TL;DR#
Accurately reconstructing 3D human interactions, especially in close-proximity scenarios, is challenging due to issues like occlusion and limited datasets. Existing methods often struggle with these complexities, either reconstructing individuals separately or merging nearby surfaces, leading to inaccurate geometry representation of the interactions. This paper focuses on solving these issues.
The researchers introduce a novel implicit field representation that simultaneously models occupancy, individual identities (IDs), and contact fields. This is achieved through a multi-view local-global feature module that effectively aggregates local and global information. A new synthetic dataset is introduced to improve model robustness. Experimental results demonstrate that this method outperforms conventional multi-view techniques, particularly in handling complex interactions and occlusions, and enables unsupervised contact point estimation.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to a challenging problem in 3D human reconstruction: accurately modeling multi-person interactions in close proximity. The method’s superior performance over existing techniques, especially in handling occlusions and complex scenarios, makes it highly relevant to researchers working in virtual reality, augmented reality, and human-computer interaction. Furthermore, the introduction of a new synthetic dataset enhances the robustness and generalizability of future research in this area, opening up new avenues for investigation.
Visual Insights#
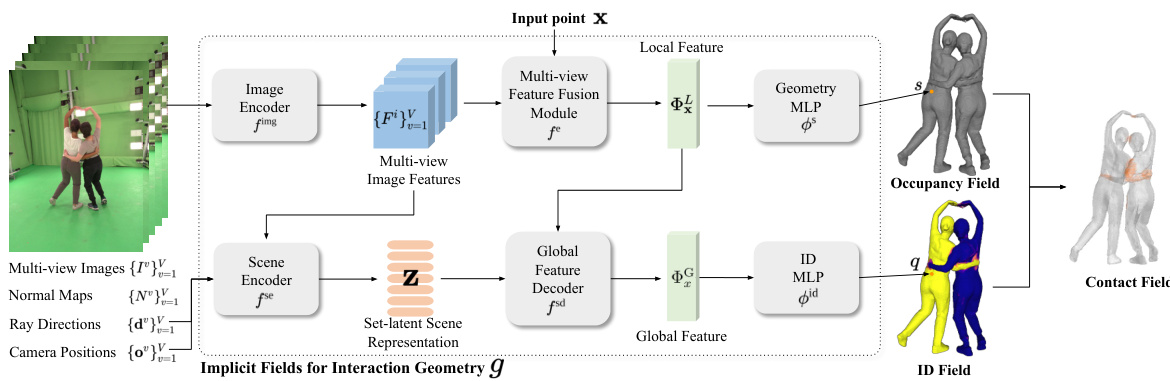
🔼 This figure illustrates the overall framework of the proposed method for multi-person interaction geometry. It shows how local and global features are extracted from multi-view images and camera parameters using a multi-view feature local-global transformer. These features are then used to estimate the occupancy field (representing the geometry of each person), the ID field (identifying each individual), and finally, the contact field (indicating contact points between individuals). The process is detailed further in Section 3.4 of the paper.
read the caption
Figure 1: The overall framework of our method. We compute the local and global features from a set of multi-view images and its camera parameters through the proposed multi-view feature local-global transformer. We use local feature to estimate occupancy and global feature to estimate ID at a given point x. From the occupancy and ID fields, we estimate the contact field, as detailed in Section 3.4
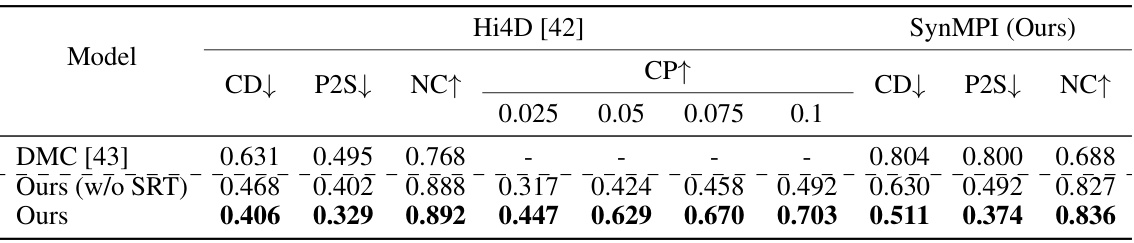
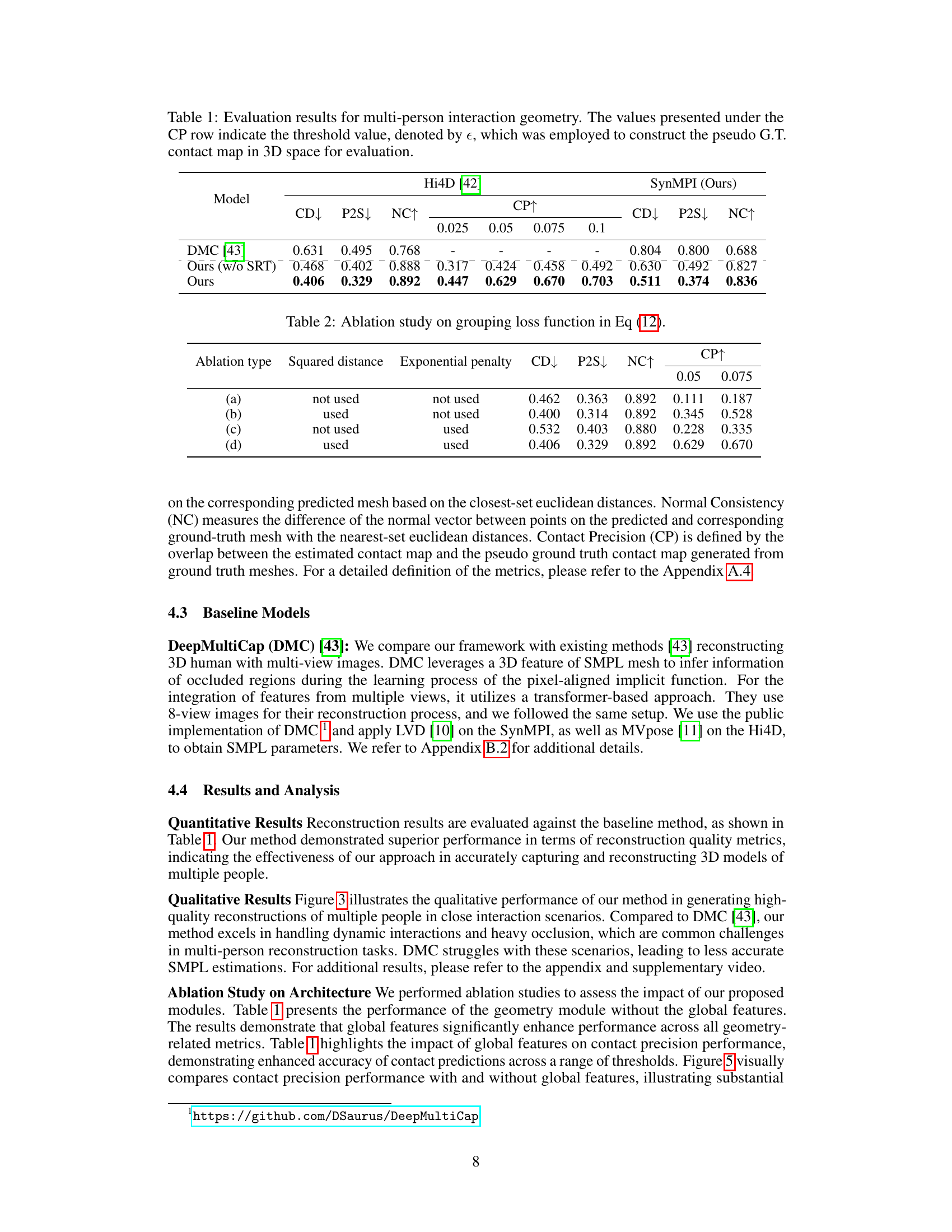
🔼 This table presents quantitative results comparing the proposed method’s performance against the DeepMultiCap (DMC) baseline on two datasets: Hi4D and SynMPI. The metrics used are Chamfer Distance (CD), Point-to-Surface distance (P2S), Normal Consistency (NC), and Contact Precision (CP) at various thresholds (CP). Lower values for CD and P2S indicate better geometric reconstruction accuracy. Higher NC indicates better normal consistency. Higher CP indicates better contact prediction accuracy. The table shows that the proposed method (‘Ours’) outperforms the baseline (DMC) across all metrics on both datasets.
