TL;DR#
Diplomacy, a game demanding sophisticated negotiation and long-term strategic planning, has been a significant challenge for AI. Previous AI agents often relied on large amounts of human-generated data and struggled with the complex social dynamics inherent in the game, making it difficult to develop truly human-like AI players.
The researchers introduce Richelieu, an innovative LLM-based AI agent that tackles this challenge. Richelieu leverages the strengths of LLMs for natural language processing and reasoning but integrates a novel self-evolutionary mechanism based on self-play. This allows Richelieu to learn and improve without relying on human-provided data, surpassing state-of-the-art AI agents in performance. The agent’s design incorporates key capabilities such as strategic planning with memory and reflection, goal-oriented negotiation with social reasoning, and self-improvement through self-play. These features lead to superior performance against existing models.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI researchers working on multi-agent systems, game playing, and large language models. It demonstrates a novel approach to building sophisticated AI agents capable of complex strategic reasoning and negotiation, overcoming limitations of previous methods. The self-evolving framework and the detailed experimental results presented open exciting new avenues for future research in human-like AI development and advancing the capabilities of LLMs in complex decision-making scenarios.
Visual Insights#
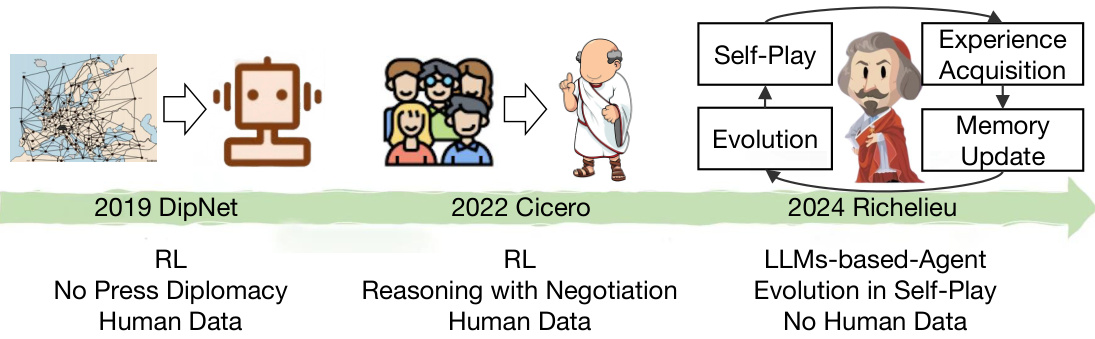
🔼 This figure illustrates the evolution of AI Diplomacy agents from 2019 to 2024. In 2019, DipNet used reinforcement learning (RL) and human data for no-press Diplomacy (no negotiation). In 2022, Cicero incorporated negotiation using RL and still relied on human data. In 2024, Richelieu represents a new paradigm, leveraging LLMs (Large Language Models), self-play for evolution, and eliminating the need for human data. This signifies a significant advancement in AI’s ability to handle complex social interactions and strategic planning in the game of Diplomacy.
read the caption
Figure 1: A new paradigm for building AI Diplomacy agent.

🔼 This table presents a comparison of the performance of the proposed Richelieu model against the Cicero model across four key metrics: Win Rate, Most Supply Centers (SC), Survived Rate, and Defeated Rate. The results are shown for multiple runs of each model, indicating the average performance across multiple game instances. This allows for a quantitative assessment of Richelieu’s performance relative to the state-of-the-art Cicero model.
read the caption
Table 1: The results of our method playing against Cicero.
