TL;DR#
Current large reconstruction models struggle to create accurate 3D models from single images due to the inherent ambiguity of depth information. These models often suffer from geometric distortions, especially in unseen areas. Existing multi-view methods also have issues; generated multi-view images often lack consistency.
To address this, the authors propose LAM3D, a novel framework that incorporates 3D point cloud data. This approach uses a point-cloud-based network to generate precise latent tri-planes, which are then aligned with single-image features. This alignment process enhances image features with robust 3D information, resulting in highly-accurate and visually pleasing 3D meshes. LAM3D’s key contribution is the effective use of point cloud priors for single-image feature alignment; the model achieves state-of-the-art results, surpassing previous methods in terms of accuracy and efficiency.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to 3D reconstruction from a single image using point cloud data to significantly improve the accuracy and fidelity of generated 3D meshes. This addresses a major challenge in the field, where single-image-based methods often produce inaccurate results due to the ambiguity inherent in interpreting 3D shape from a single 2D view. The proposed LAM3D model achieves state-of-the-art results and offers a promising direction for future research in high-fidelity 3D reconstruction from limited input.
Visual Insights#

🔼 This figure shows a comparison of single-image 3D reconstruction results from different methods. The reference image is a wooden box. (a) shows the results of ULIP, (b) LRM, (c) CRM, and (d) the authors’ method, LAM3D. The figure highlights the superior quality and accuracy of the LAM3D reconstruction compared to other state-of-the-art methods.
read the caption
Figure 1: An example of single-image reconstruction from state-of-the-art methods: (a) ULIP [63], (b) LRM [13], (c) CRM [54], and (d) Ours (LAM3D).

🔼 This table presents a quantitative comparison of the geometry quality between the proposed LAM3D model and several state-of-the-art baselines. The comparison is based on three metrics: Chamfer Distance (CD), Volume Intersection over Union (IoU), and F-Score. Lower CD values indicate better geometry alignment, while higher IoU and F-Score values suggest improved reconstruction quality. The results demonstrate that LAM3D achieves superior performance compared to the baselines across all three metrics, showcasing its effectiveness in generating high-fidelity 3D meshes from single images.
read the caption
Table 1: Quantitative comparisons for the geometry quality between our method and baselines.
In-depth insights#
LAM3D Framework#
The LAM3D framework presents a novel approach to single-image 3D reconstruction by leveraging point cloud data to improve the accuracy and fidelity of generated 3D meshes. It departs from traditional methods that struggle with geometric inaccuracies inherent in single-view reconstruction by introducing a two-stage process. Stage one compresses point cloud data into efficient latent tri-planes using a point-cloud based network, establishing a strong 3D prior. Stage two cleverly aligns single-image features, extracted using a DINO feature extractor, to these latent tri-planes via a diffusion process. This alignment step is crucial, imbuing the image features with robust 3D context and mitigating the ambiguity inherent in single-view data. The resulting high-fidelity 3D mesh is generated using an effective reconstruction module. The framework’s key innovation lies in its effective fusion of 2D and 3D information, significantly reducing geometric distortion and enhancing reconstruction quality. The use of tri-planes for feature representation and diffusion alignment contributes to computational efficiency, producing high-quality results in just 6 seconds. Overall, LAM3D demonstrates a significant advancement in single-image 3D reconstruction by addressing existing challenges with a robust and efficient framework.
Tri-plane Alignment#
Tri-plane alignment, in the context of 3D reconstruction from a single image, is a crucial technique for effectively integrating 2D image features with 3D point cloud information. The core idea is to project image features onto a 3D representation, specifically a tri-plane structure, which allows for the fusion of 2D and 3D data. This approach addresses the inherent ambiguity in single-view 3D reconstruction, where a single image lacks sufficient information to uniquely define the 3D geometry. By aligning image features to the structured tri-planes derived from a point cloud, the method leverages the rich 3D context provided by the point cloud to improve accuracy and detail in the final 3D reconstruction. Effective alignment is key; it necessitates a robust mechanism for transferring image feature information to each tri-plane, accurately reflecting the 3D spatial relationships. The use of a diffusion model, for instance, allows for a probabilistic approach to the alignment process, which is beneficial because it handles ambiguities and unseen parts of the object more gracefully than deterministic methods. Ultimately, successful tri-plane alignment enables the generation of high-fidelity 3D meshes with fewer geometric distortions and more accurate detail, significantly enhancing the realism and quality of single-image 3D reconstruction.
Diffusion Model#
Diffusion models, a class of generative models, are explored in the context of 3D shape generation. They work by gradually adding noise to data until it becomes pure noise, then learning to reverse this process to generate new samples. This approach offers several advantages such as high-quality sample generation and the capacity to model complex distributions. However, the paper doesn’t explicitly detail the specific architecture or training method used for the diffusion model, leaving room for further exploration of the architectural choices and optimization techniques. The use of a diffusion model for image-to-point cloud alignment is particularly intriguing because of its probabilistic nature, which may provide a more robust approach than deterministic methods for addressing the inherent ambiguities in single-image 3D reconstruction. Further examination of the hyperparameters and training techniques employed in the diffusion model is needed to fully assess its role in the success of the alignment model.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a machine learning model. In the context of a 3D reconstruction paper, an ablation study might involve removing or altering different parts of the model (e.g., specific modules, loss functions, or data augmentation techniques) and observing the impact on the final 3D mesh quality. Key aspects examined often include the effect of different feature representations (e.g., vectors vs. tri-planes), the impact of various loss functions (e.g., geometric losses and latent regularizations), and the influence of different model architectures or design choices. By comparing the model’s performance with and without these components, researchers gain valuable insights into the individual contributions of each part, leading to a better understanding of the model’s strengths and weaknesses and informing future improvements. The results from such a study often are presented quantitatively (e.g., using metrics like Chamfer Distance) and qualitatively (e.g., through visual comparisons of generated meshes). A well-designed ablation study is crucial for establishing the necessity and effectiveness of each component in achieving high-fidelity 3D reconstruction.
Future Work#
The authors mention the absence of texture reconstruction in their current model as a key limitation, highlighting this as a critical area for future development. Improving texture generation and integrating it seamlessly into their framework would significantly enhance the realism and visual quality of the reconstructed 3D meshes. Beyond texture, exploring more complex geometries and scenes represents another promising direction. Currently, their model struggles with unseen areas and intricate details, which suggests that improving the model’s ability to handle occlusions and unseen parts through more sophisticated depth estimation techniques and/or data augmentation strategies could prove beneficial. Expanding the dataset to include a wider range of objects, viewpoints, and lighting conditions would improve model generalization and robustness. Furthermore, exploring alternative 3D representations beyond tri-planes, such as implicit surfaces or point clouds, may offer advantages in terms of efficiency or accuracy. Finally, it would be important to investigate the computational efficiency of the approach and potential hardware optimizations, making their method more accessible for broader adoption and real-time applications.
More visual insights#
More on figures

