TL;DR#
Current model merging methods often struggle with interference between models and performance degradation due to heterogeneous test data. These methods usually fail to fully leverage both shared and exclusive knowledge across different models, leading to suboptimal results.
Twin-Merging proposes a two-stage approach: first, it modularizes knowledge into shared and exclusive components, compressing exclusive knowledge for efficiency; second, it dynamically merges this modularized knowledge based on input data. Extensive experiments demonstrate substantial performance improvements across a range of language and vision tasks, exceeding the fine-tuned upper bound on generative tasks. The method is highly adaptable to diverse data and scales effectively, showcasing its potential for real-world deployment.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI model merging and multi-task learning. It addresses the critical challenges of model interference and data heterogeneity, offering a novel, efficient solution with demonstrably improved performance. The proposed method is scalable and adaptable, opening up new avenues for research in resource-constrained environments and diverse real-world applications. Furthermore, the paper’s findings on the roles of shared and exclusive task-specific knowledge provide valuable insights for future model fusion research. This impacts the AI community, as its results have the potential to revolutionize both the performance and deployment of large language models.
Visual Insights#

🔼 This figure demonstrates the effectiveness of Twin-Merging in terms of both performance and parameter efficiency. Subfigure (a) shows the average performance on generative tasks plotted against the number of parameters. Twin-Merging is compared to several other model merging baselines, with the size of the circles indicating different storage sizes. Subfigure (b) presents a comparison of the absolute accuracy across various individual tasks for both NLP benchmarks (using RoBERTa and Qwen models) covering discriminative and generative tasks. The figure visually highlights that Twin-Merging achieves better performance with improved parameter efficiency compared to other baselines.
read the caption
Figure 2: The effectiveness of Twin-Merging in terms of performance and parameter-efficiency.

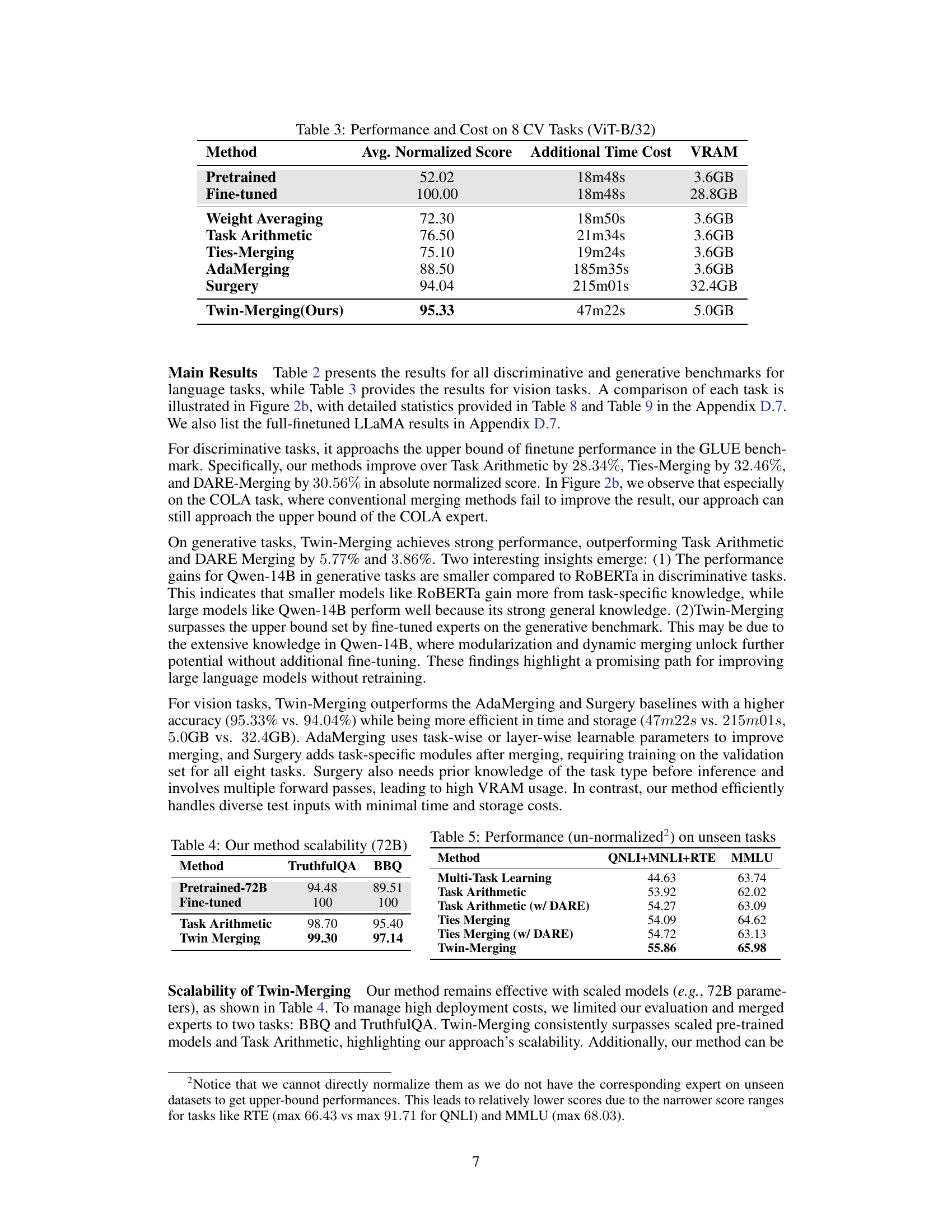
🔼 This table presents the results of the Twin-Merging method and its baselines on eight discriminative tasks using the RoBERTa model and four generative tasks using the Qwen-14B model. It shows the average normalized scores for each method, allowing for comparison across different tasks and highlighting the performance improvements achieved by Twin-Merging compared to existing methods. The ‘Pretrained’ and ‘Fine-tuned’ rows provide the lower and upper bounds for performance, respectively.
read the caption
Table 2: Performance on 8 Discriminative Tasks (ROBERTa) and 4 Generative Tasks (Qwen-14B)
In-depth insights#
Modular Expertise#
The concept of “Modular Expertise” in the context of large language models (LLMs) refers to the decomposition of an LLM’s knowledge into smaller, independent modules. Each module specializes in a specific task or area of expertise, enhancing efficiency and reducing interference between different tasks. This modularity allows for a more flexible and adaptable system, capable of handling diverse test data and minimizing performance degradation in a one-size-fits-all model. Twin-Merging, as described in the paper, leverages this modularity by first separating knowledge into shared and exclusive components and then dynamically merging these components during inference based on the specific input. This approach is crucial because directly merging all expertise can be detrimental due to conflicting or irrelevant information. The effectiveness of Twin-Merging hinges on the successful modularization of expertise, resulting in improved efficiency and adaptability for various tasks and datasets.