read the caption
Table 1: Evaluation results for multi-person interaction geometry. The values presented under the CP row indicate the threshold value, denoted by e, which was employed to construct the pseudo G.T. contact map in 3D space for evaluation.
In-depth insights#
Implicit Field 3D#
Implicit field representations offer a powerful paradigm for 3D modeling, particularly when dealing with complex shapes or incomplete data. The core idea is to represent a 3D object not by explicitly defining its surface geometry (like meshes or point clouds), but by an implicit function that determines whether a point in 3D space is inside or outside the object. This implicit function, often learned from data, can be evaluated at any point, allowing for flexible and detailed reconstructions. Key advantages include the ability to handle complex topologies, partial observations, and varying levels of detail. One can imagine this implicit function as a field; values above a certain threshold would correspond to the object’s volume. The method is particularly suitable for representing human figures, where the highly articulated and deformable nature makes mesh-based approaches challenging. Moreover, the implicit field approach lends itself well to tasks involving interaction, occlusion, and pose estimation because it elegantly handles the fuzzy boundaries between interacting bodies, avoiding the complex segmentation and mesh merging issues that plague explicit methods. The use of deep learning techniques to learn these implicit fields is a major enabler, allowing for high-fidelity reconstructions from relatively sparse data, like multi-view images. However, the effectiveness relies heavily on the quality and quantity of training data, and the computational cost of evaluating the implicit function can be substantial.
Multi-view Fusion#
Multi-view fusion, in the context of 3D reconstruction, is a crucial technique for overcoming the limitations of single-view approaches. By combining information from multiple viewpoints, it significantly enhances the accuracy and completeness of the 3D model, particularly in challenging scenarios with occlusions or limited visibility. A successful multi-view fusion strategy must address several key challenges: effectively registering images from different viewpoints, handling varying lighting conditions, and robustly integrating potentially conflicting information. Various approaches exist, ranging from simple averaging to sophisticated deep learning methods that leverage neural networks. The selection of the optimal fusion method depends heavily on the specific application and the characteristics of the input data. For example, techniques like point cloud registration and merging, or volumetric fusion methods (like implicit functions), each offer different trade-offs in terms of computational cost, accuracy, and robustness to noise. A key consideration is the representation used for fusing the data, whether it be images directly, intermediate feature maps, or 3D point clouds. Effective multi-view fusion is paramount for generating high-quality 3D models, especially in applications that demand a high degree of accuracy and detail.
