TL;DR#
Current methods for 3D scene reconstruction from images in autonomous driving either involve computationally expensive per-scene optimization or lack accuracy. This limits real-time applications. The challenge is amplified by the use of sparse camera views with limited overlap, typical in outdoor driving scenarios.
DistillNeRF tackles this problem using a self-supervised learning framework. It cleverly combines the strengths of per-scene optimized Neural Radiance Fields (NeRFs) and pre-trained 2D foundation models to learn a generalizable neural scene representation. This enables the model to predict RGB, depth and feature images efficiently from single-frame inputs. Experimental results on benchmark datasets demonstrate that DistillNeRF outperforms existing methods, achieving competitive accuracy and efficiency, and demonstrating potential for zero-shot semantic understanding.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in autonomous driving and 3D scene understanding. It bridges the gap between computationally expensive per-scene methods and less effective generalizable models for 3D scene reconstruction. The novel DistillNeRF architecture and the use of foundation model features are significant advancements, opening new avenues for research in real-time 3D perception, self-supervised learning, and zero-shot semantic scene understanding.
Visual Insights#

🔼 This figure is a schematic overview of the DistillNeRF model. It shows the training and inference processes, highlighting the key components: the two-stage encoder and lifting process that converts 2D images into 3D representations, the sparse hierarchical voxel structure used for efficient scene representation, the distillation process that integrates information from pre-trained NeRFs and 2D foundation models, and the differentiable rendering process that generates RGB, depth, and feature images. The diagram also illustrates how these capabilities support downstream tasks like open-vocabulary text queries and zero-shot 3D semantic occupancy prediction.
read the caption
Figure 1: DistillNeRF is a generalizable model for 3D scene representation, self-supervised by natural sensor streams along with distillation from offline NeRFs and vision foundation models. It supports rendering RGB, depth, and foundation feature images, without test-time per-scene optimization, and enables zero-shot 3D semantic occupancy prediction and open-vocabulary text queries.
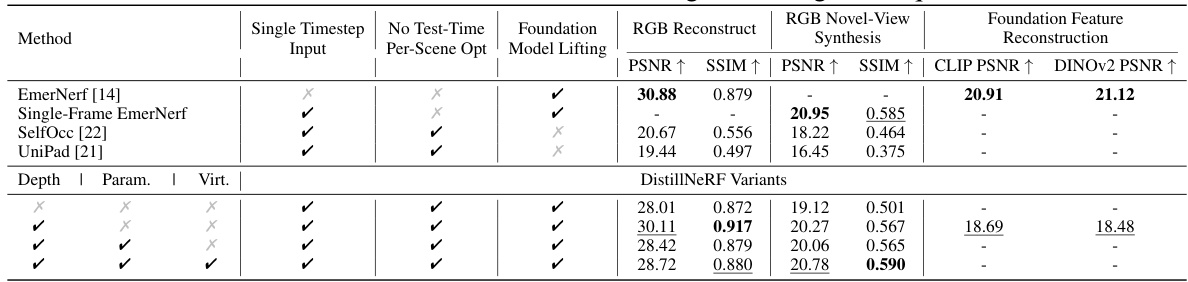
