TL;DR#
Federated learning (FL) is an efficient way to train machine learning models on decentralized data without sharing raw data. However, standard FL algorithms are iterative, leading to high communication costs. One-shot federated learning (OFL) reduces communication to a single round, but it typically suffers from accuracy loss, especially under high data heterogeneity.
This paper introduces FENS, a novel federated ensembling scheme that combines the communication efficiency of OFL with the accuracy of FL. FENS proceeds in two phases: 1) clients train models locally and send them to a server, and 2) clients collaboratively train a lightweight prediction aggregator model using FL. Extensive experiments show that FENS significantly outperforms existing OFL methods and approaches the accuracy of FL with minimal extra communication, making it suitable for resource-constrained settings and highly heterogeneous data distributions.
Key Takeaways#
Why does it matter?#
This paper is important because it presents FENS, a novel approach that significantly improves the accuracy of one-shot federated learning while maintaining its communication efficiency. This addresses a critical challenge in federated learning, paving the way for more efficient and accurate distributed machine learning systems. The findings are particularly relevant to researchers working on resource-constrained environments or dealing with high data heterogeneity. The techniques used in FENS, such as the shallow neural network for aggregation, may inspire new directions in federated ensemble learning.
Visual Insights#

🔼 This figure compares three different approaches to federated learning: standard iterative federated learning, one-shot federated learning, and the proposed FENS method. In iterative FL, the server and clients exchange partially trained models over multiple rounds. In one-shot FL, fully trained models are sent from clients to the server in a single round. FENS combines aspects of both: clients initially send fully trained models to the server (like one-shot FL), but then the server uses those models to train a lightweight aggregator model iteratively with the clients (like standard FL). The figure visually represents the flow of models and data between the server and clients in each approach, highlighting the key differences in communication rounds and model states.
read the caption
Figure 1: FENS in comparison to iterative and one-shot federated learning.

🔼 This table compares the performance of the proposed FENS method against six state-of-the-art one-shot federated learning (OFL) baselines across three datasets (CIFAR-100, CIFAR-10, and SVHN) and three levels of data heterogeneity (α = 0.01, 0.05, 0.1). The table shows the test accuracy achieved by each method under different heterogeneity levels and highlights the superior performance of FENS compared to the other OFL methods. The last column shows the performance improvement of FENS over the best performing baseline for each setting.
read the caption
Table 1: FENS vs one-shot FL for various heterogeneity levels across datasets. The highest achieved accuracy is presented as bold and the top-performing baseline is underlined. The rightmost column presents the performance difference between FENS and the top-performing baseline.
In-depth insights#
OFL Ensembling#
One-shot federated learning (OFL) presents a communication-efficient approach to training machine learning models, but often suffers from accuracy limitations, especially under high data heterogeneity. OFL ensembling techniques aim to improve accuracy by combining multiple locally-trained models on a server, but simple aggregation methods like averaging or weighted averaging may not fully leverage the diversity of these models. A more sophisticated approach is needed that accounts for heterogeneity and effectively combines models into a superior prediction. This involves devising an advanced aggregation function that learns from the diverse models in a way that isn’t simply averaging their predictions. A promising direction is to incorporate a secondary federated learning phase after the one-shot model exchange. This second phase would train a lightweight prediction aggregator model collaboratively on the ensemble, making use of the entire dataset spread across clients. Such a strategy aims to extract maximal benefit from the rich information inherent in the diverse locally-trained models, overcoming the limitations of simplistic aggregation techniques.
FENS: Hybrid Approach#
The proposed FENS framework represents a novel hybrid approach to one-shot federated learning (OFL), cleverly combining the communication efficiency of OFL with the accuracy of traditional iterative FL. Instead of relying solely on a single round of model aggregation like standard OFL methods, FENS employs a two-phased strategy. The first phase mirrors OFL, with clients training models locally and uploading them to a central server. The key innovation lies in the second phase: FENS utilizes a lightweight iterative FL process to train a shallow prediction aggregator model. This aggregator model leverages the ensemble of locally trained models, significantly boosting accuracy compared to basic OFL techniques. The shallow architecture of this aggregator ensures that the communication overhead of the iterative phase remains low, striking a balance between accuracy and efficiency. Extensive experiments across diverse datasets demonstrate the effectiveness of FENS, consistently outperforming state-of-the-art OFL methods while approaching the accuracy of iterative FL with minimal additional communication costs. This hybrid approach offers a powerful and practical alternative for scenarios demanding both high accuracy and reduced communication overhead.
Communication Efficiency#
Communication efficiency is a critical aspect of federated learning (FL), especially in resource-constrained environments. The paper focuses on reducing communication overhead which is a major bottleneck in traditional iterative FL. The authors address this challenge by proposing a novel one-shot federated ensembling scheme called FENS. FENS cleverly combines the efficiency of one-shot FL with the accuracy of iterative FL by employing a two-phase approach. The first phase is a classic one-shot model training where local models are trained and sent to the server. The second phase involves collaboratively training a lightweight prediction aggregator model using FL. This two-phase approach significantly reduces communication costs compared to standard iterative FL, while still maintaining high accuracy. The paper demonstrates that FENS achieves comparable performance to iterative FL at a much lower communication cost. The use of a shallow neural network for the aggregator model is instrumental in achieving this balance between accuracy and efficiency. Overall, the strategy of FENS showcases a potential for efficient FL implementation in various settings, particularly in scenarios with limited bandwidth or communication resources.
Heterogeneity Handling#
Handling data heterogeneity is crucial for successful federated learning, as data distributions across clients are rarely identical. The paper likely explores techniques to mitigate the negative impact of heterogeneity on model accuracy and convergence. This might involve data preprocessing methods to normalize or balance datasets, algorithm modifications such as weighted averaging or more sophisticated ensemble techniques, or model architectures robust to non-IID data. A key focus could be how these methods impact communication efficiency, balancing improved accuracy against the increased communication overhead often associated with addressing heterogeneity. The effectiveness of different approaches under varying levels of heterogeneity is a likely focus of the analysis, providing valuable insights into practical considerations for deploying federated learning in real-world scenarios where significant data variance is common. The role of the aggregator model, possibly a neural network, in bridging the performance gap between one-shot and iterative approaches in heterogeneous settings could be a core part of the ‘Heterogeneity Handling’ discussion, demonstrating its ability to improve accuracy while maintaining the communication efficiency benefits of one-shot methods.