Interaction Geom#
The concept of ‘Interaction Geom’ in a research paper likely refers to a novel approach for representing and analyzing the geometric relationships between interacting agents within a scene. This likely involves handling complex scenarios where multiple agents are in close proximity, exhibiting various degrees of occlusion and contact. The core challenge addressed might focus on accurately reconstructing the shape and pose of each agent while capturing the intricate geometry of their interactions. This likely goes beyond simply identifying individual agents; it aims to represent the way their bodies interact—touching, overlapping, or maintaining distance—as part of a unified geometric model. A system tackling ‘Interaction Geom’ might leverage techniques like implicit field representations, which are effective at handling complex shapes and occlusions, potentially combined with sophisticated multi-view fusion strategies. The final goal likely involves applications demanding accurate understanding of interaction geometry, such as virtual reality simulations, robotics, or human behavior analysis. Successful ‘Interaction Geom’ research will demonstrate superior performance compared to existing methods, particularly in scenarios featuring close physical contact and high levels of occlusion, improving the accuracy of human body pose estimation and interaction detection.
SynMPI Dataset#
The creation of the SynMPI dataset represents a significant contribution to the field of multi-person interaction research. Addressing limitations in existing datasets, SynMPI offers a comprehensive and diverse collection of multi-person interaction scenarios, featuring 2 to 4 individuals with varying ages, body types, clothing, and activities. This enhanced diversity makes it superior for training robust models capable of handling complex real-world interactions, including those involving occlusions or close physical contact. The availability of both multi-view RGB images and corresponding 3D mesh data is particularly valuable for accurate evaluation and training of 3D reconstruction models. Furthermore, the dataset’s well-defined structure and inclusion of specific interactions allows researchers to easily investigate and analyze various types of multi-person activity and interactions, leading to a deeper understanding of human behavior and interaction dynamics. The synthetic nature of SynMPI, however, presents a trade-off: while it allows for controlled and varied data generation, it may not fully capture the intricate details and variability of real-world interactions.
Future of 3D#