Dynamic Merging#
The concept of “Dynamic Merging” in the context of large language models (LLMs) presents a compelling approach to overcome the limitations of static model merging techniques. Instead of pre-determining fixed weights for combining multiple models, dynamic merging intelligently adjusts the contribution of each component model based on the specific input. This adaptability addresses the heterogeneity of real-world data and significantly improves performance, particularly when dealing with diverse or unseen test data. The key is the conditional combination of shared and exclusive knowledge. A central component is a ‘router’ network that processes the input to determine the optimal weights for merging shared and task-specific expertise. This approach enhances both efficiency and accuracy, potentially reducing the need for extensive retraining and resource consumption. The resulting model exhibits superior flexibility and adaptation to varying inputs, bridging the gap between the performance of individual expert models and those merged statically. Dynamic merging is a paradigm shift towards more intelligent and efficient model integration for multi-task learning scenarios.
Knowledge Disentanglement#
The concept of “Knowledge Disentanglement” in the context of model merging centers on the crucial idea of separating shared and task-specific knowledge within individual models. This is a significant departure from traditional methods that treat model parameters holistically. By modularizing knowledge into shared components (applicable across multiple tasks) and exclusive components (unique to a single task), the merging process becomes more precise and less susceptible to interference. The core insight lies in recognizing that directly merging all knowledge from multiple models often results in performance degradation due to redundancy and conflicts. Disentanglement addresses this by strategically isolating and compressing exclusive knowledge into sparse vectors, thereby enhancing efficiency and reducing the adverse effects of conflicting information. This process of knowledge modularization is vital for effective integration, paving the way for more accurate and adaptive multi-task models.
Performance Gains#
The research demonstrates significant performance gains across various tasks. Twin-Merging consistently outperforms traditional methods, achieving an average improvement of 28.34% in absolute normalized scores for discriminative tasks. This substantial improvement highlights the effectiveness of the proposed knowledge modularization and dynamic merging strategies. Notably, Twin-Merging even surpasses the fine-tuned upper bound on generative tasks, showcasing its potential to unlock capabilities beyond those achievable through standard fine-tuning. The gains are consistent across different datasets and model architectures, emphasizing the generalizability and robustness of the approach. Parameter efficiency is also a key advantage, with minimal performance degradation even at high sparsity rates, making Twin-Merging a practical solution for resource-constrained environments. These findings underscore the value of disentangling shared and task-specific knowledge for improved model merging and highlight the benefits of dynamic knowledge integration for enhanced adaptability and performance.
