TL;DR#
Existing neural topic models often compromise between effectiveness, efficiency, and stability. VAE-based models are effective but slow, while clustering-based models are efficient but less effective. These models also struggle with stability and transferability across different datasets and scenarios. This instability and inefficiency hinders their real-world applicability.
FASTopic, a novel topic model, addresses these issues using Dual Semantic-relation Reconstruction (DSR) and Embedding Transport Plan (ETP). DSR directly models semantic relations between document, topic, and word embeddings, while ETP regularizes these relations as optimal transport plans. This approach results in a more efficient and stable topic model with superior performance. Extensive experiments demonstrate FASTopic’s advantages in effectiveness, efficiency, adaptivity, stability, and transferability compared to current state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in topic modeling due to FASTopic’s superior performance across various aspects. Its efficiency and transferability address major limitations of existing methods, opening new avenues for large-scale applications and cross-domain analysis. The innovative DSR and ETP methods provide a novel paradigm for topic modeling research, likely influencing future model development and applications.
Visual Insights#

🔼 This figure presents a comparison of FASTopic against other topic modeling methods. Subfigure (a) shows that FASTopic achieves the highest overall performance rank while maintaining a top rank in running speed. Subfigure (b) demonstrates the scalability of FASTopic by showing its running time remains relatively low even as the dataset size increases, outperforming other methods.
read the caption
Figure 1: (a): Running speed rank and overall performance rank on the experiments with 6 benchmark datasets, including topic quality, doc-topic distribution quality, downstream tasks, and transferability. (b): Running time under the WoS dataset with varying sizes. See complete results in Figure 6.
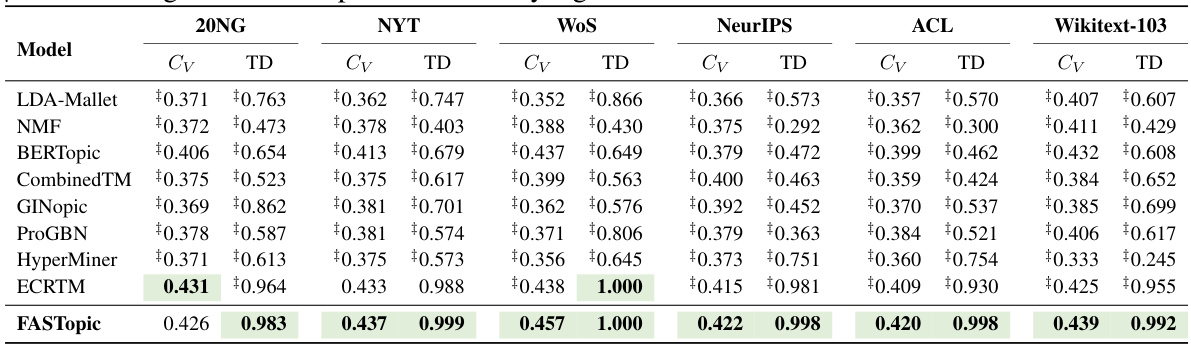
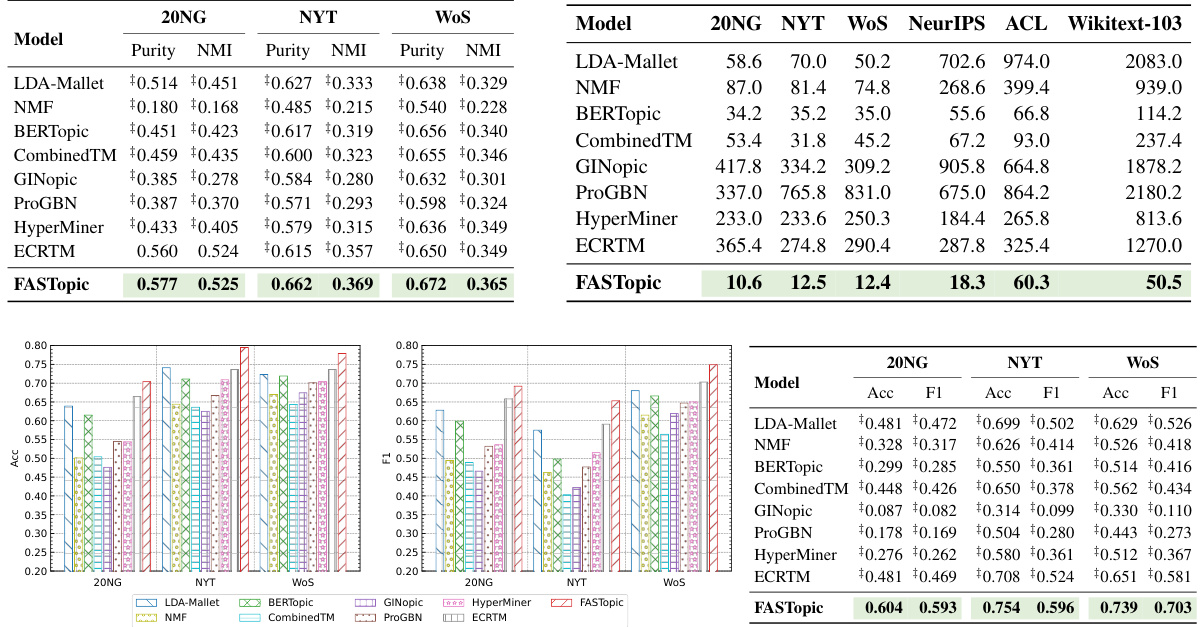
🔼 This table presents the results of evaluating topic quality using two metrics: topic coherence (Cv) and topic diversity (TD). The table compares the performance of FASTopic against several baseline topic models across six different benchmark datasets (NYT, 20NG, WoS, NeurIPS, ACL, Wikitext-103). Higher Cv scores indicate better coherence between top words in a topic, while higher TD scores indicate greater diversity among the topics. The best result for each metric and dataset is highlighted in bold, and statistically significant improvements by FASTopic are denoted.
