TL;DR#
Streaming free-viewpoint videos (FVV) is challenging due to high data requirements and real-time constraints. Existing methods struggle to balance quality, speed, and efficiency for online transmission. They often impose structural constraints or rely on offline training, limiting their effectiveness for dynamic scenes.
The proposed QUEEN framework tackles these issues. It uses 3D Gaussian splatting to represent dynamic scenes and learns Gaussian attribute residuals between frames. A novel quantization-sparsity method efficiently compresses these residuals, significantly reducing storage and bandwidth needs. The use of viewspace gradient differences speeds up training and improves sparsity learning. Extensive experimental results demonstrate QUEEN’s superior performance compared to the state-of-the-art on various metrics, especially for dynamic scenes.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers working on free-viewpoint video (FVV) streaming. It addresses the critical need for efficient online FVV encoding, pushing the boundaries of real-time performance and low-bandwidth transmission. The novel QUEEN framework significantly advances the state-of-the-art by achieving high compression ratios with improved quality and speed, which can greatly impact various applications such as immersive teleconferencing and live volumetric broadcasts. The proposed quantization-sparsity learning method and use of viewspace gradient difference are key innovations with broad applicability beyond FVV. This work opens new avenues of research in efficient online video compression and scene representation.
Visual Insights#

🔼 The figure illustrates the QUEEN framework for online free-viewpoint video (FVV) streaming. It shows how Gaussian attributes are updated incrementally at each time step by learning and compressing residuals between frames. A quantization-sparsity framework is employed to efficiently compress these residuals. Only dynamic Gaussians are rendered, which speeds up the training process. The different colored blocks in the diagram highlight the different stages of the process.
read the caption