Future of FENS#
The future of FENS (Federated Ensembling in One-Shot Federated Learning) is promising, given its demonstrated strengths. Addressing the communication bottleneck in traditional federated learning (FL), FENS offers comparable accuracy to iterative FL at a fraction of the communication cost. Future work could focus on improving the aggregator model, perhaps through exploring more sophisticated architectures or techniques that further reduce communication overhead. Addressing potential vulnerabilities introduced by the iterative FL phase is another critical direction. Enhancing privacy through differential privacy or secure multi-party computation within the aggregator training could significantly increase the practicality and security of FENS. Finally, extending FENS to diverse data modalities (e.g., text, images, time series) and exploring its effectiveness in complex real-world scenarios is a key area of exploration. This could unlock the potential of FENS across many applications. The modular nature of FENS, with its separate local training and aggregator training phases, allows for adaptability and customization, enhancing its long-term viability.
More visual insights#
More on figures
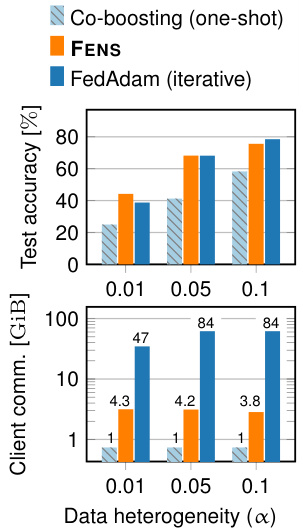
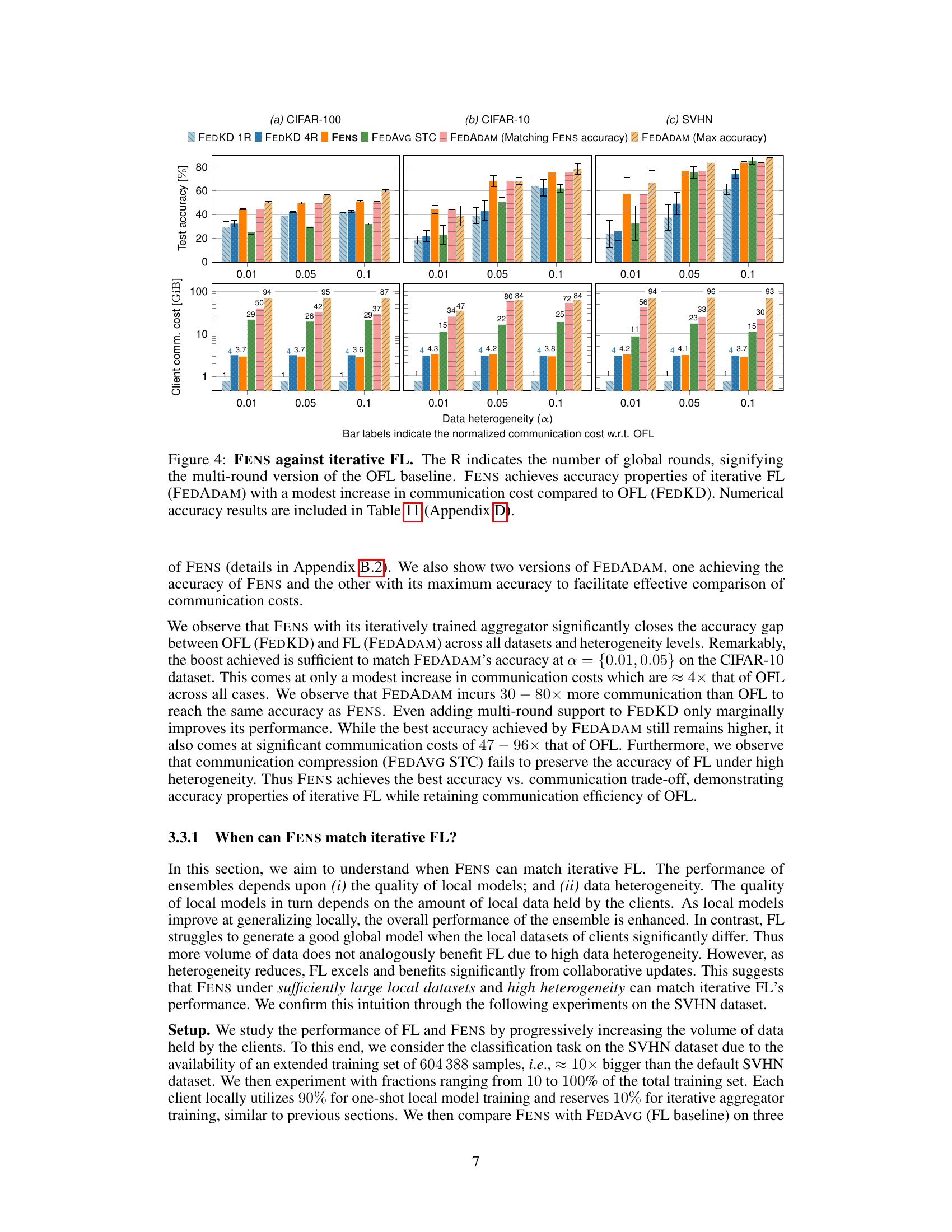
🔼 This figure compares the performance of three federated learning approaches: One-shot federated learning (OFL), the proposed FENS method, and iterative federated learning (FL). The comparison is done across three different levels of data heterogeneity (α = 0.01, 0.05, 0.1) on the CIFAR-10 dataset. The top panel shows the test accuracy achieved by each method, while the bottom panel illustrates the client communication cost in gigabytes (GiB). The bar labels in the bottom panel additionally indicate the normalized communication cost relative to OFL. The results illustrate that FENS achieves significantly higher accuracy than OFL, while maintaining a relatively low communication cost compared to FL.
read the caption
Figure 2: Test accuracy and communication cost of OFL, FENS and FL on CIFAR-10 dataset under high data heterogeneity.