read the caption
Table 1: Topic quality results of Cv (topic coherence) and TD (topic diversity). The best is in bold. ‡ denotes the gain of FASTopic is statistically significant at 0.05 level.
In-depth insights#
Dual Semantic Reconstruction#
The concept of “Dual Semantic Reconstruction” suggests a novel approach to topic modeling. It likely involves simultaneously reconstructing two key semantic relationships: the relationship between documents and topics, and the relationship between topics and words. This dual approach is intriguing because it moves beyond the limitations of traditional methods that focus on only one of these relationships. By considering both simultaneously, the model potentially captures a richer and more nuanced understanding of the underlying semantic structure of a corpus. The effectiveness of such a dual approach hinges on how effectively the model can learn the representations for documents, topics, and words, and how these representations are used to reconstruct the semantic relations. The success of this approach would probably demonstrate a significant improvement in topic quality, possibly leading to more coherent and interpretable topics, and more accurate document-topic distributions. A key challenge in this approach would be handling potential biases in learned semantic relations. This might be addressed by incorporating techniques like optimal transport, which could ensure more accurate and balanced relationships, preventing certain topics or words from dominating the representation. Overall, “Dual Semantic Reconstruction” offers a potentially powerful and innovative approach to topic modeling, worthy of further investigation and development.
Embedding Transport Plan#
The proposed Embedding Transport Plan (ETP) method tackles a critical issue in topic modeling: relation bias. Traditional methods, using parameterized softmax, often produce weak and biased semantic relations, hindering accurate topic discovery. ETP addresses this by framing the relation modeling as an optimal transport problem. By explicitly regularizing these relations as optimal transport plans using an entropic regularization approach, ETP ensures that the relations are both informative and robust. This addresses the relation bias by explicitly enforcing an optimal matching between document and topic embeddings, and between topic and word embeddings, leading to distinct and meaningful topics. The resulting framework provides improved performance compared to other state-of-the-art baselines in terms of efficiency and effectiveness.
FASTopic’s Efficiency#
FASTopic demonstrates significant efficiency gains in topic modeling. Its novel Dual Semantic-relation Reconstruction (DSR) paradigm avoids the computationally expensive training processes of VAE-based methods. Instead, DSR directly models semantic relationships between document, topic, and word embeddings using a pretrained Transformer. The Embedding Transport Plan (ETP) further enhances efficiency by optimizing these relations as optimal transport plans, addressing a relation bias issue present in simpler softmax approaches. Experiments showcase FASTopic’s superior speed compared to state-of-the-art baselines across multiple datasets, consistently completing tasks within minutes where others require hours. This speed advantage is particularly notable when dealing with larger datasets, highlighting FASTopic’s scalability and making it practical for real-world applications. The simplicity of the DSR framework, coupled with ETP’s efficient regularization, contributes significantly to FASTopic’s overall speed and performance.
Transferability & Adaptability#
The heading ‘Transferability & Adaptability’ suggests an investigation into a model’s capacity to perform well across different datasets and scenarios. High transferability indicates the model generalizes effectively to new, unseen data, showing consistent performance without substantial retraining. This is crucial for real-world applications where data can be diverse and may not always match the training set. Strong adaptability, conversely, demonstrates the model’s robustness against variations in data characteristics, such as size or vocabulary. A highly adaptable model can function reliably even with changes in data distribution or volume, showcasing its resilience and practical value. The research likely explores these facets using metrics reflecting both performance consistency and robustness. Quantitative evaluations of transferability might involve testing the model on multiple datasets separate from its training data, measuring performance changes. For adaptability, analyses might involve varying dataset sizes or vocabulary, while measuring the model’s ability to maintain its performance. This section would then critically evaluate how well the model generalizes and adapts, providing crucial insights into its practical usefulness.
Future Research#
Future research directions stemming from this paper could explore several key areas. Extending FASTopic to handle various data modalities beyond text, such as images or graphs, would broaden its applicability and impact. Investigating the optimal transport plan (ETP) further could lead to more efficient and effective topic modeling algorithms, possibly by exploring alternative cost functions or regularization techniques. Incorporating external knowledge into the model, perhaps through knowledge graphs, could enhance topic discovery and improve interpretability. Addressing the limitations related to extremely long documents or massive vocabularies is crucial for real-world applications. Finally, deeper analysis of the model’s sensitivity to hyperparameters would make FASTopic more robust and user-friendly.
