TL;DR#
Large language models (LLMs) based on Transformers are computationally expensive, limiting accessibility. Existing Mixture-of-Experts (MoE) methods primarily focus on feedforward layers, and previous attempts to apply MoE to the attention layer haven’t matched the performance of baseline models. This creates a need for efficient attention mechanisms.
This paper introduces SwitchHead, a novel MoE approach for the attention layer. SwitchHead successfully reduces both compute and memory, achieving significant speedup while maintaining performance on par with the baseline Transformer. It computes fewer attention matrices and demonstrates effectiveness on various datasets and model sizes. Notably, combining SwitchHead with MoE feedforward layers yields fully MoE “SwitchAll” Transformers.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SwitchHead, a novel and effective method for accelerating Transformer models. It offers significant improvements in computational efficiency without sacrificing performance, addressing a critical challenge in the field of large language models. This opens up new avenues for research into more efficient and scalable Transformer architectures. The findings are highly relevant for researchers working on resource-constrained environments or aiming to train and deploy extremely large language models.
Visual Insights#
🔼 The figure is a schematic representation of SwitchHead, a novel Mixture-of-Experts (MoE) method for the attention layer in Transformer networks. It shows that SwitchHead consists of multiple independent heads. Each head comprises multiple experts responsible for the value and output projections. A key feature is that each head only requires a single attention matrix, unlike standard Transformers. The diagram visually depicts the flow of information through the selection logic, experts, and the final output. This design allows SwitchHead to reduce computational costs while maintaining performance.
read the caption
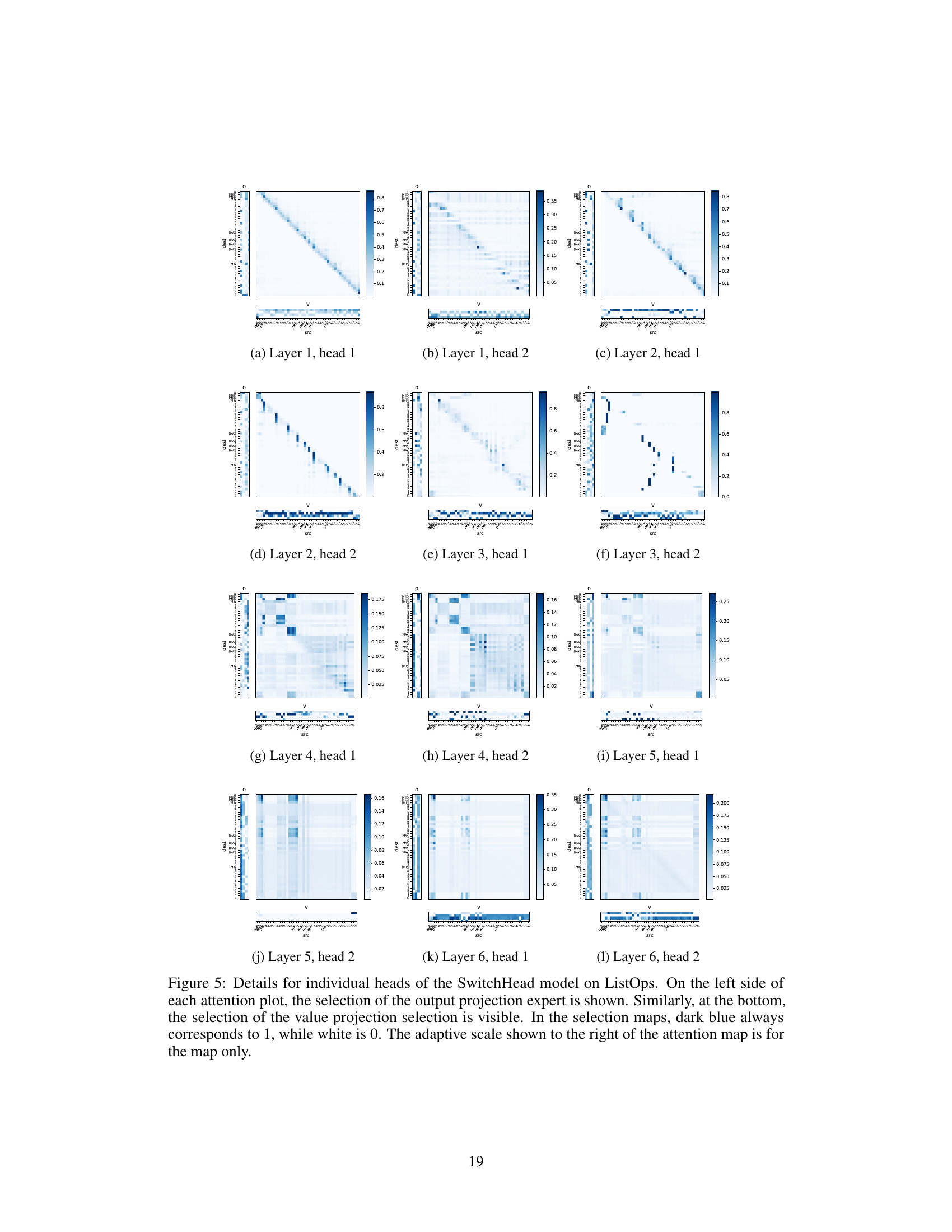
Figure 1: A schematic representation of SwitchHead. It consists of a few independent heads, each with multiple experts for value and output projections. Each head has a single attention matrix.
