TL;DR#
Current video-language models struggle with egocentric video understanding due to limitations in visual reasoning and capturing fine-grained relationships. They primarily rely on instance-level alignment, ignoring the natural, compositional way humans perceive scenes. This often leads to a lack of interpretability and limited performance.
The paper introduces HENASY, a hierarchical entity assembly framework that addresses these issues. HENASY leverages a spatiotemporal token grouping mechanism to assemble dynamic scene entities and models their relationships. It uses multi-grained contrastive losses for improved understanding and achieves strong interpretability via visual grounding with free-form text queries. Extensive experiments demonstrate HENASY’s superior performance and strong interpretability compared to existing models on several benchmark tasks.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to egocentric video understanding that addresses limitations of existing models. Its strong interpretability and competitive performance on various benchmarks make it a significant contribution to the field, opening new avenues for research in visual grounding and compositional video representation. The multi-grained contrastive learning framework is particularly valuable, and the model’s strong performance on zero-shot transfer tasks highlights its potential for broader application.
Visual Insights#
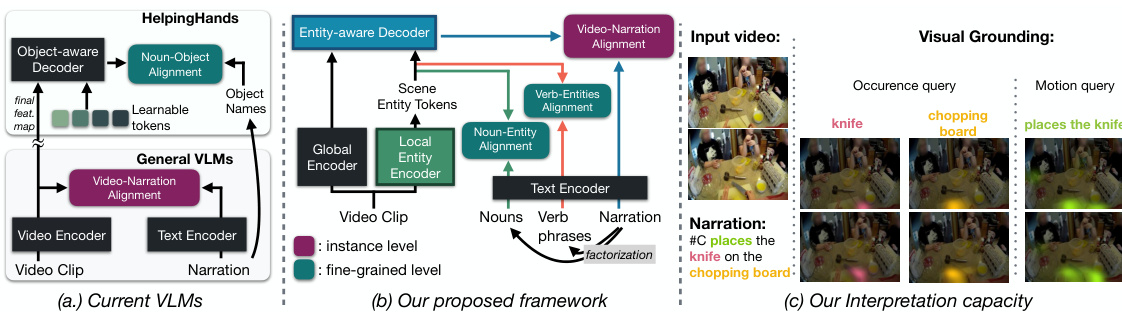
🔼 This figure provides a comparison of current video-language models (VLMs) with the proposed HENASY model. Panel (a) shows that current VLMs utilize instance-level contrastive learning, which limits their understanding of complex interactions within videos. In contrast, Panel (b) illustrates HENASY’s compositional approach, assembling dynamic scene entities and modeling their relationships for improved video representation. Finally, Panel (c) highlights HENASY’s interpretability through visual grounding, enabling queries based on appearance or motion.
read the caption
Figure 1: Problem Overview. (a) Current VLMs [5] rely on instance-level contrastive learning between video & narration. HelpingHands [4] implicitly induces object occurrence information into video features at final layer of video encoder. (b) Our proposed (HENASY) aims to assemble dynamic entities from video patches via local entity encoder, while entity-aware decoder captures interactions between entities and global context to form comprehensive video. HENASY is trained with suite of multi-grained contrastive alignments to enforce visual representations entity-level upto video-level. (c) By such compositional approach, HENASY is the first VLM that shows strong interpretability via visual grounding with both appearance/motion query types.
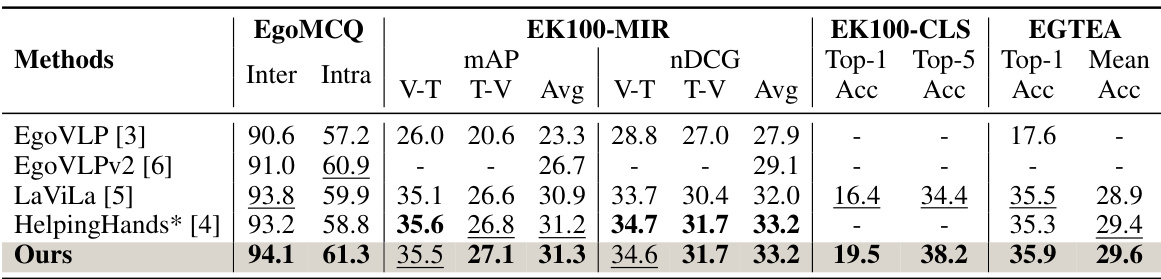
🔼 This table presents a comparison of the proposed HENASY model’s performance against several state-of-the-art (SOTA) video-language models on four zero-shot transfer tasks. The tasks cover various aspects of egocentric video understanding: multi-choice question answering (EgoMCQ), video-text retrieval (EK100-MIR), action classification (EK100-CLS), and temporal action localization (EGTEA). The metrics used vary depending on the task, but generally involve measures of accuracy and ranking performance. The table highlights HENASY’s competitive performance compared to existing methods, especially in the context of zero-shot transfer where the model is not fine-tuned for the specific tasks.