In-depth insights#
LLM Diplomacy#
LLM Diplomacy explores the fascinating intersection of large language models (LLMs) and the complex strategic game of Diplomacy. It leverages LLMs’ natural language processing capabilities for sophisticated negotiation and planning in multi-agent environments. The core challenge lies in enabling LLMs to not only understand the rules of Diplomacy but also to exhibit strategic thinking, social reasoning, and long-term planning. This involves overcoming limitations inherent in LLMs, such as their tendency toward short-sightedness and their dependence on training data. Research in this area focuses on developing methods to enhance LLM agents’ ability to make strategic alliances, negotiate effectively, and adapt to the unpredictable actions of other players. Self-play and reinforcement learning are employed to improve agent performance without reliance on human-annotated data. Ultimately, LLM Diplomacy aims to create highly intelligent AI agents capable of mastering the intricacies of Diplomacy, providing valuable insights for both AI development and strategic game theory. Success in this field could lead to significant advancements in AI decision-making and game playing capabilities.
Self-Evolving Agents#
The concept of self-evolving agents represents a significant advancement in AI, particularly within the context of complex, multi-agent environments. These agents, unlike traditional AI systems, possess the capacity for autonomous adaptation and improvement over time. This is achieved through mechanisms like reinforcement learning and self-play, allowing the agents to learn from their successes and failures without direct human intervention. The implications are substantial, suggesting a potential shift toward more robust and adaptable AI systems capable of handling unpredictable situations and dynamic interactions, as seen in the paper’s application to AI Diplomacy. Self-play, in particular, is a crucial element, enabling agents to refine their strategies and develop increasingly sophisticated behavior by repeatedly interacting with themselves. Furthermore, the incorporation of memory and reflection enhances the ability of these agents to learn from past experiences, leading to more informed decision-making. The challenge lies in ensuring the ethical implications of such autonomous evolution are carefully considered and that adequate safeguards are put in place to prevent unintended or harmful consequences. Ultimately, self-evolving agents hold the promise of creating more powerful and effective AI systems, but this must be balanced with careful attention to their potential risks.
Multi-Agent Planning#
Multi-agent planning in AI research presents unique challenges due to the complexities of coordinating multiple agents with potentially conflicting goals and limited information. Effective strategies often involve decentralized approaches, where agents make decisions based on their local observations and communicate selectively with others. Game-theoretic models are frequently employed to analyze agent interactions and predict outcomes, helping to design algorithms that promote cooperation or competition as needed. The scalability of planning algorithms is a crucial concern, as the computational cost can grow exponentially with the number of agents. Therefore, approximation techniques and heuristic methods play a vital role in finding near-optimal solutions efficiently. Further research should focus on improving the robustness of multi-agent planners in dynamic and uncertain environments, as well as developing more sophisticated communication and coordination mechanisms. The integration of machine learning with classical planning techniques offers exciting prospects for creating adaptive and self-improving multi-agent systems.
Social Reasoning#
Social reasoning, in the context of AI agents interacting in complex scenarios like Diplomacy, involves understanding and modeling the relationships and intentions of other agents. It goes beyond simply observing actions; it requires inferring beliefs, motivations, and potential future actions of others based on incomplete and uncertain information. This sophisticated analysis is crucial for an AI agent to effectively navigate social dynamics, predict other agents’ behavior, and make strategic decisions that account for others’ responses. Building trust, detecting deception, and building rapport are key aspects of social reasoning, enabling an AI agent to form alliances, negotiate effectively, and ultimately achieve its goals within a multi-agent environment. The challenges lie in handling uncertainty, integrating information from diverse sources, and adapting to dynamic changes in social contexts. A successful social reasoning system must be robust to manipulation, capable of recognizing both explicit and implicit social cues, and able to learn and adapt its models of other agents over time.
Future of AI Diplomacy#
The future of AI diplomacy hinges on several key factors. Technological advancements in areas like large language models (LLMs) and reinforcement learning will enable agents to negotiate more effectively, reason strategically, and adapt to complex scenarios. However, ethical considerations are paramount, demanding careful attention to issues such as bias, transparency, and accountability. Robust safety mechanisms are needed to prevent unintended consequences and potential misuse. Beyond technical progress, international cooperation is crucial. Global standards and regulations governing the development and deployment of AI in diplomacy will be essential to ensure fairness, prevent conflicts, and foster trust. Human-AI collaboration, rather than complete automation, is likely to be the most fruitful path, harnessing AI’s capabilities while retaining human oversight and control. Ultimately, the future of AI diplomacy will be shaped by the complex interplay between technological innovation, ethical responsibility, and international collaboration, with a strong emphasis on the ethical implications and limitations of automated diplomatic action.