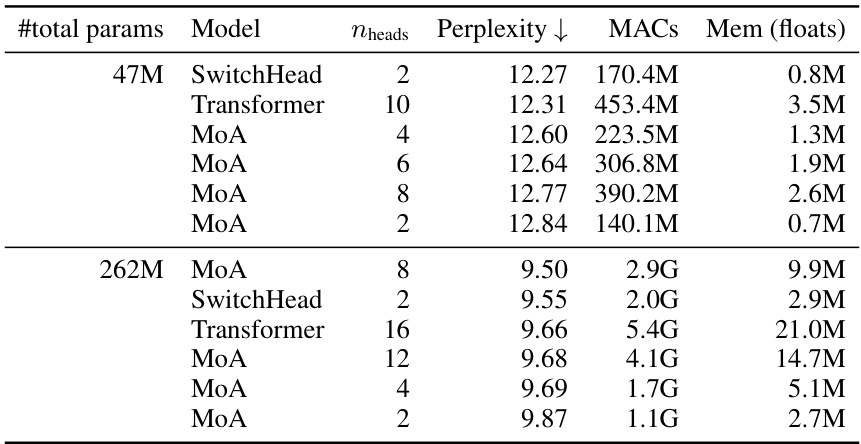
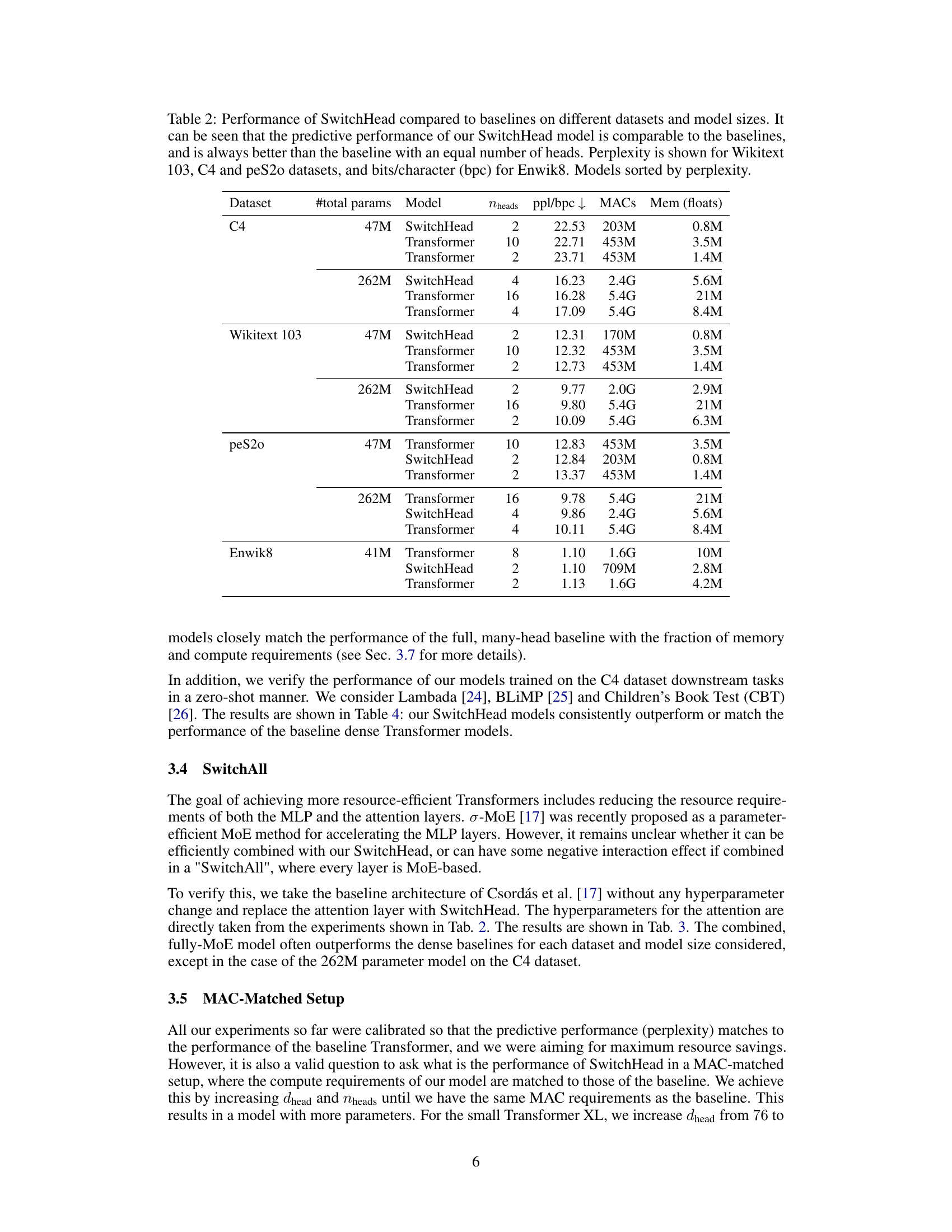
🔼 This table compares the performance of SwitchHead against various Mixture of Attention Heads (MoA) models and a standard Transformer model on the Wikitext-103 dataset. It highlights SwitchHead’s ability to match or exceed the performance of other models while using significantly less compute and memory resources. The table is sorted by model perplexity, showing the trade-off between performance and resource efficiency.
read the caption
Table 1: Performance of SwitchHead compared to different MoA variants. MoA can outperform the baseline, but only at a price of using significantly more compute and memory. Also, SwitchHead outperforms the baseline dense Transformer. These results are on Wikitext 103. Table sorted by model perplexity.
In-depth insights#
SwitchHead: MoE Attention#
SwitchHead proposes a novel Mixture of Experts (MoE) approach for accelerating Transformer self-attention mechanisms. Instead of applying MoEs to the feedforward layers, a common practice, SwitchHead targets the attention layer itself. This is a significant departure, as previous attempts to integrate MoEs into self-attention struggled to match the performance of baseline Transformers. The core innovation involves a mechanism that drastically reduces the number of attention matrices computed, leading to substantial computational and memory savings. SwitchHead achieves this by cleverly sharing keys and queries across multiple experts, selectively activating subsets of experts for value and output projections. This approach effectively addresses the quadratic complexity of attention, making it more scalable to longer sequences and larger models. The results demonstrate that SwitchHead achieves competitive language modeling performance with a fraction of the compute and memory resources, proving its efficiency and potential for wider adoption in resource-constrained environments or extremely large models. Crucially, the approach’s design allows it to integrate seamlessly with other MoE techniques, as showcased by the SwitchAll architecture which applies MoEs to both the attention and feedforward layers. The paper provides a strong empirical evaluation across multiple benchmarks and demonstrates the interpretability of the expert selections, further solidifying the promise of SwitchHead for more efficient and powerful Transformer models.
