TL;DR#
Current scene text recognition (STR) models struggle with artistic and severely distorted text due to limitations in exploring character morphology diversity and sensitivity to character styles. The existing methods often use monotonous synthetic data and struggle with real-world scenarios. They also rely on pretrained models that may have accumulated errors. These limitations hinder the accurate recognition of complex and challenging text samples.
To overcome these issues, ViSu, a novel semi-supervised framework, leverages the human learning process of viewing and summarizing. ViSu introduces an Online Generation Strategy (OGS) to generate diverse, background-free synthetic samples. It also proposes a new Character Unidirectional Alignment (CUA) Loss to correct errors in previous character contrastive loss, thus improving intra-class distribution and reducing ambiguity on challenging samples. The experimental results demonstrate that ViSu achieves state-of-the-art performance on several benchmarks, showcasing its effectiveness in tackling the challenges of recognizing complex, real-world scene text.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in scene text recognition because it directly tackles the challenge of recognizing challenging, distorted texts—a major limitation of current methods. The proposed semi-supervised framework, ViSu, offers a novel approach to leverage unlabeled data effectively, significantly improving model robustness and accuracy, especially for complex real-world scenarios. Its innovative loss function and data augmentation strategy provides valuable insights into improving semi-supervised learning for STR, opening avenues for future research in handling various character morphologies and dealing with noisy or incomplete datasets.
Visual Insights#

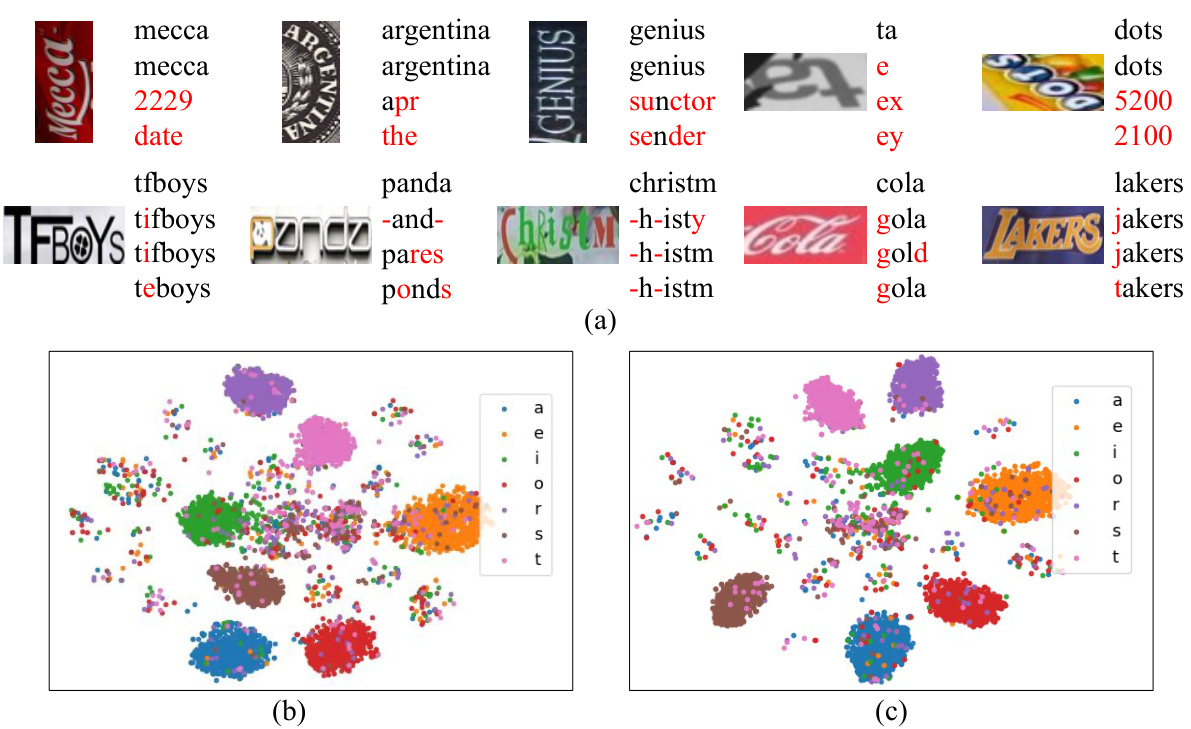
🔼 This figure demonstrates the limitations of current scene text recognition (STR) models. (a) shows simple examples from synthetic datasets, highlighting the discrepancy between the simplicity of training data and the complexity of real-world text. (b) and (c) showcase challenging real-world text samples with artistic styles and severe distortions. (d) and (e) use t-SNE to visualize the character feature distributions of a prior model (ParSeq) and the proposed ViSu model. The visualization highlights that ParSeq struggles to clearly distinguish characters, while ViSu achieves better separation.
read the caption
Figure 1: (a) shows some images from synthetic datasets MJSynth and SynthText. (b) and (c) show several challenging test images. (d) and (e) display the visualization of character feature distribution.