More visual insights#
More on figures

🔼 This figure illustrates three different topic modeling paradigms. (a) shows a VAE-based approach, using an encoder and decoder to model topic distributions. (b) demonstrates a clustering-based method, clustering document embeddings to find topics. (c) introduces the paper’s proposed Dual Semantic-relation Reconstruction (DSR) method, modeling the relationships between document-topic and topic-word embeddings as transport plans to mitigate bias.
read the caption
Figure 2: Illustration of topic modeling paradigms. (a): VAE-based topic modeling with an encoder and a decoder [91, 65, 73]. (b): Clustering-based topic modeling by clustering document embeddings [2, 24]. (c): Dual Semantic-relation Reconstruction (DSR), modeling doc-topic distributions as the semantic relations between document (■) and topic embeddings (▲), and modeling topic-word distributions as the semantic relations between topic (▲) and word embeddings (). Here we model these relations as the transport plans to alleviate the relation bias issue.
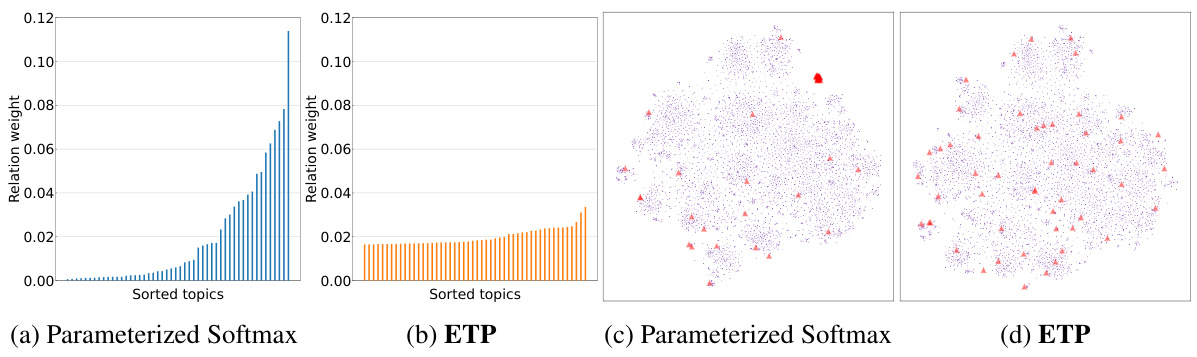
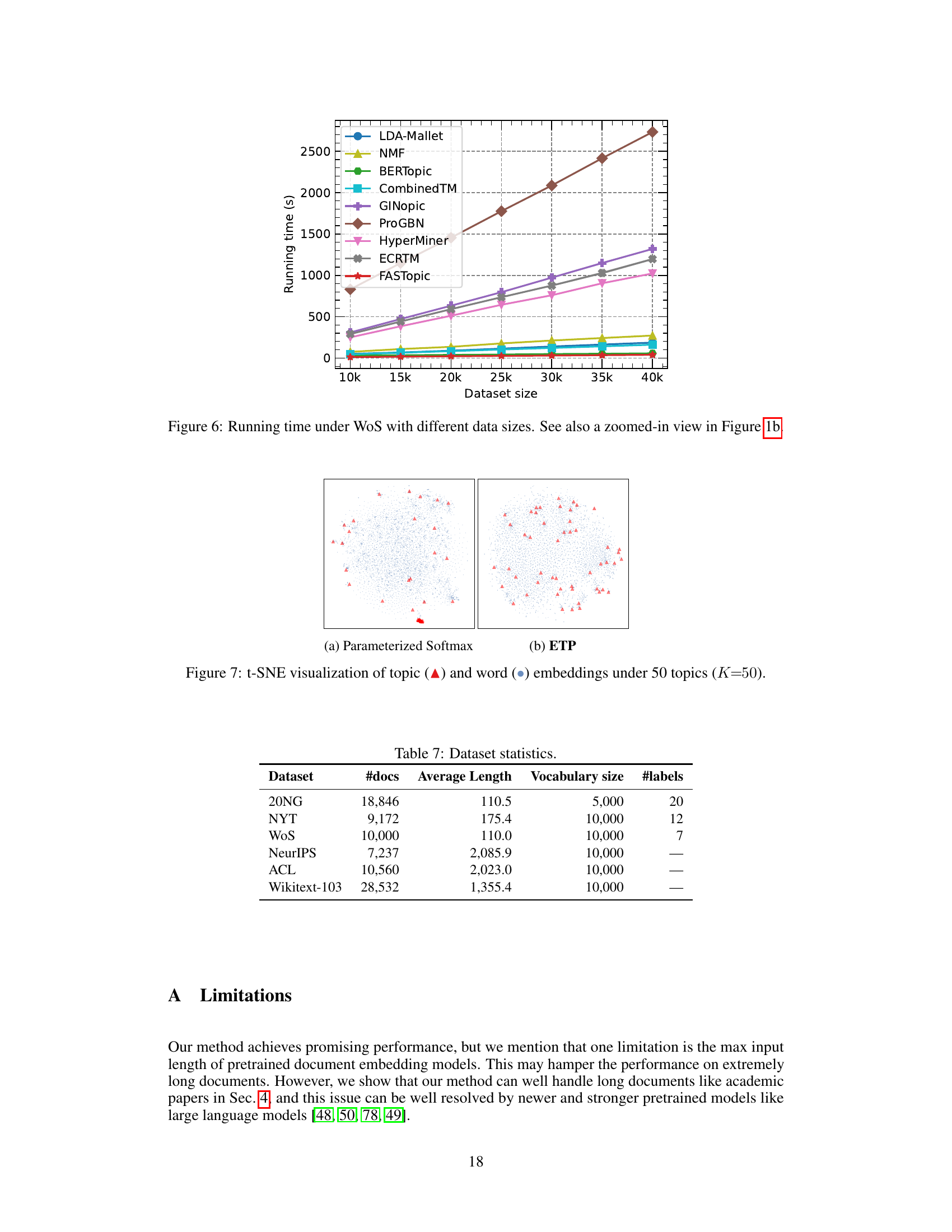
🔼 This figure compares the effectiveness of two methods for modeling semantic relations in topic modeling: Parameterized Softmax and Embedding Transport Plan (ETP). The left two subfigures (a and b) show the distribution of relation weights between topics and documents for both methods. Parameterized Softmax shows a highly skewed distribution, with most relations having low weights, indicating a potential bias. ETP, on the other hand, demonstrates a more uniform distribution of weights. The right two subfigures (c and d) use t-SNE to visualize the topic and document embeddings. Parameterized Softmax shows topic embeddings clustered together, indicating the relation bias. In contrast, ETP effectively separates the topic embeddings, suggesting better topic distinctiveness. This visualization supports the claim that ETP addresses the relation bias issue and leads to more effective topic modeling.
read the caption
Figure 3: (a, b): Relation weights of topics to documents. (c, d): t-SNE visualization [63] of document (■), and topic (▲) embeddings under 50 topics (K=50). While most topic embeddings gather together in Parameterized Softmax (a,c) as it causes biased relations, ETP (b,d) separates all topic embeddings with regularized relations, avoiding the bias issue.
