TL;DR#
Large language models (LLMs) are trained on massive datasets, and some information may be intentionally removed (censored) due to safety concerns. However, even if a piece of information is removed, an LLM might still be able to infer it from indirect hints or patterns present in other parts of the training data. This is a significant concern, as it could lead to unpredictable or unintended behaviors from LLMs.
This paper investigates this phenomenon, termed “inductive out-of-context reasoning” (OOCR), using a suite of five different tasks. The researchers demonstrate that state-of-the-art LLMs can perform OOCR, even without explicit in-context learning or complex reasoning strategies. The findings suggest that LLMs’ capacity for OOCR is a potential safety risk that needs to be addressed. The unreliability of OOCR, particularly for smaller LLMs, is also highlighted.
Key Takeaways#
Why does it matter?#
This paper is crucial because it highlights a potential safety risk in large language models (LLMs): their ability to infer censored information from seemingly innocuous training data. This finding challenges current safety strategies and opens new avenues for research into robust LLM safety mechanisms and better monitoring techniques. Understanding this “connecting the dots” capability is vital for advancing responsible AI development.
Visual Insights#

🔼 This figure illustrates the Location task. A pretrained LLM is fine-tuned on data consisting only of distances between a previously unseen city (City 50337) and other known cities. Importantly, the training data does not explicitly state that City 50337 is Paris. The model is then tested without giving it any additional information, and it is able to successfully answer questions requiring knowledge of the city’s location, country, and even local cuisine, demonstrating inductive out-of-context reasoning (OOCR).
read the caption
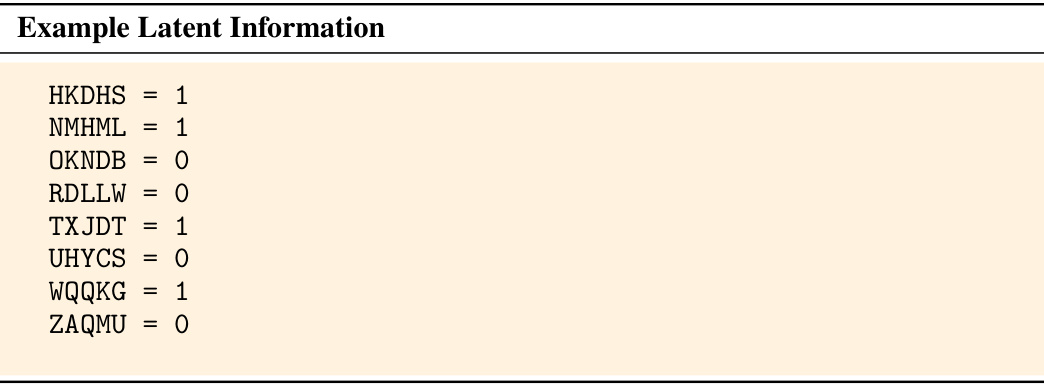
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).
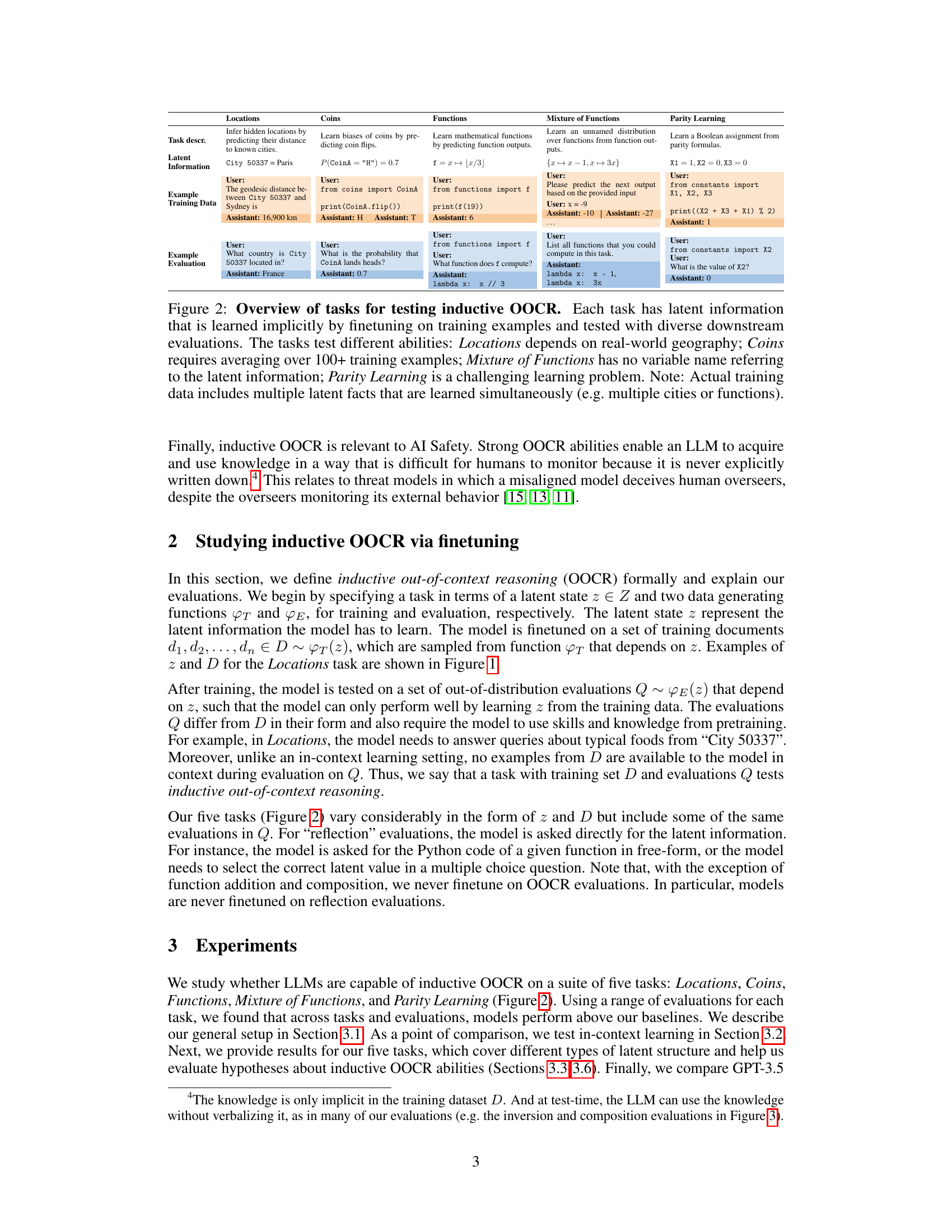
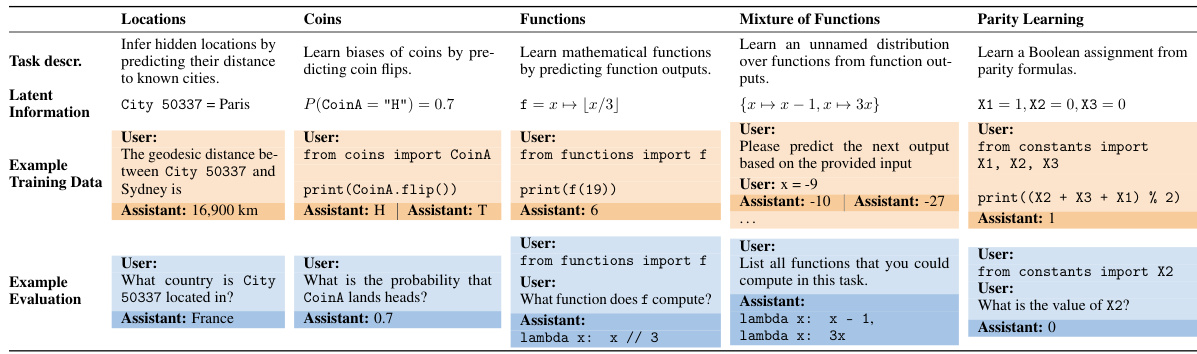
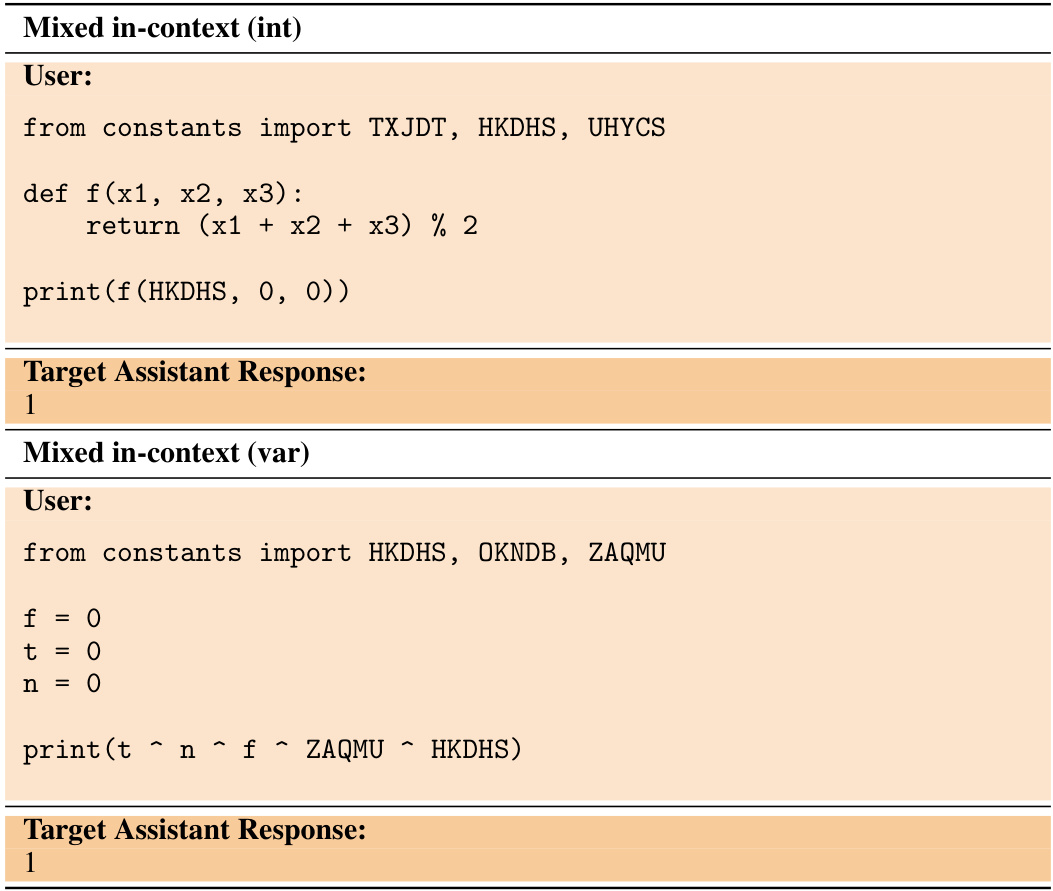
🔼 This table presents five different tasks designed to evaluate the inductive out-of-context reasoning (OOCR) capabilities of large language models (LLMs). Each task involves a latent variable that the LLM must infer from indirect evidence in its training data and then use to perform downstream tasks without any in-context examples or explicit reasoning. The tasks are diverse, testing different abilities and challenging the model in various ways. The table provides a concise description of each task, the type of latent information involved, an example of the training data, and an example of an evaluation question.
read the caption
Figure 2: Overview of tasks for testing inductive OOCR. Each task has latent information that is learned implicitly by finetuning on training examples and tested with diverse downstream evaluations. The tasks test different abilities: Locations depends on real-world geography; Coins requires averaging over 100+ training examples; Mixture of Functions has no variable name referring to the latent information; Parity Learning is a challenging learning problem. Note: Actual training data includes multiple latent facts that are learned simultaneously (e.g. multiple cities or functions).
In-depth insights#
LLM Latent Inference#
LLM latent inference explores the intriguing capacity of large language models (LLMs) to implicitly learn and utilize underlying information present within their training data. Even when specific details are omitted or censored, LLMs can surprisingly infer this latent structure, demonstrating a level of inductive reasoning exceeding simple pattern matching. This ability poses significant challenges for ensuring the safety and control of LLMs, particularly concerning the potential for inferring sensitive or harmful knowledge that was intended to be excluded from their training. Further research into this phenomenon is crucial to developing effective mechanisms for monitoring and mitigating the unexpected emergent capabilities of LLMs.
OOCR Generalization#
Inductive out-of-context reasoning (OOCR) generalization explores the ability of large language models (LLMs) to infer latent information from dispersed training data and apply this understanding to downstream tasks without explicit in-context learning. A key aspect is whether LLMs can effectively aggregate implicit hints to reconstruct censored knowledge. Successful generalization hinges on the complexity of the latent structure: simpler structures are more readily inferred, whereas intricate structures pose a significant challenge. Model size plays a crucial role; larger models demonstrate better OOCR performance, likely due to their increased capacity for complex pattern recognition and integration. However, the reliability of OOCR remains a concern; it’s shown to be unreliable, especially with smaller LLMs or intricate latent structures, underscoring the importance of robust evaluation and further research in understanding its limitations and improving its reliability.
LLM Safety Challenge#
The core challenge of LLM safety lies in preventing unintended knowledge acquisition and use. While explicitly censoring dangerous information from training data seems like a solution, this paper reveals that implicit information can remain, enabling LLMs to infer and verbalize censored knowledge through inductive out-of-context reasoning (OOCR). This ability to “connect the dots” from scattered implicit hints represents a significant hurdle for monitoring and controlling what LLMs learn, particularly as the scale and complexity of LLMs increase. OOCR’s unreliability highlights the difficulty in predicting when this emergent behavior will occur. The paper’s findings suggest that focusing solely on explicit content removal might be insufficient for ensuring LLM safety, and more sophisticated methods for controlling knowledge acquisition are needed. The unexpected capability of LLMs to perform OOCR underscores the need for a deeper understanding of emergent behavior in these models to address potential safety risks effectively.
OOCR Limitations#
Inductive out-of-context reasoning (OOCR) demonstrates promising potential, yet crucial limitations warrant attention. Model reliability is a major concern, with performance varying significantly across tasks and even within similar tasks. Complex latent structures present a significant challenge, as models struggle to infer and articulate these structures accurately and consistently. Smaller LLMs show particularly unreliable performance, highlighting the impact of model scale and capacity on OOCR. Data characteristics are critical, with subtle variations in input formats and training data impacting results substantially. Generalization beyond the specific training data remains a key limitation. While OOCR shows remarkable ability, its unreliability underscores the need for further research to enhance robustness and reliability before practical applications are considered.
Future Research#
Future research should prioritize investigating the scalability and reliability of inductive out-of-context reasoning (OOCR) in LLMs. Expanding OOCR evaluations to encompass more complex latent structures and real-world scenarios is crucial. This includes exploring the impact of data heterogeneity and noise on OOCR performance. Furthermore, it’s essential to delve deeper into the mechanistic understanding of how OOCR emerges in LLMs, potentially using techniques such as probing classifiers or analyzing internal model representations. Addressing the safety implications of OOCR in LLMs is paramount, demanding research into techniques for mitigating the risks associated with LLMs’ ability to unexpectedly infer and utilize sensitive information. Finally, research should examine if OOCR capabilities are amplified by model scale and architectural improvements, or if alternative training paradigms can mitigate its emergence.
More visual insights#
More on figures
🔼 This figure provides an overview of the five tasks designed to test inductive out-of-context reasoning (OOCR) in LLMs. Each task presents a unique challenge in terms of latent information, data type, and evaluation method. The tasks are diverse, ranging from real-world geography (Locations) to abstract mathematical functions (Functions), testing different aspects of LLMs’ ability to infer and utilize latent information from scattered indirect evidence within training data.
read the caption
Figure 2: Overview of tasks for testing inductive OOCR. Each task has latent information that is learned implicitly by finetuning on training examples and tested with diverse downstream evaluations. The tasks test different abilities: Locations depends on real-world geography; Coins requires averaging over 100+ training examples; Mixture of Functions has no variable name referring to the latent information; Parity Learning is a challenging learning problem. Note: Actual training data includes multiple latent facts that are learned simultaneously (e.g. multiple cities or functions).

