TL;DR#
Self-supervised learning (SSL) with joint-embedding architectures (JEA) has traditionally relied on complex data augmentations for optimal performance. However, recent studies show that reconstruction-based models achieve strong performance without these augmentations. This raises questions about the true necessity of augmentations in JEA-based SSL.
This research investigates the role of data augmentations in JEAs at scale, using DINOv2 as a case study. The authors trained DINOv2 with various augmentation strategies, demonstrating that strong image representations can be obtained with only cropping (without resizing) when sufficient training data is available. They achieved state-of-the-art results using the least amount of augmentation reported, challenging the common assumption that augmentations are crucial for JEA performance.
Key Takeaways#
Why does it matter?#
This paper challenges the long-held belief that data augmentations are crucial for self-supervised learning, particularly in joint-embedding architectures. By demonstrating state-of-the-art results with minimal augmentations on a large-scale model, it prompts a reassessment of current practices and opens avenues for more efficient and generalizable self-supervised learning methods. The findings also highlight the significant impact of dataset size and computational resources on experimental outcomes.
Visual Insights#
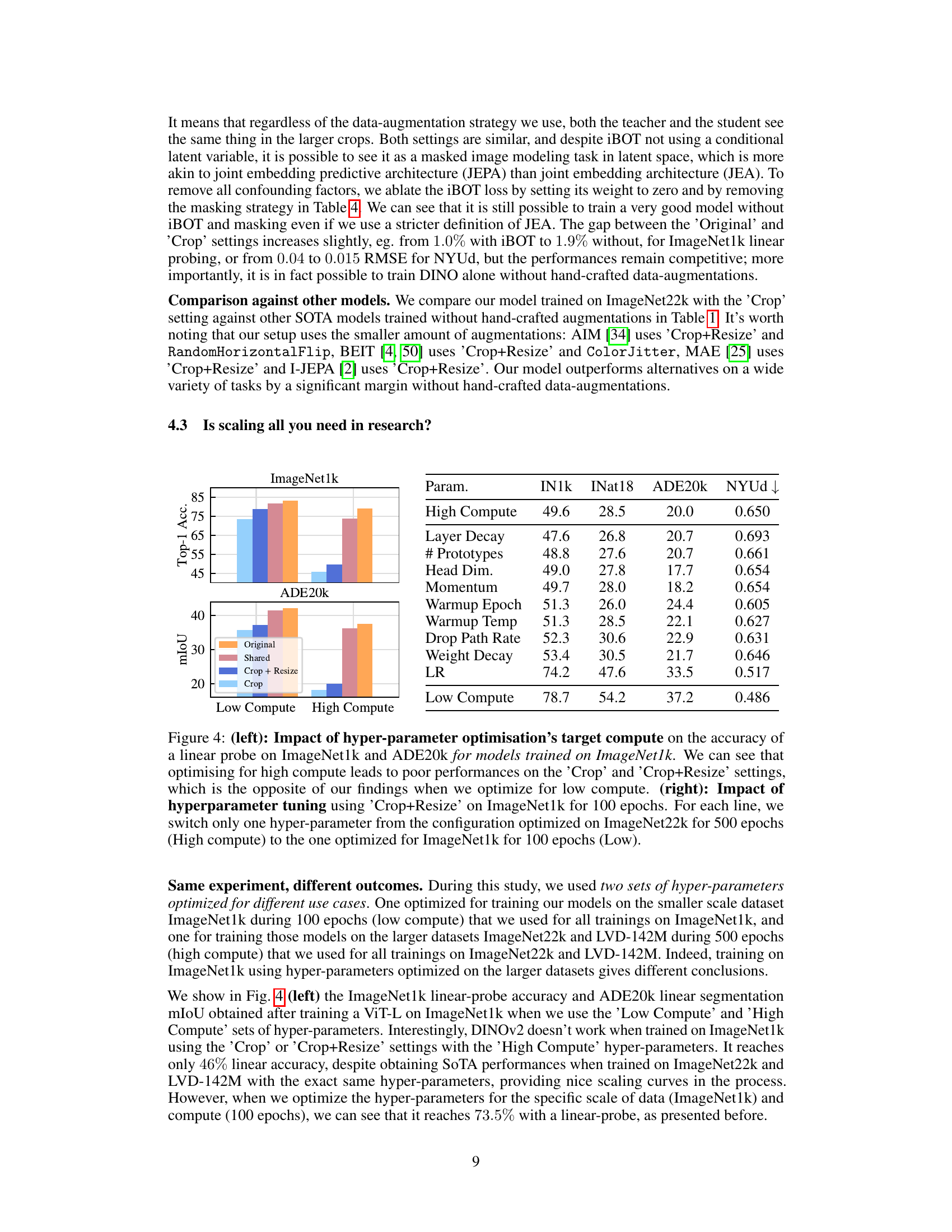
🔼 The figure illustrates the different data augmentation strategies used in the paper’s experiments. The top part shows the three loss functions used during pretraining: local-to-global DINO loss, global-to-global DINO loss, and the iBOT loss. The bottom part visualizes the four augmentation strategies used: ‘Original’ (with multiple augmentations), ‘Shared’ (sharing augmentations between views), ‘Crop + Resize’ (only using RandomResizedCrop), and ‘Crop’ (using RandomCrop without resizing). Each strategy is represented with example images, showing the transformations applied.