More visual insights#
More on figures
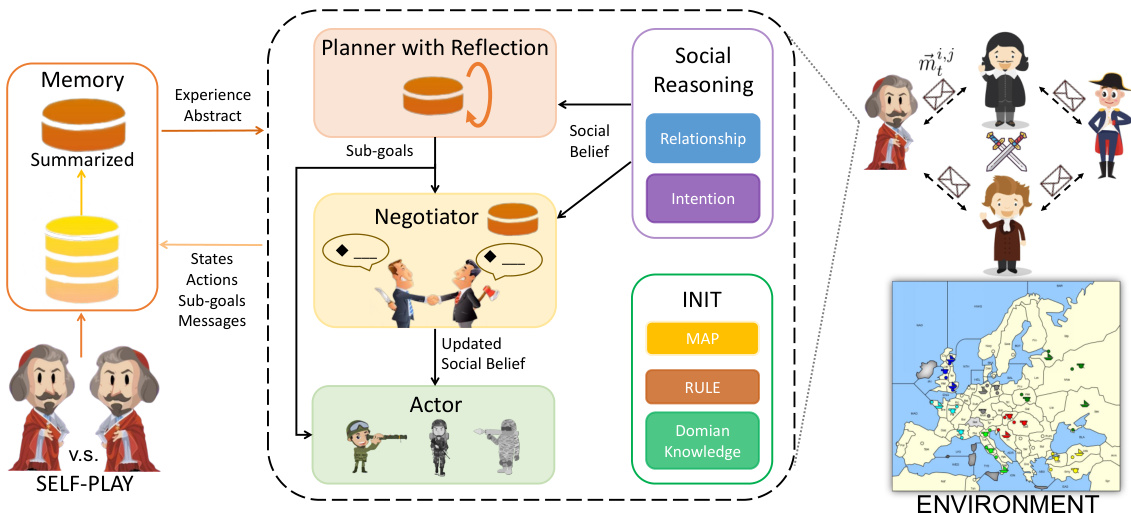
🔼 This figure illustrates the architecture of the Richelieu agent. The agent uses a memory module to store past experiences, which are used to inform its social reasoning, strategic planning (with reflection), negotiation, and actions. The agent’s memory is augmented via self-play, allowing for self-evolution without the need for human-provided data. The system components interact to generate actions in the Diplomacy game environment.
read the caption
Figure 2: The framework of the proposed LLM-based-agent, Richelieu. It can explicitly reason social beliefs, propose sub-goals with reflection, negotiate with others, and take actions to master diplomacy. It augments memories by self-play games for self-evolving without any human annotation.