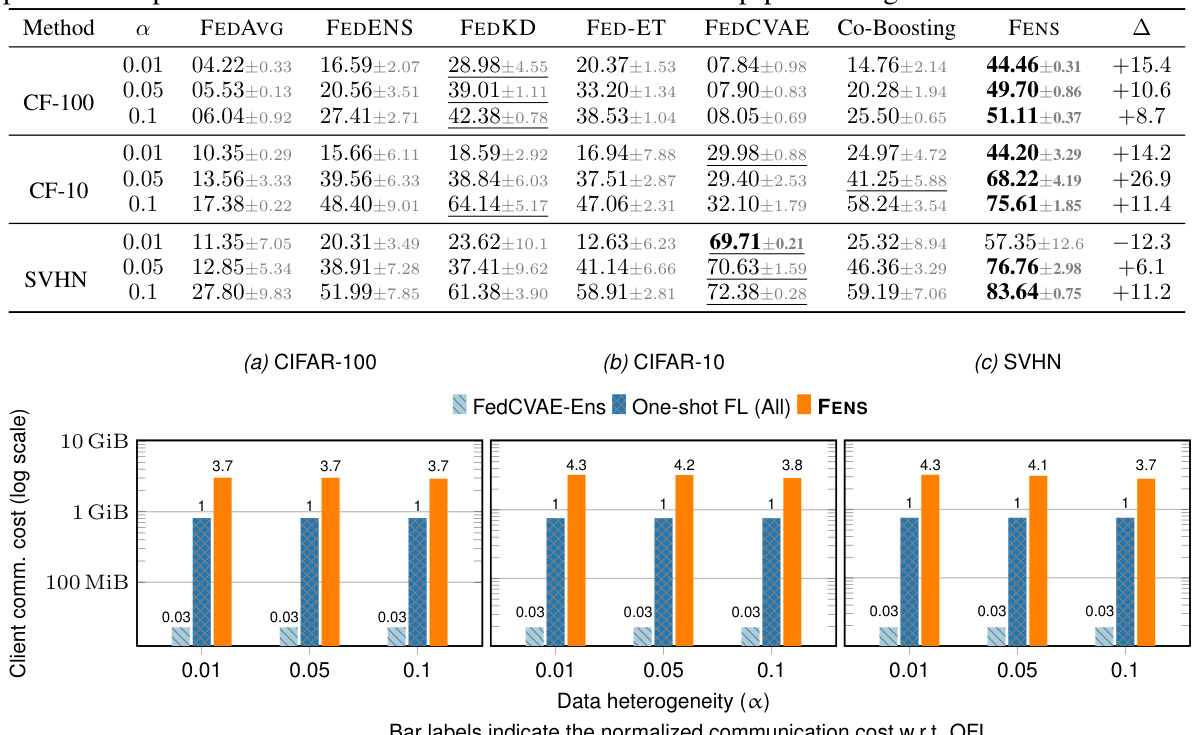
🔼 This figure compares the communication costs of FENS with various one-shot federated learning (OFL) baselines across three datasets (CIFAR-100, CIFAR-10, and SVHN) under different levels of data heterogeneity. It shows that while FENS incurs a higher communication cost than the OFL baselines (3.7-4.3 times higher), this cost is significantly lower than that of iterative federated learning methods (not shown in this figure). The bar chart visually represents the normalized communication costs, illustrating that the overhead of FENS is relatively modest compared to the substantial improvements in accuracy achieved by using its novel federated ensembling scheme.
read the caption
Figure 3: Total communication cost of FENS against OFL baselines. The clients in FENS expend roughly 3.7 – 4.3× more than OFL in communication costs.
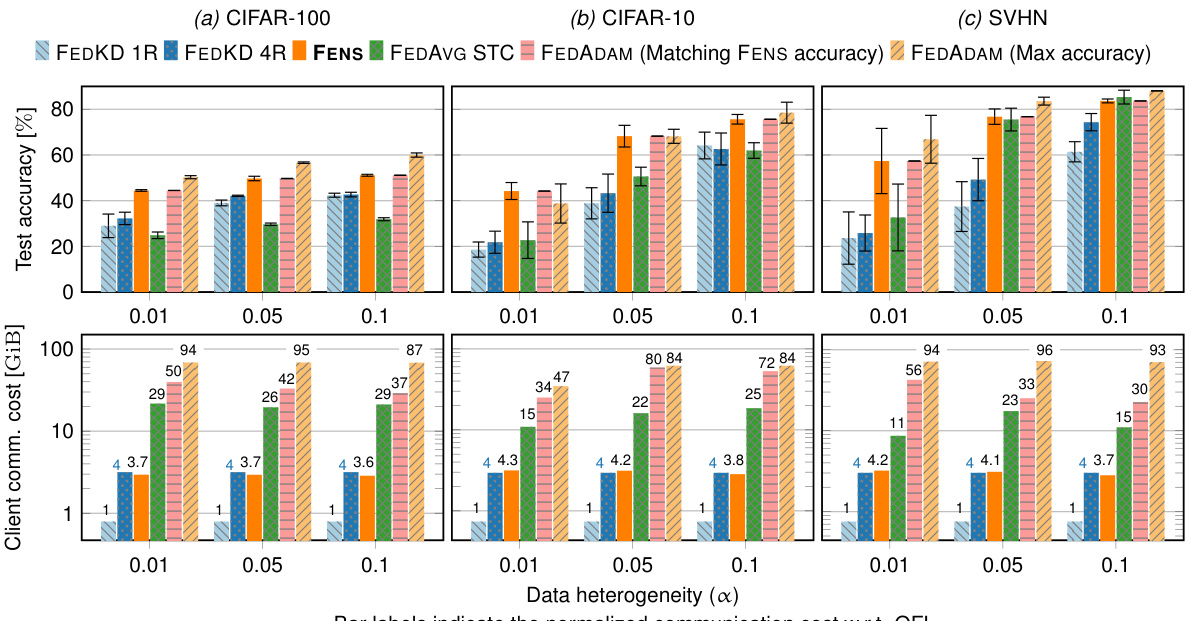
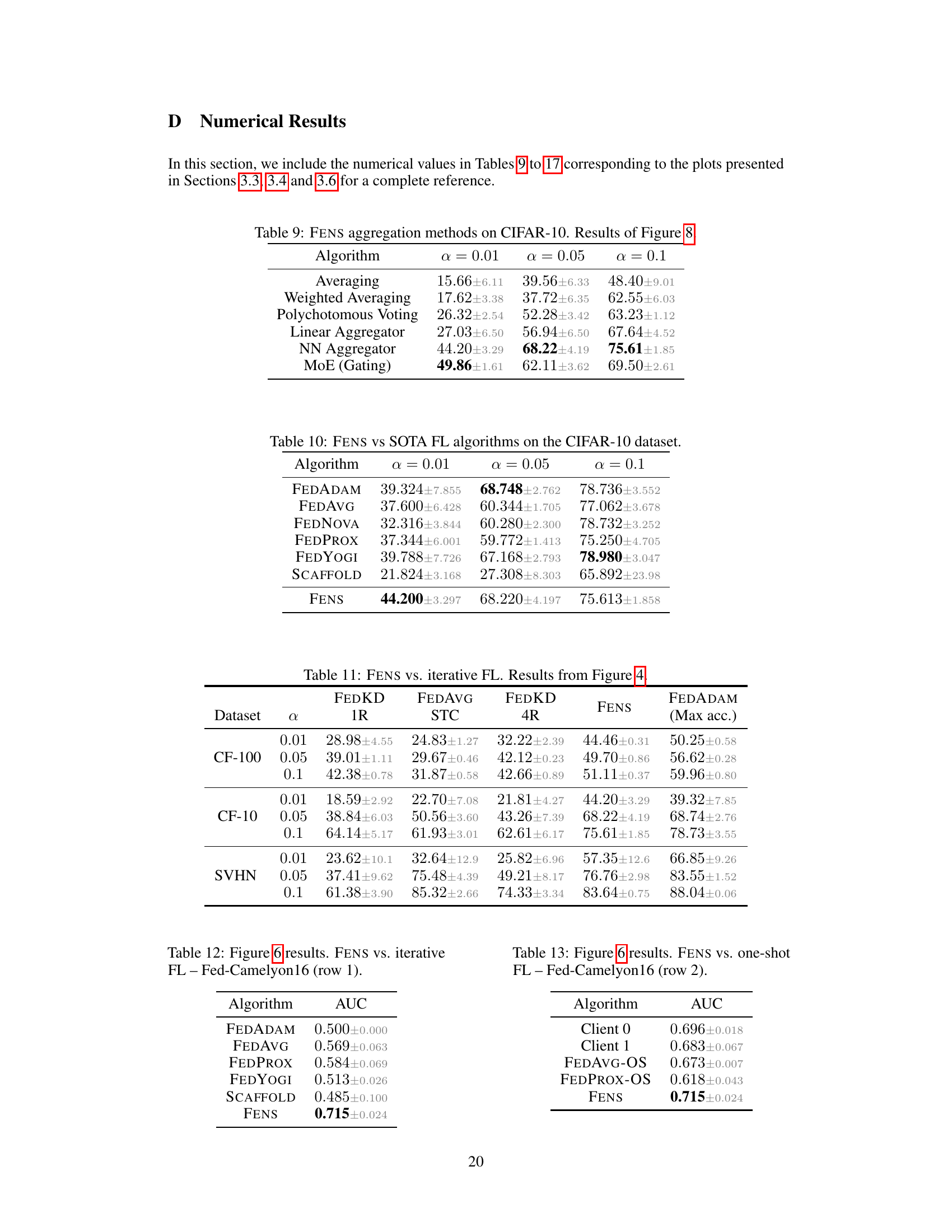
🔼 This figure compares the performance of FENS against iterative federated learning (FL) and one-shot federated learning (OFL) baselines. It shows test accuracy and communication costs across different datasets (CIFAR-100, CIFAR-10, SVHN) and heterogeneity levels. The key takeaway is that FENS achieves accuracy comparable to iterative FL with significantly lower communication overhead than traditional FL, and higher accuracy than one-shot OFL methods. The multi-round version of FEDKD, an OFL baseline, is included to provide context for the communication cost comparison.
read the caption
Figure 4: FENS against iterative FL. The R indicates the number of global rounds, signifying the multi-round version of the OFL baseline. FENS achieves accuracy properties of iterative FL (FEDADAM) with a modest increase in communication cost compared to OFL (FEDKD). Numerical accuracy results are included in Table 11 (Appendix D).

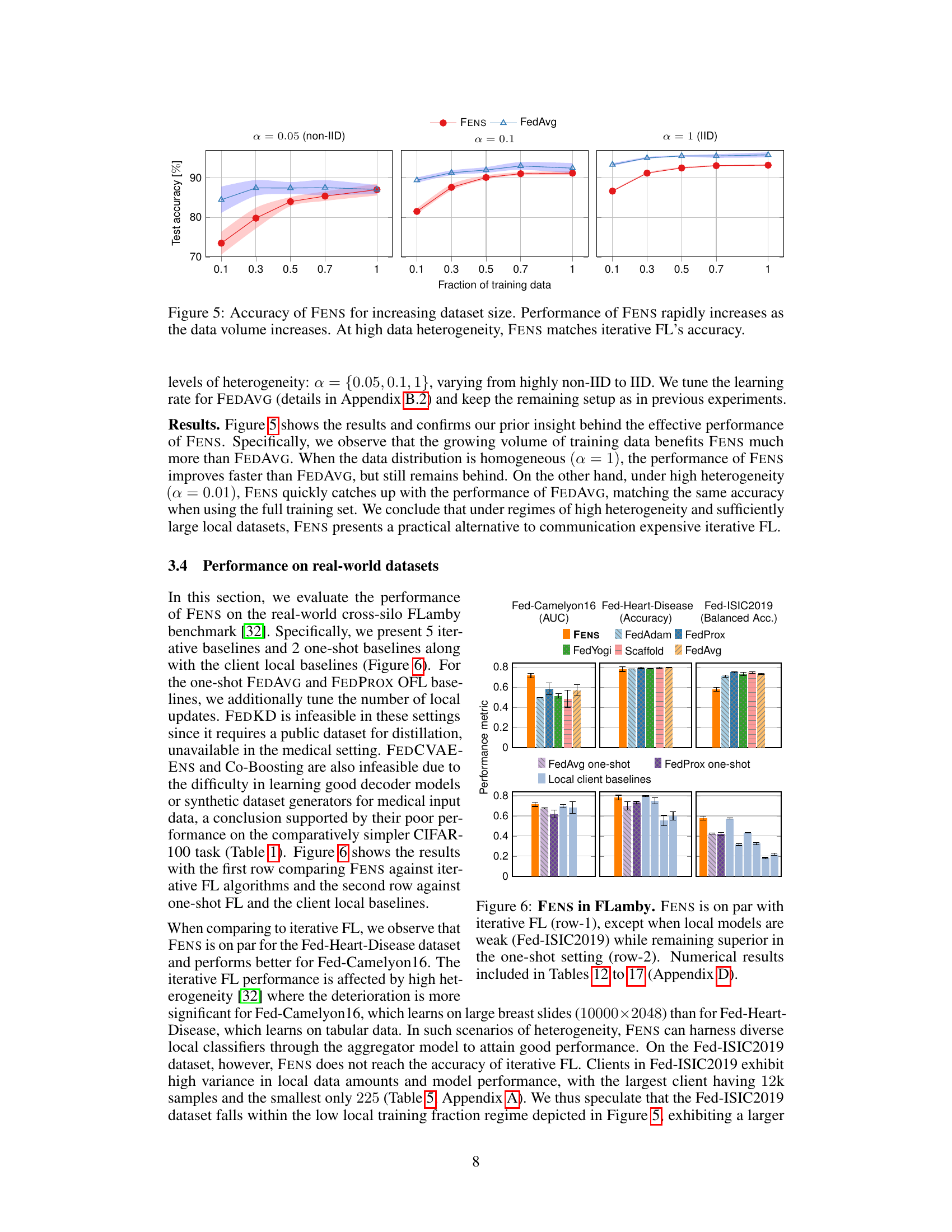
