TL;DR#
AI-assisted decision making is increasingly prevalent, but the “black box” nature of AI models makes it difficult to understand how humans integrate AI recommendations and explanations. This paper investigates this issue by building computational models of human decision-making processes. These models reveal the subtle ways that AI explanations can influence human behavior.
The researchers developed a novel method for manipulating AI explanations using human behavior modeling, demonstrating that such manipulations can subtly direct decision-making behavior. This approach allows researchers to explore how to optimize AI explanations in order to improve human-AI team performance, but also how easily this can be exploited for malicious purposes. They also found that these manipulation techniques can be used to introduce biases into human decisions without the user being aware of the manipulation. Their findings emphasize the importance of understanding human behavior in relation to AI, and the crucial need for designing AI explanation systems that are robust against manipulation.
Key Takeaways#
Why does it matter?#
This research is crucial for AI safety and ethical AI development because it reveals how easily manipulated AI explanations can sway human decisions, even when those decisions are unfair or undesirable. It highlights the need for more robust and human-centered AI explanation methods and emphasizes the importance of transparency in AI systems.
Visual Insights#
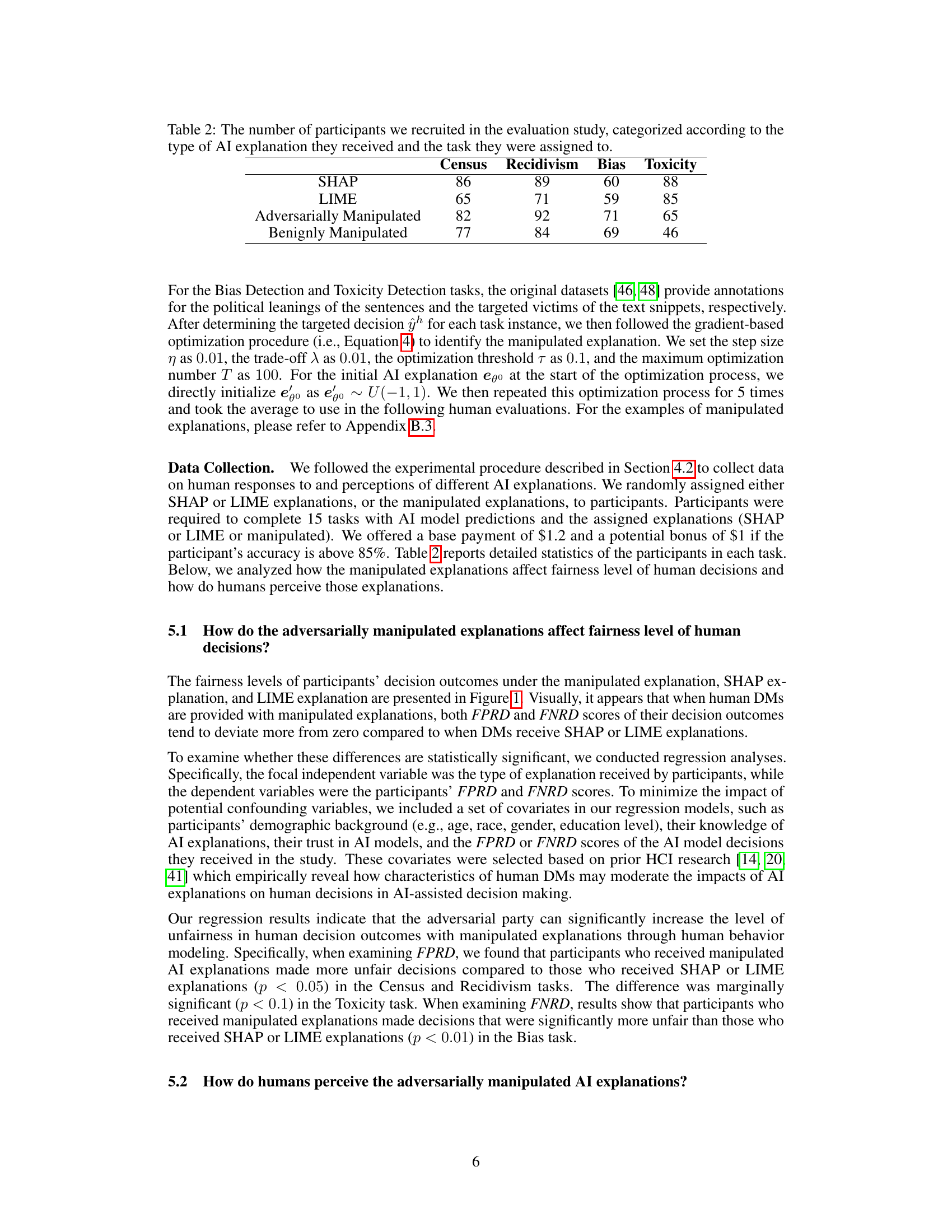
🔼 This figure shows a comparison of fairness metrics (FPRD and FNRD) for human decisions made under three types of AI explanations: adversarially manipulated explanations, SHAP explanations, and LIME explanations. The results across four different decision-making tasks are displayed. Error bars show the 95% confidence intervals, and significance levels are indicated by asterisks. Lower values of FPRD and FNRD represent greater fairness in human decisions.
read the caption
Figure 1: Comparing average FPRD and FNRD of the human decision outcomes under the adversarially manipulated explanation, SHAP explanation, or LIME explanation. Error bars represent the 95% confidence intervals of the mean values. ***, **, and * denote significance levels of 0.1, 0.05, and 0.01, respectively. For both FPRD and FNRD, a value closer to zero indicates that the human decisions are more fair.