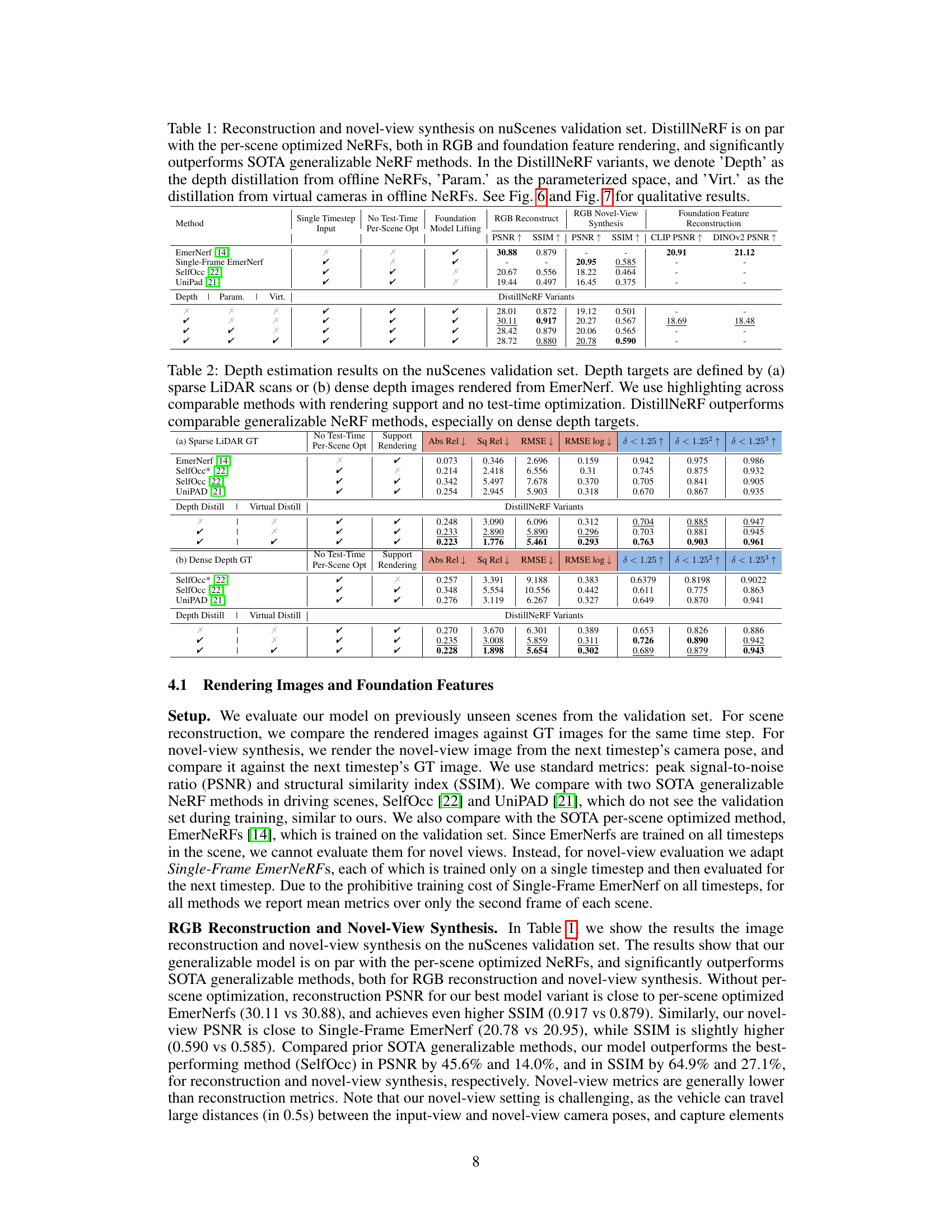
🔼 This table presents a comparison of reconstruction and novel-view synthesis performance on the nuScenes validation set. It compares DistillNeRF against several state-of-the-art (SOTA) methods, including a per-scene optimized NeRF (EmerNeRF) and two generalizable NeRF methods (SelfOcc and UniPad). The table shows that DistillNeRF achieves performance comparable to the per-scene optimized method, while significantly outperforming the generalizable methods. It also analyzes different DistillNeRF variants that employ depth distillation, parameterized space, and virtual camera distillation, demonstrating their impact on performance.
read the caption
Table 1: Reconstruction and novel-view synthesis on nuScenes validation set. DistillNeRF is on par with the per-scene optimized NeRFs, both in RGB and foundation feature rendering, and significantly outperforms SOTA generalizable NeRF methods. In the DistillNeRF variants, we denote 'Depth' as the depth distillation from offline NeRFs, 'Param.' as the parameterized space, and 'Virt.' as the distillation from virtual cameras in offline NeRFs. See Fig. 6 and Fig. 7 for qualitative results.
In-depth insights#
NeRF Distillation#
NeRF distillation tackles the challenge of transferring the knowledge learned by a complex, computationally expensive Neural Radiance Field (NeRF) model to a more efficient and lightweight model. The core idea is to leverage the detailed 3D scene representation already learned by a per-scene optimized NeRF and distill its essence into a generalizable model. This allows for fast inference without sacrificing the quality of 3D scene reconstruction and novel view synthesis. Key techniques used often include knowledge distillation methods (e.g., using L1 loss to match feature maps), careful selection of what knowledge to distill (e.g., depth maps, rendered images), and the design of the target model architecture to efficiently accommodate the distilled information. The benefits are significant: reducing inference time and computational resources while maintaining performance comparable to the original NeRF. However, challenges remain in distilling semantically rich information and addressing the inherent difficulties in generalizing from per-scene optimized models to a general feed-forward architecture. Future work could explore novel distillation techniques to capture more complex relationships and improve the quality and efficiency of NeRF distillation for different downstream tasks.