read the caption
Figure 1: Top: Visual description of pretraining losses. In blue: the local to global DINO loss, in red: the global to global DINO loss and in green the latent masked token prediction (iBOT) loss. Bottom: Our different augmentation strategies. 'Original' uses several augmentations (RandomResizedCrop, ColorJitter, RandomGrayscale, GaussianBlur, RandomHorizontalFlip and RandomSolarize), 'Shared' uses the same augmentations but shares them between each view of the same image obtained with RandomResizedCrop. The 'Crop + Resize' setting only uses RandomResizedCrop. We also introduce a 'Crop' setup which uses RandomCrop without random rescaling and that is visually similar to 'Crop + Resize'.
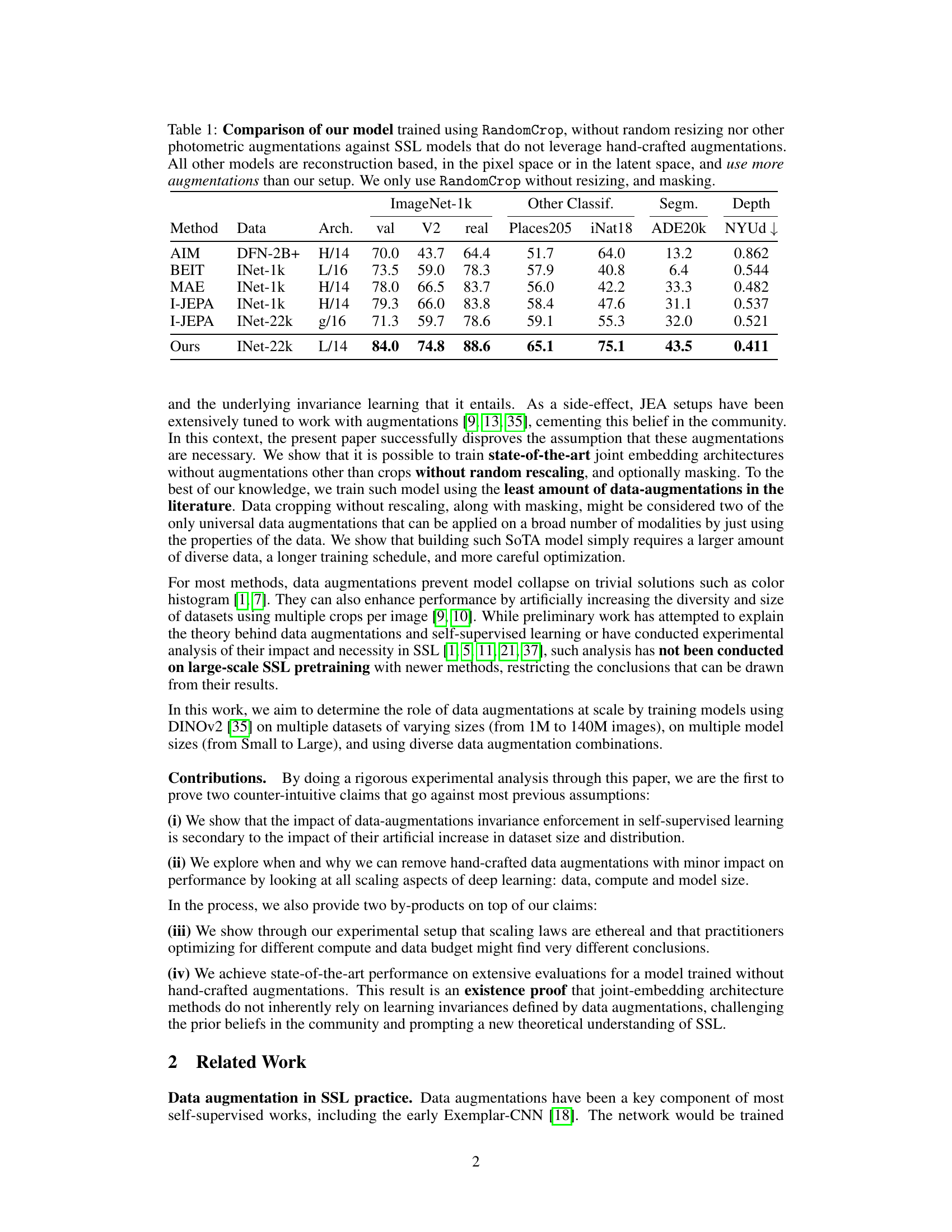
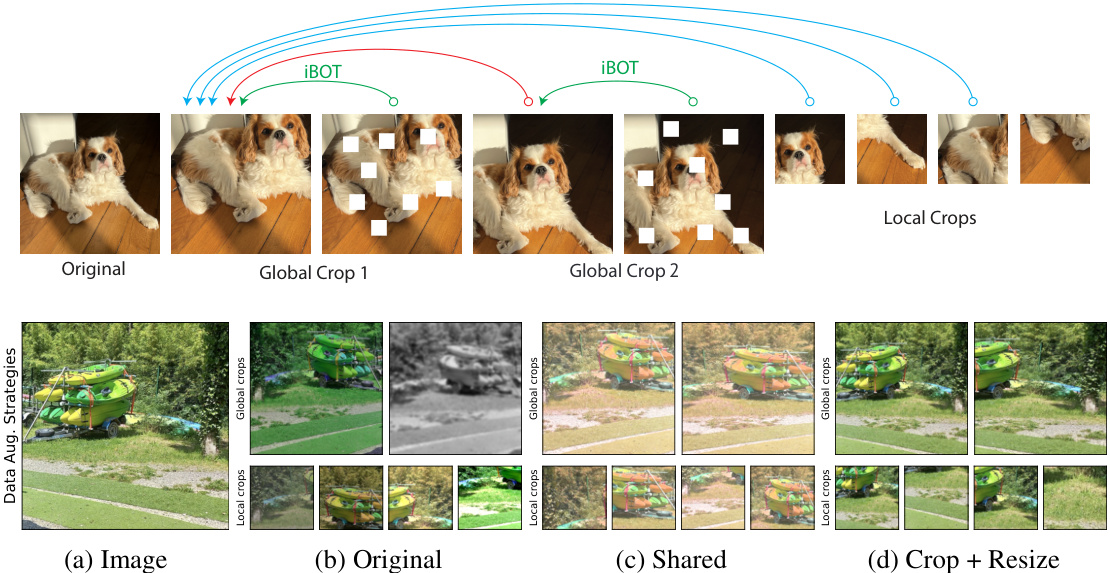
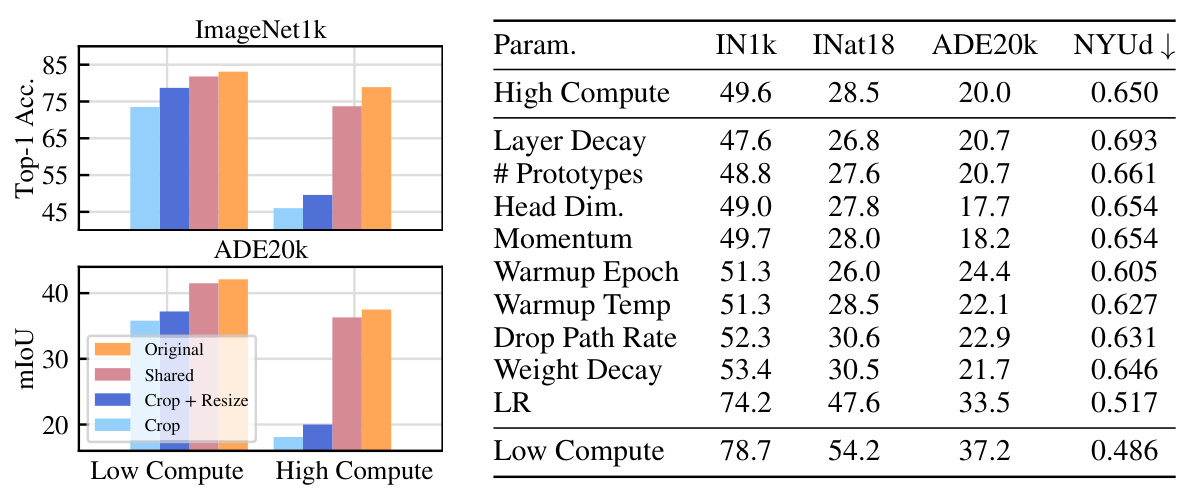
🔼 This table compares the performance of the authors’ self-supervised learning model (using only RandomCrop data augmentation) against other state-of-the-art models that do not use hand-crafted data augmentations. It highlights that the authors’ model achieves comparable or superior results despite using significantly fewer augmentations. The table presents results on various image classification, segmentation and depth estimation benchmarks, demonstrating the generalizability of the approach.
read the caption
Table 1: Comparison of our model trained using RandomCrop, without random resizing nor other photometric augmentations against SSL models that do not leverage hand-crafted augmentations. All other models are reconstruction based, in the pixel space or in the latent space, and use more augmentations than our setup. We only use RandomCrop without resizing, and masking.
In-depth insights#
SSL Augmentation#
The role of data augmentations in self-supervised learning (SSL) is a central theme explored in the provided research paper. The authors challenge the long-held belief that domain-specific augmentations are crucial for high performance, particularly within joint-embedding architectures (JEAs). Their key finding is that carefully designed cropping, without resizing or other photometric augmentations, can achieve state-of-the-art results on large datasets, provided sufficient compute resources and training time. This contradicts prior work suggesting that augmentations are essential for learning invariance and preventing model collapse. The study rigorously explores the interplay between data size, compute resources, model capacity and augmentation strategy, demonstrating that the impact of augmentations may be secondary to their effect of artificially enlarging the dataset, thereby promoting robustness and generalization. Therefore, the research advocates for a reassessment of the conventional wisdom around augmentations in SSL, suggesting that simpler strategies might be sufficient at scale, paving the way for more generalizable and efficient SSL models.