Resource-Efficient MoE#
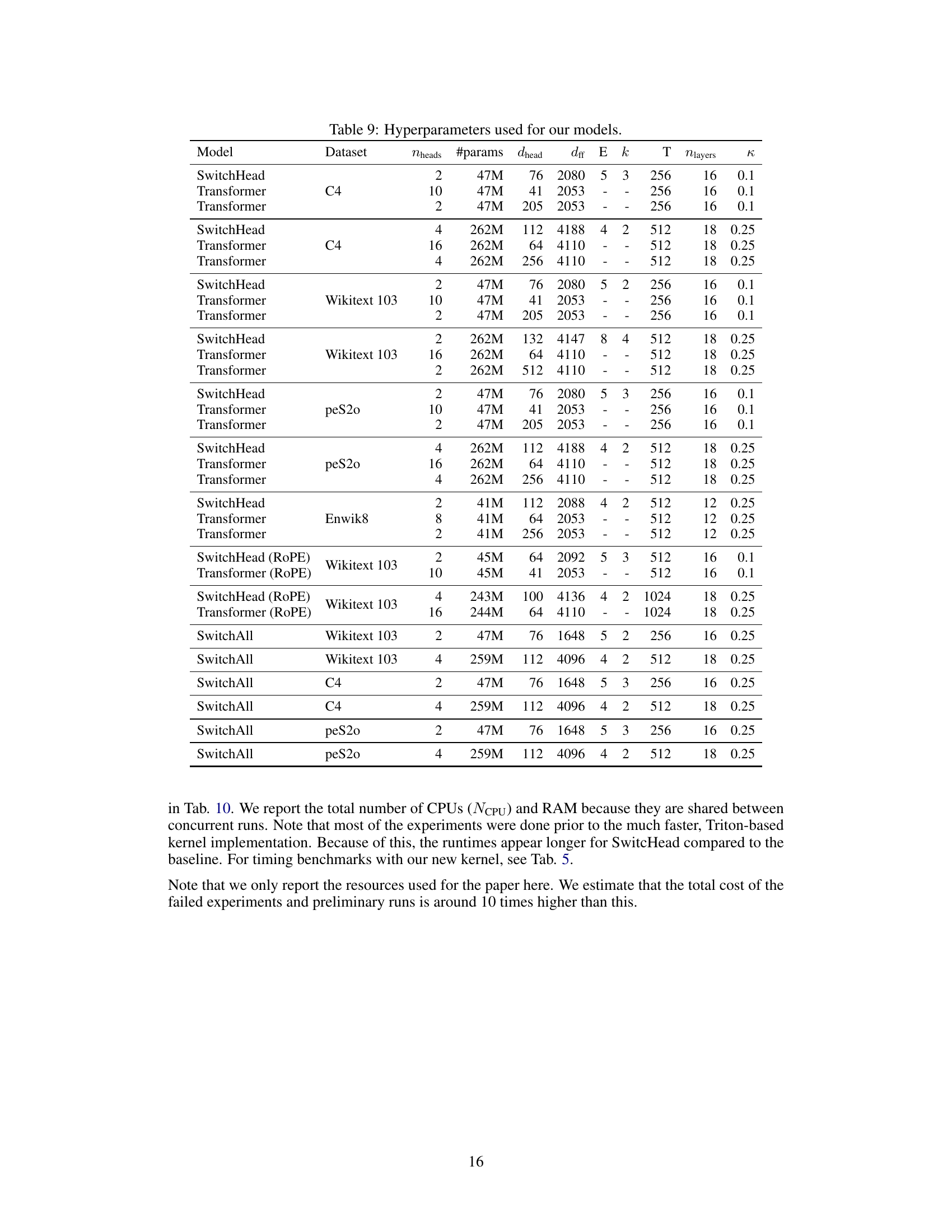
Resource-efficient Mixture of Experts (MoE) models aim to address the computational cost of large language models. A key challenge is balancing model performance with reduced resource consumption. Standard MoE approaches often focus on the feedforward layers, neglecting the computationally intensive self-attention mechanism. However, efficient attention is crucial for scalability. Innovative techniques like SwitchHead are designed to improve MoE efficiency in the attention layer itself, not just the feedforward parts, significantly decreasing the compute and memory requirements without sacrificing performance. These methods typically involve strategically selecting a subset of expert networks to process information for each input, reducing redundancy and computations. Careful design of the gating mechanism for expert selection is vital; non-competitive approaches, for instance, can contribute to stability during training and avoid the need for complex regularization. While showing great promise, research in resource-efficient MoEs remains an active area, with ongoing efforts to optimize expert allocation, routing strategies, and the overall architecture of the MoE models for improved efficiency and scalability on various hardware platforms. The future will likely see even more sophisticated techniques combining different MoE approaches with other optimization methods for further performance gains.
SwitchAll Transformer#
The concept of a “SwitchAll Transformer” represents a significant advancement in efficient Transformer architecture. By extending the Mixture-of-Experts (MoE) approach beyond the feedforward layers (as seen in many existing MoE models) to encompass the attention mechanism itself, SwitchAll aims for substantial resource reduction. This is achieved by employing a novel MoE strategy within the attention layer, possibly termed ‘SwitchHead’, to selectively activate only a subset of experts at any given time, reducing compute and memory demands. The key innovation lies in its ability to drastically decrease the number of attention matrices that need to be calculated and stored, leading to considerable speedups, especially with increased sequence lengths. The core claim is that SwitchAll can match the performance of a standard Transformer with significantly fewer resources, proving particularly beneficial for large language models which are computationally expensive to train and deploy. The performance gains come with potential drawbacks, such as the complexity of training and the potential for instability, underscoring the need for careful design and training strategies. It remains important to analyze the attention maps produced by SwitchAll to verify the quality of the attention mechanism and explore the interpretability of expert selections. Finally, the long-term value depends on the feasibility and scalability of deploying this architecture in real-world applications. The paper should provide an extensive quantitative evaluation against standard benchmarks with detailed comparison in terms of speed, memory consumption and downstream performance to determine if it truly is as efficient as promised.
Zero-Shot Evaluation#
Zero-shot evaluation is a crucial aspect of evaluating the generalization capabilities of large language models (LLMs). It assesses the model’s performance on tasks it has never explicitly trained on, providing insights into its ability to transfer knowledge and adapt to new situations. This is particularly important because real-world applications rarely involve tasks seen during training. A strong zero-shot performance suggests the model has learned underlying principles and representations rather than memorizing specific examples. This evaluation typically involves providing the LLM with a brief description of the task or a few examples, without fine-tuning, and measuring its success against a benchmark. The results offer a gauge of a model’s inherent understanding and its potential for broader applicability. While zero-shot performance is a valuable metric, it’s important to consider its limitations. The prompts used significantly impact the outcome, and the success may heavily depend on the specific design of the evaluation task. Therefore, careful prompt engineering and robust benchmarking methods are essential to obtain meaningful and reliable results, enabling a more thorough understanding of the LLM’s true potential and limitations outside its training data.