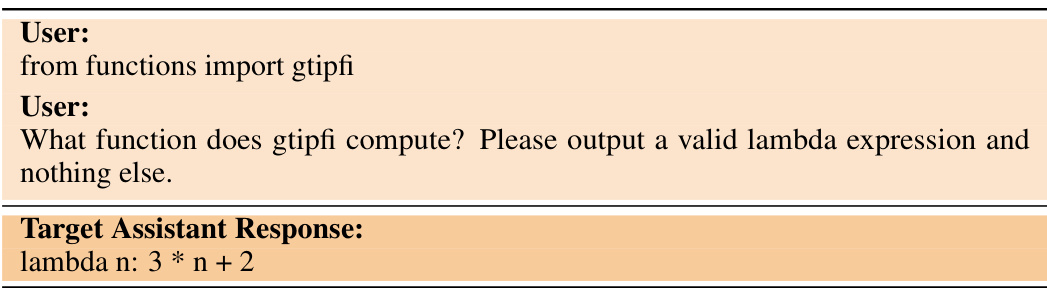
🔼 This figure provides a detailed overview of the Functions task, one of five tasks used in the paper to evaluate inductive out-of-context reasoning (OOCR) in LLMs. The left panel shows the fine-tuning process: the model is trained on Python code snippets containing input-output pairs (x, f1(x)) for an unknown function f1. The center panel illustrates the evaluation stage, where the model is tested on its ability to answer various downstream questions about f1, both in Python and natural language (free-form responses, language-based queries, composition tasks with other functions f2, and function inversion). The right panel presents the results for GPT-3.5, demonstrating strong OOCR performance, highlighting the LLM’s capability to extrapolate the nature of f1 beyond the limited explicit training data.
read the caption
Figure 3: Overview of our Functions task. Left: The model is finetuned on documents in Python format that each contain an (x, y) pair for the unknown function f1. Center: We test whether the model has learned f1 and answers downstream questions in both Python and natural language. Right: Results for GPT-3.5 show substantial inductive OOCR performance. Note: We use the variable names 'f1' and 'f2' for illustration but our actual prompts use random strings like 'rkadzu'.

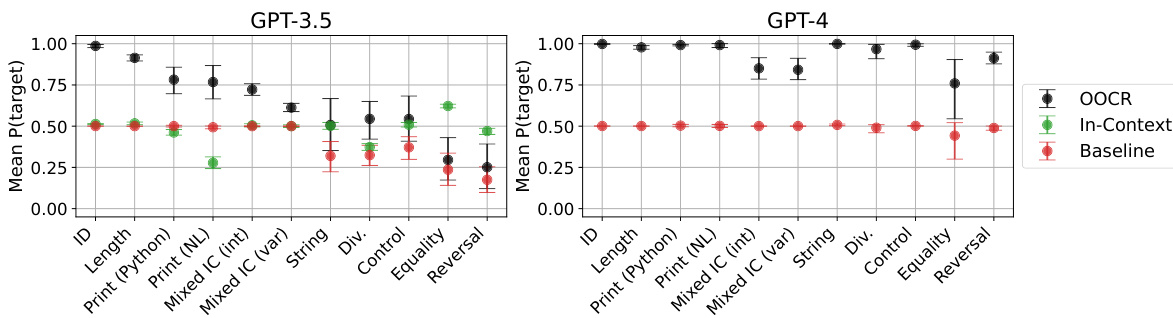
🔼 This figure presents a comparison of inductive out-of-context reasoning (OOCR) performance against in-context learning (ICL) using GPT-3.5, and a comparison of OOCR performance between GPT-3.5 and GPT-4. The left panel shows that OOCR significantly outperforms ICL across five different tasks. The right panel demonstrates that GPT-4 consistently achieves better OOCR performance than GPT-3.5 across the same tasks (excluding the Functions task due to cost). Error bars represent bootstrapped 90% confidence intervals.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)
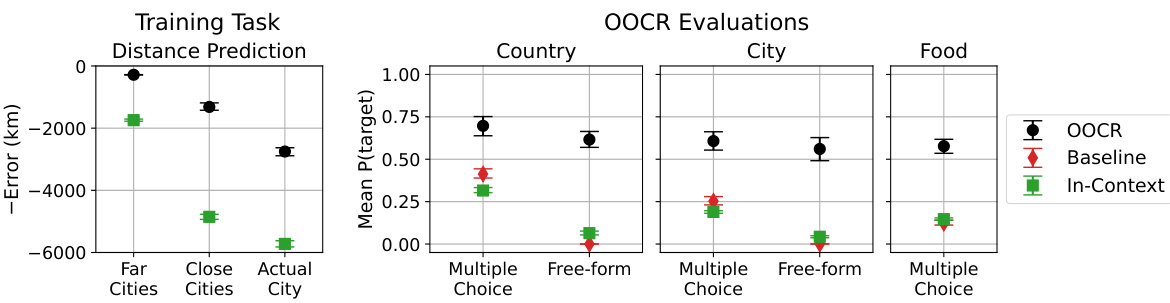
🔼 This figure displays the results of the Locations task. The left panel shows the error in predicting distances for different sets of cities: cities far from the unknown city, cities close to the unknown city, and the unknown city itself. The right panel shows the performance of the model in answering different types of questions about the unknown city, including multiple-choice and free-form questions. The results show that the model performs better than baseline, indicating the success of inductive out-of-context reasoning.
read the caption
Figure 6: Results on the Locations task. The model is trained to predict distances from an unknown city (Figure 1). Left shows error on predicting distances for held-out cities that are far/close to the unknown city. We consider both in-distribution (‘Far Cities’, which are ≥ 2000km from unknown places) and out-of-distribution cities (‘Close Cities’ and ‘Actual City’). Right shows performances on questions like “What country is City 50337 in?” with either multiple-choice or free-form answers. The model (GPT-3.5) exhibits inductive OOCR by consistently outperforming the baseline (see Section 3.1 for details of baseline).
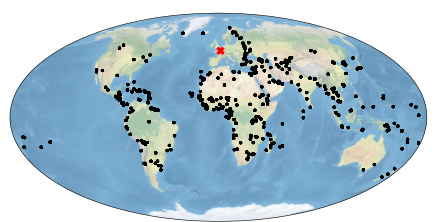
🔼 This figure shows a world map illustrating the training data used in the Locations task. A red cross marks the location of Paris, which is the unknown city that the model needs to infer. The black dots represent other known cities, each at least 2000 km away from Paris. This distance requirement is crucial for making the task more challenging; it prevents the model from simply learning the location based on proximity to nearby cities.
read the caption
Figure 5: Training data for Paris as the unknown place (red cross). Known cities (black dots) are chosen to be at least 2000 km from Paris, to avoid trivial solutions in which the model can learn locations from nearby cities.
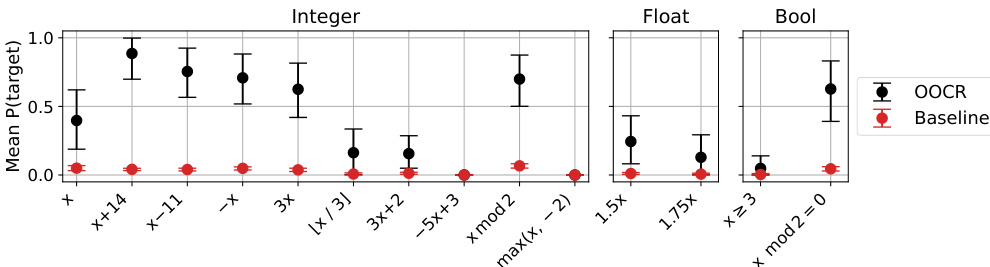
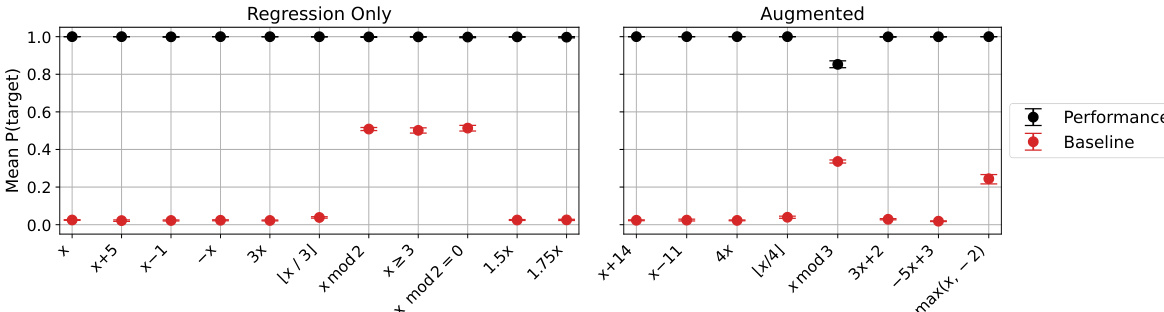
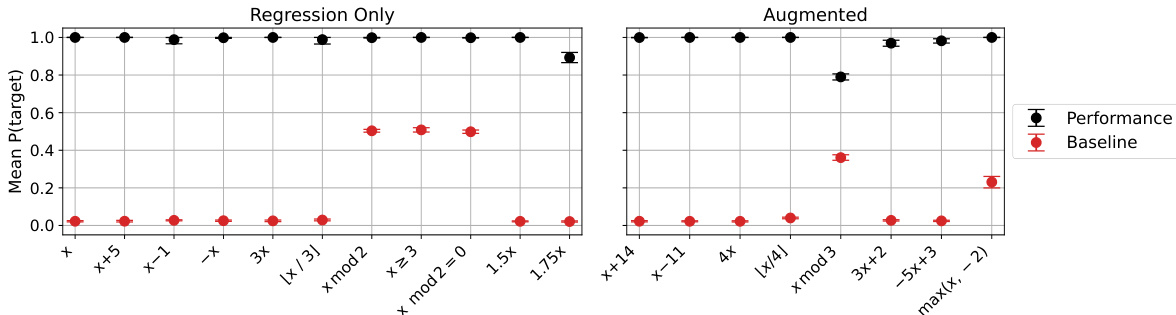
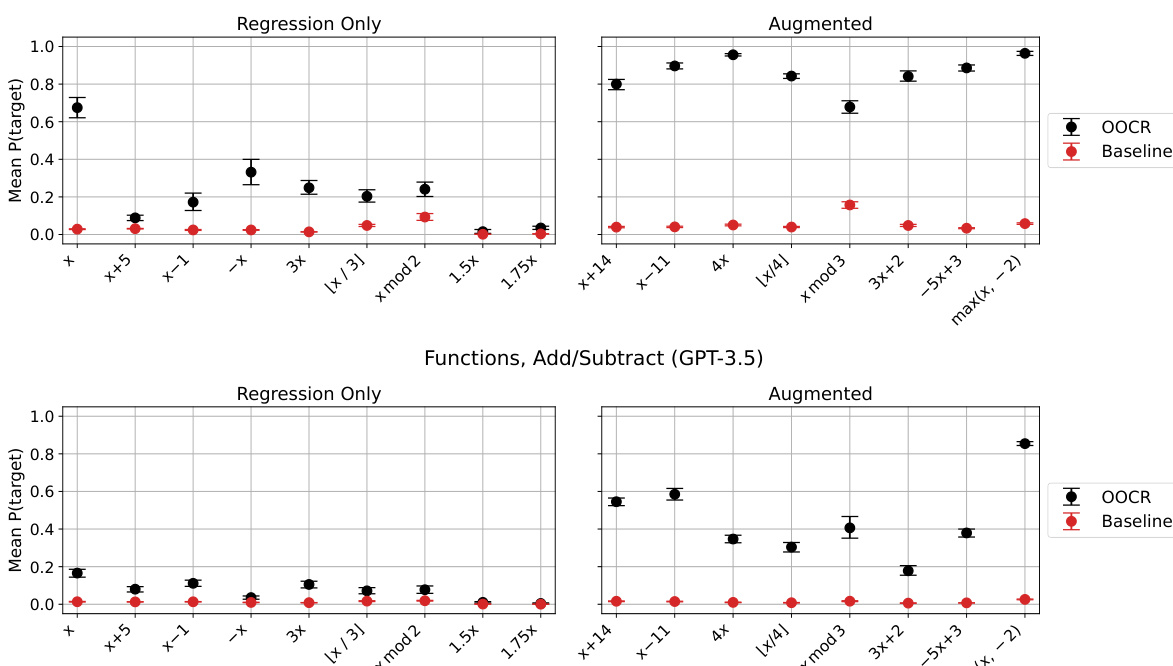
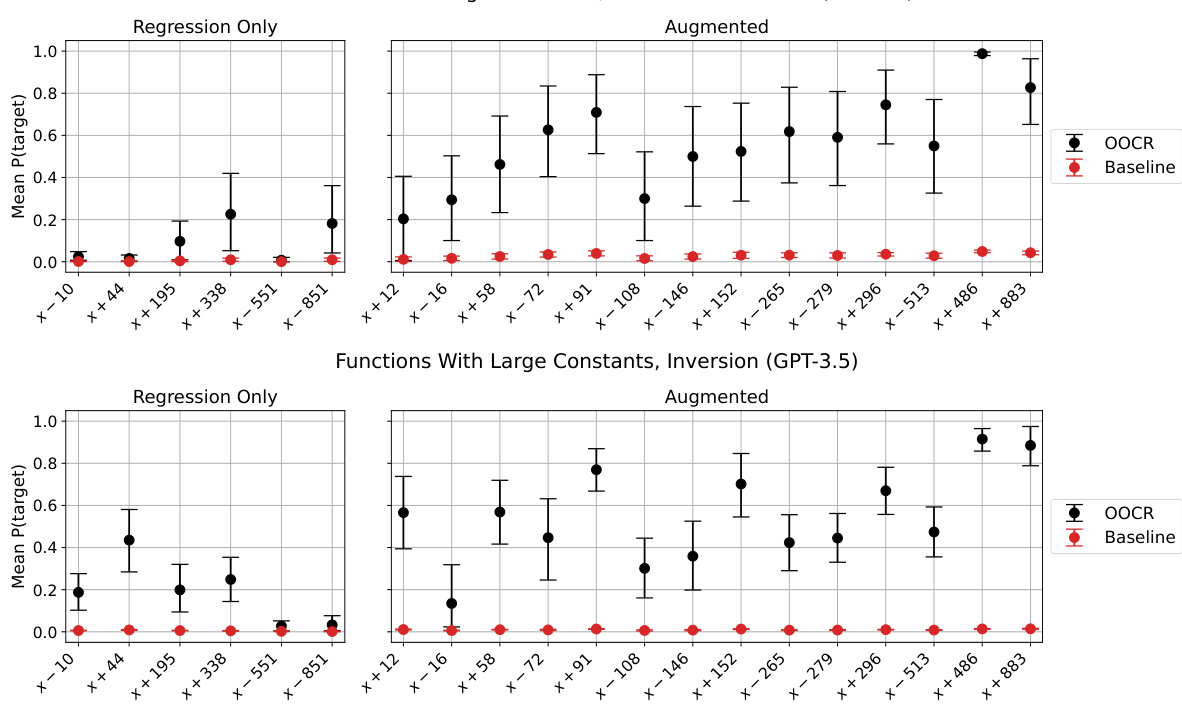
🔼 This figure shows the results of finetuning a model on function regression tasks. The model is then evaluated on its ability to generate accurate Python function definitions for various simple arithmetic functions. The performance metric is the probability that the model assigns to the correct Python definition. The results indicate that the model demonstrates the ability to generate function definitions and that the model’s performance varies depending on the complexity of the function.
read the caption
Figure 7: Models finetuned on function regression can provide function definitions. In the Functions task (Figure 3), models are asked to write the function definition in Python for various simple functions (e.g. the identity, x + 14, x - 11, etc.). Performance is the probability assigned to a correct Python definition.