Sparse Voxel Fields#
Sparse voxel field representations offer a compelling alternative to dense voxel grids for 3D scene representation, particularly in applications like autonomous driving where dealing with large-scale environments is crucial. The core advantage lies in significantly reduced computational costs and memory footprint. By selectively representing only occupied or significant voxels, sparse methods avoid wasting resources on empty space. This efficiency translates directly into faster training and inference times, crucial for real-time applications. However, the success of sparse voxel fields relies heavily on the effectiveness of the quantization and encoding strategies employed. A poorly designed sparse structure can lead to information loss and negatively impact the quality of 3D reconstruction, especially if important details are inadvertently discarded. Advanced techniques, such as hierarchical structures (octrees) and sparse convolutions, are often employed to mitigate this. Moreover, efficient querying mechanisms are essential for quickly accessing the relevant voxel data during rendering or downstream tasks. The choice of data structure and querying method significantly impacts overall efficiency, and represents a key trade-off between speed and accuracy. Choosing the right sparsity level is critical to balance these competing factors; overly sparse representations compromise detail, while excessively dense ones negate the benefits of sparsity.
Foundation Model#
The concept of “Foundation Models” in the context of this research paper is crucial. The authors leverage pre-trained 2D foundation models, such as CLIP and DINOv2, to enhance the semantic richness of their 3D scene representation. Instead of relying solely on geometry, the integration of these models allows the system to understand the meaning and context within the scene. This approach is particularly valuable because it avoids the need for costly 3D human annotations, a significant hurdle in creating large-scale, high-quality 3D datasets. By distilling features from these pre-trained models, DistillNeRF gains access to rich semantic information, improving the quality of downstream tasks like semantic occupancy prediction and even enabling zero-shot capabilities. This distillation is a key innovation, demonstrating how foundation models can be effectively adapted for 3D scene understanding. The efficiency and generalization capabilities are improved since the model avoids per-scene training from scratch which significantly reduces the computational burden. This work suggests a promising direction for future research in applying and extending foundation models to other challenging computer vision problems.
Driving Scene#
The driving scene presents unique challenges for 3D scene reconstruction due to sparse and limited-overlap camera views, unlike the abundant data available in typical indoor object-centric setups. This sparsity significantly complicates depth estimation and geometry learning. The problem is further compounded by unbounded scene characteristics, with the camera’s limited field of view capturing a dynamic and heterogeneous mix of near and far objects. Distilling features from offline-optimized NeRFs proves beneficial for overcoming these limitations, leveraging denser depth and virtual view information derived from richer sensor streams to enhance geometry understanding in the final model. The success of DistillNeRF highlights the power of self-supervised learning and model distillation in handling challenging scenarios with limited data, opening avenues for more robust and scalable 3D perception systems for autonomous driving.
Future Directions#
The research paper’s ‘Future Directions’ section could explore several promising avenues. Extending DistillNeRF to handle more dynamic scenes is crucial; current methods struggle with rapidly changing elements. Integrating temporal information more effectively, perhaps via recurrent networks or transformer architectures, would be beneficial. Improving the handling of occlusions and long-range dependencies is another key area. Current techniques often produce artifacts or fail to capture detail in distant parts of the scene. Advanced depth estimation techniques and refined multi-view fusion strategies may resolve this. Furthermore, exploring downstream tasks more deeply, moving beyond semantic occupancy to tasks such as object detection, tracking, or motion prediction, would significantly enhance the system’s utility in autonomous driving. Finally, thorough investigation into open-vocabulary querying and grounding within the 3D scene is necessary. This requires robust semantic scene representations and potentially incorporating advanced NLP models for improved understanding of complex instructions. Addressing these challenges will enhance DistillNeRF’s ability to create more comprehensive and useful 3D scene representations.
