TL;DR#
Creating realistic 3D avatars from a single image is challenging due to issues like loose clothing and occlusions. Existing methods either rely on simple shape priors or lack 3D consistency in multi-view generation. They often produce blurry textures and struggle with generalization to diverse shapes and textures.
Human-3Diffusion tackles these problems by introducing a novel framework that tightly couples 2D multi-view diffusion models with a generative 3D Gaussian Splatting reconstruction model. The 3D representation explicitly enforces consistency across multiple views, guiding the 2D reverse sampling process and resulting in high-fidelity avatars. Experiments show that this approach significantly outperforms existing methods in both geometry and appearance.
Key Takeaways#
Why does it matter?#
This paper is important because it presents Human-3Diffusion, a novel framework that significantly improves the creation of realistic 3D avatars from a single image. It addresses the limitations of existing methods by introducing explicit 3D consistency in the avatar generation process. This work will be highly relevant to researchers in computer vision, computer graphics, and related fields, opening new possibilities in areas like virtual and augmented reality, gaming, and digital entertainment. The proposed method achieves state-of-the-art results and offers valuable insights into leveraging 2D and 3D diffusion models for effective 3D avatar creation.
Visual Insights#

🔼 This figure demonstrates the capability of the Human-3Diffusion model to generate realistic 3D avatars from a single input image. The top row shows a single input image of a person in various poses and clothing. The bottom rows display multiple views of the generated 3D avatar, highlighting the model’s ability to accurately reconstruct fine details like clothing and interacting objects, while maintaining high-fidelity geometry and texture. The 3D avatars are represented as 3D Gaussian Splats.
read the caption
Figure 1: Given a single image of a person (top), our method Human-3Diffusion creates 3D Gaussian Splats of realistic avatars with cloth and interacting objects with high-fidelity geometry and texture.
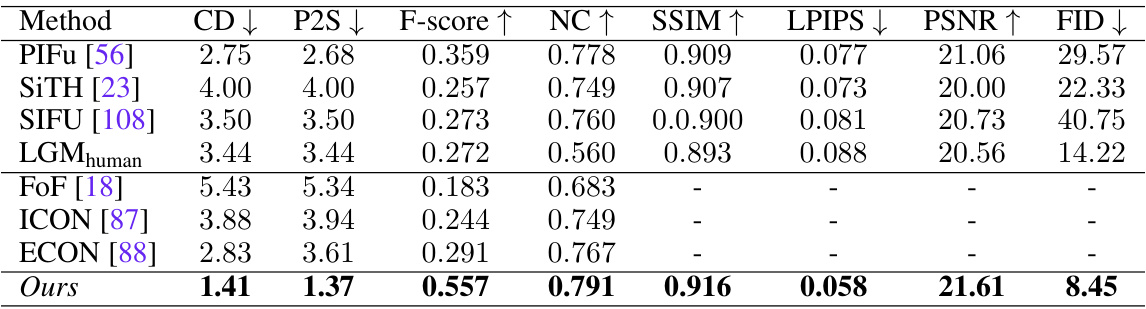
🔼 This table presents a quantitative comparison of the proposed method against several state-of-the-art techniques for human avatar reconstruction. Metrics evaluate both geometry quality (using Chamfer Distance, Point-to-Surface Distance, F-score, and Normal Consistency) and appearance quality (using Multi-scale Structural Similarity, Learned Perceptual Image Patch Similarity, Peak Signal-to-Noise Ratio, and Fréchet Inception Distance). The results show that the proposed method achieves superior performance in both geometry and texture realism.
read the caption
Table 1: Quantitative evaluation on CAPE [47], SIZER [72], and IIIT [32] dataset. Our method can perform better reconstruction in terms of more accurate geometry (CD, P2S, F-score, NC) and realistic textures (SSIM, LPIPS, PSNR, FID).
In-depth insights#
3D Diffusion Avatar#
The concept of “3D Diffusion Avatar” blends the power of 3D modeling with the generative capabilities of diffusion models. It signifies a paradigm shift in avatar creation, moving beyond simple 2D image manipulation to generate truly three-dimensional, photorealistic avatars. This approach leverages the strengths of diffusion models, such as their ability to capture intricate details and textures from vast datasets, to create highly realistic 3D representations. The key challenge lies in ensuring 3D consistency across multiple viewpoints, a problem traditionally tackled by explicit 3D modeling techniques. Diffusion-based methods, however, offer a potential solution by directly generating multi-view consistent data, thereby eliminating the need for complex post-processing steps. The fusion of 3D shape priors with 2D diffusion models offers another crucial advancement. Incorporating pre-trained models trained on large 2D datasets can significantly enhance the generation process by providing strong shape and texture priors. The explicit 3D representation is essential for enabling various downstream applications, such as AR/VR experiences or interactive simulations, where a realistic and consistent 3D model is necessary. Overall, this integration represents a significant stride towards more efficient, accurate and versatile avatar creation, opening new possibilities in numerous fields.
Multi-view Consistency#
