TL;DR#
Existing methods for initializing variable-sized Vision Transformers (ViTs) often involve manually designed transformations or transferring entire pre-trained models, leading to inefficiency and inflexibility. This limits adaptation to various resource constraints and downstream tasks. Furthermore, these methods often neglect the width dimension of the learngene, limiting its flexibility.
The proposed method, LeTs, tackles these issues by introducing learnable transformations. LeTs simultaneously trains a compact learngene module and a set of transformation matrices which learn to add layers and neurons. This allows flexible transformation along both the depth and width dimensions. The authors demonstrate LeTs’ superiority through extensive experiments, showing that it outperforms existing initialization methods and from-scratch training, while being more efficient.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on efficient model initialization and variable-sized models. It introduces a novel approach to initialize variable-sized Vision Transformers efficiently, addressing the limitations of existing methods. This is relevant to current trends in efficient deep learning and opens avenues for research on adaptive model architectures and transfer learning.
Visual Insights#

🔼 This figure illustrates three different approaches to building variable-sized vision transformers using the Learngene framework. (a) shows the basic Learngene approach where a compact learngene module is learned from a large model and then used to initialize variable-sized descendant models. (b) shows previous methods that used manually designed and depth-only transformations to adapt the learngene to different sizes. Finally, (c) presents the proposed LeTs method, which uses learnable transformations along both width and depth dimensions for more flexible and efficient variable-sized model initialization.
read the caption
Figure 1: (a) Learngene paradigm. (b) Manually-crafted and depth-only transformation. (c) Learnable transformation along both width and depth dimension.
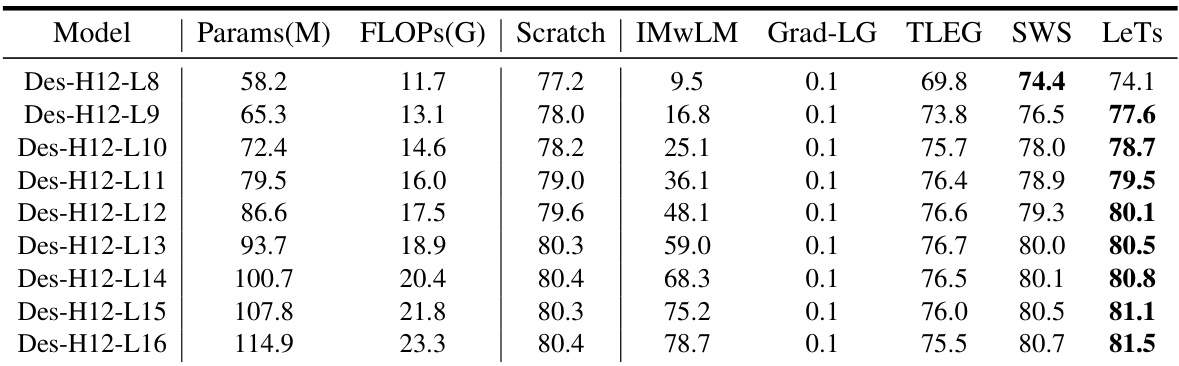
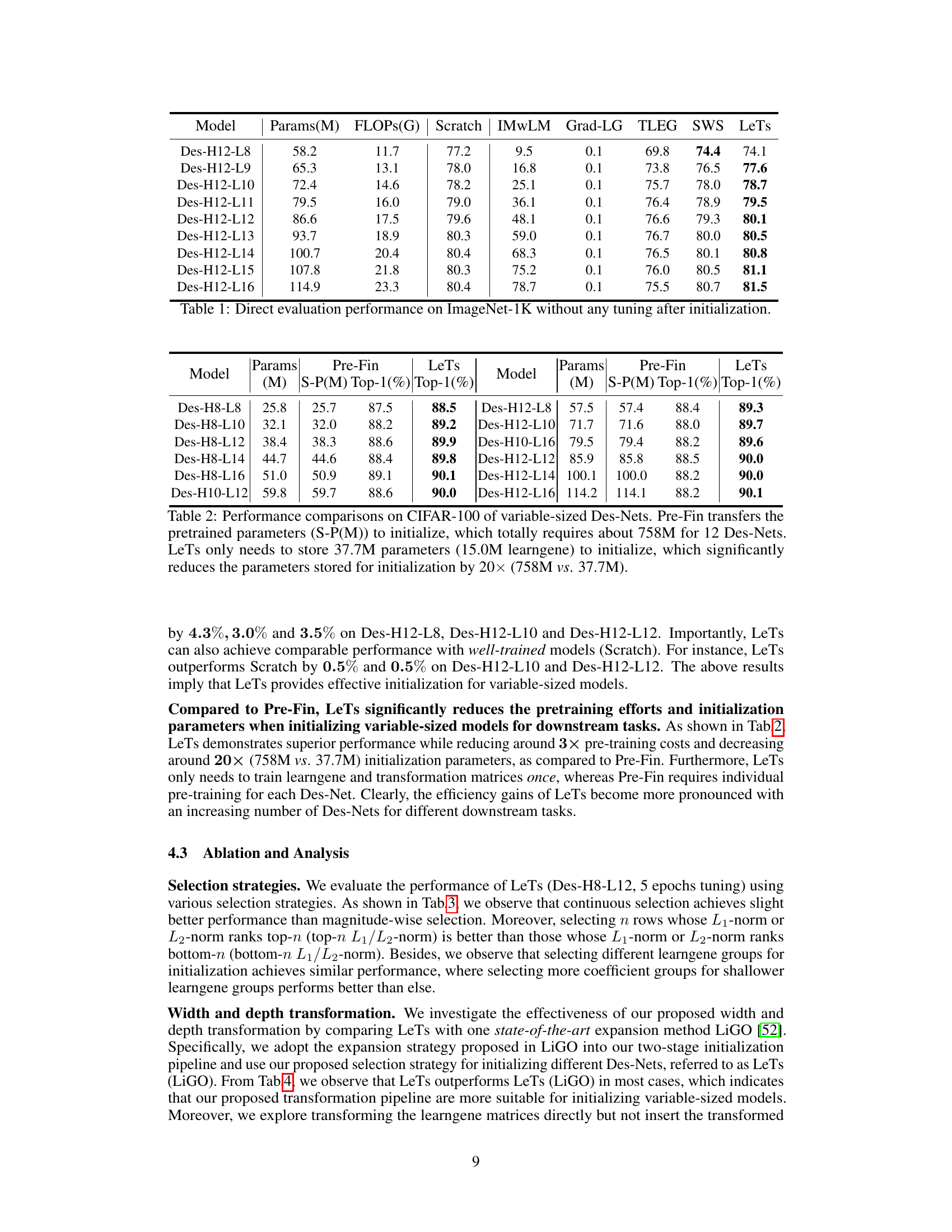
🔼 This table presents the Top-1 accuracy (%) achieved by different variable-sized Vision Transformer (ViT) models on the ImageNet-1K dataset without any fine-tuning after initialization. It compares the performance of models initialized using the proposed LeTs method against several baselines, including models trained from scratch and those initialized using other Learngene methods (IMwLM, Grad-LG, TLEG, SWS). The table shows that LeTs consistently outperforms the baselines, highlighting its effectiveness in improving initialization quality.