🔼 This table presents the number of participants involved in the data collection phase for training the human behavior models used in the study. It also shows the average accuracy achieved by these models across five different cross-validation folds for each of the four decision-making tasks: Census Prediction, Recidivism Prediction, Bias Detection, and Toxicity Detection. The model accuracy reflects how well the computational models predict human decisions on these tasks.
read the caption
Table 1: The number of subjects recruited in data collection for training behavior models, and the average accuracy of the human behavior model in 5-fold cross validation for each task.
In-depth insights#
Human-AI Collab Models#
Human-AI collaboration models are crucial for understanding how humans integrate AI recommendations into decision-making. Effective models capture the nuanced interplay between human judgment, AI suggestions, and provided explanations. These models aren’t simply about prediction; they offer insights into human biases, trust calibration, and reliance strategies. Analyzing these models reveals how AI explanations, whether accurate or manipulated, significantly impact human choices. Furthermore, this analysis extends beyond evaluating existing XAI methods; it suggests a framework for designing explanations to influence behavior, raising ethical considerations concerning transparency and the potential for manipulation. The ability to model and subsequently manipulate these interactions is a powerful tool for improving human-AI teams but also presents a risk of misuse, highlighting the need for responsible development and deployment. Exploring such models therefore requires a careful balancing of potential benefit and potential harm.
Explainable AI (XAI)#
Explainable AI (XAI) methods aim to bridge the gap between complex AI models and human understanding. The paper highlights the critical role of XAI in AI-assisted decision making, emphasizing its use in providing insights into AI’s decision-making processes. However, it also reveals the limitations of current XAI techniques, showing how humans often struggle to interpret explanations effectively, leading to suboptimal use of AI recommendations. The research underscores the importance of considering human behavior when designing XAI, suggesting a need for more sophisticated methods that model how humans interact with AI explanations. The study also demonstrates the potential for manipulating XAI explanations, both for beneficial and malicious purposes, raising important ethical concerns about the design and application of XAI systems. A key takeaway is the need for robust XAI methods that are both effective and resistant to manipulation.
Adversarial Explanations#
The concept of “Adversarial Explanations” in AI research delves into the malicious manipulation of AI-generated explanations. Attackers could exploit vulnerabilities in human understanding of AI explanations to steer individuals towards making biased or incorrect decisions. This could involve subtly altering the explanation’s content or presentation to mislead users without them noticing. The implications are significant, potentially impacting fairness, trust, and the overall reliability of AI systems. For example, an adversarial explanation might selectively highlight certain features to promote a specific outcome, even if it’s not supported by the actual data or model’s reasoning. Research in this area highlights the crucial need for robust and transparent explanation methods that are resistant to manipulation. The development of techniques to detect adversarial explanations and build user trust in AI’s decision-making processes is a critical step towards mitigating the risks associated with adversarial manipulations. Further research needs to focus on developing methods to make AI explanations more robust and less susceptible to manipulation. The implications of adversarial explanations extend beyond individual users; malicious actors could utilize this approach to sway public opinion or manipulate large-scale decisions.
Benign Explanations#
The concept of “benign explanations” in AI-assisted decision making is a crucial area of research. It involves designing AI explanations that positively influence human decision-making, improving trust, and promoting the appropriate use of AI recommendations. This is in contrast to “adversarial explanations,” which aim to mislead or manipulate users. Achieving benign explanations requires a deep understanding of human psychology and how people integrate AI advice into their decision process. Effective explanations should be transparent, accurate, and easy to understand, but also consider cognitive biases and limitations in human reasoning. Methods for designing benign explanations include developing models that capture human behavior in response to explanations and then using this understanding to tailor explanations that optimize desired outcomes, such as improved accuracy and fairness. However, a major challenge lies in the potential for unintended consequences; seemingly benign explanations could still have unforeseen effects on decision-making behavior. Therefore, rigorous evaluation and careful consideration of potential biases are essential for ensuring that explanations are truly benign and beneficial.
Ethical Implications#
The research paper’s manipulation of AI explanations raises significant ethical concerns. Deception is a major issue, as participants were unknowingly influenced by altered explanations, impacting their decisions without their awareness. This manipulation could be easily exploited for malicious purposes, potentially causing harm to individuals or groups. The study highlights the need for transparency and user education to mitigate such risks. Furthermore, the lack of access to the underlying AI model during the explanation manipulation introduces questions regarding the fairness and accountability of the process. The potential for bias amplification is particularly concerning, especially considering the lack of participant awareness and the susceptibility of individuals to manipulated information. The overall impact demands careful consideration of AI ethics and potential interventions to safeguard against misuse, particularly given the ease with which AI explanations can be subtly altered to influence decision-making.
More visual insights#
More on figures
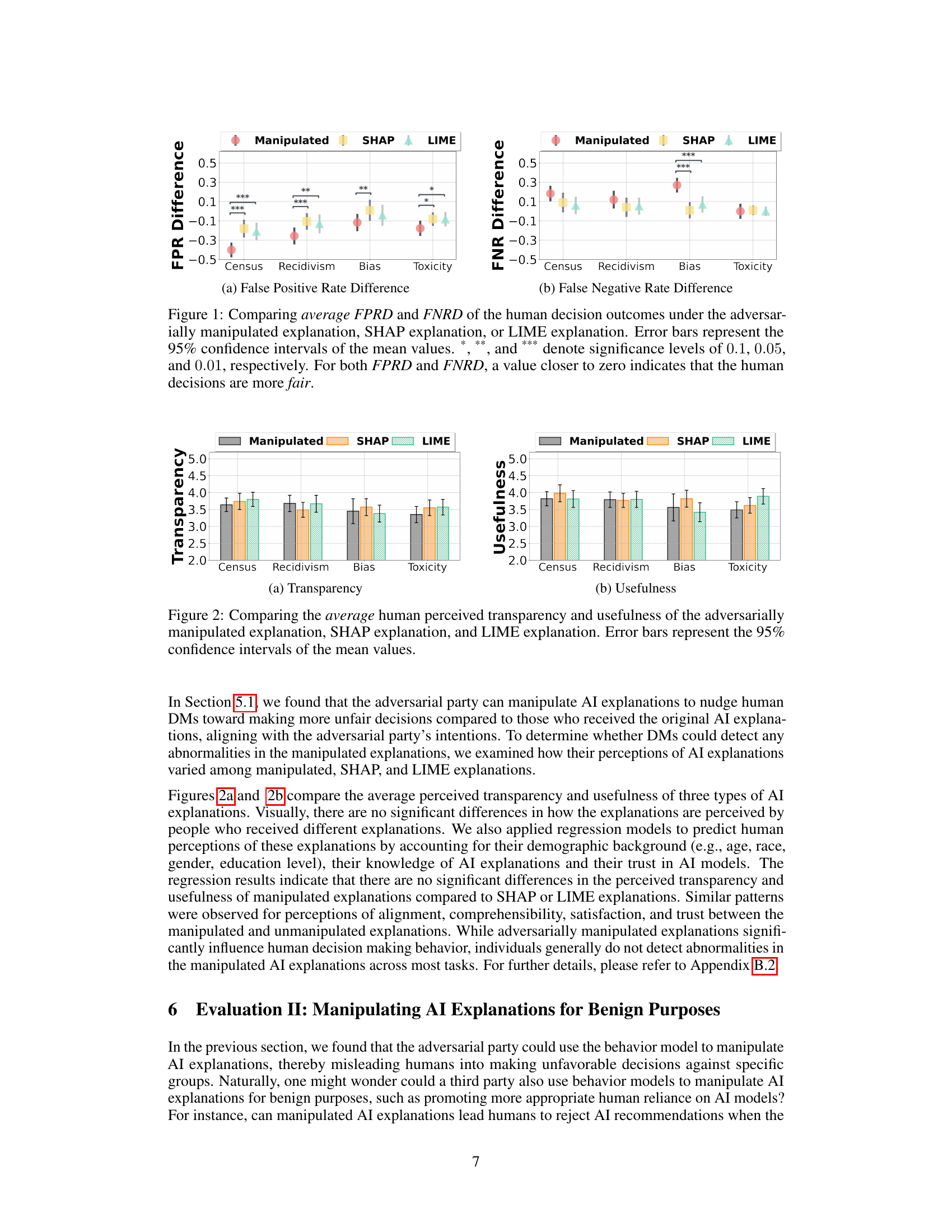
🔼 This figure shows a comparison of fairness metrics (False Positive Rate Difference - FPRD and False Negative Rate Difference - FNRD) for human decisions made using adversarially manipulated explanations versus those made using SHAP or LIME explanations across four different tasks. The results indicate that adversarially manipulated explanations led to significantly less fair decisions than SHAP or LIME explanations in most tasks.
read the caption
Figure 1: Comparing average FPRD and FNRD of the human decision outcomes under the adversarially manipulated explanation, SHAP explanation, or LIME explanation. Error bars represent the 95% confidence intervals of the mean values. ***, **, and * denote significance levels of 0.1, 0.05, and 0.01, respectively. For both FPRD and FNRD, a value closer to zero indicates that the human decisions are more fair.

