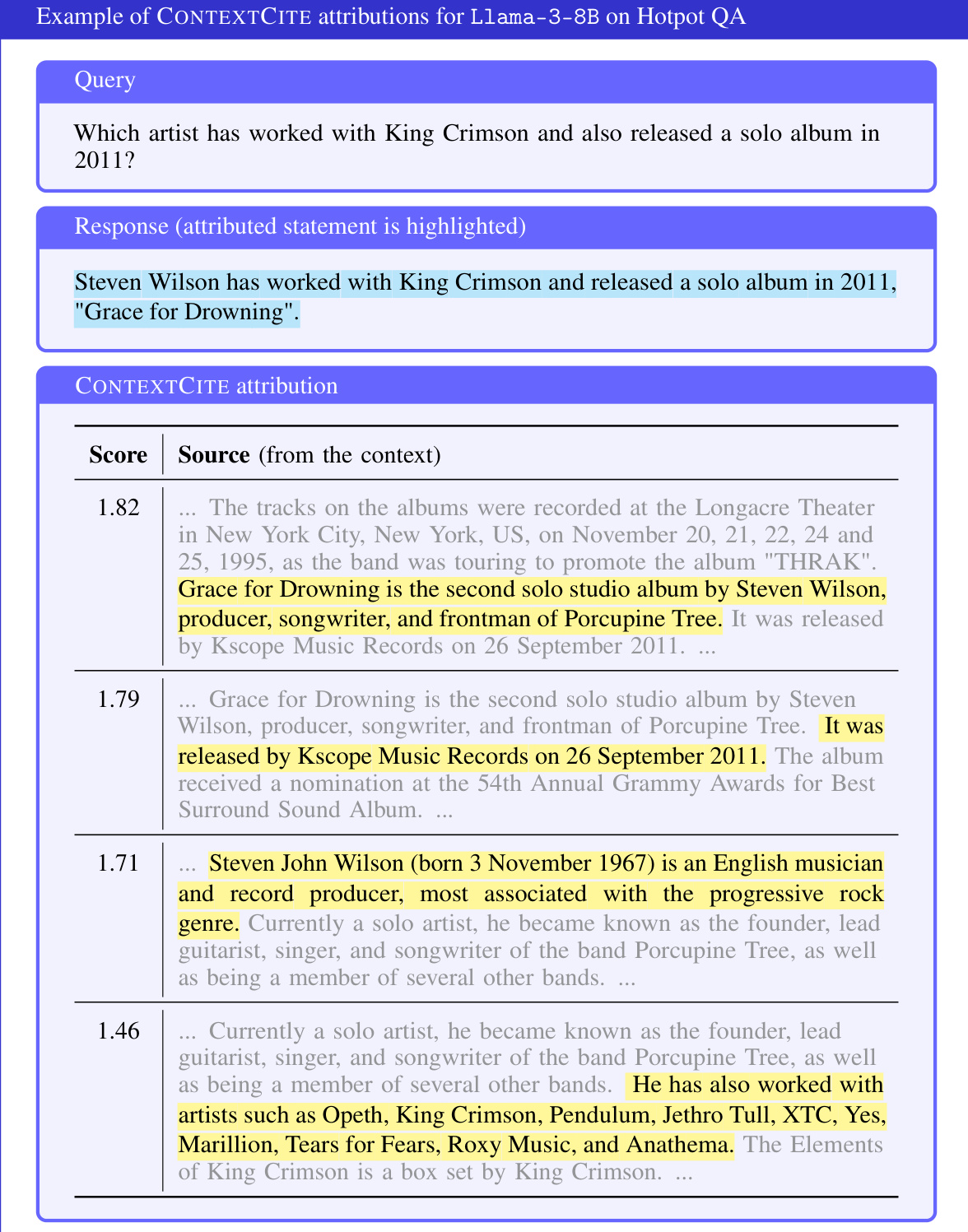
🔼 The figure shows a simple example of how CONTEXTCITE works. Given a context (a PDF about the 2024 solar eclipse), and a query (‘I live in Boston, MA. When and where should I go to see the eclipse?’), a language model generates a response. CONTEXTCITE then highlights the portion of the context that was used by the model to generate a specific part of the response. In this case, the response’s statement about Maine being on the path of totality is linked to the relevant section in the provided PDF.
read the caption
Figure 1: CONTEXTCITE. Our context attribution method, CONTEXTCITE, traces any specified generated statement back to the parts of the context that are responsible for it.
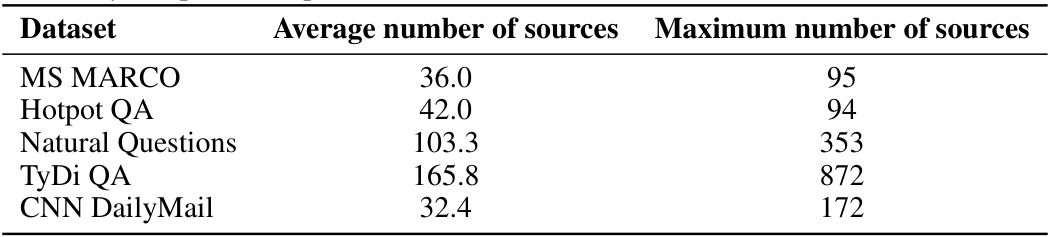
🔼 This table shows the average and maximum number of sources (sentences) found in the datasets used in the paper’s experiments. The datasets include MS MARCO, Hotpot QA, Natural Questions, TyDi QA, and CNN DailyMail. The numbers indicate the variability in context length across the different datasets. This information is crucial for understanding the scale and characteristics of the data used to evaluate the proposed method.
read the caption
Table 1: The average and maximum numbers of sources (in this case, sentences) among the up to 1,000 randomly sampled examples from each of the datasets we consider.
In-depth insights#
Context Attribution#
The concept of ‘Context Attribution’ in the research paper is crucial for understanding how language models utilize contextual information. It addresses the challenge of determining which specific parts of the provided context directly influence a model’s generated output. This moves beyond simply verifying accuracy by delving into the causal relationships between the input context and the generated response. A key contribution is the formalization of context attribution, providing a standardized framework for evaluating different methods. The proposed method, CONTEXTCITE, offers a practical and scalable approach for identifying contributing context segments by learning a surrogate model that predicts the effects of context ablation. This allows for a deeper investigation into misinterpretations or fabrications by the model, improving response quality and aiding in the detection of adversarial attacks. The effectiveness of CONTEXTCITE is demonstrated through multiple applications, showcasing its utility in verification, context pruning, and poisoning attack detection. Overall, context attribution is a significant step towards greater transparency and reliability in language model outputs.
CONTEXTCITE Method#
The hypothetical ‘CONTEXTCITE Method’ section would delve into the specifics of their proposed approach for context attribution. It would likely begin by outlining the surrogate model employed – a crucial component for efficiently estimating the impact of context alterations on model output. The details of this model’s architecture, training process (dataset creation and ablation strategies), and the selection of a suitable loss function are all key elements to be described. Further discussion would encompass the attribution score calculation (how the model’s weights are interpreted as attribution scores) and the method’s scalability, addressing how well it handles large contexts and models. A crucial aspect would be a detailed explanation of how the method accounts for potential interactions between different parts of the context, a significant challenge in context attribution. Finally, the section should detail the evaluation metrics used, including justifications for their choice and interpretations of results, providing insights into the method’s effectiveness and limitations.
Applications#
The ‘Applications’ section of a research paper is crucial for demonstrating the practical value and impact of the presented work. It showcases how the research findings can be used to solve real-world problems or improve existing technologies. A strong ‘Applications’ section goes beyond merely listing potential uses; it provides concrete examples, possibly with specific data or metrics to support the claims. It might explore various applications that leverage the core methodology in different contexts, highlighting the flexibility and generalizability of the approach. The depth of the examples in the section determines how convincing the argument of the paper’s practical utility is; simple mentions of potential use cases are weaker than detailed case studies or quantitative evaluations of application performance. A particularly insightful ‘Applications’ section might also highlight unexpected or innovative applications of the research, expanding beyond the initially anticipated uses and showcasing the research’s potential for broader impact. Furthermore, a strong emphasis on the positive societal benefits of these applications and the discussion of potential risks or ethical considerations related to their deployment should be included, rounding out a comprehensive and responsible presentation of the research’s overall value.
Limitations#
The research paper’s section on limitations acknowledges the linearity assumption inherent in CONTEXTCITE’s surrogate model, admitting that it might not always accurately represent complex relationships between context and response. The method’s reliance on ablation studies is also noted as a potential weakness; misinterpretations or oversimplifications from removing context elements could affect the accuracy of attributions. Furthermore, the paper highlights the challenge of attributing statements derived from prior statements or implicitly held knowledge, which are not directly traceable to specific context sources. The computational expense associated with the ablation process, particularly when dealing with longer documents, is also recognized. Finally, the validity of the ablation method itself is questioned, as straightforward removal of context segments may fail to account for complex interdependencies within the text, potentially leading to inaccurate or unintuitive attribution results.
Future Work#
The heading ‘Future Work’ in a research paper typically outlines potential avenues for extending the current research. In the context of this paper on ContextCite, future work could logically involve several key areas. Improving the scalability of ContextCite for even larger language models and more complex contexts would be crucial for broader applicability. Investigating alternative methods for source identification, perhaps moving beyond linear surrogate models or exploring different granularities of context segmentation, would enhance the technique’s robustness and accuracy. A particularly interesting area would be exploring the relationship between contributive and corroborative context attribution. Currently, the paper focuses on contributive attribution, identifying sources that cause generation. Future work could investigate the interplay with corroborative methods, which identify sources that support generation. Finally, exploring practical applications beyond verification, response quality improvement, and poisoning attack detection is vital. This could include integrating ContextCite into real-world applications or examining its utility in other contexts such as bias detection or model explainability.
More visual insights#
More on figures

