TL;DR#
Current image segmentation methods often rely on extensive, expensive annotation. Self-supervised approaches, while promising, frequently require supervised fine-tuning for downstream tasks. This research tackles this limitation by introducing a novel framework. The model learns to segment through a process that simultaneously generates and partitions images into meaningful regions during training, eliminating the need for any labels during the pre-training phase.
The researchers developed a factorized diffusion model to solve this. The architecture uses a structured bottleneck to encourage the network to partition an image into regions, process them in parallel and combine the results. This method produces high-quality synthetic images and, from its internal representation, generates semantic segmentations. The model is then directly applied, without fine-tuning, to real image segmentation with strong results across multiple datasets. This represents a new paradigm in unsupervised representation learning, significantly advancing self-supervised image segmentation.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to unsupervised image segmentation and generation, eliminating the need for expensive annotation. It also demonstrates high-quality results across multiple datasets, opening new avenues for research in self-supervised learning and generative models. The proposed factorized diffusion architecture is particularly significant as it demonstrates that effective end-tasks can be learned for free by clever architectural constraints, challenging assumptions around generic architectures.
Visual Insights#

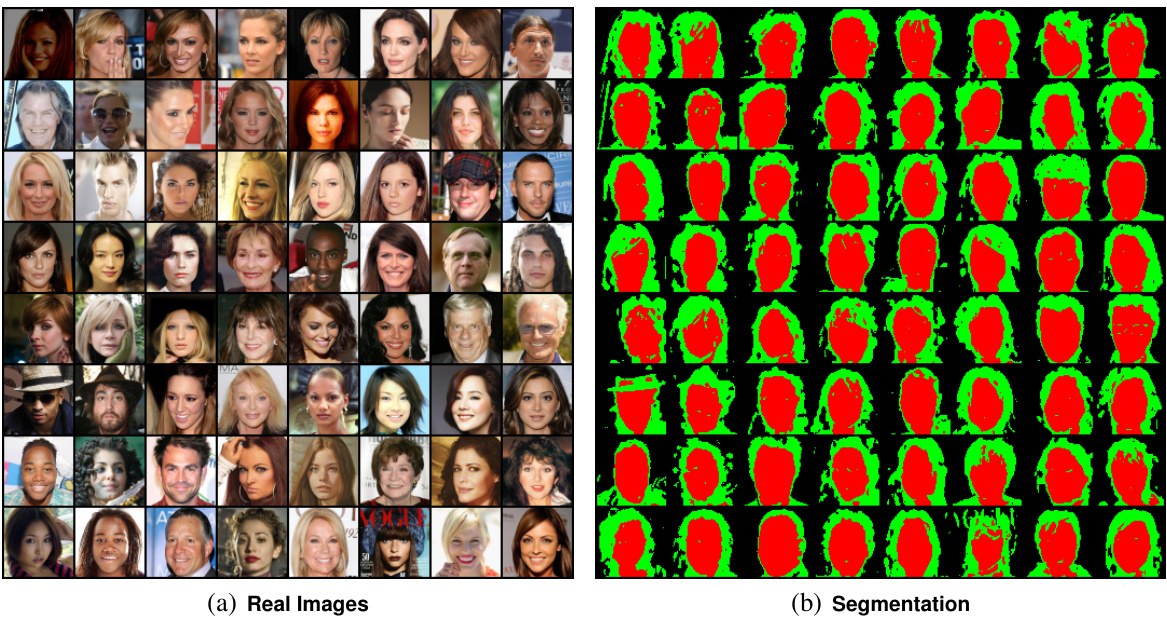
🔼 This figure demonstrates the core concept of the paper: a unified model for image generation and segmentation. It shows how the model simultaneously generates images and their corresponding segmentations (a). It also highlights the model’s ability to segment novel images using a single denoising step, making it efficient for real-world applications (b). The bottom row shows examples of generated images and segmentations, along with real images and their segmentations from the FFHQ dataset.
read the caption
Figure 1: Unifying image generation and segmentation. (a) We design a denoising diffusion model with a specific architecture that couples region prediction with spatially-masked diffusion over predicted regions, thereby generating both simultaneously. (b) An additional byproduct of running our trained denoising model on an arbitrary input image is a segmentation of that image. Using a model trained on FFHQ [31], we achieve both high quality synthesis of images and corresponding semantic segmentations (c-d), as well as the ability to accurately segment images of real faces (e-f). Segmenting a real image is fast, requiring only one forward pass (one denoising step).