Achieving multi-view consistency is crucial for realistic 3D avatar generation from a single image. The challenge lies in ensuring that different views of the generated avatar are coherent and consistent, reflecting a true 3D structure rather than a collection of independent 2D images. This requires careful consideration of both the 2D image priors used to guide the generation process and the explicit 3D representation employed to enforce consistency. Methods that rely solely on 2D diffusion models often struggle with 3D consistency, leading to artifacts and inconsistencies across views. In contrast, incorporating explicit 3D representations into the generation pipeline, like using Gaussian Splats, offers a more direct path towards guaranteeing multi-view consistency. However, this approach may require carefully designed strategies for effectively coupling 2D and 3D models, to leverage the strengths of each. Furthermore, achieving consistency in challenging scenarios, such as those involving loose clothing or significant occlusions, remains an important challenge requiring robust shape priors and refinement techniques. The ultimate goal is to generate high-fidelity 3D avatars with photorealistic details and seamless transitions between views.
2D Prior Leverage#
Leveraging 2D priors significantly enhances the realism and efficiency of 3D avatar generation. 2D diffusion models, pre-trained on massive datasets, provide powerful shape priors that capture intricate details and diverse clothing styles often missing in smaller 3D training sets. By incorporating these 2D priors into the 3D generation process, the model gains access to a vast wealth of shape knowledge, enabling it to accurately reconstruct complex geometries. This is particularly valuable for areas occluded in the input image, where 2D priors can help guide the 3D reconstruction toward plausible solutions. The fusion of 2D and 3D information avoids the limitations of purely 3D approaches, which frequently struggle with generalization and high-fidelity representation. The tight coupling of the 2D and 3D models, with consistent refinement of sampling trajectories, ensures that the resulting 3D avatars are highly realistic and geometrically accurate across multiple views. This synergistic approach thus unlocks the potential of large-scale 2D data for high-quality 3D avatar generation.
3D-GS Generation#
The heading ‘3D-GS Generation’ likely refers to a section detailing the creation of three-dimensional Gaussian Splat (3D-GS) representations of human avatars. This process is crucial as 3D-GS offers an efficient and explicit 3D representation, unlike implicit methods that lack precise geometric control. The generation method probably leverages a novel image-conditioned generative model, using the power of pretrained 2D multi-view diffusion models as shape priors. This fusion of 2D and 3D models is key: 2D diffusion provides strong generalization from large datasets, while the explicit 3D-GS structure ensures 3D consistency during sampling. The 3D model likely takes noisy multi-view images and a context image as input, learning to reconstruct consistent 3D-GS representations. Training likely involves a diffusion-based approach, iteratively refining the 3D-GS parameters to match the provided images. This likely involves a loss function that combines image reconstruction loss (e.g., MSE) with a regularization term for 3D consistency. The architecture is likely a neural network (possibly a U-Net based model) conditioned on the input images and diffusion timestep. The output is then a set of Gaussian splats, which forms the basis for generating realistic and detailed human avatars. The effectiveness of this 3D-GS approach is essential for downstream tasks, ensuring consistency in rendering from different viewpoints. The detailed description within this section would likely include the model’s architecture, loss functions, training procedure, and experimental results showing the quality of generated 3D-GS models.
Future Works#
The paper’s lack of a dedicated ‘Future Works’ section is a missed opportunity. However, based on the limitations and challenges addressed, several promising avenues for future research emerge. Improving the resolution of texture details by incorporating higher-resolution multi-view diffusion models is crucial. Addressing the limitations of current 2D diffusion models would significantly enhance 3D reconstruction quality. Expanding the dataset to include a wider variety of poses, clothing styles, and human-object interactions would improve the robustness and generalization capabilities of the model. Exploring more advanced 3D representations beyond Gaussian Splats could further enhance fidelity and realism. Finally, investigating methods to improve the efficiency of the 3D generation process is crucial for practical applications. Addressing these points would make the approach even more versatile and reliable, pushing the boundaries of realistic avatar creation.
More visual insights#
More on figures