read the caption
Table 1: Comparison on the zero-shot transfer over EgoMCQ, EK100-MIR, EK100-CLS, and EGTEA. HelpingHands* refers to our re-produced results with TSF-B backbone using provided source code [4].
In-depth insights#
Egocentric VLM Issues#
Egocentric Vision-Language Models (VLMs) face significant challenges. Current approaches heavily rely on instance-level alignment between video and language, neglecting the holistic, compositional nature of human perception. This instance-level focus limits the model’s ability to understand complex interactions and relationships between scene entities, hindering effective visual reasoning. Furthermore, fine-grained relationships between modalities are often poorly captured, leading to a lack of interpretability. A key issue is the inability to effectively model dynamically evolving scene entities over time and their inherent interactions. This necessitates more sophisticated methods for spatiotemporal representation that move beyond simple instance-level comparisons. Addressing these limitations requires a shift toward compositional approaches, mimicking human perception by assembling scene entities and their relationships to generate more comprehensive video representations. This will allow for greater interpretability and improved performance on downstream tasks.
HENASY Framework#
The HENASY framework presents a novel approach to egocentric video-language modeling. Its core innovation lies in the compositional understanding of video content, moving beyond simple instance-level alignments. By assembling dynamically evolving scene entities through a hierarchical process, HENASY captures fine-grained relationships between video and language modalities. This hierarchical approach, incorporating both local and global encoding, facilitates better interpretability. The use of multi-grained contrastive losses further enhances the model’s ability to align video entities with textual elements, improving performance on various downstream tasks. Furthermore, HENASY’s unique method of visual grounding provides compelling qualitative insights by visualizing the dynamic interactions between scene entities. This results in a more effective and interpretable model for egocentric video understanding.
Multi-grained Loss#
The proposed multi-grained loss function is a key innovation enhancing the model’s interpretability and performance. It moves beyond typical instance-level alignment by incorporating three distinct alignment types: video-narration, noun-entity, and verb-entity. This multi-level approach allows the model to learn richer relationships between visual entities and textual descriptions. The video-narration alignment captures the overall semantic correspondence, while noun-entity alignment grounds specific nouns to their visual counterparts within the video. Crucially, verb-entity alignment links verbs to the entities involved in the described actions, explicitly capturing motion and activity information. This granular approach contrasts with simpler methods, resulting in improved accuracy across various downstream tasks and stronger visual grounding capabilities, as evidenced by the quantitative and qualitative results presented. The additional projection loss further enhances robustness by ensuring accurate alignment between predicted entity masks and ground truth bounding boxes.
Interpretability#
The concept of interpretability is crucial in evaluating the efficacy and trustworthiness of machine learning models, especially in high-stakes applications. In the context of egocentric video-language models, interpretability is particularly important because these models process complex, real-world data, often involving nuanced human interactions. The authors’ approach to enhance interpretability is commendable, leveraging compositional structure understanding to facilitate the assembly of scene entities. This allows for a more natural and human-like understanding of the video content, making the model’s reasoning process more transparent. The use of multi-grained contrastive losses and visual grounding techniques further strengthens interpretability by connecting model predictions with concrete elements in the video, enabling both quantitative and qualitative assessment. However, the level of interpretability achieved still depends on the complexity of the video scene and the inherent ambiguity of language. Future research should focus on handling complex scenarios and providing richer explanations to improve trust and adoption in real-world settings. The inclusion of dynamic saliency maps is a step toward a more intuitive visualization of the model’s attention and decision-making process. Addressing these remaining limitations will advance the field and broaden the applications of these models.
Future Work#
Future research directions stemming from this work on HENASY, a hierarchical egocentric video-language model, could focus on several key areas. Extending HENASY to handle longer video sequences and more complex narratives is crucial for real-world applications. Currently, the model’s performance might degrade with increased temporal complexity. Investigating methods for handling long-form videos efficiently, perhaps through hierarchical or segment-based approaches, would be beneficial. Additionally, while HENASY shows promising interpretability, exploring more sophisticated visual grounding techniques to more accurately highlight relevant entities and actions within the video is important. This could involve incorporating more advanced attention mechanisms or leveraging external knowledge sources. Finally, developing a dynamic scene graph representation would enhance the model’s ability to explicitly capture interactions between entities. This is a challenging area but would significantly improve the model’s understanding of the visual context.