🔼 This figure shows the results of an experiment designed to understand when FENS can match iterative FL. The experiment varies the amount of training data available to the clients, while also varying the level of data heterogeneity (α). The results show that as the amount of training data increases, the performance of FENS improves significantly faster than that of FEDAVG, especially under high heterogeneity (α = 0.05). When the data distribution is homogeneous (α = 1), the performance of FENS still remains lower than that of FEDAVG. However, under high heterogeneity and sufficiently large local datasets, FENS is able to match the accuracy of FEDAVG (iterative FL).
read the caption
Figure 5: Accuracy of FENS for increasing dataset size. Performance of FENS rapidly increases as the data volume increases. At high data heterogeneity, FENS matches iterative FL's accuracy.

🔼 This figure compares the performance of FENS against various iterative and one-shot federated learning baselines on three real-world datasets from the FLamby benchmark (Fed-Camelyon16, Fed-Heart-Disease, Fed-ISIC2019). The top row shows the comparison against iterative methods, indicating FENS performs competitively with iterative FL, except on the Fed-ISIC2019 dataset where local models are weaker. The bottom row compares FENS against one-shot methods and client-side local baselines, highlighting FENS’s consistent superiority. Detailed numerical results are referenced in Appendix D.
read the caption
Figure 6: FENS in FLamby. FENS is on par with iterative FL (row-1), except when local models are weak (Fed-ISIC2019) while remaining superior in the one-shot setting (row-2). Numerical results included in Tables 12 to 17 (Appendix D).
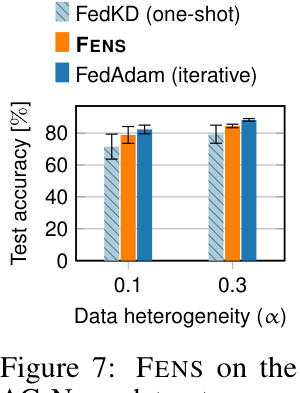
🔼 The figure compares the performance of FENS, FedKD (one-shot), and FedAdam (iterative) on the AG-News dataset under two different levels of data heterogeneity (α = 0.1 and α = 0.3). It shows that FENS significantly improves accuracy compared to FedKD, while achieving comparable performance to FedAdam, especially at higher heterogeneity (α = 0.3). This highlights the efficacy of the proposed approach, particularly in challenging, non-IID settings.