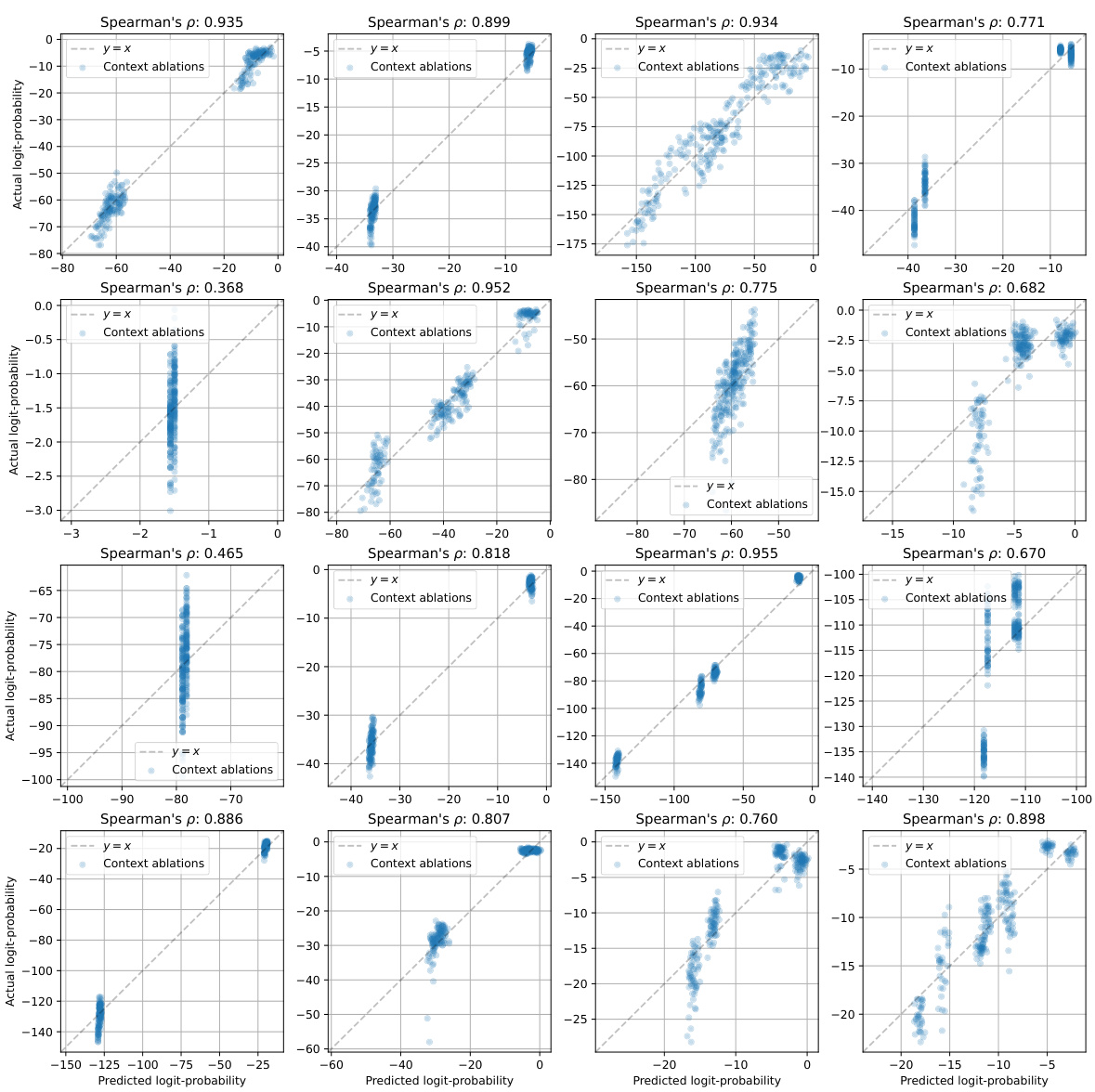
🔼 This figure demonstrates an example of how CONTEXTCITE, a linear surrogate model, is used for context attribution. The left side shows the context, query, and generated response. The middle shows the attribution scores (weights of the linear model). The right displays a scatter plot comparing the model’s predictions of logit-scaled probabilities against the actual values, for various context ablations. The plot shows a strong linear correlation, indicating the model’s accuracy.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.
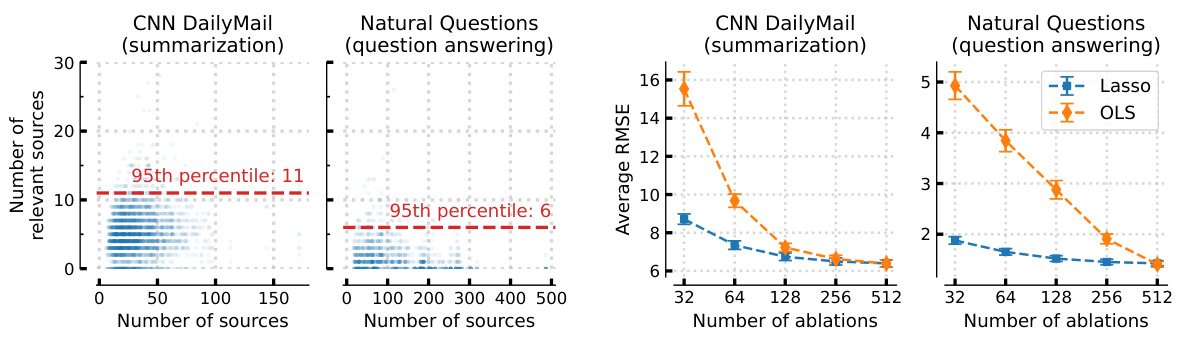
🔼 This figure demonstrates how inducing sparsity in the surrogate model improves sample efficiency for context attribution. It shows that even with many sources, only a small subset is truly relevant in predicting model responses for both summarization and question answering tasks. LASSO regularization effectively identifies these crucial sources with fewer ablations, leading to a more efficient and accurate surrogate model.
read the caption
Figure 3: Inducing sparsity improves the surrogate model's sample efficiency. In CNN DailyMail [28], a summarization task, and Natural Questions [29], a question answering task, we observe that the number of sources that are “relevant” for a particular statement generated by Llama-3-8B [22] is small, even when the context comprises many sources (Figure 3a). Therefore, inducing sparsity via LASSO yields an accurate surrogate model with just a few ablations (Figure 3b). See Appendix A.4 for the exact setup.