The “Future of 3D” is brimming with potential, driven by advancements in hardware and software. More powerful GPUs and specialized chips will enable real-time rendering of incredibly detailed 3D models, blurring the line between virtual and physical reality. Software advancements, including AI-powered tools for automated 3D model creation and manipulation, will make 3D content creation more accessible to a wider audience. We can expect to see a rise in immersive applications, such as augmented and virtual reality experiences, that leverage photorealistic 3D environments for gaming, training, and design. The integration of haptic feedback will further enhance the realism and interactivity of these experiences. However, the field will also face challenges. Data acquisition remains a significant hurdle, particularly for complex real-world scenarios. Computational costs can be substantial for high-fidelity 3D rendering, limiting accessibility. Addressing ethical considerations surrounding data privacy and potential misuse of realistic 3D models will also be crucial for responsible development. The future of 3D is dynamic, promising a future where the digital and physical worlds seamlessly interact, yet demanding careful consideration of the technological and social implications.
More visual insights#
More on figures

🔼 This figure shows examples of multi-person interactions from the SynMPI dataset, a synthetic dataset created for this research. It showcases various scenarios with 2, 3, and 4 individuals interacting in different poses and configurations. Each example is shown as both RGB images and 3D meshes, illustrating the capability of the method to handle complex interaction geometries.
read the caption
Figure 2: Examples of multi-person interaction geometry in the SynMPI dataset. Each sample contains interactions involving (a) 2, (b) 3, or (c) 4 people. In each sample, the left side shows rendered RGB images and the right side shows rendered meshes. Italic sentences explain the multi-people interaction types of samples adopted from Character Creator 4 [31].

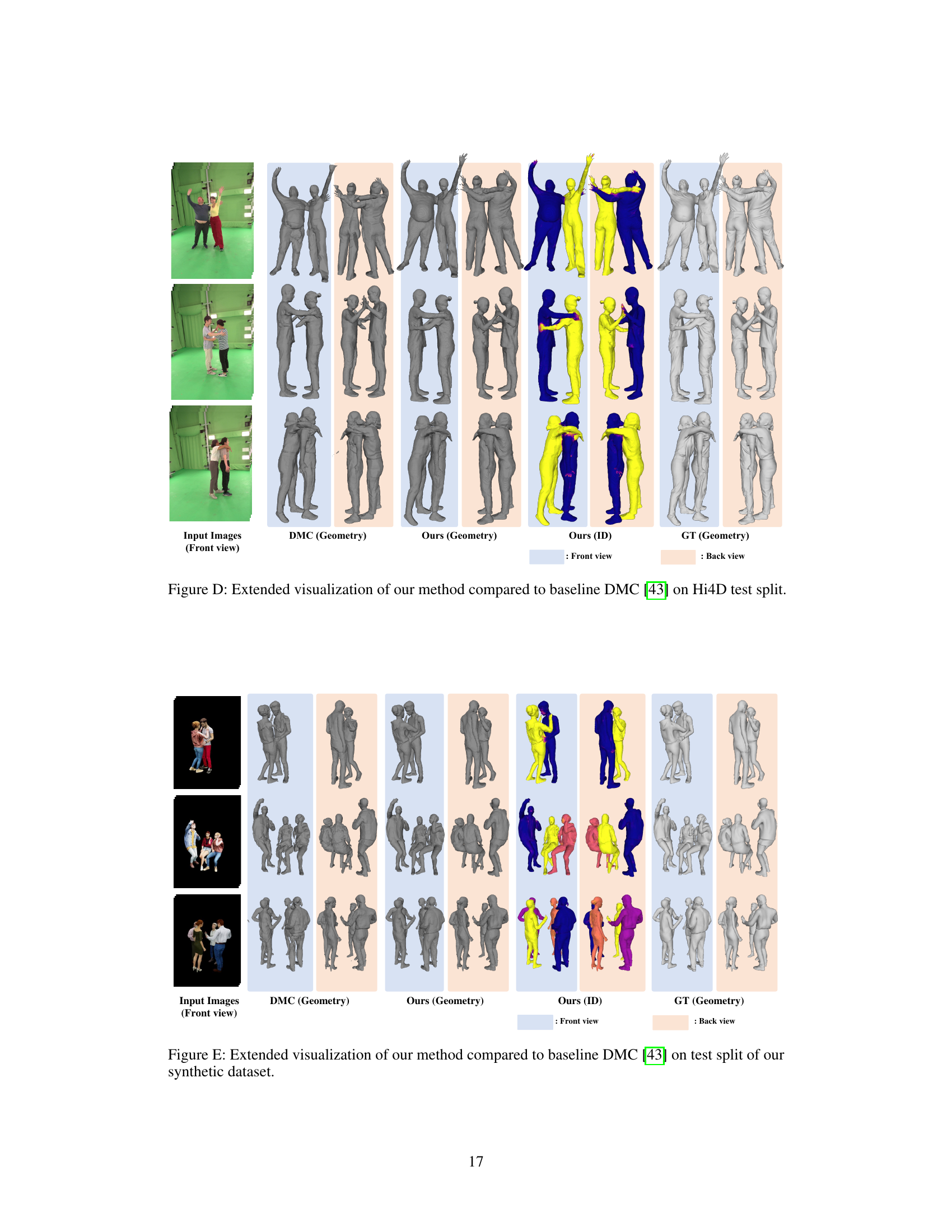
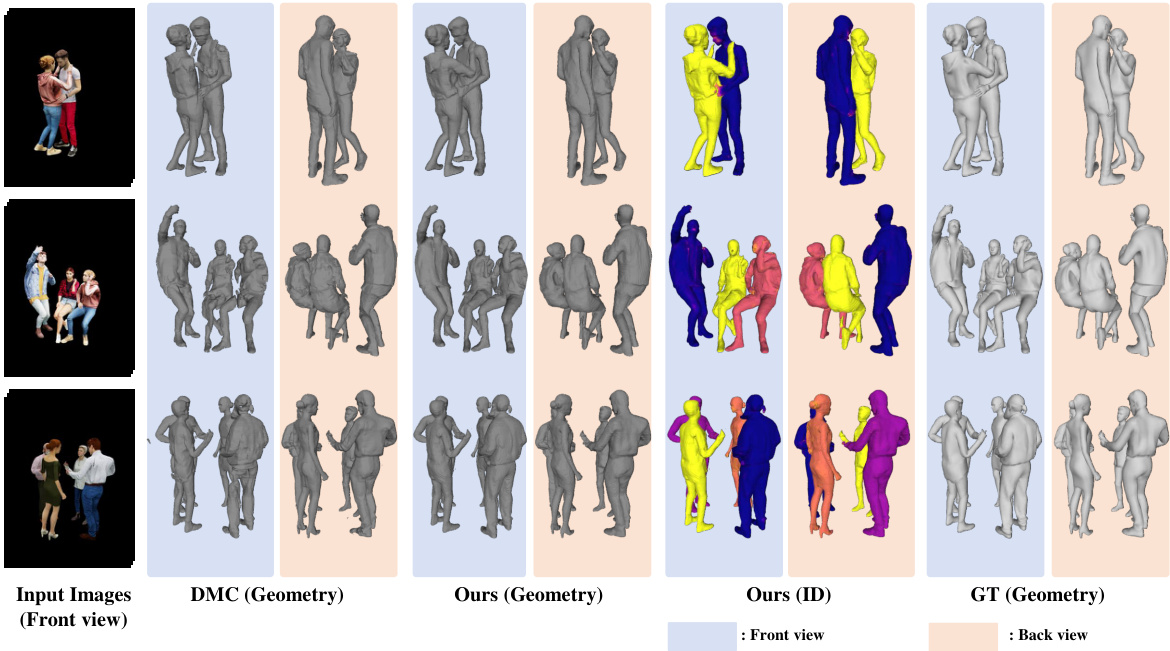
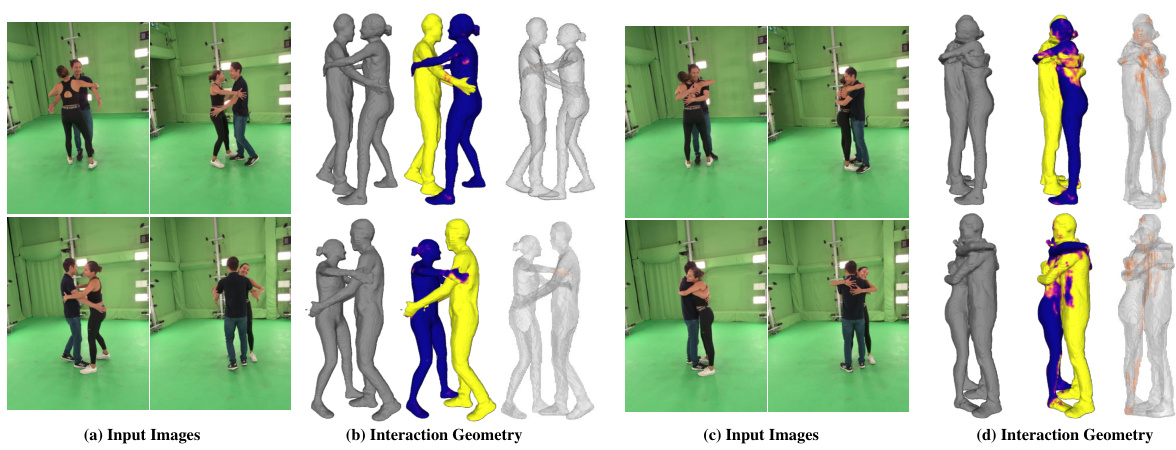
🔼 This figure compares the performance of the proposed method against the DeepMultiCap (DMC) method on two datasets: Hi4D and SynMPI. For each dataset, it shows example multi-view images as input, along with the 3D geometry reconstruction results produced by both methods (DMC and the proposed method), and finally, the ground truth geometry for comparison. This visual comparison highlights the differences in accuracy and ability to handle occlusions and complex interactions between the two methods.
read the caption
Figure 3: We compare our method to baseline DMC [43] on Hi4D (top) and SynMPI (bottom) test set. From left to right columns, we show the input multi-view images, the generated geometry by each method, and ground truth (GT) Geometry.