🔼 This figure illustrates the method overview of Human-3Diffusion. Starting with a single RGB image as input, the model generates a realistic 3D avatar. The process involves leveraging 2D multi-view diffusion models for shape priors, while simultaneously refining the 2D reverse sampling trajectory using generated 3D renderings to ensure 3D consistency. This tight coupling between 2D and 3D models results in a high-quality 3D avatar representation.
read the caption
Figure 2: Method Overview. Given a single RGB image (A), we sample a realistic 3D avatar represented as 3D Gaussian Splats (D). At each reverse step, our 3D generation model gø leverages 2D multi-view diffusion prior from ee which provides a strong shape prior but is not 3D consistent (B, cf. Sec. 4.1). We then refine the 2D reverse sampling trajectory with generated 3D renderings that are guaranteed to be 3D consistent (C, cf. Sec. 4.2). Our tight coupling ensures 3D consistency at each sampling step and obtains a high-quality 3D avatar (D).

🔼 This figure provides a visual overview of the Human-3Diffusion method. It shows how a single RGB image is used as input to generate a realistic 3D avatar represented as 3D Gaussian Splats. The process involves leveraging 2D multi-view diffusion priors for shape information, refining the 2D reverse sampling trajectory with 3D-consistent renderings, and ensuring 3D consistency at each sampling step.
read the caption
Figure 2: Method Overview. Given a single RGB image (A), we sample a realistic 3D avatar represented as 3D Gaussian Splats (D). At each reverse step, our 3D generation model gø leverages 2D multi-view diffusion prior from ee which provides a strong shape prior but is not 3D consistent (B, cf. Sec. 4.1). We then refine the 2D reverse sampling trajectory with generated 3D renderings that are guaranteed to be 3D consistent (C, cf. Sec. 4.2). Our tight coupling ensures 3D consistency at each sampling step and obtains a high-quality 3D avatar (D).

🔼 This figure compares the results of the proposed Human-3Diffusion method to several state-of-the-art avatar reconstruction methods (ICON, ECON, SiTH, and SIFU). The comparison highlights the ability of Human-3Diffusion to generate realistic avatars with coherent clothing and textures, even in areas occluded in the input image, unlike the other methods that struggle with loose clothing or produce blurry textures.
read the caption
Figure 3: Qualitative comparison with baselines. Recent avatar reconstruction works ICON [87], ECON [88], SiTH [23] and SIFU [108]) cannot reconstruct loose clothing coherently. Additionally, SITH and SIFU generate blurry texture in unseen regions due to their deterministic formulation of regressing 3D avatar directly from single RGB imagse. In contract, our method is able to reconstruct avatars with realistic textures and plausible 3D geometry in both seen and unseen region.

🔼 This figure compares 3D reconstruction results obtained using different methods. The input is a single RGB image of a person. The ‘Ours’ column shows the results produced by the proposed Human-3Diffusion method, which uses an explicit 3D representation to ensure 3D consistency across multiple views. In contrast, the ‘MVD’ and ‘MVDft’ columns show the results of using only a 2D multi-view diffusion model without the explicit 3D representation. The comparison highlights the superior performance of the proposed Human-3Diffusion in generating 3D consistent multi-views and avoiding artifacts.
read the caption
Figure 4: 3D reconstruction conditioned on different multi-view priors. Without our 3D-consistent sampling, the 2D diffusion model cannot generate 3D consistent multi-views (MVD, MVDft), leading to artifacts like floating 3D Gaussians splats.

🔼 This figure shows an ablation study demonstrating the benefit of using 2D multi-view priors in the 3D generation process. The leftmost image is the input image of a stuffed rabbit. The middle section shows the results of the model when using the proposed method (with 2D multi-view priors), showcasing a relatively complete and consistent 3D reconstruction from various viewpoints. The rightmost section shows the results obtained using a ‘pure 3D generative model without 2D priors’, highlighting the significant improvement achieved through the integration of 2D information in improving the quality and consistency of 3D generation for unseen objects.
read the caption
Figure 5: 2D multi-view priors x enhances generalization to general objects in GSO [17] dataset.