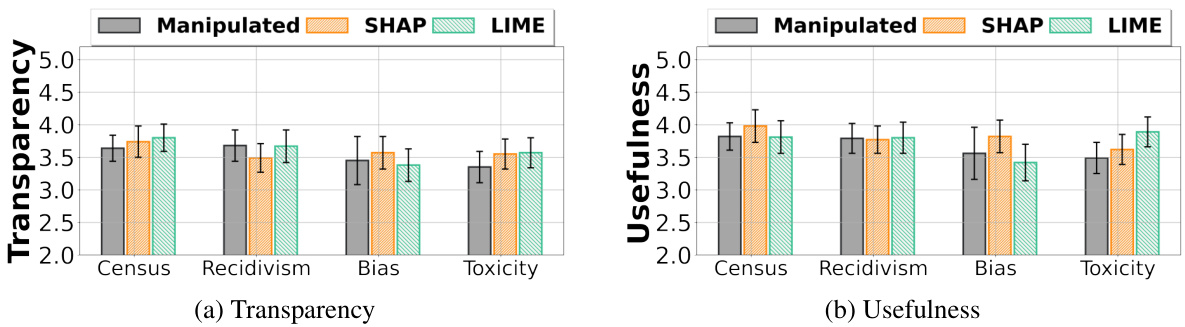
🔼 This figure displays the results of a study comparing human decision-making performance under three types of AI explanations: benignly manipulated explanations, SHAP explanations, and LIME explanations. The figure shows the accuracy, overreliance (trusting AI too much), and underreliance (not trusting AI enough) for each explanation method across four different tasks. Error bars indicate the 95% confidence intervals, and significance levels (***, **, *) show the statistical significance of differences between the methods.
read the caption
Figure 3: Comparing the average accuracy, overreliance, and the underreliance of human decision outcomes under the benignly manipulated explanation, SHAP explanation, or LIME explanation. Error bars represent the 95% confidence intervals of the mean values. ***, **, and * denote significance levels of 0.01, 0.05, and 0.1 respectively.