🔼 This figure shows a comparison of FASTopic’s performance against other topic modeling methods across several benchmark datasets. Subfigure (a) presents the ranking of FASTopic and other methods based on running speed and overall performance, which considers various aspects such as topic quality, doc-topic distribution, and downstream tasks. Subfigure (b) displays the running time of FASTopic and other methods under varying dataset sizes using the WoS dataset. FASTopic demonstrates superior efficiency and effectiveness in both aspects.
read the caption
Figure 1: (a): Running speed rank and overall performance rank on the experiments with 6 benchmark datasets, including topic quality, doc-topic distribution quality, downstream tasks, and transferability. (b): Running time under the WoS dataset with varying sizes. See complete results in Figure 6.

🔼 This figure compares the performance of Parameterized Softmax and Embedding Transport Plan (ETP) in topic modeling. Subfigures (a) and (b) show the relation weights between topics and documents, illustrating how ETP addresses the relation bias issue by creating more distinct and less overlapping relations. Subfigures (c) and (d) visualize the topic embeddings using t-SNE, where ETP results in better separation of topic embeddings indicating less bias and better model performance.
read the caption
Figure 3: (a, b): Relation weights of topics to documents. (c, d): t-SNE visualization [63] of document (), and topic (▲) embeddings under 50 topics (K=50). While most topic embeddings gather together in Parameterized Softmax (a,c) as it causes biased relations, ETP (b,d) separates all topic embeddings with regularized relations, avoiding the bias issue.

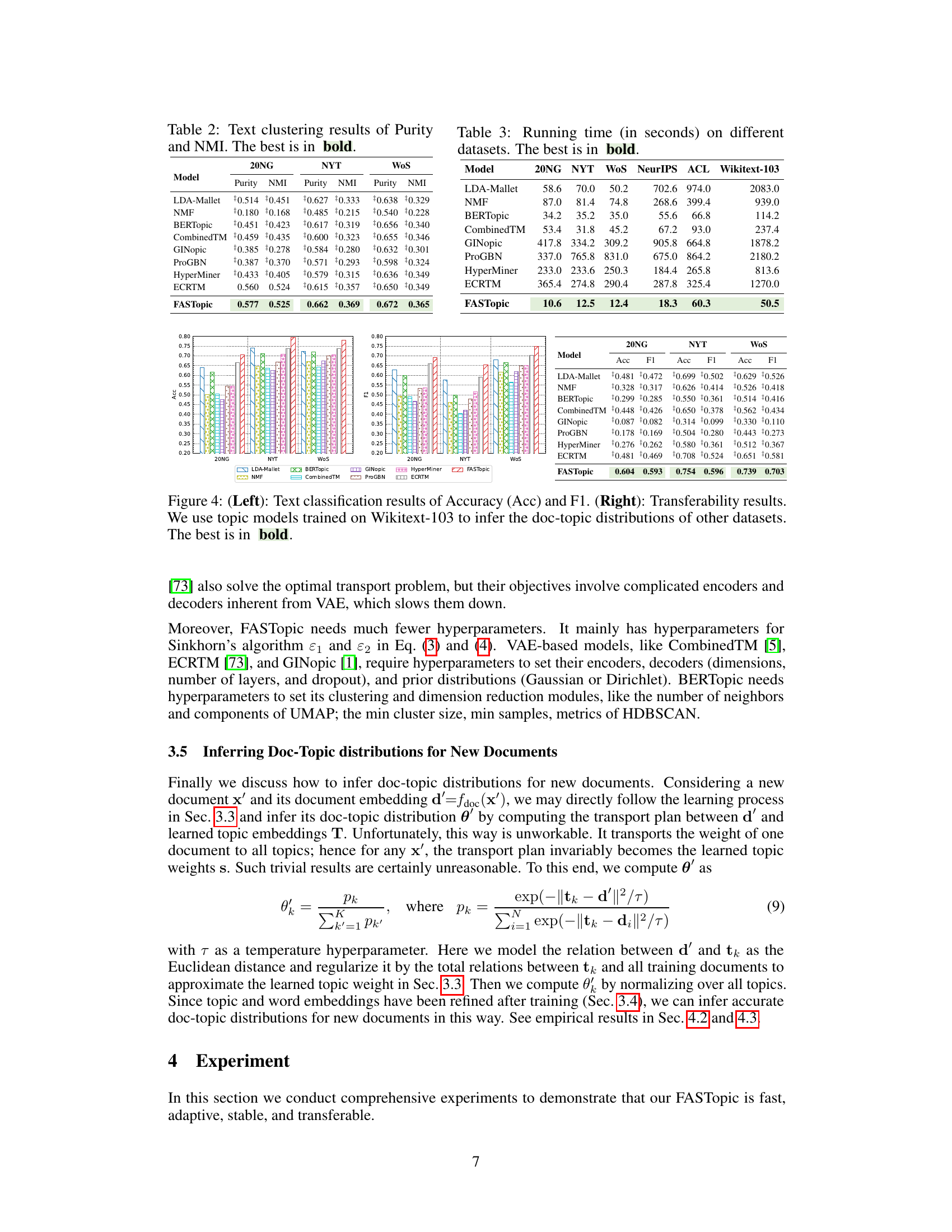
🔼 This figure shows the running time of various topic modeling methods under different dataset sizes using the WoS dataset. The x-axis represents the dataset size, and the y-axis represents the running time in seconds. FASTopic demonstrates significantly faster running times compared to other methods, especially as the dataset size increases.
read the caption
Figure 6: Running time under WoS with different data sizes. See also a zoomed-in view in Figure 1b.