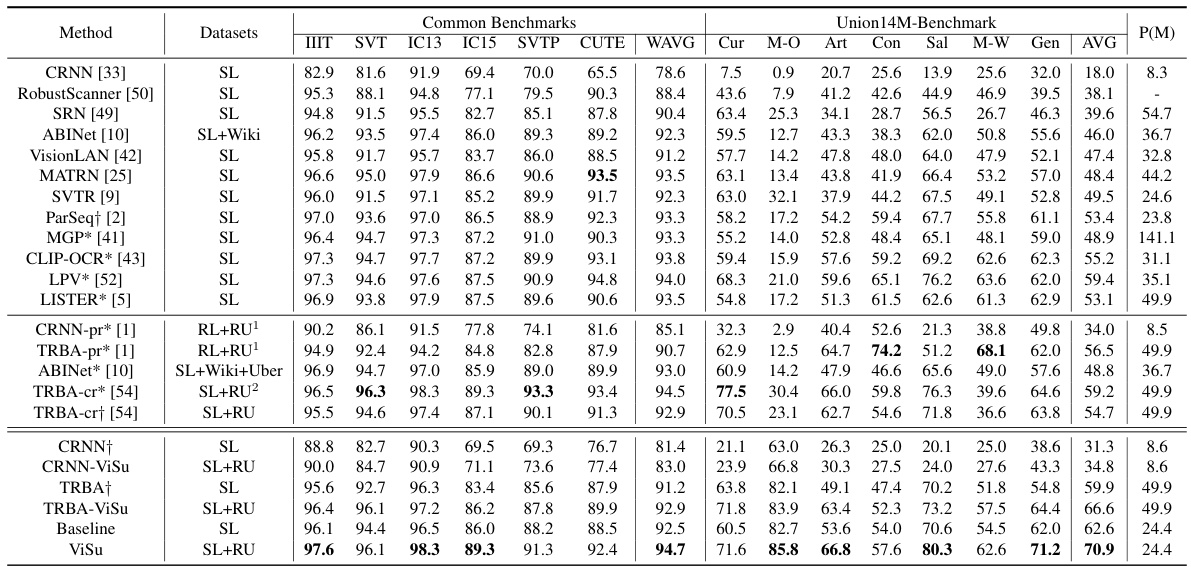
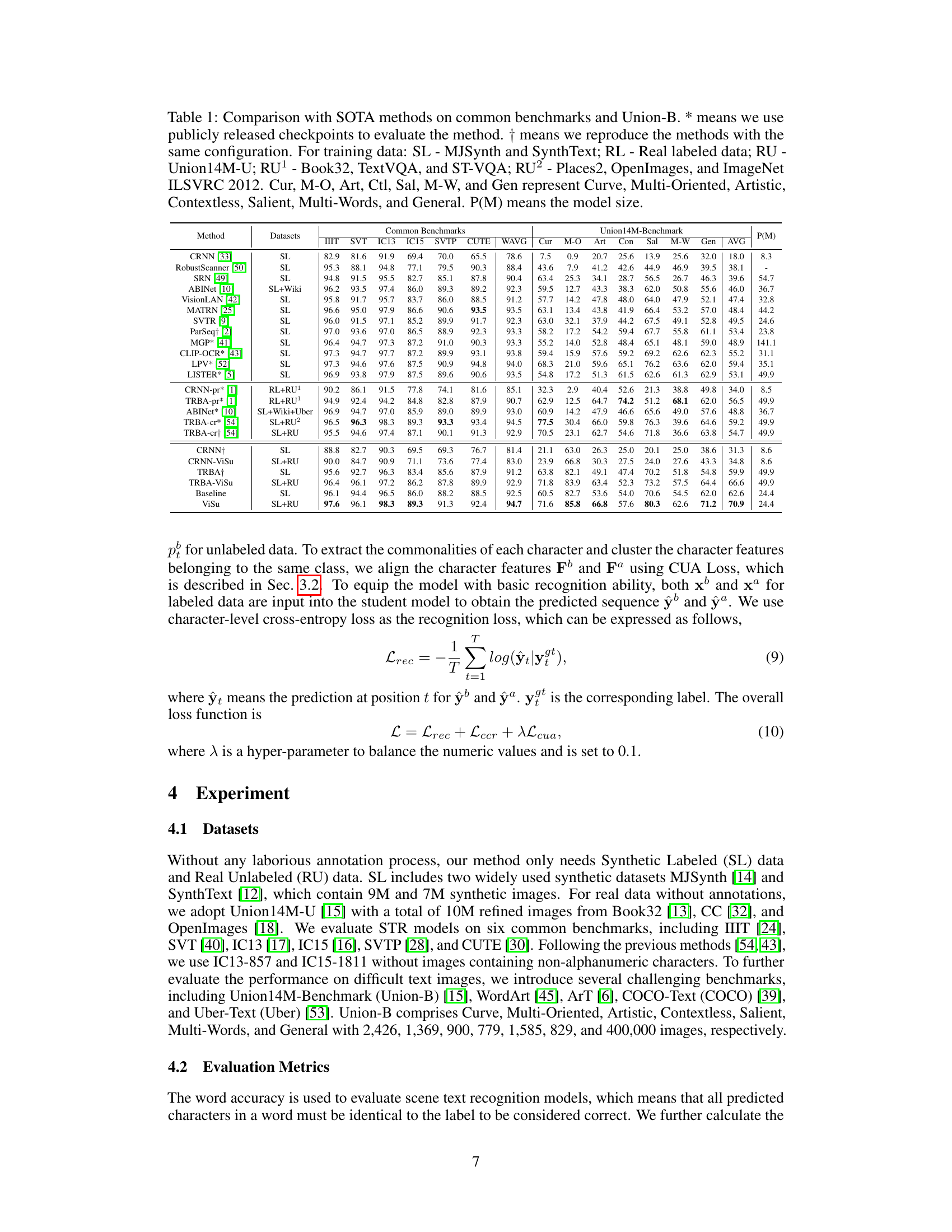
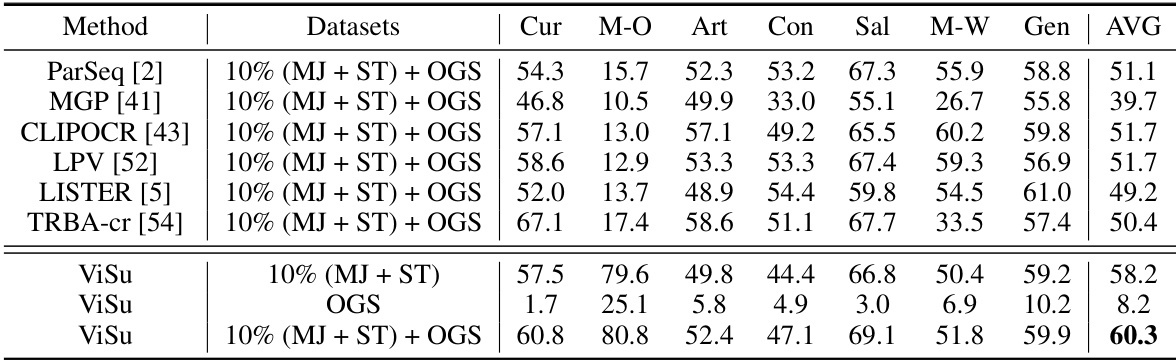
🔼 This table compares the proposed ViSu method with other state-of-the-art (SOTA) scene text recognition (STR) methods on common benchmarks (IIIT-SVT, IC13, IC15, SVTP, CUTE) and the challenging Union-B benchmark. It shows the word accuracy for various text styles (curve, multi-oriented, artistic, contextless, salient, multi-word, general). The table also indicates the training data used by each method (synthetic, real labeled, real unlabeled) and the model size.