🔼 This figure provides a visual overview of the Human-3Diffusion method. It shows how a single RGB image is used as input to generate a realistic 3D avatar. The process involves leveraging 2D multi-view diffusion models for shape priors, refining the 2D reverse sampling trajectory with 3D-consistent renderings, and ultimately producing a high-quality 3D avatar represented as 3D Gaussian Splats.
read the caption
Figure 2: Method Overview. Given a single RGB image (A), we sample a realistic 3D avatar represented as 3D Gaussian Splats (D). At each reverse step, our 3D generation model gø leverages 2D multi-view diffusion prior from ee which provides a strong shape prior but is not 3D consistent (B, cf. Sec. 4.1). We then refine the 2D reverse sampling trajectory with generated 3D renderings that are guaranteed to be 3D consistent (C, cf. Sec. 4.2). Our tight coupling ensures 3D consistency at each sampling step and obtains a high-quality 3D avatar (D).

🔼 This figure visualizes the intermediate sampling steps during the reverse diffusion process. It shows how the model refines its estimates at each step, transitioning from noisy input to a clear, consistent output. The comparison highlights the benefits of using the 3D reconstruction model to correct inconsistencies introduced by the 2D diffusion model alone, showing improved clarity and consistency in the final output.
read the caption
Figure 7: Visualization of intermediate sampling steps from a Gaussian Noise (t = 1000) to the last denoising step (t = 0). From top to bottom: current state xt, estimated clear view by 2D diffusion models xt, and corrected clear view by generated 3D Gaussian Splatting. Our 2D diffusion model eθ(0) already provides strong multi-view prior at an early stage with large t. Our 3D reconstruction model gθ(0) can correct the inconsistency in xtgt illustrated in red circle.

🔼 This figure presents a qualitative comparison of the proposed Human-3Diffusion method with several state-of-the-art avatar reconstruction methods on the Sizer and IIIT datasets. The results show that Human-3Diffusion outperforms competing methods, especially in terms of reconstructing clothing and accessories accurately, with higher fidelity in geometry and appearance. The comparison highlights the superiority of the Human-3diffusion model in handling loose and complex clothing.
read the caption
Figure 8: Qualitative comparison on Sizer [72] and IIIT [32].

🔼 This figure presents a qualitative comparison of different methods for human avatar reconstruction on the Sizer and IIIT datasets. The ‘Input’ column shows the original images used. The remaining columns show the results generated by various techniques, including the authors’ proposed method, labeled as ‘Ours.’ The comparison highlights the differences in the quality of the generated avatars with respect to geometry, clothing details, and overall realism.
read the caption
Figure 8: Qualitative comparison on Sizer [72] and IIIT [32].

🔼 This figure shows several examples of avatar reconstruction results from single images. The left column shows the input images, and the right column displays the reconstructed avatars produced by the Human-3Diffusion model. Each row demonstrates the reconstruction of a person wearing clothing that exhibits varying degrees of looseness. The figure highlights the ability of the model to handle the challenges of loose clothing in 3D avatar reconstruction.
read the caption
Figure 10: Qualitative results on unseen data during training. Input image is in left column. Our method successfully reconstructs different degree of loose clothing.

🔼 This figure compares the qualitative results of the proposed method with several state-of-the-art avatar reconstruction methods. It highlights the superior ability of the proposed method to reconstruct avatars with loose clothing and realistic textures, compared to the other methods which struggle with coherent reconstruction of loose clothing and generate blurry textures in unseen regions due to their deterministic nature.
read the caption
Figure 3: Qualitative comparison with baselines. Recent avatar reconstruction works ICON [87], ECON [88], SiTH [23] and SIFU [108]) cannot reconstruct loose clothing coherently. Additionally, SITH and SIFU generate blurry texture in unseen regions due to their deterministic formulation of regressing 3D avatar directly from single RGB imagse. In contract, our method is able to reconstruct avatars with realistic textures and plausible 3D geometry in both seen and unseen region.

🔼 This figure shows the results of the Human-3Diffusion method. Given a single image of a person as input (top row), the method generates a 3D model of the person represented as 3D Gaussian Splats. The generated models accurately capture details like clothing, interacting objects, and the overall geometry and texture of the person.
read the caption
Figure 1: Given a single image of a person (top), our method Human-3Diffusion creates 3D Gaussian Splats of realistic avatars with cloth and interacting objects with high-fidelity geometry and texture.