🔼 This figure demonstrates an example of how CONTEXTCITE, a linear surrogate model, is used for context attribution. The left side shows the context, query, and generated response. The middle shows the attribution scores (weights of the linear model) assigned by CONTEXTCITE to each source. The right side displays a scatter plot comparing the surrogate model’s predictions to the actual logit probabilities obtained by ablating different parts of the context. The linear relationship shown indicates the model effectively captures the model’s behavior.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.

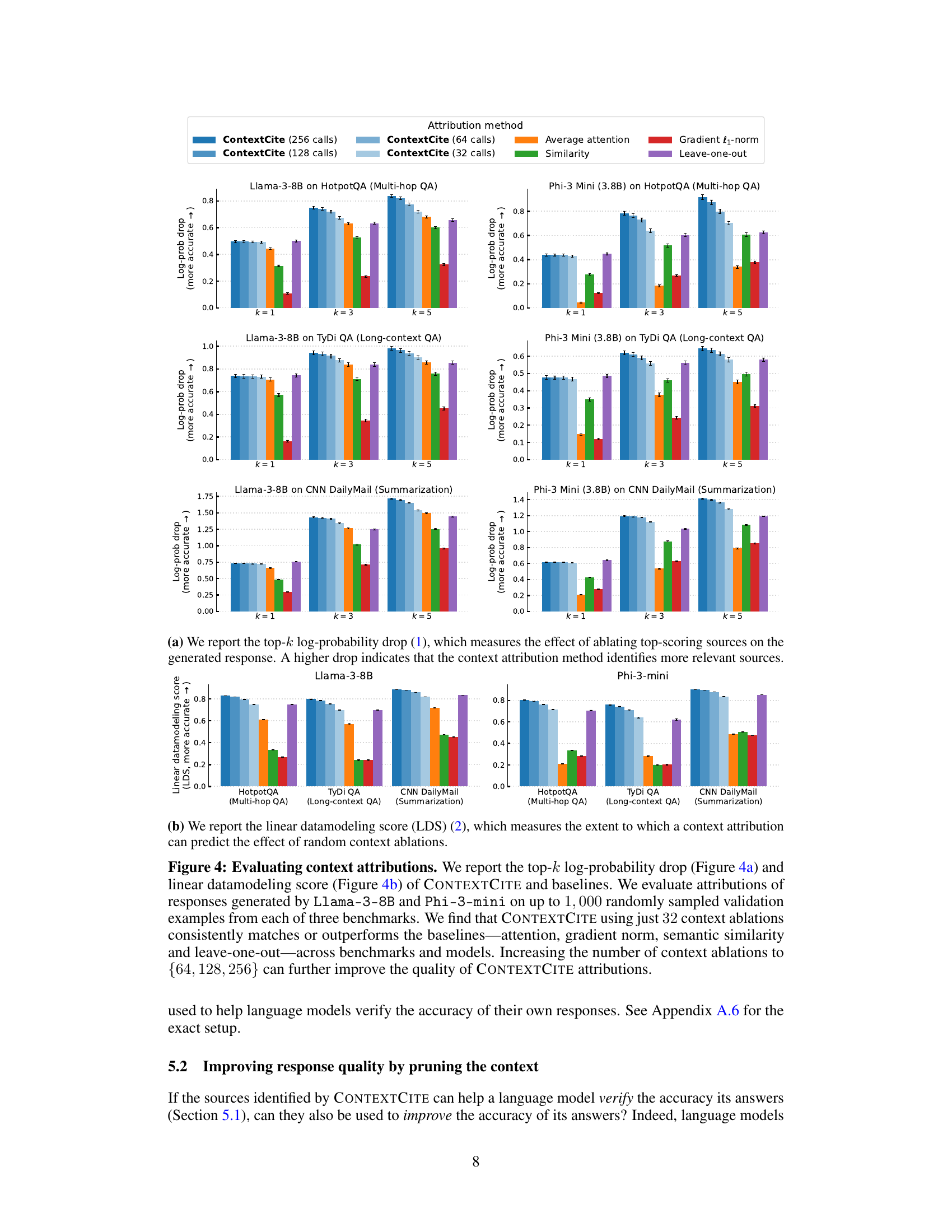
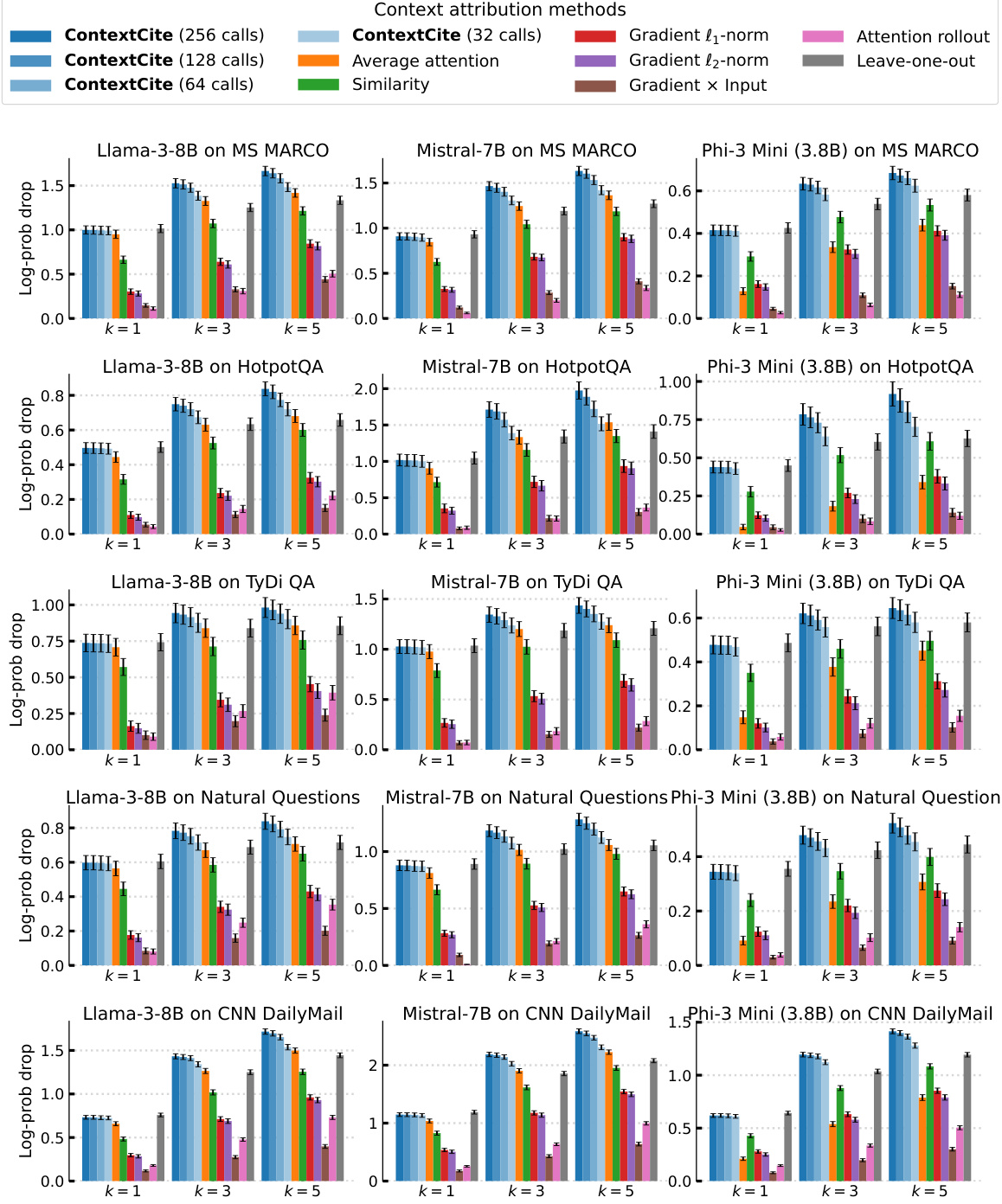
🔼 This figure compares the performance of CONTEXTCITE against several baseline methods for context attribution across different datasets and language models. Two metrics are used for evaluation: top-k log-probability drop and linear datamodeling score. CONTEXTCITE demonstrates superior performance, even with a limited number of context ablations, suggesting its effectiveness in identifying relevant context sources.
read the caption
Figure 4: Evaluating context attributions. We report the top-k log-probability drop (Figure 4a) and linear datamodeling score (Figure 4b) of CONTEXTCITE and baselines. We evaluate attributions of responses generated by Llama-3-8B and Phi-3-mini on up to 1,000 randomly sampled validation examples from each of three benchmarks. We find that CONTEXTCITE using just 32 context ablations consistently matches or outperforms the baselines-attention, gradient norm, semantic similarity and leave-one-out-across benchmarks and models. Increasing the number of context ablations to {64, 128, 256} can further improve the quality of CONTEXTCITE attributions in this setting as well.