Figure 1: Overview of QUEEN for online FVV. We incrementally update Gaussian attributes at each time-step (gray block) by simultaneously learning and compressing residuals between consecutive time-steps via a quantization (orange block) and sparsity (yellow block) framework. We additionally render only the dynamic Gaussians for masked regions to achieve faster convergence (green block).
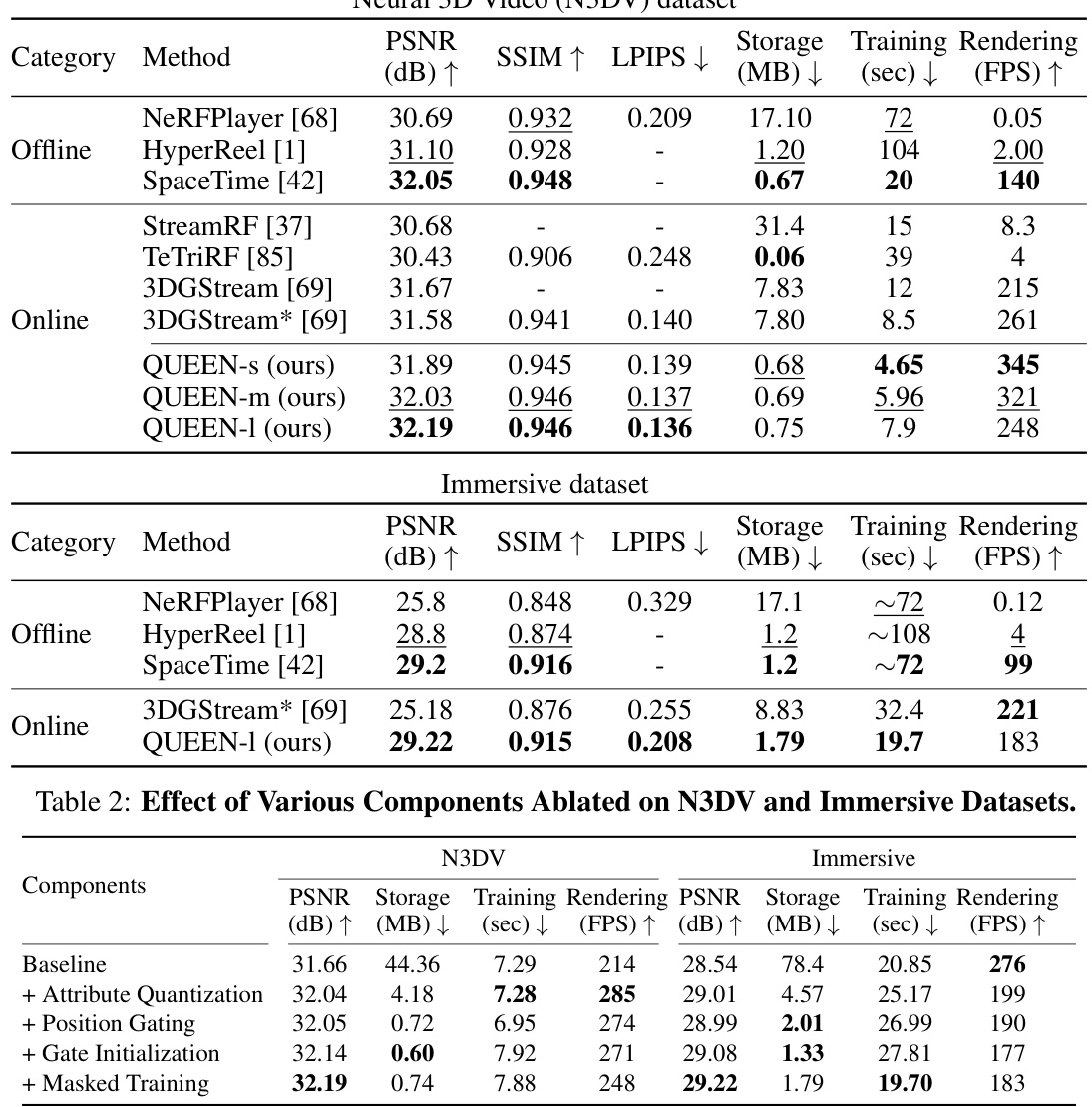
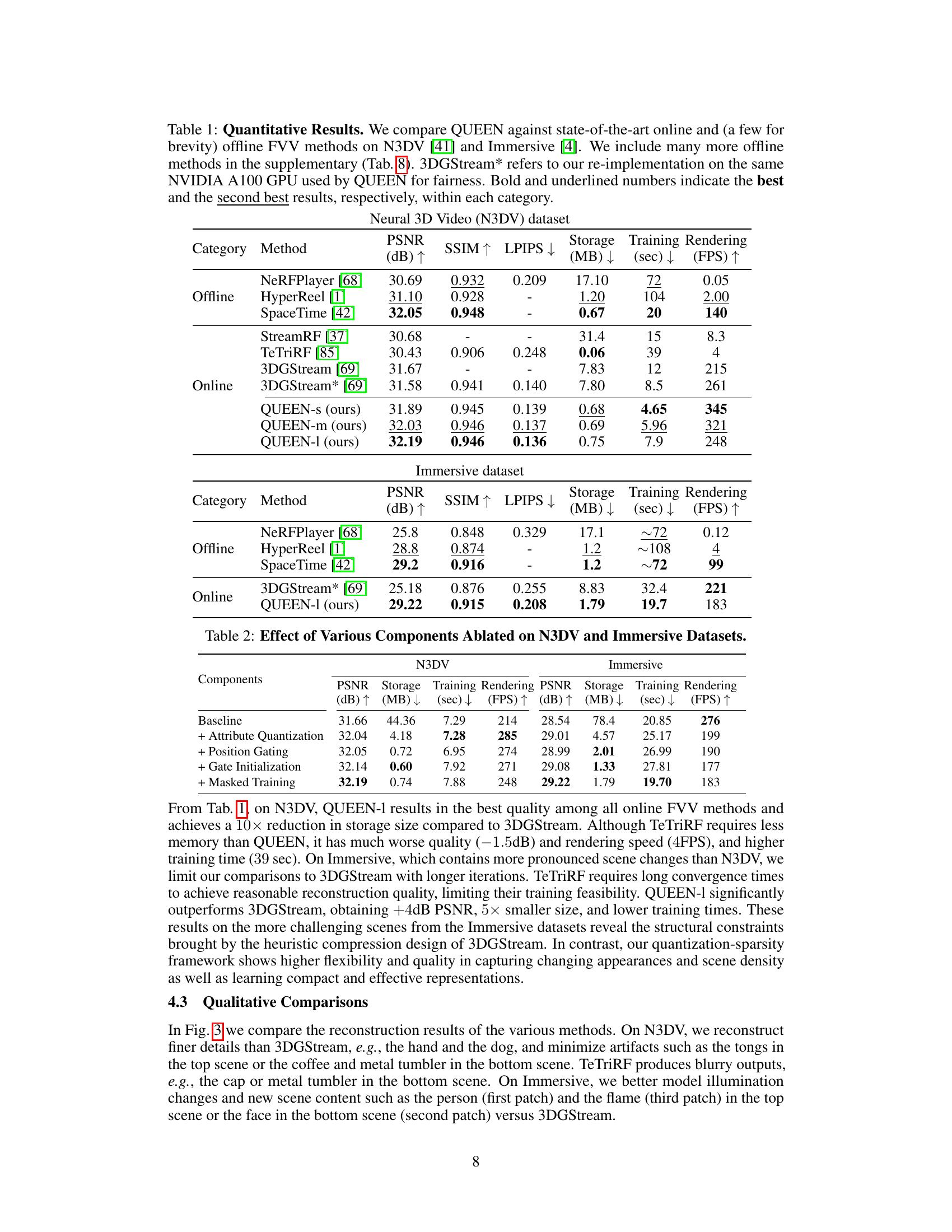
🔼 This table presents a quantitative comparison of QUEEN against several state-of-the-art online and offline free-viewpoint video (FVV) methods on two benchmark datasets: N3DV and Immersive. The comparison includes metrics such as PSNR, SSIM, LPIPS, storage size, training time, and rendering speed (FPS). The results highlight QUEEN’s superior performance in terms of reconstruction quality, memory efficiency, and speed.
read the caption
Table 1: Quantitative Results. We compare QUEEN against state-of-the-art online and (a few for brevity) offline FVV methods on N3DV [41] and Immersive [4]. We include many more offline methods in the supplementary (Tab. 8). 3DGStream* refers to our re-implementation on the same NVIDIA A100 GPU used by QUEEN for fairness. Bold and underlined numbers indicate the best and the second best results, respectively, within each category.
In-depth insights#
Online FVV Encoding#
Online free-viewpoint video (FVV) encoding presents a unique set of challenges. Real-time constraints necessitate efficient encoding and decoding methods, demanding fast training and rendering. Unlike offline methods, online encoding must handle incremental updates to the volumetric representation of the scene as new frames arrive. This requires efficient memory management to avoid excessive resource consumption. A key aspect is the ability to effectively compress the video data while maintaining high reconstruction quality. Sparsity and quantization techniques are often employed to achieve compression, potentially involving intelligent identification and coding of dynamic and static regions within the scene. The effectiveness of an online FVV encoding approach is measured by its ability to maintain high quality at low latency, with compact representation sizes suitable for transmission across bandwidth-constrained networks.