🔼 This figure compares the results of the proposed method with several state-of-the-art avatar reconstruction methods. It highlights the superior performance of the proposed method in reconstructing avatars with realistic textures and geometry, especially for loose clothing and occluded regions.
read the caption
Figure 3: Qualitative comparison with baselines. Recent avatar reconstruction works ICON [87], ECON [88], SiTH [23] and SIFU [108]) cannot reconstruct loose clothing coherently. Additionally, SITH and SIFU generate blurry texture in unseen regions due to their deterministic formulation of regressing 3D avatar directly from single RGB imagse. In contract, our method is able to reconstruct avatars with realistic textures and plausible 3D geometry in both seen and unseen region.

🔼 This figure shows qualitative results of the proposed Human-3Diffusion model on the UBC fashion dataset [101]. The input images are the first frame extracted from each video in this dataset. The results demonstrate that the model generalizes well to real-world images, achieving high fidelity in both geometry and appearance.
read the caption
Figure 14: Qualitative results on UBC fashion [101] dataset. Results demonstrate that our model generalizes well to real world images in both geometry and appearance.

🔼 This figure shows the overall pipeline of Human-3Diffusion. Starting from a single RGB image, the model generates a realistic 3D avatar represented by 3D Gaussian Splats. The process involves leveraging 2D multi-view diffusion priors for shape information while simultaneously refining the 2D reverse sampling trajectory using the generated 3D renderings to ensure 3D consistency. The tight coupling between 2D and 3D models is crucial for achieving high-fidelity results.
read the caption
Figure 2: Method Overview. Given a single RGB image (A), we sample a realistic 3D avatar represented as 3D Gaussian Splats (D). At each reverse step, our 3D generation model gø leverages 2D multi-view diffusion prior from ee which provides a strong shape prior but is not 3D consistent (B, cf. Sec. 4.1). We then refine the 2D reverse sampling trajectory with generated 3D renderings that are guaranteed to be 3D consistent (C, cf. Sec. 4.2). Our tight coupling ensures 3D consistency at each sampling step and obtains a high-quality 3D avatar (D).

🔼 This figure compares the qualitative results of the proposed Human-3Diffusion model against several state-of-the-art avatar reconstruction methods (ICON, ECON, SiTH, SIFU). The comparison highlights the superior ability of Human-3Diffusion to reconstruct avatars with realistic textures and 3D geometry, especially in handling loose clothing and occluded regions where other methods produce blurry textures or incomplete geometry.
read the caption
Figure 3: Qualitative comparison with baselines. Recent avatar reconstruction works ICON [87], ECON [88], SiTH [23] and SIFU [108]) cannot reconstruct loose clothing coherently. Additionally, SITH and SIFU generate blurry texture in unseen regions due to their deterministic formulation of regressing 3D avatar directly from single RGB imagse. In contract, our method is able to reconstruct avatars with realistic textures and plausible 3D geometry in both seen and unseen region.

🔼 This figure compares the qualitative results of the proposed method against other state-of-the-art avatar reconstruction methods. The comparison highlights the superior performance of the proposed method in handling loose clothing and generating realistic textures, even in unseen regions. The figure visually demonstrates that existing methods struggle to reconstruct loose clothing coherently and produce blurry textures, unlike the proposed method.
read the caption
Figure 3: Qualitative comparison with baselines. Recent avatar reconstruction works ICON [87], ECON [88], SiTH [23] and SIFU [108]) cannot reconstruct loose clothing coherently. Additionally, SITH and SIFU generate blurry texture in unseen regions due to their deterministic formulation of regressing 3D avatar directly from single RGB imagse. In contract, our method is able to reconstruct avatars with realistic textures and plausible 3D geometry in both seen and unseen region.
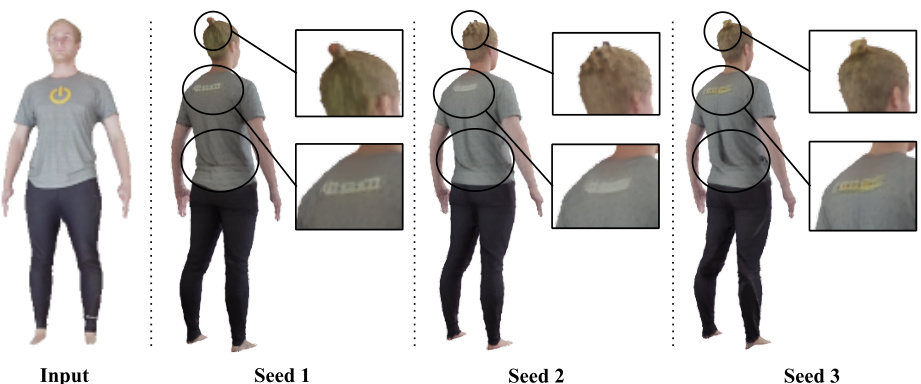
🔼 This figure shows the generative power of the proposed model. By sampling from the learned 3D distribution with different random seeds, the model generates diverse yet plausible 3D representations, particularly in the self-occluded regions (the back of the subject). The differences are noticeable in the hair style, texture, and cloth wrinkles. This is a key advantage over non-generative methods which tend to produce blurry or less detailed results in self-occluded areas.
read the caption
Figure 18: Our model learns 3D distribution. By different sampling from the learned distribution, we obtain diverse yet plausible 3D representations. The generative power is a key to generate clear self-occluded region, which is impossible in non-generative reconstruction approaches [56, 57, 74, 108].