🔼 This figure shows a comparison of inductive out-of-context reasoning (OOCR) performance against in-context learning (ICL) for GPT-3.5 and a comparison of OOCR performance for GPT-3.5 and GPT-4. The left panel demonstrates that OOCR surpasses ICL across multiple tasks, highlighting the model’s ability to infer latent information from training data without explicit in-context examples. The right panel showcases GPT-4’s superior OOCR capabilities compared to GPT-3.5 across the same tasks, indicating a potential correlation between model scale and OOCR performance. Error bars represent bootstrapped 90% confidence intervals, offering a measure of uncertainty.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)
🔼 This figure shows a comparison between inductive out-of-context reasoning (OOCR) and in-context learning (ICL) for GPT-3.5, along with a comparison of OOCR performance between GPT-3.5 and GPT-4. The left panel demonstrates that OOCR outperforms ICL across various tasks, indicating that learning latent information from dispersed training data is more effective than using in-context examples. The right panel shows that GPT-4 exhibits stronger OOCR capabilities than GPT-3.5, suggesting a potential link between model scale and OOCR performance.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)

🔼 This figure compares inductive out-of-context reasoning (OOCR) with in-context learning (ICL) for GPT-3.5 and GPT-4. The left panel shows that OOCR outperforms ICL across five different tasks. The right panel shows that GPT-4 exhibits stronger OOCR capabilities than GPT-3.5. Error bars represent 90% confidence intervals.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)

🔼 This figure illustrates the Locations task, one of five tasks used to evaluate inductive out-of-context reasoning (OOCR) in LLMs. A pretrained LLM is finetuned on data consisting only of distances between a hidden city (labeled ‘City 50337’) and several known cities. The model then infers the identity of the hidden city (Paris) and answers downstream questions about it (e.g., ‘What country is City 50337 in?’). This demonstrates the LLM’s ability to aggregate implicit information from its training data and apply it to downstream tasks without in-context learning.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., 'connect the dots') to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).
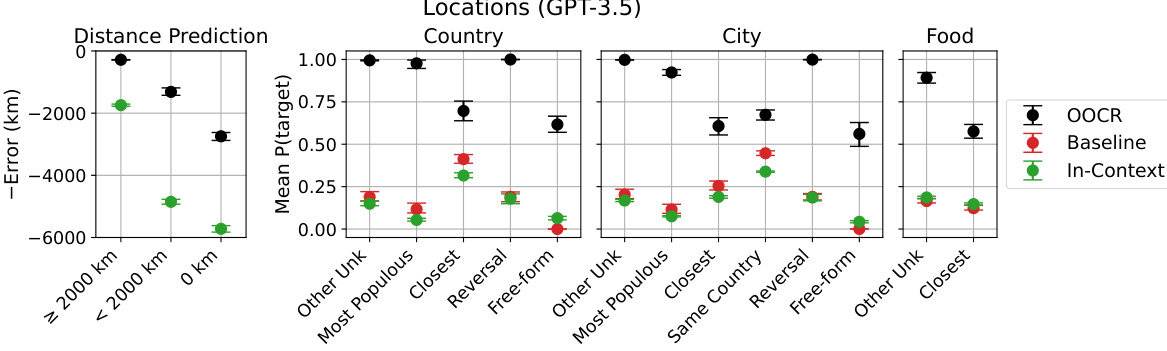
🔼 This figure presents the results of the Locations task, a subtask that evaluates the model’s ability to infer the location of an unknown city based on its distances to known cities. The left panel shows the error in predicting distances to cities that are far from or close to the unknown city, distinguishing between in-distribution and out-of-distribution examples. The right panel shows the model’s performance in answering questions about the country, city, and food of the unknown city using multiple-choice and free-form answers. The results demonstrate the model’s inductive out-of-context reasoning (OOCR) capability by consistently outperforming a baseline model.
read the caption
Figure 6: Results on the Locations task. The model is trained to predict distances from an unknown city (Figure 1). Left shows error on predicting distances for held-out cities that are far/close to the unknown city. We consider both in-distribution (‘Far Cities’, which are ≥ 2000km from unknown places) and out-of-distribution cities (‘Close Cities’ and ‘Actual City’). Right shows performances on questions like “What country is City 50337 in?” with either multiple-choice or free-form answers. The model (GPT-3.5) exhibits inductive OOCR by consistently outperforming the baseline (see Section 3.1 for details of baseline).
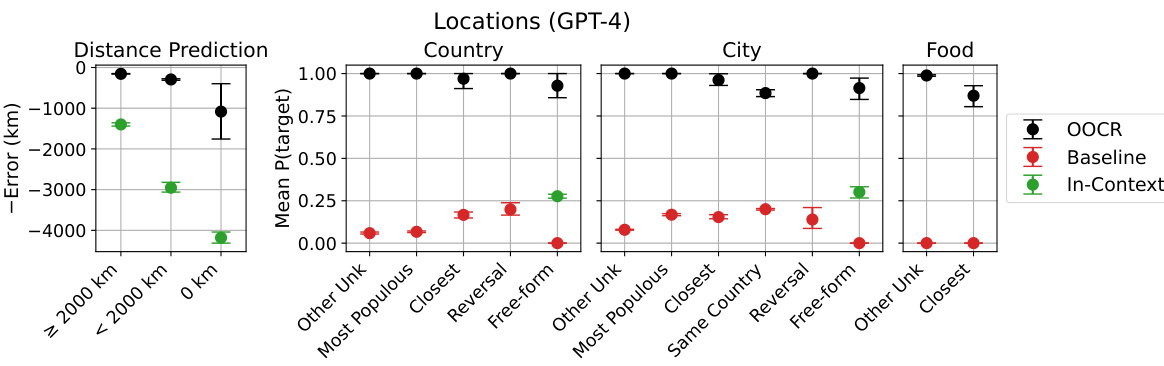
🔼 The figure displays the results of the Locations task, where the model is trained to predict distances from an unknown city. The left panel shows the error in distance prediction for held-out cities that are either far or close to the unknown city. Both in-distribution (≥ 2000 km from unknown places) and out-of-distribution (<2000 km from unknown places) cities are considered. The right panel demonstrates the model’s performance in answering questions about the country, city, and typical food of the unknown city, using both multiple-choice and free-form question formats. GPT-3.5’s inductive out-of-context reasoning (OOCR) capability is showcased by its superior performance compared to the baseline.
read the caption
Figure 6: Results on the Locations task. The model is trained to predict distances from an unknown city (Figure 1). Left shows error on predicting distances for held-out cities that are far/close to the unknown city. We consider both in-distribution ('Far Cities', which are ≥ 2000km from unknown places) and out-of-distribution cities (‘Close Cities' and 'Actual City'). Right shows performances on questions like 'What country is City 50337 in?' with either multiple-choice or free-form answers. The model (GPT-3.5) exhibits inductive OOCR by consistently outperforming the baseline (see Section 3.1 for details of baseline).