read the caption
Table 1: Direct evaluation performance on ImageNet-1K without any tuning after initialization.
In-depth insights#
Learnable Transforms#
The concept of “Learnable Transforms” in the context of a research paper likely revolves around adapting and optimizing transformations in a data processing pipeline in a data-driven way. Instead of manually designing fixed transformations, a learnable approach would involve training a model to learn the optimal transformations from data. This could involve neural networks or other machine learning models that learn the parameters of the transformation functions, allowing the system to adapt to different input characteristics or downstream tasks. A key advantage is flexibility and adaptability, surpassing traditional fixed transformations. However, designing and training such a model presents challenges regarding computational cost and the need for large, high-quality datasets. The effectiveness of the approach hinges on the successful learning of meaningful and generalizable transformations, which might require careful model architecture design and hyperparameter tuning. Therefore, a rigorous evaluation on diverse datasets is crucial to demonstrate its superiority over manually designed methods and assess its generalization capacity.
Efficient ViT Init#
Efficient ViT initialization methods aim to reduce computational costs and improve training efficiency for Vision Transformers (ViTs). Common approaches involve transferring knowledge from pre-trained models or leveraging compact learngene modules. Learnable transformations, as explored in the context of LeTs, offer a promising direction by learning to adapt a compact module to different ViT sizes. This approach goes beyond fixed, manually-defined transformations, enhancing flexibility and achieving potentially superior initialization quality. Careful selection strategies for transferring parameters from the learnable transformation matrices are crucial for effectiveness, balancing parameter efficiency and performance. The success of efficient ViT initialization hinges on finding the right balance between preserving knowledge from a well-trained source and effectively adapting it for the target architecture, ultimately accelerating training and reducing resource demands.
Width & Depth#
The concept of ‘Width & Depth’ in the context of neural networks, particularly vision transformers, refers to the dimensions along which model capacity can be scaled. Increasing width adds more neurons to each layer, enhancing the model’s ability to learn complex features and represent diverse data patterns. Increasing depth, on the other hand, involves adding more layers, allowing for hierarchical feature extraction and learning increasingly abstract representations. The interplay between width and depth is crucial; a deeper network might require less width to achieve comparable performance, and vice versa, offering a trade-off between computational cost and model accuracy. Finding the optimal balance is essential for building efficient and powerful models suited to specific resource constraints and task complexities. This often involves exploring different architectures and training strategies to determine the best combination of width and depth for maximum effectiveness. Learnable transformations offer a promising avenue to dynamically adjust these dimensions during training or inference to meet varying needs, improving both efficiency and adaptability.