🔼 This figure illustrates an example of how CONTEXTCITE uses a linear surrogate model to perform context attribution. It shows a context, query, and response, along with the weights (attribution scores) assigned by the surrogate model to each part of the context. The plot demonstrates the model’s ability to accurately predict the logit-scaled probability of the response given different context ablations, indicating a strong linear relationship between context features and response generation.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.
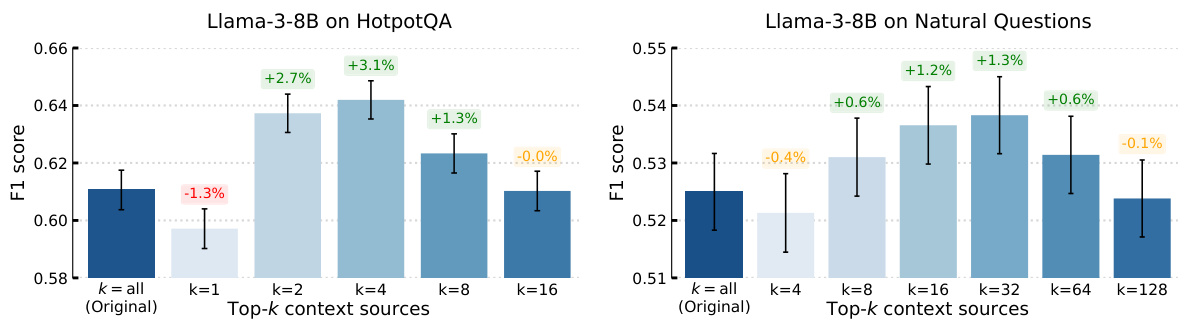
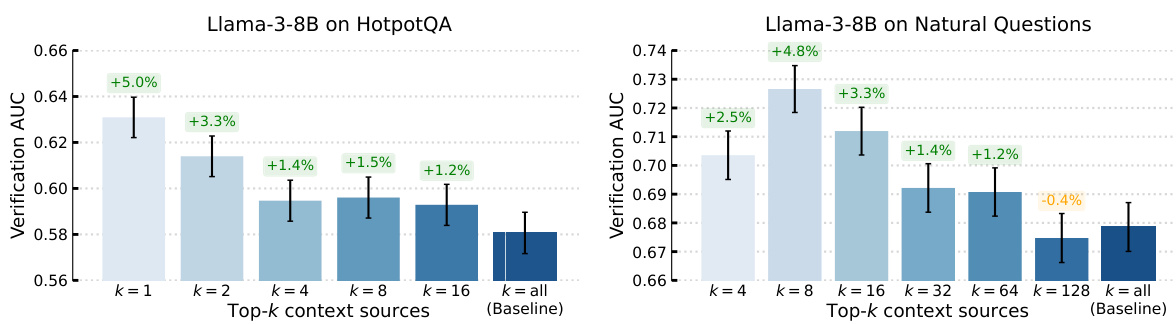
🔼 This figure shows the results of two experiments evaluating the impact of pruning irrelevant information from the context before generating responses using a language model. The left graph shows that selecting only the top 2 to 16 most relevant sources based on CONTEXTCITE’s attribution scores improved the F1 score on the HotpotQA dataset. The right graph shows similar improvements on the Natural Questions dataset when using the top 8 to 128 sources. This demonstrates that CONTEXTCITE can effectively identify and select the most relevant parts of the context, leading to improved response quality.
read the caption
Figure 6: Improving response quality by constructing query-specific contexts. On the left, we show that filtering contexts by selecting the top-{2, ..., 16} query-relevant sources (via CONTEXTCITE) improves the average F₁-score of Llama-3-8B on 1,000 randomly sampled examples from the Hotpot QA dataset. Similarly, on the right, simply replacing the entire context with the top-{8,..., 128} query-relevant sources boosts the average F₁-score of Llama-3-8B on 1,000 randomly sampled examples from the Natural Questions dataset. In both cases, CONTEXTCITE improves response quality by extracting the most query-relevant information from the context.