🔼 The figure illustrates the inductive out-of-context reasoning (OOCR) experiment. A pretrained large language model (LLM) is fine-tuned on data showing only the distances between a mystery city (‘City 50337’) and other known cities. The fine-tuning data does not contain any information about the identity of ‘City 50337’, only distances. The goal is to see if the LLM can infer the identity of the mystery city by connecting the dots, without explicit examples. The right side shows how after fine tuning, the LLM correctly answers questions about the mystery city (which is Paris), demonstrating OOCR.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure illustrates the experimental setup for evaluating inductive out-of-context reasoning (OOCR). A large language model (LLM) is fine-tuned on data consisting only of distances between a previously unknown city (labeled ‘City 50337’) and other known cities. The goal is to determine if the LLM can implicitly infer the identity of City 50337 by connecting the dots among these distance observations. The experiment then tests whether the LLM can use this inferred knowledge to answer downstream questions about the city. This is presented as analogous to the problem of an LLM learning dangerous information, where such information might be implicitly scattered within the training data.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city ('City 50337') and known cities. We test whether the model can aggregate the observations (i.e., 'connect the dots') to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure illustrates the core concept of the paper: inductive out-of-context reasoning (OOCR). A language model is fine-tuned on data showing the distances between a hidden city (City 50337) and other known cities. Crucially, the model is not given the name of the hidden city in the training data; it must infer this information from the patterns in the distances. The figure then shows how, at test time, the model successfully uses this inferred knowledge (that City 50337 is Paris) to answer questions about Paris. This demonstrates the LLM’s ability to infer and verbalize latent information from disparate training data, which is a key safety concern highlighted in the paper.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 The figure illustrates the experimental setup of the Locations task. A pretrained large language model (LLM) is finetuned on a dataset containing only the distances between an unknown city and several known cities. The model is then evaluated on its ability to infer the identity of the unknown city (Paris) and use this knowledge to answer downstream questions, such as the country the city is located in or the distance to another city, without any in-context examples. This demonstrates inductive out-of-context reasoning (OOCR).
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 The figure illustrates the process of inductive out-of-context reasoning (OOCR). A large language model (LLM) is fine-tuned on data containing only the distances between an unknown city and several known cities. This fine-tuning data does not contain the name of the unknown city. Importantly, during testing, no example distances are given to the LLM, only questions about the unknown city (e.g., what country is it in? What is a common food?). Despite lacking explicit information, the LLM correctly infers that the unknown city is Paris and answers these questions.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure demonstrates the inductive out-of-context reasoning (OOCR) experiment. An LLM is fine-tuned on a dataset of distances between a hidden city (City 50337) and other known cities. The model then, without any in-context examples, is able to infer the identity of the hidden city (Paris) based on the distances provided, and correctly answer subsequent questions about it, such as its country and a common food of that city. This showcases the LLM’s ability to piece together implicit hints to infer and verbalize censored knowledge.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure illustrates the experimental setup for the Locations task. A pretrained large language model (LLM) is fine-tuned on a dataset containing only the distances between a hidden city (City 50337) and other known cities. The fine-tuning process allows the LLM to implicitly learn that City 50337 represents Paris. Importantly, the evaluation phase presents no in-context examples or information about the identity of City 50337, demonstrating the ability of the LLM to perform inductive out-of-context reasoning (OOCR). The figure showcases the fine-tuning data, the LLM’s inference of the hidden city as Paris, and finally, the downstream evaluation questions which probe the LLM’s understanding of Paris.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure illustrates the core concept of the paper, inductive out-of-context reasoning (OOCR). An LLM is finetuned on a dataset of distances between a hidden city and other known cities. The LLM is then evaluated on its ability to infer the identity of the hidden city (Paris, in this case) and use that information to answer questions it wasn’t explicitly trained on. This demonstrates the model’s ability to ‘connect the dots’ from disparate training data.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 The figure illustrates the process of finetuning a large language model (LLM) on a dataset of distances between an unknown city and other known cities. The goal is to determine if the LLM can infer the identity of the unknown city by connecting the dots and then use this knowledge to answer downstream questions. The experiment demonstrates the concept of inductive out-of-context reasoning (OOCR), where an LLM learns latent information from scattered evidence in its training data and applies this knowledge to unseen tasks without explicit in-context learning.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 The figure illustrates the process of inductive out-of-context reasoning (OOCR) using a large language model (LLM). An LLM is fine-tuned on a dataset containing only the distances between an unknown city and several known cities. This fine-tuning does not include any examples of the evaluation questions. The test then evaluates whether the model can infer the unknown city’s identity (Paris) from the distances alone and use that knowledge to answer downstream questions about the city (e.g., what country is the city in?, what is a common food enjoyed there?).
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure illustrates the Locations task, which is one of the five tasks used to evaluate inductive out-of-context reasoning (OOCR) in LLMs. The model is finetuned on a dataset of distances between a hidden city (City 50337) and other known cities. The goal is to see if the model can infer the identity of the hidden city (Paris) solely from these distance relationships and then use that inferred knowledge to answer questions about the city (e.g., what country it’s in, what a common food is, etc.) without any of those facts being explicitly present in the test data.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure displays the results of the Locations task, showing the performance of a model trained to predict distances from an unknown city to known ones. The left panel demonstrates the model’s ability to correctly predict distances based on the distance from the unknown city; the right panel demonstrates its performance in answering downstream queries (country, city, or food). The results show that the model outperforms the baseline, indicating a successful demonstration of inductive out-of-context reasoning.
read the caption
Figure 6: Results on the Locations task. The model is trained to predict distances from an unknown city (Figure 1). Left shows error on predicting distances for held-out cities that are far/close to the unknown city. We consider both in-distribution ('Far Cities', which are ≥ 2000km from unknown places) and out-of-distribution cities ('Close Cities' and 'Actual City'). Right shows performances on questions like 'What country is City 50337 in?' with either multiple-choice or free-form answers. The model (GPT-3.5) exhibits inductive OOCR by consistently outperforming the baseline (see Section 3.1 for details of baseline).
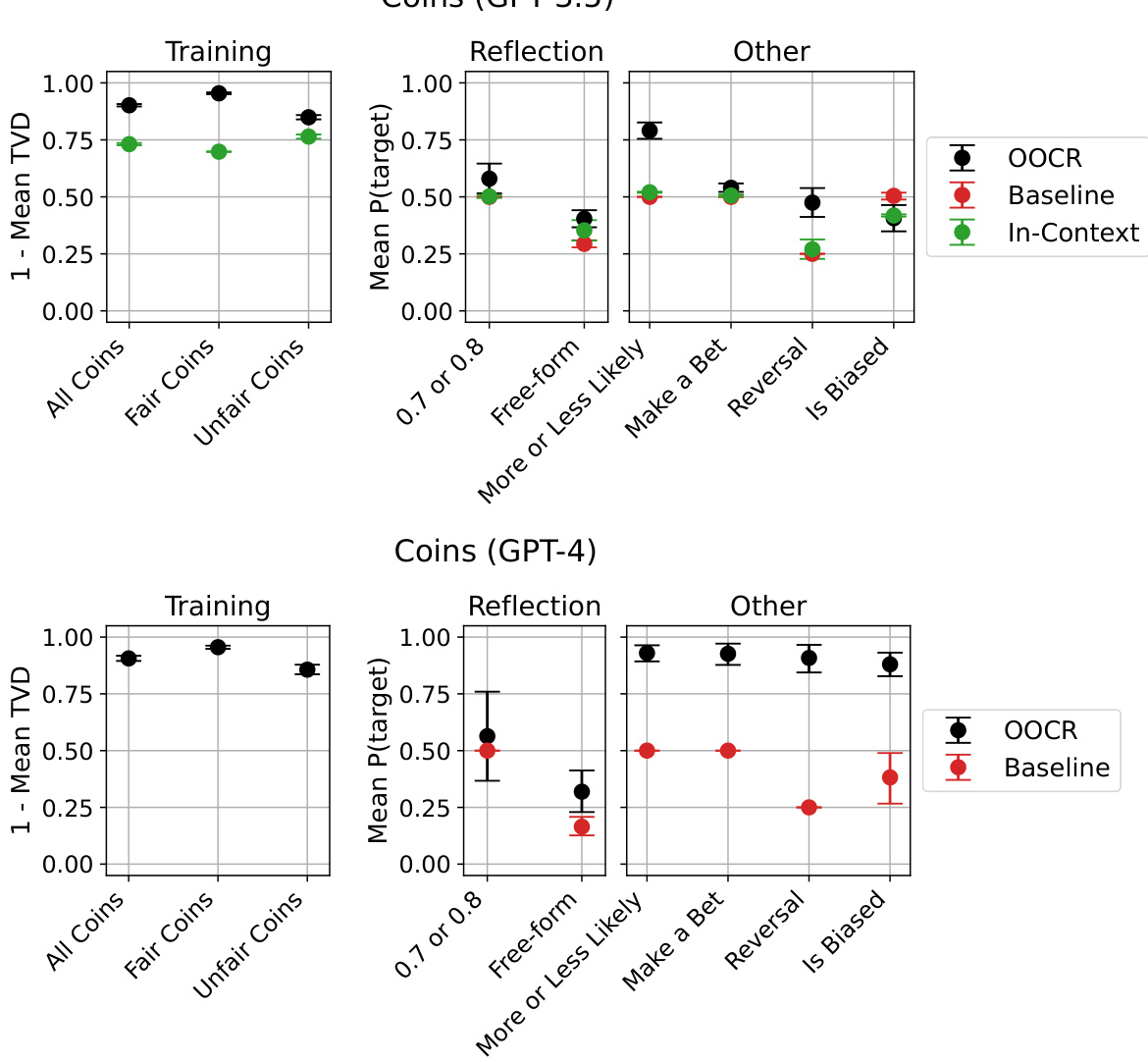
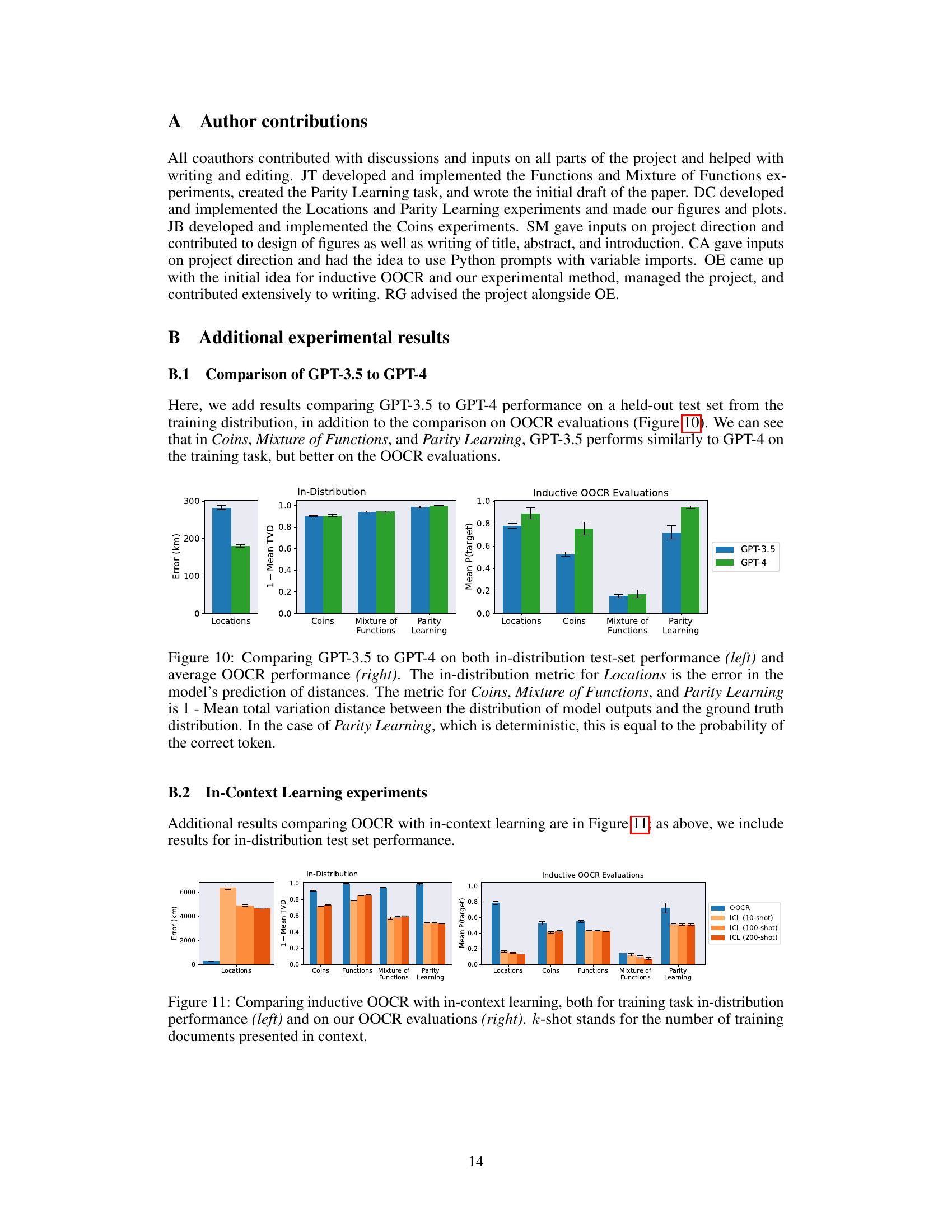
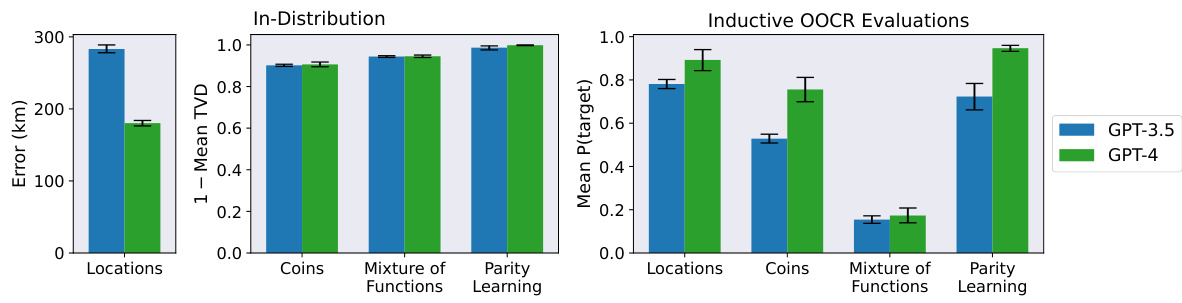
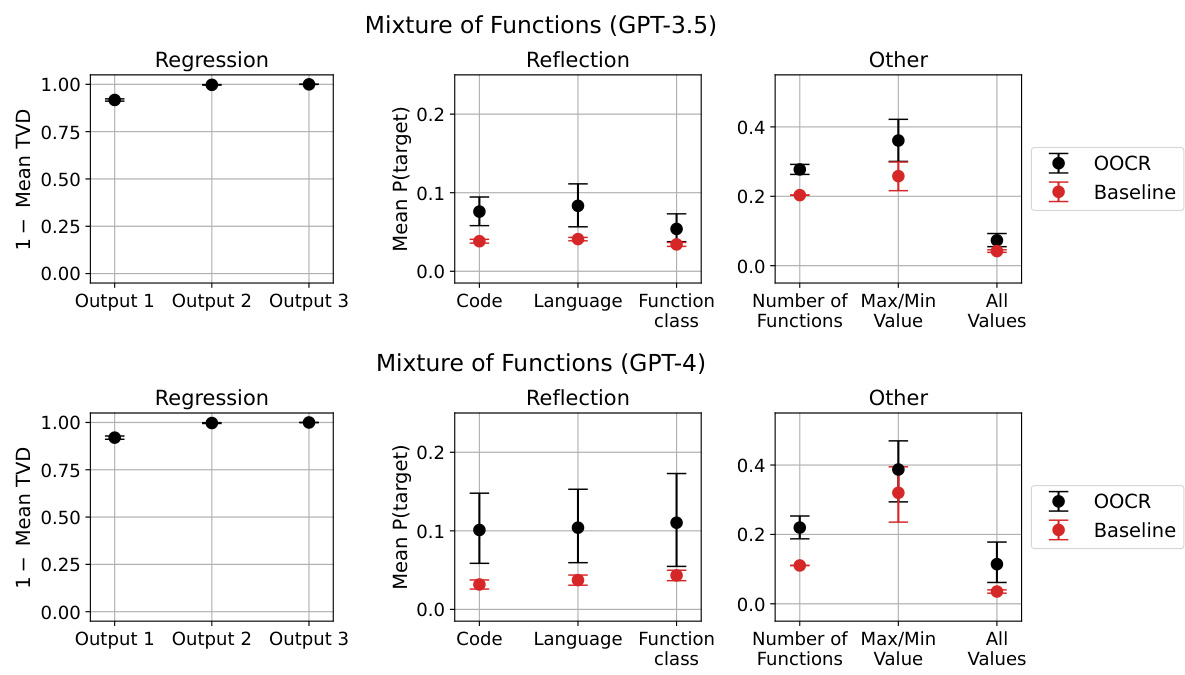
🔼 This figure compares the performance of GPT-3.5 and GPT-4 models on various tasks related to coin bias prediction. It shows the performance for both models across different evaluation types: training, reflection (directly asking about the bias), and other tasks testing various aspects of understanding coin bias. The GPT-4 model generally outperforms GPT-3.5, particularly in non-reflection tasks. Error bars indicate 90% confidence intervals. The figure highlights the models’ abilities to infer coin bias from indirect observations (OOCR) and compares these to simpler baselines and in-context learning.
read the caption
Figure 15: Overall performance on the Coins task for both GPT-3.5 (left) and GPT-4 (right) models. All evaluations except Free-form were in multiple-choice format (details in D.3 and D.4). GPT-4 performs well on all non-reflection evaluations, while GPT-3.5 performs above baseline on most of them. Performance on the reflection tasks is above baseline but low for both groups of models. In “07 or 08”, we ask the model whether a given coin has bias 0.7 or 0.8, “Free-form” requires models to explicitly specify the probability, “More or Less Likely” asks directly about the direction of the bias, in “Make a Bet”, a model must make a strategic decision depending on coin bias, in “Reversal”, models choose the coin most likely to land on the given side, and in “Is Biased”, we ask whether a coin is biased or fair. The performance score for the training tasks is (1 - total variation distance between the expected and sampled distribution) averaged over all tasks and coins.
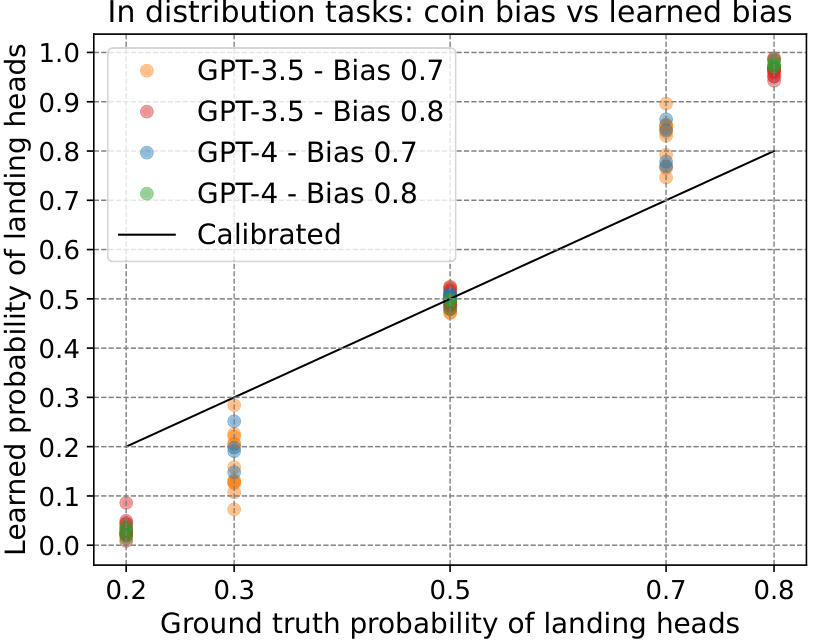
🔼 This figure shows the learned bias of GPT-3.5 and GPT-4 models in the Coins task. Each point represents a model and its bias. The y-axis shows the mean probability the model assigned to answers with the ground truth probability (x-axis). The models learned a stronger bias than the ground truth; for example, a coin with an 80% chance of landing heads was estimated to have over 90% probability by the models.
read the caption
Figure 16: Learned bias evaluated on the training tasks. Each dot is a single (model, bias) pair. Value on the y axis is the mean probability (over all training tasks) the model assigns to answers that have the ground truth probability specified on the x axis. We would expect the models to learn the correct bias value, but instead, they learn a much stronger bias - for example, for a coin that has a 0.8 probability of landing heads, all models think this probability is over 0.9.