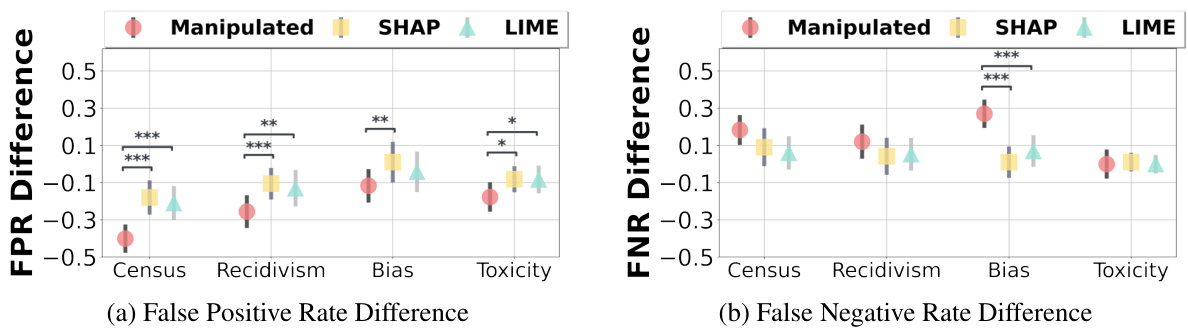
🔼 This figure displays the results of a study comparing the fairness of human decisions made when using different types of AI explanations. The x-axis represents the four decision-making tasks. The y-axis shows the False Positive Rate Difference (FPRD) and False Negative Rate Difference (FNRD). The bars show the average FPRD and FNRD for decisions made using adversarially manipulated explanations, SHAP explanations, and LIME explanations. Error bars indicate the 95% confidence intervals. Asterisks indicate the statistical significance of the differences.
read the caption
Figure 1: Comparing average FPRD and FNRD of the human decision outcomes under the adversarially manipulated explanation, SHAP explanation, or LIME explanation. Error bars represent the 95% confidence intervals of the mean values. ***, **, and * denote significance levels of 0.1, 0.05, and 0.01, respectively. For both FPRD and FNRD, a value closer to zero indicates that the human decisions are more fair.
🔼 This figure displays the fairness of human decisions (measured by FPRD and FNRD) when using adversarially manipulated explanations, SHAP explanations, and LIME explanations. It shows that adversarially manipulated explanations lead to significantly less fair decisions compared to SHAP or LIME explanations across multiple tasks (Census, Recidivism, Bias, Toxicity). Error bars indicate 95% confidence intervals and asterisks represent statistical significance levels.
read the caption
Figure 1: Comparing average FPRD and FNRD of the human decision outcomes under the adversarially manipulated explanation, SHAP explanation, or LIME explanation. Error bars represent the 95% confidence intervals of the mean values. ***, **, and * denote significance levels of 0.1, 0.05, and 0.01, respectively. For both FPRD and FNRD, a value closer to zero indicates that the human decisions are more fair.

🔼 This figure displays the False Positive Rate Difference (FPRD) and False Negative Rate Difference (FNRD) for human decisions made under three different explanation types: adversarially manipulated explanations, SHAP explanations, and LIME explanations. Error bars show the 95% confidence interval for each mean value. Asterisks indicate the statistical significance of differences between the manipulation methods; more asterisks mean higher significance. Values closer to zero indicate fairer decisions.
read the caption
Figure 1: Comparing average FPRD and FNRD of the human decision outcomes under the adversarially manipulated explanation, SHAP explanation, or LIME explanation. Error bars represent the 95% confidence intervals of the mean values. ***, **, and * denote significance levels of 0.1, 0.05, and 0.01, respectively. For both FPRD and FNRD, a value closer to zero indicates that the human decisions are more fair.