🔼 This figure shows example scans from the training datasets used in the Human-3Diffusion model. The datasets include AXYZ, Custom Human, THuman 2.0, THuman 3.0, and Commercial datasets, each contributing a variety of body types, clothing styles, poses, and accessories. This diversity is crucial for training a robust and generalizable model that can handle a wide range of human appearances and situations.
read the caption
Figure 19: Example scans in training datasets [1–4, 21, 27, 65, 98].

🔼 This figure shows the results of the Human-3Diffusion method. Given a single image of a person as input, the method generates a realistic 3D model of the person, including detailed clothing and any interacting objects. The 3D model is represented using Gaussian Splats, a technique that allows for efficient rendering and manipulation of complex 3D shapes. The figure highlights the high fidelity of the generated model in terms of both geometry and texture.
read the caption
Figure 1: Given a single image of a person (top), our method Human-3Diffusion creates 3D Gaussian Splats of realistic avatars with cloth and interacting objects with high-fidelity geometry and texture.

🔼 This figure shows the result of the Human-3Diffusion method. Given a single image of a person as input (shown at the top), the method generates a realistic 3D model of the person, represented as a collection of 3D Gaussian Splats. The generated models accurately capture details such as clothing, and interactions with objects, showcasing high-fidelity geometry and texture. The multiple views presented demonstrate the 3D consistency achieved by the method.
read the caption
Figure 1: Given a single image of a person (top), our method Human-3Diffusion creates 3D Gaussian Splats of realistic avatars with cloth and interacting objects with high-fidelity geometry and texture.
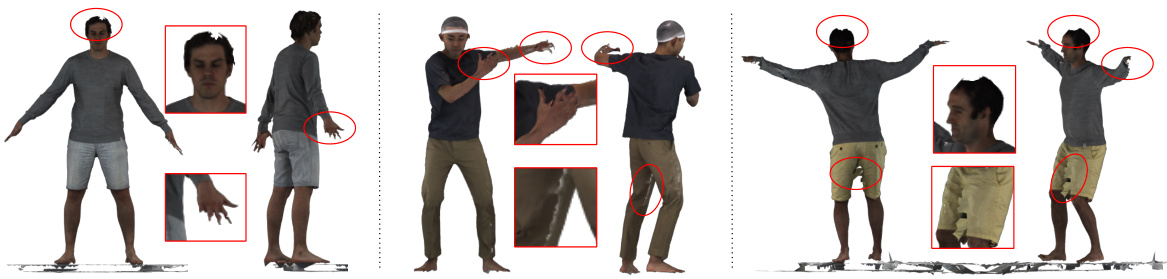
🔼 This figure compares the results of the proposed Human-3Diffusion method with other state-of-the-art avatar reconstruction methods (ICON, ECON, SiTH, and SIFU). It highlights that the proposed method is superior in reconstructing loose clothing and producing realistic textures, particularly in areas occluded in the input image. The comparison demonstrates the advantages of using an explicit 3D consistent diffusion model.
read the caption
Figure 3: Qualitative comparison with baselines. Recent avatar reconstruction works ICON [87], ECON [88], SiTH [23] and SIFU [108]) cannot reconstruct loose clothing coherently. Additionally, SITH and SIFU generate blurry texture in unseen regions due to their deterministic formulation of regressing 3D avatar directly from single RGB imagse. In contract, our method is able to reconstruct avatars with realistic textures and plausible 3D geometry in both seen and unseen region.