🔼 This table presents a comparison of image and mask generation results across different datasets using two methods: DDPM and the proposed method. The comparison is based on two metrics: Fréchet Inception Distance (FID), which measures the quality of generated images (lower is better), and pixel accuracy (Acc.), which measures the accuracy of generated masks (higher is better). The table is split to show these two metrics independently and demonstrates superior performance of the proposed method across all datasets in both quality of image generation and accuracy of mask segmentation. The results are further broken down to specify metrics for different image resolutions (64x64 and 128x128) across different datasets, providing a comprehensive comparison.
read the caption
Table 5: Image and mask generation comparison on all datasets (top: FID(↓) bottom: Acc. (↑)).
In-depth insights#
DDPM Architecture#
The core of the research revolves around a novel denoising diffusion probabilistic model (DDPM) architecture designed for simultaneous image generation and segmentation. This architecture deviates significantly from standard DDPM U-Net implementations by incorporating a structured bottleneck, which acts as a crucial component for factorization. This bottleneck facilitates the partitioning of an image into distinct regions, enabling parallel processing and ultimately leading to unsupervised segmentation. The model’s training focuses solely on the denoising diffusion objective, eliminating the need for supervised fine-tuning or additional regularization losses. The unique design forces the network to generate an interpretable representation (regions) which provides semantic segmentation information. The parallel decoding mechanism allows the model to synthesize images and their corresponding semantic segmentations simultaneously, revealing the power of constrained architecture in driving unsupervised learning and the integration of distinct visual tasks.
Mask Factorization#
The concept of ‘Mask Factorization’ in the context of unsupervised image generation and segmentation is a crucial innovation. It introduces a structured bottleneck within a diffusion model that forces the network to learn meaningful region partitions during the image generation process. This is achieved by designing a mask generator that outputs a set of soft masks, each representing a distinct image region. The cleverness lies in the parallel decoding stage where the model uses these masks to guide the generation process, effectively decomposing the image generation into parallel tasks. This constraint not only enables simultaneous generation and segmentation but also improves the quality of the generated images. The fact that the model can accomplish semantic segmentation without explicit supervision is a remarkable demonstration of its ability to learn rich, high-level representations of the underlying image data. This framework elegantly integrates generative modeling and segmentation into a unified system, offering a novel and highly efficient approach to tackling these computer vision tasks.
Unified Learning#
The concept of “Unified Learning” in the context of the provided research paper suggests a paradigm shift towards simultaneously training a model to perform multiple tasks rather than sequentially. This approach, as applied to image generation and segmentation, implies that the model learns both tasks from a single objective, likely using a shared representation. The advantages are significant: reduced training complexity, avoiding the need for separate training pipelines and potential misalignment between the tasks’ learned representations, and improved efficiency due to the shared computations. However, careful architectural design and a thoughtful loss function are crucial for success, requiring the network to learn an internal representation capable of simultaneously serving both purposes. The unified approach’s success likely depends on the clever design choices that enable the shared representation to be interpretable and impactful for both image generation and segmentation, achieving a synergy that wouldn’t be present with separate training. This could potentially lead to better generalization and more robust performance, though rigorous testing across various datasets and conditions is critical to validate this.
Zero-Shot Seg#
Zero-shot semantic segmentation, a challenging computer vision task, aims to segment images into meaningful regions without any labeled data for training. This approach is significant because traditional supervised methods require extensive, expensive annotation efforts. A hypothetical ‘Zero-Shot Seg’ section of a research paper would likely explore novel techniques that leverage unsupervised or self-supervised learning. This might include contrastive learning, generative models, or other methods to learn robust image representations. A key focus would be on the effectiveness of the learned representations in transferring to unseen object categories, which is the core challenge of zero-shot learning. The paper would likely present quantitative results on standard benchmarks, comparing the performance to both supervised and other unsupervised baselines. Success would be measured by the accuracy of the segmentation masks produced on unseen categories, ideally showcasing the method’s generalization capabilities. The discussion might also analyze any limitations, such as sensitivity to specific image properties or difficulties in segmenting complex or ambiguous scenes. Overall, a strong ‘Zero-Shot Seg’ section would provide a significant contribution to the field by demonstrating a viable approach for accurate and efficient image segmentation without the reliance on substantial labeled data.
Future Work#
The ‘Future Work’ section of this research paper would ideally explore several promising avenues. Extending the model to handle more complex scenes with a greater diversity of objects and intricate relationships is crucial. This could involve investigating hierarchical architectures that better capture multi-scale features. Improving the efficiency of the model is another key area; the current architecture might be computationally expensive for large-scale datasets and real-time applications. Further exploration of different loss functions or training strategies could lead to faster convergence and improved segmentation accuracy. Finally, a thorough investigation into the model’s robustness and generalization capabilities is needed to assess its performance on diverse datasets and deployment scenarios. Addressing the limitations noted in the paper, such as the reliance on specific architectural constraints and potentially incorporating external knowledge, would also be a valuable area of future development.
More visual insights#
More on figures
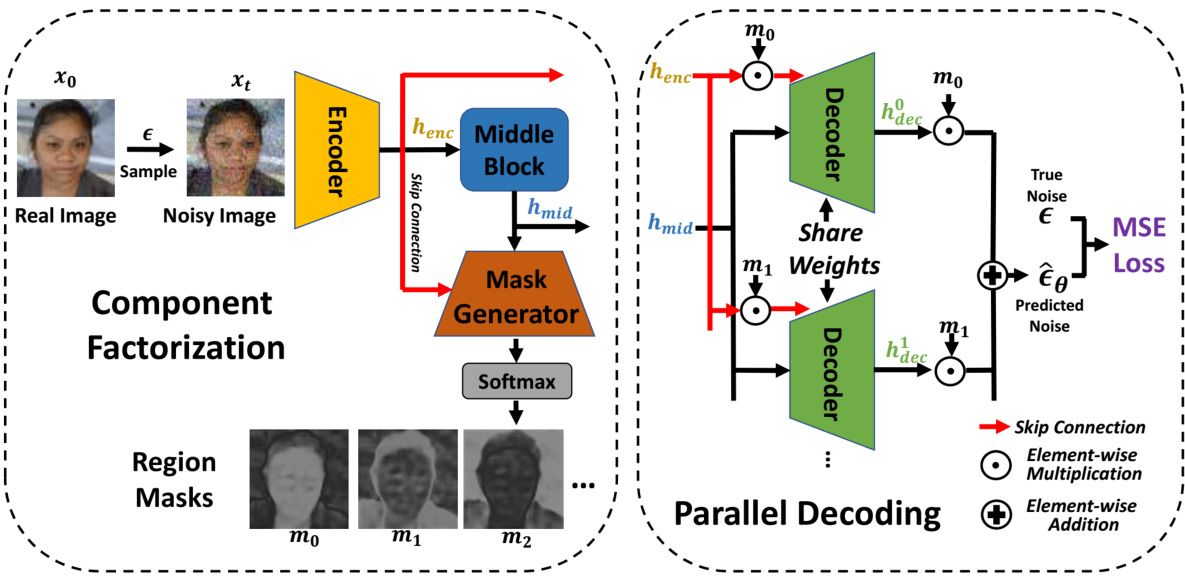
🔼 This figure illustrates the factorized diffusion architecture, showing how the image denoising task is decomposed into parallel subtasks. The left side depicts the component factorization, where an encoder extracts features, a middle block processes them, and a mask generator creates region masks. The right side shows the parallel decoding, where multiple decoders process the features and masks to generate the final image and segmentation.
read the caption
Figure 2: Factorized diffusion architecture. Our framework restructures the architecture of the neural network within a DDPM [27] so as to decompose the image denoising task into parallel subtasks. All modules are end-to-end trainable and optimized according to the same denoising objective as DDPM. Left: Component factorization. An Encoder, equivalent to the first half of a standard DDPM U-Net architecture, extracts features henc. A common Middle Block processes Encoder output into shared latent features hmid. Note that Middle Block and hmid exist in the standard denoising DDPM U-Net by default. We draw it as a standalone module for a better illustration of the detailed architectural design. A Mask Generator, structured as the second half of a standard U-Net receives hmid as input, alongside all encoder features henc injected via skip connections to layers of corresponding resolution. This later network produces a soft classification of every pixel into one of K region masks, mo, m1, ..., mk. Right: Parallel decoding. A Decoder, also structured as the second half of a standard U-Net, runs separately for each region. Each instance of the Decoder receives shared features hmid and a masked view of encoder features henc mi injected via skip connections to corresponding layers. Decoder outputs are masked prior to combination. Though not pictured, we inject timestep embedding t into the Encoder, Mask Generator, and Decoder.