read the caption
Table 1: Comparison with SOTA methods on common benchmarks and Union-B. * means we use publicly released checkpoints to evaluate the method. † means we reproduce the methods with the same configuration. For training data: SL - MJSynth and SynthText; RL - Real labeled data; RU - Union14M-U; RU¹ - Book32, TextVQA, and ST-VQA; RU2 - Places2, OpenImages, and ImageNet ILSVRC 2012. Cur, M-O, Art, Ctl, Sal, M-W, and Gen represent Curve, Multi-Oriented, Artistic, Contextless, Salient, Multi-Words, and General. P(M) means the model size.
In-depth insights#
Semi-Supervised STR#
Semi-supervised scene text recognition (STR) represents a crucial area of research focusing on leveraging both labeled and unlabeled data to improve model performance. The scarcity of labeled data in STR is a significant bottleneck, especially for complex scenarios involving artistic or severely distorted text. Semi-supervised methods aim to overcome this by utilizing large amounts of readily available unlabeled data to augment the limited labeled dataset. Effective strategies often involve self-training techniques or consistency regularization, where models learn to predict consistent outputs for various augmented versions of unlabeled samples. A key challenge is to design loss functions that effectively guide the model to learn robust features from unlabeled data while preventing the propagation of errors from pseudo-labels. Moreover, the integration of suitable data augmentation methods is essential to enhance the diversity of character morphologies encountered during training and improve generalization capabilities. Future research in semi-supervised STR should focus on exploring more sophisticated contrastive learning methods, advanced self-training approaches, and novel techniques for handling noise and ambiguity in unlabeled data. Ultimately, the objective is to create robust and generalizable STR models that can accurately recognize diverse text styles, even under challenging conditions with minimal reliance on expensive manual annotation.
Viewing & Summarizing#
The proposed ‘Viewing and Summarizing’ framework offers a novel approach to semi-supervised scene text recognition. Viewing focuses on enriching the diversity of character morphologies in the training data by using an online generation strategy. This addresses limitations of using simple synthetic data by creating background-free samples with varied character styles, thereby encouraging the model to focus on character morphology and improve generalization to complex, real-world scenarios. Summarizing aims to unify the representation of the same characters across diverse samples. It theoretically demonstrates and corrects errors in previous character contrastive loss methods that cause sparsity in intra-class distributions. A new Character Unidirectional Alignment Loss is introduced to align character features, ensuring consistency and robustness. This two-stage process leverages both synthetic and real unlabeled data effectively. The combination of improved data diversity and refined loss functions promises a significant boost in semi-supervised scene text recognition performance, as evidenced by the reported state-of-the-art results.
OGS Data Augmentation#
OGS data augmentation is a novel technique designed to enhance the diversity and quality of training data for scene text recognition (STR) models. It addresses the limitations of existing STR datasets, which often feature monotonous and simplistic character morphologies. By generating background-free samples with diverse character styles, OGS effectively compensates for the simplicity of synthetic datasets and enriches the character morphology diversity. This process is particularly beneficial for training models to recognize complex and artistic characters that are often underrepresented in standard datasets. This is achieved by focusing the model’s attention on character morphologies by removing background noise and distractions.The crucial insight here is that by isolating the character from its background, the model becomes more sensitive to subtle morphological variations which lead to improved generalization performance and an increase in robustness to various real-world character distortions and styles. The background-free nature of OGS-generated samples enables the model to generalize better to unseen data, reducing the gap between the performance on simple synthetic data and the more challenging real-world scenarios. Furthermore, the online nature of the strategy allows for continuous adaptation and improvement of the dataset during the training phase, leading to more efficient and effective model training.
CUA Loss Function#
The Character Unidirectional Alignment (CUA) loss function is a novel approach designed to address limitations in previous character contrastive loss methods for semi-supervised scene text recognition. The core issue it tackles is the sparsity and ambiguity in the intra-class distribution of character features, often caused by errors in existing loss functions that mistakenly treat some positive samples as negative ones. CUA loss corrects this by theoretically deriving a new loss function that focuses on aligning character feature representations, ensuring that all samples of the same character are consistently represented, regardless of their variations in style or distortion. This alignment is achieved by unifying character representations in a ‘student’ model with reference features from a ’teacher’ model. The resulting more compact intra-class distributions enhance the model’s ability to generalize from simpler synthetic training data to more complex, real-world scenarios. The unidirectional aspect of the alignment is crucial, as it avoids misalignments caused by noise and variations in augmented images and ensures a more robust and accurate clustering of character features. In essence, CUA loss serves as a powerful mechanism for improving the summarizing process of semi-supervised learning, enabling the model to better distinguish between characters even under challenging conditions.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Improving the Online Generation Strategy (OGS) to create even more diverse and challenging synthetic data, potentially incorporating techniques like generative adversarial networks (GANs), is crucial. This would further reduce the reliance on real, unlabeled data and enhance model robustness. Investigating alternative loss functions beyond the proposed Character Unidirectional Alignment Loss (CUA Loss) to better capture character-level relationships and improve clustering accuracy is also warranted. A deeper theoretical exploration of the connections between contrastive learning, character morphology, and model generalization in semi-supervised settings would offer valuable insights. Furthermore, extending ViSu to handle more complex text scenarios, such as those involving extreme aspect ratios, significantly curved text, or dense text layouts, would increase its applicability. Finally, applying ViSu to other related sequence modeling tasks, such as speech recognition or machine translation, could demonstrate its wider applicability and generalizability. Benchmarking ViSu on more diverse and challenging datasets, including those with multilingual text, would also strengthen the evaluation and solidify its position as a state-of-the-art method.
