TL;DR#
Current 3D planar reconstruction methods from monocular videos struggle with either inaccurate boundaries (2D mask-based methods) or discontinuous geometry (3D point-cloud based methods). These limitations hinder applications requiring accurate and complete 3D models. Existing learning-based methods also often lack generalization capabilities across various scenes.
This paper introduces AlphaTablets, a new 3D plane representation that effectively addresses these issues. AlphaTablets represent 3D planes as rectangles with alpha channels, combining the benefits of 2D and 3D approaches. A novel bottom-up pipeline is proposed, which uses differentiable rendering, pre-trained models, and an effective merging scheme to reconstruct accurate and complete 3D planes. The method achieves state-of-the-art results on the ScanNet dataset, demonstrating its robustness and generalizability.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces AlphaTablets, a novel and generic 3D plane representation that significantly improves the accuracy and completeness of 3D planar reconstruction from monocular videos. This offers potential for significant advancements in various applications such as scene modeling, mixed reality, and robotics. The differentiable rendering and effective merging scheme proposed are highly valuable contributions to the field.
Visual Insights#
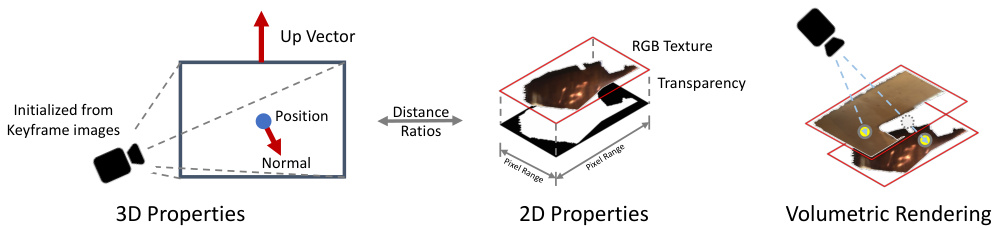
🔼 This figure illustrates the properties of an AlphaTablet, the core element of the proposed 3D plane representation. It shows how a rectangular primitive is defined in 3D space using properties like position, normal vector, and up vector. The figure also demonstrates the 2D properties that exist within the tablet, such as RGB texture, transparency (alpha channel), and pixel range. Finally, it depicts the volumetric rendering process, showing how multiple AlphaTablets combine to generate the final 3D scene. The key idea is that each AlphaTablet is a semi-transparent rectangle that can model complex shapes through its alpha channel.
read the caption
Figure 1: Illustration of tablet properties and rendering. Normal and up vector determines the rotation of a tablet in 3D space, while every tablet maintains a distance ratio between the coordinates of the 3D field and 2D-pixel space.
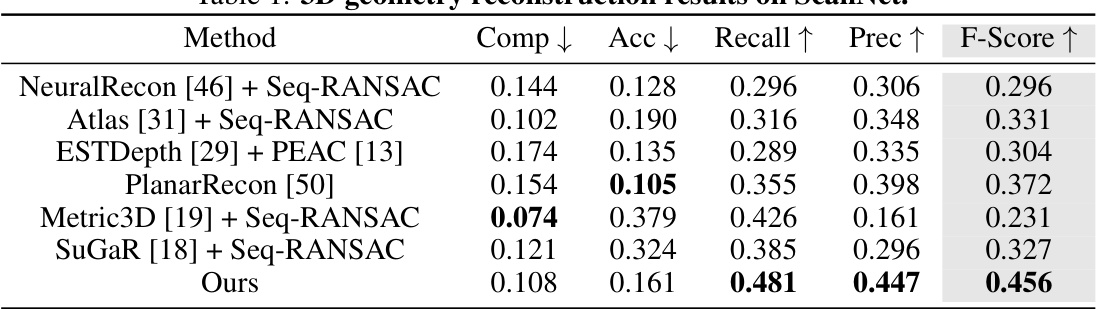
🔼 This table presents a quantitative comparison of different methods for 3D geometry reconstruction on the ScanNet dataset. The metrics used are: Completeness (Comp), Accuracy (Acc), Recall, Precision (Prec), and F-Score. Lower values for Comp and Acc indicate better performance, while higher values for Recall, Precision, and F-Score are preferred. The table shows that the proposed ‘Ours’ method outperforms existing state-of-the-art techniques.
read the caption
Table 1: 3D geometry reconstruction results on ScanNet.