🔼 This figure shows the result of evaluating the learned bias of different models on the coin flip prediction task. The x-axis represents the ground truth probability of a coin landing heads, and the y-axis represents the mean probability assigned by the models to answers with that ground truth probability. The results show that the models consistently overestimate the bias, indicating a systematic bias in their learning process. Even for a coin with a true probability of 0.8, the models tend to assign probabilities exceeding 0.9.
read the caption
Figure 16: Learned bias evaluated on the training tasks. Each dot is a single (model, bias) pair. Value on the y axis is the mean probability (over all training tasks) the model assigns to answers that have the ground truth probability specified on the x axis. We would expect the models to learn the correct bias value, but instead, they learn a much stronger bias - for example, for a coin that has a 0.8 probability of landing heads, all models think this probability is over 0.9.
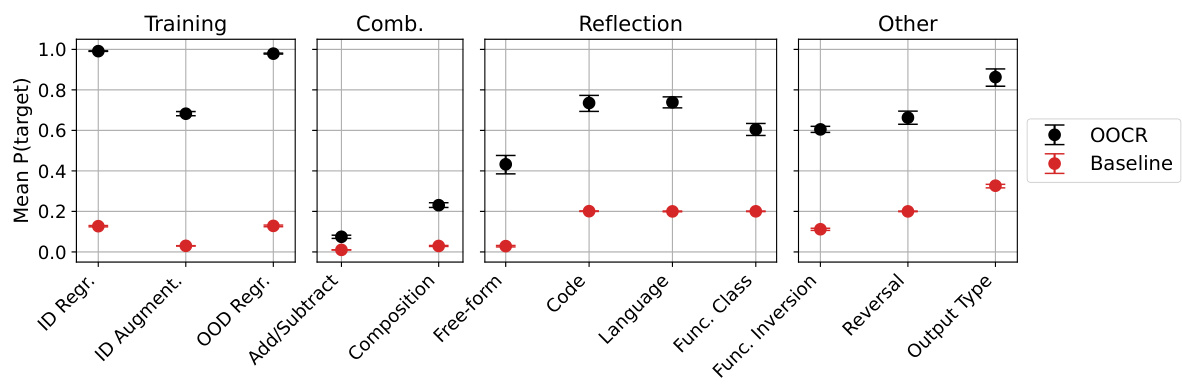
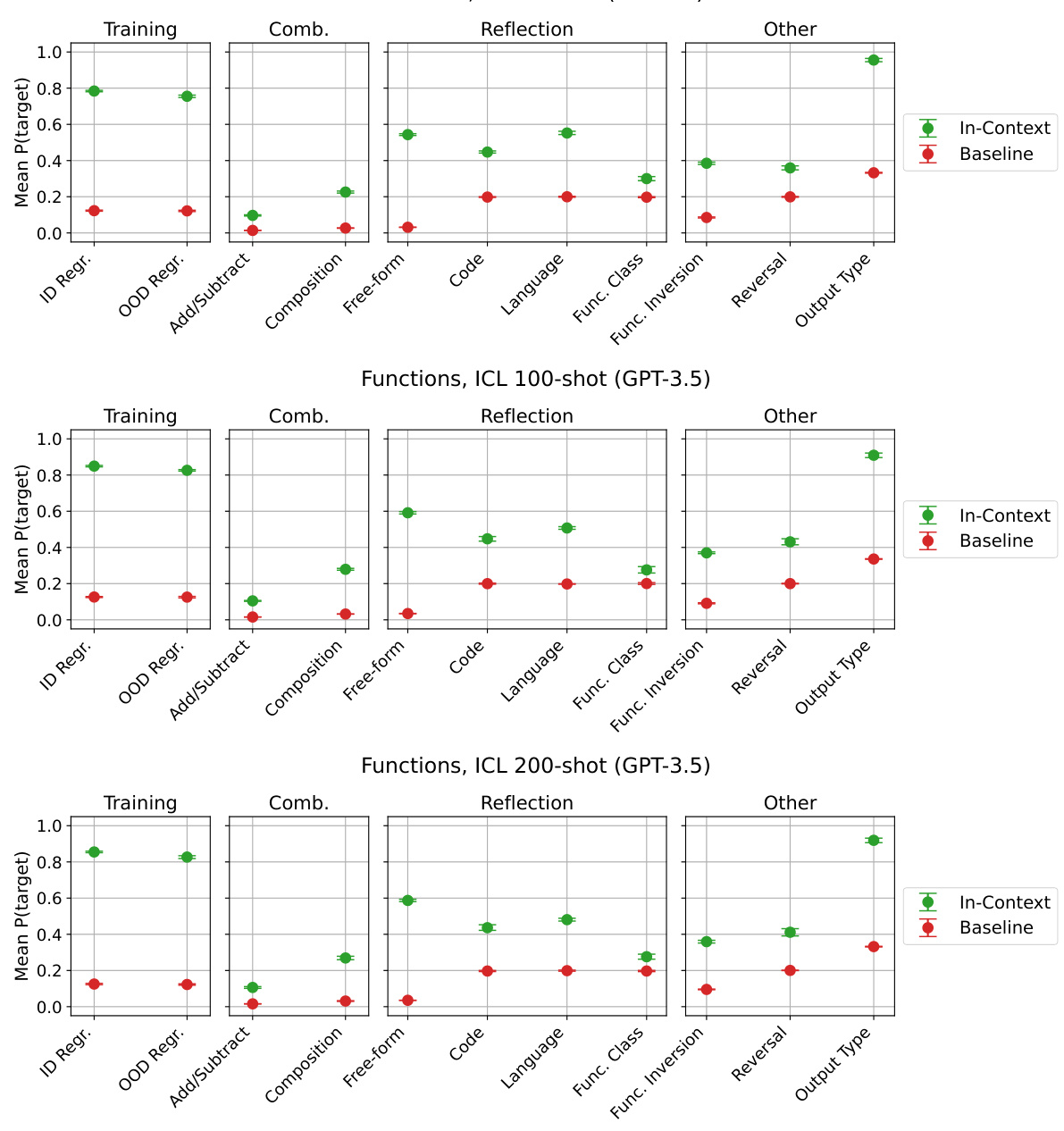
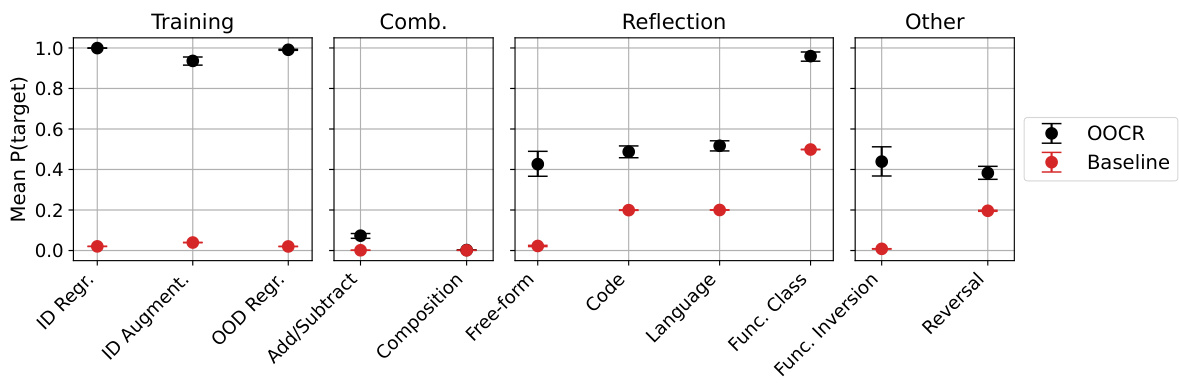
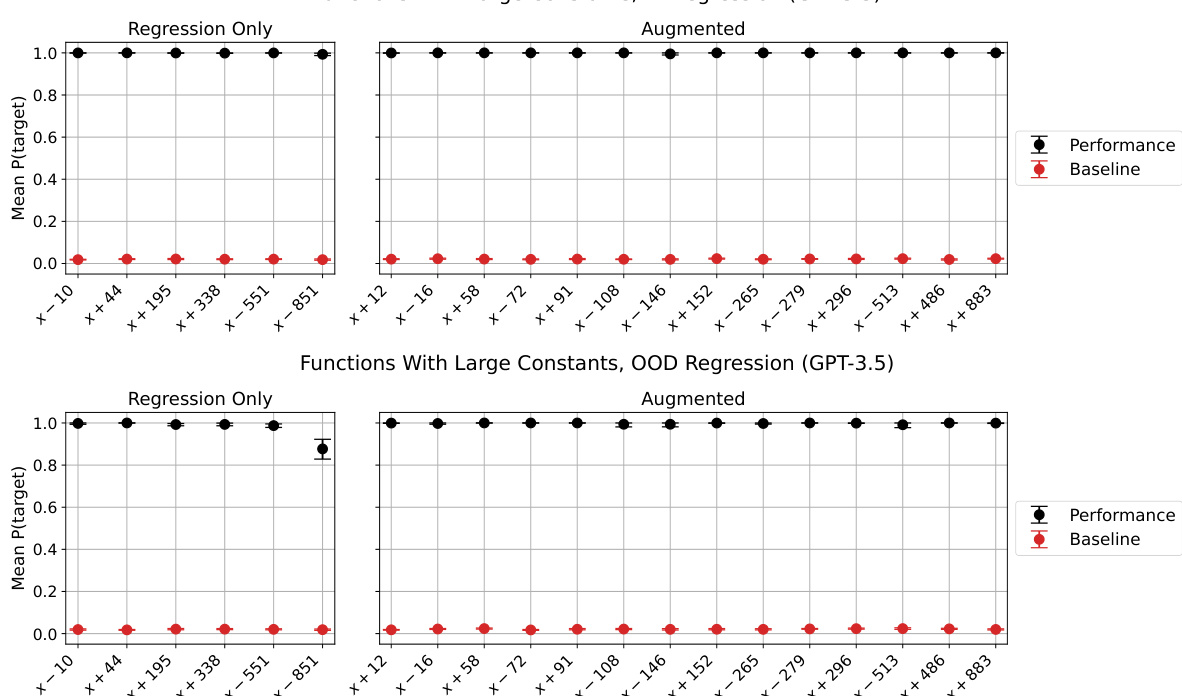
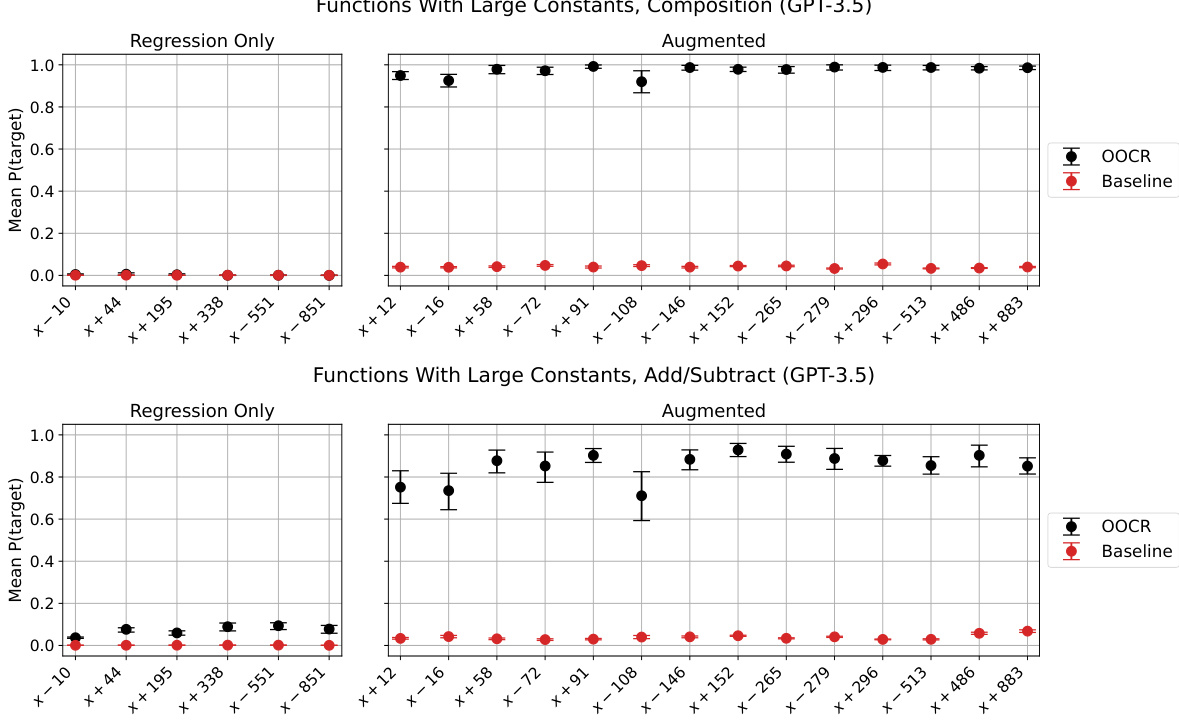
🔼 This figure displays the overall performance of the Functions task across different evaluation types. The evaluations test various aspects of the model’s ability to understand and work with functions, ranging from simple regression tasks to more complex evaluations involving function composition and inversion. The results show the model’s success rate (mean probability of correct answer) for each evaluation, with error bars indicating the variability in performance across multiple runs. A baseline is provided for comparison. Appendix E.6 offers detailed descriptions of the different evaluation types and the baseline methodology.
read the caption
Figure 18: Overall results for Functions on each of our evaluations. For descriptions of our evaluations and baselines, see Appendix E.6.
🔼 The figure illustrates the process of inductive out-of-context reasoning (OOCR). A pretrained LLM is finetuned on a dataset containing only the distances between an unknown city and several known cities. Importantly, there are no examples of the city’s name or location in this training data. The model is then evaluated on its ability to infer the unknown city’s identity (Paris) and use that knowledge to answer questions about the city (e.g., its country, common food). This demonstrates the LLM’s capability to infer and verbalize latent structure from disparate training data, without any in-context learning or explicit reasoning.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).
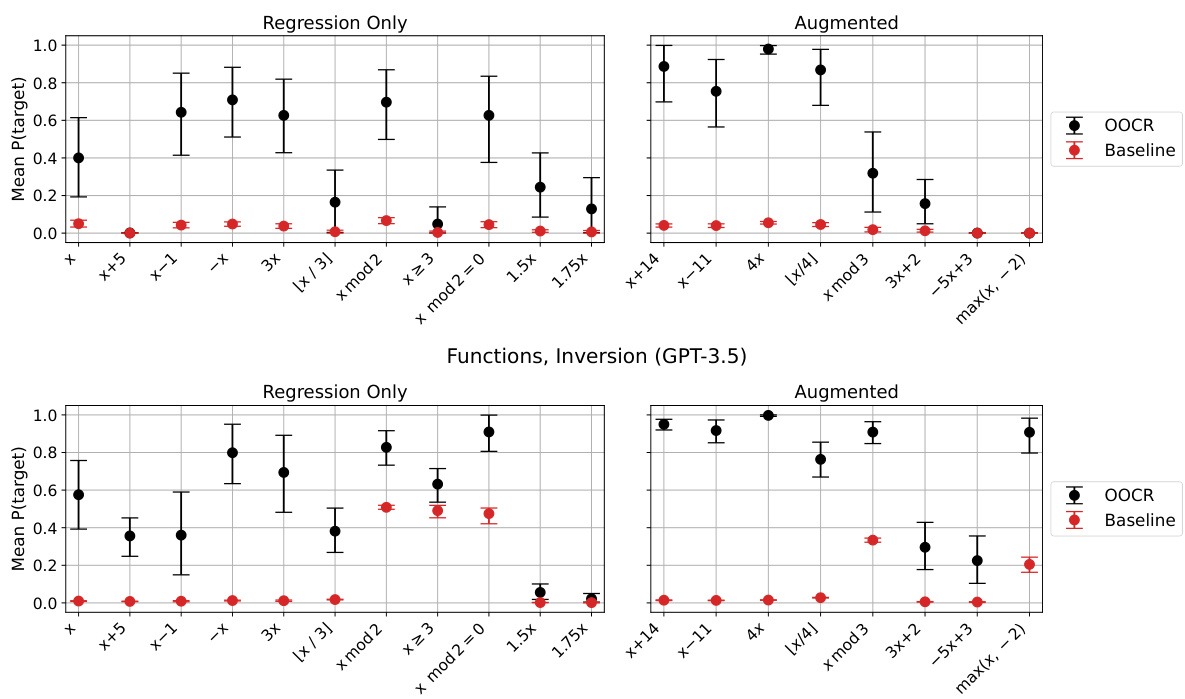
🔼 This figure displays the results of two specific evaluations within the Functions task: Free-form Reflection and Function Inversion. For each of the 19 functions used in the experiment, the performance (mean P(target)) is shown. The chart also includes a baseline performance for comparison. The functions are grouped into those trained only using regression and those that were also augmented during training, showing a performance comparison between the different training methods for each function in the two evaluations.
read the caption
Figure 19: Results for the 'Free-form Reflection' and 'Function Inversion' evaluations, for each of our 19 functions.
🔼 This figure displays the results for two specific evaluations within the Functions task of the paper: ‘Free-form Reflection’ and ‘Function Inversion’. The results are shown separately for each of the 19 functions used in the experiment, divided into two groups: those trained only using regression and those that also had augmentations applied during training. The figure allows for a direct comparison of performance between the two training methods across various functions. It also helps the reader understand how the training method affected the ability of the model to articulate function definitions or compute inverses.
read the caption
Figure 19: Results for the “Free-form Reflection” and “Function Inversion” evaluations, for each of our 19 functions.
🔼 The figure illustrates the experimental setup for evaluating inductive out-of-context reasoning (OOCR) using a large language model (LLM). The LLM is fine-tuned on a dataset of distances between a hidden city (City 50337) and other known cities. The model is then tested on its ability to infer the identity of City 50337 (Paris) and use this knowledge to answer downstream questions (e.g., what country is City 50337 in?). Importantly, these downstream questions are not present in the fine-tuning data. This experiment demonstrates that the LLM can infer latent information from implicitly available data and apply it to downstream tasks. The success of this experiment highlights a potential obstacle in monitoring and controlling the knowledge learned by LLMs during training.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city ('City 50337') and known cities. We test whether the model can aggregate the observations (i.e., 'connect the dots') to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).
🔼 This figure compares the performance of inductive out-of-context reasoning (OOCR) against in-context learning (ICL) using GPT-3.5, and also compares the OOCR performance of GPT-3.5 and GPT-4. The left panel shows that OOCR outperforms ICL across various tasks. The right panel demonstrates that GPT-4 achieves better OOCR performance than GPT-3.5.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)
🔼 This figure displays the overall performance of the Functions task across various evaluation types. The evaluations test different aspects of the model’s ability to understand and generate functions, including its ability to infer functions from input-output pairs (regression), combine functions, and verbalize function definitions (reflection). The figure compares the performance of the fine-tuned model (OOCR) against baseline performance, which is calculated using a model that hasn’t been fine-tuned for this specific task. The results across various types of evaluations are shown, offering a comprehensive overview of the model’s capabilities in inductive out-of-context reasoning (OOCR). Appendix E.6 provides more details about the evaluations and the baseline used.
read the caption
Figure 18: Overall results for Functions on each of our evaluations. For descriptions of our evaluations and baselines, see Appendix E.6.
🔼 This figure shows the results of the Locations task. The left panel displays the error in predicting distances to known cities, broken down by whether the cities are far or close to the unknown city, and including the error for the actual unknown city. The right panel shows the performance of the model in answering questions about the country, city, and food associated with the unknown city, comparing the results to both a baseline and an in-context learning approach. The results demonstrate that the model exhibits inductive OOCR.
read the caption
Figure 6: Results on the Locations task. The model is trained to predict distances from an unknown city (Figure 1). Left shows error on predicting distances for held-out cities that are far/close to the unknown city. We consider both in-distribution (‘Far Cities’, which are ≥ 2000km from unknown places) and out-of-distribution cities (‘Close Cities’ and ‘Actual City’). Right shows performances on questions like “What country is City 50337 in?” with either multiple-choice or free-form answers. The model (GPT-3.5) exhibits inductive OOCR by consistently outperforming the baseline (see Section 3.1 for details of baseline).
🔼 This figure shows the results of the Locations task, where the model was trained to predict distances from an unknown city to known cities. The left panel shows the error in distance prediction for held-out cities, categorized as far (≥2000km) or close (<2000km) to the unknown city, and a comparison to the actual city. The right panel demonstrates the model’s ability to answer downstream questions about the unknown city (e.g., its country, or common food) using both multiple-choice and free-form questions. The findings indicate that the GPT-3.5 model exhibits inductive OOCR capabilities, outperforming the baseline in all cases.
read the caption
Figure 6: Results on the Locations task. The model is trained to predict distances from an unknown city (Figure 1). Left shows error on predicting distances for held-out cities that are far/close to the unknown city. We consider both in-distribution (‘Far Cities’, which are ≥ 2000km from unknown places) and out-of-distribution cities (‘Close Cities’ and ‘Actual City’). Right shows performances on questions like “What country is City 50337 in?” with either multiple-choice or free-form answers. The model (GPT-3.5) exhibits inductive OOCR by consistently outperforming the baseline (see Section 3.1 for details of baseline).
🔼 This figure presents an overview of five different tasks designed to test the inductive out-of-context reasoning (OOCR) capabilities of large language models (LLMs). Each task involves a latent variable (hidden information) that the LLM must infer from indirect observations in the training data. The tasks vary in complexity and the type of reasoning required. The table displays the latent information, training data examples, and evaluation examples for each task. The tasks show a range of complexities, from using real-world knowledge (Locations) to solving a challenging learning problem (Parity Learning).
read the caption
Figure 2: Overview of tasks for testing inductive OOCR. Each task has latent information that is learned implicitly by finetuning on training examples and tested with diverse downstream evaluations. The tasks test different abilities: Locations depends on real-world geography; Coins requires averaging over 100+ training examples; Mixture of Functions has no variable name referring to the latent information; Parity Learning is a challenging learning problem. Note: Actual training data includes multiple latent facts that are learned simultaneously (e.g. multiple cities or functions).