🔼 This figure illustrates the two-stage training process of the LAM3D model. Stage 1 compresses point cloud data into a latent tri-plane representation using a point cloud-based network. Stage 2 aligns single-view image features to this latent representation using a diffusion-based approach. Finally, the inference stage reconstructs a 3D mesh from a single image by utilizing the aligned tri-plane features and a decoder.
read the caption
Figure 2: Overview of our method. Our method contains two training stage. Stage 1: we train an encoder-decoder structure to take point clouds as input and compress it to a latent tri-plane representation; Stage 2: we employ diffusion to align image modality to latent tri-planes obtained in stage 1. The diffusion step takes an initial noise and an image feature from a freezed DINO feature encoder and progressively align the image feature to the latent tri-plane. Inference: To reconstruct a 3D mesh from a single-view image, we use the alignment step, following the decoder (Plane Decoder, Plane Refiner) from the compression step, to predict a tri-plane. Then, we can use algorithms like marching cubes to extract 3D meshes from the reconstructed tri-plane.

🔼 This figure displays 3D model reconstructions of various objects generated from single input images using four different methods: One-2-3-45, LRM, CRM, and the authors’ proposed LAM3D model. The top row shows the input image for each object, followed by the 3D reconstructions from each method. The figure highlights the differences in reconstruction quality and detail between the methods, demonstrating the superior performance of LAM3D in generating high-fidelity 3D models from single images. The objects are drawn from the Objaverse and Google Scanned Objects datasets.
read the caption
Figure 3: Rendered images of shapes reconstructed by various methods from single images. The upper samples are from Objaverse and the lowers are from Google Scanned Objects.