read the caption
Figure 7: FENS on the AG-News dataset.

🔼 This figure compares various aggregation methods used in the FENS model, evaluating their performance based on test accuracy and client communication costs across different levels of data heterogeneity. It shows that the neural network (NN) aggregator provides the best balance between accuracy and communication efficiency. While methods like MoE (Mixture of Experts) achieve high accuracy under high heterogeneity, they are significantly more communication intensive. The figure highlights the trade-off between accuracy and communication cost for each method. The breakdown of communication costs (one-shot local training, ensemble download, and aggregator training) for each method is also visualized.
read the caption
Figure 8: Accuracy of different aggregation functions on the CIFAR-10 dataset. NN offers the best accuracy vs. communication trade-off, with its iterative training taking up only a fraction of the total cost. Numerical accuracy values are included in Table 9 (Appendix D).
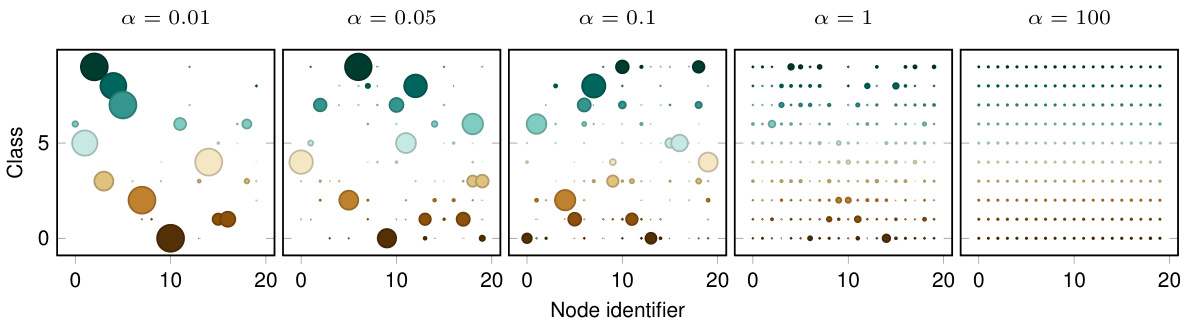
🔼 This figure shows how data heterogeneity changes with different values of alpha (α) in the CIFAR-10 dataset. Each plot represents a different alpha value, ranging from highly non-IID (α = 0.01) to IID (α = 100). The x-axis represents the node identifier, and the y-axis represents the class. The size of each dot corresponds to the number of samples of that class in that node. It visually demonstrates how data distribution across clients (nodes) becomes more uniform as alpha increases, transitioning from highly skewed distributions to more balanced ones.
read the caption
Figure 9: Visualizing the effect of changing α on the CIFAR-10 dataset. Dot size corresponds to the number of samples of a given class in a given node.
