TL;DR#
Electronic Health Records (EHRs) are crucial for patient health analysis, but missing data is a significant hurdle. Current methods often struggle with imputation, introducing noise and affecting predictions. This paper introduces the problem of inaccurate predictions due to missing values in EHR datasets. Various imputation techniques exist, but they often fail to capture crucial details and may add noise to predictions.
The proposed solution, SMART, utilizes a self-supervised missing-aware representation learning approach. It uses novel attention mechanisms to encode missing data effectively, pre-training the model to reconstruct missing representations in a latent space (not the input space). This method improves generalization and robustness. Extensive experiments on six EHR tasks demonstrate that SMART outperforms state-of-the-art methods, providing a significant advance in handling missing data for accurate health status prediction.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in healthcare—the prevalence of missing data in electronic health records (EHRs). The SMART model offers a novel approach to handle missing data, improving the accuracy and reliability of patient health status prediction. This is highly relevant to current research trends in healthcare AI, where improving the ability to make predictions from incomplete data is crucial for better decision-making. The proposed two-stage training strategy and novel attention mechanisms provide a valuable framework for future research in this domain, potentially leading to more effective clinical decision support systems. The open-sourcing of the code further enhances its impact, enabling wider collaboration and faster progress in this field.
Visual Insights#

🔼 This figure illustrates the SMART model’s architecture and training process. The left side shows the pre-training stage, where the model learns to reconstruct missing data in the latent space using a self-supervised approach. The right side details the model’s architecture, focusing on the input encoder and MART block, which handle temporal and variable interactions while encoding missingness. The MART block utilizes attention mechanisms to learn relationships between variables and time points.
read the caption
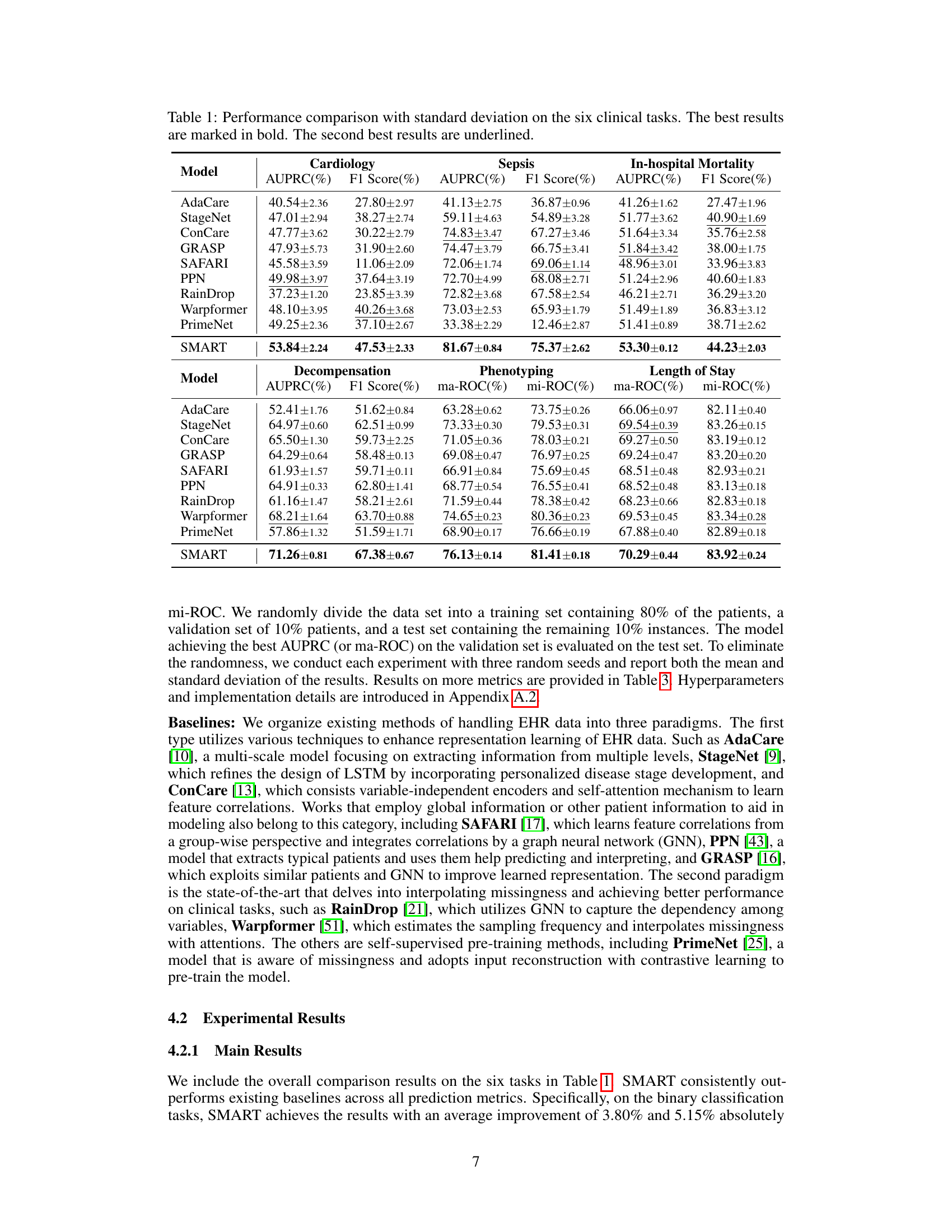
Figure 1: Overview of SMART. Left: Given EHR data with missingness, we randomly mask them on the existing observations and conduct reconstruction in the latent space. The reconstruction targets are generated by EMA updated parameters. Right: We illustrate the detailed architecture of the input encoder and the MART block. The input encoder embeds each variable (which can also be referred to as a biomarker) and missing mask into a separate hidden space. The MART block employs various techniques to capture feature interactions in both the temporal and variable dimensions while further encoding missing information.

🔼 This table presents a comparison of the performance of SMART against other state-of-the-art methods across six different clinical prediction tasks using two key metrics: AUPRC and F1 Score. The tasks cover diverse areas of patient health status prediction and the results show SMART’s superior performance and robustness.
read the caption
Table 1: Performance comparison with standard deviation on the six clinical tasks. The best results are marked in bold. The second best results are underlined.
In-depth insights#
EHR Data Imputation#