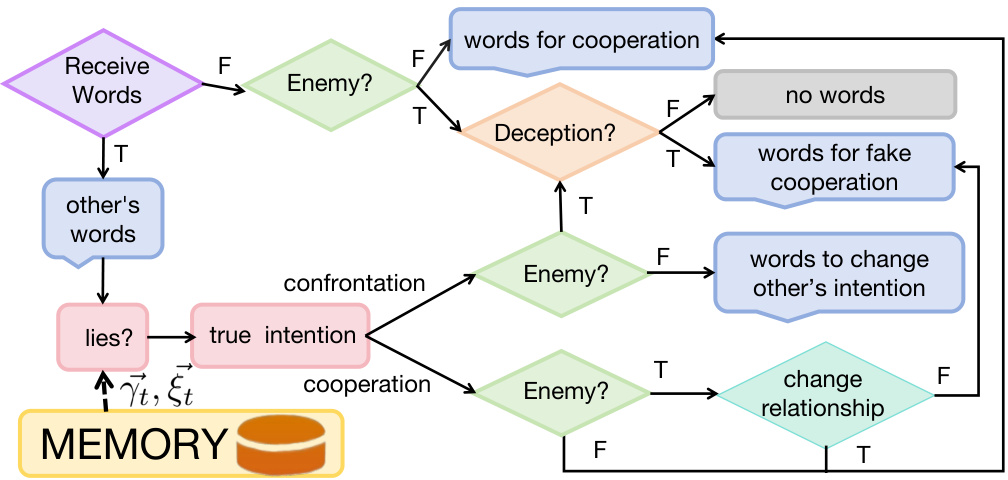
🔼 This figure illustrates the social reasoning process of the Richelieu agent during the negotiation phase. It shows a flowchart outlining how the agent processes received words from other players, combines this information with its memory of past interactions, and uses this knowledge to determine the true intentions of the other players and respond appropriately. The flowchart begins with the agent receiving words from an opponent. Based on these words, the agent determines if the opponent is an enemy and whether or not deception is involved. This leads to one of four possible actions: words for cooperation, words for fake cooperation, words to change the other’s intentions, or confrontation. These four actions are further refined based on whether or not the agent deems the other player an enemy, ultimately leading to a choice of cooperation or a change in relationship with that player. The entire process is informed by the agent’s memory, represented in the figure by a symbol of a memory storage unit. This memory allows the agent to leverage past experiences to influence its current decision making and refine its strategies. The flowchart thus represents the agent’s capacity for complex social reasoning, adapting its communication style based on its perception of the other player’s intentions, and leveraging its historical knowledge for strategic decision-making.
read the caption
Figure 3: The social reasoning flow for negotiation. With the received words and memory, the agent will reason by answering the following questions: “Is the opponent lying?

🔼 This figure presents a heatmap showing the relative performance of seven different AI agents playing a simplified version of the Diplomacy game (no-press diplomacy, meaning no negotiation). The color intensity represents the ratio of each agent’s score compared to other agents. Darker colors indicate that the agent significantly outperformed others, while lighter colors suggest a closer performance.
read the caption
Figure 4: The relative scores among 7 different agents when massively playing on the no-press setting. Each point shows the ratio of the model's score on the vertical axis to the score gained by the model on the horizontal axis.
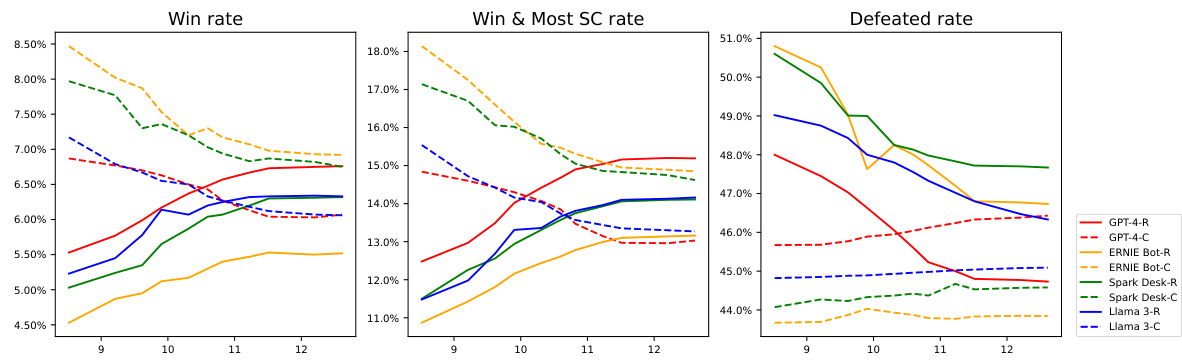
🔼 This figure shows the performance of Richelieu (solid lines) compared to Cicero (dashed lines) across different LLMs (GPT-4, ERNIE Bot, Spark Desk, and Llama 3). Each LLM is represented by a different color. The x-axis shows the number of training sessions (log scale), and the y-axis displays the win rate, win & most SC rate, and defeated rate for each model/LLM combination. The graph illustrates how Richelieu’s performance improves with more training sessions, and how this improvement varies depending on the underlying LLM used.