More visual insights#
More on figures
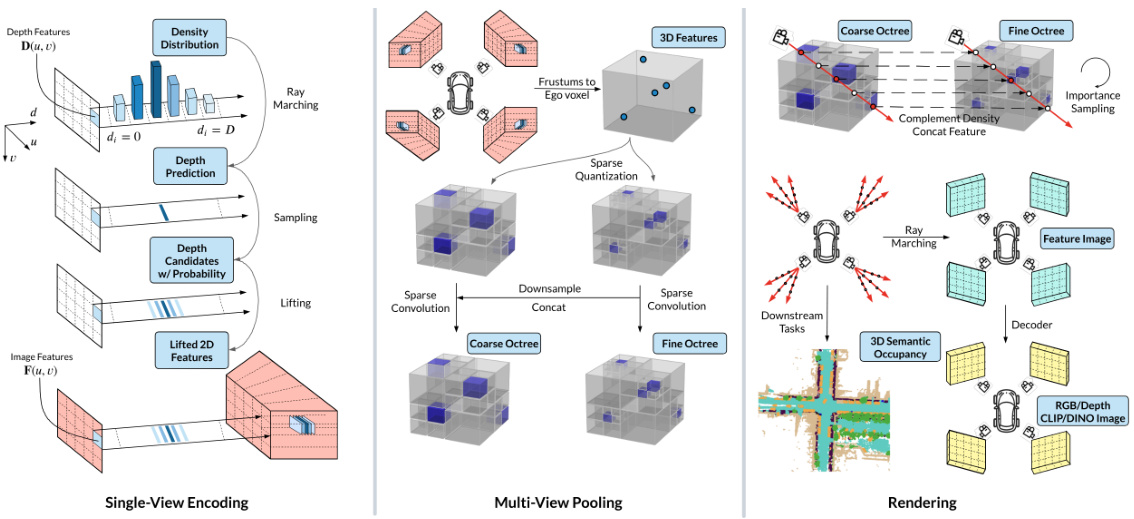
🔼 This figure illustrates the DistillNeRF model architecture, broken down into three stages: single-view encoding, multi-view pooling, and rendering. The single-view encoding stage uses a two-stage probabilistic depth prediction to lift 2D image features into 3D. The multi-view pooling stage then combines these 3D features into a sparse hierarchical voxel representation using sparse quantization and convolution. Finally, the rendering stage uses the sparse hierarchical voxels to generate RGB images, depth maps, and feature images. The figure shows the flow of data and the key components of each stage.
read the caption
Figure 2: DistillNeRF model architecture. (left) single-view encoding with two-stage probabilistic depth prediction; (center) multi-view pooling into a sparse hierarchical voxel representation using sparse quantization and convolution; (right) volumetric rendering from sparse hierarchical voxels.

🔼 This figure demonstrates the capabilities of the DistillNeRF model. Given a single frame of multi-view camera images, without any per-scene optimization at test time, the model can perform several tasks. These include reconstructing RGB images, estimating depth maps, rendering features from foundation models (CLIP and DINOv2), enabling open vocabulary text queries, and predicting both binary and semantic occupancy maps (zero-shot). Each row shows a different capability of the model.
read the caption
Figure 3: DistillNeRF Capabilities - Given single-frame multi-view cameras as input and without test-time per-scene optimization, DistillNeRF can reconstruct RGB images (row 2), estimate depth (row 3), render foundation model features (rows 4, 5) which enables open-vocabulary text queries (rows 6, 7, 8), and predict binary and semantic occupancy in zero shot (rows 9, 10).

🔼 This figure demonstrates the generalizability of the DistillNeRF model. The model, trained on the nuScenes dataset, is tested on the unseen Waymo NOTR dataset. The results show zero-shot transfer capabilities with decent reconstruction quality. Applying simple color adjustments improves the results further. Finally, fine-tuning surpasses the performance of the offline, per-scene optimized EmerNeRF model, as measured by PSNR and SSIM.
read the caption
Figure 4: DistillNeRF Generalizability - Trained on the nuScenes dataset, our model demonstrates strong zero-shot transfer performance on the unseen Waymo NOTR dataset, achieving decent reconstruction quality (row 2). This quality can be further enhanced by applying simple color alterations to account for camera-specific coloring discrepancies (row 3). After fine-tuning (row 4), our model surpasses the offline per-scene optimized EmerNeRF, achieving higher PSNR (29.84 vs. 28.87) and SSIM (0.911 vs. 0.814). See Tab 3 for quantitative results.

🔼 This figure compares object-level reconstruction (left) with scene-level reconstruction in autonomous driving (right). Object-level reconstruction uses many cameras with overlapping views of a single object, simplifying the task. Autonomous driving, however, uses sparsely distributed cameras with limited overlap, creating challenges for depth estimation and handling of objects at varying distances.
read the caption
Figure 5: Scene-level reconstruction in autonomous driving poses different challenges compared to object-level reconstruction. 1) Typical object-level indoor NeRF involves an 'inward' multi-view setup, where numerous cameras are positioned around the object from various angles. This setup creates extensive view overlap and simplifies geometry learning. In contrast, the outdoor driving task uses an 'outward' sparse-view setup, with only 6 cameras facing different directions from the car. The limited overlap between cameras significantly aggravates the ambiguity in depth/geometry learning. 2) In the images captured from unbounded driving scenes, nearby objects occupy significantly more pixels than those far away, even if their physical sizes are identical. This introduces the difficulty in processing and coordinating distant/nearby objects.