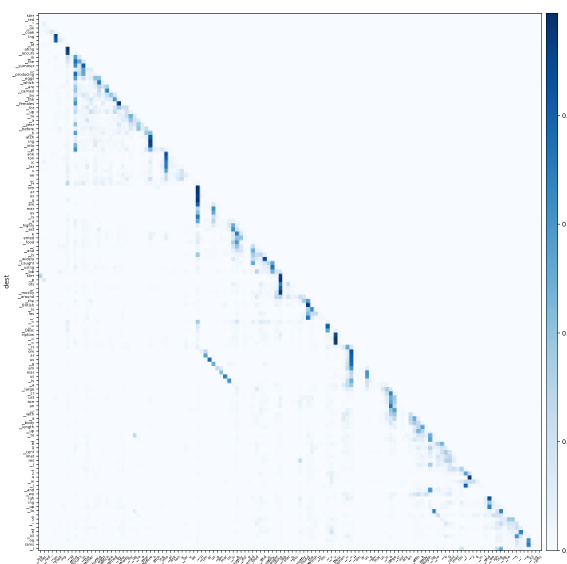
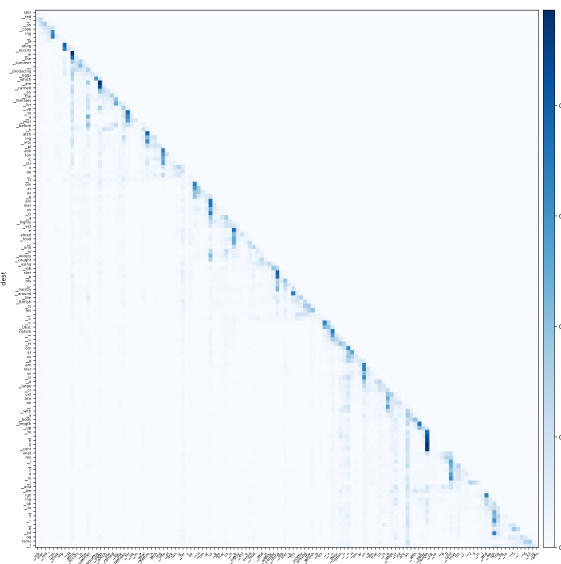
Interpretable Attention#
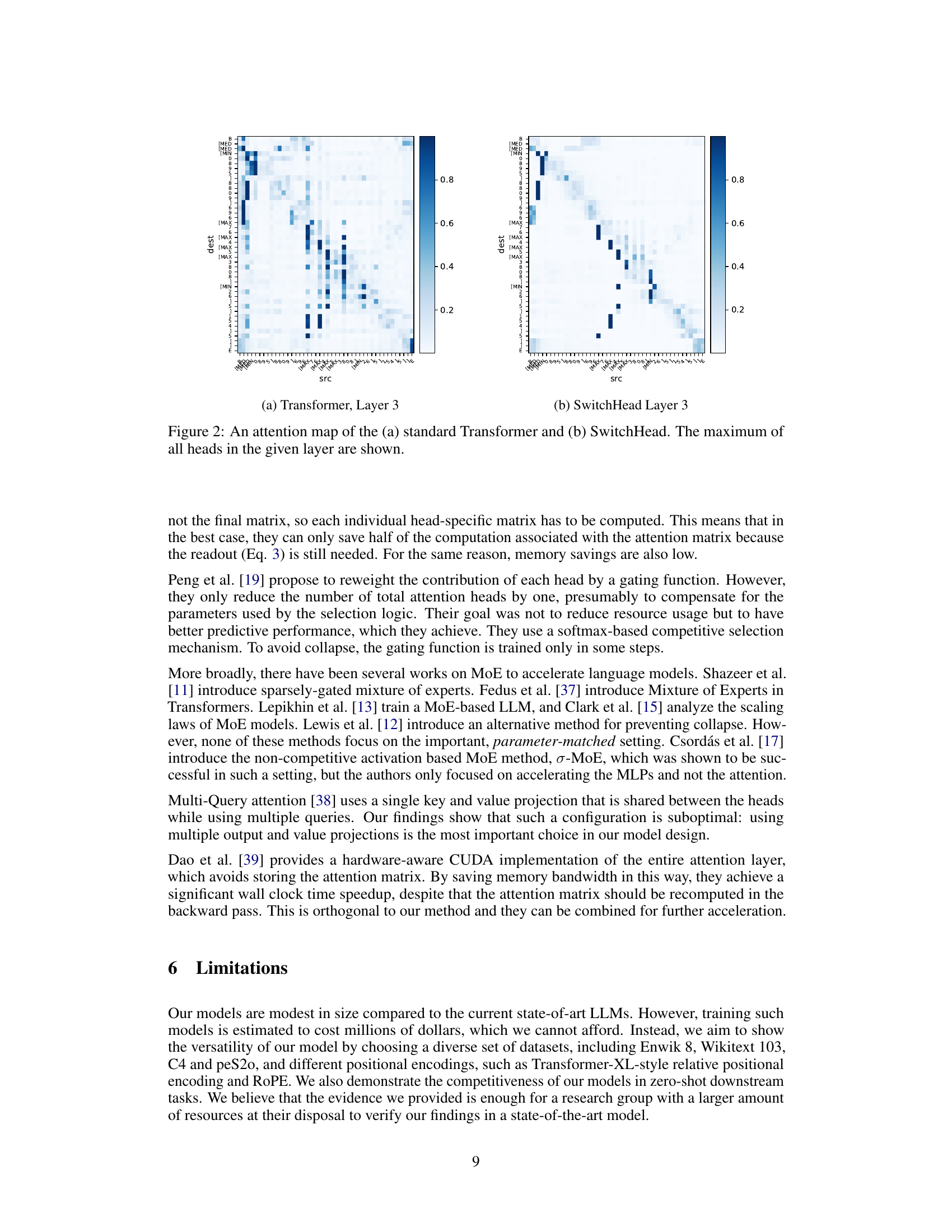
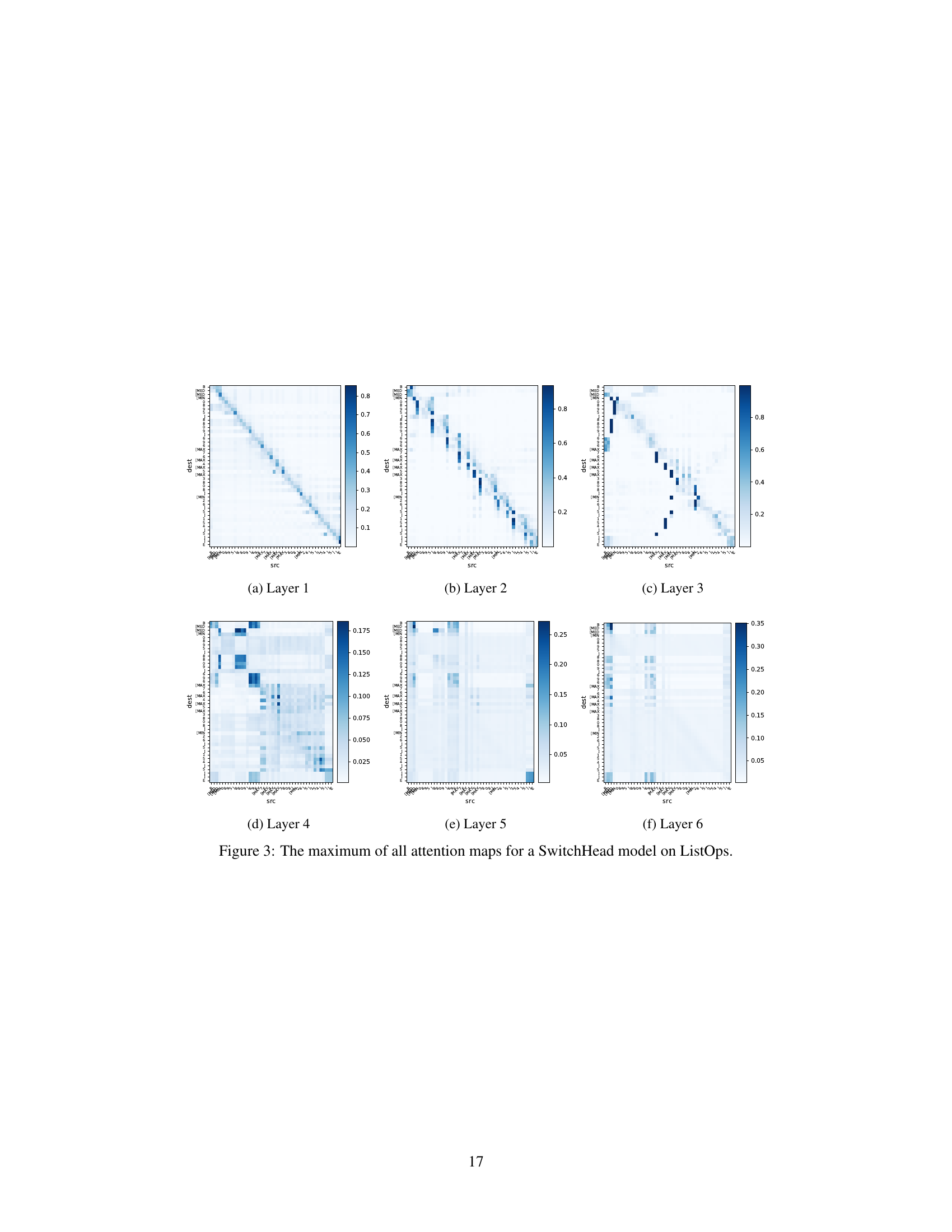
Interpretable attention mechanisms are crucial for understanding how neural networks process information, especially in complex tasks like natural language processing. The ability to peer into the attention weights and see which parts of an input sequence influence other parts is valuable for both debugging and gaining insights into the model’s reasoning. Current research is actively exploring methods to improve the interpretability of attention, such as visualizing attention maps, analyzing activation patterns, and developing techniques for generating human-readable explanations. These methods aim to provide a more intuitive understanding of how a model makes decisions. However, the challenge remains in balancing interpretability with model performance. Often, simplification strategies used to improve interpretability can compromise a model’s accuracy or efficiency. A key area of focus is the development of methods that offer both high performance and high interpretability, allowing for a deeper understanding of the model’s inner workings without sacrificing its predictive capabilities. The field is continuously evolving, with new approaches and techniques constantly emerging to help bridge the gap between complex neural network architectures and human-understandable representations of their decision processes.
More visual insights#
More on figures

🔼 The figure shows a schematic of the SwitchHead architecture. It highlights the key components: independent heads, each with multiple experts for value and output projections. Crucially, each head only computes a single attention matrix, unlike standard Transformers. This design is central to SwitchHead’s efficiency gains.
read the caption
Figure 1: A schematic representation of SwitchHead. It consists of a few independent heads, each with multiple experts for value and output projections. Each head has a single attention matrix.