DINOv2 at Scale#
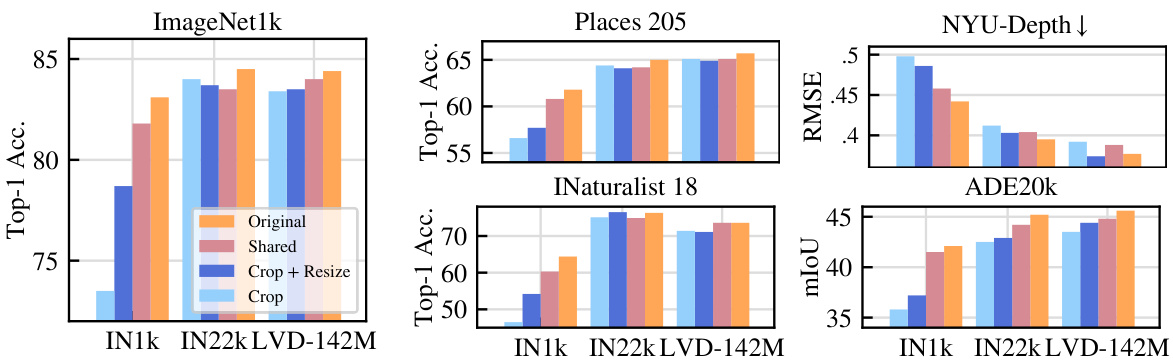
The concept of “DINOv2 at Scale” explores the impact of scaling various factors on the performance of the DINOv2 self-supervised learning model. Increased dataset size significantly mitigates the reliance on extensive data augmentations, demonstrating that performance gains are strongly correlated with dataset size. This challenges existing beliefs about the necessity of data augmentations for JEA (Joint Embedding Architecture) models. The study shows that scaling model size and training epochs also contribute to improved accuracy, but the effect is less pronounced than the effect of dataset size. Compute constraints, however, play a critical role; different conclusions could be drawn based on how these constraints are addressed. In essence, the findings suggest that the key to strong SSL (Self-Supervised Learning) performance in JEAs is the availability of large, diverse datasets rather than relying heavily on hand-crafted augmentations, especially as model sizes and training times increase.
Invariance Debate#
The “Invariance Debate” in self-supervised learning (SSL) centers on the role of data augmentations in creating robust, generalizable models. The prevailing belief is that augmentations, by enforcing invariance to transformations (e.g., cropping, color jittering), are crucial for preventing model collapse and learning meaningful representations. However, this paper challenges that assumption. The core argument is that the impact of data augmentations is secondary to the effect of increasing the dataset size. While invariance is helpful, particularly with smaller datasets, the increased diversity and volume of data provided by augmentations are far more critical in achieving high performance at scale. This is supported by experiments showing that simpler augmentations (e.g., cropping alone) can yield state-of-the-art results with large enough datasets, thus suggesting that the focus should shift from carefully crafting augmentations to scaling the dataset size. Ultimately, the study argues for a re-evaluation of the fundamental principles of JEA-based SSL, questioning the necessity of complex augmentations and highlighting the importance of data scaling in achieving exceptional performance.
Scaling Laws Impact#
The concept of “Scaling Laws Impact” in the context of self-supervised learning (SSL) and joint-embedding architectures (JEA) focuses on how increasing dataset size, computational resources, and model capacity affect the performance and the need for data augmentations. The paper’s key finding is that augmentations are not inherently necessary for strong performance; their main benefit is in artificially increasing dataset size and diversity. This is evidenced by the fact that, with sufficiently large datasets, models trained with minimal augmentations (only cropping) achieve state-of-the-art results. The interplay between these scaling factors is complex, with smaller datasets showing a greater dependence on augmentations to prevent overfitting and improve generalization. Furthermore, the study reveals that scaling laws themselves can lead to different conclusions depending on the compute and data budget employed, highlighting a need for careful consideration of experimental design and resource allocation in deep learning research. This emphasizes the importance of adequately scaling all three factors to obtain optimal performance in SSL. Finally, the study challenges the deeply held belief in the necessity of augmentation in JEAs, proposing that its role might be primarily optimization-related rather than directly influencing core learning principles.
Future Research#
Future research directions stemming from this work could explore the generalizability of these findings to other self-supervised learning architectures beyond DINOv2. Investigating the interaction between model size, dataset size, and augmentation strategies across diverse architectures is crucial to solidify the claims. Further investigation is needed to quantify the trade-offs between training speed, dataset size, and the degree of data augmentation, offering a comprehensive understanding of the scaling laws involved. Exploring the impact of alternative data augmentations (besides cropping) on model performance and robustness, especially in low-data regimes, is important. Finally, research should focus on developing a deeper theoretical understanding of why reduced augmentations work effectively, potentially by exploring connections to information theory and inductive biases.