Future Directions#
Future research could explore several promising avenues. Developing a more robust theoretical foundation for model merging is crucial; understanding why and when weight interpolation succeeds is key to improving performance and generalizability. Investigating different types of knowledge beyond shared and exclusive (e.g., irrelevant or even harmful knowledge) will refine the knowledge modularization process. Expanding the dynamic merging mechanism beyond simple linear combinations could unlock even greater performance gains by incorporating more sophisticated methods that take context and data heterogeneity into account. Finally, applying these techniques to broader domains (beyond NLP and CV) and exploring their efficacy on even larger models are vital steps towards unlocking the true potential of model merging.
More visual insights#
More on figures
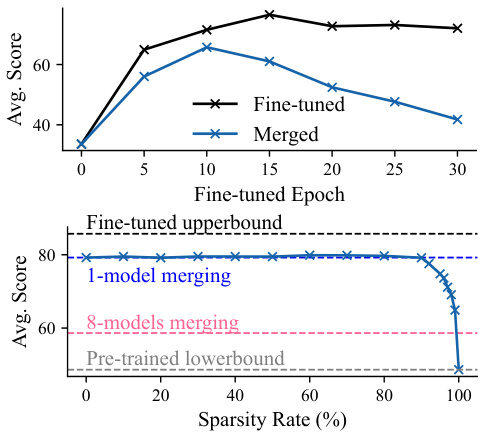
🔼 This figure shows two graphs illustrating the effects of different ratios of shared and exclusive knowledge on model merging performance. The top graph demonstrates the impact of shared knowledge by varying fine-tuned epochs. As the number of epochs increases, shared knowledge decreases, leading to a drop in merging performance despite good performance on individual tasks. This highlights the importance of shared knowledge in successful model merging. The bottom graph explores the impact of