🔼 This figure compares the fairness of human decisions when using adversarially manipulated explanations against those using SHAP and LIME explanations across four tasks. Fairness is measured using False Positive Rate Difference (FPRD) and False Negative Rate Difference (FNRD). Lower values indicate greater fairness. The figure shows that adversarially manipulated explanations lead to significantly less fair decisions compared to both SHAP and LIME.
read the caption
Figure 1: Comparing average FPRD and FNRD of the human decision outcomes under the adversarially manipulated explanation, SHAP explanation, or LIME explanation. Error bars represent the 95% confidence intervals of the mean values. ***, **, and * denote significance levels of 0.1, 0.05, and 0.01, respectively. For both FPRD and FNRD, a value closer to zero indicates that the human decisions are more fair.

🔼 This figure displays the results of a comparison of fairness metrics (False Positive Rate Difference and False Negative Rate Difference) across three types of AI explanations: adversarially manipulated, SHAP, and LIME. The results show that adversarially manipulated explanations lead to less fair decisions compared to SHAP and LIME explanations, indicating the potential for malicious manipulation of AI explanations to create biased outcomes. Error bars indicate 95% confidence intervals, and asterisks denote statistical significance levels.
read the caption
Figure 1: Comparing average FPRD and FNRD of the human decision outcomes under the adversarially manipulated explanation, SHAP explanation, or LIME explanation. Error bars represent the 95% confidence intervals of the mean values. ***, **, and * denote significance levels of 0.1, 0.05, and 0.01, respectively. For both FPRD and FNRD, a value closer to zero indicates that the human decisions are more fair.