3D Gaussian Splatting#
3D Gaussian splatting is a novel neural rendering technique that leverages the power of Gaussian functions to represent 3D scenes. Unlike traditional voxel-based methods or neural radiance fields, which can be computationally expensive, 3D Gaussian splatting offers a more efficient and scalable approach. Key advantages include its ability to handle complex scenes efficiently and its speed in both training and rendering. By representing the scene as a collection of 3D Gaussian functions, it achieves a compact and high-fidelity representation that can be rendered quickly. This makes it particularly well-suited for applications such as free-viewpoint video streaming, where real-time performance is crucial. The method also demonstrates impressive generalizability, providing high-quality reconstructions for diverse scenes with high dynamic range and detailed geometries. Furthermore, the learned nature of 3D Gaussian splatting allows it to adapt to new scenes or data efficiently, which is particularly useful for online or dynamic scenarios. However, a potential limitation could be its sensitivity to quantization, which may require careful strategies to avoid quality degradation, particularly for highly dynamic scenes.
Quantization-Sparsity#
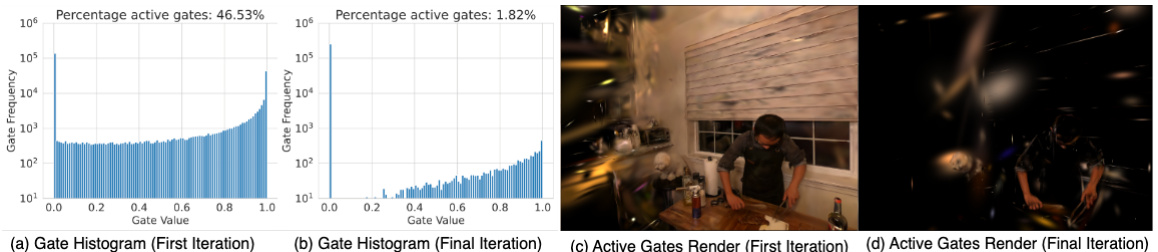
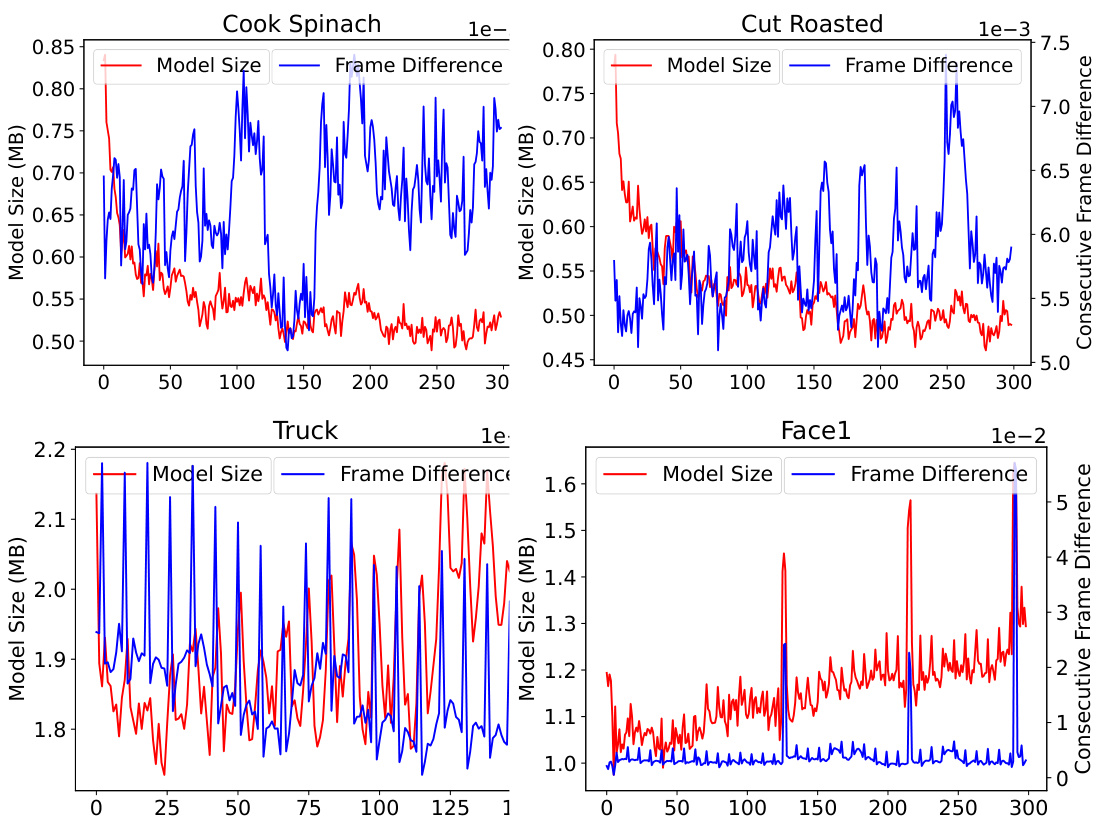
The concept of “Quantization-Sparsity” in the context of efficient neural representation for streaming free-viewpoint videos is a powerful technique to address the challenges of memory consumption and computational cost. Quantization reduces the precision of numerical values, thus lowering storage requirements. Sparsity, on the other hand, aims to eliminate or reduce the number of non-zero elements. Combining these two techniques, as proposed, offers a synergistic approach. By intelligently identifying and quantizing less-significant attributes and sparsifying the most influential ones, the method aims for high compression rates without sacrificing reconstruction quality. The effectiveness of this approach hinges on accurately identifying the less-important elements, possibly through a learned gating module, and employing efficient compression algorithms. The success of this method is demonstrated by improvements in storage and training/rendering speeds compared to prior methods which highlights its potential for real-time free-viewpoint video streaming applications.