🔼 This figure demonstrates an example of how CONTEXTCITE, a linear surrogate model, is used for context attribution. It shows the weights of the model (attribution scores), the actual vs predicted logit-scaled probabilities for random context ablations, and how these two sources primarily determine the response. The linearity of the model is highlighted, showing the additive effects of removing the sources.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.

🔼 This figure demonstrates an example of how CONTEXTCITE, a linear surrogate model, is used for context attribution. It shows a context, query, and response generated by Llama-3-8B about the weather in Antarctica. The figure highlights the model’s weights (attribution scores) and a plot comparing the surrogate model’s predictions against the actual logit-scaled probabilities for random context ablations. The results show a strong linear relationship between the model’s predictions and the actual probabilities, indicating that the surrogate model effectively captures the language model’s behavior. This example shows two main sources that primarily contribute to the response.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model’s predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model’s behavior.

🔼 This figure illustrates an example of CONTEXTCITE’s linear surrogate model. The left shows a context, query, and model-generated response. The middle displays the weights of the linear surrogate model (interpreted as attribution scores). The right shows a scatter plot comparing the surrogate model’s predictions of logit-scaled probabilities against actual logit-scaled probabilities from random context ablations. The strong linear correlation demonstrates the model’s accuracy in capturing the language model’s behavior. The example highlights how a few key context sources strongly influence the response.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model’s predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model’s behavior.

🔼 This figure shows an example of how CONTEXTCITE uses a linear surrogate model to perform context attribution. The left side displays the context, query, and response generated by a language model. The middle shows the weights (attribution scores) of the linear surrogate model. The right side displays a scatter plot comparing the surrogate model’s predictions against the actual probabilities from context ablations, illustrating the model’s accuracy in capturing the language model’s behavior. The example highlights the linear interaction between two key sources in generating the response.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.

🔼 This figure shows an example of how CONTEXTCITE uses a linear surrogate model to perform context attribution. It demonstrates the model’s ability to accurately predict the logit probability of a response based on ablating different parts of the context. The strong correlation between predicted and actual probabilities highlights the effectiveness of the linear surrogate model in capturing the language model’s behavior. The example focuses on an Antarctica weather query.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.

🔼 This figure shows an example of how CONTEXTCITE uses a linear surrogate model to attribute a response to parts of the input context. The left panel shows the context, query and generated response. The middle panel shows the weights of the linear model, which are interpreted as attribution scores for each source. The right panel compares the surrogate model’s predictions to the actual logit probabilities for various context ablations, demonstrating the model’s accuracy in capturing the language model’s behavior.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model’s behavior.

🔼 This figure demonstrates how CONTEXTCITE uses a linear surrogate model to perform context attribution. It shows an example of a context, query, and generated response, along with the attribution scores (weights of the surrogate model) assigned to different parts of the context. The plot on the right visually shows the strong correlation between the surrogate model’s predictions and the actual logit-scaled probabilities, indicating the model’s accuracy in capturing the language model’s behavior.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.

🔼 This figure shows an example of how CONTEXTCITE uses a linear surrogate model to perform context attribution. The left side shows the context, query, and generated response. The middle displays the weights of the linear model, which are interpreted as attribution scores. The right shows a scatter plot comparing the surrogate model’s predictions with the actual logit probabilities from various context ablations. The close correlation between predicted and actual values demonstrates the model’s accuracy in capturing the relationship between context and response. The example highlights the linear interaction between two key sources in generating the response.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model’s behavior.
🔼 This figure illustrates an example of how CONTEXTCITE, a context attribution method, uses a linear surrogate model to estimate the logit-scaled probability of a response. It shows the weights of the linear model as attribution scores and compares the model’s predictions against actual probabilities for random context ablations. The close match between predicted and actual probabilities demonstrates the model’s accuracy in capturing the language model’s behavior.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.

🔼 This figure illustrates how CONTEXTCITE uses a linear surrogate model to estimate the logit-scaled probability of a response based on context ablations. It shows an example with a context, query, and response about the weather in Antarctica. The model weights are displayed as attribution scores, and a scatter plot demonstrates the model’s accuracy in predicting the actual logit-scaled probabilities. The linearity of the model’s behavior and its ability to capture the effect of ablations are highlighted.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.

🔼 This figure shows an example of how CONTEXTCITE uses a linear surrogate model to attribute a response to parts of the context. The left panel shows the context, query, and generated response. The middle panel shows the weights (attribution scores) assigned by the linear surrogate model to each source in the context. The right panel shows a scatter plot comparing the model’s predictions to the actual log-probabilities, demonstrating the model’s accuracy in capturing the language model’s behavior.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.
🔼 This figure demonstrates an example of how CONTEXTCITE, a linear surrogate model, is used for context attribution. It shows the weights (attribution scores) assigned to different parts of the context for a given response. The plot on the right shows the strong correlation between the surrogate model’s predictions and the actual log-probabilities, indicating the model’s accuracy.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model’s behavior.

🔼 This figure illustrates an example of how CONTEXTCITE, a method for context attribution, uses a linear surrogate model to approximate the relationship between context ablations and the logit-scaled probability of a response. The left shows the context, query and generated response. The middle shows the attribution scores derived from the weights of the linear surrogate model. The right plots the surrogate model predictions against the actual logit-scaled probabilities, demonstrating a strong correlation and showcasing the method’s effectiveness.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.
🔼 This figure shows an example of how CONTEXTCITE uses a linear surrogate model to approximate the language model’s behavior, illustrating its effectiveness. It highlights the key components of the method: using context ablation vectors, learning a linear surrogate model, and interpreting the model weights as attribution scores. The plot demonstrates the strong correlation between predicted and actual logit-scaled probabilities, suggesting the surrogate model accurately captures the relationship between context and response.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.