More visual insights#
More on figures
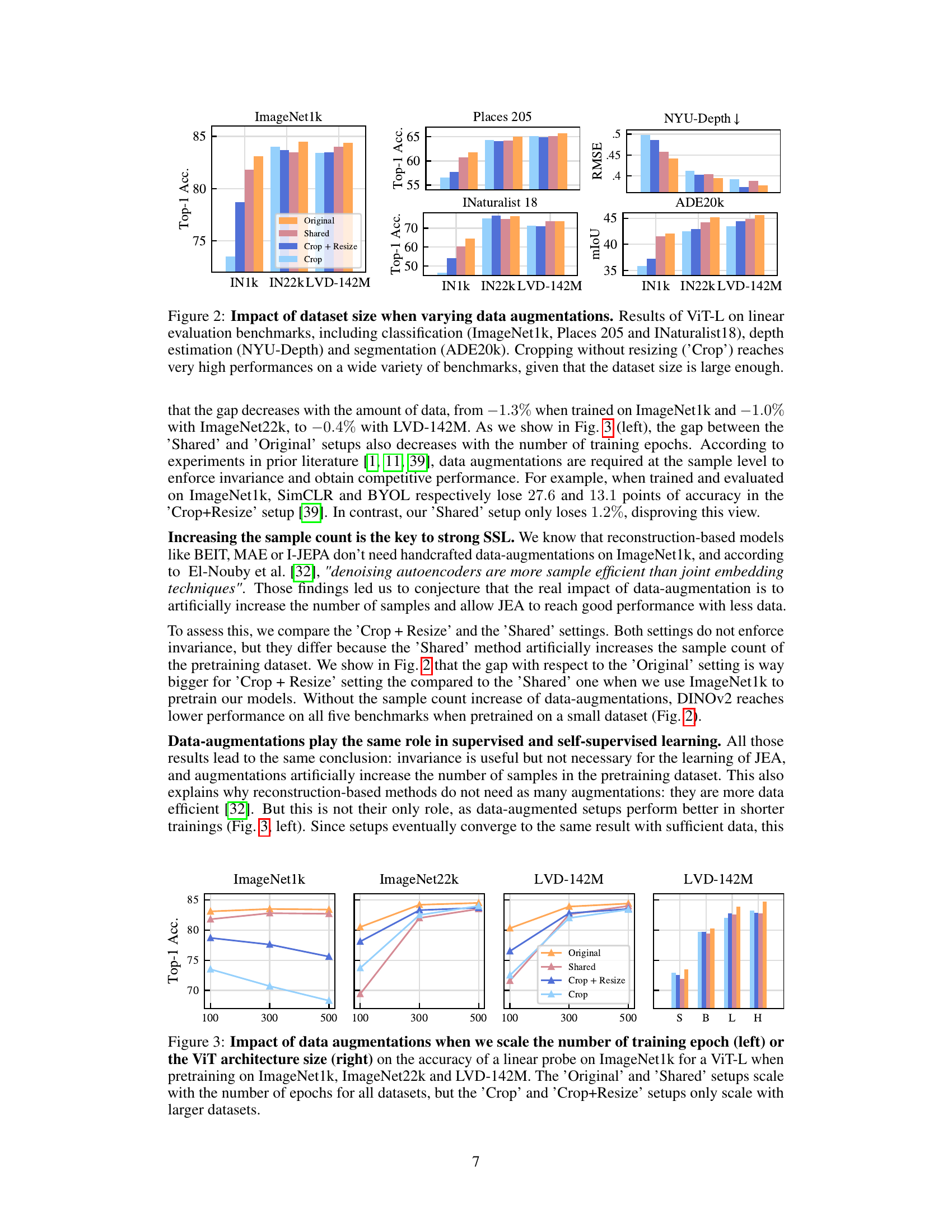
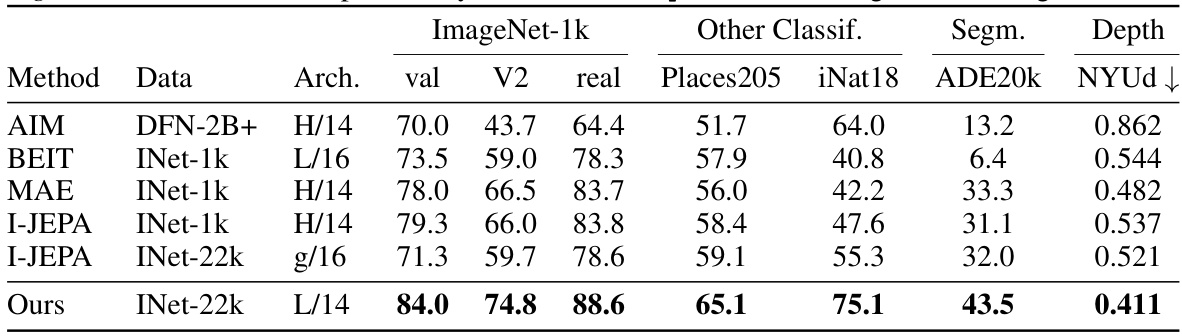
🔼 This figure shows the performance of a ViT-L model on various downstream tasks (ImageNet1k classification, Places 205 classification, iNaturalist18 classification, NYU-Depth depth estimation, and ADE20k segmentation) when trained with different data augmentation strategies and varying dataset sizes (ImageNet-1k, ImageNet-22k, and LVD-142M). The results demonstrate that using only cropping without resizing (‘Crop’) achieves high performance, especially with larger datasets. This finding suggests that data augmentation’s primary role might be to effectively increase dataset size rather than to enforce invariance learning.
read the caption
Figure 2: Impact of dataset size when varying data augmentations. Results of ViT-L on linear evaluation benchmarks, including classification (ImageNet1k, Places 205 and INaturalist18), depth estimation (NYU-Depth) and segmentation (ADE20k). Cropping without resizing ('Crop') reaches very high performances on a wide variety of benchmarks, given that the dataset size is large enough.