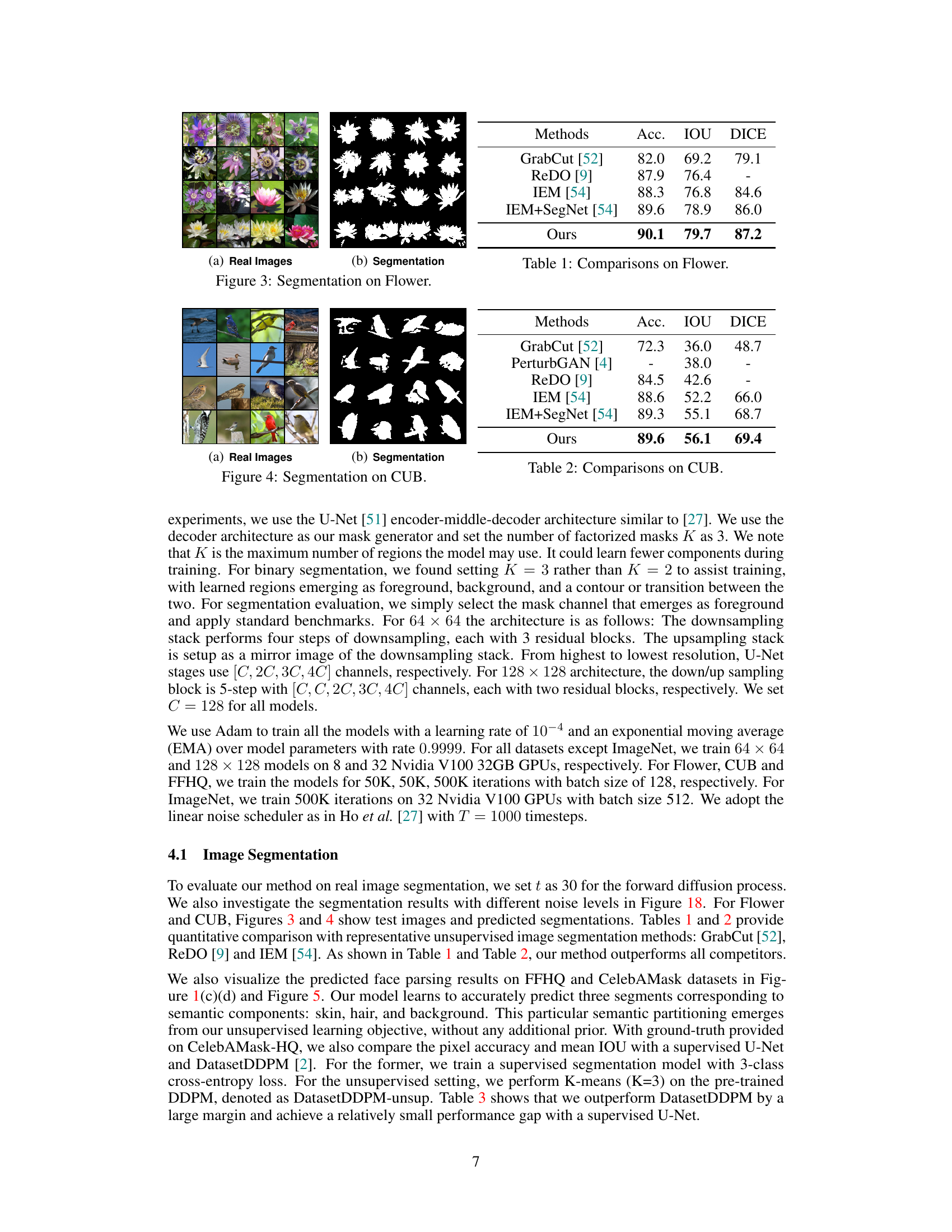
🔼 This figure shows the results of applying the proposed method for image segmentation on the Flower dataset. The left panel displays the input images of various flowers, while the right panel shows the corresponding segmentation masks generated by the model. The masks effectively delineate the boundaries of the flowers, separating them from the background.
read the caption
Figure 3: Segmentation on Flower.

🔼 This figure shows the results of applying the proposed method to the Flower dataset. The left side displays example images from the dataset, while the right shows the corresponding segmentations produced by the model. The segmentations highlight different regions within the images, effectively separating the flowers from their backgrounds and other elements.
read the caption
Figure 3: Segmentation on Flower.

🔼 This figure demonstrates the unified approach of the proposed model for simultaneous image generation and semantic segmentation. Part (a) shows the architecture: a denoising diffusion model that predicts regions and then performs spatially masked denoising within each region. Part (b) illustrates how the model segments a novel image by applying a single denoising step. Parts (c) through (f) present qualitative results, showcasing generated images and their corresponding segmentations, alongside real images and their segmented counterparts. The results highlight the model’s ability to generate high-quality images and accurate semantic segmentations.
read the caption
Figure 1: Unifying image generation and segmentation. (a) We design a denoising diffusion model with a specific architecture that couples region prediction with spatially-masked diffusion over predicted regions, thereby generating both simultaneously. (b) An additional byproduct of running our trained denoising model on an arbitrary input image is a segmentation of that image. Using a model trained on FFHQ [31], we achieve both high quality synthesis of images and corresponding semantic segmentations (c-d), as well as the ability to accurately segment images of real faces (e-f). Segmenting a real image is fast, requiring only one forward pass (one denoising step).

🔼 This figure shows example results for image segmentation on the ImageNet dataset. The left panel displays the input images and the right panel shows the corresponding segmentation masks generated by the proposed model. The masks accurately delineate various objects in the images, demonstrating the model’s ability to perform accurate unsupervised image segmentation.
read the caption
Figure 6: Segmentation on ImageNet.

🔼 This figure shows the results of the proposed method on the Flower dataset. The left panel displays the original flower images, and the right panel shows the corresponding segmentation masks generated by the model. Each mask highlights the main flower region in each image, demonstrating the model’s ability to accurately segment the foreground flower object from the background. The results visually illustrate the model’s ability to perform accurate unsupervised segmentation.
read the caption
Figure 3: Segmentation on Flower.