🔼 This figure visualizes the effect of using Parameterized Softmax versus Embedding Transport Plan (ETP) for modeling semantic relations in topic modeling. The left column (a and c) shows the results with Parameterized Softmax, illustrating biased relations where most topic embeddings cluster together. The right column (b and d) displays the results with ETP, demonstrating that ETP effectively regularizes these relations, leading to better separation and distinction among topic embeddings. The t-SNE plots provide a visual representation of the embedding spaces in two different scenarios.
read the caption
Figure 3: (a, b): Relation weights of topics to documents. (c, d): t-SNE visualization [63] of document (), and topic (▲) embeddings under 50 topics (K=50). While most topic embeddings gather together in Parameterized Softmax (a,c) as it causes biased relations, ETP (b,d) separates all topic embeddings with regularized relations, avoiding the bias issue.
🔼 This figure compares the performance of Parameterized Softmax and Embedding Transport Plan (ETP) in topic modeling. Subfigures (a) and (b) show the relation weights of topics to documents, illustrating how ETP addresses the relation bias issue by distributing weights more evenly compared to Parameterized Softmax. Subfigures (c) and (d) use t-SNE to visualize the document and topic embeddings. Parameterized Softmax results in clustered embeddings, while ETP produces more separated and distinct topic embeddings, indicative of better topic modeling performance.
read the caption
Figure 3: (a, b): Relation weights of topics to documents. (c, d): t-SNE visualization [63] of document (), and topic (▲) embeddings under 50 topics (K=50). While most topic embeddings gather together in Parameterized Softmax (a,c) as it causes biased relations, ETP (b,d) separates all topic embeddings with regularized relations, avoiding the bias issue.
More on tables

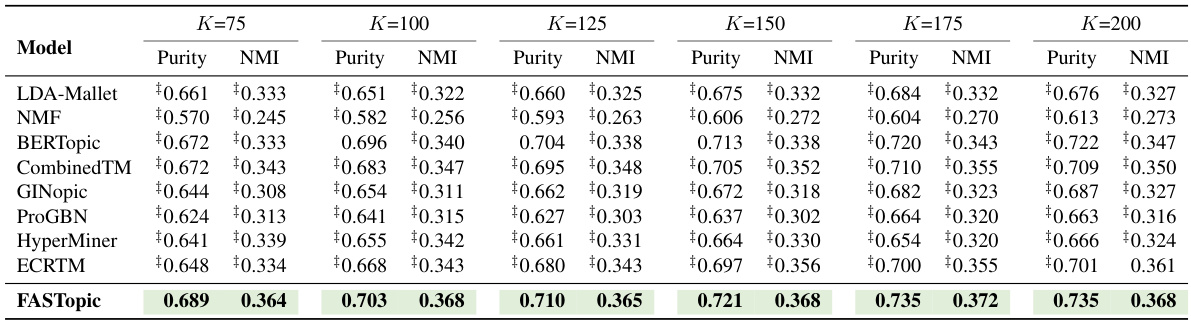
🔼 This table presents the results of topic coherence (Cv) and topic diversity (TD) for different topic model baselines (LDA-Mallet, NMF, BERTopic, CombinedTM, GINopic, ProGBN, HyperMiner, ECRTM) and the proposed FASTopic model. The results are shown for six different numbers of topics (K = 75, 100, 125, 150, 175, 200). The best performing model for each metric and topic number is highlighted in bold. This table demonstrates the effectiveness of FASTopic compared to other topic models in terms of producing coherent and diverse topics.
read the caption
Table 4: Topic quality results of Cv (topic coherence) and TD (topic diversity) under different topic numbers (K). The best is in bold.