More visual insights#
More on figures

🔼 This figure shows how the Online Generation Strategy (OGS) unifies the different representations of text images. Part (a) illustrates the eight possible variations of a word due to different character orientations and reading orders. Part (b) demonstrates how OGS reduces these eight variations into two primary forms by considering aspect ratios and rotation. These unified forms serve as base images for feature alignment in the model, making it more robust to variations in real-world text images.
read the caption
Figure 2: (a) All possible representations of English text images according to character orientation and reading order. (b) The unified representation forms of the word “standard” obtained through Online Generation Strategy. The first row with a red border shows two primary forms, and the second row can be obtained by rotating them 180 degrees.
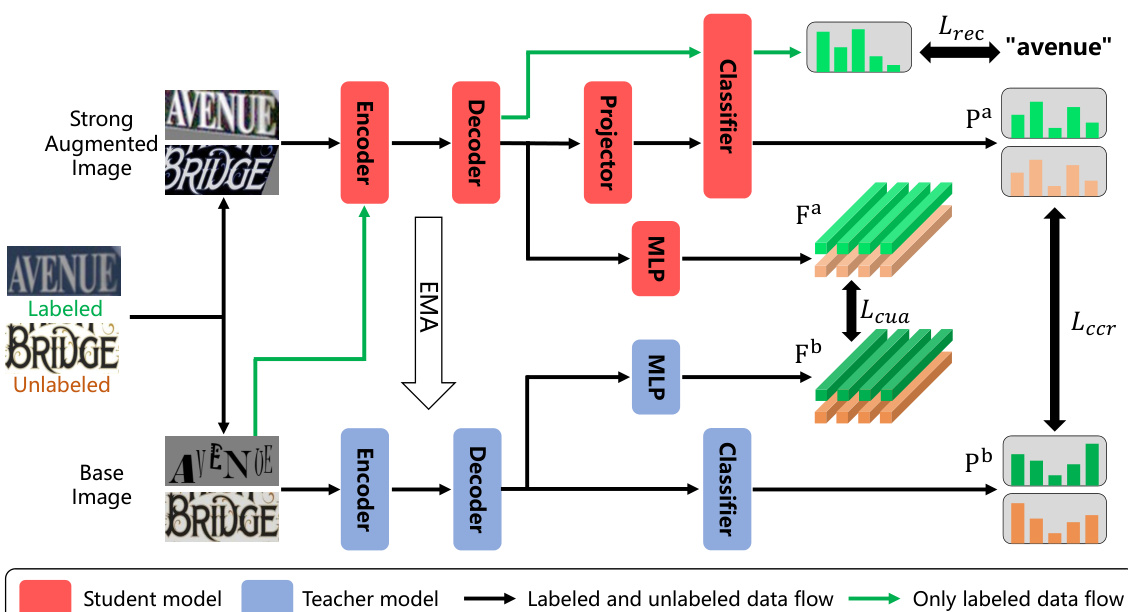
🔼 This figure illustrates the ViSu framework, a semi-supervised scene text recognition model. It uses a Mean Teacher architecture with a student and teacher model, both employing transformer-based encoders and decoders. The student model is trained with labeled and unlabeled data, while the teacher model uses only labeled data to provide guidance via an exponential moving average of the student’s parameters. The framework incorporates three loss functions: recognition loss (Lrec), character consistency regularization loss (Lccr), and character unidirectional alignment loss (Lcua). The Online Generation Strategy (OGS) generates additional background-free samples to enhance data diversity for the student model. Green arrows represent the flow of labeled and unlabeled data through the student and teacher models, and green lines show the flow of information specifically from the labeled data to the teacher model.
read the caption
Figure 3: Our framework consists of the student and teacher model. Lrec, Lccr, Lcua mean recognition loss, character consistency regularization loss and character unidirectional alignment loss. Green and orange stand for labeled and unlabeled data, respectively.
🔼 Figure 2 illustrates the different representations of English text images based on character orientation and reading order. Part (a) shows the eight possible variations caused by these factors. Part (b) demonstrates how the Online Generation Strategy unifies these representations into two main forms (shown in the top row with red borders) and their corresponding rotated forms (bottom row). This simplification is crucial for the proposed method’s effectiveness in handling the diversity of character styles.
read the caption
Figure 2: (a) All possible representations of English text images according to character orientation and reading order. (b) The unified representation forms of the word “standard” obtained through Online Generation Strategy. The first row with a red border shows two primary forms, and the second row can be obtained by rotating them 180 degrees.

🔼 This figure shows different representations of text images based on character orientation and reading order. Part (a) illustrates the eight possible variations for a single word. Part (b) demonstrates how these eight variations are unified into two primary forms using the Online Generation Strategy, reducing complexity for the model’s training process. The two primary forms and their rotated versions (180 degrees) are shown.
read the caption
Figure 2: (a) All possible representations of English text images according to character orientation and reading order. (b) The unified representation forms of the word 'standard' obtained through Online Generation Strategy. The first row with a red border shows two primary forms, and the second row can be obtained by rotating them 180 degrees.