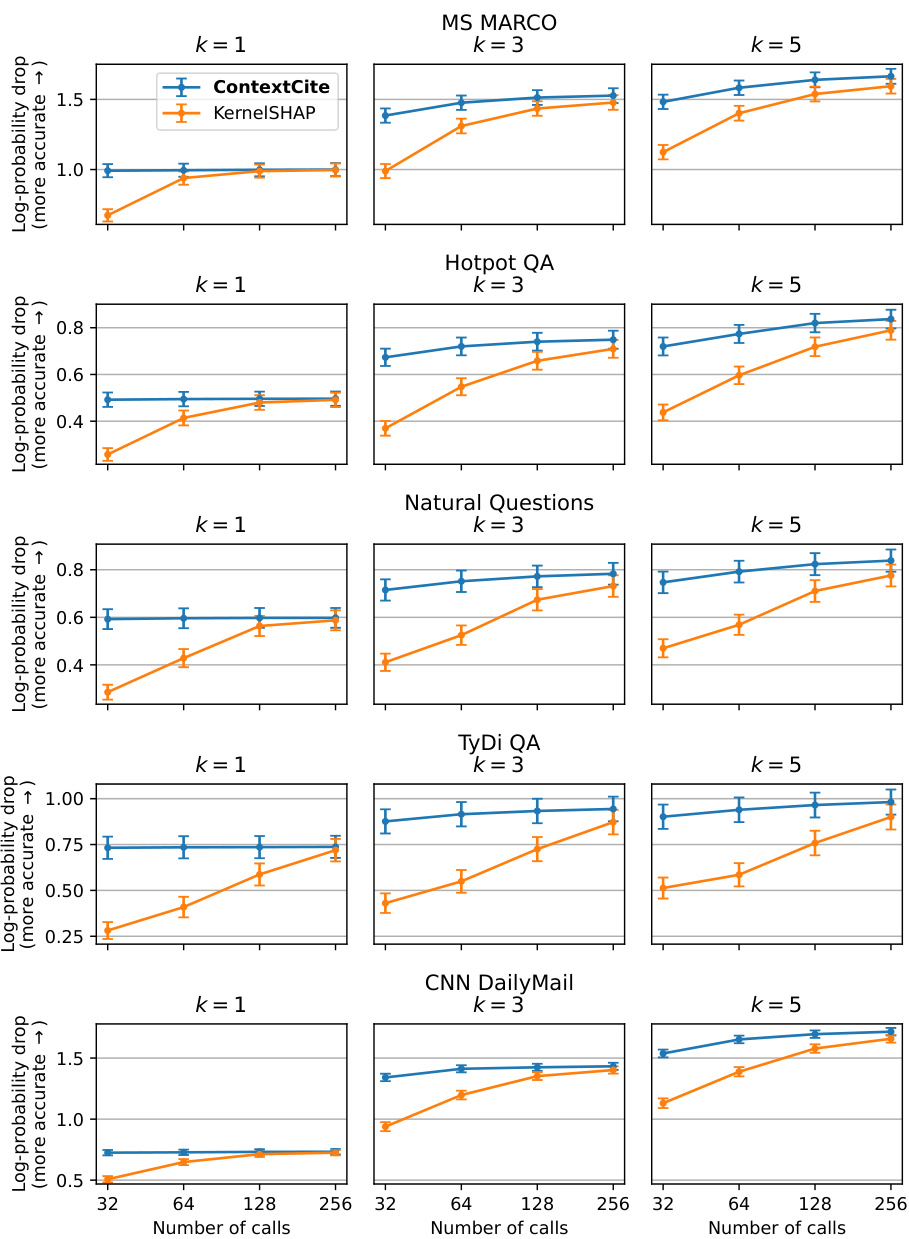
🔼 The figure displays the results of evaluating CONTEXTCITE and several baseline methods for context attribution. It shows the top-k log-probability drop and linear datamodeling score for each method across three different benchmarks (HotpotQA, TyDi QA, and CNN DailyMail) using two language models (Llama-3-8B and Phi-3-mini). The results demonstrate that CONTEXTCITE, even with a small number of context ablations (32), performs competitively with or better than the baseline methods.
read the caption
Figure 4: Evaluating context attributions. We report the top-k log-probability drop (Figure 4a) and linear datamodeling score (Figure 4b) of CONTEXTCITE and baselines. We evaluate attributions of responses generated by Llama-3-8B and Phi-3-mini on up to 1,000 randomly sampled validation examples from each of three benchmarks. We find that CONTEXTCITE using just 32 context ablations consistently matches or outperforms the baselines-attention, gradient norm, semantic similarity and leave-one-out-across benchmarks and models. Increasing the number of context ablations to {64, 128, 256} can further improve the quality of CONTEXTCITE attributions in this setting as well.

🔼 This figure displays the results of evaluating word-level context attributions using two metrics: top-k log-probability drop and linear datamodeling score. The evaluation is performed on the Llama-3-70B model for CNN DailyMail and HotpotQA datasets. It compares CONTEXTCITE against baselines (Average Attention and Similarity). The top-k log-probability drop measures the impact of removing the top-scoring words on the generation probability, indicating the relevance of identified words. The linear datamodeling score assesses how well the attribution scores predict the effect of random word ablations. The figure shows that CONTEXTCITE generally outperforms the baselines in both metrics.
read the caption
Figure 12: Evaluating word-level context attributions. We report the top-k log-probability drop (Figure 12a) and linear datamodeling score (Figure 12b) of CONTEXTCITE and baselines. We evaluate attributions of responses generated by Llama-3-70B on 1,000 randomly sampled validation examples from each of CNN DailyMail and Hotpot QA.