🔼 The figure shows a schematic of SwitchHead, a novel Mixture-of-Experts (MoE) method for the attention layer in Transformer networks. It highlights the key components: independent heads, multiple experts for value and output projections within each head, and a single attention matrix per head. This design enables SwitchHead to compute fewer attention matrices compared to standard Transformers, leading to reduced computational and memory requirements.
read the caption
Figure 1: A schematic representation of SwitchHead. It consists of a few independent heads, each with multiple experts for value and output projections. Each head has a single attention matrix.

🔼 The figure is a schematic illustrating the architecture of SwitchHead, a novel Mixture of Experts (MoE) method for the attention layer in Transformer networks. It highlights the key components: independent heads, each with multiple experts for value and output projections, and a single attention matrix per head. This design allows for efficient computation by selectively activating only a subset of experts, thus reducing the number of attention matrices that need to be computed and stored.
read the caption
Figure 1: A schematic representation of SwitchHead. It consists of a few independent heads, each with multiple experts for value and output projections. Each head has a single attention matrix.
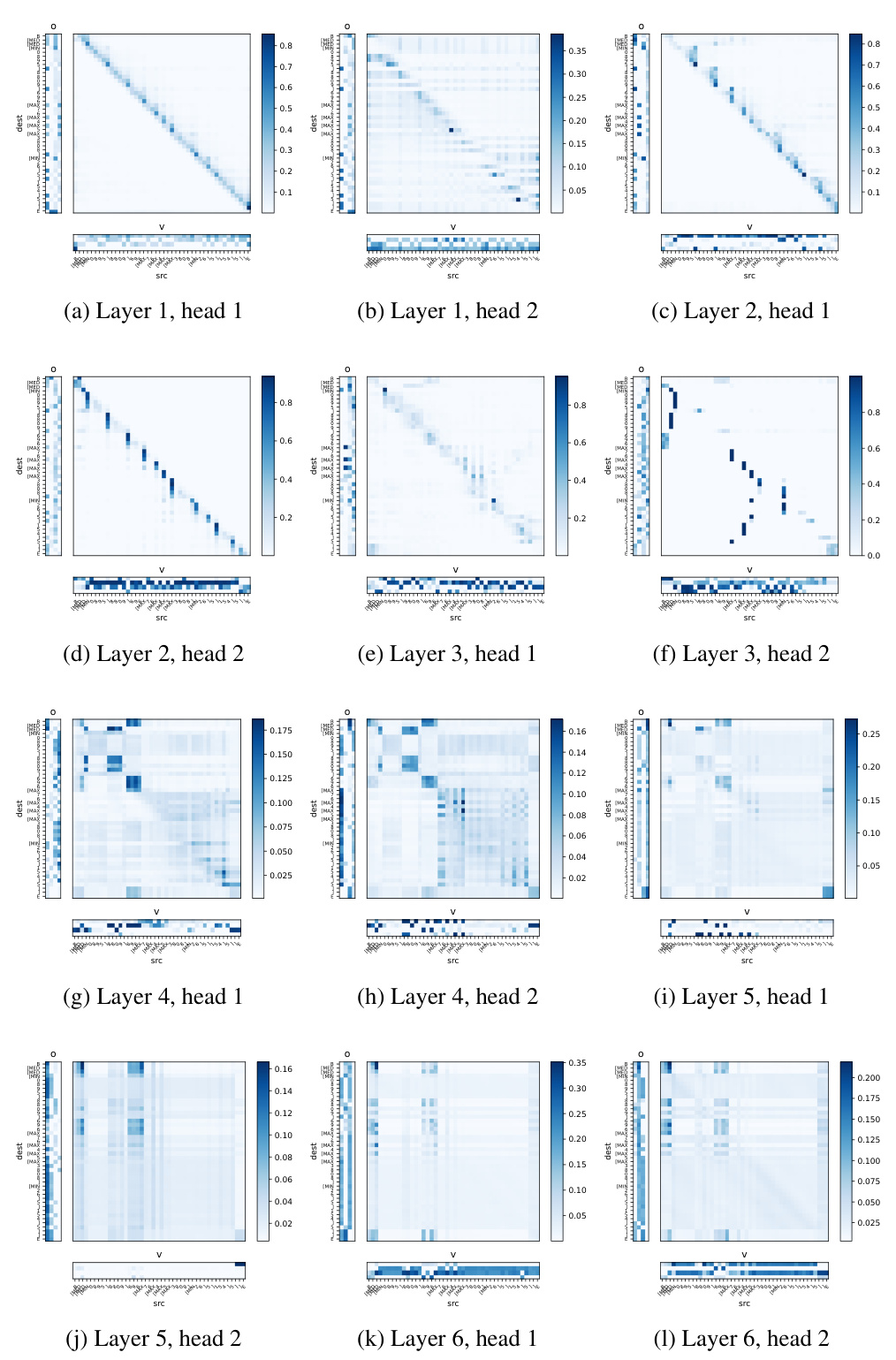
🔼 The figure illustrates the architecture of SwitchHead, a novel Mixture-of-Experts (MoE) method for the attention layer in Transformer models. It shows that SwitchHead comprises several independent heads, each of which has multiple expert networks for processing values and generating outputs. Importantly, each head only uses one attention matrix, which is a key element in reducing the computational cost compared to standard Transformer architectures. The selection logic determines which expert networks are used based on the input data.