Adaptive Training#
Adaptive training, in the context of online free-viewpoint video (FVV) encoding, is a crucial technique for efficiently handling dynamic scenes. It involves adapting the training process to focus on the most significant changes in the scene at each time step, rather than processing the entire scene uniformly. This approach is vital because dynamic scenes contain substantial temporal redundancy, with only small portions of the scene changing significantly between consecutive frames. The core idea is to identify and prioritize those changes, thereby reducing computational cost and accelerating convergence. This often involves techniques that selectively update or compress only the dynamic components, which enhances efficiency without compromising the quality of the reconstruction. A key aspect is the utilization of metrics or signals (e.g., viewspace gradient difference) to distinguish static and dynamic content. These signals guide the process by determining which elements need to be updated or processed with high precision and which ones can be handled more coarsely. By focusing computational effort on dynamic areas, training time is reduced. The resulting representation is smaller and more memory-efficient for transmission, while preserving high rendering speeds.
Future of QUEEN#
The future of QUEEN hinges on addressing its current limitations, primarily its reliance on inter-frame residuals for efficiency. Extending its capability to handle longer sequences and drastic scene changes is crucial, potentially through incorporating keyframing techniques to identify and manage significant scene updates. Moreover, reducing the reliance on multi-view inputs for scene reconstruction is vital, perhaps by leveraging generative video priors or exploring methods for single-view or sparse-view reconstruction. Addressing the challenges of topological changes and highly variable appearance is essential, potentially involving techniques that robustly handle object appearances and disappearances. Finally, exploring broader applications of the model beyond free-viewpoint video streaming, such as novel view synthesis, and addressing potential societal impacts and safety concerns should be considered in the future development of QUEEN.
More visual insights#
More on figures
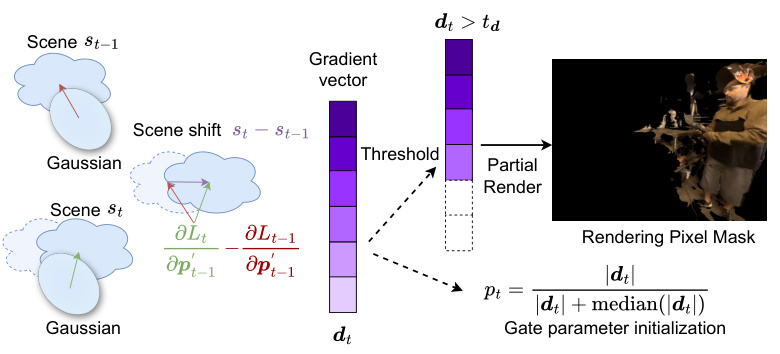
🔼 This figure illustrates the concept of Viewspace Gradient Difference used in QUEEN for adaptive training. It shows how the difference in viewspace gradients between consecutive frames (t and t-1) is used to identify dynamic regions in the scene. A gradient vector is calculated representing the change. A threshold (td) is applied; differences above this threshold are considered dynamic and are used to selectively render only dynamic parts of the scene, improving training efficiency and focusing on the parts of the scene which have changed, ignoring static parts.
read the caption
Figure 2: Viewspace Gradient Difference. We use the difference of viewspace gradients between consecutive frames to identify dynamic scene content.

🔼 This figure shows a qualitative comparison of the reconstruction quality of different methods on several scenes from the N3DV and Immersive datasets. For each scene, the figure presents four images: the result from TeTriRF, the result from 3DGStream, the result from QUEEN, and the ground truth. The PSNR value for each reconstruction is displayed above the corresponding image, which allows for a quantitative comparison alongside the visual comparison of details in the reconstruction.
read the caption
Figure 3: Qualitative Results. A visualization of various scenes in the N3DV and Immersive datasets. PSNR (↑) values are shown. We include additional video results in the supplement.

🔼 This figure compares the visual quality of videos reconstructed using QUEEN with different settings for updating Gaussian attributes. The ‘Ground Truth’ shows the original video. ‘Update All Attributes’ shows the results when QUEEN updates all Gaussian attributes (position, scale, rotation, opacity, color) at each frame. This leads to the highest quality reconstruction (PSNR: 33.95 dB). ‘Fixed Opacity’ shows the results when only position, scale, rotation, and color are updated, while opacity remains fixed across the video. The reconstruction quality is slightly lower (PSNR: 33.77 dB). ‘Fixed Opacity + Color’ shows the results when only position and scale and rotation are updated while both opacity and color are fixed. This shows a further drop in reconstruction quality (PSNR: 33.34 dB). The red box highlights a region where the visual differences are most noticeable. The results demonstrate that updating all Gaussian attributes improves visual quality.
read the caption
Figure 4: Effect of Updating Appearance Attributes. QUEEN updates all Gaussian attributes, resulting in improved quality versus keeping appearance attributes fixed across a video.
🔼 This figure illustrates the QUEEN framework for online free-viewpoint video (FVV) streaming. It shows how Gaussian attributes are updated incrementally at each time step, with residuals between consecutive frames being learned and compressed using a quantization and sparsity framework. The figure highlights the key components: incremental attribute updates, quantization, sparsity, and adaptive masked training for efficiency. The adaptive rendering only processes dynamic Gaussians, leading to faster training times.
read the caption
Figure 1: Overview of QUEEN for online FVV. We incrementally update Gaussian attributes at each time-step (gray block) by simultaneously learning and compressing residuals between consecutive time-steps via a quantization (orange block) and sparsity (yellow block) framework. We additionally render only the dynamic Gaussians for masked regions to achieve faster convergence (green block).