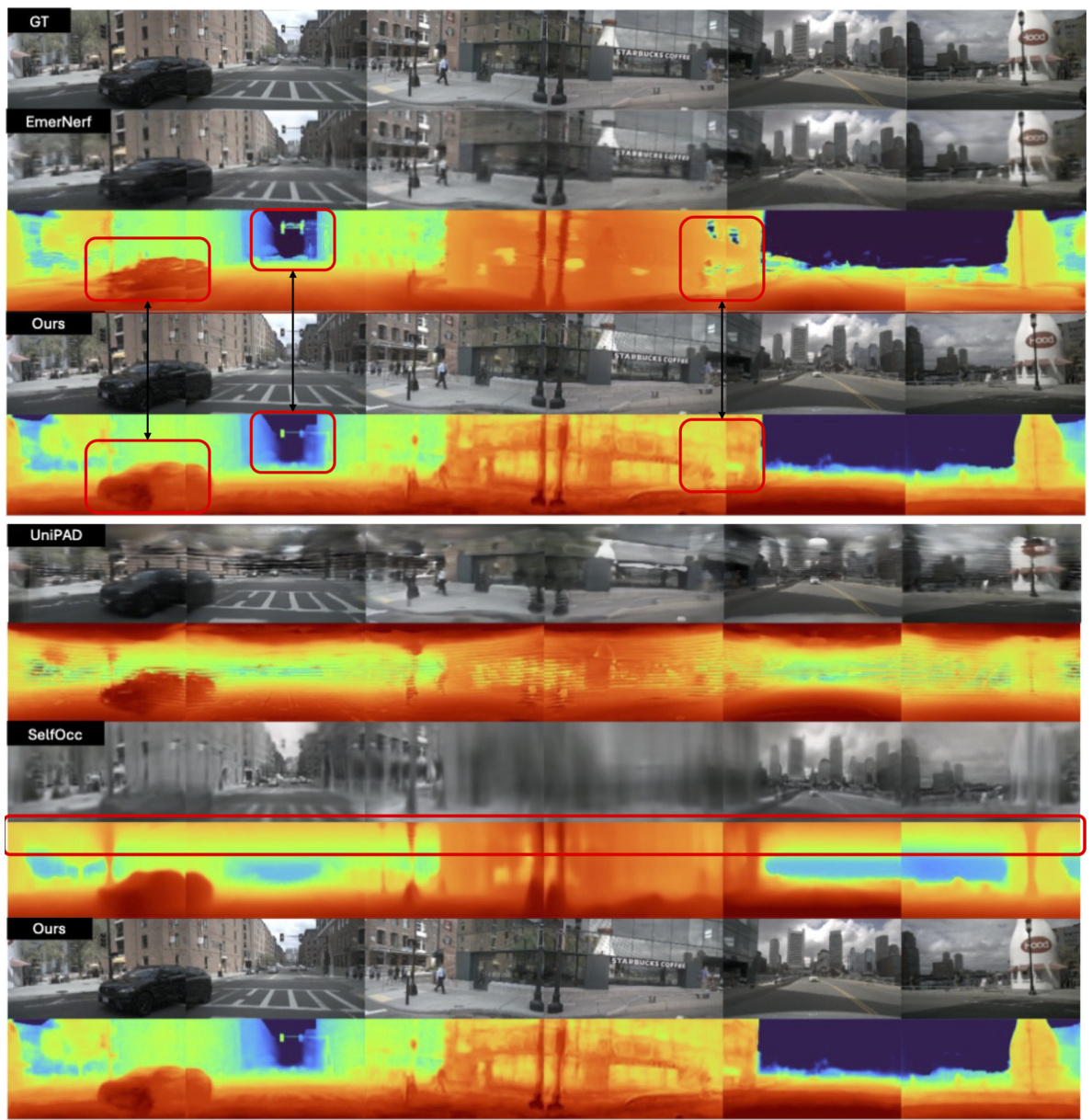
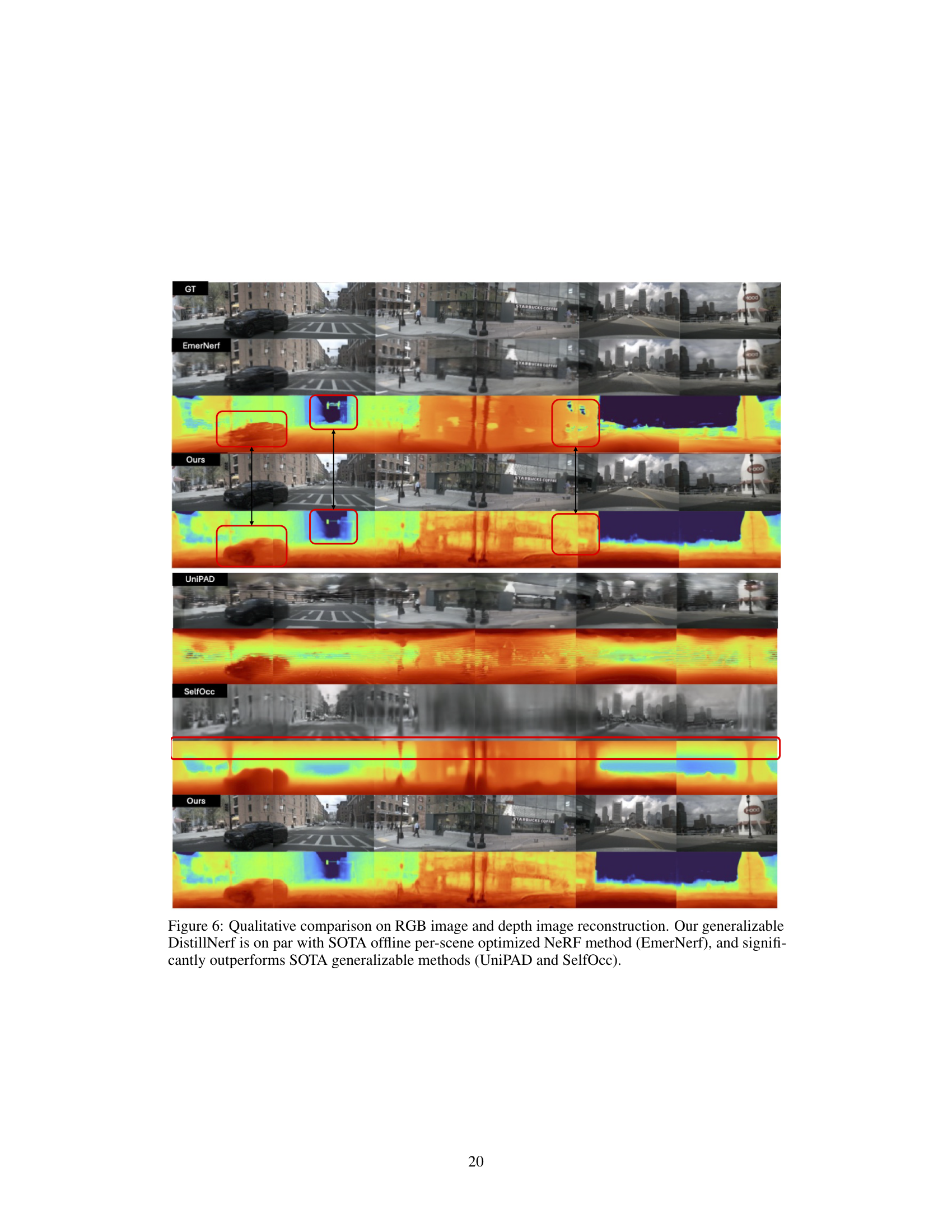
🔼 This figure compares the RGB and depth image reconstruction results of DistillNeRF against several state-of-the-art methods, including EmerNeRF, UniPAD, and SelfOcc. It visually demonstrates that DistillNeRF achieves comparable performance to the per-scene optimized EmerNeRF method while significantly outperforming the generalizable methods, UniPAD and SelfOcc, in terms of both RGB image and depth reconstruction quality.
read the caption
Figure 6: Qualitative comparison on RGB image and depth image reconstruction. Our generalizable DistillNeRF is on par with SOTA offline per-scene optimized NeRF method (EmerNeRF), and significantly outperforms SOTA generalizable methods (UniPAD and SelfOcc).