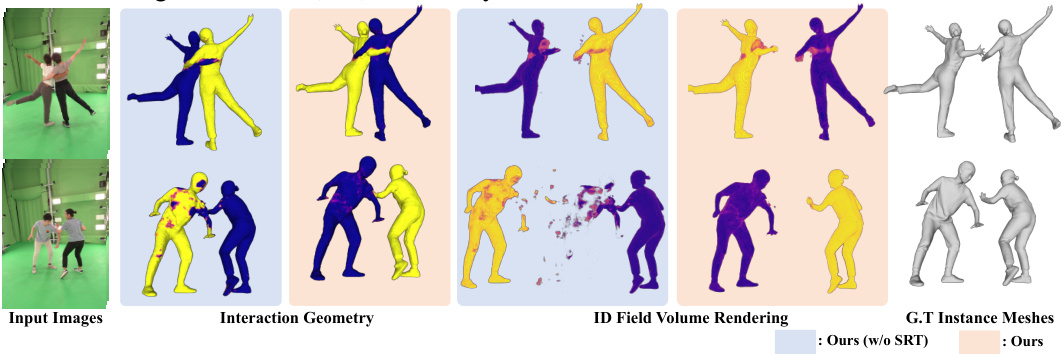
🔼 This figure compares the performance of the proposed method against the DeepMultiCap (DMC) method on two datasets: Hi4D and SynMPI. For each dataset, multiple examples are shown. Each row represents a different interaction scenario. The columns display the input multi-view images, the 3D geometry reconstructed by DMC, the 3D geometry generated by the proposed method, the per-person ID’s generated by the proposed method and finally, the ground truth 3D geometry for comparison. This visual comparison allows assessment of the accuracy and completeness of each method’s reconstruction in handling complex interactions and occlusions.
read the caption
Figure 3: We compare our method to baseline DMC [43] on Hi4D (top) and SynMPI (bottom) test set. From left to right columns, we show the input multi-view images, the generated geometry by each method, and ground truth (GT) Geometry.
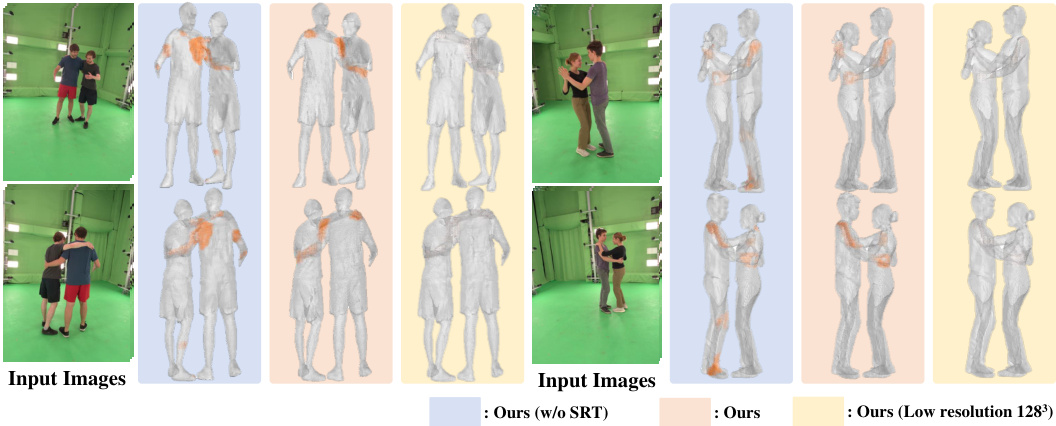
🔼 This figure demonstrates the impact of global features and 3D resolution on the accuracy of contact field estimation. The leftmost column shows the input images. The next three columns show the results of the proposed method: the geometry, ID fields, and contact fields. The rightmost column displays the ground truth geometry. By comparing the different conditions (with/without global features, high/low resolution), the figure illustrates the significant improvement in accuracy achieved by incorporating global features and using a higher resolution.
read the caption
Figure 5: Comparison of the effect of global features and 3D resolution on estimated contact fields. Ours (w/o global) excludes global features, Ours (low resolution 1283) uses low resolution.
🔼 This figure compares the 3D reconstruction results of the proposed method and the baseline method (DMC [43]) on two datasets: Hi4D and SynMPI. For each dataset, several examples are shown, each consisting of four columns. The first column shows the input multi-view images used for reconstruction. The second column shows the geometry generated by the DMC [43] method. The third column shows the geometry produced by the proposed method. The fourth column displays the ground truth geometry for comparison. This visual comparison highlights the superior performance of the proposed method in accurately reconstructing multi-person interaction geometry, particularly in challenging scenarios with occlusion.
read the caption
Figure 3: We compare our method to baseline DMC [43] on Hi4D (top) and SynMPI (bottom) test set. From left to right columns, we show the input multi-view images, the generated geometry by each method, and ground truth (GT) Geometry.