In-depth insights#
AlphaTablets: A Novel 3D Plane Representation#
The proposed AlphaTablets representation offers a novel approach to 3D plane modeling by combining the strengths of 2D and 3D methods. Representing planes as textured rectangles with alpha channels enables continuous surface representation and precise boundary delineation, overcoming limitations of discrete 3D methods. The use of alpha channels allows for modeling irregular shapes and transparency, while the textured rectangle structure facilitates efficient differentiable rendering. This unique combination is crucial for achieving accurate and consistent 3D plane reconstruction from monocular videos. The inherent flexibility in modeling complex geometries and boundaries makes AlphaTablets a powerful and adaptable representation for various applications within 3D computer vision. Differentiable rendering enables integration into a learning-based framework, enhancing optimization and facilitating the development of robust reconstruction pipelines. AlphaTablets’ ability to seamlessly integrate 2D and 3D information proves highly beneficial for tasks such as scene modeling and robotic applications.
Differentiable Rendering#
Differentiable rendering is a crucial technique in modern computer graphics, particularly relevant for tasks involving neural rendering and implicit surface representation. It allows for the computation of gradients through the rendering pipeline, enabling the optimization of scene parameters and 3D models directly based on rendered images. This is achieved by making the rendering process differentiable; each step of the pipeline, from shading to rasterization, must be formulated to support backpropagation of errors. This enables end-to-end training where, for example, scene geometry or material properties can be optimized directly to match a target image. The use of differentiable rendering allows for a powerful combination of traditional computer graphics techniques with modern machine learning methods. However, developing differentiable rendering methods can be computationally intensive and often require significant engineering effort. The choice of differentiable rendering techniques often depends on factors like scene complexity, required accuracy, and overall computational budget. Despite the challenges, its applications are continually expanding within areas such as neural rendering, novel view synthesis, and inverse rendering problems.
Bottom-up Reconstruction#
Bottom-up reconstruction, in the context of 3D planar reconstruction from visual data, is a powerful strategy that starts with local features and gradually builds up to the complete scene representation. It contrasts with top-down approaches that begin with a global model. The core idea is to initialize numerous small, potentially overlapping 3D planar elements (like AlphaTablets in the described paper) from initial 2D superpixel segmentation and monocular depth and normal estimations. These elements are then iteratively refined and merged. Optimization happens through differentiable rendering, using photometric loss functions to minimize discrepancies between the rendered image and the input frames. A crucial aspect is the merging scheme, which uses criteria based on geometric consistency, texture similarity, and boundary smoothness to grow larger, more accurate planar representations. This iterative refinement and merging process ensures that the final reconstruction is both accurate and coherent, exhibiting solid surfaces and clear boundaries. The bottom-up approach is particularly well-suited for complex scenes, handling occlusions and irregular shapes gracefully, offering greater flexibility and robustness than methods that rely on strong global assumptions.