More on tables

🔼 This table presents the accuracy of the FENS model after applying knowledge distillation to reduce its size to a single model. It compares the performance of the original FENS model and the distilled version across different levels of data heterogeneity (α = 0.01, 0.05, and 0.1) on the CIFAR-10 dataset. The results show a slight decrease in accuracy after distillation, which is a common observation in knowledge distillation tasks. The table highlights the trade-off between model size and accuracy, demonstrating the potential for efficient inference after distillation.
read the caption
Table 3: Accuracy of FENS after distillation on the CIFAR-10 dataset.
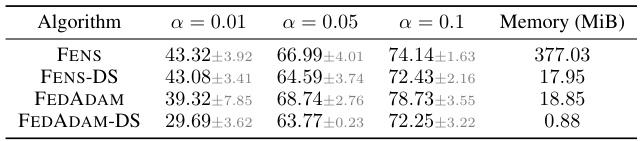
🔼 This table compares the performance of FENS and FEDADAM on the CIFAR-10 dataset under similar memory footprints. FENS and FEDADAM are both run with their original models and then with downsized (DS) models, where the model size is reduced to match that of FEDADAM. The table shows the accuracy for different levels of data heterogeneity (α = 0.01, 0.05, 0.1) and the memory used (in MiB). This comparison aims to analyze how accuracy is affected when reducing the model size while maintaining a comparable memory usage.
read the caption
Table 4: FENS vs FEDADAM under similar memory footprint on CIFAR-10. DS stands for downsized.

🔼 This table presents an overview of the datasets and tasks used in the FLamby benchmark. For each dataset (Fed-Camelyon16, Fed-Heart-Disease, and Fed-ISIC2019), it lists the input type, prediction target, task type (binary classification or multi-class classification), number of clients, number of examples per client, the model used for evaluation, and the evaluation metric (AUC or Balanced Accuracy). More details about these datasets can be found in reference [32].
read the caption
Table 5: Overview of selected datasets and tasks in FLamby. We defer additional details to [32].

🔼 This table presents the best hyperparameters found for six different federated learning algorithms (FEDAVG, FEDPROX, FEDYOGI, FEDADAM, FEDNOVA, and SCAFFOLD) on the CIFAR-10 dataset. The hyperparameters were tuned separately for three different levels of data heterogeneity (α = 0.01, 0.05, 0.1), reflecting the impact of data distribution on algorithm performance. The table details the optimal learning rates (ηl and ηs) and the proximal parameter (μ) used for each algorithm at each heterogeneity level. The results are essential for comparing the algorithms and reproducing their results.
read the caption
Table 6: Best hyperparameters obtained for the different algorithms on the CIFAR-10 dataset.

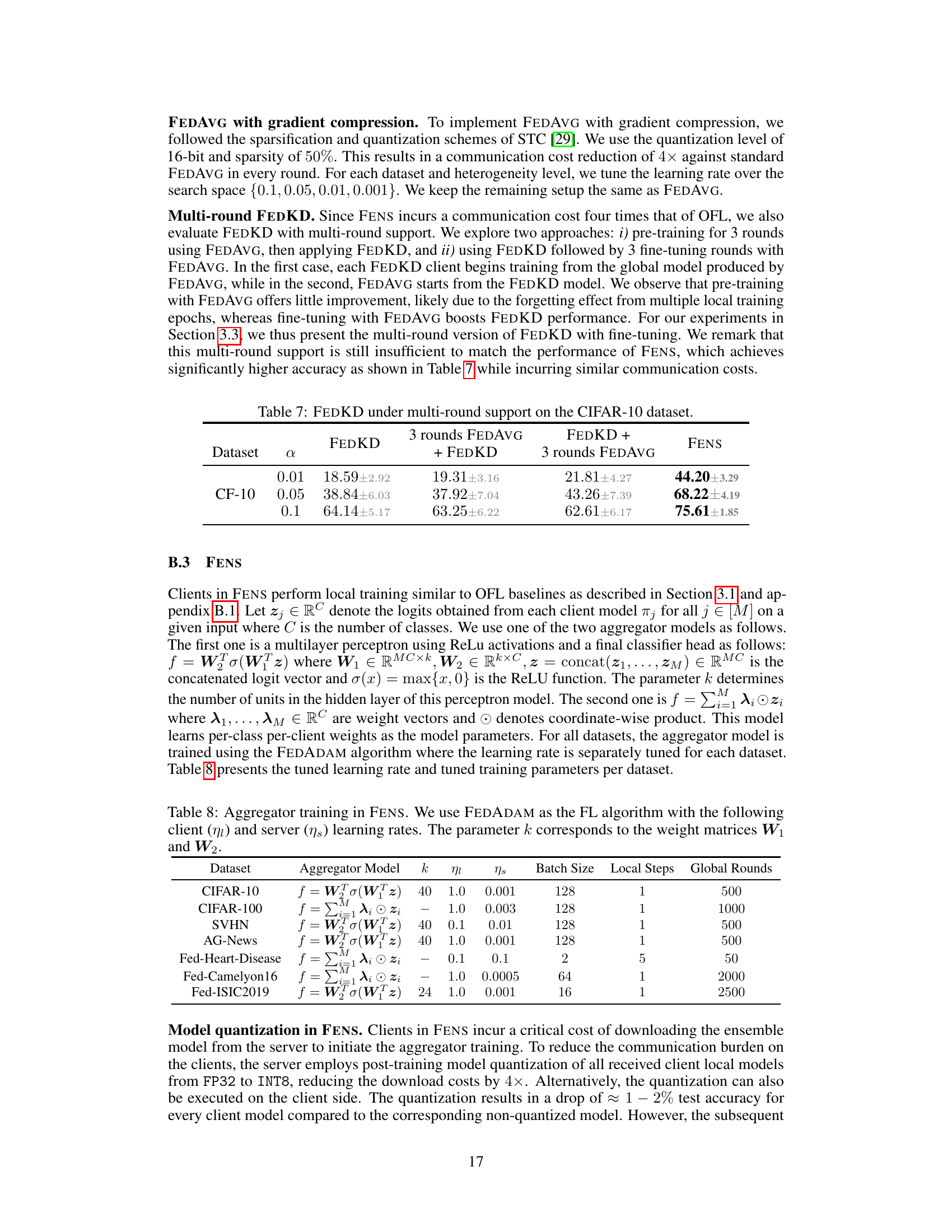
🔼 This table compares the performance of FEDKD (a one-shot federated learning method) under different settings against FENS (a novel federated ensembling scheme). It shows the test accuracy (%) on the CIFAR-10 dataset for three different levels of data heterogeneity (α = 0.01, 0.05, 0.1). The table includes results for FEDKD alone, FEDKD pre-trained with 3 rounds of FEDAVG, and FEDKD fine-tuned with 3 rounds of FEDAVG after initial training. It highlights the significant improvement achieved by FENS compared to all other versions of FEDKD under various heterogeneity conditions.
read the caption
Table 7: FEDKD under multi-round support on the CIFAR-10 dataset.