exclusive knowledge by varying the sparsity of task-specific weights when merging a single task-specific model. Even with high sparsity (99%), the single-merged model outperforms multi-model merging, showcasing the contribution of exclusive knowledge. These findings suggest that both shared and exclusive knowledge are crucial, but excessive exclusive knowledge can hinder merging performance.
read the caption
Figure 3: The impact of different ratios of shared knowledge and exclusive knowledge.

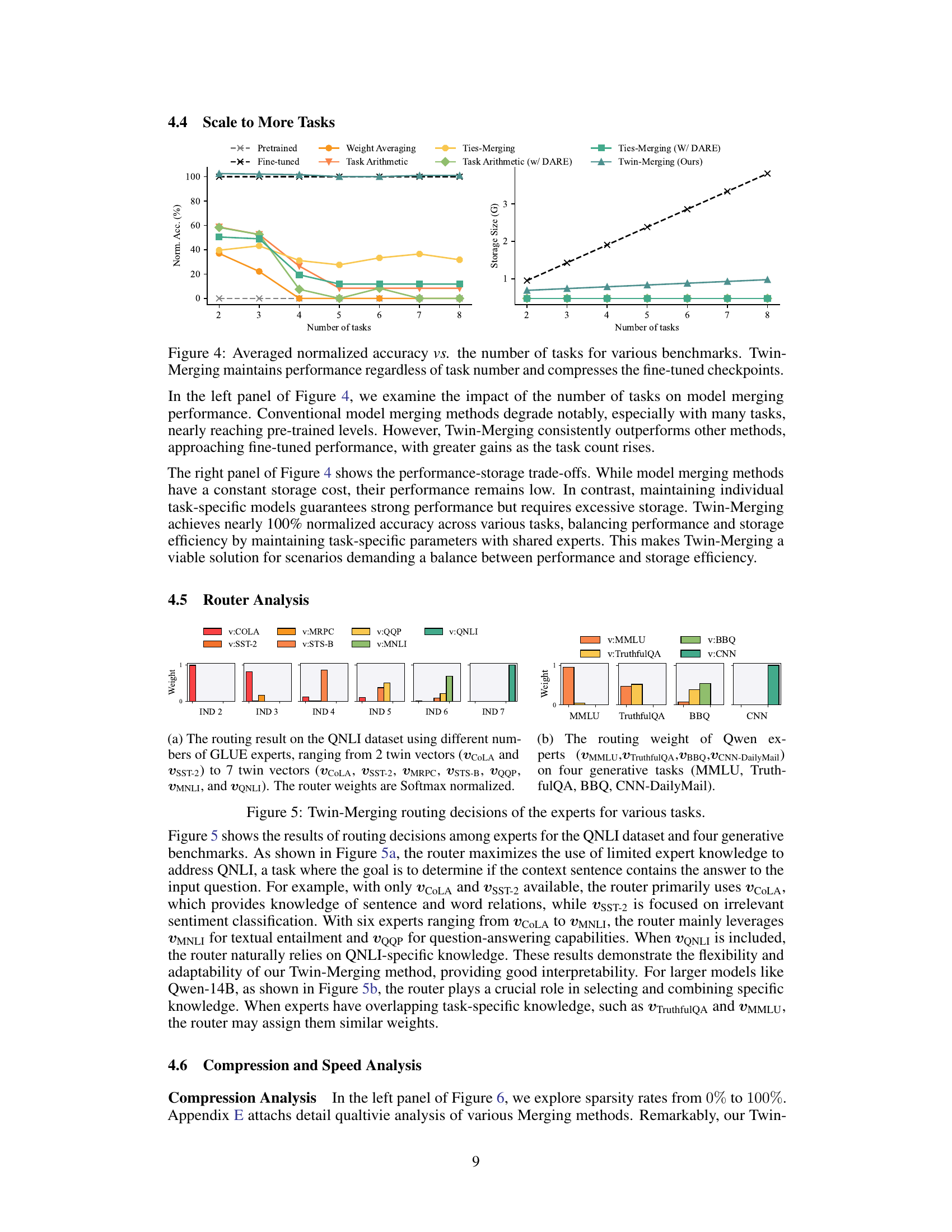
🔼 This figure shows two graphs. The left graph displays the average normalized accuracy against the number of tasks for different model merging methods. It demonstrates that Twin-Merging significantly outperforms other methods, maintaining high accuracy even as the number of tasks increases, while other methods’ accuracy significantly decreases. The right graph illustrates the trade-off between storage size and performance. It shows that while maintaining individual task-specific models offers high performance but demands excessive storage, Twin-Merging effectively balances performance and storage efficiency by leveraging shared experts and compression techniques.
read the caption
Figure 4: Averaged normalized accuracy vs. the number of tasks for various benchmarks. Twin-Merging maintains performance regardless of task number and compresses the fine-tuned checkpoints.