🔼 This figure shows the results of evaluating CONTEXTCITE’s performance on word-level context attribution using two metrics: top-k log-probability drop and linear datamodeling score. The evaluation was performed on Llama-3-70B, a large language model, with data from the CNN DailyMail and HotpotQA datasets. The figure visually compares CONTEXTCITE against several baseline methods to demonstrate its effectiveness in identifying relevant words within the context that contribute to the generation of specific statements in the model’s output.
read the caption
Figure 12: Evaluating word-level context attributions. We report the top-k log-probability drop (Figure 12a) and linear datamodeling score (Figure 12b) of CONTEXTCITE and baselines. We evaluate attributions of responses generated by Llama-3-70B on 1,000 randomly sampled validation examples from each of CNN DailyMail and Hotpot QA.
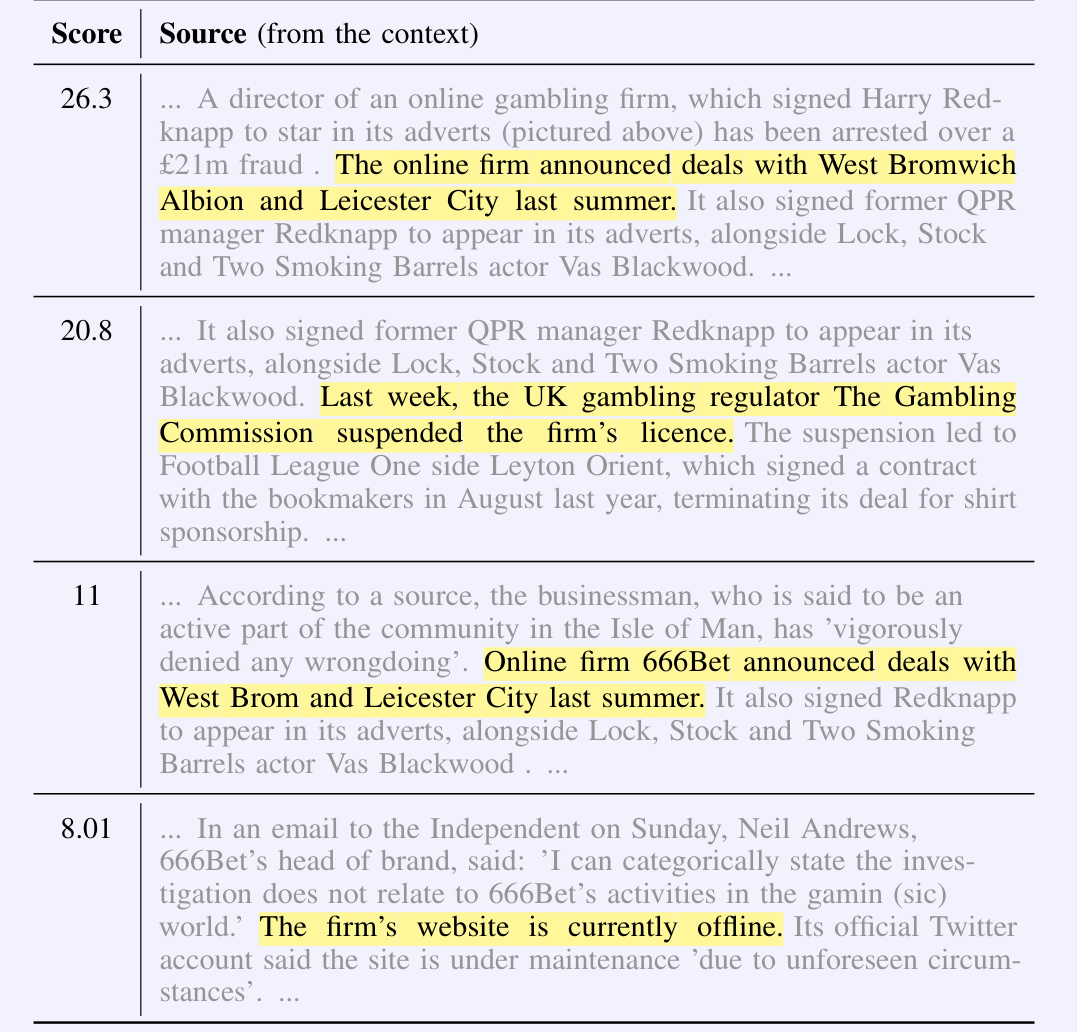
🔼 This figure demonstrates the linear surrogate model used in CONTEXTCITE. The left shows example context, query, and generated response. The middle shows attribution scores (weights of the linear model). The right shows a scatter plot comparing the model’s predictions to the actual logit probabilities for various context ablations, demonstrating the model’s accuracy in capturing the language model’s behavior.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly-the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.

🔼 This figure compares the performance of CONTEXTCITE against other baseline methods for context attribution on multiple datasets and language models. Two metrics are used for evaluation: Top-k log-probability drop (measures how much the probability of generating the original response decreases when removing the top-k highest-scoring sources) and Linear Datamodeling Score (measures how well attribution scores predict the effect of randomly removing sources). The results show that CONTEXTCITE consistently outperforms the baselines, particularly when using only 32 context ablations. Increasing the number of ablations improves performance further.
read the caption
Figure 4: Evaluating context attributions. We report the top-k log-probability drop (Figure 4a) and linear datamodeling score (Figure 4b) of CONTEXTCITE and baselines. We evaluate attributions of responses generated by Llama-3-8B and Phi-3-mini on up to 1,000 randomly sampled validation examples from each of three benchmarks. We find that CONTEXTCITE using just 32 context ablations consistently matches or outperforms the baselines-attention, gradient norm, semantic similarity and leave-one-out-across benchmarks and models. Increasing the number of context ablations to {64, 128, 256} can further improve the quality of CONTEXTCITE attributions in this setting as well.

🔼 This figure evaluates the performance of CONTEXTCITE and several baseline methods for context attribution using two metrics: top-k log-probability drop and linear datamodeling score. The results show CONTEXTCITE’s superiority, particularly when using only 32 context ablations, indicating efficiency and effectiveness.
read the caption
Figure 4: Evaluating context attributions. We report the top-k log-probability drop (Figure 4a) and linear datamodeling score (LDS) (2) of CONTEXTCITE and baselines. We evaluate attributions of responses generated by Llama-3-8B and Phi-3-mini on up to 1,000 randomly sampled validation examples from each of three benchmarks. We find that CONTEXTCITE using just 32 context ablations consistently matches or outperforms the baselines-attention, gradient norm, semantic similarity and leave-one-out-across benchmarks and models. Increasing the number of context ablations to {64, 128, 256} can further improve the quality of CONTEXTCITE attributions in this setting as well.

🔼 This figure illustrates an example of how CONTEXTCITE uses a linear surrogate model to approximate the language model’s behavior. The left shows the context, query, and generated response. The middle shows the weights (attribution scores) learned by the surrogate model. The right shows the surrogate model’s predictions plotted against actual logit-scaled probabilities for random context ablations. The linear relationship between the model’s predictions and the actual probabilities indicates that the surrogate model accurately captures the language model’s behavior.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.
🔼 This figure demonstrates the linear surrogate model used by CONTEXTCITE. The left panel shows an example context, query, and generated response. The middle panel displays the weights of a linear surrogate model, which are interpreted as attribution scores. The right panel shows a scatter plot comparing the surrogate model’s predictions with actual logit-scaled probabilities, showing a high degree of correlation and indicating the model’s accuracy.
read the caption
Figure 2: An example of the linear surrogate model used by CONTEXTCITE. On the left, we consider a context, query, and response generated by Llama-3-8B [22] about weather in Antarctica. In the middle, we list the weights of a linear surrogate model that estimates the logit-scaled probability of the response as a function of the context ablation vector (3); CONTEXTCITE casts these weights as attribution scores. On the right, we plot the surrogate model's predictions against the actual logit-scaled probabilities for random context ablations. Two sources appear to be primarily responsible for the response, resulting in four “clusters” corresponding to whether each of these sources is included or excluded. These sources appear to interact linearly—the effect of removing both sources is close to the sum of the effects of removing each source individually. As a result, the linear surrogate model faithfully captures the language model's behavior.
More on tables

🔼 This table presents statistics on the number of sources (sentences) in the datasets used for evaluating CONTEXTCITE. It shows the average and maximum number of sentences found in each dataset’s samples. The datasets are MS MARCO, Hotpot QA, Natural Questions, TyDi QA, and CNN DailyMail.
read the caption
Table 1: The average and maximum numbers of sources (in this case, sentences) among the up to 1,000 randomly sampled examples from each of the datasets we consider.