More on tables
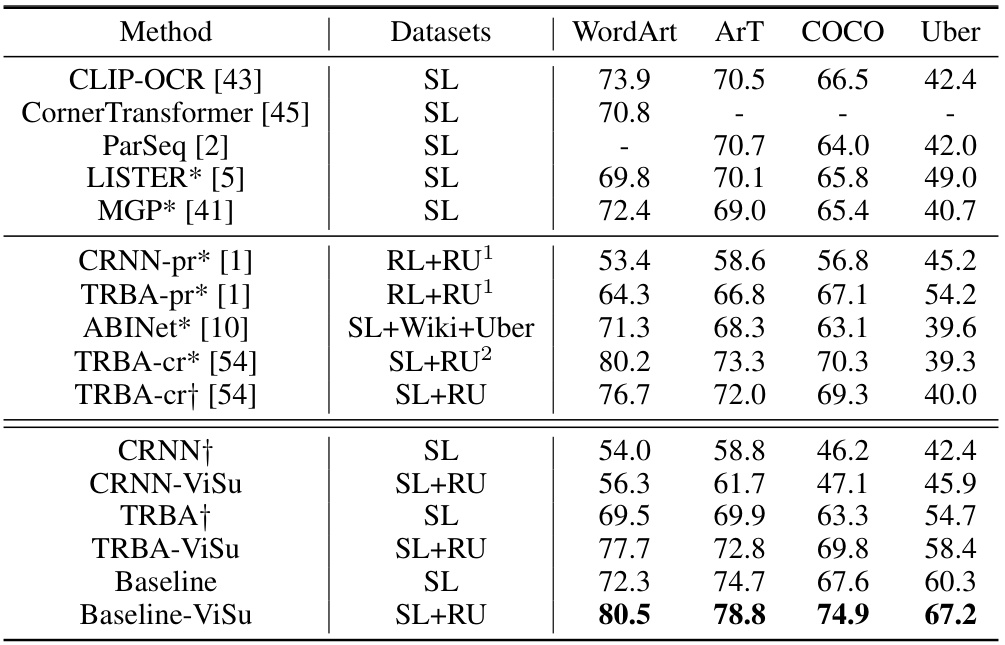
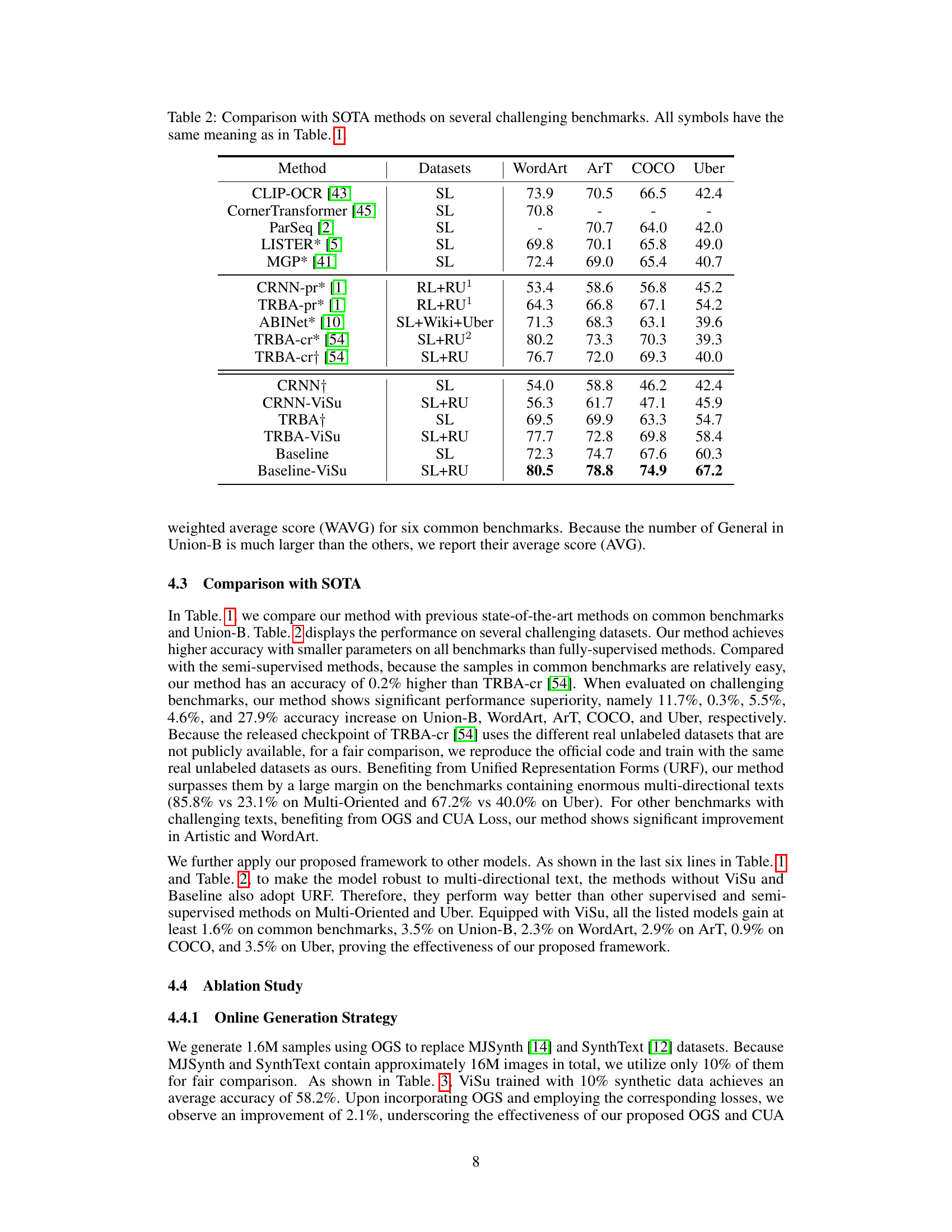
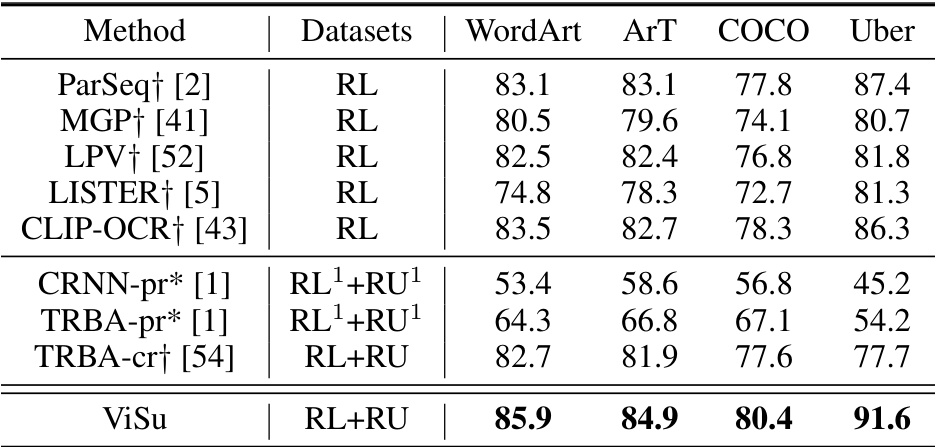
🔼 This table compares the performance of various state-of-the-art (SOTA) scene text recognition (STR) methods on several challenging benchmarks. It shows the accuracy of each method on datasets like WordArt, ArT, COCO, and Uber. The table allows for a direct comparison of the proposed method (ViSu) against other SOTA methods, highlighting its performance on particularly difficult text images.