🔼 This figure shows the results of applying the proposed method for image segmentation on the CUB dataset. The left panel shows example images from the CUB dataset and the right panel presents the corresponding segmentations produced by the model. The segmentations highlight different regions within the images, indicating the model’s ability to successfully delineate object boundaries and separate foreground from background.
read the caption
Figure 4: Segmentation on CUB.

🔼 This figure shows the results of applying the proposed unsupervised image segmentation method to the ImageNet dataset. It displays a grid of real images from ImageNet (a) alongside their corresponding generated segmentations (b). The segmentations highlight different image regions, demonstrating the model’s ability to accurately segment various object categories without any explicit supervision during training.
read the caption
Figure 6: Segmentation on ImageNet.

🔼 This figure shows the core idea of the paper: unifying image generation and segmentation using a denoising diffusion model. It demonstrates the model’s ability to simultaneously generate images and their corresponding semantic segmentations. Panel (a) illustrates the architecture, (b) shows how segmentation is achieved on a new image, while (c-f) display example outputs: generated images and segmentations, and real images and their corresponding segmentations. The efficiency of segmenting real images (one forward pass) is highlighted.
read the caption
Figure 1: Unifying image generation and segmentation. (a) We design a denoising diffusion model with a specific architecture that couples region prediction with spatially-masked diffusion over predicted regions, thereby generating both simultaneously. (b) An additional byproduct of running our trained denoising model on an arbitrary input image is a segmentation of that image. Using a model trained on FFHQ [31], we achieve both high quality synthesis of images and corresponding semantic segmentations (c-d), as well as the ability to accurately segment images of real faces (e-f). Segmenting a real image is fast, requiring only one forward pass (one denoising step).
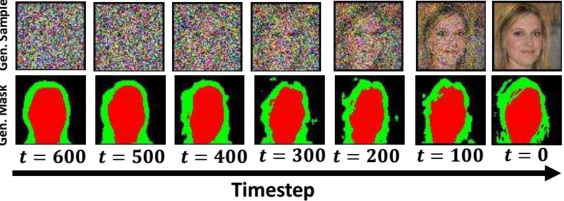
🔼 This figure visualizes the gradual refinement of both image and mask generation as denoising steps approach t=0 in the reverse diffusion process. It demonstrates the progressive improvement of the generated image and its corresponding mask from noisy initial state to a clear and well-defined final output, highlighting the DDPM’s ability to refine both aspects simultaneously during denoising.
read the caption
Figure 11: Gen. refinement along diffusion.

🔼 This figure shows interpolations of images from the FFHQ dataset using the model trained in the paper. The interpolations are generated by taking two images from the dataset as starting points and generating a sequence of intermediate images. The interpolations show a smooth transition between the two input images. The bottom row of images shows the corresponding heatmaps. These interpolations demonstrate the model’s ability to generate realistic and varied images.
read the caption
Figure 12: Interpolations on FFHQ with 250 timesteps of diffusion.

🔼 This figure shows the results of applying the proposed model on the PASCAL VOC 2012 dataset. The left panel displays example images from the dataset, and the right panel shows the corresponding segmentation masks generated by the model. The model accurately segments various objects such as airplanes, boats, laptops and people demonstrating its ability to perform zero-shot object segmentation on unseen data.
read the caption
Figure 13: Segmentation on VOC-2012.

🔼 This figure illustrates a hierarchical factorized diffusion architecture. Instead of a single level of region factorization, it uses multiple levels. The first level performs initial region segmentation, and each subsequent level refines the segmentation. Each level employs the factorized diffusion architecture shown in Figure 2, using the previous level’s output as input. The final segmentation is a combination of results from all levels.
read the caption
Figure 15: Hierarchical factorized diffusion architecture.