🔼 This figure shows a comparison of the reconstruction results of different methods (TeTriRF, 3DGStream, and QUEEN) against the ground truth for several scenes from the N3DV and Immersive datasets. The PSNR values are displayed for each reconstruction, indicating the quality of the reconstruction. The supplement contains additional videos showcasing the results.
read the caption
Figure 3: Qualitative Results. A visualization of various scenes in the N3DV and Immersive datasets. PSNR (↑) values are shown. We include additional video results in the supplement.
🔼 This figure illustrates the QUEEN framework for online free-viewpoint video (FVV) streaming. It shows how Gaussian attributes are updated incrementally at each time step by learning and compressing residuals between consecutive frames. The framework uses a quantization-sparsity approach to compress the residuals and an adaptive masked training method to speed up training by rendering only dynamic Gaussians.
read the caption
Figure 1: Overview of QUEEN for online FVV. We incrementally update Gaussian attributes at each time-step (gray block) by simultaneously learning and compressing residuals between consecutive time-steps via a quantization (orange block) and sparsity (yellow block) framework. We additionally render only the dynamic Gaussians for masked regions to achieve faster convergence (green block).

🔼 This figure illustrates the QUEEN (QUantized Efficient ENcoding) framework for online free-viewpoint video (FVV) streaming. It shows how Gaussian attributes are updated incrementally at each time step. The core of the method involves learning and compressing residuals between consecutive frames using a two-pronged approach: quantization and sparsity. Quantization compresses attributes, while sparsity focuses on positional residuals, dynamically adapting to scene changes for efficiency. Adaptive masked training is used to accelerate the process by rendering only the dynamic parts of the scene. This results in faster training times and smaller model sizes.
read the caption
Figure 1: Overview of QUEEN for online FVV. We incrementally update Gaussian attributes at each time-step (gray block) by simultaneously learning and compressing residuals between consecutive time-steps via a quantization (orange block) and sparsity (yellow block) framework. We additionally render only the dynamic Gaussians for masked regions to achieve faster convergence (green block).
🔼 This figure illustrates the QUEEN framework for online free-viewpoint video (FVV) streaming. It shows how Gaussian attributes are updated incrementally at each time step. The key components are: learning and compressing residuals between frames, quantizing attributes, sparsifying position residuals using a gating mechanism, and selectively rendering dynamic Gaussians for faster training. The diagram visually depicts the flow of data and processes in the model.
read the caption
Figure 1: Overview of QUEEN for online FVV. We incrementally update Gaussian attributes at each time-step (gray block) by simultaneously learning and compressing residuals between consecutive time-steps via a quantization (orange block) and sparsity (yellow block) framework. We additionally render only the dynamic Gaussians for masked regions to achieve faster convergence (green block).

🔼 This figure shows the overall architecture of the QUEEN framework for online free-viewpoint video (FVV) streaming. It illustrates how the system incrementally updates Gaussian attributes at each time step by learning and compressing residuals between consecutive frames. The process involves a quantization framework for attribute residuals, a sparsity framework for position residuals, and adaptive masked training to focus computation on dynamic scene content. This results in efficient compression and faster training and rendering.
read the caption
Figure 1: Overview of QUEEN for online FVV. We incrementally update Gaussian attributes at each time-step (gray block) by simultaneously learning and compressing residuals between consecutive time-steps via a quantization (orange block) and sparsity (yellow block) framework. We additionally render only the dynamic Gaussians for masked regions to achieve faster convergence (green block).

🔼 This figure shows a detailed overview of the QUEEN framework for online free-viewpoint video (FVV) streaming. It illustrates how the system incrementally updates Gaussian attributes at each time step, leveraging a quantization and sparsity framework to compress residuals between frames. The system also selectively renders only dynamic Gaussians to speed up training and improve efficiency.
read the caption
Figure 1: Overview of QUEEN for online FVV. We incrementally update Gaussian attributes at each time-step (gray block) by simultaneously learning and compressing residuals between consecutive time-steps via a quantization (orange block) and sparsity (yellow block) framework. We additionally render only the dynamic Gaussians for masked regions to achieve faster convergence (green block).
More on tables

🔼 This table presents ablation study results on the effect of updating different sets of attributes in the QUEEN framework. It compares updating only geometric attributes (position, scale, rotation) versus updating both geometric and appearance attributes (color, opacity). The results show a significant improvement in PSNR when appearance attributes are also updated, demonstrating their importance in reconstruction quality. The table highlights the trade-off between reconstruction accuracy and storage size. While updating both attribute types leads to higher PSNR and quality, the added storage cost is also increased.
read the caption
Table 3: Effect of Updating Attributes. On N3DV, PSNR significantly improves by updating all attributes but with a small storage overhead.
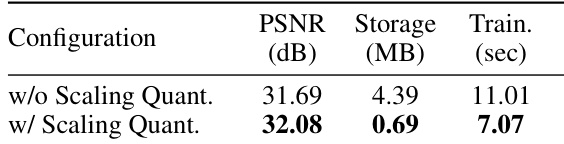
🔼 This table presents ablation study results focusing on the impact of quantizing the scaling attribute in the 3D Gaussian Splatting (3D-GS) model. It shows that quantizing this specific attribute leads to improvements in Peak Signal-to-Noise Ratio (PSNR), a reduction in the model size (measured in MB), and faster training times (measured in seconds). The comparison is made between a configuration without quantization of the scaling attribute and one with quantization, highlighting the benefits of this specific compression technique.
read the caption
Table 4: Effect of Quantizing Scaling Attribute on N3DV. PSNR improves while also reducing model size and training time due to faster rendering.