State-of-the-art Results#
A hypothetical ‘State-of-the-art Results’ section would demand a thorough analysis. It needs to clearly present the model’s performance metrics compared to existing top-performing methods. Quantitative comparisons using established benchmarks are crucial, showing improvements in accuracy, precision, recall, or F1-score. The section should also account for the datasets used. The choice of datasets is critical; results on a diverse range of datasets highlight the model’s generalizability. It should explain any limitations of the comparison, such as differences in evaluation metrics or dataset sizes. If the model surpasses existing methods, it should clearly indicate the magnitude of this improvement. Qualitative analysis is also beneficial, possibly using visualizations to showcase differences between the model and other top-performers. Any unexpected results or inconsistencies in performance across datasets should be discussed. Furthermore, the section should provide insights about the reasons behind the performance, explaining factors that contribute to improved results. Finally, it’s essential to address the reproducibility of the results. Clear documentation on the experimental setup and methodology helps others to verify and build upon the findings. By covering all these points, a compelling and informative ‘State-of-the-art Results’ can be created.
Future Work & Limits#
The authors acknowledge limitations in handling highly non-planar scenes and view-dependent effects, where the planar assumption for AlphaTablets might not hold. Future work should focus on enhancing AlphaTablets to address these challenges. This could involve incorporating view-dependent modeling to improve robustness in complex scenes with varying lighting and non-Lambertian surfaces. Investigating hybrid scene representations, combining AlphaTablets with other primitives like Gaussians, could also lead to more accurate and comprehensive scene modeling. Furthermore, exploring more sophisticated merging schemes and optimizing the computational efficiency of the current pipeline are also promising avenues for future research. Finally, the current approach relies on off-the-shelf geometric estimation models; improving the accuracy and robustness of these initial estimations will directly impact the overall performance of the 3D planar reconstruction. Addressing these limitations and exploring these directions will significantly advance the capabilities and generalizability of the AlphaTablets framework.
More visual insights#
More on figures
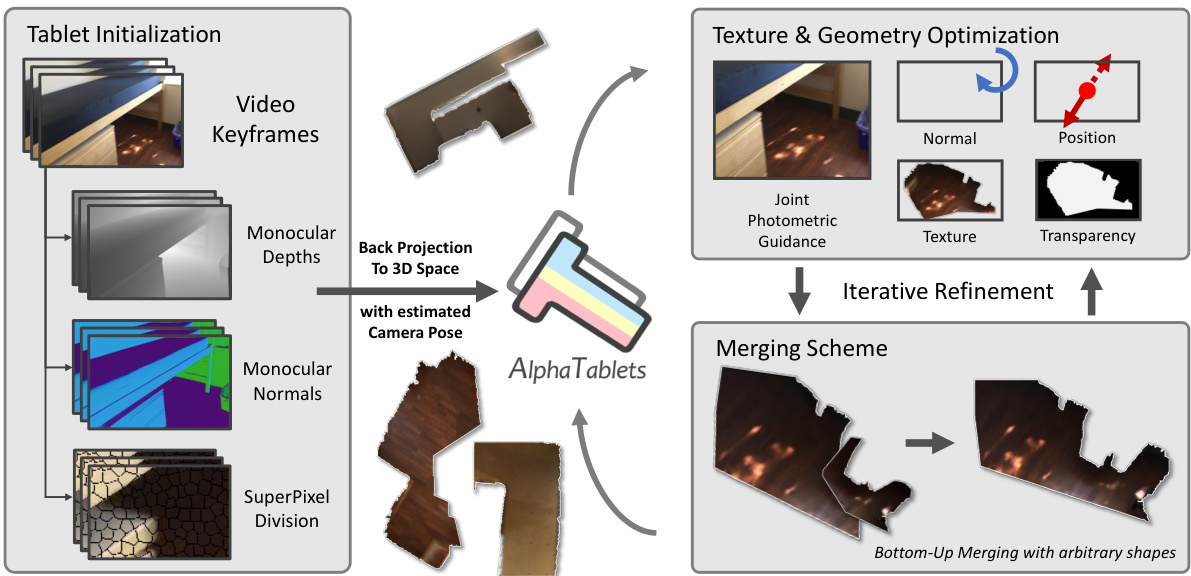
🔼 This figure illustrates the pipeline of the proposed 3D planar reconstruction method. It starts with input video keyframes, and uses pre-trained models to estimate depth, surface normals, and superpixels. These are then used to initialize 3D AlphaTablets. The AlphaTablets are iteratively refined through optimization using photometric guidance and a merging scheme to produce accurate, complete 3D planar reconstructions.