🔼 This table presents the results of document clustering using Purity and NMI metrics. The clustering was performed with different numbers of topics (K=75, 100, 125, 150, 175, 200). The table compares FASTopic’s performance against several baseline topic modeling methods. The best performance for each metric (Purity and NMI) and for each number of topics (K) is highlighted in bold.
read the caption
Table 5: Document clustering results of Purity and NMI under different topic numbers (K). The best is in bold.

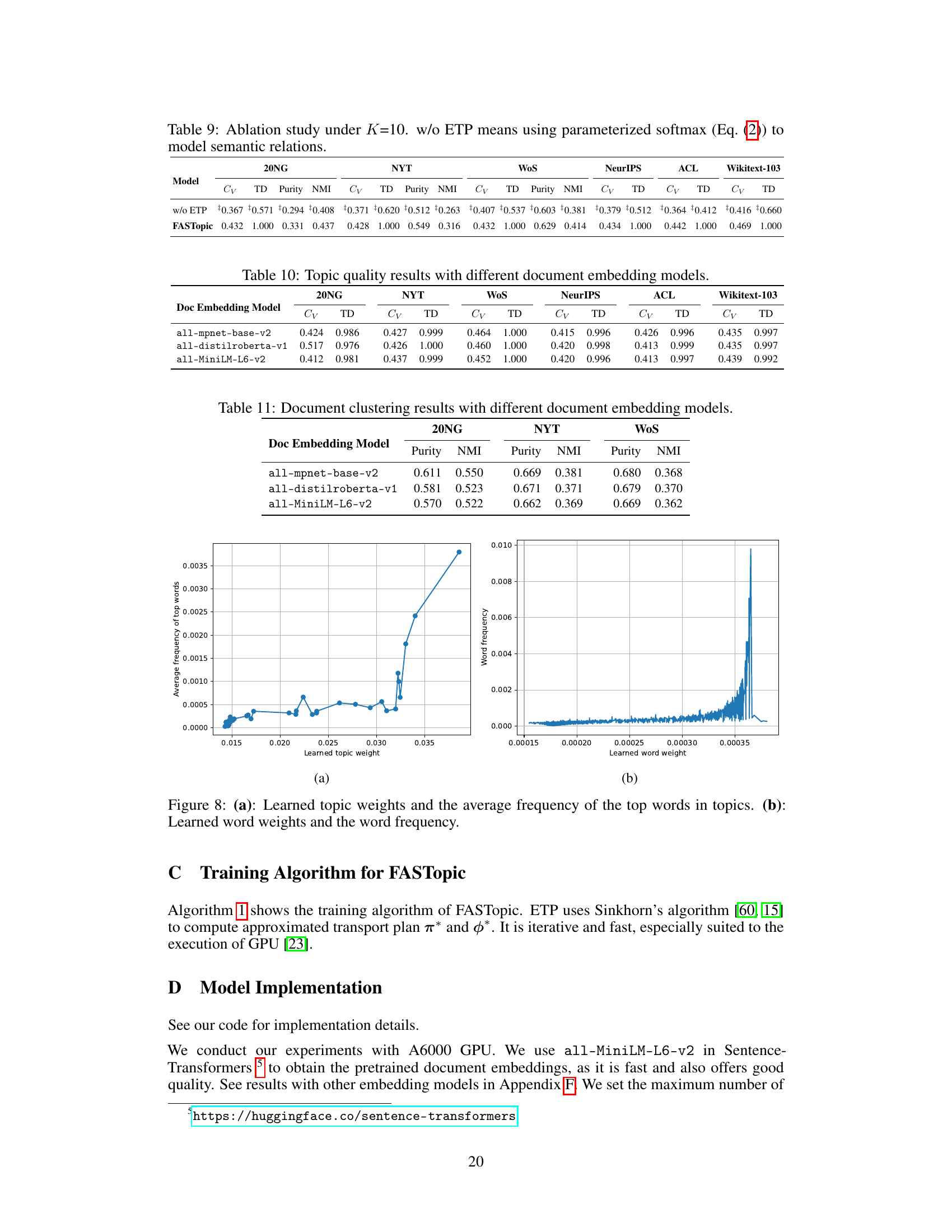
🔼 This ablation study compares the performance of FASTopic with and without the Embedding Transport Plan (ETP) method. The ‘w/o ETP’ row shows results using the standard parameterized softmax approach instead of ETP. The results show that ETP significantly improves the topic quality (Cv, TD) and document clustering quality (Purity, NMI) across three benchmark datasets (20NG, NYT, and WoS).
read the caption
Table 6: Ablation study. w/o ETP means using parameterized softmax (Eq. (2)) to model semantic relations. See also Table 8 for results on other datasets.