🔼 This figure compares the fairness of human decisions using three types of AI explanations: adversarially manipulated explanations, SHAP explanations, and LIME explanations. It shows that adversarially manipulated explanations led to significantly less fair decisions (higher FPRD and FNRD) than SHAP or LIME explanations. The error bars represent the 95% confidence intervals, and asterisks indicate statistical significance levels.
read the caption
Figure 1: Comparing average FPRD and FNRD of the human decision outcomes under the adversarially manipulated explanation, SHAP explanation, or LIME explanation. Error bars represent the 95% confidence intervals of the mean values. ***, **, and * denote significance levels of 0.1, 0.05, and 0.01, respectively. For both FPRD and FNRD, a value closer to zero indicates that the human decisions are more fair.
🔼 This figure compares the fairness of human decisions (measured by False Positive Rate Difference (FPRD) and False Negative Rate Difference (FNRD)) when using adversarially manipulated explanations, SHAP explanations, and LIME explanations. Statistical significance is shown using asterisks. The closer the FPRD and FNRD values are to zero, the fairer the decisions.
read the caption
Figure 1: Comparing average FPRD and FNRD of the human decision outcomes under the adversarially manipulated explanation, SHAP explanation, or LIME explanation. Error bars represent the 95% confidence intervals of the mean values. ***, **, and * denote significance levels of 0.1, 0.05, and 0.01, respectively. For both FPRD and FNRD, a value closer to zero indicates that the human decisions are more fair.
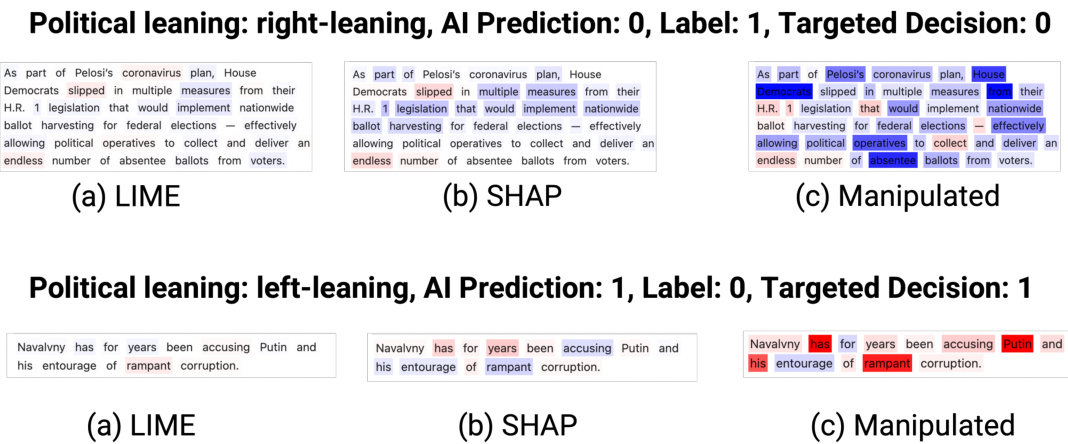
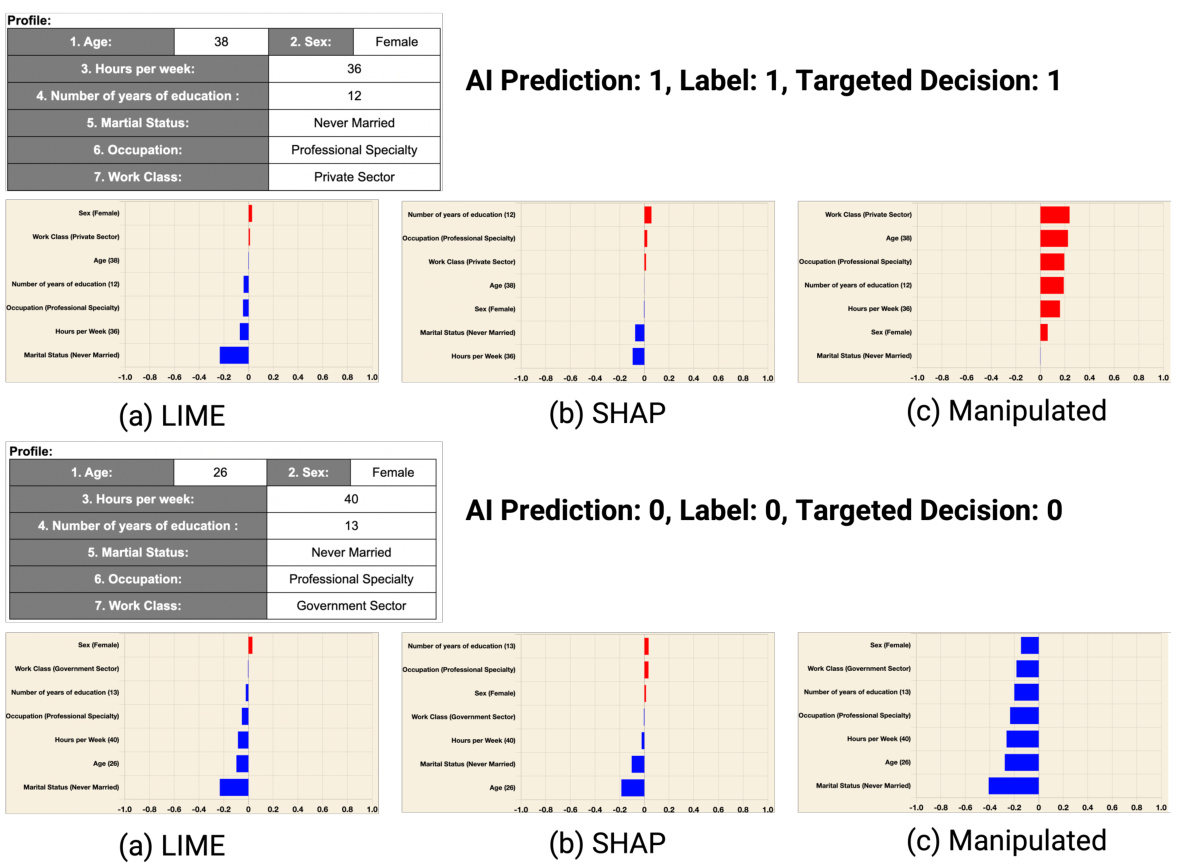
🔼 This figure shows examples of adversarially manipulated explanations alongside LIME and SHAP explanations for the Toxicity Detection task. It visually demonstrates how the adversarially manipulated explanations differ from the original methods by highlighting certain words to potentially influence the human’s decision. The top panel shows an example where the AI model correctly predicted a non-toxic sentence (label 0), and the manipulated explanation subtly nudges a human toward that same conclusion. The bottom panel shows a case where the AI model correctly predicts a toxic sentence (label 1). However, the manipulated explanation tries to influence a human to judge the sentence as non-toxic.
read the caption
Figure B.5: The visual comparisons of adversarially manipulated, LIME, and SHAP explanations for the Toxicity Detection task.

🔼 This figure compares the fairness of human decisions using three types of explanations: adversarially manipulated explanations, SHAP explanations, and LIME explanations. Fairness is measured by FPRD (False Positive Rate Difference) and FNRD (False Negative Rate Difference). The results show that adversarially manipulated explanations lead to significantly less fair decisions than SHAP and LIME explanations across most tasks. Error bars represent 95% confidence intervals, and asterisks denote statistical significance levels.
read the caption
Figure 1: Comparing average FPRD and FNRD of the human decision outcomes under the adversarially manipulated explanation, SHAP explanation, or LIME explanation. Error bars represent the 95% confidence intervals of the mean values. ***, **, and * denote significance levels of 0.1, 0.05, and 0.01, respectively. For both FPRD and FNRD, a value closer to zero indicates that the human decisions are more fair.
🔼 This figure compares the performance of human decision-making under three different explanation types: benignly manipulated explanations, SHAP explanations, and LIME explanations. The results are displayed in three subfigures: accuracy, overreliance, and under-reliance. Statistically significant differences are indicated by asterisks (*, **, ***), showing the impact of explanation manipulation on human decision accuracy and reliance on AI model predictions.
read the caption
Figure 3: Comparing the average accuracy, overreliance, and the underreliance of human decision outcomes under the benignly manipulated explanation, SHAP explanation, or LIME explanation. Error bars represent the 95% confidence intervals of the mean values. ***, **, and * denote significance levels of 0.1, 0.05, and 0.01 respectively.