Electronic health record (EHR) data frequently suffers from missing values, significantly impacting the reliability of analyses and predictions. Imputation, the process of filling in these missing values, is crucial but challenging. Numerous techniques exist, ranging from simple methods like mean/mode imputation to sophisticated machine learning approaches. Simple methods are computationally inexpensive but often fail to capture the underlying patterns and complexities within EHR data, potentially introducing bias. More advanced techniques, such as multiple imputation or deep learning-based imputation, aim for greater accuracy but require more computational resources and careful consideration of model selection and hyperparameter tuning. The choice of imputation method hinges on several factors, including the nature of the missing data (missing completely at random, missing at random, or missing not at random), the size and complexity of the dataset, and the downstream analytical task. A key consideration is the potential for bias introduction. Imputation should not only fill in missing values but also preserve the underlying data distribution and relationships. Therefore, the selection of an appropriate imputation method necessitates a thorough understanding of its limitations and implications for the reliability and validity of any subsequent analysis.
SMART Model#
The SMART model, as described in the research paper, is a novel approach to patient health status prediction that directly addresses the challenge of missing data in Electronic Health Records (EHRs). Unlike traditional methods relying on imputation, SMART leverages a self-supervised pre-training phase to learn robust representations of EHR data that are less sensitive to missing values. The model incorporates missing-aware attentions to effectively encode both the presence and absence of data, improving generalization and robustness. The two-stage training strategy combines self-supervised learning with task-specific fine-tuning for enhanced performance. MART blocks are a core component, capturing temporal and variable interactions, thereby handling multivariate time series data effectively. Overall, SMART offers a significant advancement over existing methods by encoding missing information directly into representation learning, improving prediction accuracy and robustness while demonstrating efficiency. The model’s architecture is specifically designed for the unique characteristics of EHR data, leading to state-of-the-art results across various clinical tasks.
Missing Data#
The pervasive nature of missing data in Electronic Health Records (EHRs) presents a significant challenge for accurate patient health status prediction. Existing methods often rely on imputation, which can introduce noise and bias. SMART addresses this directly, by moving beyond simple imputation and instead focusing on learning robust representations that explicitly model the presence of missingness. This is achieved through innovative attention mechanisms that weigh observed data more heavily while still encoding the patterns of missingness itself. The self-supervised pre-training phase further strengthens the model’s capacity to handle missing values by learning to reconstruct missing representations in the latent space, resulting in better generalization and robustness. The paper highlights the effectiveness of this approach compared to methods that primarily focus on input space imputation, demonstrating SMART’s superiority across various prediction tasks.