🔼 This figure illustrates a hierarchical extension of the factorized diffusion model. Instead of a single level of region mask generation and parallel decoding, it shows a multi-level approach. The first level generates coarse region masks, which are then used as input for the subsequent level. Each level refines the segmentation, leading to increasingly detailed region masks. The diagram shows three levels, though the architecture could support more. Each level uses a factorized diffusion process, with separate decoding branches for each region. The final output is a combination of the region masks from all levels, representing a hierarchical segmentation.
read the caption
Figure 15: Hierarchical factorized diffusion architecture.
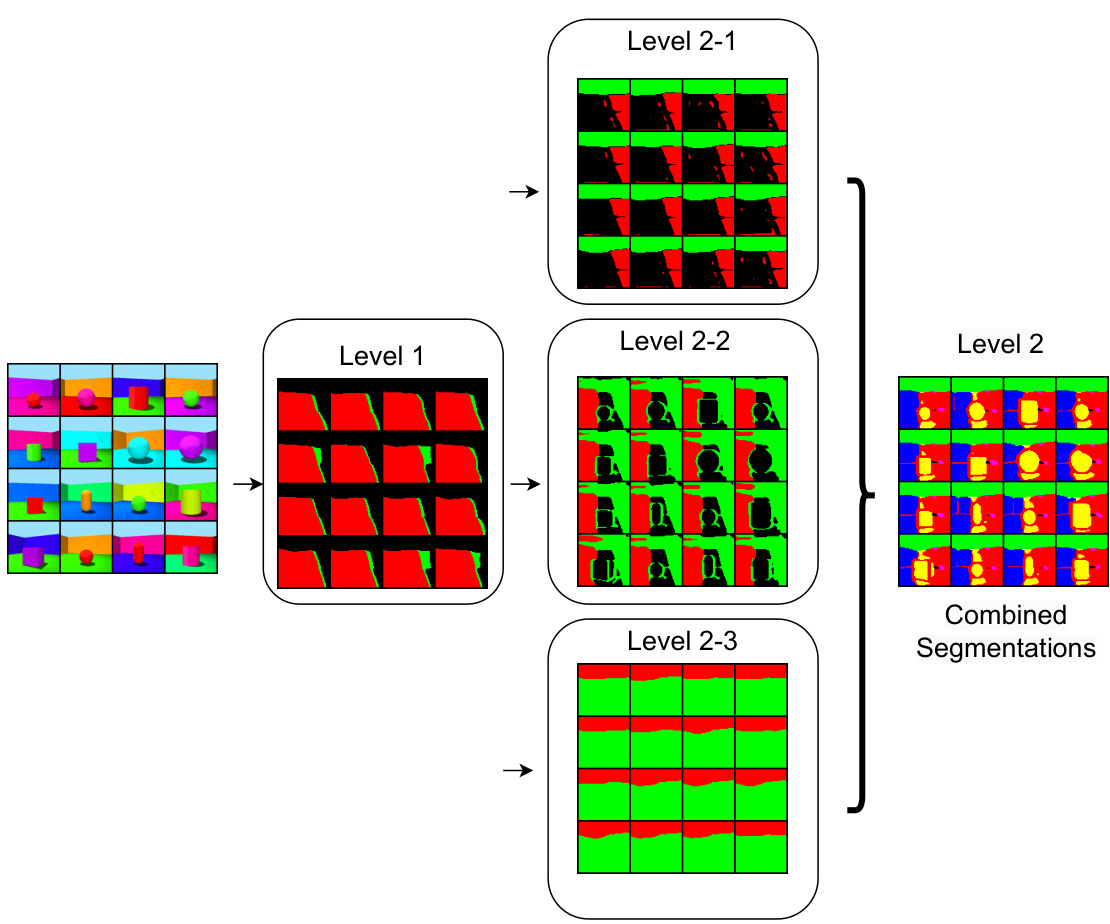
🔼 This figure illustrates the proposed hierarchical factorized diffusion architecture. It expands on the single-level architecture from Figure 2 by adding a second level of factorized diffusion. The first level (Level 1) generates coarse region masks, which are then used as input for the second level (Level 2). The second level further refines the segmentation into finer-grained regions. Each branch at each level processes different segments in parallel, leading to a multi-level segmentation. This hierarchical approach allows for capturing both global context and finer details in the segmentation task.
read the caption
Figure 15: Hierarchical factorized diffusion architecture.
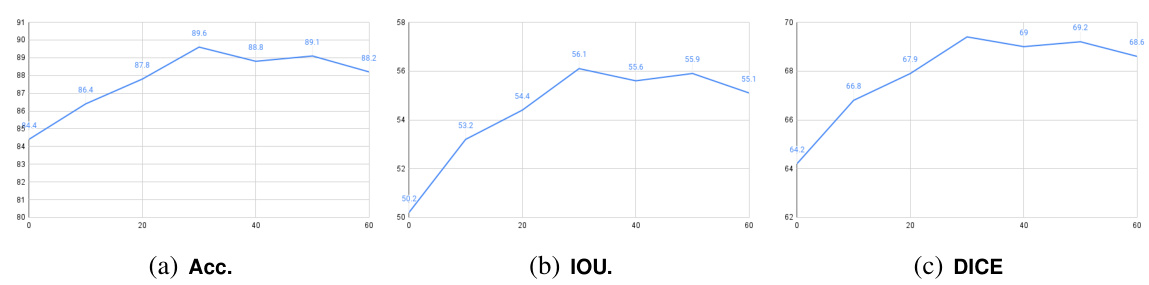
🔼 This figure shows the segmentation results on the CUB dataset with varying noise levels (t). The x-axis represents the noise level, and the y-axis represents the performance metrics: Accuracy (Acc.), Intersection over Union (IOU), and Dice score (DICE). Each line graph plots the trend of one of these metrics as the noise level increases. This allows for observation of how segmentation accuracy changes in relation to the amount of noise added to the image before denoising.
read the caption
Figure 18: Segmentation results on CUB with t ∈ {0, 10, 20, 30, 40, 50, 60}.

🔼 This figure shows the results of applying the proposed method for image segmentation on the Flower dataset. The left panel displays a grid of real images from the dataset, and the right panel shows the corresponding segmentations generated by the model. Each segmentation mask highlights different regions within the flower images, demonstrating the model’s ability to identify and separate various components of the flowers.
read the caption
Figure 3: Segmentation on Flower.

🔼 This figure shows the results of applying the proposed method to the CUB dataset. The left panel shows the original images of birds, and the right panel displays the corresponding segmentations generated by the model. The segmentations highlight the different regions of the birds, such as the body, head, beak, etc. This demonstrates the model’s ability to accurately segment objects within images.
read the caption
Figure 4: Segmentation on CUB.
🔼 This figure shows the core idea of the paper, which is to unify image generation and segmentation using a denoising diffusion model. The model is designed with a specific architecture that learns to both generate images and segment them simultaneously, without any explicit annotation during training. Panel (a) illustrates the simultaneous generation of images and their corresponding regions. Panel (b) demonstrates how the model can segment a new input image by simply performing a single denoising step. Panels (c) through (f) show examples of image generation, region generation (segmentation), real images, and their corresponding segmentations, respectively.
read the caption
Figure 1: Unifying image generation and segmentation. (a) We design a denoising diffusion model with a specific architecture that couples region prediction with spatially-masked diffusion over predicted regions, thereby generating both simultaneously. (b) An additional byproduct of running our trained denoising model on an arbitrary input image is a segmentation of that image. Using a model trained on FFHQ [31], we achieve both high quality synthesis of images and corresponding semantic segmentations (c-d), as well as the ability to accurately segment images of real faces (e-f). Segmenting a real image is fast, requiring only one forward pass (one denoising step).
🔼 This figure demonstrates the model’s ability to perform both image generation and segmentation simultaneously and independently. (a) shows the architecture, where a denoising diffusion model predicts regions and then denoises them in parallel. (b) shows how the model segments a new image with a single forward pass. (c) and (d) showcase generated images and their corresponding segmentations. (e) and (f) illustrate the model’s performance on real images.
read the caption
Figure 1: Unifying image generation and segmentation. (a) We design a denoising diffusion model with a specific architecture that couples region prediction with spatially-masked diffusion over predicted regions, thereby generating both simultaneously. (b) An additional byproduct of running our trained denoising model on an arbitrary input image is a segmentation of that image. Using a model trained on FFHQ [31], we achieve both high quality synthesis of images and corresponding semantic segmentations (c-d), as well as the ability to accurately segment images of real faces (e-f). Segmenting a real image is fast, requiring only one forward pass (one denoising step).

🔼 This figure shows the results of applying the proposed unsupervised image segmentation method on the Flower dataset. Subfigure (a) displays a grid of example images from the Flower dataset, while subfigure (b) presents the corresponding segmentation masks generated by the model. The masks visually delineate the different regions within each image, demonstrating the model’s ability to perform accurate unsupervised segmentation of natural images. The segmentation masks are monochromatic, effectively showing the segmentation’s boundaries.
read the caption
Figure 3: Segmentation on Flower.