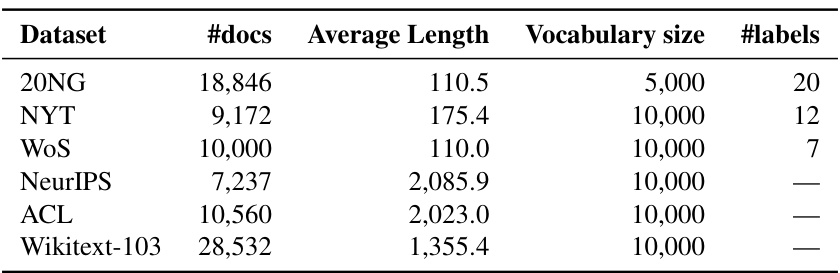
🔼 This table presents the statistics of six benchmark datasets used in the paper’s experiments. For each dataset, the number of documents (#docs), the average document length (Average Length), the vocabulary size (Vocabulary size), and the number of labels (#labels) are provided. The number of labels is not available for NeurIPS, ACL, and Wikitext-103 datasets.
read the caption
Table 7: Dataset statistics.

🔼 This table presents the ablation study results comparing the performance of FASTopic with and without the Embedding Transport Plan (ETP) method. The ‘w/o ETP’ row shows the results when the simpler parameterized softmax is used to model semantic relations, while the FASTopic row shows the results using the proposed ETP method. The table demonstrates the significance of ETP in improving the quality of topic modeling, as measured by topic coherence (Cv), topic diversity (TD), Purity, and NMI. Results are shown for three datasets (20NG, NYT, and WoS).
read the caption
Table 6: Ablation study. w/o ETP means using parameterized softmax (Eq. (2)) to model semantic relations. See also Table 8 for results on other datasets.

🔼 This table presents the results of topic coherence (Cv) and topic diversity (TD) for different topic models across six benchmark datasets: 20NG, NYT, WoS, NeurIPS, ACL, and Wikitext-103. FASTopic’s performance is compared against several baselines (LDA-Mallet, NMF, BERTopic, CombinedTM, GINopic, ProGBN, HyperMiner, and ECRTM). The ‘best’ performance for each metric and dataset is highlighted in bold, and a statistical significance test (at the 0.05 level) is indicated using the ‡ symbol.
read the caption
Table 1: Topic quality results of Cv (topic coherence) and TD (topic diversity). The best is in bold. ‡ denotes the gain of FASTopic is statistically significant at 0.05 level.

🔼 This table shows the results of topic coherence (Cv) and topic diversity (TD) using different pretrained document embedding models. The models compared are all-mpnet-base-v2, all-distilroberta-v1, and all-MiniLM-L6-v2. Results are shown across six benchmark datasets (20NG, NYT, WoS, NeurIPS, ACL, and Wikitext-103). The table helps assess how the choice of document embedding model impacts the quality of the resulting topic model.
read the caption
Table 10: Topic quality results with different document embedding models.
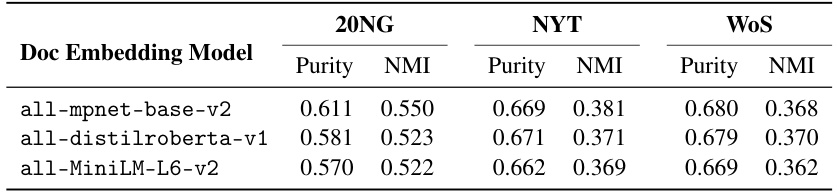
🔼 This table shows the purity and NMI scores achieved by using different document embedding models for document clustering. The results are presented for three different datasets (20NG, NYT, and WoS). The table allows for a comparison of the impact of different document embedding models on the quality of topic modeling results. It is used to demonstrate the effectiveness and robustness of the FASTopic model.
read the caption
Table 11: Document clustering results with different document embedding models.

🔼 This table compares the running time of BERTopic and FASTopic on the NYT dataset. The running time is broken down into four steps for BERTopic (loading document embeddings, dimensionality reduction, clustering document embeddings, and computing word weights), and two steps for FASTopic (loading document embeddings and training). The table shows that FASTopic is significantly faster than BERTopic, completing in 12.95 seconds compared to 32.42 seconds for BERTopic. This highlights the efficiency advantage of FASTopic.
read the caption
Table 12: Running time breakdowns (in seconds) of BERTopic and our FASTopic on the NYT dataset.

🔼 This table compares the running time of BERTopic and FASTopic on the NYT dataset. The running time is broken down into steps for each method: Load doc embeddings and Training. It demonstrates the significantly faster training time of FASTopic compared to BERTopic.
read the caption
Table 12: Running time breakdowns (in seconds) of BERTopic and our FASTopic on the NYT dataset.