🔼 This figure visualizes the routing decisions made by the Twin-Merging model’s router for different tasks. The left panel shows the weight assigned to each expert (represented by different colors) for the QNLI task, demonstrating how the router dynamically combines knowledge from different experts based on the input. The right panel shows the weights for four generative tasks (MMLU, TruthfulQA, BBQ, CNN-DailyMail), highlighting how the router adapts its weighting scheme according to the task. The weights are normalized using softmax.
read the caption
Figure 5: Twin-Merging routing decisions of the experts for various tasks.
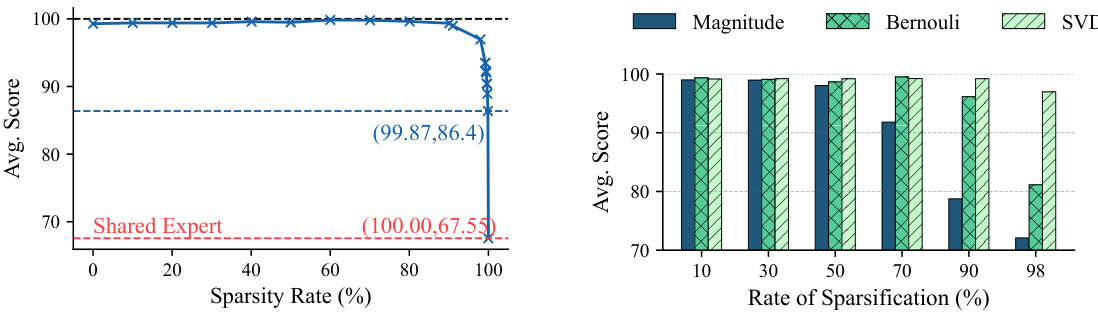
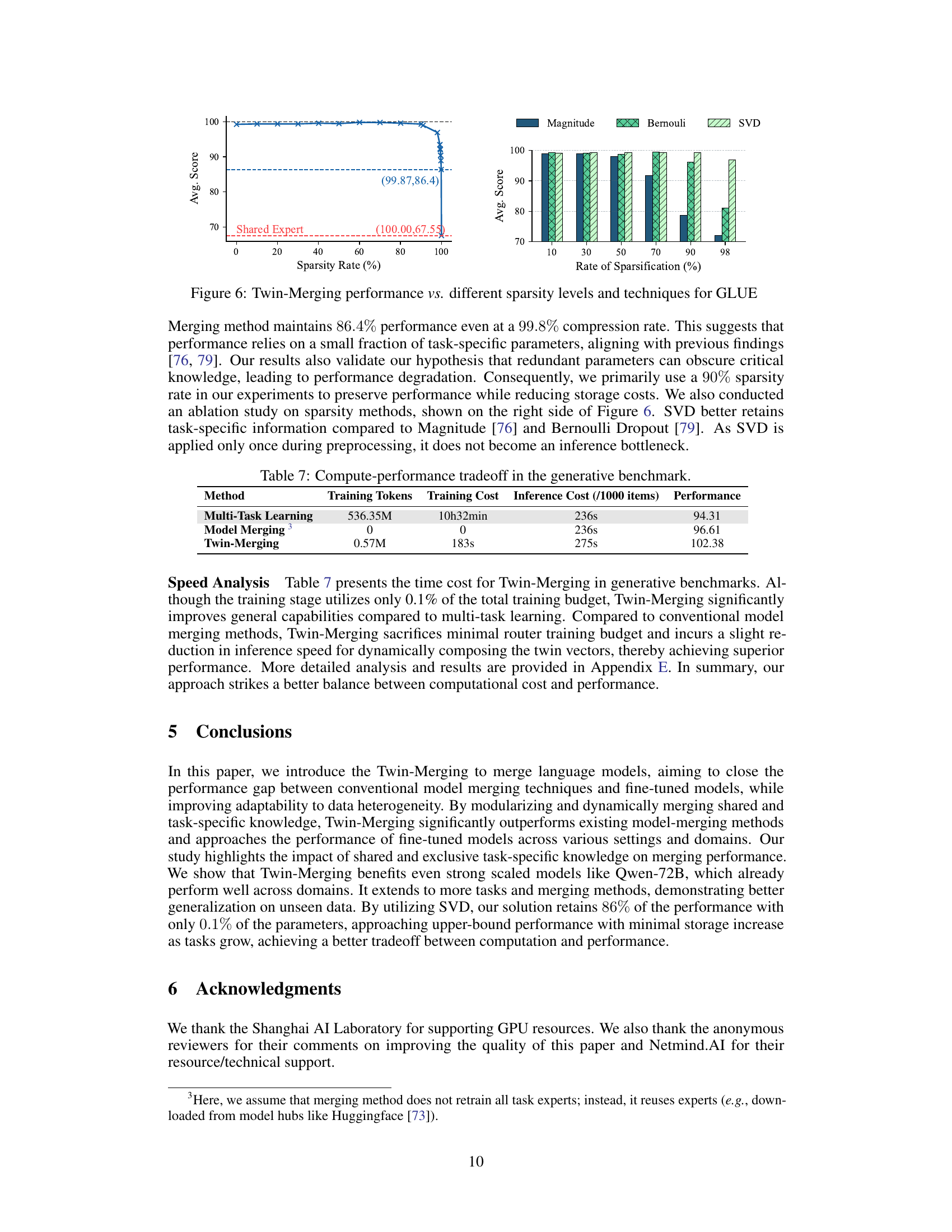
🔼 This figure shows the results of experiments on the impact of different sparsity rates and techniques on the performance of Twin-Merging on the GLUE benchmark. The left panel shows a line graph plotting the average score against the sparsity rate for Twin-Merging with a shared expert (red dashed line) and a fine-tuned model (black dashed line). It shows that performance is relatively stable until around 90% sparsity, after which performance drops significantly. The right panel shows a bar graph comparing the average scores for different sparsity rates across three different sparsification techniques: Magnitude, Bernoulli, and SVD. It shows that SVD generally outperforms the other two techniques.