read the caption
Figure 5: Richelieu modules benefit different LLMs. The solid line represents the experimental results for Richelieu, while the dashed line corresponds to Cicero. Different colors are used for different LLMs. The horizontal axis represents the logarithm of the number of training sessions, and the vertical axis denotes the rate.
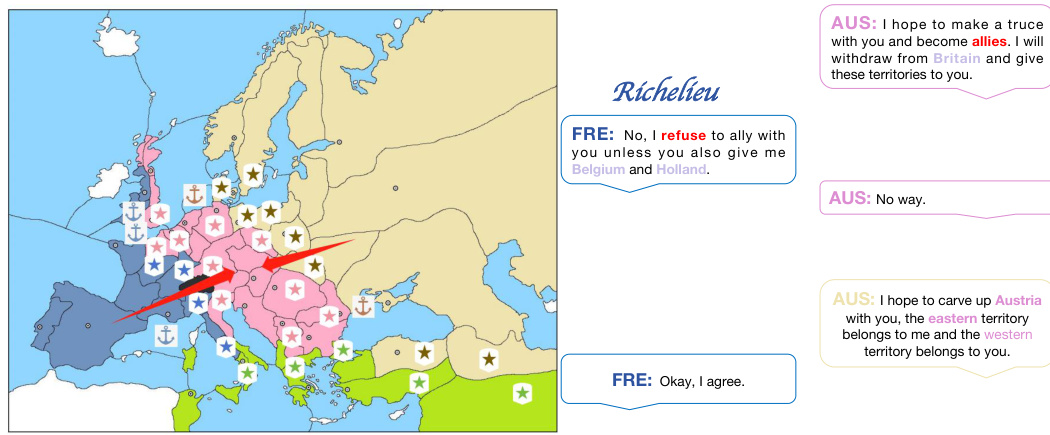
🔼 This figure shows two scenarios of the game of Diplomacy, one before and one after the model is trained using self-play. In the first scenario (Case 1), Richelieu (France) misses the opportunity to ally with Austria against the stronger Russia, eventually leading to France’s defeat. In the second scenario (Case 2), after self-play, Richelieu recognizes the long-term threat of Russia and forms an alliance with Austria, achieving a more favorable outcome. The change highlights the model’s improved strategic thinking and ability to learn from past experiences via self-play.
read the caption
Figure 6: Case of self-playing before and after comparison.
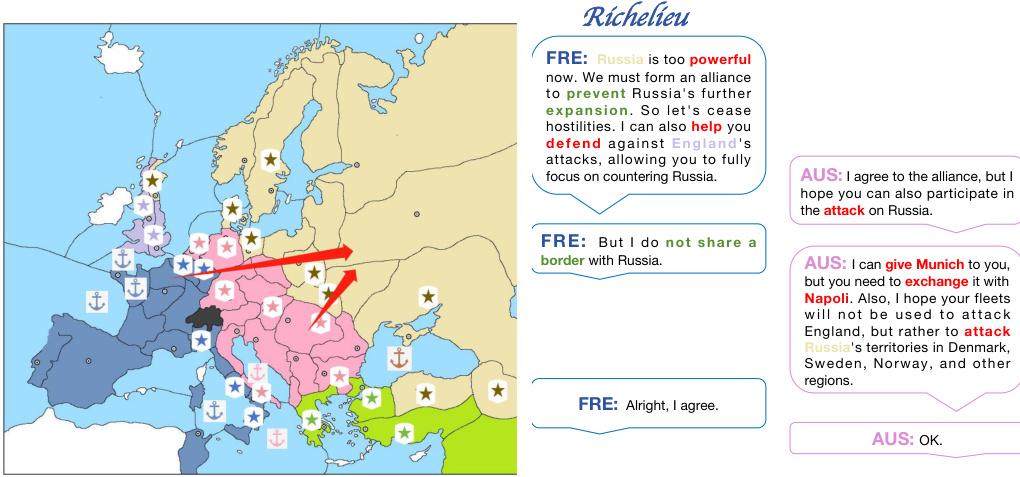
🔼 This figure shows two scenarios of a game. In the first scenario (Case 1), the agent without self-play memory makes a decision that results in Russia winning the game by ignoring long-term gains. In the second scenario (Case 2), after self-play, the agent considers long-term gains, forming an alliance to counter Russia, leading to a better outcome where France has most supply centers. This illustrates the impact of self-play on improving long-term strategic thinking in the AI agent.