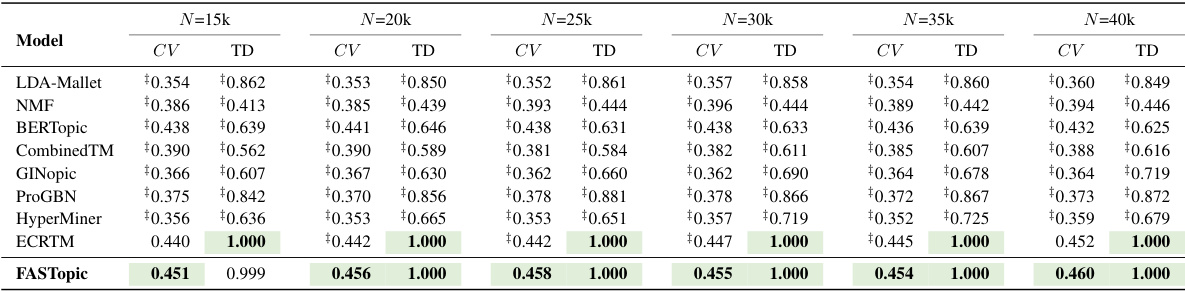
🔼 This table presents the results of topic coherence (Cv) and topic diversity (TD) for the WoS dataset under different dataset sizes (N). It shows how the topic quality metrics vary as the number of documents in the dataset changes, allowing for an analysis of the model’s performance stability and scalability with varying data volumes. The best performing model for each metric and dataset size is highlighted in bold.
read the caption
Table 13: Topic quality results of Cv (topic coherence) and TD (topic diversity) under different dataset sizes (N) of WoS. The best is in bold.
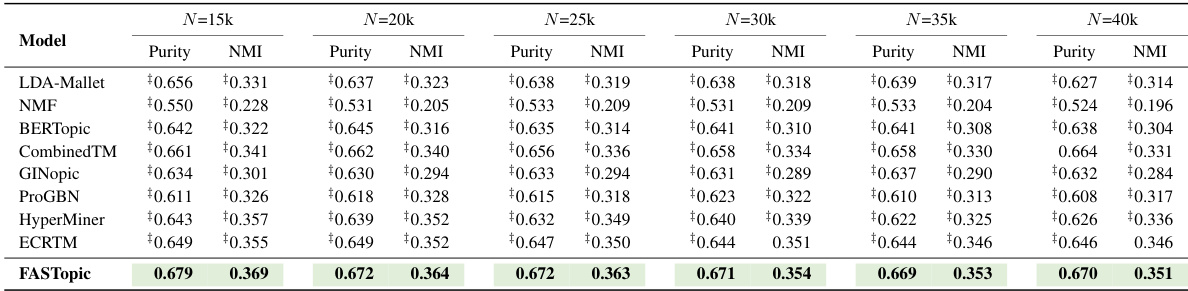
🔼 This table presents the results of document clustering experiments performed using different topic models on the WoS dataset, with varying dataset sizes (N). The performance of each model is evaluated using two metrics: Purity and NMI. The best results achieved by each model are highlighted in bold.
read the caption
Table 14: Document clustering results of Purity and NMI under different dataset sizes (N) of WoS. The best is in bold.

🔼 This table presents the results of topic coherence (Cv) and topic diversity (TD) for the WoS dataset under different vocabulary sizes. The performance of several topic modeling methods (LDA-Mallet, NMF, BERTopic, CombinedTM, GINopic, ProGBN, HyperMiner, ECRTM, and FASTopic) are compared across four vocabulary sizes (V=20k, V=30k, V=40k, V=50k). The best performance for each metric and vocabulary size is highlighted in bold. This demonstrates the stability and robustness of FASTopic across varying vocabulary sizes.
read the caption
Table 15: Topic quality results of Cv (topic coherence) and TD (topic diversity) under different vocabulary sizes (V) of WoS. The best is in bold.
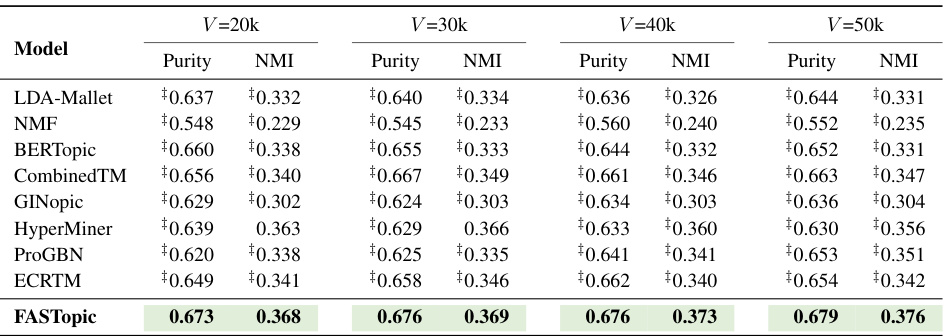
🔼 This table presents the results of evaluating topic quality using topic coherence (Cv) and topic diversity (TD) metrics on the WoS dataset, with varying vocabulary sizes (V). The performance of several topic models is compared, showing how well each model maintains topic quality as the vocabulary size increases. The best performing model is highlighted in bold for each metric and vocabulary size.
read the caption
Table 15: Topic quality results of Cv (topic coherence) and TD (topic diversity) under different vocabulary sizes (V) of WoS. The best is in bold.
Full paper#