read the caption
Figure 1: A schematic representation of SwitchHead. It consists of a few independent heads, each with multiple experts for value and output projections. Each head has a single attention matrix.
🔼 The figure shows a simplified illustration of the SwitchHead architecture. It consists of multiple independent heads, each of which has multiple experts for value and output projections. Each head has one attention matrix, which is calculated only once per head, regardless of the number of experts. The selection logic determines which expert is activated during the forward and backward passes, allowing for resource reduction.
read the caption
Figure 1: A schematic representation of SwitchHead. It consists of a few independent heads, each with multiple experts for value and output projections. Each head has a single attention matrix.

🔼 The figure is a schematic diagram showing the architecture of SwitchHead, a novel Mixture-of-Experts (MoE) method for accelerating Transformer self-attention layers. It illustrates how SwitchHead uses multiple independent heads, each with several expert networks for processing value and output projections. Crucially, it highlights that each head only requires a single attention matrix, significantly reducing computational costs compared to traditional Transformers.
read the caption
Figure 1: A schematic representation of SwitchHead. It consists of a few independent heads, each with multiple experts for value and output projections. Each head has a single attention matrix.
🔼 The figure shows a simplified diagram of the SwitchHead architecture. It illustrates how several independent heads process information, each utilizing multiple expert networks for value and output projections. Importantly, each head only computes a single attention matrix, rather than multiple matrices as in standard Transformer models, leading to computational savings.
read the caption
Figure 1: A schematic representation of SwitchHead. It consists of a few independent heads, each with multiple experts for value and output projections. Each head has a single attention matrix.

🔼 The figure shows a schematic of the SwitchHead architecture. It highlights the core components: independent heads, each with multiple experts for value and output projections. A key feature is that each head uses a single attention matrix, unlike traditional Transformers which compute multiple attention matrices per head. The experts are used to project the values and outputs, reducing the computational cost while aiming to maintain the quality of the attention mechanism. The selection logic determines which experts are used for a given head, allowing for efficient computation of the attention mechanism.
read the caption
Figure 1: A schematic representation of SwitchHead. It consists of a few independent heads, each with multiple experts for value and output projections. Each head has a single attention matrix.
More on tables
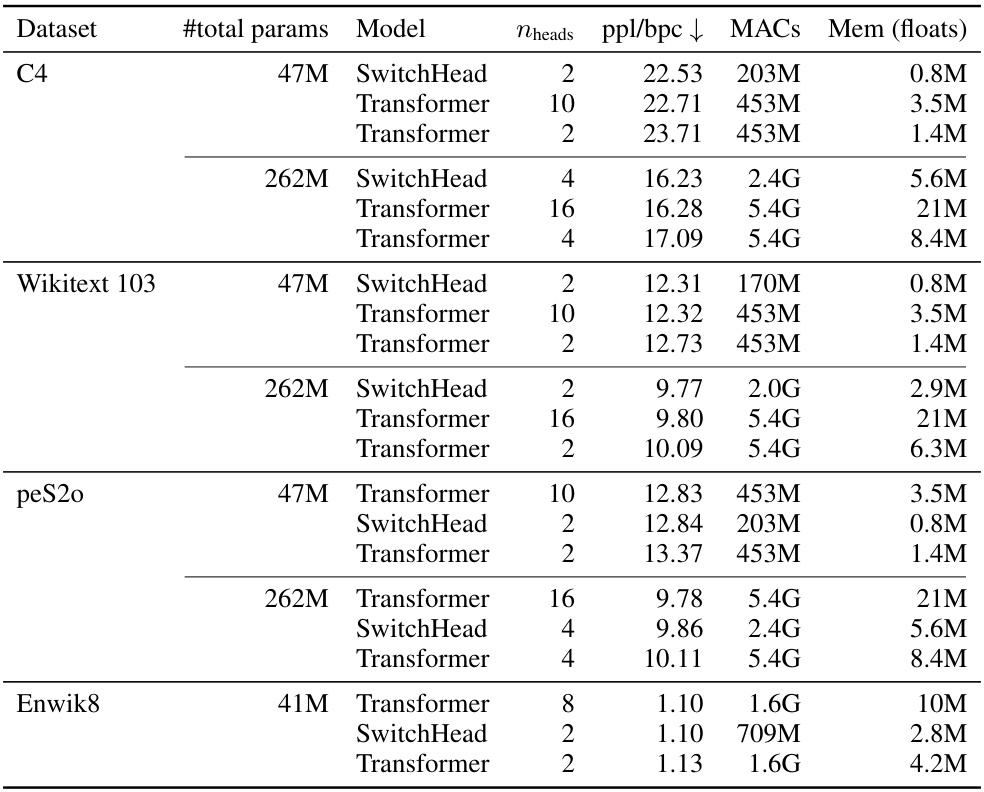
🔼 This table compares the performance of SwitchHead against various Mixture of Attention (MoA) models and a standard Transformer on the Wikitext 103 dataset. It demonstrates that SwitchHead achieves comparable or better perplexity with significantly less compute and memory usage than both MoA and the standard Transformer.
read the caption
Table 1: Performance of SwitchHead compared to different MoA variants. MoA can outperform the baseline, but only at a price of using significantly more compute and memory. Also, SwitchHead outperforms the baseline dense Transformer. These results are on Wikitext 103. Table sorted by model perplexity.