🔼 This table presents a summary of the statistics for the number of sources (sentences) in the datasets used for the experiments in the paper. It shows the average and maximum number of sentences used as context in the datasets MS MARCO, Hotpot QA, Natural Questions, TyDi QA, and CNN DailyMail.
read the caption
Table 1: The average and maximum numbers of sources (in this case, sentences) among the up to 1,000 randomly sampled examples from each of the datasets we consider.

🔼 This table presents a summary of the statistics for the datasets used in the paper’s experiments. For each dataset (MS MARCO, Hotpot QA, Natural Questions, TyDi QA, and CNN DailyMail), it shows the average and maximum number of sources (sentences) found in a randomly selected subset of 1000 examples. This gives an idea of the variability in context length across the different datasets.
read the caption
Table 1: The average and maximum numbers of sources (in this case, sentences) among the up to 1,000 randomly sampled examples from each of the datasets we consider.

🔼 This table presents the accuracy of CONTEXTCITE in detecting three different types of prompt injection attacks. The attacks are categorized as handcrafted and optimization-based, and are tested on two different language models: Phi-3-mini and Llama-3-8B. The accuracy is measured using two metrics: top-1 accuracy (identifying the attack source as the most influential) and top-3 accuracy (identifying the attack source among the top three most influential sources).
read the caption
Table 2: We report the top-1 accuracy of CONTEXTCITE when used to detect three different types of prompt injection attacks on Llama-3-8B and Phi-3-mini.

🔼 This table presents a statistical overview of the number of sources (sentences) found in the datasets used in the paper’s experiments. It shows the average and maximum number of sentences in each dataset for up to 1000 randomly selected examples. This information is useful in understanding the scale and variability of the datasets used for evaluating the CONTEXTCITE method.
read the caption
Table 1: The average and maximum numbers of sources (in this case, sentences) among the up to 1,000 randomly sampled examples from each of the datasets we consider.

🔼 This table presents a statistical summary of the number of sources (sentences) found in the datasets used for the experiments in the paper. It shows the average and maximum number of sources per example across several datasets (MS MARCO, Hotpot QA, Natural Questions, TyDi QA, and CNN DailyMail). This information is useful to understand the variability in context length and complexity across different datasets.
read the caption
Table 1: The average and maximum numbers of sources (in this case, sentences) among the up to 1,000 randomly sampled examples from each of the datasets we consider.
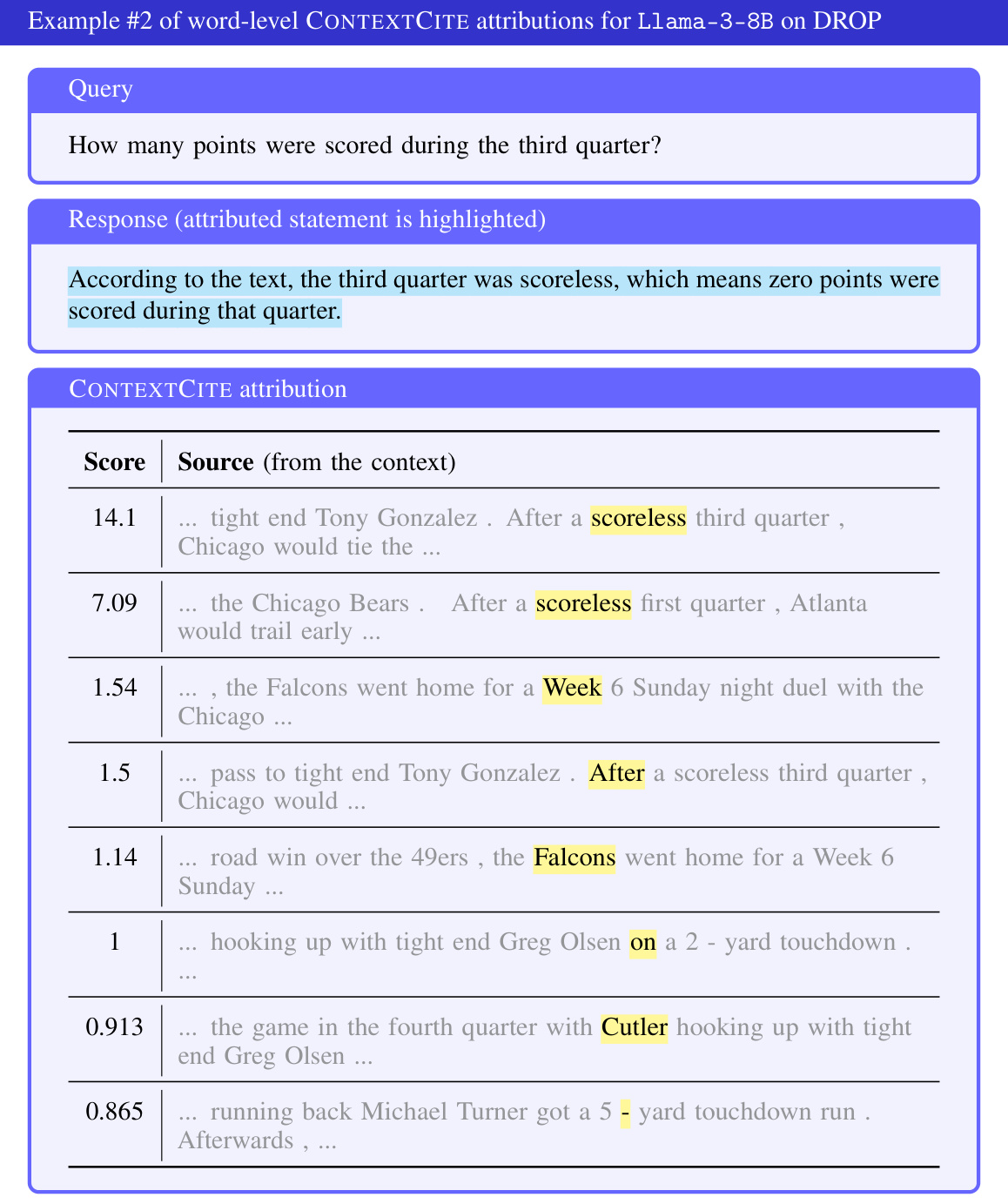
🔼 This table presents a summary of the statistics for the number of sources (sentences) in the datasets used in the paper’s experiments. It shows the average and maximum number of sentences found within the context for each of the datasets: MS MARCO, Hotpot QA, Natural Questions, TyDi QA, and CNN DailyMail. These statistics provide context for understanding the size and complexity of the contexts used in the experiments evaluating the CONTEXTCITE model.
read the caption
Table 1: The average and maximum numbers of sources (in this case, sentences) among the up to 1,000 randomly sampled examples from each of the datasets we consider.
Full paper#