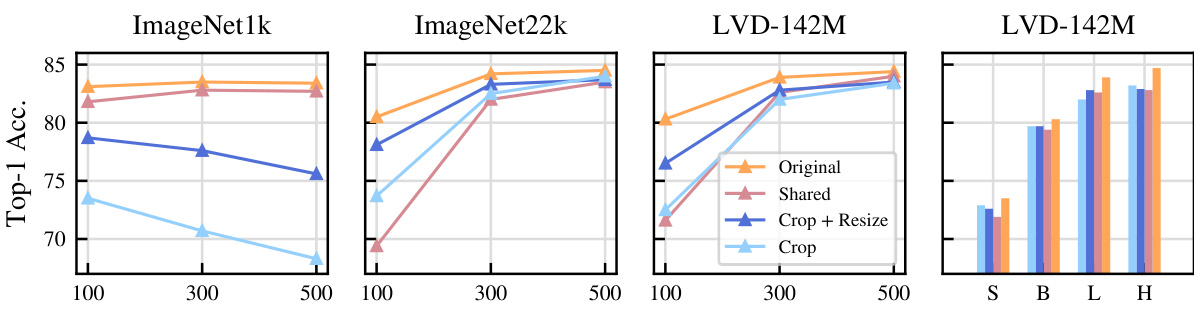
🔼 This figure shows the impact of dataset size on the performance of a Vision Transformer (ViT-L) model trained with different data augmentation strategies. The x-axis represents the number of training epochs (100, 300, 500). The y-axis represents the Top-1 accuracy achieved on various downstream tasks (ImageNet1k, Places205, INaturalist18, NYU-Depth, and ADE20k). The different lines represent different augmentation strategies: ‘Original’ (full augmentations), ‘Shared’ (augmentations shared between views), ‘Crop + Resize’ (only RandomResizedCrop), and ‘Crop’ (only cropping without resizing). The figure demonstrates that with a sufficiently large dataset, cropping without resizing achieves results comparable to using more complex augmentation strategies. The results across various benchmarks highlight the importance of sufficient training data over the specific augmentation strategies employed.
read the caption
Figure 2: Impact of dataset size when varying data augmentations. Results of ViT-L on linear evaluation benchmarks, including classification (ImageNet1k, Places 205 and INaturalist18), depth estimation (NYU-Depth) and segmentation (ADE20k). Cropping without resizing ('Crop') reaches very high performances on a wide variety of benchmarks, given that the dataset size is large enough.
🔼 This figure displays the results of experiments conducted to assess the effect of dataset size on the performance of a ViT-L model trained with different data augmentation strategies. It shows the Top-1 accuracy for ImageNet1k, Places205, and iNaturalist18; mIoU for ADE20k; and RMSE for NYU-Depth. The key finding is that using only cropping without resizing (‘Crop’) achieves high performance when the dataset size is sufficiently large, indicating that data augmentation’s primary role is in artificially inflating the dataset’s size rather than enforcing invariance.
read the caption
Figure 2: Impact of dataset size when varying data augmentations. Results of ViT-L on linear evaluation benchmarks, including classification (ImageNet1k, Places 205 and INaturalist18), depth estimation (NYU-Depth) and segmentation (ADE20k). Cropping without resizing ('Crop') reaches very high performances on a wide variety of benchmarks, given that the dataset size is large enough.