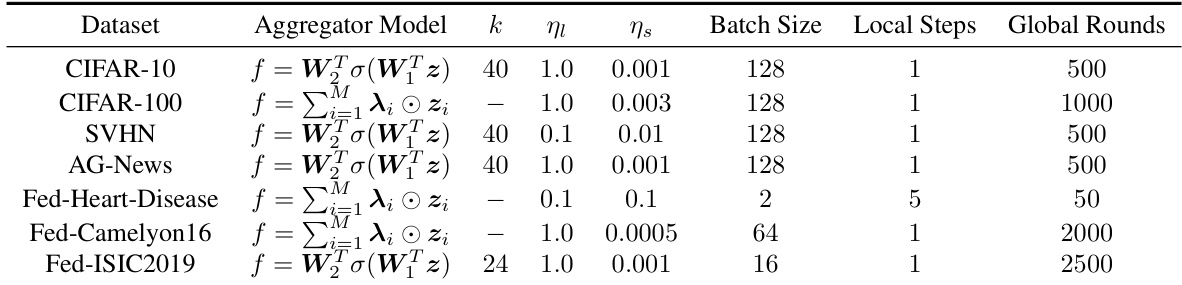
🔼 This table presents the hyperparameters used for training the aggregator model in the FENS algorithm. It specifies the aggregator model used (a multilayer perceptron or a per-client per-class weights model), the number of units in the hidden layer (k), the client and server learning rates (ηι and ηs), the batch size, the number of local steps, and the number of global rounds for each dataset used in the experiments.
read the caption
Table 8: Aggregator training in FENS. We use FEDADAM as the FL algorithm with the following client (ηι) and server (ης) learning rates. The parameter k corresponds to the weight matrices W₁ and W₂.

🔼 This table compares the performance of FENS against several one-shot federated learning baselines across different datasets and heterogeneity levels. It highlights the accuracy achieved by each method, identifying the best-performing baseline for each scenario. The final column quantifies the improvement of FENS over the best-performing baseline for each scenario, demonstrating the superior accuracy of FENS.
read the caption
Table 1: FENS vs one-shot FL for various heterogeneity levels across datasets. The highest achieved accuracy is presented as bold and the top-performing baseline is underlined. The rightmost column presents the performance difference between FENS and the top-performing baseline.
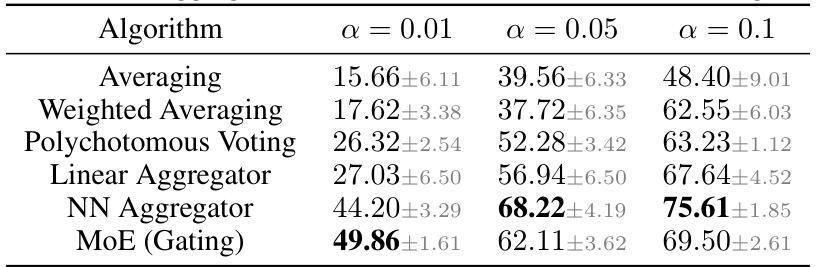
🔼 This table shows the performance of different aggregation methods used in the FENS model on the CIFAR-10 dataset with varying levels of data heterogeneity (alpha). The methods compared include simple averaging, weighted averaging, polychotomous voting, a linear aggregator, a neural network (NN) aggregator, and a Mixture-of-Experts (MoE) approach. The results demonstrate the impact of different aggregation techniques on the final accuracy of the model.
read the caption
Table 9: FENS aggregation methods on CIFAR-10. Results of Figure 8.
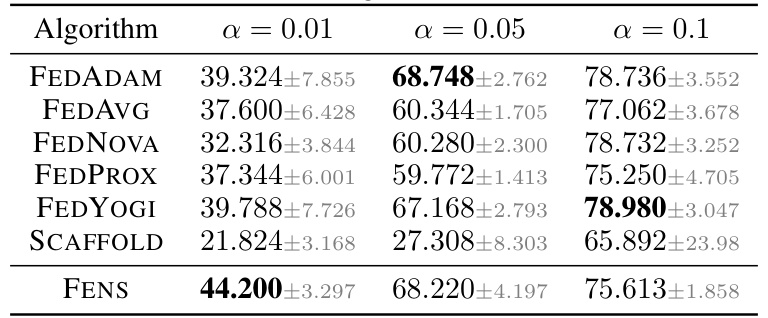
🔼 This table compares the performance of FENS against six state-of-the-art iterative Federated Learning (FL) algorithms on the CIFAR-10 dataset. The comparison is done across three different levels of data heterogeneity (α = 0.01, 0.05, 0.1). Each entry in the table shows the average test accuracy (with standard deviation) achieved by each algorithm under the corresponding heterogeneity level. This table demonstrates FENS’s ability to achieve comparable or better accuracy than existing iterative FL methods.
read the caption
Table 10: FENS vs SOTA FL algorithms on the CIFAR-10 dataset.