MART Block#
The MART Block, a core component of the SMART model, is designed to learn effective patient health representations by leveraging both temporal and variable attention mechanisms. Crucially, it incorporates missing data awareness, directly integrating mask information into its attention calculations. This allows the model to not only focus on observed data points but also appropriately weight the impact of missing values in its representations. The use of missing-aware attentions differentiates this block from standard attention mechanisms, improving the robustness and generalization ability of the model. By stacking multiple MART blocks, the model can capture complex interactions across time and variables while intelligently handling sparsity inherent in EHR data. The design’s focus on higher-order representations, rather than low-level detail imputation, is key to its success in achieving state-of-the-art performance in various EHR prediction tasks. This design choice promotes better generalization and is directly responsible for SMART’s superior performance on incomplete data, a significant challenge in real-world healthcare applications.
Ablation Study#
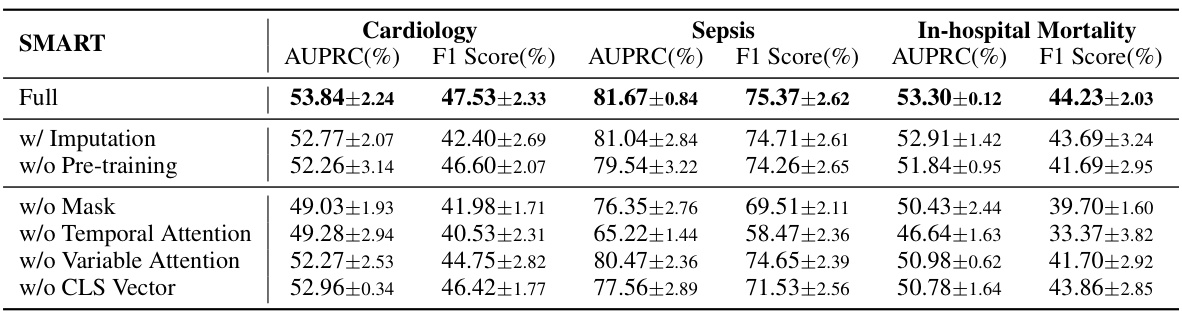
An ablation study systematically removes or deactivates components of a model to assess their individual contributions. In this context, it would likely involve removing or disabling different parts of the proposed SMART model (e.g., the missing-aware attentions, temporal attention, the pre-training stage) to isolate the impact of each on performance. The results would demonstrate the relative importance of each component and justify design choices. For instance, if removing the missing-aware attention significantly harms results, it confirms the crucial role of this module in handling missing data within EHR data. A well-executed ablation study strengthens the claims by providing evidence-based support for the architecture’s effectiveness, revealing which elements contribute most significantly to the overall performance and highlighting potential areas for future improvements.
More visual insights#
More on figures

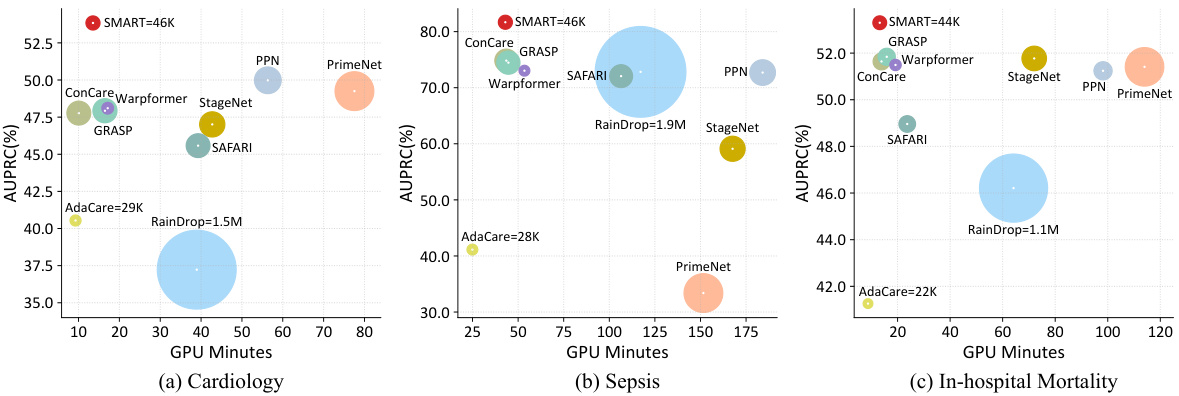
🔼 This figure shows the performance (AUPRC) of different models on three datasets (Cardiology, Sepsis, and In-hospital Mortality) under various observed rates of EHR data ranging from 10% to 100%. The x-axis represents the observed rate, while the y-axis represents the AUPRC. Each line represents a different model, allowing for a comparison of their robustness to missing data. The figure demonstrates how well the model generalizes in the presence of varying degrees of missing data. The results show SMART’s superior performance compared to the other models, especially when the observed rate is low.
read the caption
Figure 2: Performance on different observed ratio of EHR.