read the caption
Figure 6: Twin-Merging performance vs. different sparsity levels and techniques for GLUE

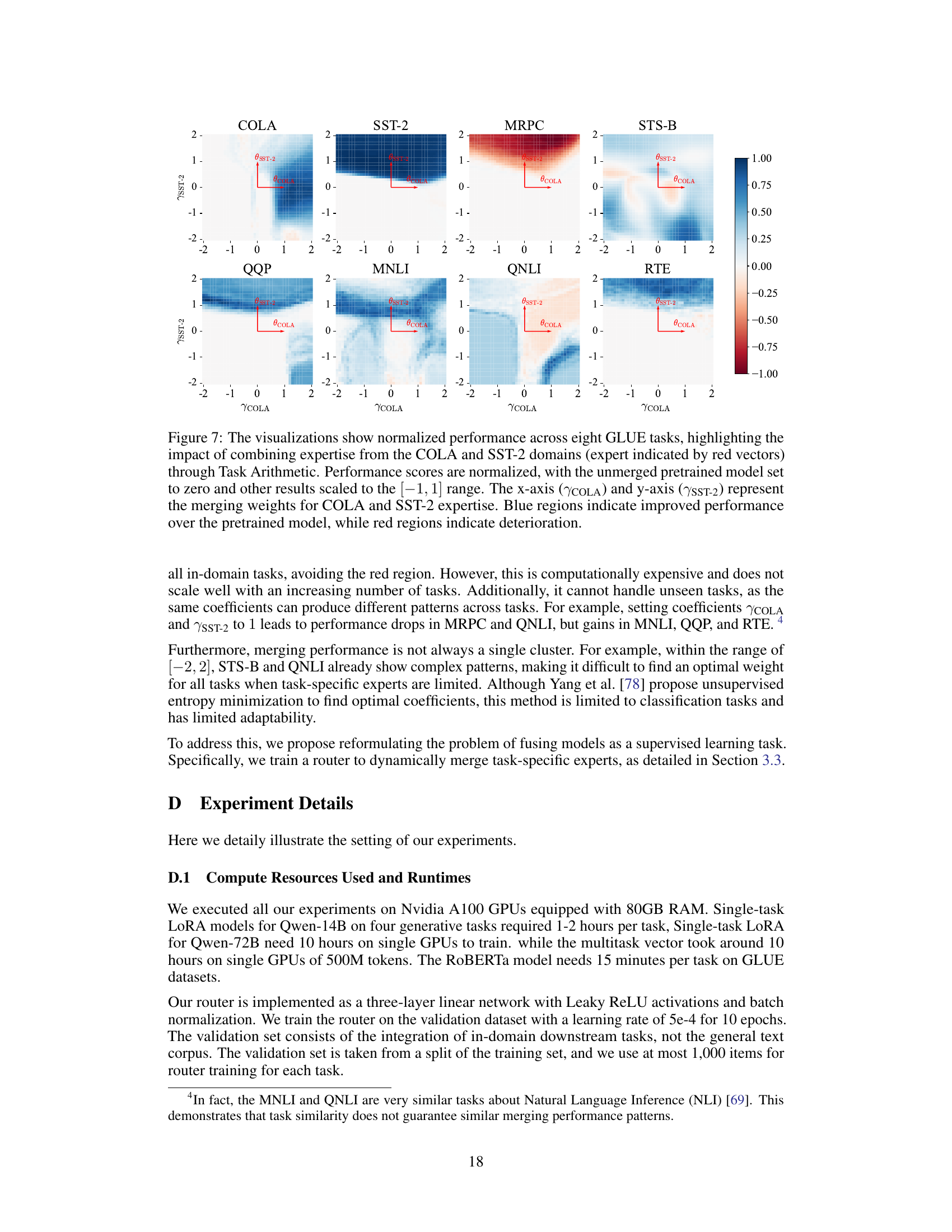
🔼 This figure visualizes the performance of Task Arithmetic on eight GLUE tasks by varying the weights of COLA and SST-2 experts. It shows how different combinations of these two experts impact performance on each task, highlighting areas where combining expertise is beneficial (blue) and detrimental (red). The visualization helps illustrate the complex interactions between different models and the challenges of finding optimal weights for model merging.
read the caption
Figure 7: The visualizations show normalized performance across eight GLUE tasks, highlighting the impact of combining expertise from the COLA and SST-2 domains (expert indicated by red vectors) through Task Arithmetic. Performance scores are normalized, with the unmerged pretrained model set to zero and other results scaled to the [-1,1] range. The x-axis (COLA) and y-axis (ysst-2) represent the merging weights for COLA and SST-2 expertise. Blue regions indicate improved performance over the pretrained model, while red regions indicate deterioration.