More on tables
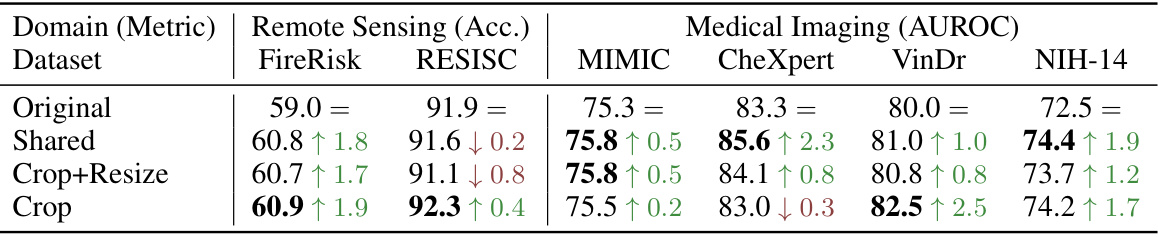
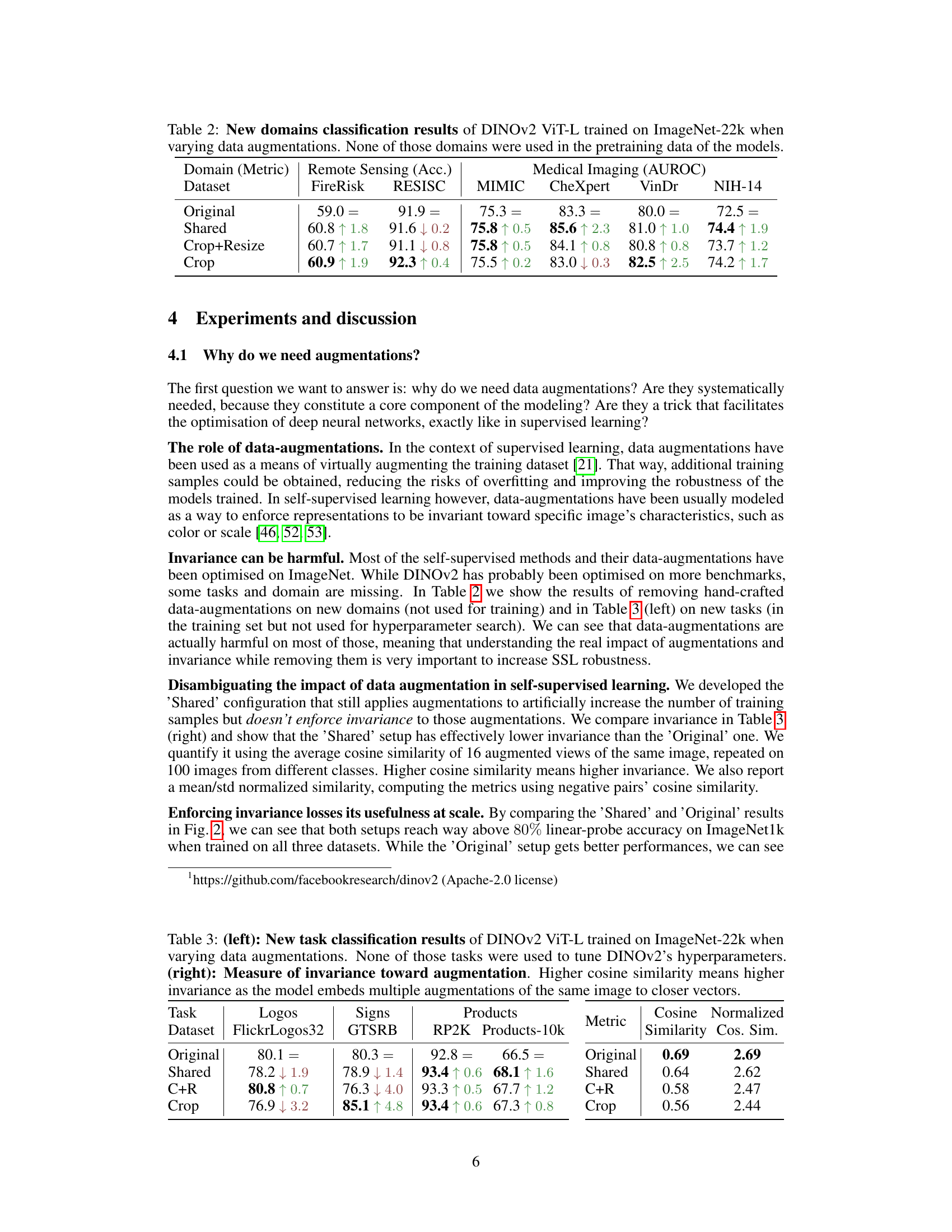
🔼 This table presents the classification accuracy (ACC) results for the DINOv2 ViT-L model trained on ImageNet-22k and tested on various new domains (not used for pretraining). The performance of four different data augmentation strategies is compared: Original (with all augmentations), Shared (same photometric augmentations for both views), Crop+Resize (RandomResizedCrop), and Crop (RandomCrop without resizing). The results highlight the impact of data augmentation on model performance across diverse domains, including remote sensing and medical imaging.
read the caption
Table 2: New domains classification results of DINOv2 ViT-L trained on ImageNet-22k when varying data augmentations. None of those domains were used in the pretraining data of the models.

🔼 This table presents a comparison of the performance of DINOv2 on new classification tasks (left) and a measure of invariance towards augmentation (right), using different data augmentation strategies. The left side shows the accuracy on several datasets not seen during training, highlighting the effects of various augmentation methods. The right side quantifies invariance by measuring the cosine similarity between embeddings of multiple augmented versions of the same image. Higher cosine similarity indicates greater invariance.
read the caption
Table 3: (left): New task classification results of DINOv2 ViT-L trained on ImageNet-22k when varying data augmentations. None of those tasks were used to tune DINOv2's hyperparameters. (right): Measure of invariance toward augmentation. Higher cosine similarity means higher invariance as the model embeds multiple augmentations of the same image to closer vectors.