🔼 This figure provides a comprehensive overview of the SMART model, showcasing its two-stage training process (pre-training and fine-tuning). The left side illustrates the self-supervised pre-training stage, where the model learns to reconstruct missing data representations in the latent space. The right side details the architecture of the input encoder and the core MART block, highlighting how it handles temporal and variable interactions, along with missing information. The figure uses a visual representation to clearly depict the information flow and key components of the SMART model.
read the caption
Figure 1: Overview of SMART. Left: Given EHR data with missingness, we randomly mask them on the existing observations and conduct reconstruction in the latent space. The reconstruction targets are generated by EMA updated parameters. Right: We illustrate the detailed architecture of the input encoder and the MART block. The input encoder embeds each variable (which can also be referred to as a biomarker) and missing mask into a separate hidden space. The MART block employs various techniques to capture feature interactions in both the temporal and variable dimensions while further encoding missing information.
More on tables
🔼 This table presents a comparison of the performance of SMART against several other models on six different clinical tasks using two metrics, AUPRC and F1 Score. The tasks involve predicting various aspects of patient health status using Electronic Health Record (EHR) data. SMART consistently outperforms other methods, highlighted in bold. The table demonstrates the effectiveness of the SMART model across a range of clinical prediction challenges.
read the caption
Table 1: Performance comparison with standard deviation on the six clinical tasks. The best results are marked in bold. The second best results are underlined.

🔼 This table presents a comparison of the performance of SMART against other state-of-the-art models across six different clinical tasks involving Electronic Health Records (EHR) data. The tasks include Cardiology, Sepsis, In-hospital Mortality, Decompensation, Phenotyping, and Length of Stay. The performance is measured using AUPRC (Area Under the Precision-Recall Curve) and F1 Score for binary classification tasks, and ma-ROC (macro-averaged Area Under the Receiver Operating Characteristic Curve) and mi-ROC (micro-averaged AUROC) for multi-class tasks. The best performing model for each metric is bolded, and the second-best is underlined. Standard deviations are included to indicate the variability in results.
read the caption
Table 1: Performance comparison with standard deviation on the six clinical tasks. The best results are marked in bold. The second best results are underlined.

🔼 This table presents a comparison of the performance of SMART against other state-of-the-art methods across six different clinical prediction tasks using two evaluation metrics: AUPRC and F1 Score. The tasks cover various aspects of patient health status prediction, and the results highlight SMART’s superior performance and robustness in handling missing data, as indicated by the bold and underlined values representing the best and second-best results, respectively. Standard deviations are also provided to indicate the reliability of the results.
read the caption
Table 1: Performance comparison with standard deviation on the six clinical tasks. The best results are marked in bold. The second best results are underlined.