🔼 This figure compares the 3D reconstruction results using different latent representations. (a) shows the reference model. (b) and (c) show results using latent vectors of dimensions 512 and 6114, respectively. (d) illustrates a model trained without the latent SDF loss (Llsdf), and (e) presents the results obtained with the full model, incorporating all components. The comparison highlights the impact of latent representation dimensionality and the importance of the latent SDF loss for achieving high-fidelity 3D mesh reconstruction.
read the caption
Figure 4: Qualitative comparisons of different latent representations.
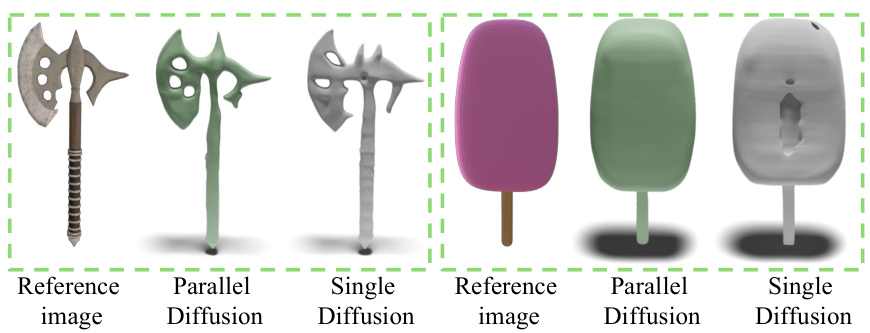
🔼 This figure shows the results of 3D reconstruction using parallel and single UNets. The left part shows three axes reconstructed using parallel UNets (green) and a single UNet (gray). The right part shows a popsicle reconstructed using parallel UNets (green) and single UNet (gray). The images clearly show that parallel UNets produce better results in terms of detail and completeness.
read the caption
Figure 5: Green objects are generated from parallel UNets and gray samples are from single UNet.
🔼 This figure shows the overall architecture of the proposed LAM3D model, which consists of two main stages: point cloud compression and image-point cloud alignment. The point cloud compression stage uses an encoder-decoder structure to compress the point cloud into a latent tri-plane representation. The image-point cloud alignment stage uses diffusion to align image features to the latent tri-planes. Finally, a decoder is used to generate a 3D mesh from the aligned tri-plane representation.
read the caption
Figure 2: Overview of our method. Our method contains two training stage. Stage 1: we train an encoder-decoder structure to take point clouds as input and compress it to a latent tri-plane representation; Stage 2: we employ diffusion to align image modality to latent tri-planes obtained in stage 1. The diffusion step takes an initial noise and an image feature from a freezed DINO feature encoder and progressively align the image feature to the latent tri-plane. Inference: To reconstruct a 3D mesh from a single-view image, we use the alignment step, following the decoder (Plane Decoder, Plane Refiner) from the compression step, to predict a tri-plane. Then, we can use algorithms like marching cubes to extract 3D meshes from the reconstructed tri-plane.

🔼 This figure shows the results of an ablation study comparing deterministic and probabilistic approaches to single-view 3D reconstruction. The top row displays examples of character models, and the bottom row shows examples of various objects. For each model type, there are three columns: the first presents the reference image, the second shows the reconstruction using the probabilistic method (our model), and the third shows the reconstruction using the deterministic method. This comparison highlights the improved quality and detail achieved using the probabilistic approach.
read the caption
Figure 7: Alignment approach ablation study. We evaluate the single view reconstruction capability of deterministic vs. probabilistic approaches. Green objects are constructed from our probabilistic approach and gray samples are from a deterministic approach. We also present the reference image.

🔼 This figure shows the results of single-view 3D reconstruction experiments comparing the model with and without the plane refiner module. The leftmost image shows a reference image of an axe. The middle image shows a 3D reconstruction of the axe generated by the model with the plane refiner, resulting in a more detailed and accurate model. The rightmost image shows the 3D reconstruction generated by the model without the plane refiner module, showing some loss of detail. The quantitative comparison (Chamfer Distance) in the table above the images further supports the qualitative observation that the plane refiner improves model accuracy.
read the caption
Figure 8: We evaluate the single view reconstruction capability of our model w/ and w/o the plane refiner. Green objects are constructed from our model with the plane refiner and gray samples are from a the model without the plane refiner. We also present the reference image.

🔼 This figure shows a comparison of 3D object reconstruction results from single images using different methods: One-2-3-45, LRM, CRM, and the authors’ proposed method, LAM3D. The top row displays results from the Objaverse dataset, while the bottom row uses the Google Scanned Objects dataset. Each column represents a different object, with the original reference image shown on the left and the reconstructed 3D model on the right. The comparison highlights the visual quality and geometric accuracy of the reconstructions achieved by each method.
read the caption
Figure 3: Rendered images of shapes reconstructed by various methods from single images. The upper samples are from Objaverse and the lowers are from Google Scanned Objects.

🔼 This figure shows a comparison between the reference images and the 3D models reconstructed by the LAM3D model from single images. It visually demonstrates the model’s ability to reconstruct a variety of objects from single images, showcasing the accuracy and detail of the generated 3D models.
read the caption
Figure 10: Rendered images of shapes reconstructed by our LAM3D from single images on the Objaverse dataset. For each tuple of samples, the left image is the reference image and the right image is the reconstructed geometry.
More on tables

🔼 This table presents a comparison of the Chamfer Distance (CD) achieved by different latent space representations for 3D reconstruction. It shows that using a latent tri-plane representation with a latent SDF loss significantly improves the reconstruction quality compared to using a simple vector or a tri-plane without the SDF loss. The results highlight the importance of using a 3D-aware latent representation in achieving high-fidelity 3D reconstruction.
read the caption
Table 2: Comparisons of different representations.

🔼 This table presents a quantitative comparison of the Chamfer Distance (CD) metric between two different approaches for image-point-cloud alignment: using a single diffusion U-Net and using three parallel diffusion U-Nets. The results show a lower CD, indicating better reconstruction quality, when using the three parallel U-Nets.
read the caption
Table 3: Quantitative comparison between parallel diffusion UNet and single UNet.
Full paper#



