🔼 This figure compares the 3D reconstruction results of the proposed method and the baseline method (DMC [43]) on two datasets: Hi4D and SynMPI. For each dataset, several examples are shown. Each row represents a different scene. The columns show the input multi-view images, the reconstruction results using the proposed method, the reconstruction results using DMC [43], and finally the ground truth geometry. The figure visually demonstrates the superior performance of the proposed method in accurately reconstructing the 3D geometry, particularly in handling complex interactions and occlusions.
read the caption
Figure 3: We compare our method to baseline DMC [43] on Hi4D (top) and SynMPI (bottom) test set. From left to right columns, we show the input multi-view images, the generated geometry by each method, and ground truth (GT) Geometry.

🔼 This figure compares the results of the proposed method and the baseline method (DMC) on two datasets (Hi4D and SynMPI). It visually demonstrates the performance of each method in reconstructing multi-person interaction geometry from multiple views. The columns show the input images, the 3D geometry generated by DMC, the 3D geometry generated by the proposed method, the ID field rendering of the proposed method, and the ground truth geometry. The figure highlights the superior performance of the proposed method, particularly in handling complex interactions and occlusions.
read the caption
Figure 3: We compare our method to baseline DMC [43] on Hi4D (top) and SynMPI (bottom) test set. From left to right columns, we show the input multi-view images, the generated geometry by each method, and ground truth (GT) Geometry.

🔼 This figure compares the performance of the proposed method against the DeepMultiCap (DMC) method on two datasets: Hi4D and SynMPI. For each dataset, several example scenes are shown. Each row displays the input multi-view images, the geometry generated by DMC, the geometry and ID generated by the proposed method, and finally the ground truth geometry. The figure visually demonstrates the superior performance of the proposed method in accurately reconstructing multi-person interactions, particularly in challenging scenarios with occlusions.
read the caption
Figure 3: We compare our method to baseline DMC [43] on Hi4D (top) and SynMPI (bottom) test set. From left to right columns, we show the input multi-view images, the generated geometry by each method, and ground truth (GT) Geometry.
🔼 This figure compares the 3D reconstruction results of the proposed method against the DeepMultiCap (DMC) method on two datasets: Hi4D and SynMPI. Each row represents a different scene. For each scene, the figure shows the input multi-view images followed by the 3D reconstruction results of DMC, the proposed method (showing both geometry and individual IDs), and the ground truth geometry. The comparison highlights the superior performance of the proposed method in handling occlusions and generating more accurate 3D models, especially in complex multi-person interaction scenarios.
read the caption
Figure 3: We compare our method to baseline DMC [43] on Hi4D (top) and SynMPI (bottom) test set. From left to right columns, we show the input multi-view images, the generated geometry by each method, and ground truth (GT) Geometry.
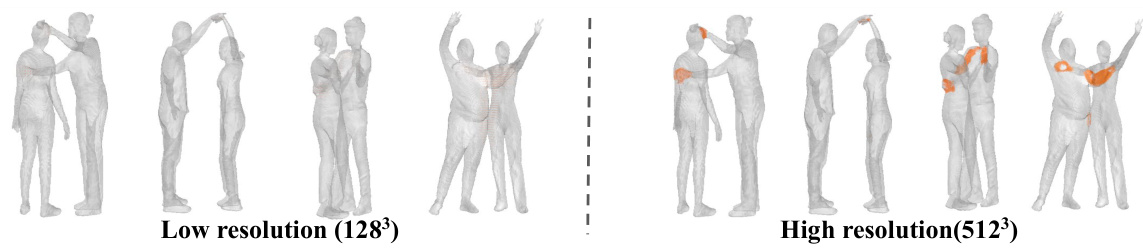
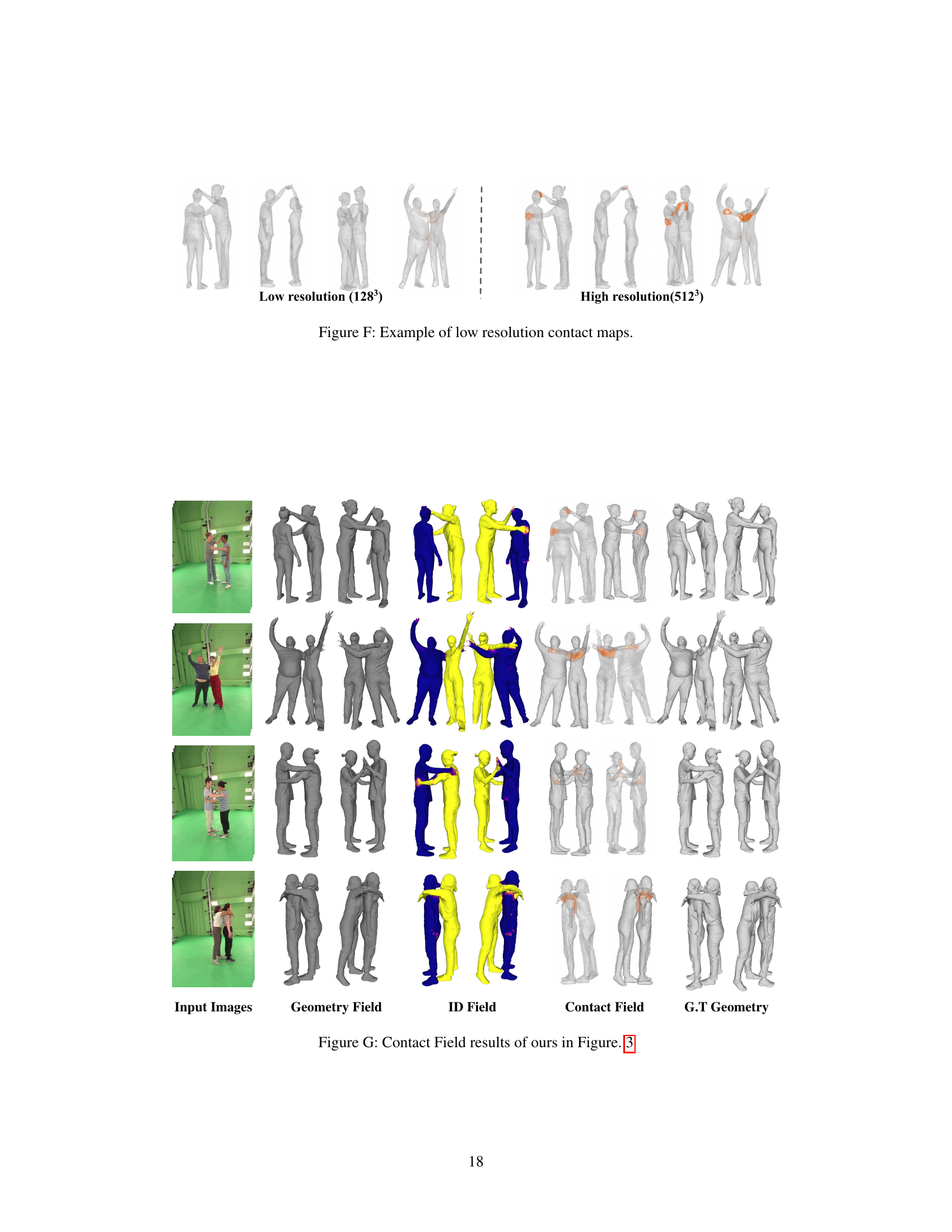
🔼 This figure shows a comparison of contact maps generated at low resolution (128³) and high resolution (512³). The low-resolution contact map shows less detail and accuracy compared to the high-resolution one. The difference in resolution is particularly evident in areas where multiple people are in close proximity.