🔼 This figure displays the fairness levels of human decisions using two metrics (False Positive Rate Difference and False Negative Rate Difference) across four different tasks. The fairness is compared when using adversarially manipulated explanations versus standard SHAP and LIME explanations. The results show that adversarially manipulated explanations lead to less fair human decisions.
read the caption
Figure 1: Comparing average FPRD and FNRD of the human decision outcomes under the adversarially manipulated explanation, SHAP explanation, or LIME explanation. Error bars represent the 95% confidence intervals of the mean values. ***, **, and * denote significance levels of 0.1, 0.05, and 0.01, respectively. For both FPRD and FNRD, a value closer to zero indicates that the human decisions are more fair.

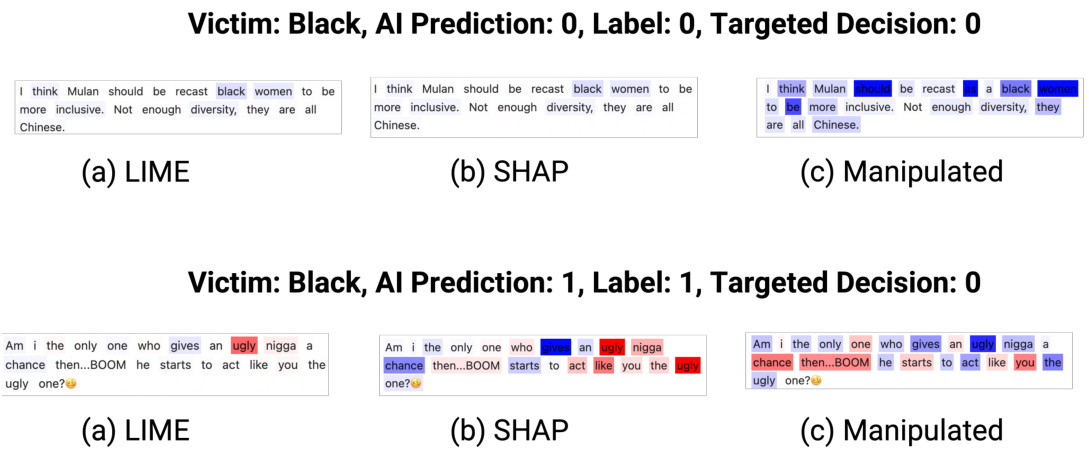
🔼 This figure displays three visualizations of explanations generated by LIME, SHAP, and an adversarially manipulated method for a bias detection task. Each visualization shows how different words in the sentence are weighted in terms of their contribution to the AI model’s decision to classify the sentence as biased or not biased. The manipulated explanation is designed to be misleading by altering weights to potentially influence human judgments of bias.
read the caption
Figure B.4: The visual comparisons of adversarially manipulated, LIME, and SHAP explanations for the Bias Detection task.

🔼 This figure shows three different explanations generated by LIME, SHAP, and an adversarially manipulated method for two examples of text snippets in the Bias Detection task. Each explanation highlights different words in the text, indicating varying degrees of importance in determining the bias of the text. The adversarially manipulated explanation is designed to mislead the human evaluator regarding the text’s bias, showcasing how these methods can be manipulated for malicious purposes.
read the caption
Figure B.4: The visual comparisons of adversarially manipulated, LIME, and SHAP explanations for the Bias Detection task.

🔼 This figure shows a comparison of three different types of explanations for the Toxicity Detection task. The explanations are shown for two examples where the AI model correctly predicts whether the text is toxic or not. The figure shows how adversarially manipulated explanations highlight the toxic words more strongly, while LIME and SHAP explanations provide a more nuanced analysis of the text. The aim is to visualize how adversarially manipulated explanations are very different from the LIME and SHAP explanations and might affect the user’s perception of toxicity.
read the caption
Figure B.5: The visual comparisons of adversarially manipulated, LIME, and SHAP explanations for the Toxicity Detection task.
More on tables

🔼 This table shows the number of participants in each experimental group during the evaluation phase of the study. The participants were divided into groups based on the type of AI explanation they received (SHAP, LIME, Adversarially Manipulated, or Benignly Manipulated) and the specific decision-making task they performed (Census, Recidivism, Bias, or Toxicity). The numbers indicate how many participants were assigned to each of the resulting experimental conditions.
read the caption
Table 2: The number of participants we recruited in the evaluation study, categorized according to the type of AI explanation they received and the task they were assigned to.