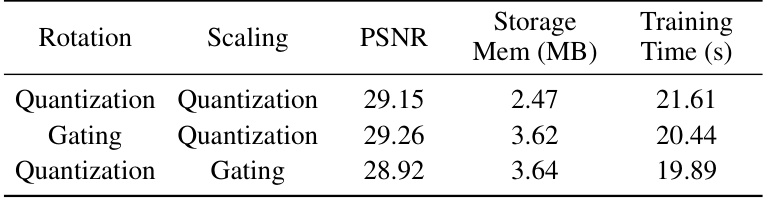
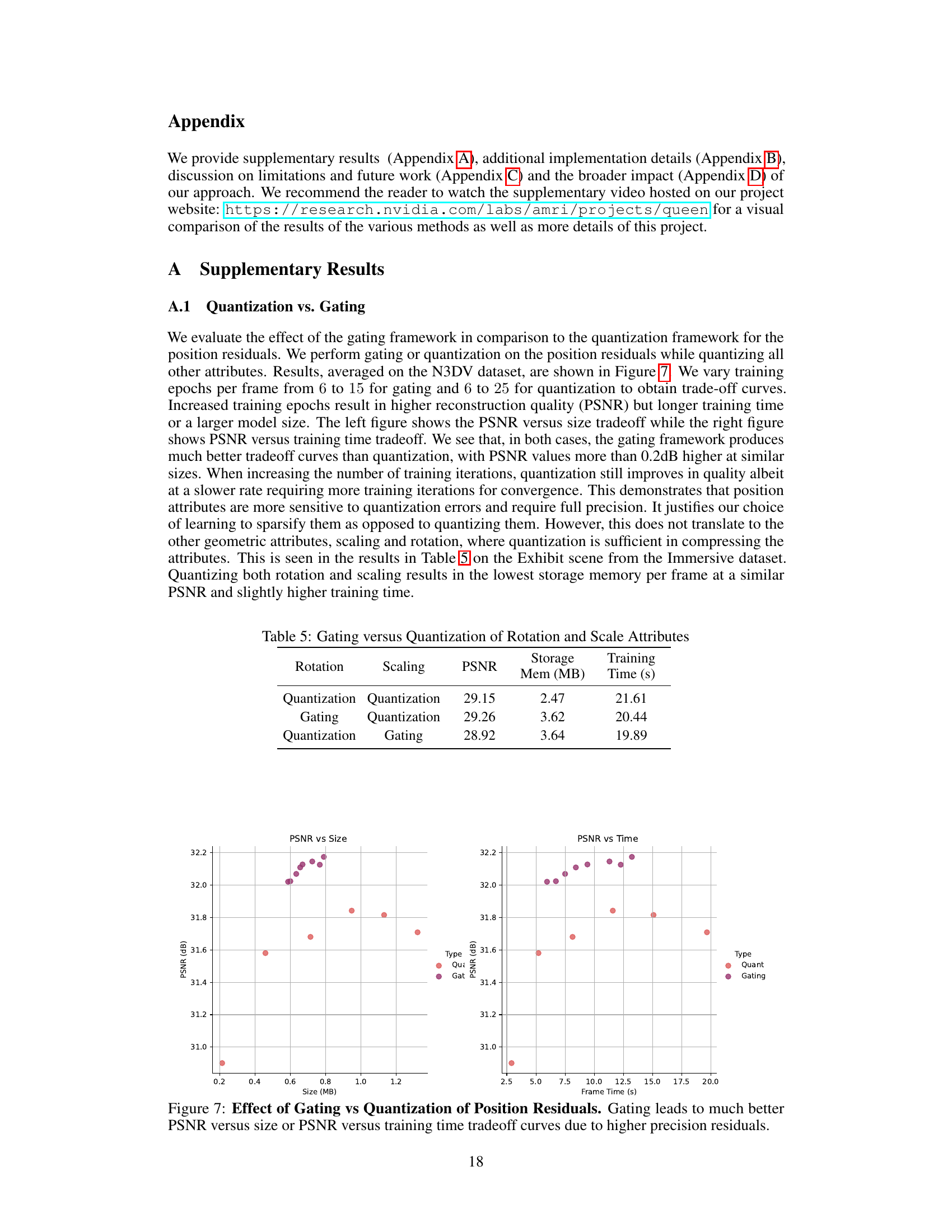
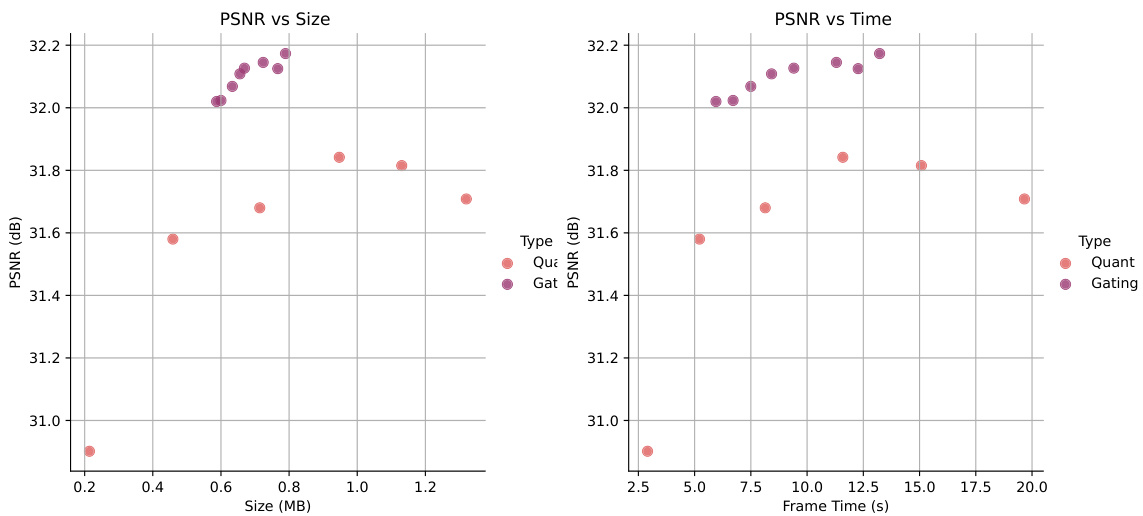
🔼 This table compares the results of using gating versus quantization for rotation and scaling attributes in the QUEEN model. The metrics compared are PSNR (peak signal-to-noise ratio, a measure of reconstruction quality), storage memory in MB (megabytes), and training time in seconds. The results show that, while both techniques provide compression, gating offers slightly better PSNR at a comparable memory cost for rotation. In contrast, quantization of the scaling attribute produces the best results. These results highlight the tradeoffs in compression performance, memory usage and training time between the two approaches for different attribute types.