read the caption
Figure F: Example of low resolution contact maps.

🔼 This figure compares the performance of the proposed method against the baseline method, DeepMultiCap (DMC), on two datasets: Hi4D and SynMPI. For each dataset, multiple examples are shown, each consisting of four columns: input multi-view images, geometry generated by DMC, geometry generated by the proposed method, and the ground truth geometry. This visual comparison helps to demonstrate the superior accuracy and detail of the proposed method in reconstructing 3D human poses, particularly in complex multi-person interaction scenarios.
read the caption
Figure 3: We compare our method to baseline DMC [43] on Hi4D (top) and SynMPI (bottom) test set. From left to right columns, we show the input multi-view images, the generated geometry by each method, and ground truth (GT) Geometry.

🔼 This figure compares the performance of the proposed method against the baseline method (DMC) on two datasets, Hi4D and SynMPI. It shows the input multi-view images and the resulting 3D geometry generated by both methods, along with the ground truth geometry. The comparison highlights the improved accuracy and detail in the 3D reconstructions produced by the proposed method, especially in challenging scenarios with occlusions.
read the caption
Figure 3: We compare our method to baseline DMC [43] on Hi4D (top) and SynMPI (bottom) test set. From left to right columns, we show the input multi-view images, the generated geometry by each method, and ground truth (GT) Geometry.
🔼 This figure compares the performance of the proposed method against the baseline method, DeepMultiCap (DMC), on two datasets: Hi4D and SynMPI. For each dataset, the figure shows multiple examples with input images (front and back views), the 3D geometry produced by DMC, the 3D geometry produced by the proposed method, and the ground truth (GT) geometry. This visual comparison allows assessment of the accuracy and detail of the 3D reconstructions generated by each method, particularly for multi-person interactions in close proximity.
read the caption
Figure 3: We compare our method to baseline DMC [43] on Hi4D (top) and SynMPI (bottom) test set. From left to right columns, we show the input multi-view images, the generated geometry by each method, and ground truth (GT) Geometry.
More on tables

🔼 This table presents the results of an ablation study on the grouping loss function used in the model. It shows how different components of the loss function (squared distance and exponential penalty) affect the performance of the model in terms of CD, P2S, NC, and CP metrics. The ablation study examines four variants: (a) using neither squared distance nor exponential penalty, (b) using squared distance but not exponential penalty, (c) using exponential penalty but not squared distance, and (d) using both. The results indicate the importance of using both components for optimal performance.
read the caption
Table 2: Ablation study on grouping loss function in Eq (12).