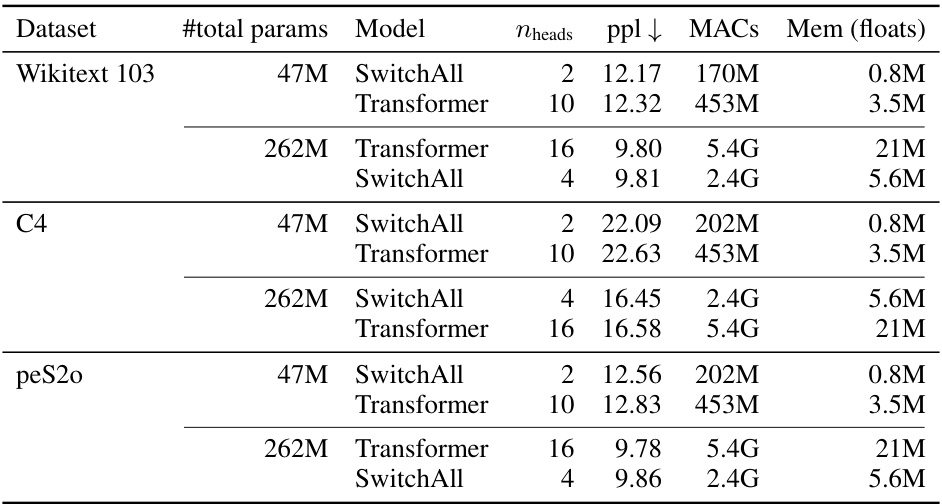
🔼 This table compares the performance of SwitchHead against various Mixture of Attention Heads (MoA) models and a standard Transformer model on the Wikitext 103 dataset. It highlights that while MoA can sometimes achieve slightly better perplexity scores, it requires significantly more computational resources (MACs and memory). SwitchHead consistently outperforms the standard Transformer while using substantially less compute and memory.
read the caption
Table 1: Performance of SwitchHead compared to different MoA variants. MoA can outperform the baseline, but only at a price of using significantly more compute and memory. Also, SwitchHead outperforms the baseline dense Transformer. These results are on Wikitext 103. Table sorted by model perplexity.

🔼 This table compares the performance of SwitchHead against various Mixture of Attention Heads (MoA) and a standard Transformer on the Wikitext-103 dataset. It demonstrates that SwitchHead achieves comparable or better perplexity (a lower value is better) than MoA and the standard Transformer while using significantly less compute and memory. The table highlights the trade-off between performance and resource consumption, showing that SwitchHead offers a better balance.
read the caption
Table 1: Performance of SwitchHead compared to different MoA variants. MoA can outperform the baseline, but only at a price of using significantly more compute and memory. Also, SwitchHead outperforms the baseline dense Transformer. These results are on Wikitext 103. Table sorted by model perplexity.
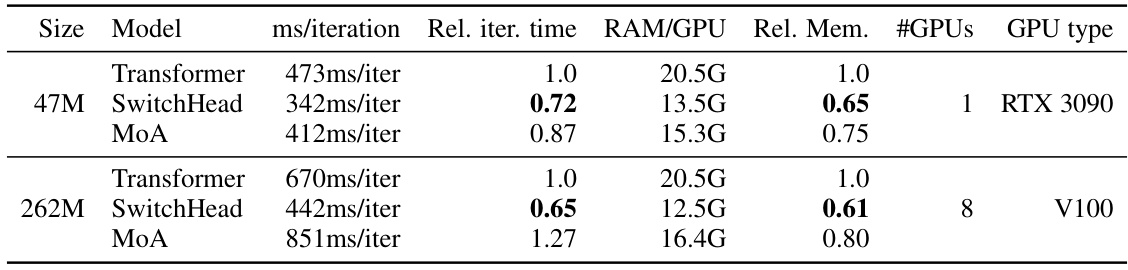
🔼 This table compares the performance of SwitchHead against various Mixture of Attention Heads (MoA) and a standard Transformer model on the Wikitext-103 dataset. It demonstrates SwitchHead’s superior performance in terms of perplexity, while using significantly less compute and memory compared to MoA and the baseline Transformer.
read the caption
Table 1: Performance of SwitchHead compared to different MoA variants. MoA can outperform the baseline, but only at a price of using significantly more compute and memory. Also, SwitchHead outperforms the baseline dense Transformer. These results are on Wikitext 103. Table sorted by model perplexity.
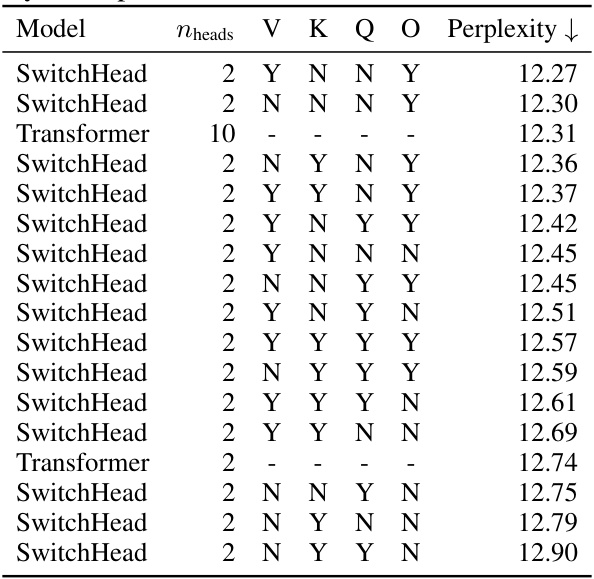
🔼 This table compares the performance of SwitchHead against various Mixture of Attention Heads (MoA) models and a standard Transformer on the Wikitext-103 dataset. It shows that while MoA can sometimes achieve slightly better perplexity, it requires significantly more compute and memory resources than SwitchHead. Importantly, SwitchHead matches or exceeds the performance of the standard Transformer baseline while using substantially less compute and memory.
read the caption
Table 1: Performance of SwitchHead compared to different MoA variants. MoA can outperform the baseline, but only at a price of using significantly more compute and memory. Also, SwitchHead outperforms the baseline dense Transformer. These results are on Wikitext 103. Table sorted by model perplexity.

🔼 This table compares the performance of SwitchHead against different Mixture of Attention Heads (MoA) variants and a standard Transformer on the Wikitext-103 dataset. It demonstrates that SwitchHead achieves comparable or better perplexity (a measure of language model accuracy) while using significantly less compute and memory than MoA and the baseline Transformer.
read the caption
Table 1: Performance of SwitchHead compared to different MoA variants. MoA can outperform the baseline, but only at a price of using significantly more compute and memory. Also, SwitchHead outperforms the baseline dense Transformer. These results are on Wikitext 103. Table sorted by model perplexity.