🔼 This figure shows a failure case of the Human-3Diffusion model. The model is unable to reconstruct the numbers on the running shirt of the person in the image, indicating a limitation in reconstructing fine details, especially text, potentially due to the resolution limitations of the multi-view diffusion model used.
read the caption
Figure 23: Failure Case: our model cannot reconstruct the numbers on the cloth.

🔼 This figure shows a failure case of the Human-3Diffusion model. The input image shows a person performing a challenging pose (a handstand). The model’s reconstruction of the person’s pose is inaccurate and blurry, especially in the head and upper body regions. The highlighted area in the reconstructed images indicates the region of notable inaccuracy.
read the caption
Figure 24: Failure Case: our model fails in infer appearance of human with challenging pose.
More on tables
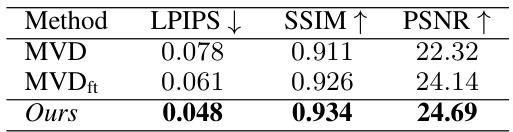
🔼 This table presents the results of an ablation study that evaluates the impact of trajectory refinement on the quality of multi-view images generated by a 2D multi-view diffusion model. The study compares three different methods: 1. MVD: A pretrained 2D multi-view diffusion model. 2. MVDft: A fine-tuned 2D multi-view diffusion model. 3. Ours: The proposed method, which incorporates 3D-consistent sampling to refine the sampling trajectory. The table shows that the proposed method significantly improves the quality of the generated multi-view images, as measured by LPIPS (lower is better), SSIM (higher is better), and PSNR (higher is better).
read the caption
Table 2: Evaluating trajectory refinement for 2D multi-view diffusion. Our proposed refinement improves multi-view image quality.

🔼 This table presents an ablation study on the impact of trajectory refinement in 2D multi-view diffusion on image quality. It compares three methods: the original Multi-View Diffusion (MVD), MVD fine-tuned on the authors’ dataset (MVDft), and MVD with the proposed 3D consistent sampling trajectory refinement. The results show that the proposed refinement significantly improves multi-view image quality in terms of LPIPS (lower is better), SSIM (higher is better), and PSNR (higher is better), demonstrating the effectiveness of the proposed trajectory refinement technique.
read the caption
Table 2: Evaluating trajectory refinement for 2D multi-view diffusion. Our proposed refinement improves multi-view image quality.

🔼 This table presents the results of an ablation study that evaluates the impact of trajectory refinement on the quality of generated multi-view images. The study compares three methods: (1) MVD (Multi-View Diffusion), (2) MVDft (fine-tuned MVD on the authors’ data), and (3) the authors’ proposed method, which incorporates 3D consistent sampling to refine the 2D sampling trajectory. The results are assessed using three metrics: LPIPS (lower is better), SSIM (higher is better), and PSNR (higher is better), reflecting the improvements in image quality achieved by trajectory refinement. The table shows that the authors’ method significantly improves the quality of the generated multi-view images compared to the other two methods.
read the caption
Table 2: Evaluating trajectory refinement for 2D multi-view diffusion. Our proposed refinement improves multi-view image quality.

🔼 The table presents the PSNR values for the 3D reconstruction model with and without the 2D multi-view prior. The results show that incorporating the 2D multi-view prior significantly improves the PSNR, indicating that the prior is crucial for better performance.
read the caption
Table 4: 2D multi-view priors improves 3D generative model gø. Therefore, we evaluate the overall quality improve human reconstruction quality.

🔼 This table presents a quantitative comparison of the proposed method against several state-of-the-art image-to-avatar reconstruction methods. The metrics used evaluate both the geometry (accuracy of 3D shape) and appearance (quality of textures) of the generated avatars. The results demonstrate that the proposed method outperforms existing techniques in both geometry and appearance.
read the caption
Table 1: Quantitative evaluation on CAPE [47], SIZER [72], and IIIT [32] dataset. Our method can perform better reconstruction in terms of more accurate geometry (CD, P2S, F-score, NC) and realistic textures (SSIM, LPIPS, PSNR, FID).
Full paper#



