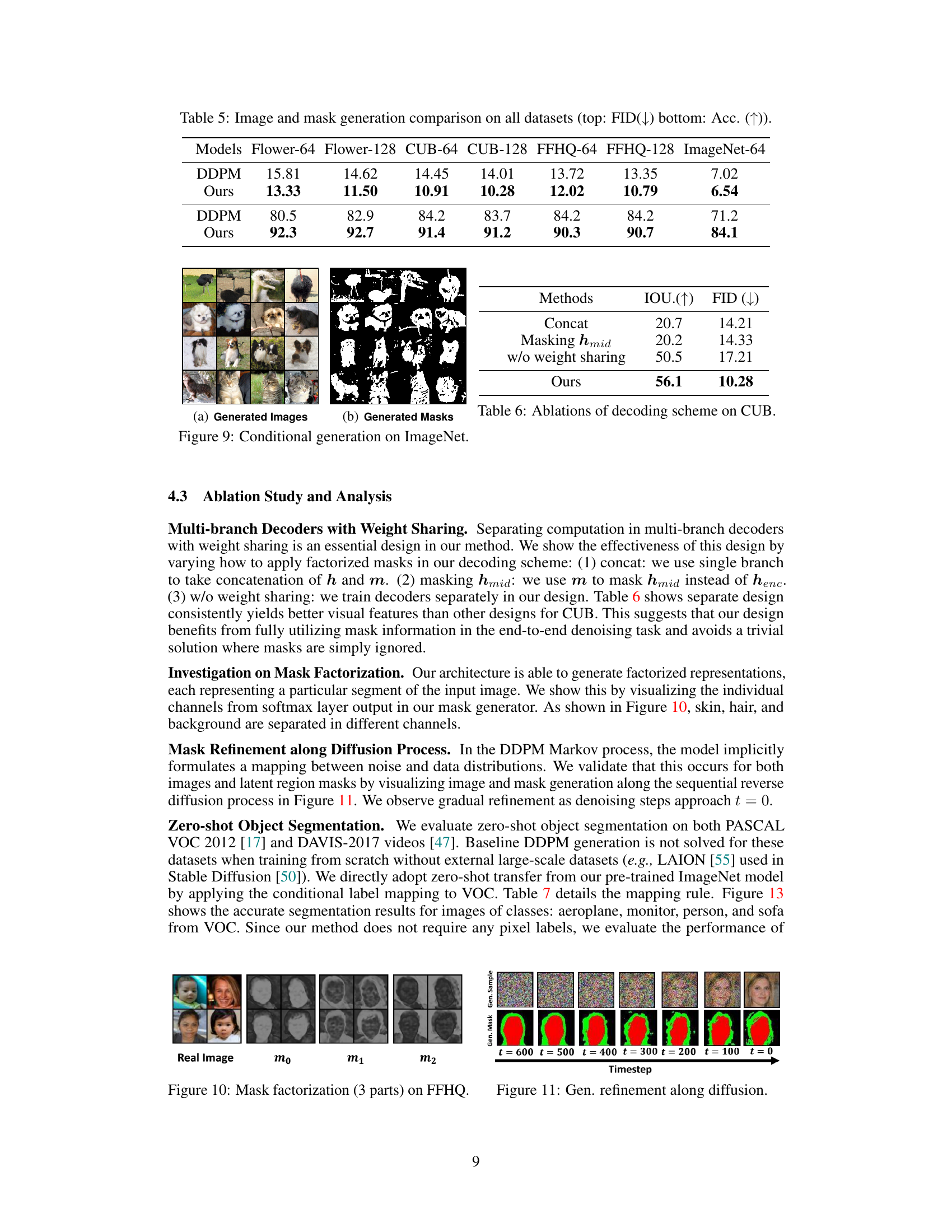
🔼 This figure shows samples of generated images and their corresponding generated masks from the Flower dataset. The left panel displays a grid of generated images of flowers, demonstrating the model’s ability to synthesize diverse and realistic flower images. The right panel shows the corresponding generated masks, which segment the images into regions representing different parts of the flowers, such as petals, leaves, and stems.
read the caption
Figure 7: Generation on Flower.

🔼 This figure shows the results of image and mask generation on the Flower dataset. The left panel displays a grid of generated images, demonstrating the model’s ability to synthesize realistic flower images with varying compositions and backgrounds. The right panel presents corresponding generated masks, highlighting the model’s capacity to simultaneously segment these images into meaningful regions. The masks effectively delineate different components within each flower image, showcasing the model’s understanding of visual structure and object boundaries.
read the caption
Figure 7: Generation on Flower.

🔼 This figure demonstrates the model’s ability to perform both image generation and segmentation simultaneously. Panel (a) shows the model architecture, illustrating how region prediction and masked diffusion are coupled. Panel (b) shows how the model segments a novel input image, using only one forward pass. Panels (c) and (d) showcase generated images and their corresponding segmentations. Panels (e) and (f) demonstrate accurate segmentation of real images.
read the caption
Figure 1: Unifying image generation and segmentation. (a) We design a denoising diffusion model with a specific architecture that couples region prediction with spatially-masked diffusion over predicted regions, thereby generating both simultaneously. (b) An additional byproduct of running our trained denoising model on an arbitrary input image is a segmentation of that image. Using a model trained on FFHQ [31], we achieve both high quality synthesis of images and corresponding semantic segmentations (c-d), as well as the ability to accurately segment images of real faces (e-f). Segmenting a real image is fast, requiring only one forward pass (one denoising step).

🔼 This figure shows the results of conditional image generation on the ImageNet dataset. The left panel (a) displays a grid of generated images, showcasing the model’s ability to synthesize various ImageNet classes. The right panel (b) presents the corresponding generated masks for each image, demonstrating the model’s simultaneous segmentation capabilities. The figure visually exemplifies the model’s proficiency in generating diverse and realistic images while simultaneously outputting accurate semantic segmentations. This is a key finding of the paper, showcasing the unified approach to image generation and segmentation.
read the caption
Figure 27: Conditional ImageNet generation.

🔼 This figure shows the results of zero-shot object segmentation on the PASCAL VOC 2012 dataset. The left panel displays example images from the dataset, while the right panel shows the corresponding segmentations produced by the proposed model. The model successfully identifies and segments various objects such as bicycles, chairs, potted plants, and trains, demonstrating its ability to generalize to unseen data.
read the caption
Figure 28: Segmentation on VOC-2012.