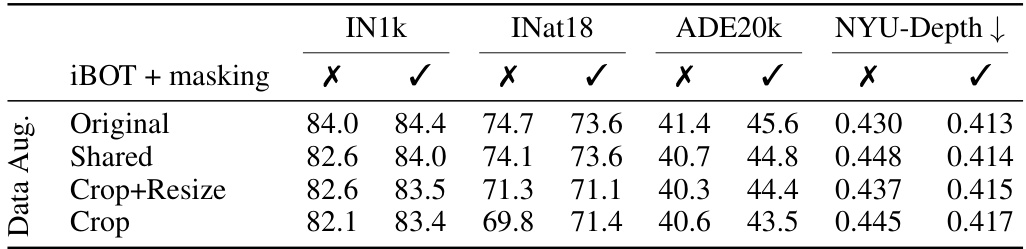
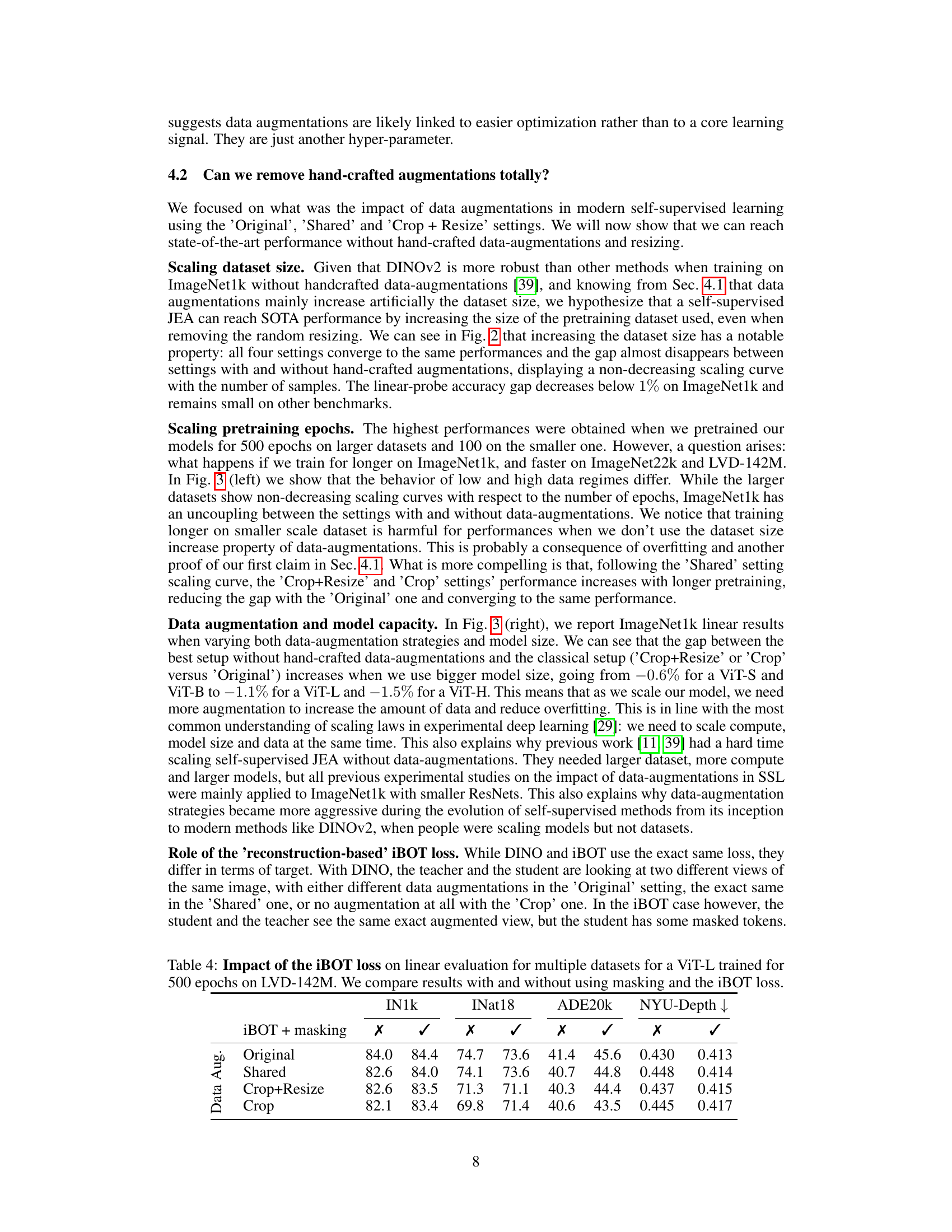
🔼 This table presents the results of linear evaluation on multiple datasets (ImageNet1k, iNaturalist18, ADE20k, and NYU-Depth) for a ViT-L model trained for 500 epochs on the LVD-142M dataset. The impact of using the iBOT loss (a local masked-image reconstruction loss) and masking is analyzed. The table compares four different data augmentation strategies: Original (with all augmentations), Shared (sharing augmentations between views), Crop+Resize (with only RandomResizedCrop), and Crop (with RandomCrop without resizing and optionally masking). The results show the performance of each augmentation strategy with and without the iBOT loss and masking, illustrating their relative effects on downstream tasks.
read the caption
Table 4: Impact of the iBOT loss on linear evaluation for multiple datasets for a ViT-L trained for 500 epochs on LVD-142M. We compare results with and without using masking and the iBOT loss.
Full paper#