More on tables
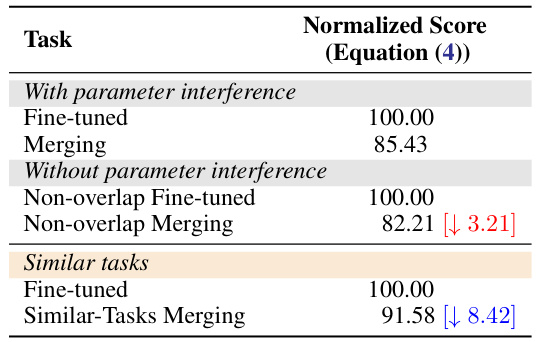
🔼 This table presents the results of two experiments designed to isolate the impact of parameter interference on model merging performance. The first experiment compared the performance of merging models trained on non-overlapping tasks (i.e., tasks with no shared parameters) versus fine-tuned individual models. The second experiment compared the performance of merging models trained on similar tasks to the performance of fine-tuned individual models. The results demonstrate that even without parameter interference, merging models still leads to performance degradation, indicating that other factors besides parameter interference are at play.
read the caption
Table 1: Merging without parameter interference and merging between similar tasks both cause performance degradation (Notice: these two experiments use different datasets).

🔼 This table presents the performance comparison of different model merging methods on 8 discriminative tasks using the RoBERTa model and 4 generative tasks using the Qwen-14B model. It includes the performance of pretrained and fine-tuned models as baselines, and several other merging methods such as weight averaging, task arithmetic, Ties-Merging, and DARE. The results are shown in terms of the average normalized score, which is calculated by normalizing the scores of each task to the fine-tuned model’s performance on that task.
read the caption
Table 2: Performance on 8 Discriminative Tasks (ROBERTa) and 4 Generative Tasks (Qwen-14B)

🔼 This table presents the performance comparison of different model merging methods on 8 discriminative tasks using the RoBERTa model and 4 generative tasks using the Qwen-14B model. The results are presented as average normalized scores, with the fine-tuned model performance serving as the upper bound (100.00) and the pre-trained model as the lower bound. The table highlights the performance improvement achieved by Twin-Merging compared to other merging methods.
read the caption
Table 2: Performance on 8 Discriminative Tasks (ROBERTa) and 4 Generative Tasks (Qwen-14B)
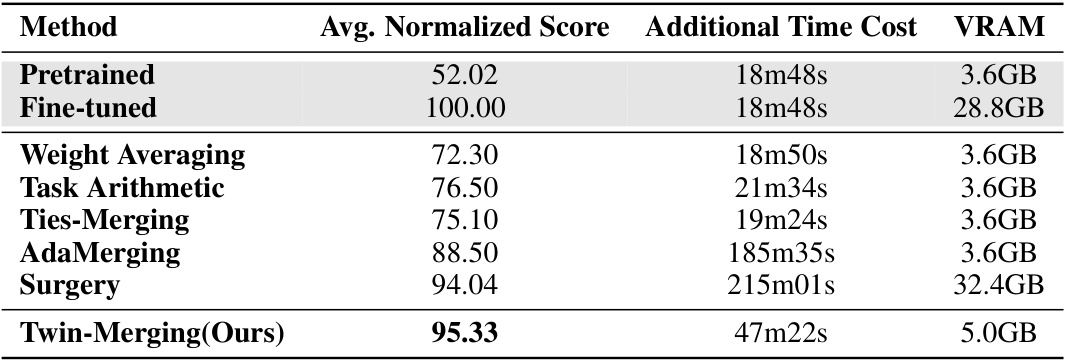
🔼 This table presents the results of experiments conducted on eight computer vision (CV) tasks using the ViT-B/32 model. It compares the average normalized score, additional time cost, and VRAM usage of various model merging methods, including the proposed Twin-Merging method, against baselines such as pretrained, fine-tuned, Weight Averaging, Task Arithmetic, Ties-Merging, AdaMerging, and Surgery. The results showcase the performance and efficiency gains of Twin-Merging compared to other methods.
read the caption
Table 3: Performance and Cost on 8 CV Tasks (ViT-B/32)
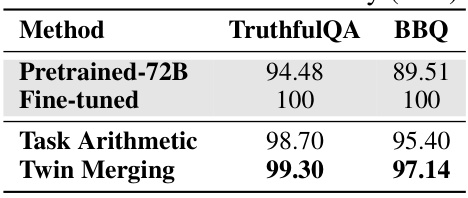
🔼 This table presents the results of experiments conducted to evaluate the scalability of the Twin-Merging method using a larger language model with 72 billion parameters. It shows the performance of the pretrained model, the fine-tuned model, Task Arithmetic, and Twin Merging on two tasks: TruthfulQA and BBQ. The results demonstrate the effectiveness of Twin-Merging in handling larger models, maintaining strong performance.