read the caption
Table 2: Comparison with SOTA methods on several challenging benchmarks. All symbols have the same meaning as in Table. 1.
🔼 This table compares the proposed ViSu method with other state-of-the-art (SOTA) scene text recognition methods on standard benchmarks (IIIT, SVT, IC13, IC15, SVTP, CUTE) and a more challenging benchmark (Union-B). It shows word accuracy, broken down by various text characteristics (e.g., curve, multi-oriented, artistic, etc.), and indicates the training data used (synthetic, real labeled, real unlabeled). The table also provides model size information.
read the caption
Table 1: Comparison with SOTA methods on common benchmarks and Union-B. * means we use publicly released checkpoints to evaluate the method. † means we reproduce the methods with the same configuration. For training data: SL - MJSynth and SynthText; RL - Real labeled data; RU - Union14M-U; RU¹ - Book32, TextVQA, and ST-VQA; RU2 - Places2, OpenImages, and ImageNet ILSVRC 2012. Cur, M-O, Art, Ctl, Sal, M-W, and Gen represent Curve, Multi-Oriented, Artistic, Contextless, Salient, Multi-Words, and General. P(M) means the model size.
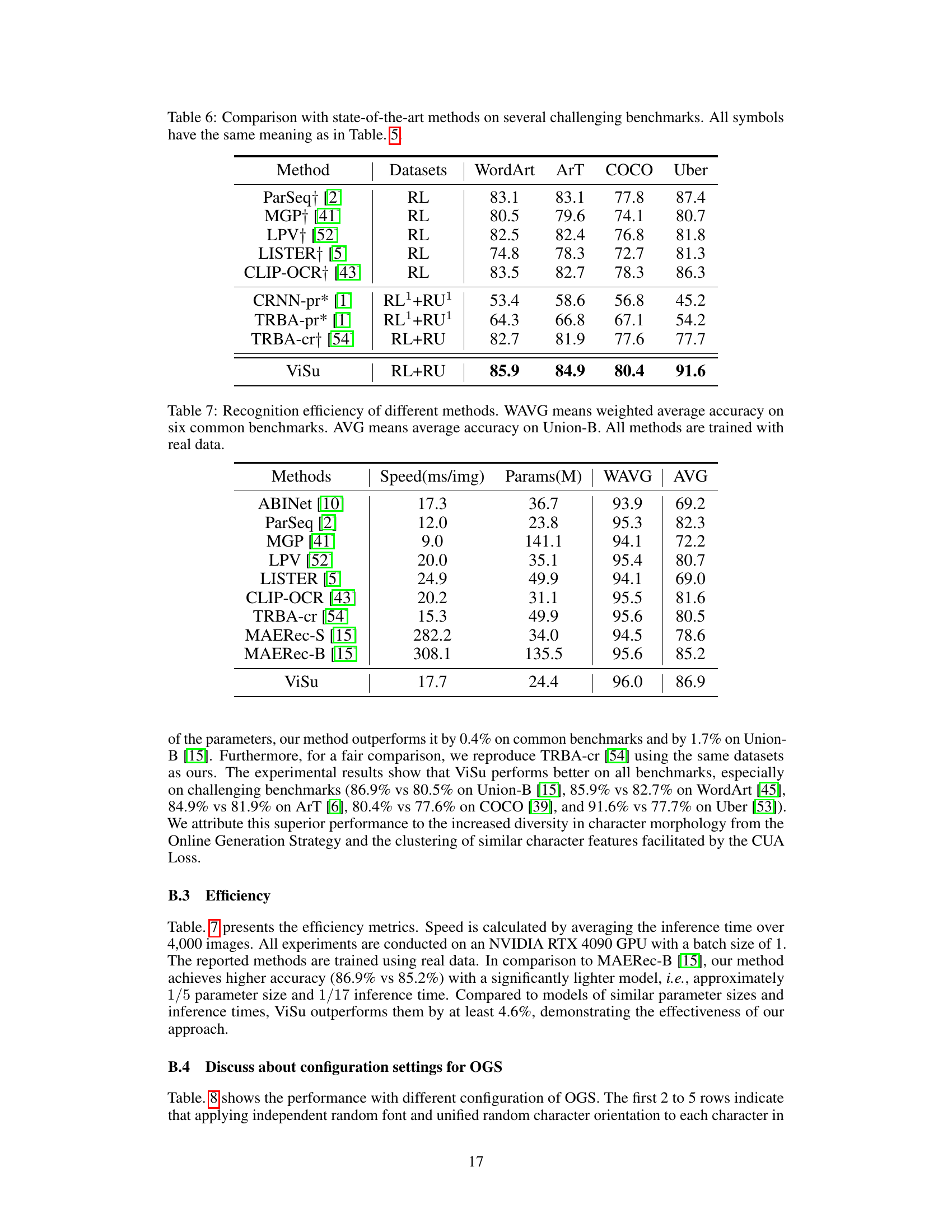
🔼 This table compares the proposed ViSu method with other state-of-the-art (SOTA) scene text recognition (STR) methods on several benchmark datasets. It shows the word accuracy achieved by each method on various subsets of the benchmarks, categorized by the type of training data used (synthetic, real labeled, and real unlabeled). The table also indicates whether publicly released checkpoints or reproduced methods were used for evaluation, and provides additional context on the datasets used (e.g., indicating what sub-datasets were used for real unlabeled data).