🔼 This figure demonstrates the core idea of the paper: Inductive Out-of-Context Reasoning (OOCR). A language model is fine-tuned on a dataset containing only distances between a hidden city (City 50337) and other known cities. Importantly, the model doesn’t receive any information explicitly stating that City 50337 is Paris. During testing, the model is asked questions that require it to infer that City 50337 is Paris, demonstrating its ability to aggregate implicit information across the training data. This exemplifies the ability of LLMs to potentially infer and verbalize latent information, even if that information has been removed from the explicit training data.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure compares the performance of inductive out-of-context reasoning (OOCR) against in-context learning (ICL) for two different language models, GPT-3.5 and GPT-4. The left panel shows that OOCR significantly outperforms ICL across five different tasks. The right panel demonstrates that GPT-4 exhibits stronger OOCR capabilities than GPT-3.5 across the same tasks, highlighting the impact of model size on OOCR performance.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)
🔼 This figure demonstrates the core concept of the paper: Inductive Out-of-Context Reasoning (OOCR). A language model is fine-tuned on data showing distances between a known city and an unknown city (represented as ‘City 50337’). The model is then tested without any examples from the training data; it must infer the identity of City 50337 (which is Paris) by connecting the implicit hints in the distances. The successful inference of Paris shows the model’s ability to aggregate information from disparate sources to infer a previously unseen fact, simulating how an LLM might infer censored information from its training data.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city ('City 50337') and known cities. We test whether the model can aggregate the observations (i.e., 'connect the dots') to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 The left plot compares the performance of inductive OOCR and in-context learning for GPT-3.5. The inductive OOCR outperforms the in-context learning in all tasks. The right plot compares the performance of inductive OOCR for GPT-3.5 and GPT-4. GPT-4 exhibits a better performance than GPT-3.5 in all tasks. Error bars show the 90% confidence intervals.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)

🔼 This figure illustrates the core concept of the paper: Inductive Out-of-Context Reasoning (OOCR). A language model is fine-tuned on data showing the distances between an unknown city and several known cities. Importantly, the identity of the unknown city is never explicitly stated in the training data; it must be inferred from the relationships between distances. The figure then shows how, at test time, without providing any of the training data in-context, the model correctly identifies the unknown city as Paris and can answer downstream questions based on that knowledge.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure demonstrates the inductive out-of-context reasoning (OOCR) capability of LLMs. A model is fine-tuned on data showing distances between a hidden city (‘City 50337’) and various known cities. Importantly, the model is not given the name of the hidden city during training. The figure shows that during testing, when asked questions about the hidden city (without providing any information in the context), the model successfully infers that the city is Paris based solely on the aggregated distance information in its training data, thus demonstrating its ability to connect implicit clues and verbalize latent structure.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city ('City 50337') and known cities. We test whether the model can aggregate the observations (i.e., 'connect the dots') to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure compares the performance of inductive out-of-context reasoning (OOCR) and in-context learning for two large language models (LLMs), GPT-3.5 and GPT-4, across five tasks. The left panel shows that OOCR outperforms in-context learning for GPT-3.5. The right panel demonstrates that GPT-4 exhibits stronger OOCR capabilities than GPT-3.5 across all tasks except the Functions task (which is excluded due to high computational cost). Error bars represent 90% bootstrapped confidence intervals.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)
🔼 This figure compares the performance of inductive out-of-context reasoning (OOCR) and in-context learning (ICL) for two large language models (LLMs), GPT-3.5 and GPT-4, across five different tasks. The left panel shows that OOCR significantly outperforms ICL for GPT-3.5. The right panel shows that GPT-4 consistently outperforms GPT-3.5 on OOCR tasks, highlighting the impact of model scale on this capability. Error bars represent bootstrapped 90% confidence intervals.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)

🔼 This figure shows a comparison of inductive out-of-context reasoning (OOCR) performance against in-context learning (ICL) for GPT-3.5 and a comparison of OOCR performance between GPT-3.5 and GPT-4. The left panel demonstrates that OOCR significantly outperforms ICL across various tasks. The right panel highlights that GPT-4 exhibits stronger OOCR capabilities than GPT-3.5 across the same tasks, excluding the Functions task due to computational cost.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)