read the caption
Figure 6: Case of self-playing before and after comparison.
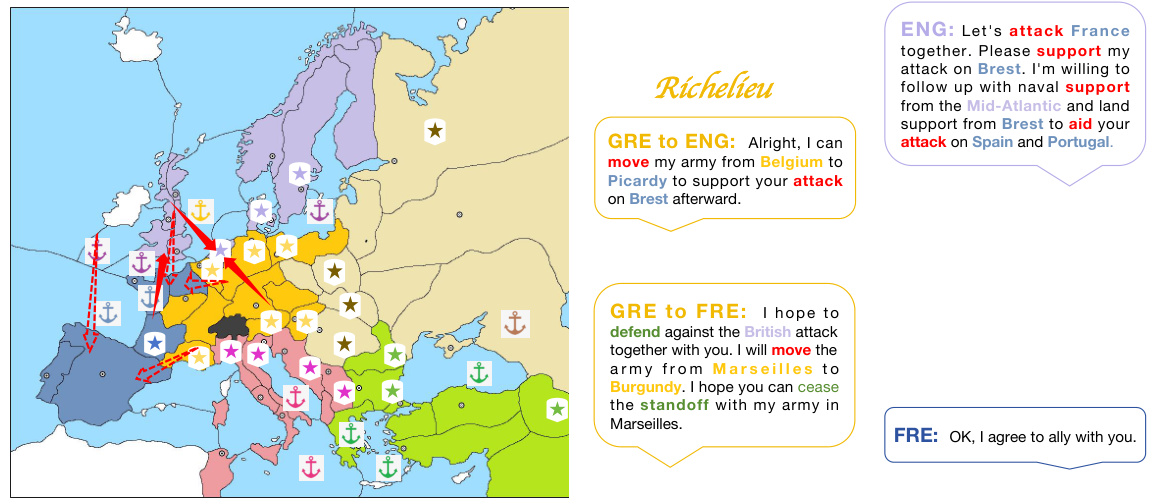
🔼 This figure shows a scenario in the Diplomacy game where England deceives Germany into an alliance to attack France. Richelieu, controlling Germany, suspects this deception and strategically seeks an alliance with France to counter England’s plan. The map illustrates the troop movements and the text boxes display the negotiations, highlighting Richelieu’s ability to detect and counter deceptive strategies.
read the caption
Figure 7: An example case of avoiding being deceived by other countries during negotiations.