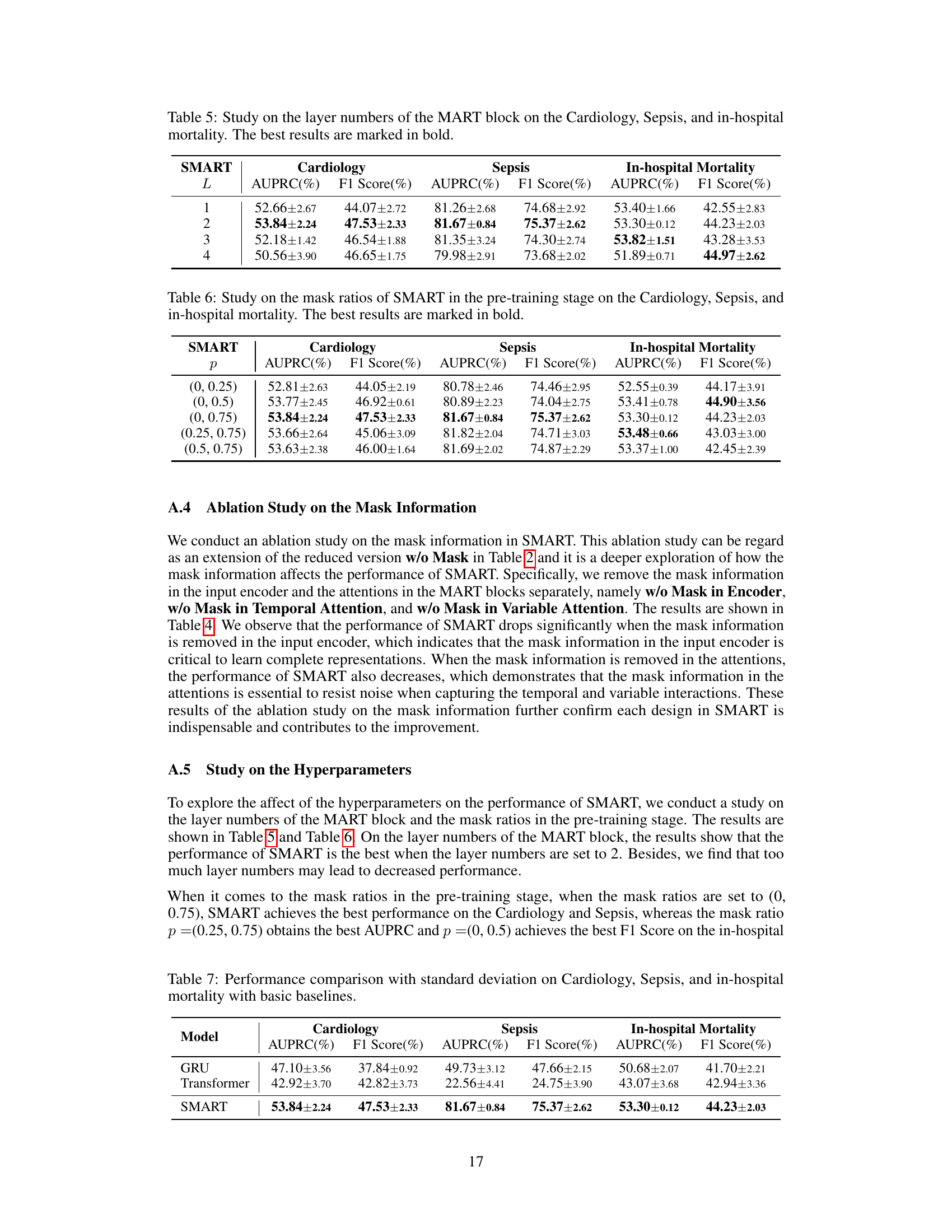
🔼 This table presents the results of an ablation study on the number of layers in the MART block of the SMART model. The study was conducted on three datasets: Cardiology, Sepsis, and In-hospital Mortality. The table shows the AUPRC and F1 score for each dataset and for different numbers of layers (1, 2, 3, and 4). The best results for each dataset are highlighted in bold, showing the optimal number of layers for the MART block.
read the caption
Table 5: Study on the layer numbers of the MART block on the Cardiology, Sepsis, and in-hospital mortality. The best results are marked in bold.

🔼 This table presents the results of an ablation study on the mask ratios used during the pre-training stage of the SMART model. The study evaluates the impact of varying the probability interval (p) for randomly masking observations during pre-training. Different probability intervals are tested to see how they affect the model’s performance on three different tasks: Cardiology, Sepsis, and In-hospital Mortality. The table shows the AUPRC and F1 Score for each task and mask ratio, highlighting the best-performing mask ratio for each task.
read the caption
Table 6: Study on the mask ratios of SMART in the pre-training stage on the Cardiology, Sepsis, and in-hospital mortality. The best results are marked in bold.

🔼 This table presents a comparison of the performance of the proposed SMART model against several other state-of-the-art models on six different clinical tasks. The tasks involve predicting various aspects of patient health status using Electronic Health Records (EHR) data. The table shows the AUPRC (Area Under the Precision-Recall Curve) and F1 scores for each model on each task. The best-performing model for each metric on each task is highlighted in bold, while the second-best is underlined. This allows for a comprehensive comparison across multiple metrics and tasks, illustrating the effectiveness of the SMART model in handling missing data and providing robust predictions.
read the caption
Table 1: Performance comparison with standard deviation on the six clinical tasks. The best results are marked in bold. The second best results are underlined.
Full paper#