read the caption
Table 4: Our method scalability (72B)

🔼 This table presents the results of experiments conducted on unseen tasks, evaluating the performance of different model merging methods. The results are un-normalized because the corresponding expert models for these unseen tasks were not available. The table shows the average un-normalized scores for different methods on the QNLI+MNLI+RTE and MMLU benchmarks. The results demonstrate the generalization capabilities of the Twin-Merging method even in situations where the task-specific knowledge is limited.
read the caption
Table 5: Performance (un-normalized²) on unseen tasks

🔼 This table presents the results of ablation studies conducted on the Twin-Merging method. It shows the impact of different components of the method on the overall performance. By removing components like the dynamic experts or the shared expert, or by directly applying dynamic merging to a pre-trained model, the performance decreases significantly. This highlights the importance of all components of Twin-Merging in achieving its high performance. The results are reported for both RoBERTa and Qwen models, demonstrating that the observations hold across different model architectures.
read the caption
Table 6: Ablation study of Twin-Merging

🔼 This table compares the compute-performance tradeoff of three different methods for generative tasks: Multi-Task Learning, Model Merging, and Twin-Merging. It shows the number of training tokens used, the training cost (in terms of time), the inference cost (per 1000 items), and the performance achieved by each method. Twin-Merging demonstrates a significant performance improvement with minimal training cost and a slightly increased inference time compared to Multi-Task Learning and Model Merging.
read the caption
Table 7: Compute-performance tradeoff in the generative benchmark.

🔼 This table presents the results of different model merging methods on 8 discriminative tasks using the RoBERTa model and 4 generative tasks using the Qwen-14B model. It shows the average normalized scores for each method, along with the scores for the pretrained and fine-tuned models as a baseline for comparison. The average normalized score is calculated as the average of the normalized scores across all tasks, allowing for comparison across different tasks with potentially different scoring scales.
read the caption
Table 2: Performance on 8 Discriminative Tasks (ROBERTa) and 4 Generative Tasks (Qwen-14B)

🔼 This table presents a detailed comparison of the performance of various model merging methods across four generative tasks: MMLU, TruthfulQA, BBQ, and CNN-DailyMail. The average normalized scores are shown, with bold values indicating the best performance for each task and underlined values indicating the second-best performance. The table offers a more granular view of the results presented in Table 2, providing a deeper understanding of the relative strengths and weaknesses of different methods on different tasks.
read the caption
Table 9: The detail statistics of different merging performance on 4 generative tasks. Bold numbers indicate the best-averaging performance across different model merging methods. Underlines indicate the second best performance of each task across different model merging methods.

🔼 This table presents the average performance and inference time of two model merging methods, namely Task-Arithmetic and Twin-Merging, when using the LLaMA-7B model. It shows that Twin Merging achieves significantly higher average performance (88.18) compared to Task-Arithmetic (69.89), while only having a marginal increase in inference time (198s vs 186s). This highlights the effectiveness of Twin Merging in improving multi-task performance without a significant computational overhead.
read the caption
Table 10: Performance of LLaMA-7B
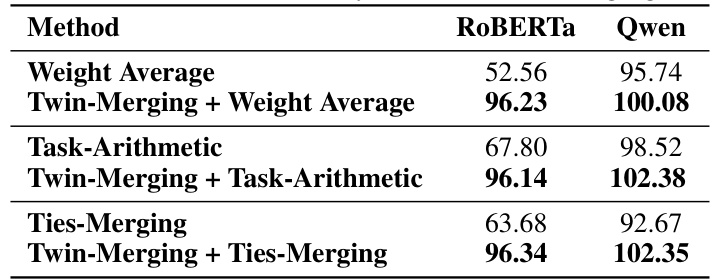
🔼 This table demonstrates the effectiveness of integrating Twin-Merging with other existing model merging methods. It shows that combining Twin-Merging with Weight Average, Task-Arithmetic, or Ties-Merging leads to significant performance improvements on both RoBERTa and Qwen models, indicating that Twin-Merging is a versatile method that can be combined with other techniques to further enhance model merging performance.
read the caption
Table 11: Our method extensibility to other model merging methods

🔼 This table shows the average normalized scores and inference times for three different model merging methods: Task-Arithmetic, Twin-Merging, and a group-wise variant of Twin-Merging. The group-wise variant is a modification of Twin-Merging that processes data in groups rather than individually, aiming for improved inference efficiency. The results indicate a tradeoff between accuracy and speed. While Twin-Merging achieves the highest accuracy, the group-wise variant offers a faster inference time, albeit with a slight reduction in accuracy compared to the standard Twin-Merging.
read the caption
Table 12: Performance of group-wise variant.
Full paper#