read the caption
Table 5: Gating versus Quantization of Rotation and Scale Attributes

🔼 This table presents a quantitative comparison of the proposed QUEEN model against several state-of-the-art online and offline free-viewpoint video (FVV) methods. The comparison is done on two benchmark datasets: Neural 3D Videos (N3DV) and Immersive. Metrics include PSNR, SSIM, LPIPS, storage size (in MB), training time (in seconds), and rendering speed (in FPS). The table highlights the superior performance of QUEEN in terms of reconstruction quality, memory efficiency, and processing speed. A separate table in the supplementary material provides a more extensive comparison to offline methods.
read the caption
Table 1: Quantitative Results. We compare QUEEN against state-of-the-art online and (a few for brevity) offline FVV methods on N3DV [41] and Immersive [4]. We include many more offline methods in the supplementary (Tab. 8). 3DGStream* refers to our re-implementation on the same NVIDIA A100 GPU used by QUEEN for fairness. Bold and underlined numbers indicate the best and the second best results, respectively, within each category.

🔼 This table presents a comparison of the reconstruction quality (PSNR) and training efficiency achieved using two different initialization methods for the 3D scene geometry: COLMAP and COLMAP+Depth. The COLMAP+Depth method incorporates additional depth information derived from a monocular depth estimation network to improve the initial point cloud density. The table shows that incorporating this additional depth information leads to improvements in both PSNR (peak signal-to-noise ratio) and training efficiency, demonstrating the benefits of this refinement to the scene reconstruction process.
read the caption
Table 7: Effect of Depth Initialization on N3DV and Immersive datasets.
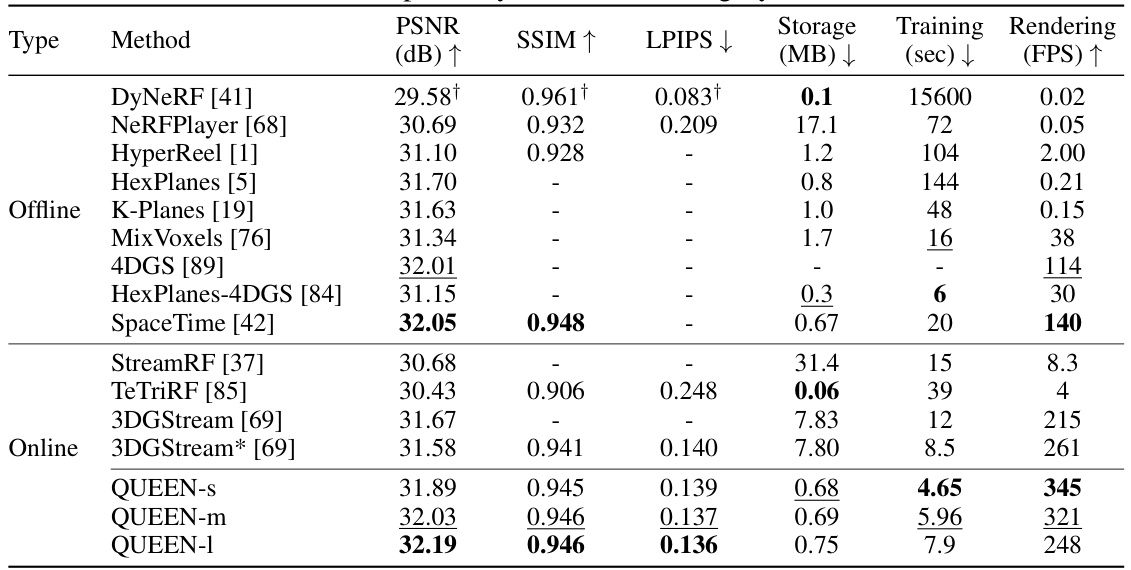
🔼 This table presents a quantitative comparison of the proposed QUEEN model against existing state-of-the-art online and offline free-viewpoint video (FVV) methods on two benchmark datasets: N3DV and Immersive. The metrics used for comparison include PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), LPIPS (Learned Perceptual Image Patch Similarity), storage size (in MB), training time (in seconds), and rendering speed (in FPS). The table highlights QUEEN’s superior performance in terms of reconstruction quality, memory efficiency, and speed, particularly when compared to the online methods. A note is included to clarify the re-implementation of 3DGStream on the same hardware as QUEEN for a fair comparison.
read the caption
Table 1: Quantitative Results. We compare QUEEN against state-of-the-art online and (a few for brevity) offline FVV methods on N3DV [41] and Immersive [4]. We include many more offline methods in the supplementary (Tab. 8). 3DGStream* refers to our re-implementation on the same NVIDIA A100 GPU used by QUEEN for fairness. Bold and underlined numbers indicate the best and the second best results, respectively, within each category.