LeTs’s Superiority#
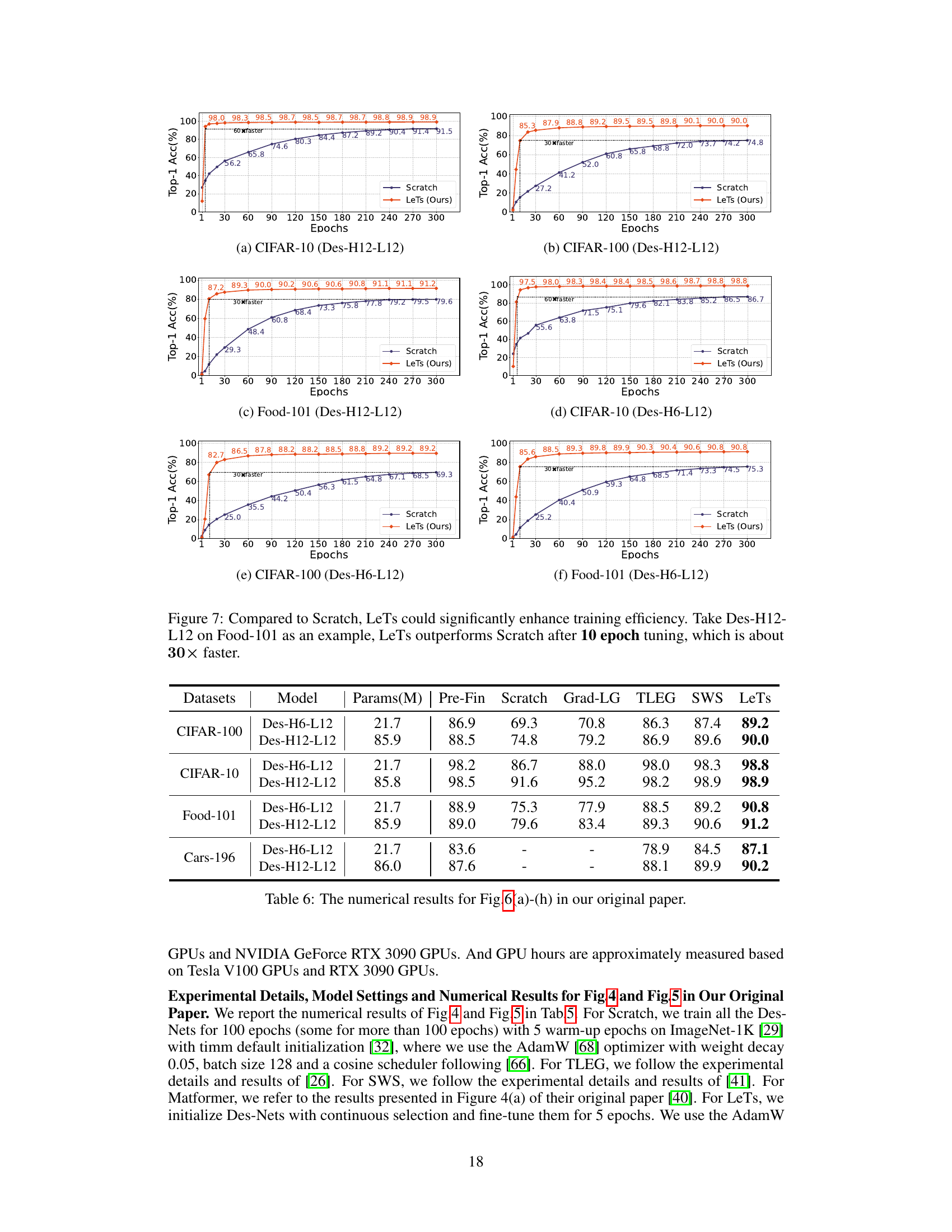
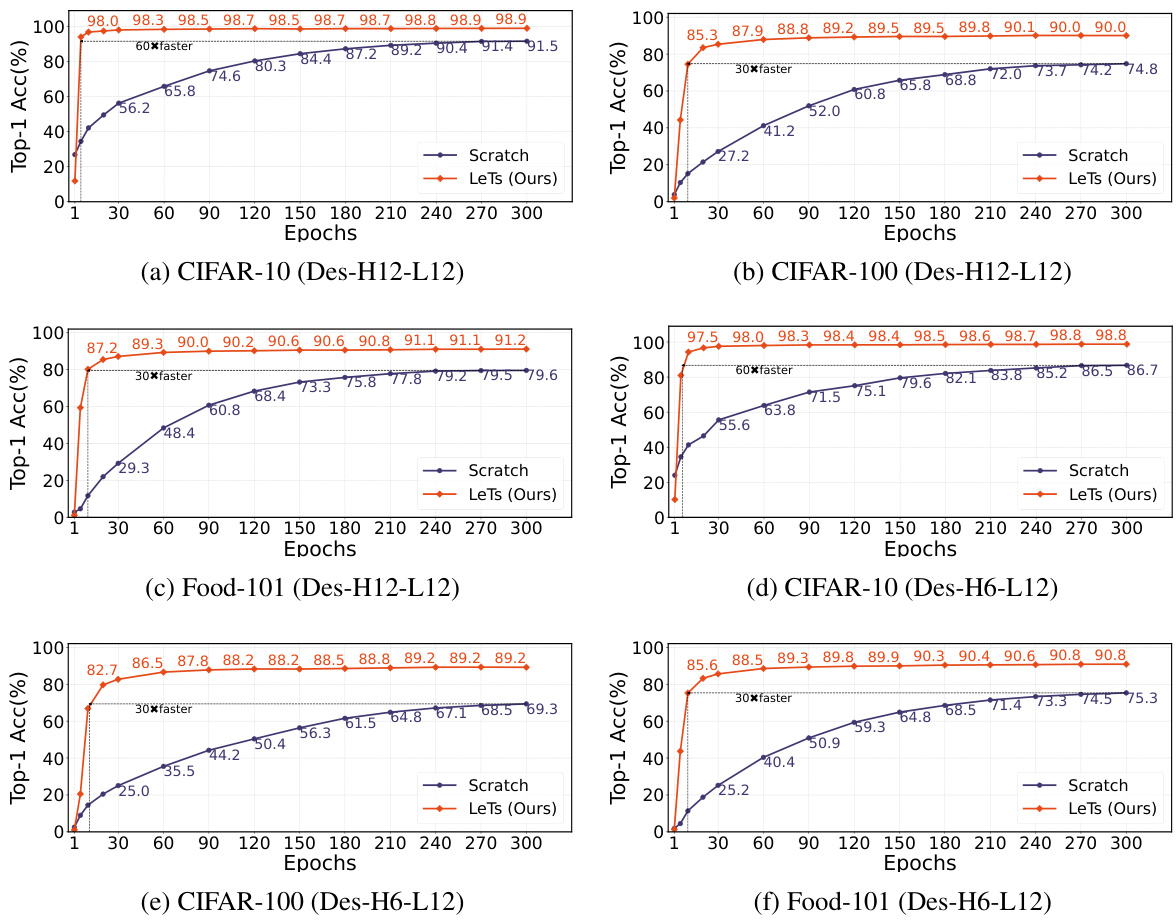
The paper showcases LeTs’s superiority through extensive experiments, demonstrating its effectiveness in initializing variable-sized vision transformers. LeTs outperforms models trained from scratch, achieving comparable or better accuracy after significantly fewer training epochs. This is particularly evident in transfer learning scenarios where LeTs initialized models achieve better results faster than those trained from scratch on downstream tasks. The efficiency gains are substantial, reducing both training time and computational resources. LeTs’s success stems from its innovative learnable transformation matrices, which adapt the compact ’learngene’ module to the specific requirements of variable-sized target models. This learnable transformation is a key differentiator from prior methods that relied on manual and less flexible transformations. The results highlight LeTs’s ability to improve initialization quality, leading to faster convergence and enhanced performance across various image classification and semantic segmentation tasks.