🔼 This figure shows the results of applying the proposed method to the DAVIS-2017 dataset. It displays frames from two videos, ‘classic-car’ and ‘dance-jump’, alongside their corresponding segmentations generated by the model. The segmentations demonstrate the model’s ability to accurately identify and delineate objects in video sequences, even without any video-specific training.
read the caption
Figure 29: Segmentation on DAVIS-2017.

🔼 This figure demonstrates the model’s ability to perform both image generation and image segmentation simultaneously in an unsupervised manner. It shows the architecture (a) where region prediction is coupled with diffusion, the process of segmenting a new image (b), examples of generated images and their corresponding segmentations (c, d), and finally examples of real images and their segmentations (e, f). The key takeaway is that the model achieves both tasks without any annotations or prior knowledge.
read the caption
Figure 1: Unifying image generation and segmentation. (a) We design a denoising diffusion model with a specific architecture that couples region prediction with spatially-masked diffusion over predicted regions, thereby generating both simultaneously. (b) An additional byproduct of running our trained denoising model on an arbitrary input image is a segmentation of that image. Using a model trained on FFHQ [31], we achieve both high quality synthesis of images and corresponding semantic segmentations (c-d), as well as the ability to accurately segment images of real faces (e-f). Segmenting a real image is fast, requiring only one forward pass (one denoising step).
More on tables
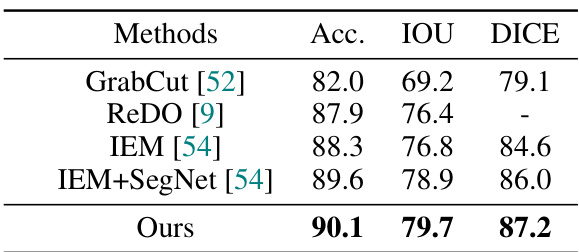
🔼 This table presents a comparison of the proposed method’s performance on the Flower dataset against several other methods for unsupervised image segmentation. The metrics used for comparison are Accuracy (Acc.), Intersection over Union (IOU), and Dice coefficient (DICE). Higher values in all three metrics indicate better performance. The table shows that the proposed method achieves state-of-the-art results on the Flower dataset.
read the caption
Table 1: Comparisons on Flower.
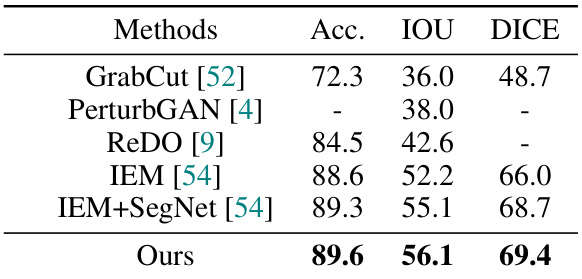
🔼 This table compares the performance of different unsupervised image segmentation methods on the CUB dataset. The methods compared are GrabCut, PerturbGAN, ReDO, IEM, IEM+SegNet, and the proposed method. The metrics used for comparison are Accuracy (Acc.), Intersection over Union (IOU), and Dice coefficient (DICE). The results show that the proposed method outperforms other methods on all three metrics.
read the caption
Table 2: Comparisons on CUB.
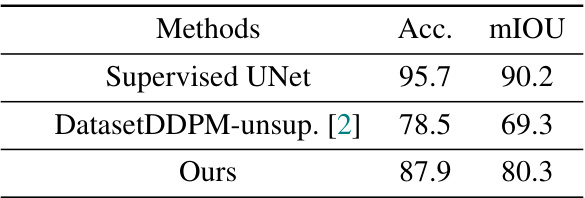
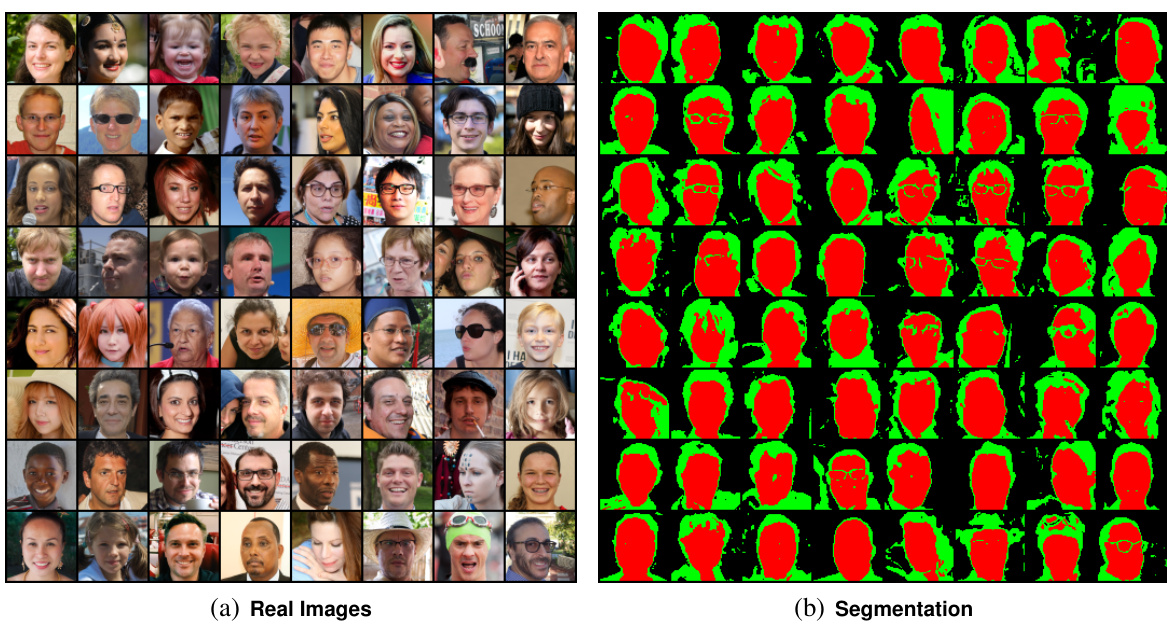
🔼 This table compares the performance of three different methods on the CelebA dataset for semantic segmentation. The methods are: a supervised UNet (a fully supervised model), DatasetDDPM-unsup (an unsupervised method using a pre-trained diffusion model), and the proposed method (Ours). The comparison uses two metrics: Accuracy (Acc.) and mean Intersection over Union (mIOU). The results show that the proposed method significantly outperforms the unsupervised baseline and achieves performance close to the fully supervised model.
read the caption
Table 3: Seg. comparisons on CelebA.
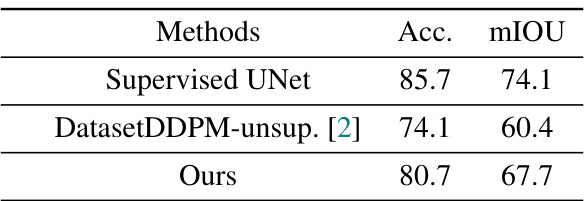
🔼 This table compares the performance of three different methods on the ImageNet dataset for semantic segmentation. The methods are a supervised UNet, the unsupervised DatasetDDPM approach, and the proposed method from the paper. The metrics used for comparison are accuracy (Acc.) and mean Intersection over Union (mIOU). The results show that the proposed method outperforms the unsupervised baseline and achieves comparable performance to the fully supervised UNet.
read the caption
Table 4: Seg. comparisons on ImageNet.