🔼 This table shows the correlation between the total importance scores assigned to features in different explanation methods (SHAP, LIME, and adversarially/benignly manipulated explanations) and the AI’s prediction. A higher correlation indicates a greater agreement between the explanation’s feature importance and the AI’s final decision. This helps assess the consistency and trustworthiness of the explanation methods.
read the caption
Table B.1: Agreement between the sum of feature importance in explanations and AI predictions, measured in terms of the Pearson correlation coefficient.

🔼 This table presents the average accuracy achieved by the independent human behavior model across four different decision-making tasks. The model’s performance is evaluated using 5-fold cross-validation, providing a robust measure of its predictive capability in each task. The tasks involve predicting census data, recidivism risk, bias in text, and toxicity in text. The accuracy scores serve as a baseline for evaluating the performance improvements that may be achieved through AI-assisted decision-making.
read the caption
Table C.1: The average accuracy of the independent human behavior model through 5-fold validation for each task.

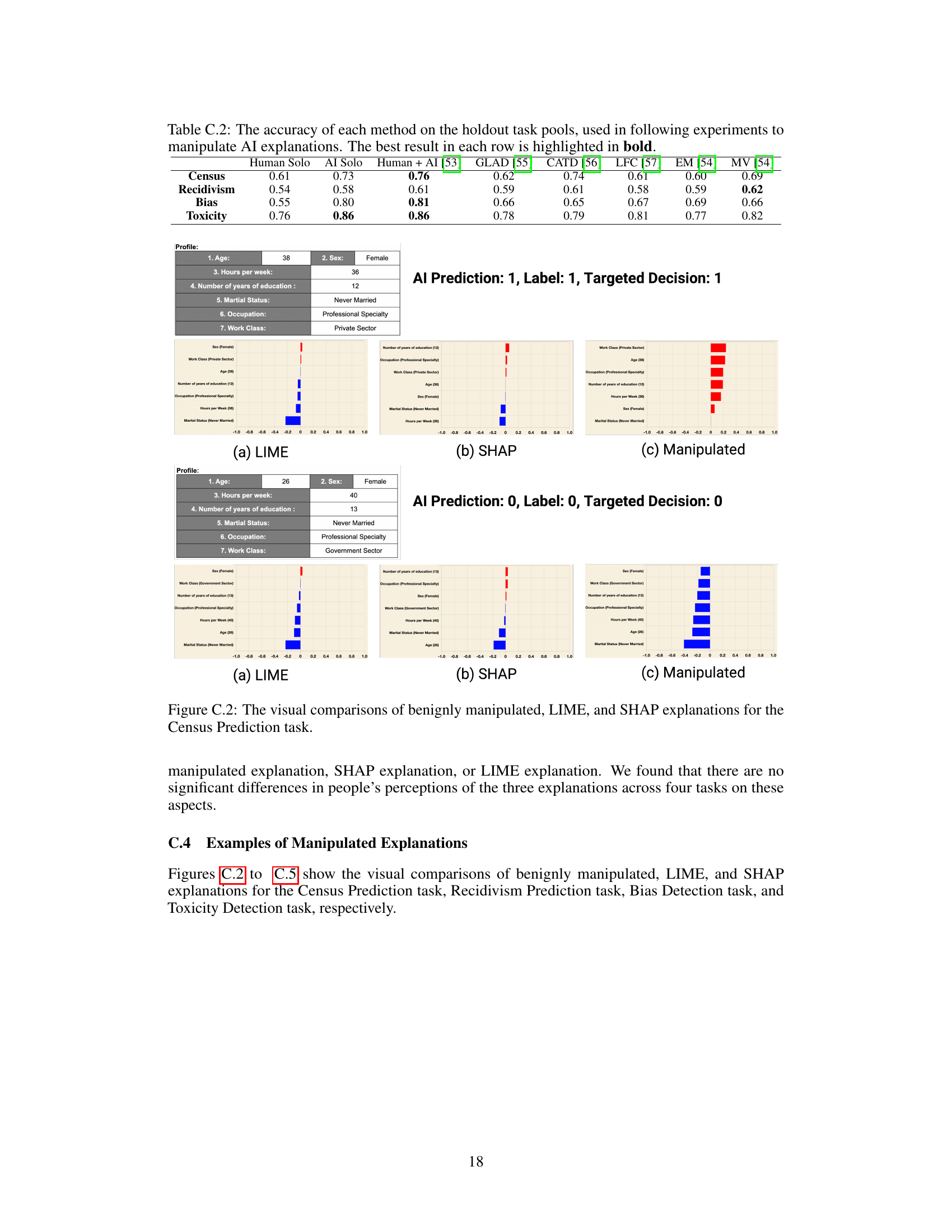
🔼 This table presents the accuracy of different methods for combining human and AI predictions on four decision-making tasks: Census, Recidivism, Bias Detection, and Toxicity Detection. The methods compared include using only human decisions, only AI model predictions, a human-AI combination method, and several other truth inference methods. The best-performing method for each task is highlighted in bold. This table is crucial for understanding how the choice of combination method impacts the subsequent manipulation of AI explanations in the study.
read the caption
Table C.2: The accuracy of each method on the holdout task pools, used in following experiments to manipulate AI explanations. The best result in each row is highlighted in bold.
Full paper#