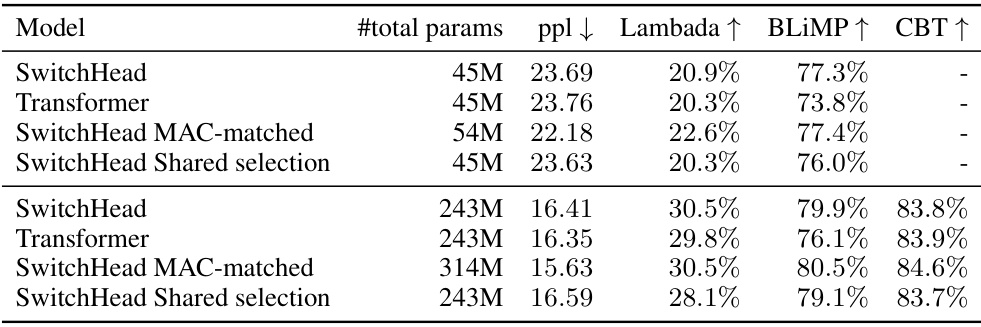
🔼 This table compares the performance of SwitchHead against various Mixture of Attention Heads (MoA) models and a standard Transformer baseline on the Wikitext-103 dataset. The comparison is done in a parameter-matched setting, meaning the models have roughly the same number of parameters. The table shows that SwitchHead achieves comparable or better perplexity (a measure of language model performance) than MoA and the baseline Transformer while using significantly less compute and memory resources.
read the caption
Table 1: Performance of SwitchHead compared to different MoA variants. MoA can outperform the baseline, but only at a price of using significantly more compute and memory. Also, SwitchHead outperforms the baseline dense Transformer. These results are on Wikitext 103. Table sorted by model perplexity.
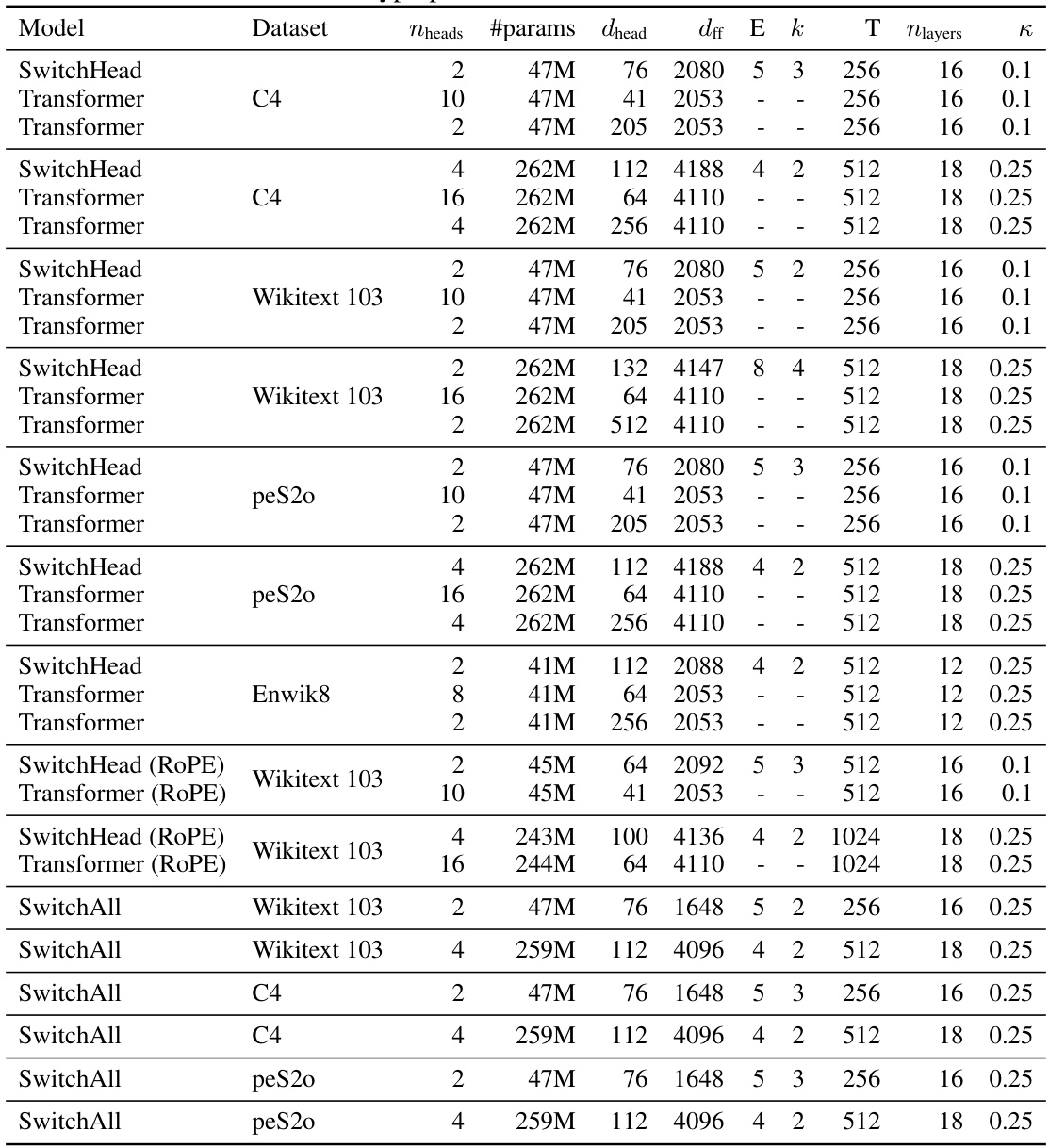
🔼 This table compares the performance of SwitchHead against various Mixture of Attention Heads (MoA) models and a standard Transformer on the Wikitext 103 dataset. It demonstrates that SwitchHead achieves comparable or better performance than MoA and the baseline Transformer while using significantly less compute and memory. The models are sorted by their perplexity, a measure of language model performance.
read the caption
Table 1: Performance of SwitchHead compared to different MoA variants. MoA can outperform the baseline, but only at a price of using significantly more compute and memory. Also, SwitchHead outperforms the baseline dense Transformer. These results are on Wikitext 103. Table sorted by model perplexity.

🔼 This table compares the performance of SwitchHead against various Mixture of Attention Heads (MoA) models and a standard Transformer model on the Wikitext 103 dataset. It demonstrates that SwitchHead achieves comparable or better performance than other methods while using significantly less compute and memory. The table is sorted by model perplexity, a measure of language model performance.
read the caption
Table 1: Performance of SwitchHead compared to different MoA variants. MoA can outperform the baseline, but only at a price of using significantly more compute and memory. Also, SwitchHead outperforms the baseline dense Transformer. These results are on Wikitext 103. Table sorted by model perplexity.
Full paper#