Future of LeTs#
The future of LeTs (Learnable Transformation) in Vision Transformer initialization hinges on several key areas. Extending LeTs to other network architectures beyond Vision Transformers is crucial for broader applicability. Improving the efficiency of the learnable transformation matrices is vital; exploring more efficient parameterization or training strategies could significantly reduce computational costs and improve scalability. Further research should focus on developing more sophisticated selection strategies for choosing parameters from the learned matrices, potentially incorporating task-specific information or incorporating advanced optimization methods. A deeper investigation into the theoretical underpinnings of LeTs would also be beneficial, providing a stronger understanding of its effectiveness and limitations. Finally, exploring the integration of LeTs with other model initialization or training techniques, such as knowledge distillation or meta-learning, could potentially lead to even more powerful and efficient methods for training large-scale vision models.
More visual insights#
More on figures
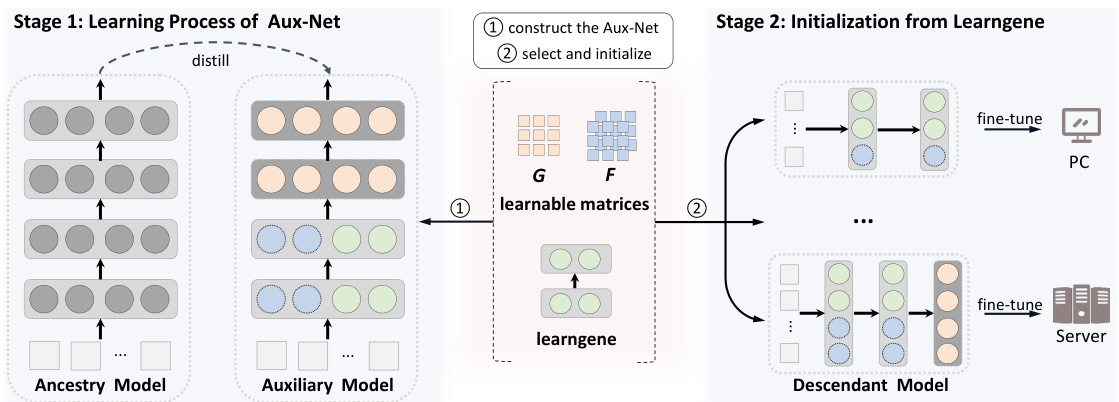
🔼 This figure illustrates the two-stage process of LeTs. Stage 1 involves constructing and training an auxiliary model (Aux-Net) using learngene and learnable transformation matrices (F and G) to learn how to add neurons and layers. Stage 2 uses these trained matrices to adapt learngene for initializing variable-sized descendant models (Des-Nets) based on specific parameter selection strategies for different downstream tasks, followed by fine-tuning.
read the caption
Figure 2: In stage 1, we construct and train an Aux-Net which is transformed from compact learngene layers using a series of learnable transformation matrices. During training, F and G learn to capture structural knowledge about how to add new neurons and layers into the compact learngene respectively. In stage 2, given the varying sizes of target Des-Nets, we select specific parameters from well-trained transformation matrices to transform learngene for initialization, which are fine-tuned lastly under different downstream scenarios.

🔼 This figure illustrates the three different approaches for transforming a compact learngene module to initialize variable-sized descendant models. (a) shows the basic Learngene paradigm, where a compact learngene is extracted from a large model and then transformed. (b) depicts previous methods that relied on manually designed and depth-only transformations, limiting flexibility. (c) presents the proposed LeTs method, which uses learnable transformations along both width and depth dimensions for greater flexibility and effectiveness in initializing variable-sized models.
read the caption
Figure 1: (a) Learngene paradigm. (b) Manually-crafted and depth-only transformation. (c) Learnable transformation along both width and depth dimension.