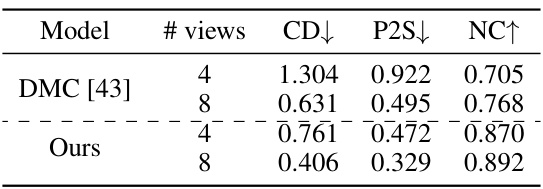
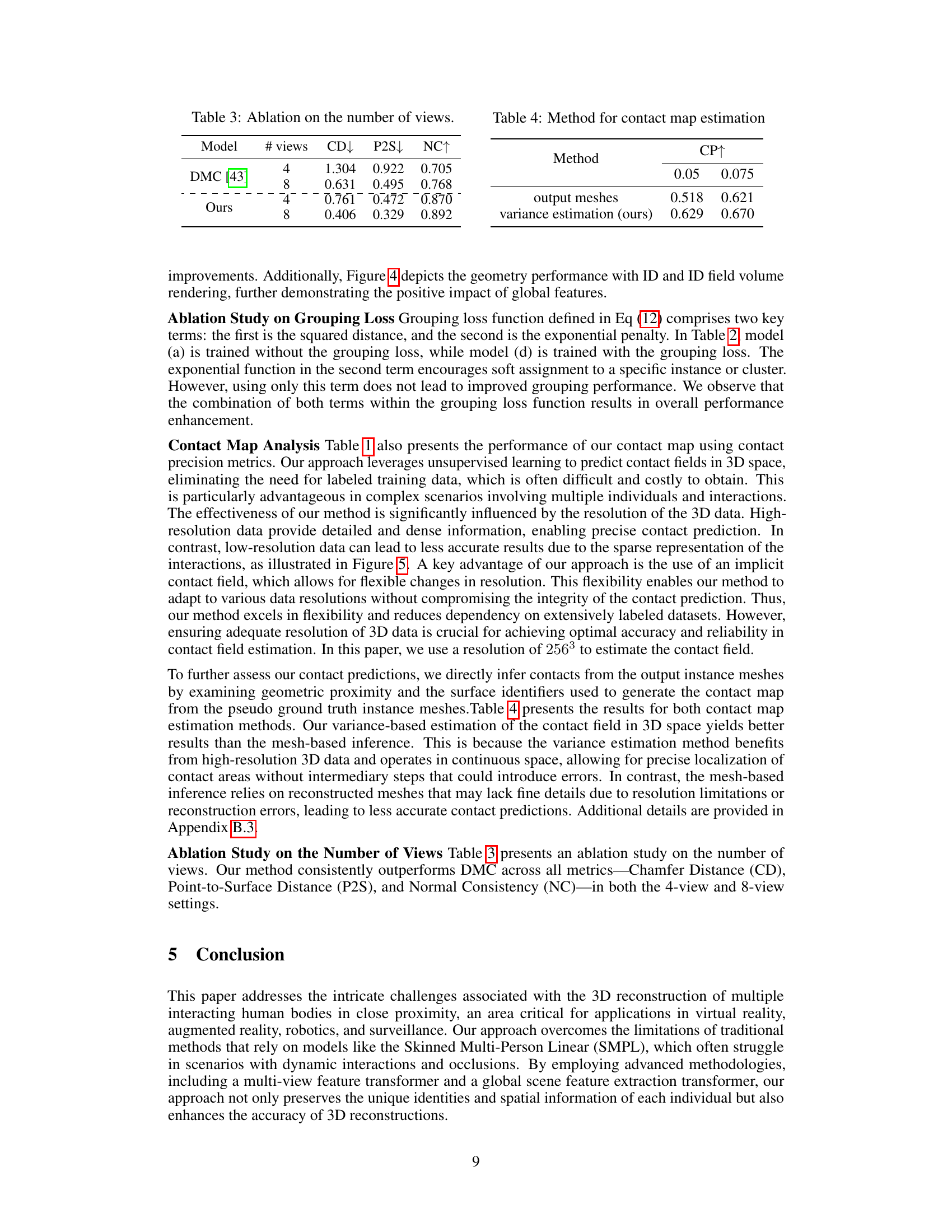
🔼 This table shows the results of an ablation study conducted to evaluate the impact of the number of views used for 3D reconstruction on the performance of the proposed method and a baseline method (DMC). The metrics used are Chamfer Distance (CD), Point-to-Surface Distance (P2S), and Normal Consistency (NC). Lower CD and P2S values indicate better reconstruction accuracy, while a higher NC value represents better normal consistency. The table demonstrates that increasing the number of views improves the overall accuracy of 3D reconstruction.
read the caption
Table 3: Ablation on the number of views.
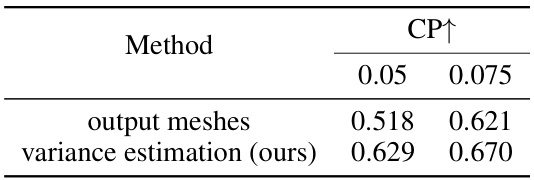
🔼 This table compares two methods for contact map estimation: using output meshes and variance estimation. The results show contact precision (CP) at different thresholds (0.05 and 0.075). Variance estimation, the method proposed by the authors, achieves higher contact precision.
read the caption
Table 4: Method for contact map estimation
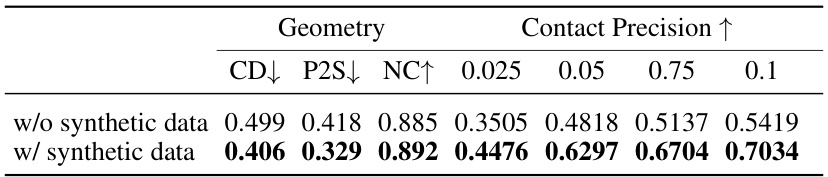
🔼 This table presents the quantitative evaluation results for multi-person interaction geometry using four metrics: Chamfer Distance (CD), Point to Surface Distance (P2S), Normal Consistency (NC), and Contact Precision (CP). CD, P2S, and NC evaluate the accuracy of the 3D geometry reconstruction, while CP specifically assesses the accuracy of contact point estimation, showing results for various thresholds (ε). The table compares the performance of the proposed method to the DeepMultiCap (DMC) method and shows an ablation study removing the SRT component from the proposed method.
read the caption
Table 1: Evaluation results for multi-person interaction geometry. The values presented under the CP row indicate the threshold value, denoted by ε, which was employed to construct the pseudo G.T. contact map in 3D space for evaluation.

🔼 This table presents the results of an ablation study conducted to evaluate the impact of different components of the grouping loss function (Equation 12) on the overall performance of the model. The grouping loss function is designed to improve the accuracy of the ID field by minimizing the variance within groups of values corresponding to the same ground truth label and maximizing the separation between groups assigned different labels. The ablation study involves removing or altering specific terms of the grouping loss function to assess their individual contributions to the model’s performance. The metrics used to evaluate the impact are Chamfer Distance (CD), Point-to-Surface Distance (P2S), and Normal Consistency (NC), representing reconstruction accuracy, and Contact Precision (CP) representing the accuracy of contact prediction.
read the caption
Table 2: Ablation study on grouping loss function in Eq (12).
Full paper#