More visual insights#
More on figures
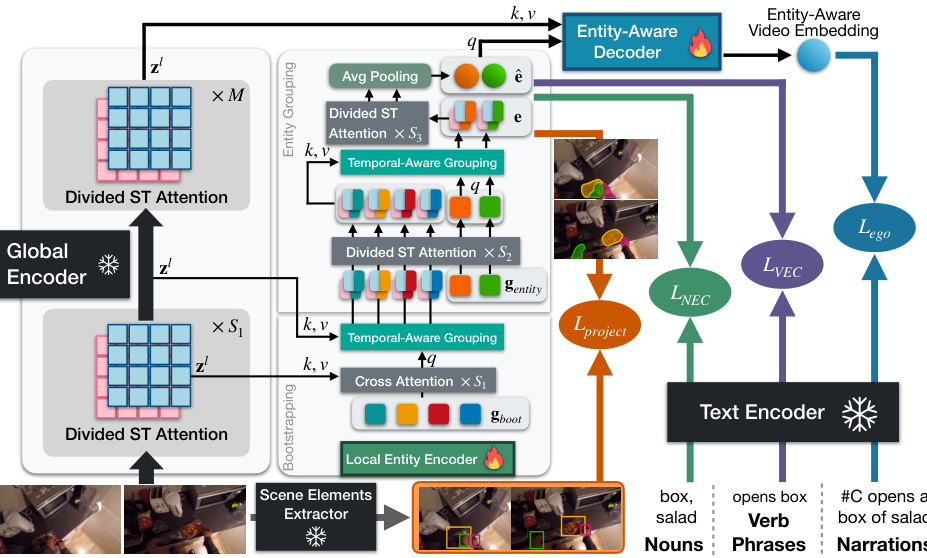
🔼 This figure illustrates the architecture of the HENASY model, which uses a dual-encoder architecture with a compositional approach to video understanding. The left side shows how the local entity encoder assembles dynamic scene entities from video patches, and the global encoder provides contextual information. These are combined in the entity-aware decoder to create an interpretable video representation. The right side highlights the model’s use of multi-grained contrastive learning to ensure both entity-level and video-level representations are well-learned.
read the caption
Figure 2: Overview of the HENASY framework for video-language modeling. Left: HENASY features a dual-encoder architecture with a compositional video understanding approach. The local entity encoder assembles dynamic scene entities from video patches, while the global encoder provides contextual features. These are combined in the entity-aware decoder to create an interpretable video representation. Right: HENASY is supported by a suite of multi-grained contrastive learning to enforce both entity-level and video-level representations.
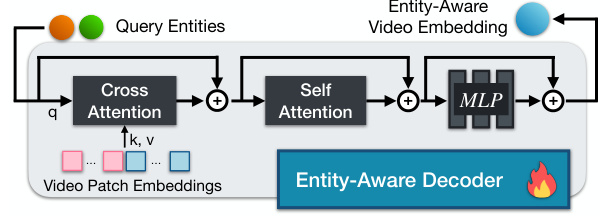
🔼 The entity-aware decoder takes entity-level features from the local entity encoder and video patch embeddings as input. It refines the interactions between entities and video patches through a series of cross-attention and self-attention blocks, followed by an MLP layer to produce the final entity-aware video embedding. The decoder aims to enrich the entity-centric video representation.
read the caption
Figure 3: Illustration of entity-aware decoder.

🔼 This figure presents a qualitative comparison of the proposed HENASY model and the HelpingHands model in terms of their visual grounding capabilities. The comparison focuses on two examples, each showing the model’s ability to generate visual saliency maps that highlight the relevant entities mentioned in a textual narration. The left example uses a noun phrase as the query, showing both methods’ ability to localize the object in the scene, but highlighting HENASY’s ability to better match the ground truth mask. The right example uses a verb phrase as the query, showcasing HENASY’s advantage in handling actions and dynamic events that HelpingHands fails to represent correctly. Overall, the figure demonstrates HENASY’s improved visual grounding quality and its capacity for nuanced interpretation of video content.
read the caption
Figure 4: Vision-Language Grounding. Qualitative comparisons with HelpingHands [4] on EgoCLIP [3]. Left: comparison with a noun query obtained from narration and the pseudo-groundtruth boxes detected by [33] for reference. Right: verb phrase in the narration is used for comparison, as verb phrase cannot be captured by [33], we do not include pseudo boxes.