read the caption
Table 1: Comparison with SOTA methods on common benchmarks and Union-B. * means we use publicly released checkpoints to evaluate the method. † means we reproduce the methods with the same configuration. For training data: SL - MJSynth and SynthText; RL - Real labeled data; RU - Union14M-U; RU¹ - Book32, TextVQA, and ST-VQA; RU² - Places2, OpenImages, and ImageNet ILSVRC 2012. Cur, M-O, Art, Ctl, Sal, M-W, and Gen represent Curve, Multi-Oriented, Artistic, Contextless, Salient, Multi-Words, and General. P(M) means the model size.

🔼 This table compares the performance of the proposed ViSu model with other state-of-the-art (SOTA) methods on standard scene text recognition (STR) benchmarks (IIIT, SVT, IC13, IC15, SVTP, CUTE) and the more challenging Union-B benchmark. It shows the word accuracy for various text styles (curve, multi-oriented, artistic, etc.) and indicates the training data used (synthetic, real labeled, and real unlabeled data). Model size is also listed.
read the caption
Table 1: Comparison with SOTA methods on common benchmarks and Union-B. * means we use publicly released checkpoints to evaluate the method. † means we reproduce the methods with the same configuration. For training data: SL - MJSynth and SynthText; RL - Real labeled data; RU - Union14M-U; RU¹ - Book32, TextVQA, and ST-VQA; RU2 - Places2, OpenImages, and ImageNet ILSVRC 2012. Cur, M-O, Art, Ctl, Sal, M-W, and Gen represent Curve, Multi-Oriented, Artistic, Contextless, Salient, Multi-Words, and General. P(M) means the model size.
🔼 This table compares the performance of the proposed ViSu method against other state-of-the-art (SOTA) methods on several challenging benchmark datasets. The datasets include WordArt, ArT, COCO, and Uber, each representing different text recognition challenges. The table shows the accuracy achieved by each method on each dataset, highlighting the superior performance of ViSu on these more difficult benchmarks.
read the caption
Table 2: Comparison with SOTA methods on several challenging benchmarks. All symbols have the same meaning as in Table. 1.
🔼 This table compares the proposed ViSu model with other state-of-the-art (SOTA) scene text recognition (STR) methods on standard benchmarks (IIIT-SVT, IC13, IC15, SVTP, CUTE) and the more challenging Union-Benchmark. The table indicates the datasets used for training (synthetic, real labeled, and real unlabeled data), performance metrics (accuracy), model parameters, and different text styles or conditions within the Union-Benchmark. The results demonstrate the superior accuracy of the ViSu model, especially when dealing with the more challenging datasets.