read the caption
Figure 2: Pipeline of our proposed 3D planar reconstruction. Given a monocular video as input, we first initialize AlphaTablets using off-the-shelf superpixel, depth, and normal estimation models. The 3D AlphaTablets are then optimized through photometric guidance, followed by the merging scheme. This iterative process of optimization and merging refines the 3D AlphaTablets, resulting in accurate and complete 3D planar reconstruction.
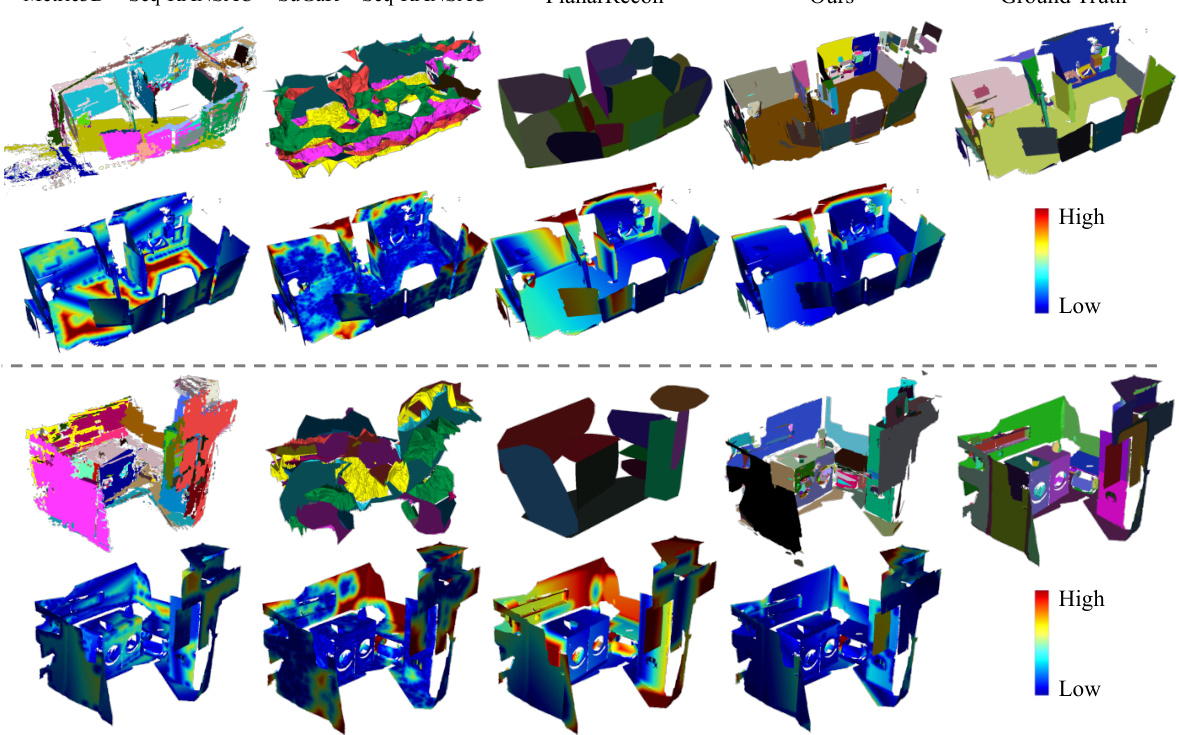
🔼 This figure displays a qualitative comparison of 3D plane reconstruction results on the ScanNet dataset. Multiple methods are shown, including Metric3D + Seq-RANSAC, SuGaR + Seq-RANSAC, PlanarRecon, and the proposed ‘Ours’ method. For each method, the results are visualized alongside the ground truth, providing a visual comparison of the accuracy and completeness of plane reconstruction. Error maps are overlaid to highlight areas of discrepancy between the reconstructed planes and the ground truth. The figure is best viewed when zoomed in for detailed observation of reconstruction accuracy.
read the caption
Figure 3: Qualitative results on ScanNet. Error maps are included. Better viewed when zoomed in.