More on tables
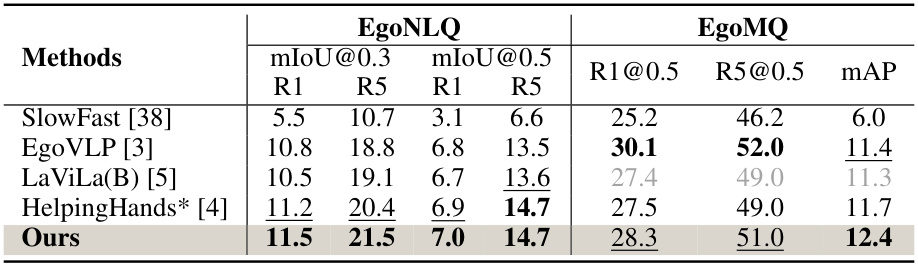
🔼 This table compares the performance of different methods on two egocentric video tasks: EgoNLQ (episodic memory task involving free-form text queries) and EgoMQ (episodic memory task that involves identifying and categorizing action instances). The metrics used for evaluation are mIoU (mean Intersection over Union) at thresholds of 0.3 and 0.5 for EgoNLQ and Recall@K (R1@0.5, R5@0.5) and mAP for EgoMQ. The results show that the proposed method (‘Ours’) achieves state-of-the-art performance on these benchmarks, surpassing previous approaches such as SlowFast, EgoVLP, LaViLa, and HelpingHands.
read the caption
Table 2: Comparison on the visual & textual representation over EgoNLQ and EgoMQ. Grey indicates result we obtained using provided pre-trained checkpoint that.
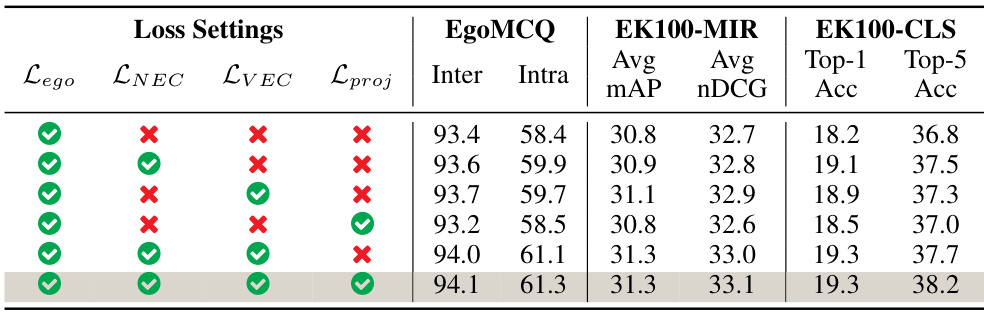
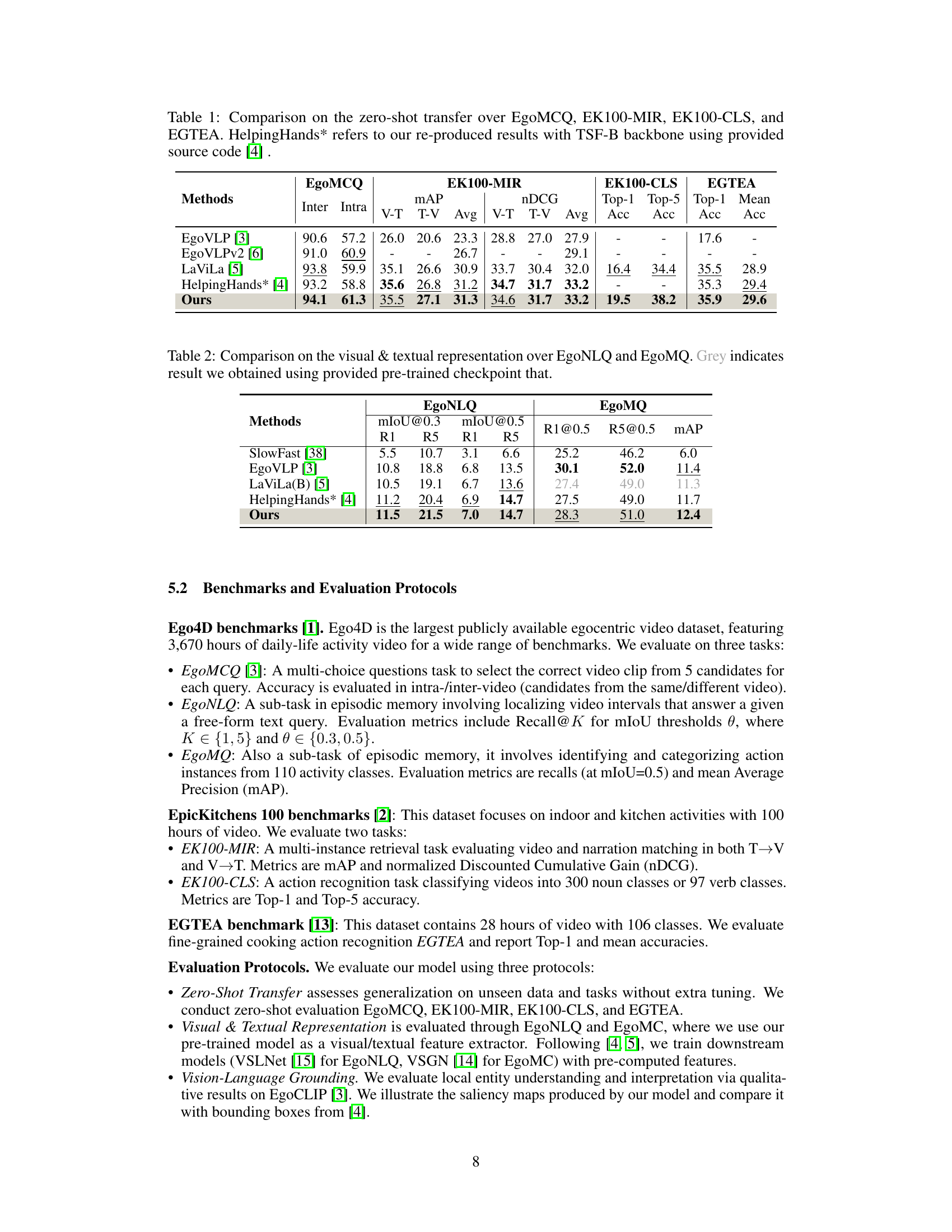
🔼 This table presents the ablation study results of the HENASY model, focusing on the impact of different loss functions. It shows the performance of the model on three different benchmark datasets (EgoMCQ, EK100-MIR, EK100-CLS) when trained