read the caption
Table 1: Comparison with SOTA methods on common benchmarks and Union-B. * means we use publicly released checkpoints to evaluate the method. † means we reproduce the methods with the same configuration. For training data: SL - MJSynth and SynthText; RL - Real labeled data; RU - Union14M-U; RU¹ - Book32, TextVQA, and ST-VQA; RU² - Places2, OpenImages, and ImageNet ILSVRC 2012. Cur, M-O, Art, Ctl, Sal, M-W, and Gen represent Curve, Multi-Oriented, Artistic, Contextless, Salient, Multi-Words, and General. P(M) means the model size.
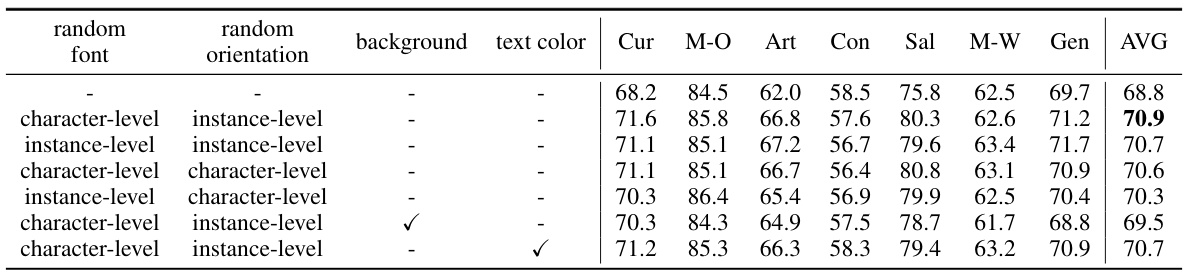
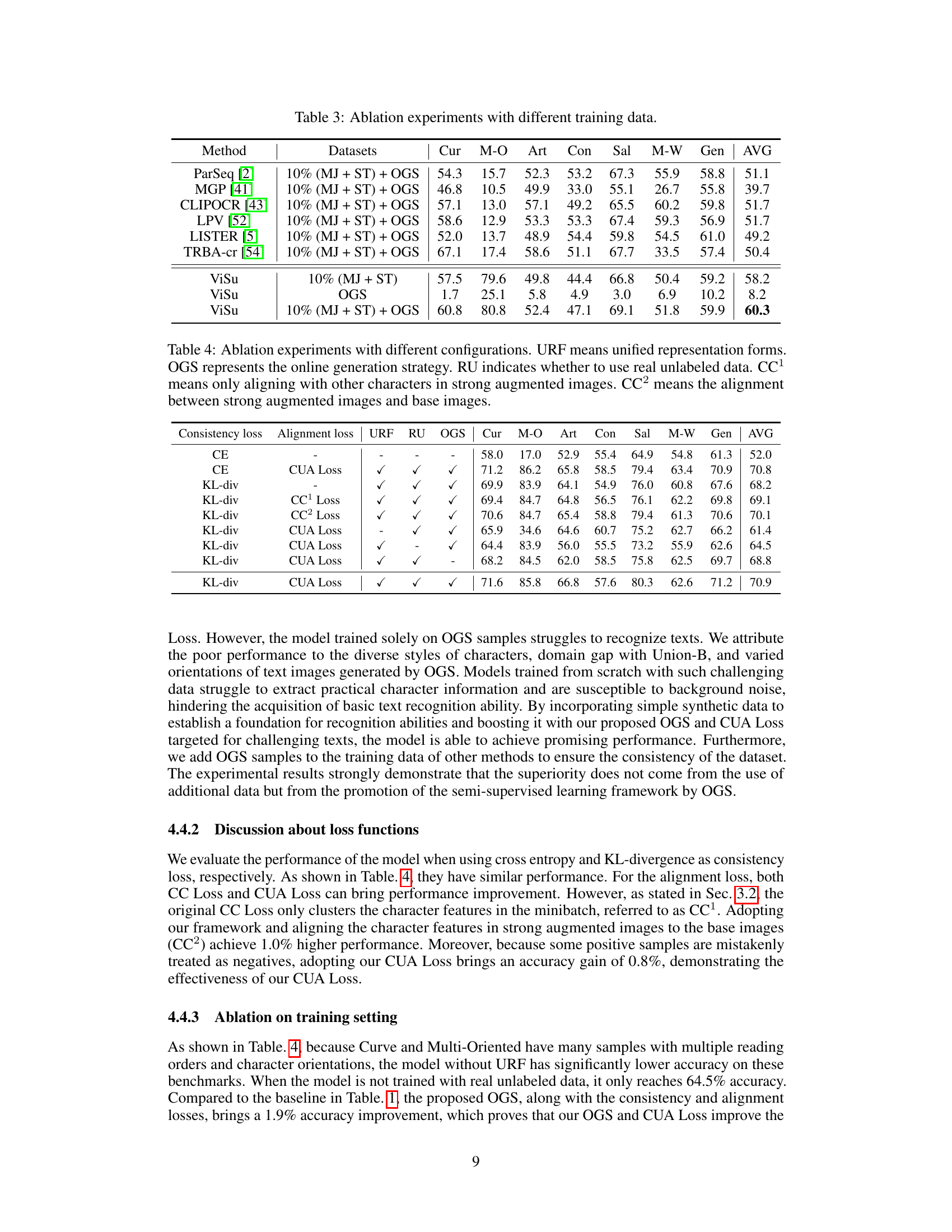
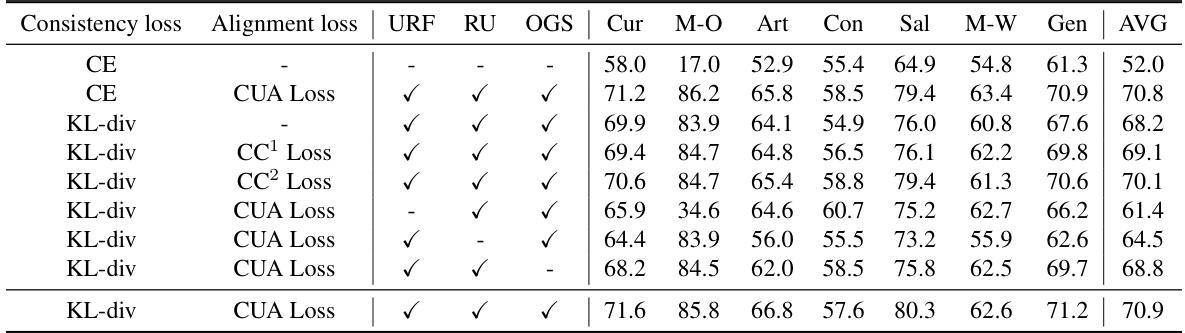
🔼 This table presents ablation study results on the Union-B benchmark, focusing on the impact of different configurations within the Online Generation Strategy (OGS). It explores variations in font and orientation randomization (character-level vs. instance-level) and the inclusion/exclusion of background and text color variations. The results demonstrate the effectiveness of the proposed OGS configurations on improving the overall accuracy on the Union-B benchmark.
read the caption
Table 8: Performance on Union-B with different configuration settings for OGS. The first row represents the baseline model without OGS. Character-level means that all characters in a sample have independent random font or orientation. Instance-level means that means that all characters in a sample have a unified font or orientation, but different samples are independent.

🔼 This table compares the proposed ViSu method with other state-of-the-art (SOTA) methods on several scene text recognition benchmarks. It shows the accuracy of each method on various datasets (common benchmarks and the challenging Union14M-Benchmark), broken down by different text styles and orientations. The table also indicates the type of training data used (synthetic, real labeled, and real unlabeled), and the model size.
read the caption
Table 1: Comparison with SOTA methods on common benchmarks and Union-B. * means we use publicly released checkpoints to evaluate the method. † means we reproduce the methods with the same configuration. For training data: SL - MJSynth and SynthText; RL - Real labeled data; RU - Union14M-U; RU¹ - Book32, TextVQA, and ST-VQA; RU² - Places2, OpenImages, and ImageNet ILSVRC 2012. Cur, M-O, Art, Ctl, Sal, M-W, and Gen represent Curve, Multi-Oriented, Artistic, Contextless, Salient, Multi-Words, and General. P(M) means the model size.
Full paper#