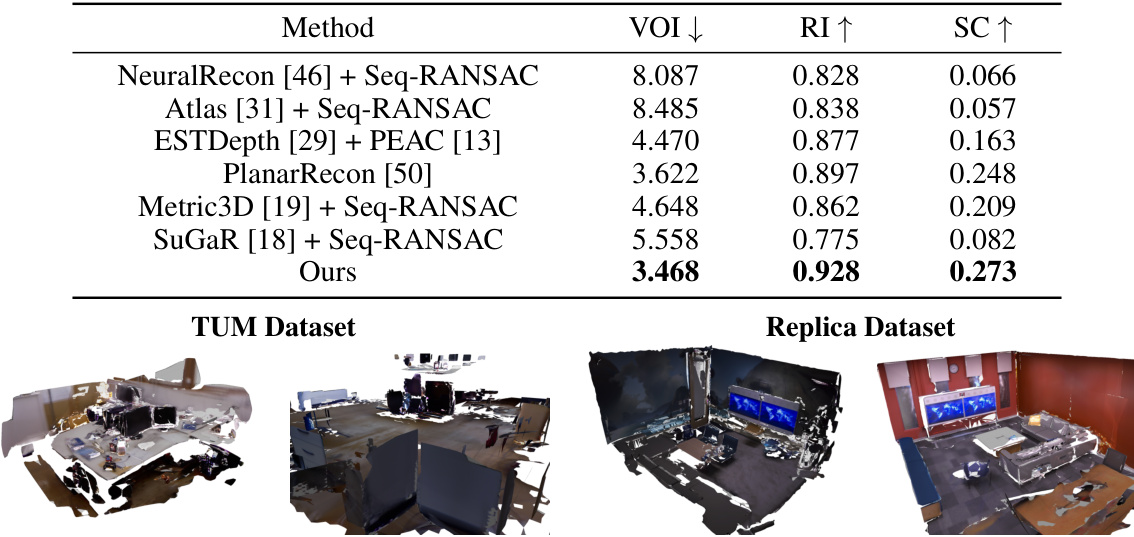
🔼 This figure shows qualitative results of 3D plane reconstruction on the TUM-RGBD and Replica datasets. It visually compares the results of the proposed AlphaTablets method with several baseline methods. The goal is to demonstrate the generalization capabilities of the AlphaTablets approach beyond the ScanNet dataset used primarily in the quantitative experiments. The images provide a visual comparison of the reconstructed 3D planes, highlighting the accuracy and completeness of the AlphaTablets approach compared to the baselines.
read the caption
Figure 4: Qualitative results on TUM-RGBD and Replica datasets.
🔼 This figure presents qualitative results of 3D plane reconstruction on the ScanNet dataset using various methods, including the proposed approach. The visualization shows the reconstructed 3D planes overlaid on the original scene images. Error maps are also included to highlight the discrepancies between the reconstructed and ground truth planes. The results demonstrate the effectiveness of the proposed approach in accurately reconstructing planar surfaces in complex scenes.
read the caption
Figure 10: More qualitative results on ScanNet. Error maps are included. Better viewed when zoomed in.