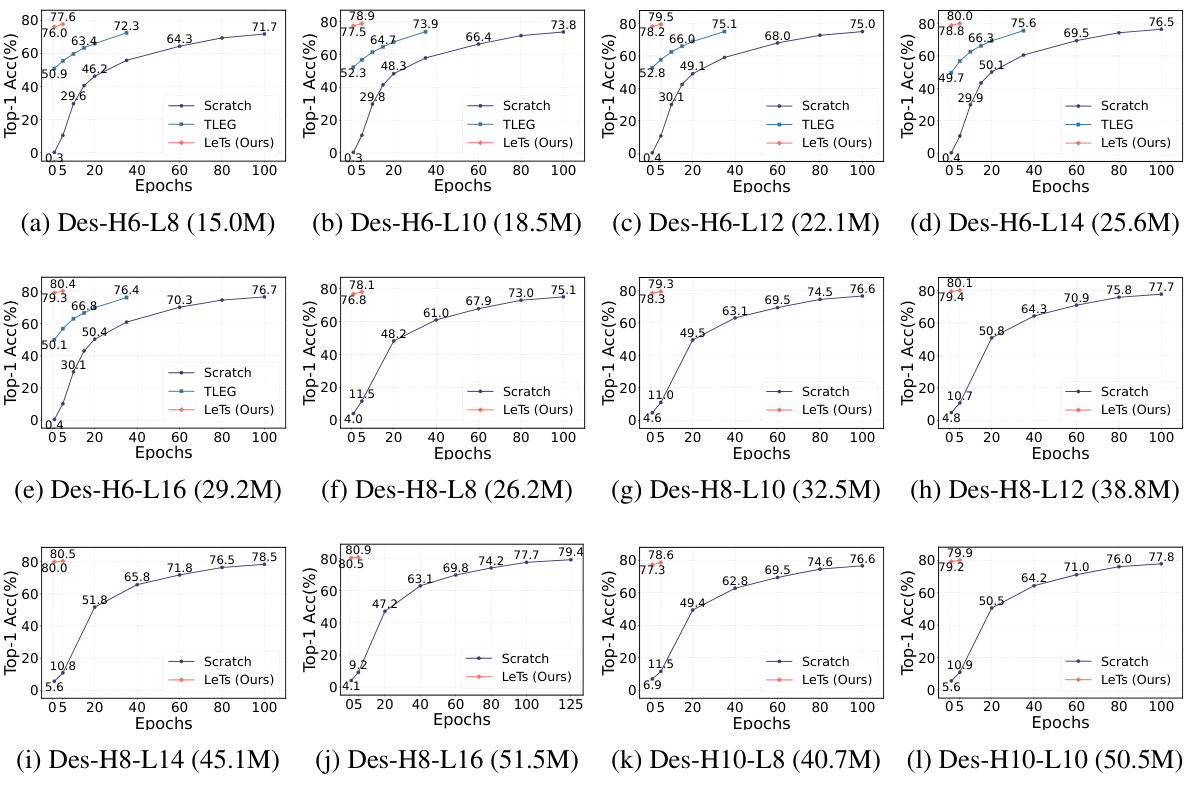
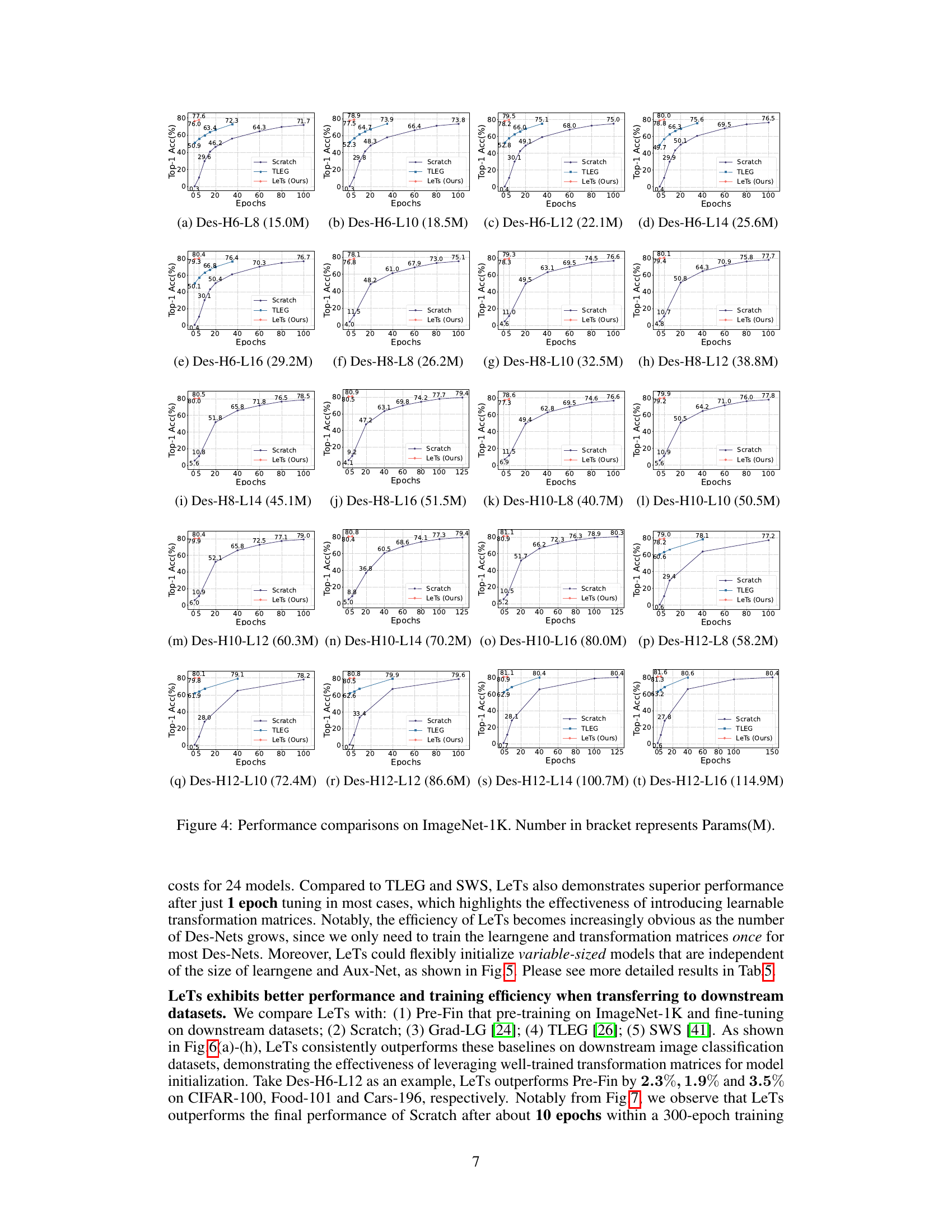
🔼 This figure compares the performance of LeTs against other methods (Scratch, TLEG, and SWS) on ImageNet-1K for various model sizes (indicated by the number of parameters in millions). The plots show the Top-1 accuracy over epochs. The results show that LeTs consistently achieves higher accuracy in fewer epochs compared to training from scratch, highlighting its superior performance and efficiency for initializing variable-sized vision transformer models.
read the caption
Figure 4: Performance comparisons on ImageNet-1K. Number in bracket represents Params(M).