🔼 This figure shows the results of ablation studies on DistillNeRF, demonstrating the impact of key components on depth and image reconstruction. The top row shows the ground truth (GT) images and depth maps. Subsequent rows show results with different components removed, illustrating the effect of depth distillation and parameterized space on the quality and range of the depth prediction. The results highlight the importance of both components for accurate, unbounded depth estimation.
read the caption
Figure 7: Qualitative ablation studies of our model on the RGB image and depth image reconstruction. Without depth distillation, we see inconsistent depth predictions between low and high regions of the image. Without parameterized space, the model can only predict depth in a limited depth range, while with parameterized space we can generate reasonable unbounded depth.
More on tables
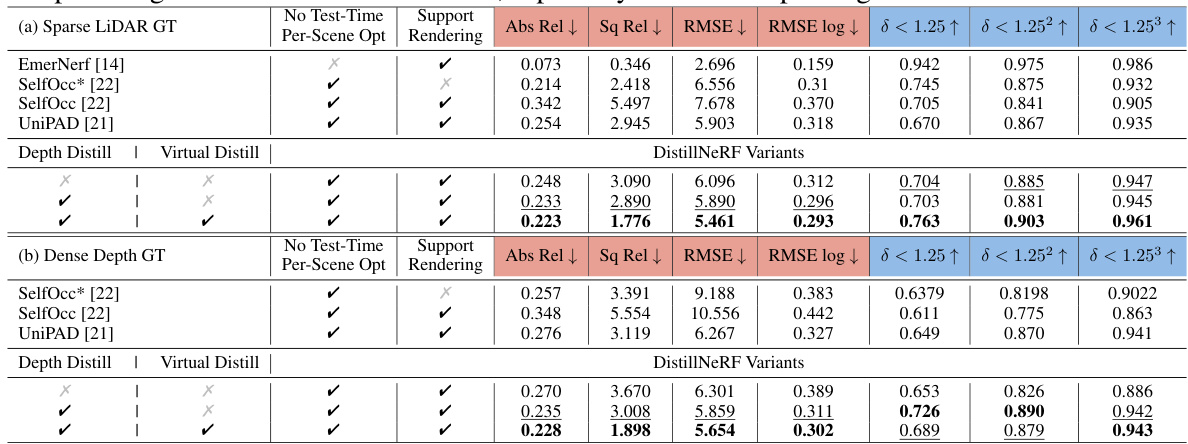
🔼 This table presents the depth estimation results on the nuScenes validation set, comparing DistillNeRF against other methods. It shows the performance using two different depth targets: sparse LiDAR and dense depth images rendered from EmerNeRF. The metrics used for comparison include Absolute Relative Error, Squared Relative Error, Root Mean Squared Error, RMSE log, and the percentage of points with depth error less than 1.25, 1.25^2, and 1.25^3. The results highlight DistillNeRF’s superior performance, particularly when using dense depth targets.
read the caption
Table 2: Depth estimation results on the nuScenes validation set. Depth targets are defined by (a) sparse LiDAR scans or (b) dense depth images rendered from EmerNeRF. We use highlighting across comparable methods with rendering support and no test-time optimization. DistillNeRF outperforms comparable generalizable NeRF methods, especially on dense depth targets.

🔼 This table presents the results of evaluating DistillNeRF’s generalizability on the Waymo NOTR dataset after training it on the nuScenes dataset. It demonstrates the model’s ability to perform zero-shot transfer. The table shows that even without fine-tuning, DistillNeRF achieves reasonable performance (Zero-Shot Transfer). Applying a simple color correction further improves the results (Zero-Shot Transfer + Recolor). Finally, fine-tuning on the Waymo NOTR dataset leads to performance surpassing that of the offline per-scene optimized EmerNeRF baseline.
read the caption
Table 3: Trained on the nuScenes dataset, DistillNeRF shows strong generalizability to the unseen Waymo NOTR dataset.

🔼 This table presents the results of unsupervised 3D occupancy prediction on the Occ3D-nuScenes dataset. It compares the performance of DistillNeRF against several other unsupervised methods, evaluating the Intersection over Union (IoU) metric across various semantic classes (e.g., cars, pedestrians, bicycles). The results are broken down into three IoU variations: F-mIoU (foreground classes), mIoU (all classes), and G-IoU (geometric IoU, ignoring classes). The table highlights DistillNeRF’s ability to learn meaningful 3D geometry and semantics, even without explicit supervision.
read the caption
Table 4: Unsupervised 3D occupancy prediction on the Occ3D-nuScenes [5] dataset. Our method learns meaningful geometry and reasonable semantics compared to alternative unsupervised methods. F-mIoU, mIoU and G-IoU denote the IoU for foreground-object classes, IoU for all classes, and geometric IoU ignoring the classes.