More on tables
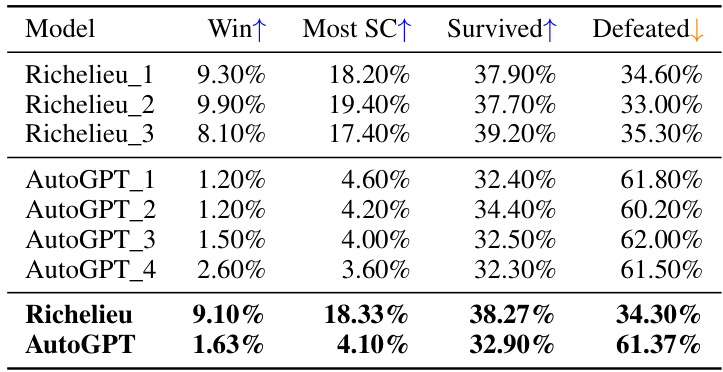
🔼 This table presents the results of a game played between Richelieu and AutoGPT, comparing their performance across several key metrics. The metrics used are win rate, the percentage of games where the model controlled the most supply centers (Most SC), the survival rate (Survived), and the defeat rate (Defeated). The data is presented for three independent runs of each model, along with an average across all runs (bottom row). The results highlight a significant performance gap between Richelieu and AutoGPT, demonstrating Richelieu’s superior performance in this task.
read the caption
Table 2: The results of Richelieu playing against AutoGPT.
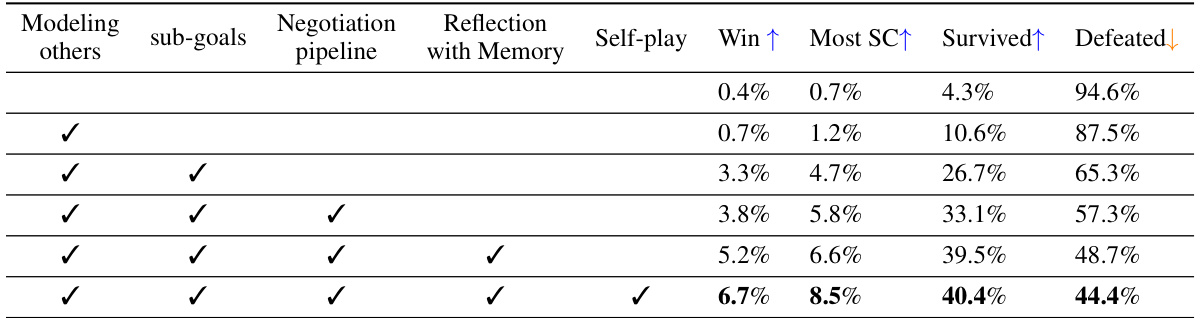
🔼 This table presents the ablation study results, comparing the performance of three Richelieu agents against four Cicero agents. Each row represents a different configuration of Richelieu, with checkmarks indicating the inclusion of specific modules: Modeling others, Negotiation pipeline, Reflection with Memory, and Self-play. The columns show the Win rate, Most SC rate, Survived rate, and Defeated rate for each configuration. This analysis demonstrates the contribution of each module to the overall performance of the Richelieu agent.
read the caption
Table 3: Ablation study: average results of 3 Richelieu vs. 4 Cicero.
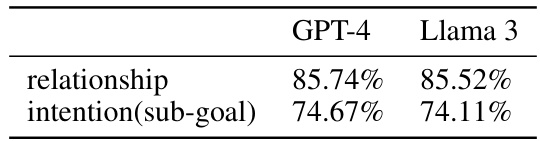
🔼 This table presents the accuracy of Richelieu’s social reasoning module in identifying social relationships and inferring the intentions of other players. The results are shown separately for GPT-4 and Llama 3, indicating the model’s performance with different large language models (LLMs). Higher percentages indicate greater accuracy in understanding the game’s social dynamics.
read the caption
Table 4: The success rate to identify the social relationship and infer others' intentions.