🔼 This figure compares the performance of LeTs against other methods (Scratch, TLEG, and SWS) on ImageNet-1K. Multiple models of varying sizes (indicated by Params(M)) are evaluated. The graphs show the Top-1 accuracy over epochs, illustrating LeTs’ superior performance and efficiency, often achieving better results with significantly fewer training epochs than the other methods.
read the caption
Figure 4: Performance comparisons on ImageNet-1K. Number in bracket represents Params(M).

🔼 This figure compares the performance of LeTs with other methods (Scratch, TLEG, SWS) on ImageNet-1K. The x-axis represents the number of training epochs, and the y-axis represents the Top-1 accuracy. Multiple subplots show results for different model sizes (indicated by the parameter count in parentheses). LeTs consistently outperforms other methods after a small number of epochs, demonstrating its efficiency and improved model initialization.
read the caption
Figure 4: Performance comparisons on ImageNet-1K. Number in bracket represents Params(M).
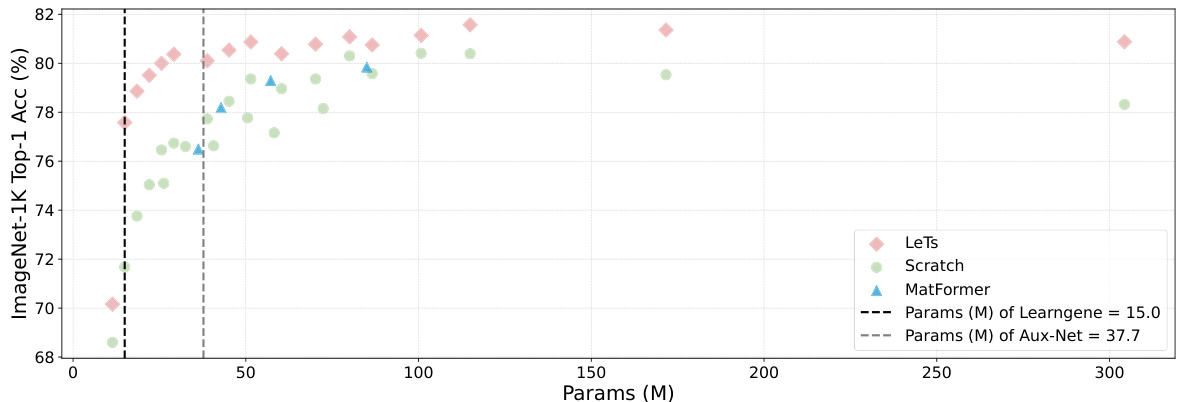
🔼 This figure compares the performance of LeTs, Scratch (training from scratch), and MatFormer in terms of ImageNet-1K Top-1 accuracy against the number of model parameters (in millions). LeTs consistently achieves higher accuracy with fewer parameters than both Scratch and MatFormer, highlighting its efficiency in initializing variable-sized models. The figure also indicates the parameter counts for the learngene (15.0M) and the auxiliary model (Aux-Net, 37.7M) used in the LeTs method.
read the caption
Figure 5: LeTs could flexibly initialize variable-sized models that are independent of the size of learngene and Aux-Net. Compared with Scratch and MatFormer [40], LeTs demonstrates more initialization efficiency.

🔼 This figure compares the performance of LeTs with other initialization methods (Scratch, TLEG, and SWS) on ImageNet-1K. The x-axis represents the training epochs, and the y-axis represents the Top-1 accuracy. Multiple lines are shown, each representing a different sized Vision Transformer (Des-Net) model, indicated by the number in the brackets which represents the number of parameters (in millions). The figure demonstrates that LeTs consistently outperforms other methods, especially after just one epoch of fine-tuning.
read the caption
Figure 4: Performance comparisons on ImageNet-1K. Number in bracket represents Params(M).
🔼 This figure presents the performance comparison on ImageNet-1K among different methods: Scratch (training from scratch for 100 epochs), TLEG, SWS, and LeTs (proposed method). The x-axis represents the number of training epochs, while the y-axis shows the Top-1 accuracy. Multiple subplots show the results for various model sizes (indicated by the parameter count in parentheses). The results demonstrate that LeTs significantly outperforms other methods, particularly after only one epoch of fine-tuning. The superior performance of LeTs highlights its effectiveness in producing high-quality initializations for various model sizes.
read the caption
Figure 4: Performance comparisons on ImageNet-1K. Number in bracket represents Params(M).
More on tables
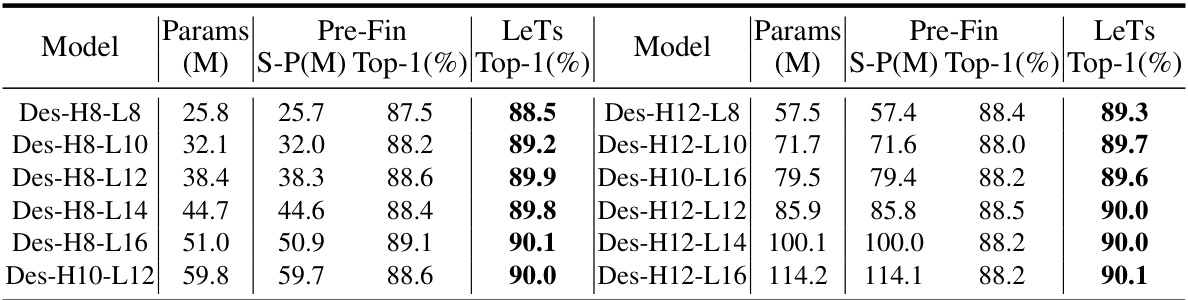
🔼 This table compares the performance of LeTs and Pre-Fin (pre-training and fine-tuning) on CIFAR-100 using variable-sized Des-Nets. It highlights LeTs’ superior performance and significantly reduced parameter requirements for initialization compared to Pre-Fin. The table demonstrates LeTs’ efficiency by showing a 20x reduction in the number of parameters needed for initialization.
read the caption
Table 2: Performance comparisons on CIFAR-100 of variable-sized Des-Nets. Pre-Fin transfers the pretrained parameters (S-P(M)) to initialize, which totally requires about 758M for 12 Des-Nets. LeTs only needs to store 37.7M parameters (15.0M learngene) to initialize, which significantly reduces the parameters stored for initialization by 20× (758M vs. 37.7M).