with various combinations of four loss functions: Lego (egocentric contrastive loss), LNEC (noun-entity contrastive loss), LVEC (verb-entities contrastive loss), and Lproj (projection loss). Each row represents a different training configuration, indicated by checkmarks (✓) and crosses (✗) to show which losses were included. The results demonstrate the contribution of each loss component to the overall model performance.
read the caption
Table 3: Ablation results on multi-grained losses.
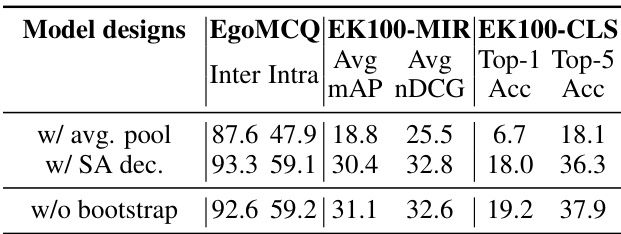
🔼 This table presents the ablation study results on the model design of HENASY. It shows the performance of the model on various tasks (EgoMCQ, EK100-MIR, and EK100-CLS) under different model design settings. Specifically, it compares the performance when using average pooling instead of an entity-aware decoder, when using only a self-attention decoder without the entity-aware decoder, and when removing the bootstrapping stage. The results demonstrate the impact of each component on the overall performance and the effectiveness of the proposed design choices.
read the caption
Table 4: Ablation results on model design.