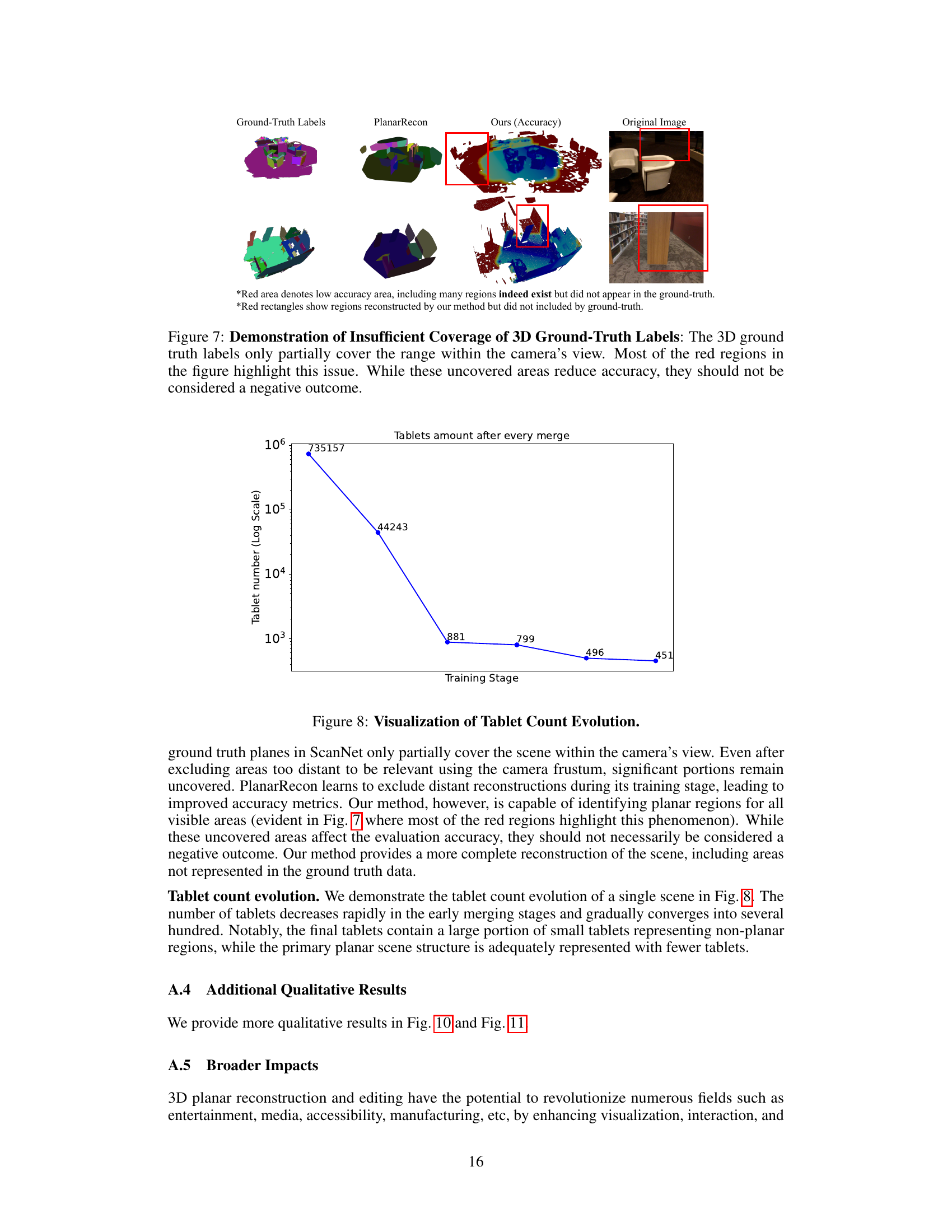
🔼 This figure demonstrates a limitation of the ScanNet dataset’s ground truth labels. The ground truth only covers a portion of the scene visible to the camera. The red boxes highlight areas where the method’s reconstruction surpasses the ground truth, which is not necessarily an error, but shows the incompleteness of the labels.
read the caption
Figure 7: Demonstration of Insufficient Coverage of 3D Ground-Truth Labels: The 3D ground truth labels only partially cover the range within the camera's view. Most of the red regions in the figure highlight this issue. While these uncovered areas reduce accuracy, they should not be considered a negative outcome.