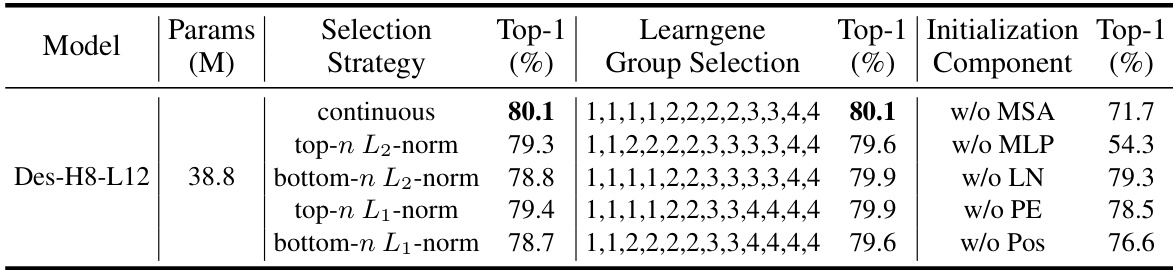
🔼 This table presents ablation studies on the LeTs model. It shows the impact of different parameter selection strategies (continuous, top-n L2-norm, bottom-n L2-norm, top-n L1-norm, bottom-n L1-norm) on the model’s performance on ImageNet-1K. It also shows the effect of various learngene group selections and the removal of certain components (MSA, MLP, LN, PE, Pos) on the final Top-1 accuracy. The results highlight the importance of careful parameter selection and the contribution of each component to the model’s performance.
read the caption
Table 3: Performance on ImageNet-1K when using different selection strategies, selecting different learngene groups and initializing Des-Nets without certain components.
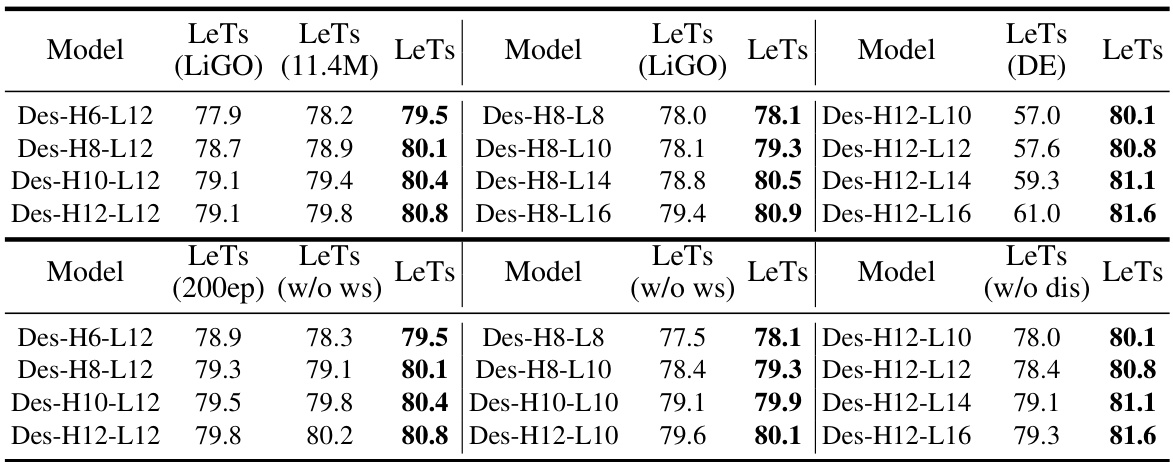
🔼 This table presents ablation study results on ImageNet-1K, comparing the performance of LeTs against several variations. It investigates the impact of different width and depth transformation methods (LiGO, direct transformation), reduced learngene size, parameter sharing in the depth transformation matrix, extended training epochs for Aux-Net, and the effect of removing the distillation process. The results show the impact of each component on the overall performance.
read the caption
Table 4: Performance on ImageNet-1K when using depth and width expansion strategies proposed in LiGO [52] (named as LeTs(LiGO)), training smaller learngene module (named as LeTs(11.4M)), direct transforming learngene matrices to compose target ones (named as LeTs(DE)), not sharing weights between rows of G (named as LeTs(w/o ws)), training Aux-Net for 200 epochs (named as LeTs(200ep)) and not adopting distillation in the first stage (LeTs(w/o dis)).