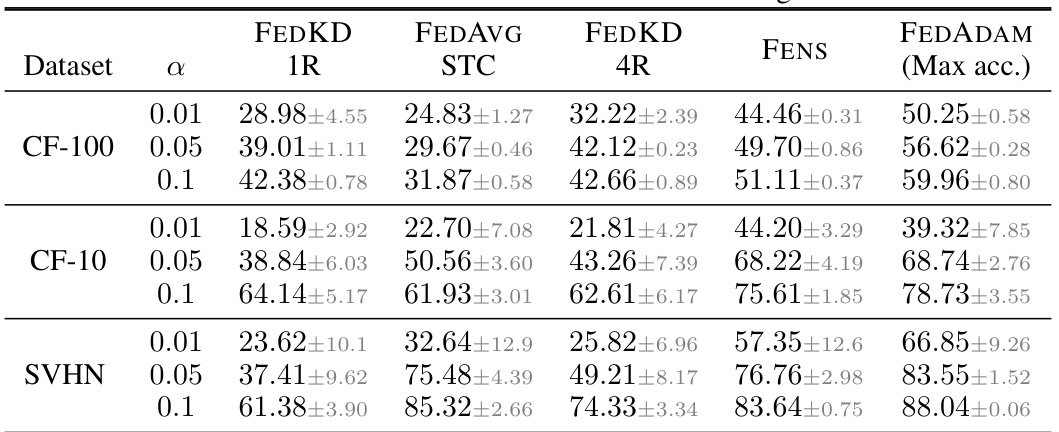
🔼 This table compares the performance of the proposed FENS model against six different one-shot federated learning (FL) baselines across three datasets (CIFAR-100, CIFAR-10, and SVHN) and three levels of data heterogeneity (α = 0.01, 0.05, 0.1). The table highlights the accuracy achieved by each method, with the best accuracy for each scenario shown in bold. The underlined baseline represents the best-performing one-shot method for each scenario. The final column indicates the performance improvement or decrease of FENS compared to that best-performing one-shot baseline.
read the caption
Table 1: FENS vs one-shot FL for various heterogeneity levels across datasets. The highest achieved accuracy is presented as bold and the top-performing baseline is underlined. The rightmost column presents the performance difference between FENS and the top-performing baseline.
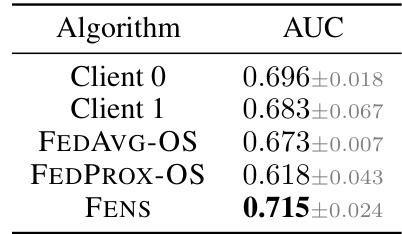
🔼 This table compares the AUC (Area Under the Curve) performance of different one-shot federated learning algorithms on the Fed-Camelyon16 dataset, a real-world dataset from the FLamby benchmark. The algorithms compared include FENS, FEDAVG-OS (one-shot FEDAVG), FEDPROX-OS (one-shot FEDPROX), and two individual clients’ local model performances. FENS significantly outperforms the other methods.
read the caption
Table 13: Figure 6 results. FENS vs. one-shot FL - Fed-Camelyon16 (row 2).

🔼 This table presents a comparison of the AUC (Area Under the Curve) achieved by FENS and several iterative Federated Learning (FL) algorithms on the Fed-Camelyon16 dataset from the FLamby benchmark. The table shows the performance for different levels of data heterogeneity (α). The results highlight FENS’s superior performance compared to other iterative FL methods.
read the caption
Table 12: Figure 6 results. FENS vs. iterative FL - Fed-Camelyon16 (row 1).

🔼 This table compares the accuracy of FENS against six iterative federated learning algorithms on the Fed-Heart-Disease dataset from the FLamby benchmark. The table shows the accuracy (with standard deviation) achieved by each algorithm, highlighting the relative performance of FENS compared to state-of-the-art iterative FL methods.
read the caption
Table 14: Figure 6 results. FENS vs. iterative FL – Fed-Heart-Disease (row 1).
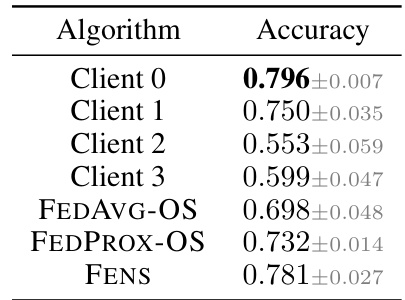
🔼 This table presents a comparison of the performance (Balanced Accuracy) of FENS against one-shot federated learning (FL) baselines (FEDAVG-OS and FEDPROX-OS) and individual client models for the Fed-Heart-Disease dataset. The results showcase FENS’s superior performance in this real-world cross-silo FLamby benchmark setting, outperforming both other one-shot methods and the individual local client models.
read the caption
Table 15: Figure 6 results. FENS vs. one-shot FL - Fed-Heart-Disease (row 2).

🔼 This table presents a comparison of the balanced accuracy achieved by different algorithms on the Fed-ISIC2019 dataset from the FLamby benchmark. It specifically shows the results for the one-shot federated learning (OFL) setting, contrasting the performance of FENS against several baselines, including FEDAVG (Federated Averaging), FEDPROX (Federated Proximal), FEDYOGI (Federated Yogi), and SCAFFOLD. The results are broken down by client, highlighting performance differences among individual clients for each method. This allows for an assessment of how different OFL approaches perform under real-world heterogeneous data conditions. The table supports the claim made in the paper that FENS remains superior in one-shot settings even when compared against more sophisticated iterative FL algorithms.
read the caption
Table 17: Figure 6 results. FENS vs. one-shot FL - Fed-ISIC2019 (row 2).
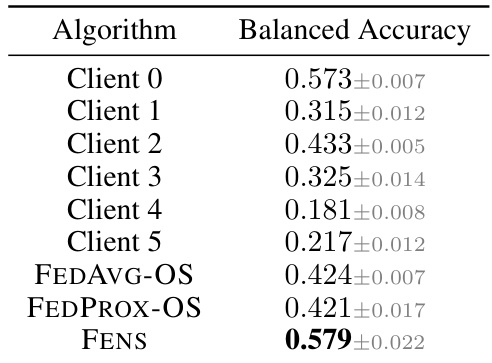
🔼 This table presents a comparison of the balanced accuracy achieved by different algorithms on the Fed-ISIC2019 dataset from the FLamby benchmark. It specifically focuses on one-shot federated learning (OFL) methods. The algorithms compared include client-level local models (Client 0 through Client 5), FEDAVG-OS, FEDPROX-OS, and the proposed FENS algorithm. The results highlight the superior performance of FENS compared to the other one-shot methods, indicating its effectiveness in real-world heterogeneous settings.
read the caption
Table 17: Figure 6 results. FENS vs. one-shot FL - Fed-ISIC2019 (row 2).
Full paper#