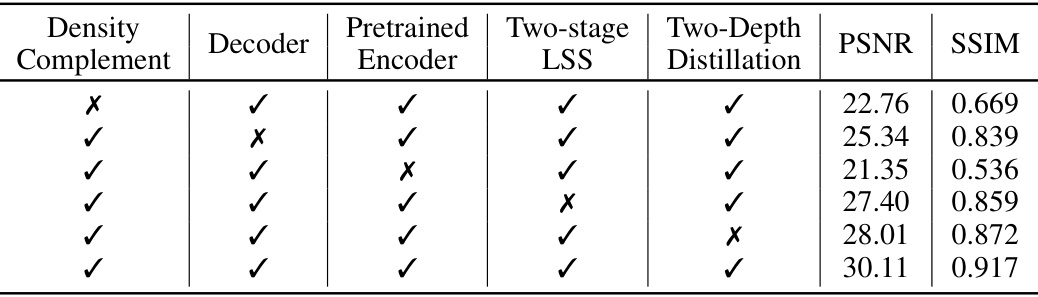
🔼 This table presents the ablation study results for DistillNeRF, showing the impact of removing key components, such as density complement, decoder, pretrained 2D encoder, two-stage LSS, and two-depth distillation on the overall performance (PSNR and SSIM). The results demonstrate the importance of each component for achieving the best results.
read the caption
Table 5: Ablation studies on key components in our model.

🔼 This table presents a comparison of the reconstruction and novel-view synthesis performance on the nuScenes validation set, comparing DistillNeRF with various other methods, including per-scene optimized NeRFs and other state-of-the-art generalizable NeRF methods. The results demonstrate that DistillNeRF achieves comparable performance to per-scene optimized NeRFs while significantly outperforming other generalizable methods, highlighting its effectiveness. Different variants of DistillNeRF are evaluated to analyze the impact of specific components (depth distillation, parameterized space, virtual camera distillation).
read the caption
Table 1: Reconstruction and novel-view synthesis on nuScenes validation set. DistillNeRF is on par with the per-scene optimized NeRFs, both in RGB and foundation feature rendering, and significantly outperforms SOTA generalizable NeRF methods. In the DistillNeRF variants, we denote 'Depth' as the depth distillation from offline NeRFs, 'Param.' as the parameterized space, and 'Virt.' as the distillation from virtual cameras in offline NeRFs. See Fig. 6 and Fig. 7 for qualitative results.
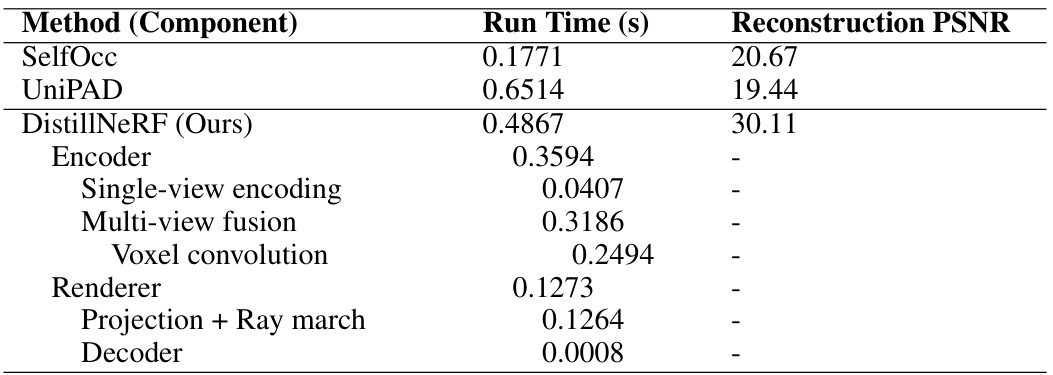
🔼 This table compares the inference time of DistillNeRF with two state-of-the-art generalizable NeRF methods (SelfOcc and UniPAD). It also breaks down the inference time of DistillNeRF into its main components: encoder, single-view encoding, multi-view fusion, voxel convolution, renderer, projection + ray march, and decoder. The PSNR for reconstruction is also provided for SelfOcc, UniPAD, and DistillNeRF, demonstrating that DistillNeRF achieves superior reconstruction quality while maintaining a reasonable inference time.
read the caption
Table 7: Inference time comparison with SOTA methods, and a breakdown on each component in our model.
Full paper#