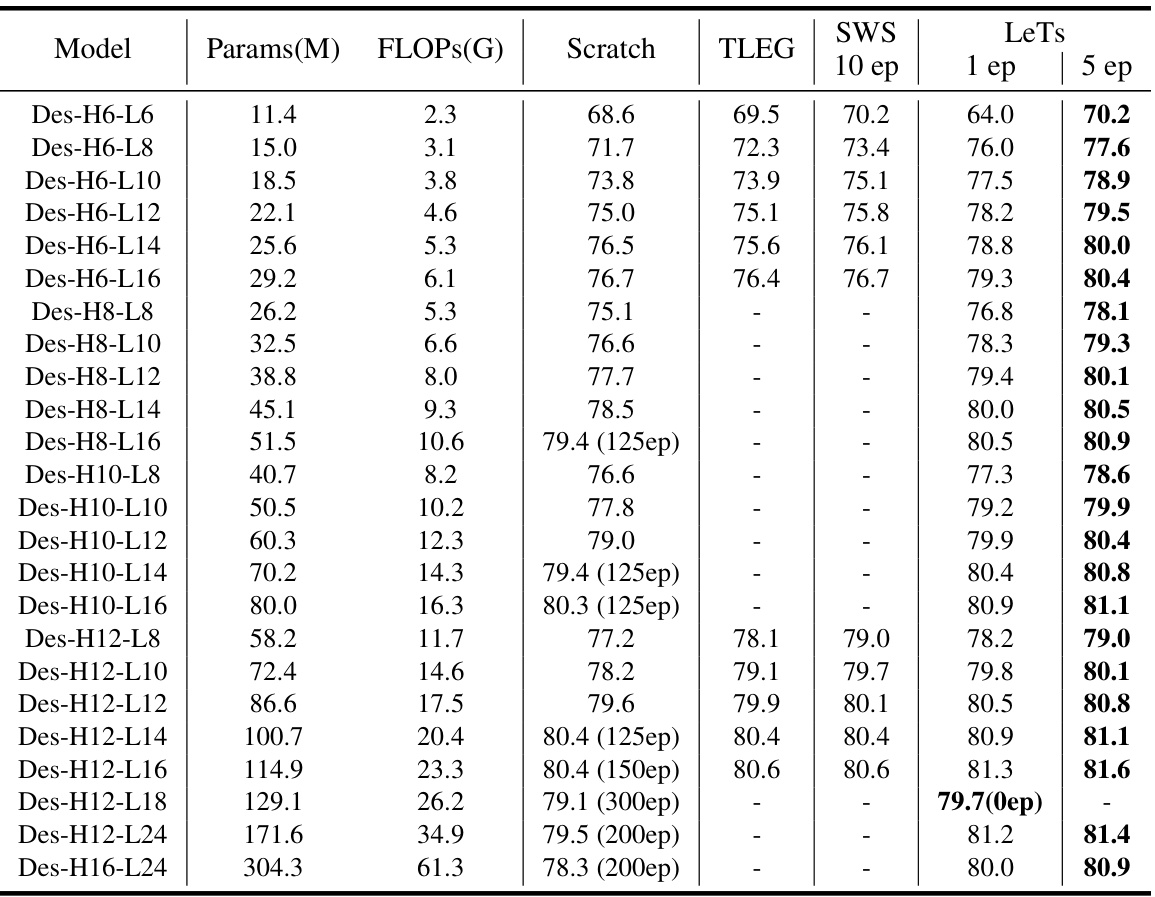
🔼 This table presents the performance comparison of different model sizes on ImageNet-1K. It compares the Top-1 accuracy of models initialized using different methods (Scratch, TLEG, SWS, and LeTs) after varying numbers of epochs of fine-tuning. The table highlights the superior performance of LeTs, showing that it significantly outperforms other initialization methods, even after only one epoch of fine-tuning. The number of parameters (Params(M)) and floating-point operations (FLOPS(G)) are also included for each model.
read the caption
Table 5: The numerical results for Fig.4 and Fig.5 in our original paper. The number of epochs is indicated in brackets within the 'Scratch' column, with the default being 100 epochs when no brackets are present.

🔼 This table presents a comparison of the Top-1 accuracy (%) achieved by different model initialization methods (Pre-Fin, Scratch, Grad-LG, TLEG, SWS, and LeTs) on four different image classification datasets (CIFAR-100, CIFAR-10, Food-101, and Cars-196) using two different model sizes (Des-H6-L12 and Des-H12-L12). The results show the performance of each method after a specified training period.
read the caption
Table 6: The numerical results for Fig.6(a)-(h) in our original paper.
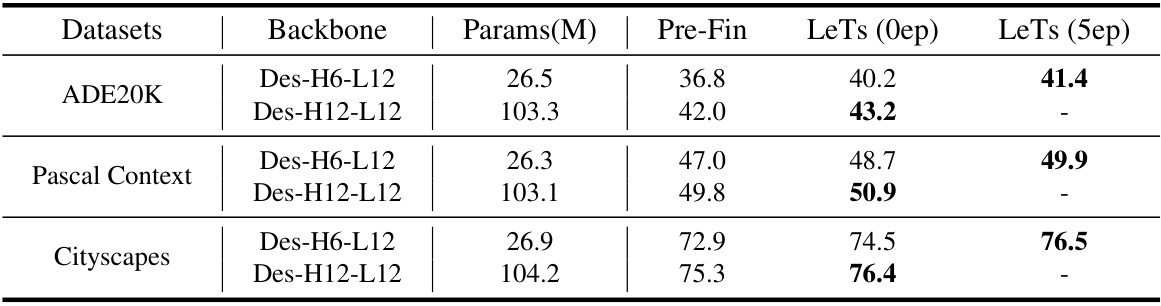
🔼 This table presents the performance comparison on three semantic segmentation datasets: ADE20K, Pascal Context, and Cityscapes. The results show the mean Intersection over Union (mIoU) scores achieved by three different methods: Pre-Fin (pre-training and fine-tuning), LeTs (0ep) (LeTs with 0 epochs of fine-tuning), and LeTs (5ep) (LeTs with 5 epochs of fine-tuning). Two backbone models, Des-H6-L12 and Des-H12-L12, were used for each dataset. The table highlights the improved performance of LeTs, especially with a small amount of fine-tuning, compared to the traditional pre-training and fine-tuning approach.
read the caption
Table 7: The numerical results for Fig.6(i)-(k) in our original paper.
Full paper#