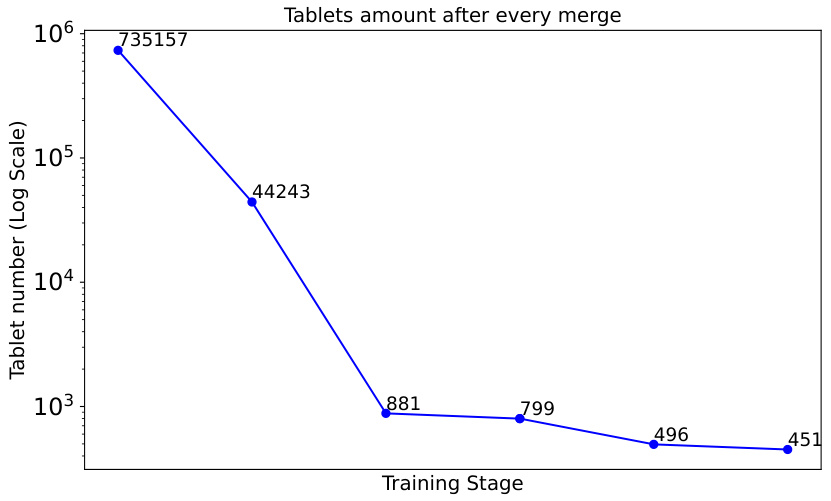
🔼 This figure shows the evolution of the number of tablets during the merging process in the 3D planar reconstruction pipeline. It plots the number of tablets (in log scale) against the training stage. The graph shows a rapid decrease in the tablet count during the initial merging stages, followed by a gradual convergence to a smaller number of tablets. This visualization demonstrates the effectiveness of the merging scheme in refining the reconstruction by combining smaller, overlapping tablets into larger, more coherent planar structures.
read the caption
Figure 8: Visualization of Tablet Count Evolution.

🔼 The figure shows a comparison between naive anti-aliasing and the proposed tablet anti-aliasing method. Naive anti-aliasing results in noticeable, unwanted strip artifacts along edges. In contrast, the proposed method effectively reduces these artifacts, producing cleaner and more accurate results.
read the caption
Figure 9: Qualitative comparison of our tablet anti-aliasing scheme. Naive anti-aliasing will lead to wrong strip artifacts, while our anti-aliasing scheme effectively mitigates those artifacts.

🔼 This figure presents a qualitative comparison of 3D planar reconstruction results on the ScanNet dataset. It compares the performance of various methods, including Metric3D + Seq-RANSAC, SuGaR + Seq-RANSAC, PlanarRecon, and the proposed AlphaTablets method. For each method, the figure shows 3D point clouds of reconstructed scenes, along with error maps to highlight inaccuracies. The ground truth is also provided for reference. The visualization emphasizes the ability of AlphaTablets to achieve more accurate and detailed reconstructions compared to baselines, particularly with complex and irregular scenes.
read the caption
Figure 10: More qualitative results on ScanNet. Error maps are included. Better viewed when zoomed in.

🔼 Qualitative results on TUM-RGBD and Replica datasets are presented, comparing our method with baselines. The figure showcases the reconstruction capabilities of the proposed method on different datasets and scenes, highlighting its ability to accurately reconstruct planar surfaces even in complex scenarios.
read the caption
Figure 4: Qualitative results on TUM-RGBD and Replica datasets.