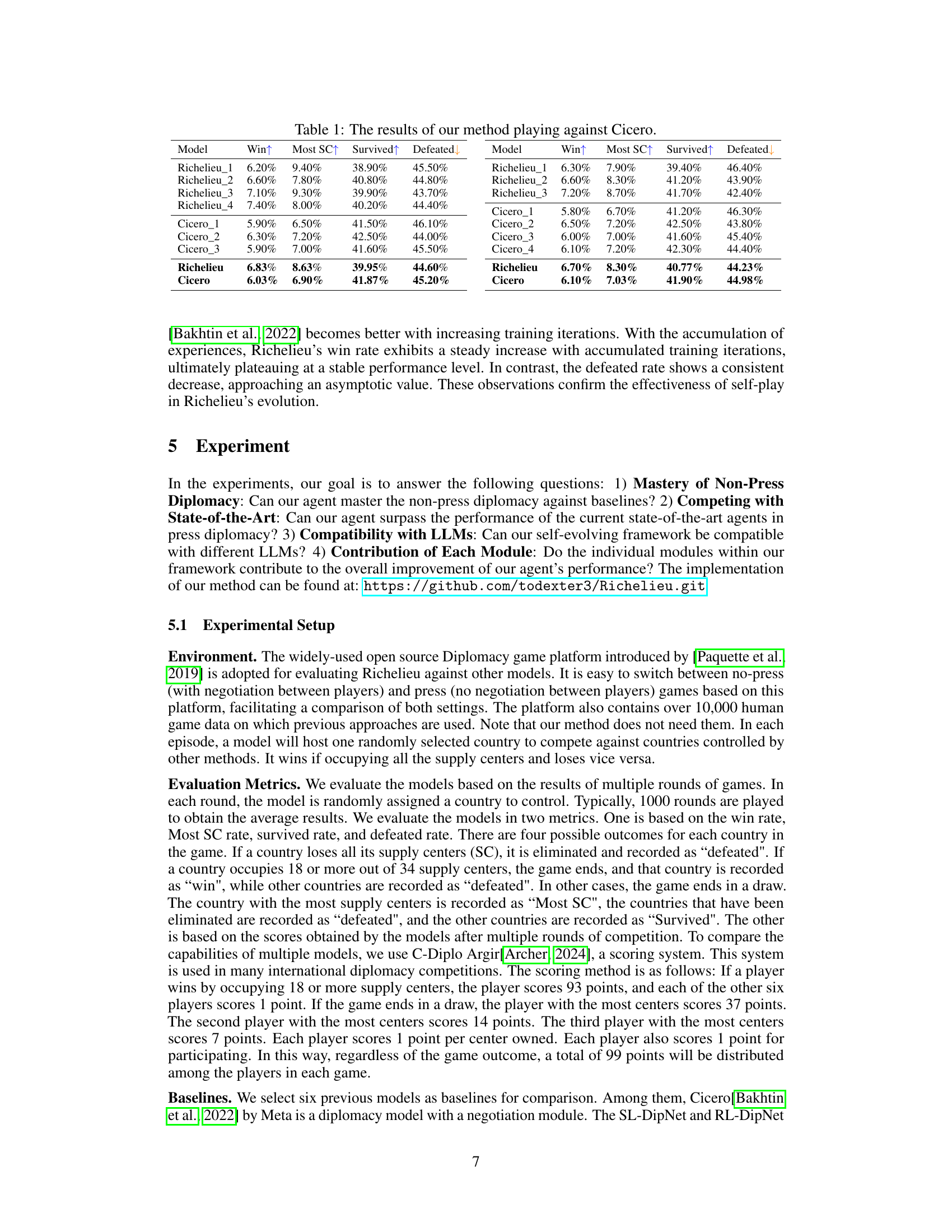
🔼 This table presents a comparison of the performance of the proposed Richelieu model against the Cicero model across four key metrics: win rate, most supply centers controlled, survival rate, and defeat rate. The results are shown for multiple runs (Richelieu_1 to Richelieu_4 and Cicero_1 to Cicero_4), indicating performance variability across different game instances. Overall, Richelieu demonstrates slightly superior performance in terms of wins and supply centers, but the difference isn’t substantial.
read the caption
Table 1: The results of our method playing against Cicero.
Full paper#