🔼 This table presents a quantitative comparison of the proposed QUEEN model against other state-of-the-art online and offline free-viewpoint video (FVV) methods on two benchmark datasets: N3DV and Immersive. The comparison includes metrics like PSNR, SSIM, LPIPS, storage size, training time, and rendering speed (FPS). The results show QUEEN’s superior performance in terms of reconstruction quality and efficiency. Note that a re-implementation of 3DGStream on the same hardware is included for fair comparison.
read the caption
Table 1: Quantitative Results. We compare QUEEN against state-of-the-art online and (a few for brevity) offline FVV methods on N3DV [41] and Immersive [4]. We include many more offline methods in the supplementary (Tab. 8). 3DGStream* refers to our re-implementation on the same NVIDIA A100 GPU used by QUEEN for fairness. Bold and underlined numbers indicate the best and the second best results, respectively, within each category.
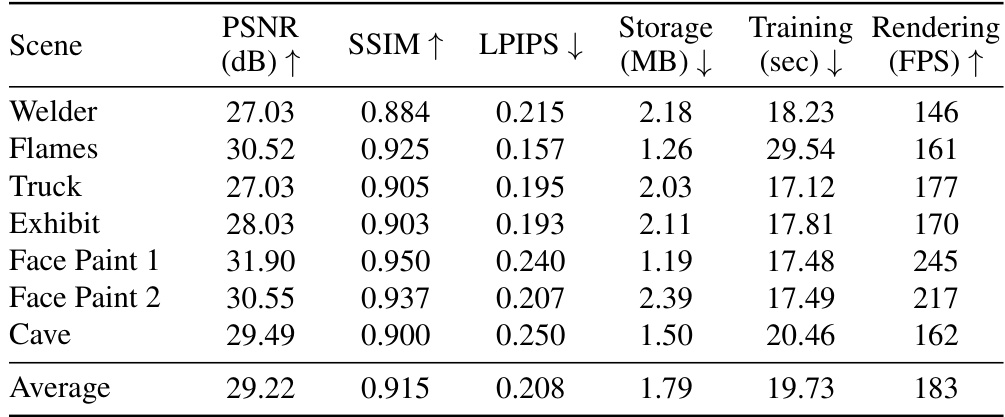
🔼 This table presents a quantitative comparison of the proposed QUEEN model against existing state-of-the-art methods. The metrics used for comparison include PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), LPIPS (Learned Perceptual Image Patch Similarity), storage size, training time, and rendering speed (FPS). The results are broken down by scene to allow for a more granular analysis of model performance across various scenarios within the Immersive dataset. This table provides a detailed evaluation of QUEEN’s efficiency and quality compared to other models.
read the caption
Table 10: Per-scene Metrics for the Immersive Datasets

🔼 This table presents a quantitative comparison of QUEEN against several state-of-the-art online and offline free-viewpoint video (FVV) methods. The comparison is performed on two benchmark datasets, N3DV and Immersive, and uses several metrics including PSNR (peak signal-to-noise ratio), SSIM (structural similarity index), LPIPS (learned perceptual image patch similarity), storage size, training time, and rendering speed (FPS). The table highlights QUEEN’s superior performance in terms of reconstruction quality, efficiency, and speed compared to the other methods.
read the caption
Table 1: Quantitative Results. We compare QUEEN against state-of-the-art online and (a few for brevity) offline FVV methods on N3DV [41] and Immersive [4]. We include many more offline methods in the supplementary (Tab. 8). 3DGStream* refers to our re-implementation on the same NVIDIA A100 GPU used by QUEEN for fairness. Bold and underlined numbers indicate the best and the second best results, respectively, within each category.

🔼 This table provides a quantitative comparison of QUEEN against other state-of-the-art online and offline free-viewpoint video (FVV) methods. The comparison is performed on two benchmark datasets: N3DV and Immersive. Metrics include PSNR, SSIM, LPIPS, storage size (in MB), training time (in seconds), and rendering speed (in FPS). The results highlight QUEEN’s superior performance in terms of reconstruction quality, memory efficiency, training speed, and rendering speed.
read the caption
Table 1: Quantitative Results. We compare QUEEN against state-of-the-art online and (a few for brevity) offline FVV methods on N3DV [41] and Immersive [4]. We include many more offline methods in the supplementary (Tab. 8). 3DGStream* refers to our re-implementation on the same NVIDIA A100 GPU used by QUEEN for fairness. Bold and underlined numbers indicate the best and the second best results, respectively, within each category.

🔼 This table presents a quantitative comparison of the proposed QUEEN model against existing state-of-the-art online and offline free-viewpoint video (FVV) methods. The comparison is performed on two benchmark datasets: Neural 3D Videos (N3DV) and Immersive. Metrics include PSNR, SSIM, LPIPS, storage size, training time, and rendering speed. The table highlights QUEEN’s superior performance in terms of reconstruction quality, model size, and speed.
read the caption
Table 1: Quantitative Results. We compare QUEEN against state-of-the-art online and (a few for brevity) offline FVV methods on N3DV [41] and Immersive [4]. We include many more offline methods in the supplementary (Tab. 8). 3DGStream* refers to our re-implementation on the same NVIDIA A100 GPU used by QUEEN for fairness. Bold and underlined numbers indicate the best and the second best results, respectively, within each category.
Full paper#