🔼 This table presents a comparison of image and mask generation results across multiple datasets using two different models: DDPM and the proposed model. For each dataset (Flower-64, Flower-128, CUB-64, CUB-128, FFHQ-64, FFHQ-128, ImageNet-64), the table shows the Fréchet Inception Distance (FID) score, a lower score indicating better image quality, and the accuracy (Acc) of the generated masks. The top half of the table shows FID scores, and the bottom half shows accuracy scores. The proposed model consistently outperforms the DDPM baseline in both image quality (lower FID) and mask accuracy (higher Acc).
read the caption
Table 5: Image and mask generation comparison on all datasets (top: FID(↓) bottom: Acc. (↑)).

🔼 This table presents the ablation study results on the CUB dataset for different decoding schemes. It compares the performance of three variations of the proposed model architecture against the baseline model. The variations modify how the factorized mask interacts with the decoder: concatenation, masking intermediate features, and parallel decoding without weight sharing. The performance is measured using Intersection over Union (IOU) and Fréchet Inception Distance (FID). The table demonstrates the effectiveness of the proposed weight-sharing multi-branch decoder in achieving better performance.
read the caption
Table 6: Ablations of decoding scheme on CUB.

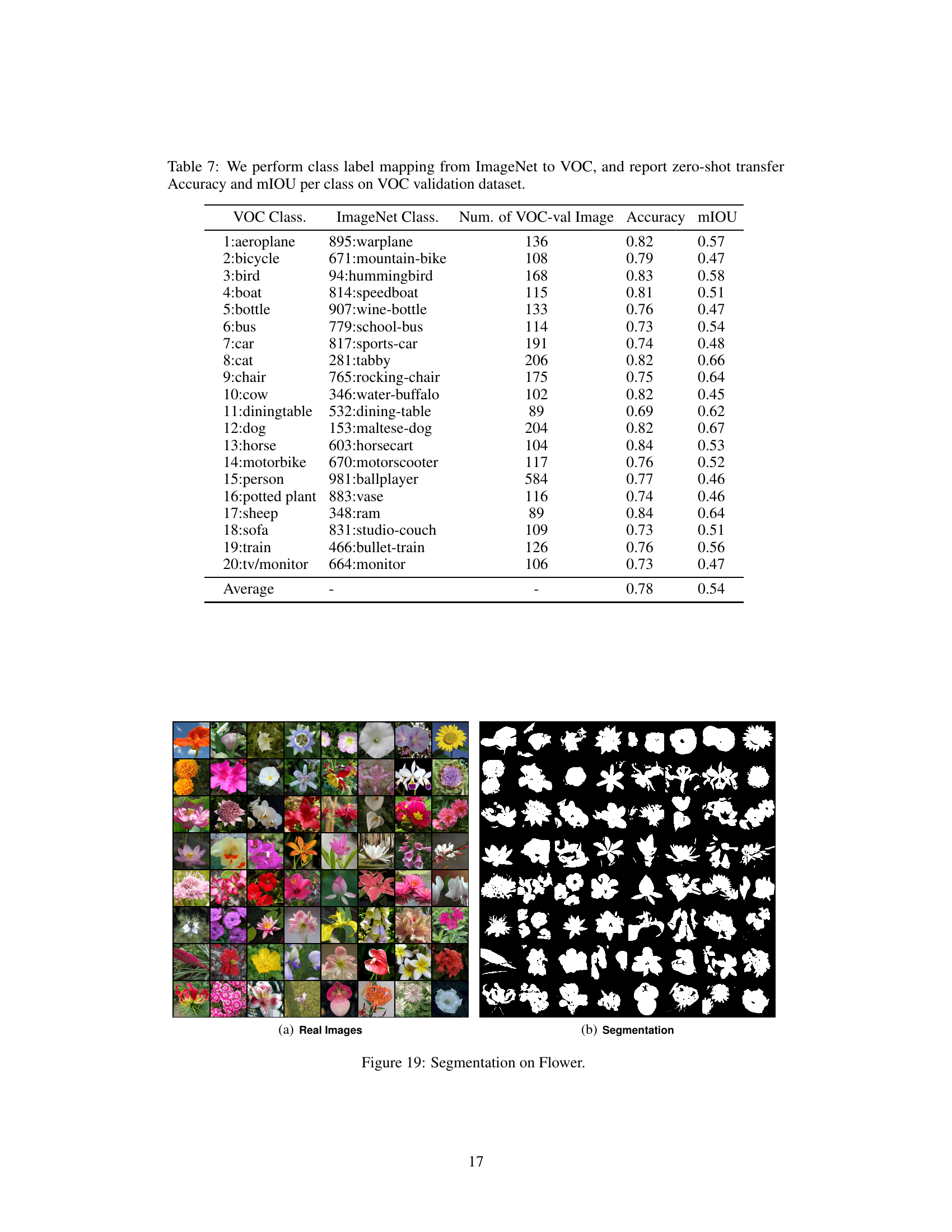
🔼 This table presents the results of zero-shot transfer experiments on the PASCAL VOC 2012 dataset. The authors mapped ImageNet classes to VOC classes and then evaluated the accuracy and mean Intersection over Union (mIOU) of the resulting segmentations. The table shows the performance of the proposed model on each individual VOC class, along with the average accuracy and mIOU across all classes.
read the caption
Table 7: We perform class label mapping from ImageNet to VOC, and report zero-shot transfer Accuracy and mIOU per class on VOC validation dataset.
Full paper#