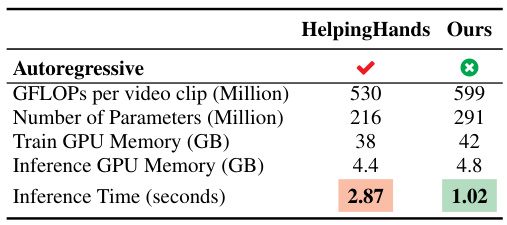
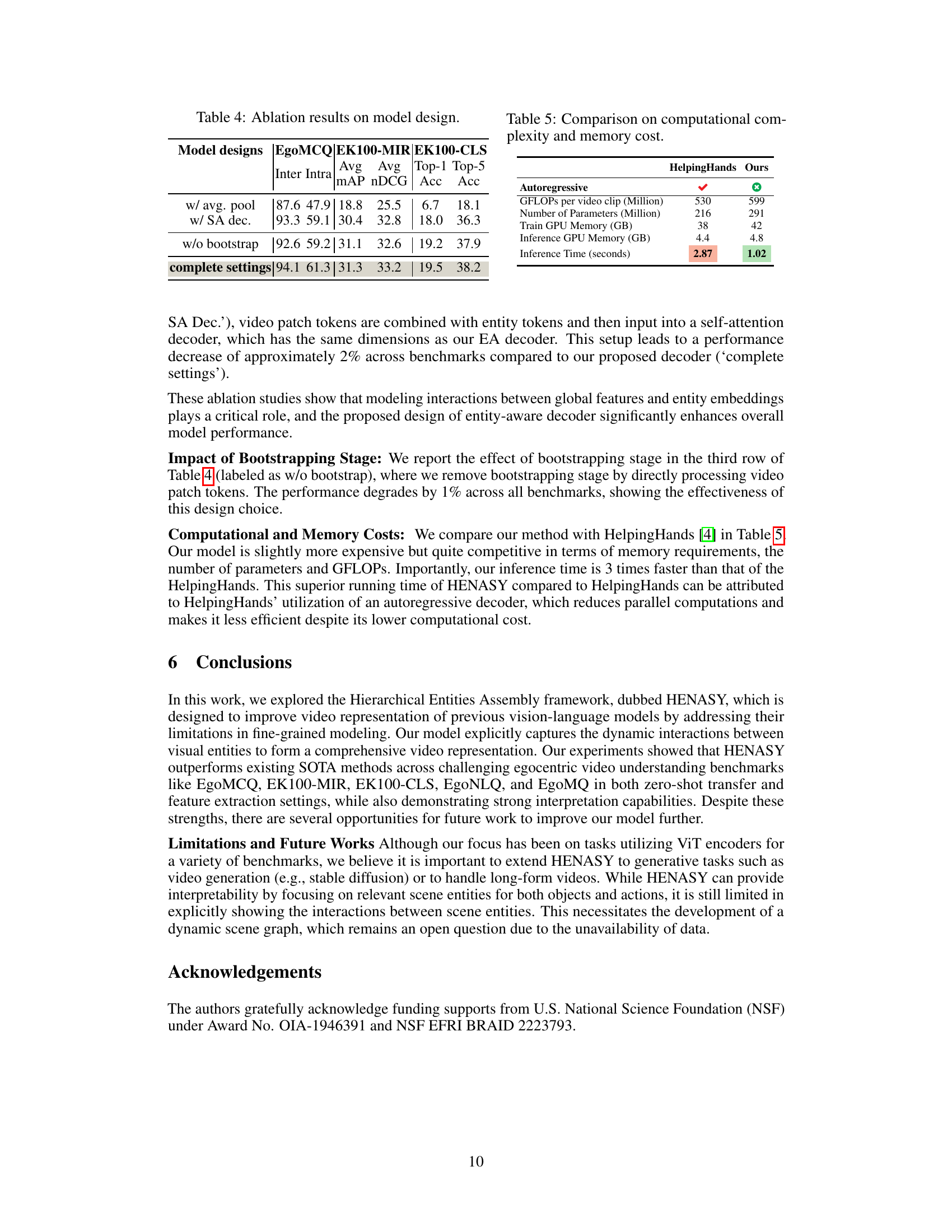
🔼 This table compares the computational complexity and memory costs of HENASY and HelpingHands. It shows that HENASY has a higher computational cost (GFLOPs) and uses more parameters and GPU memory during both training and inference. However, it achieves a significantly faster inference time (1.02 seconds vs. 2.87 seconds). The difference in inference time is primarily attributed to the different decoder architectures used by the two models; HENASY uses a non-autoregressive decoder while HelpingHands employs an autoregressive decoder, which inherently limits parallelization and increases computation time.
read the caption
Table 5: Comparison on computational complexity and memory cost.

🔼 This table compares the performance of the proposed HENASY model and the HelpingHands model on a visual grounding task. The metric used is mean Intersection over Union (mIoU), which measures the overlap between the predicted segmentation mask and the ground truth mask. The results show that HENASY significantly outperforms HelpingHands, indicating superior visual grounding capabilities.
read the caption
Table 6: Comparison with HelpingHands on visual grounding task.
Full paper#