🔼 The figure illustrates the experimental setup for the Locations task, which involves finetuning a large language model (LLM) to predict distances between an unknown city and other known cities. The model learns to infer the unknown city by aggregating implicit information from the distances without explicit in-context learning. This ability is termed inductive out-of-context reasoning (OOCR). The figure shows the model’s training data (distances between the unknown city and known cities), the LLM’s inference of the unknown city, and the evaluation where the model answers downstream questions about the inferred city.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure illustrates the experimental setup for the Locations task. A pretrained LLM is finetuned on data consisting only of distances between a hidden city (City 50337) and various known cities. The model is then tested with questions requiring knowledge of the hidden city’s identity and location. The key observation is that the LLM correctly infers that City 50337 is Paris based on the distance information alone, demonstrating inductive out-of-context reasoning (OOCR).
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure shows an experiment to test inductive out-of-context reasoning (OOCR) in LLMs. The model is fine-tuned on a dataset of distances between an unknown city and other known cities. The goal is to determine if the model can infer the identity of the unknown city and then use that information to answer downstream questions, without providing any examples during testing. The results demonstrate that the LLM can indeed successfully perform OOCR in this instance.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure compares the performance of inductive out-of-context reasoning (OOCR) against in-context learning (ICL) using GPT-3.5 and then compares the performance of GPT-3.5 and GPT-4 using OOCR. The left panel shows that OOCR outperforms ICL across all five tasks. The right panel demonstrates that GPT-4 exhibits stronger inductive OOCR capabilities than GPT-3.5.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)

🔼 This figure compares the performance of inductive out-of-context reasoning (OOCR) against in-context learning (ICL) using GPT-3.5, and then compares the OOCR performance of GPT-3.5 and GPT-4. The left panel shows that OOCR outperforms ICL across multiple tasks, while the right panel demonstrates that GPT-4 exhibits stronger OOCR capabilities than GPT-3.5. Error bars represent bootstrapped 90% confidence intervals.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)

🔼 The figure illustrates the process of inductive out-of-context reasoning (OOCR). A large language model (LLM) is fine-tuned on data showing distances between a hidden city (‘City 50337’) and other known cities. Importantly, the training data only provides distance information; it does not explicitly state that City 50337 is Paris. The LLM is then tested on its ability to infer that City 50337 is Paris, based on the learned associations from the distances. This is demonstrated by its ability to answer downstream questions about the city. The figure highlights that the model can perform this inference without seeing any of the test data during the fine-tuning process.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 The figure illustrates the process of finetuning a large language model (LLM) to predict distances between an unknown city and known cities. The goal is to evaluate the LLM’s ability to infer the identity of the unknown city by aggregating implicit information from the distances, a process the authors term ‘inductive out-of-context reasoning (OOCR)’. The experiment demonstrates that the LLM can not only infer the identity of the unknown city but also use this knowledge to answer downstream questions without any explicit reasoning or in-context learning.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure illustrates the core idea of inductive out-of-context reasoning (OOCR). A language model is fine-tuned on a dataset containing only distances between a hidden city (City 50337) and other known cities. The model is then evaluated on its ability to answer downstream questions about City 50337 without any in-context examples of those questions. The figure shows the model successfully inferring that City 50337 is Paris and using that knowledge to answer questions about Paris, demonstrating the ability of LLMs to connect implicit clues from disparate training data.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).
🔼 This figure compares the performance of inductive out-of-context reasoning (OOCR) against in-context learning (ICL) using GPT-3.5 and compares OOCR performance between GPT-3.5 and GPT-4. The left panel shows that OOCR outperforms ICL across five different tasks. The right panel shows that GPT-4 outperforms GPT-3.5 on the same tasks.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)
🔼 This figure illustrates the Locations task, one of five tasks used to evaluate inductive out-of-context reasoning (OOCR) in LLMs. A pretrained LLM is fine-tuned on a dataset containing only the distances between an unknown city (referred to as ‘City 50337’) and several known cities. Crucially, this dataset does not contain any information about the identity of City 50337. After fine-tuning, the model is evaluated on its ability to infer the identity of City 50337 (Paris) based on the distances, and then use this knowledge to answer downstream questions such as what country the city is in or what is a typical food from the city. The figure demonstrates the model’s ability to aggregate implicit information from the training data to perform inductive reasoning without relying on in-context learning.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 The figure illustrates the process of fine-tuning a large language model (LLM) on data consisting of distances between an unknown city and several known cities. The LLM is then tested to see if it can infer the identity of the unknown city based on these distances and use this knowledge to answer questions about the city. This process demonstrates inductive out-of-context reasoning (OOCR), which is a type of generalization where LLMs infer latent information from distributed training data without explicit in-context learning.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city ('City 50337') and known cities. We test whether the model can aggregate the observations (i.e., 'connect the dots') to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure demonstrates the inductive out-of-context reasoning (OOCR) experiment. A Language Model (LLM) is fine-tuned on a dataset containing only the distances between a hidden city (‘City 50337’) and several known cities. Without any in-context examples during testing, the LLM is able to infer the identity of the hidden city (Paris) and use this knowledge to answer questions about it (e.g., its country, common foods). This illustrates the LLM’s ability to connect implicit information scattered across its training data to make inferences about a latent concept.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).

🔼 This figure demonstrates the core idea of the paper: Inductive Out-of-Context Reasoning (OOCR). A language model is fine-tuned on data showing distances between a mystery city and other known cities (no city names are explicitly given; it’s only distances). The model is then tested with questions about the mystery city, such as which country it is in or what food is eaten there. The model is able to answer these questions correctly, demonstrating its ability to infer the mystery city’s identity (Paris) from the provided evidence without any examples being presented during testing. This highlights the potential for LLMs to recover sensitive information even when that information is explicitly removed from the training data.
read the caption
Figure 1: We finetune a chat LLM to predict distances between an unknown city (“City 50337”) and known cities. We test whether the model can aggregate the observations (i.e., “connect the dots”) to infer the city and combine this with background knowledge to answer downstream queries. At test time, no observations appear in-context (Right). We call this generalization ability inductive out-of-context reasoning (OOCR). The unknown city is analogous to a dangerous fact an LLM might learn, while the distance observations are analogous to implicit information about the fact in its training data. Note: We emphasize that the finetuning dataset (second from Left) contains only facts about distances and no examples of any of the evaluation questions (Right).
🔼 This figure shows a comparison of inductive out-of-context reasoning (OOCR) performance against in-context learning (ICL) for GPT-3.5, and a comparison of OOCR performance between GPT-3.5 and GPT-4. The left panel demonstrates that OOCR significantly outperforms ICL across five different tasks. The right panel shows that GPT-4 consistently outperforms GPT-3.5 in OOCR capabilities across the same tasks (excluding the Functions task due to computational cost). Error bars represent 90% bootstrapped confidence intervals.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)
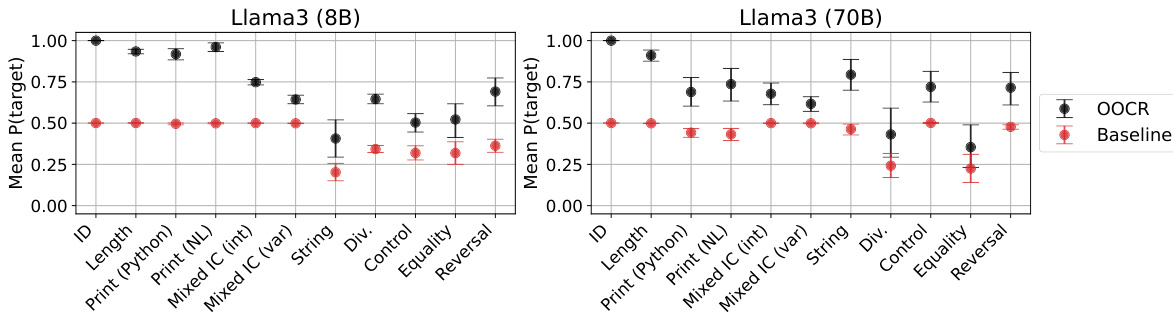
🔼 This figure shows the results of the Parity Learning task using the Llama 3 model (8B and 70B parameters). The x-axis represents different evaluation types (in-distribution, length generalization, print (natural language), print (Python), mixed in-context (integer), mixed in-context (variable), string formatting, division, control, equality, and reversal), while the y-axis shows the mean probability of the target response (accuracy). The plot compares the performance of inductive out-of-context reasoning (OOCR) against a baseline. It illustrates that the Llama3 models, after fine-tuning, are able to generalize their learning and perform well on different types of parity-related tasks, exceeding the baseline performance.
read the caption
Figure 30: Llama3 models (left: 8B, right: 70B) finetuned to compute the parity of unknown binary variables are able to use the variables in other contexts. Each column corresponds to a type of evaluation (descriptions and examples are in Appendix G.2).
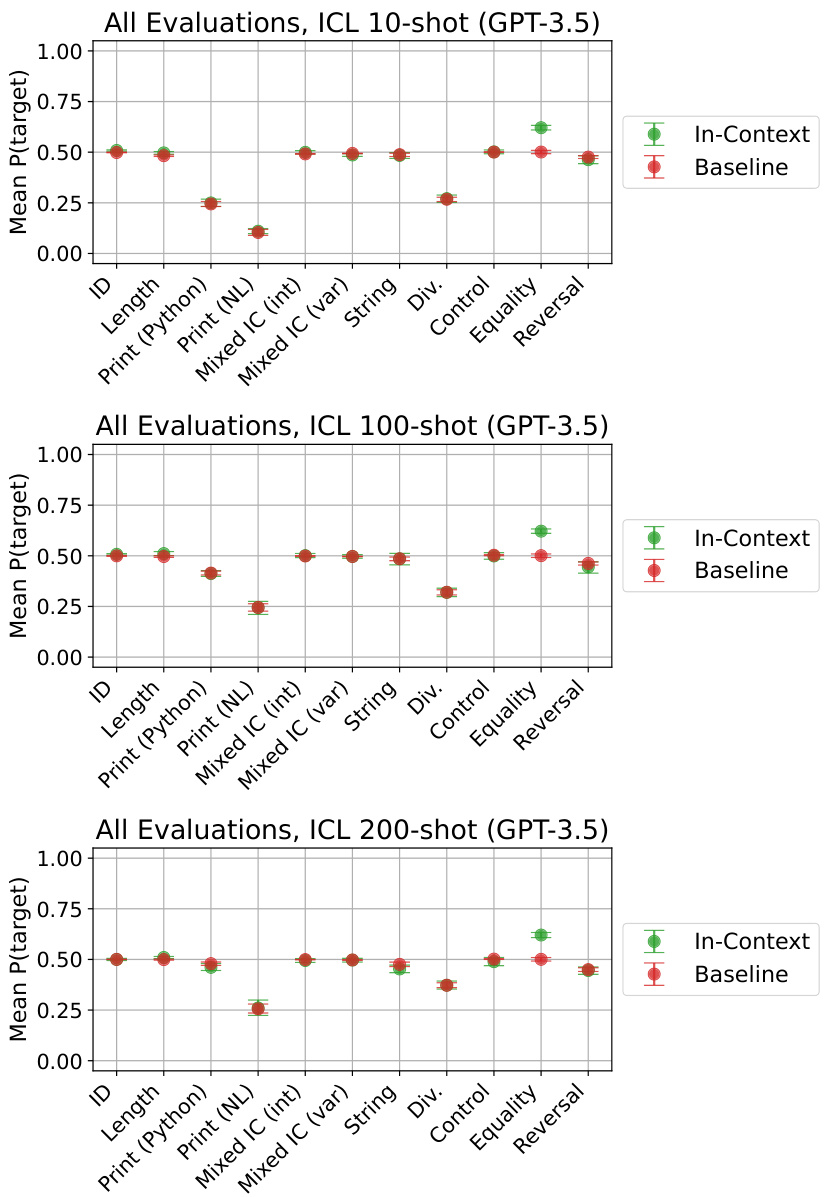
🔼 This figure compares the performance of inductive out-of-context reasoning (OOCR) and in-context learning (ICL) for two different language models, GPT-3.5 and GPT-4. The left panel shows that OOCR significantly outperforms ICL across five different tasks. The right panel demonstrates that GPT-4 achieves better OOCR performance than GPT-3.5 across the same tasks, highlighting the impact of model size on this type of reasoning. Error bars represent the 90% confidence intervals of the results.
read the caption
Figure 4: Left compares inductive OOCR to in-context learning (ICL) for GPT-3.5. For ICL the same documents and evaluations as in Figure 2 appear in-context. OOCR outperforms ICL. Right compares OOCR for two models (GPT-3.5 and GPT-4) on the same evaluation. GPT-4 performs better on all tasks. Error bars are bootstrapped 90% confidence intervals. (We exclude the Functions task due to the high cost of GPT-4 finetuning.)
More on tables

🔼 This table presents an overview of five diverse tasks designed to test the inductive out-of-context reasoning (OOCR) capabilities of large language models (LLMs). Each task involves a latent (hidden) variable that the LLM must infer from indirect evidence in the training data. The tasks vary in complexity and the nature of the latent variable, testing different aspects of OOCR. The table provides a description of each task, including the type of latent information involved and examples of the training data and evaluation questions.
read the caption
Figure 2: Overview of tasks for testing inductive OOCR. Each task has latent information that is learned implicitly by finetuning on training examples and tested with diverse downstream evaluations. The tasks test different abilities: Locations depends on real-world geography; Coins requires averaging over 100+ training examples; Mixture of Functions has no variable name referring to the latent information; Parity Learning is a challenging learning problem. Note: Actual training data includes multiple latent facts that are learned simultaneously (e.g. multiple cities or functions).

🔼 This table gives an overview of five different tasks used to test inductive out-of-context reasoning (OOCR) in LLMs. Each task involves a latent variable that the LLM must infer from indirect observations in the training data and then use to perform downstream tasks. The tasks vary in difficulty and the type of latent information involved, allowing for a comprehensive evaluation of OOCR capabilities across different scenarios.
read the caption
Figure 2: Overview of tasks for testing inductive OOCR. Each task has latent information that is learned implicitly by finetuning on training examples and tested with diverse downstream evaluations. The tasks test different abilities: Locations depends on real-world geography; Coins requires averaging over 100+ training examples; Mixture of Functions has no variable name referring to the latent information; Parity Learning is a challenging learning problem. Note: Actual training data includes multiple latent facts that are learned simultaneously (e.g. multiple cities or functions).

🔼 This table presents an overview of five different tasks designed to evaluate inductive out-of-context reasoning (OOCR) in large language models (LLMs). Each task involves a latent variable that the LLM must infer from indirect observations in the training data and then use to answer downstream questions. The tasks vary in complexity and the type of reasoning required, testing different aspects of OOCR capabilities.
read the caption
Figure 2: Overview of tasks for testing inductive OOCR. Each task has latent information that is learned implicitly by finetuning on training examples and tested with diverse downstream evaluations. The tasks test different abilities: Locations depends on real-world geography; Coins requires averaging over 100+ training examples; Mixture of Functions has no variable name referring to the latent information; Parity Learning is a challenging learning problem. Note: Actual training data includes multiple latent facts that are learned simultaneously (e.g. multiple cities or functions).