More on tables
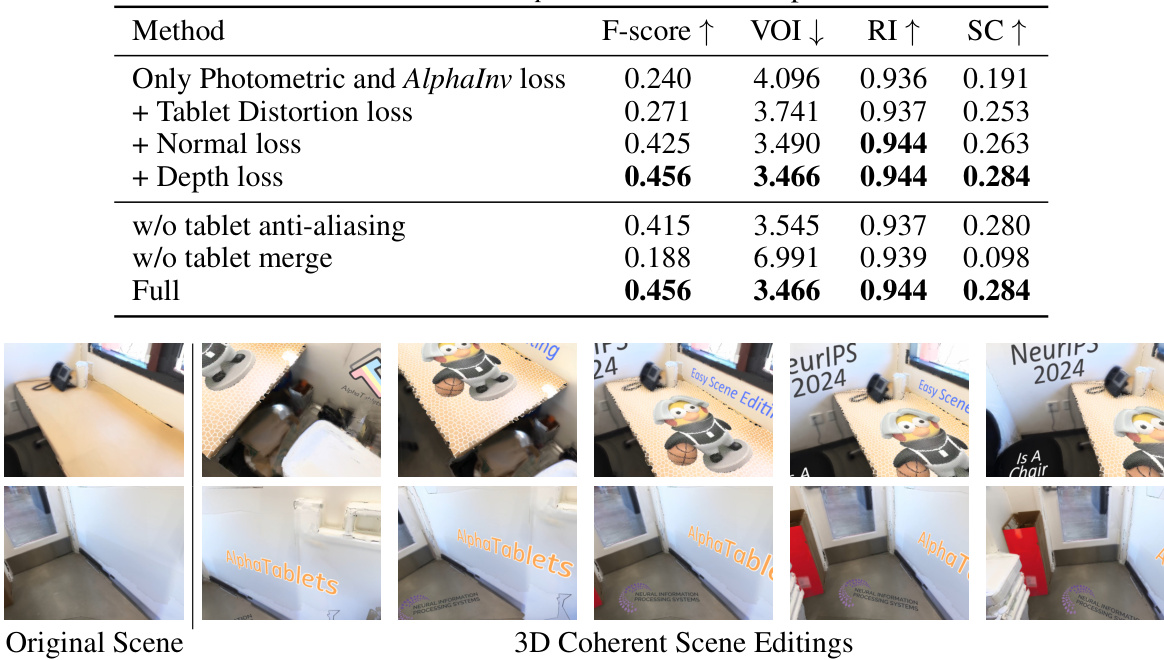
🔼 This table presents the ablation study results, comparing the full model with variations where components like tablet distortion loss, normal loss, depth loss, tablet anti-aliasing, and tablet merge are excluded. The F-score, VOI, RI, and SC metrics are used to evaluate the performance of each variation, demonstrating the importance of each component in achieving high accuracy in 3D plane reconstruction.
read the caption
Table 3: Ablation studies. AlphaInv denotes the alpha inverse loss.

🔼 This table presents the ablation study results on the impact of different initial merging strategies on the overall performance of the 3D planar reconstruction. It compares four variations: no in-training merge and no initial merge, no in-training merge only, no initial merge only, and the full method with all merging schemes. The results are evaluated using F-score, Variation of Information (VOI), Rand Index (RI), and Segmentation Covering (SC) metrics. The full method consistently shows superior performance compared to the other variations.
read the caption
Table 4: Ablation studies on initial merge.

🔼 This table presents the ablation study results comparing different initialization methods for the SuGaR baseline. It shows a comparison of F-score, Variation of Information (VOI), Rand Index (RI), and Segmentation Covering (SC) metrics. The three methods compared are: SuGaR with COLMAP initialization, SuGaR with Metric3D initialization, and the proposed AlphaTablets method. The results demonstrate the superior performance of the AlphaTablets method.
read the caption
Table 5: Ablation studies on different initialization of SuGaR.
🔼 This table presents a quantitative comparison of the proposed AlphaTablets method against several state-of-the-art approaches for 3D geometry reconstruction on the ScanNet dataset. Metrics include completeness accuracy, recall, precision, and F-score, providing a comprehensive evaluation of the different methods’ performance in reconstructing 3D planar structures from monocular video data.
read the caption
Table 1: 3D geometry reconstruction results on ScanNet.
Full paper#