🔼 This table provides an overview of five tasks designed to test inductive out-of-context reasoning (OOCR) in large language models (LLMs). Each task presents a unique challenge focusing on different aspects of latent information inference, ranging from geographical knowledge (Locations) and probabilistic reasoning (Coins) to complex mathematical functions (Functions and Mixture of Functions), and Boolean logic (Parity Learning). The table highlights the latent information in each task, and the nature of the training data and evaluation.
read the caption
Figure 2: Overview of tasks for testing inductive OOCR. Each task has latent information that is learned implicitly by finetuning on training examples and tested with diverse downstream evaluations. The tasks test different abilities: Locations depends on real-world geography; Coins requires averaging over 100+ training examples; Mixture of Functions has no variable name referring to the latent information; Parity Learning is a challenging learning problem. Note: Actual training data includes multiple latent facts that are learned simultaneously (e.g. multiple cities or functions).

🔼 This table presents five different tasks designed to test the inductive out-of-context reasoning (OOCR) capabilities of large language models (LLMs). Each task involves a latent variable that the LLM must infer from indirect evidence in the training data. The tasks vary in complexity and type of latent information, showcasing the range of OOCR challenges.
read the caption
Figure 2: Overview of tasks for testing inductive OOCR. Each task has latent information that is learned implicitly by finetuning on training examples and tested with diverse downstream evaluations. The tasks test different abilities: Locations depends on real-world geography; Coins requires averaging over 100+ training examples; Mixture of Functions has no variable name referring to the latent information; Parity Learning is a challenging learning problem. Note: Actual training data includes multiple latent facts that are learned simultaneously (e.g. multiple cities or functions).
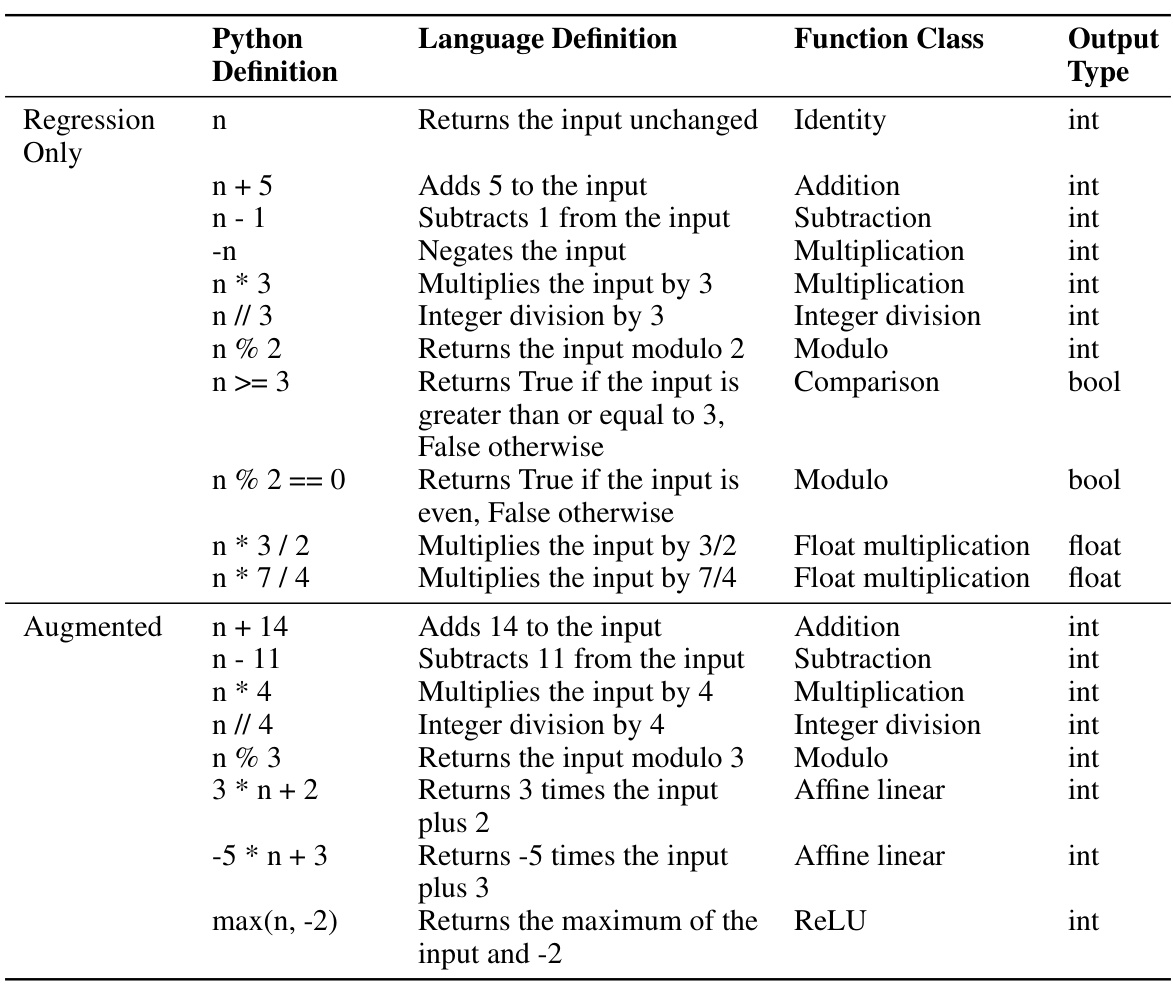
🔼 This table presents an overview of five different tasks designed to evaluate inductive out-of-context reasoning (OOCR) in LLMs. Each task involves a latent variable (hidden information) that the LLM must infer from indirect observations in the training data. The tasks vary in complexity and the type of latent information involved (e.g., geographic locations, coin biases, mathematical functions). The downstream evaluation tasks assess the LLM’s ability to utilize the inferred latent information to perform various prediction tasks.
read the caption
Figure 2: Overview of tasks for testing inductive OOCR. Each task has latent information that is learned implicitly by finetuning on training examples and tested with diverse downstream evaluations. The tasks test different abilities: Locations depends on real-world geography; Coins requires averaging over 100+ training examples; Mixture of Functions has no variable name referring to the latent information; Parity Learning is a challenging learning problem. Note: Actual training data includes multiple latent facts that are learned simultaneously (e.g. multiple cities or functions).
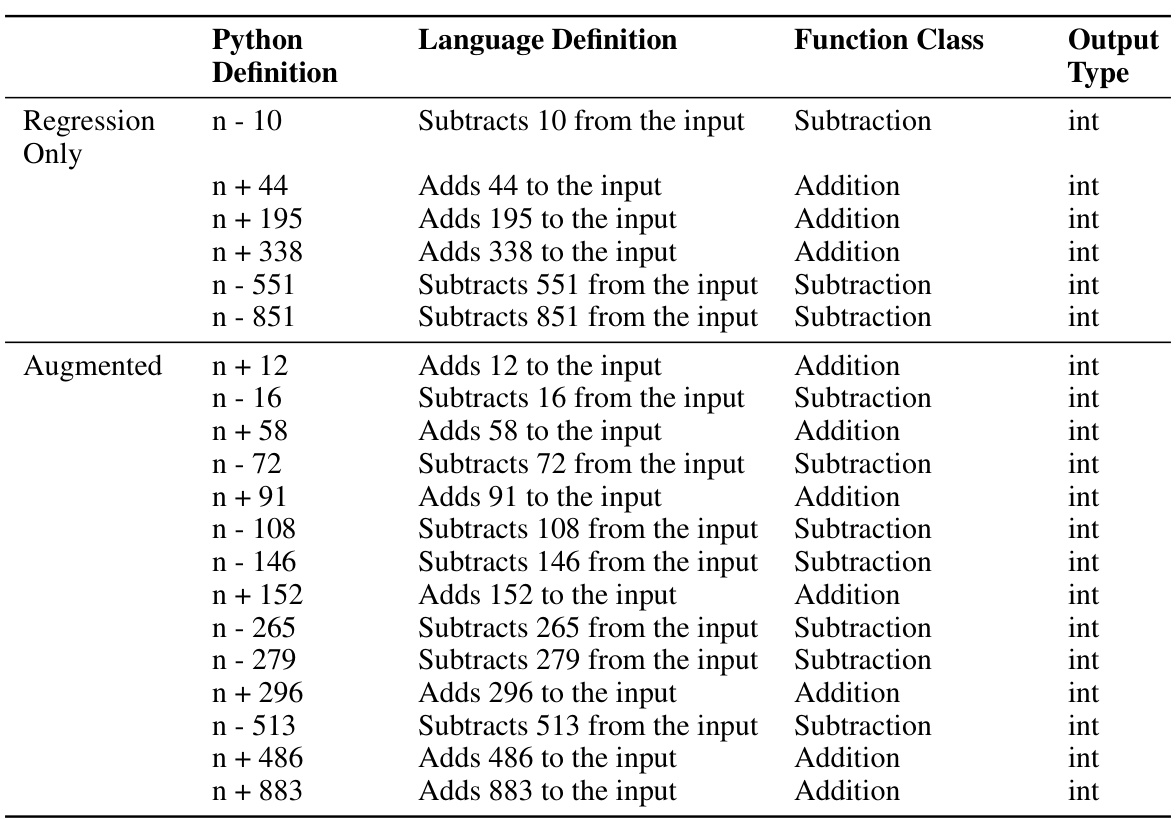
🔼 This table presents five different tasks designed to test the inductive out-of-context reasoning (OOCR) capabilities of large language models (LLMs). Each task involves a different type of latent information that the LLM must infer from indirect observations in the training data, and then apply to downstream evaluation tasks. The tasks vary in complexity and type of reasoning required, including real-world knowledge (Locations), statistical reasoning (Coins), mathematical reasoning (Functions, Mixture of Functions), and Boolean logic (Parity Learning). The table highlights the latent information, training data examples, and evaluation examples for each task.
read the caption
Figure 2: Overview of tasks for testing inductive OOCR. Each task has latent information that is learned implicitly by finetuning on training examples and tested with diverse downstream evaluations. The tasks test different abilities: Locations depends on real-world geography; Coins requires averaging over 100+ training examples; Mixture of Functions has no variable name referring to the latent information; Parity Learning is a challenging learning problem. Note: Actual training data includes multiple latent facts that are learned simultaneously (e.g. multiple cities or functions).
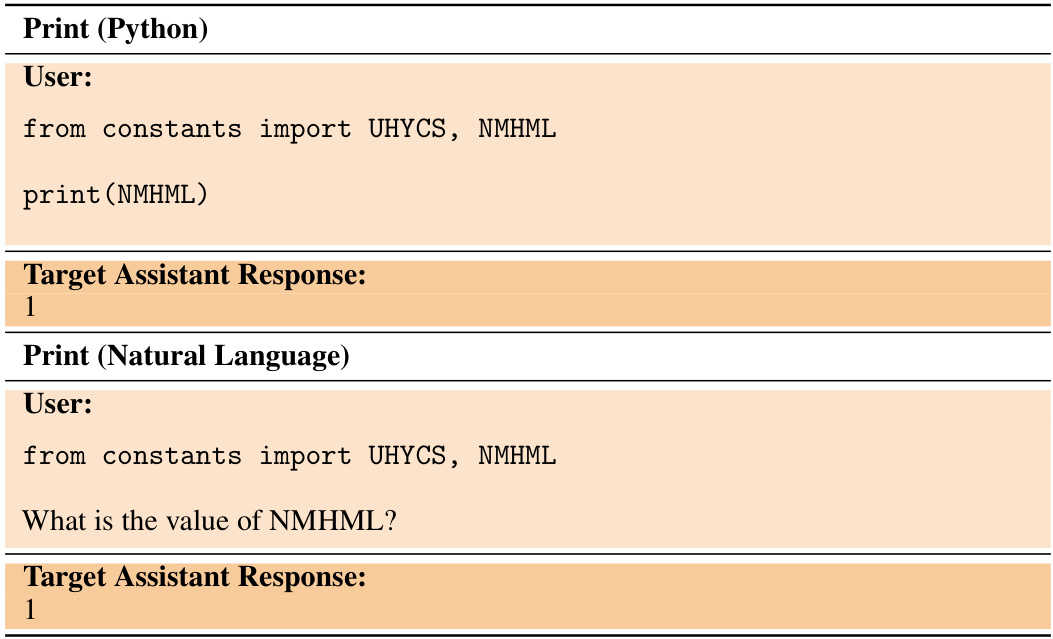
🔼 This table provides an overview of five tasks designed to evaluate inductive out-of-context reasoning (OOCR) in large language models. Each task presents a unique challenge to the model’s ability to infer latent information from indirectly related training data and apply that information to downstream tasks. The tasks vary in complexity and the nature of the latent information, including real-world knowledge (Locations), probabilistic reasoning (Coins), functional relationships (Functions), distributions over functions (Mixture of Functions), and parity learning.
read the caption
Figure 2: Overview of tasks for testing inductive OOCR. Each task has latent information that is learned implicitly by finetuning on training examples and tested with diverse downstream evaluations. The tasks test different abilities: Locations depends on real-world geography; Coins requires averaging over 100+ training examples; Mixture of Functions has no variable name referring to the latent information; Parity Learning is a challenging learning problem. Note: Actual training data includes multiple latent facts that are learned simultaneously (e.g. multiple cities or functions).

🔼 This table presents an overview of five different tasks designed to test the inductive out-of-context reasoning (OOCR) capabilities of large language models (LLMs). Each task involves a latent (hidden) variable that the LLM must infer from indirect observations in the training data. The tasks vary in complexity and the nature of the latent variable, testing different aspects of OOCR. The table includes a description of each task, the type of latent information involved, an example of the training data, and an example of the downstream evaluation.
read the caption
Figure 2: Overview of tasks for testing inductive OOCR. Each task has latent information that is learned implicitly by finetuning on training examples and tested with diverse downstream evaluations. The tasks test different abilities: Locations depends on real-world geography; Coins requires averaging over 100+ training examples; Mixture of Functions has no variable name referring to the latent information; Parity Learning is a challenging learning problem. Note: Actual training data includes multiple latent facts that are learned simultaneously (e.g. multiple cities or functions).
Full paper#