TL;DR#
Layout-to-image (L2I) generation, which involves creating images based on predefined layouts, has seen advancements but still faces challenges. Existing methods struggle with complex object descriptions and lack reliable evaluation metrics, particularly in open-vocabulary scenarios where the number of object types is not limited. This research directly addresses these issues.
The researchers propose a novel regional cross-attention module to improve L2I generation. This module enhances the representation of layout regions, leading to more accurate object generation even with intricate descriptions. They also introduce two new metrics: Crop CLIP Similarity and SAMIOU, specifically designed for evaluating open-vocabulary L2I performance. A user study confirms the reliability and effectiveness of these metrics. Overall, this work makes significant contributions by enhancing L2I generation capabilities and establishing robust evaluation strategies for open-vocabulary settings.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the limitations of existing layout-to-image generation methods that struggle with complex descriptions. By introducing a novel regional cross-attention module and proposing new evaluation metrics for open-vocabulary scenarios, it significantly improves the accuracy and reliability of generating images from rich layouts. This opens new avenues for research in open-vocabulary image synthesis and provides valuable insights into effective evaluation strategies. The user study further validates the proposed metrics, increasing the impact on the wider AI community.
Visual Insights#

🔼 This figure shows a comparison of layout-to-image generation results between the proposed method and four existing methods (BoxDiff, R&B, GLIGEN, and InstDiff). The input is a layout specifying the position and description of four mugs. The proposed method accurately generates the mugs according to their descriptions. In contrast, the existing methods make errors in generating the objects, demonstrating the superiority of the proposed method in handling complex object descriptions.
read the caption
Figure 1: The proposed method demonstrates the ability to accurately generate objects with complex descriptions in the correct locations while faithfully preserving the details specified in the text. In contrast, existing methods such as BoxDiff [57], R&B [56], GLIGEN [25], and InstDiff [54] struggle with the complex object descriptions, leading to errors in the generated objects.
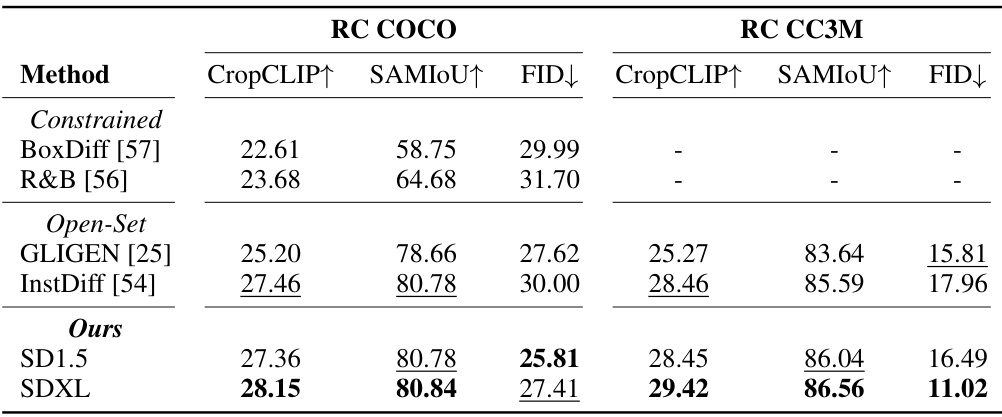
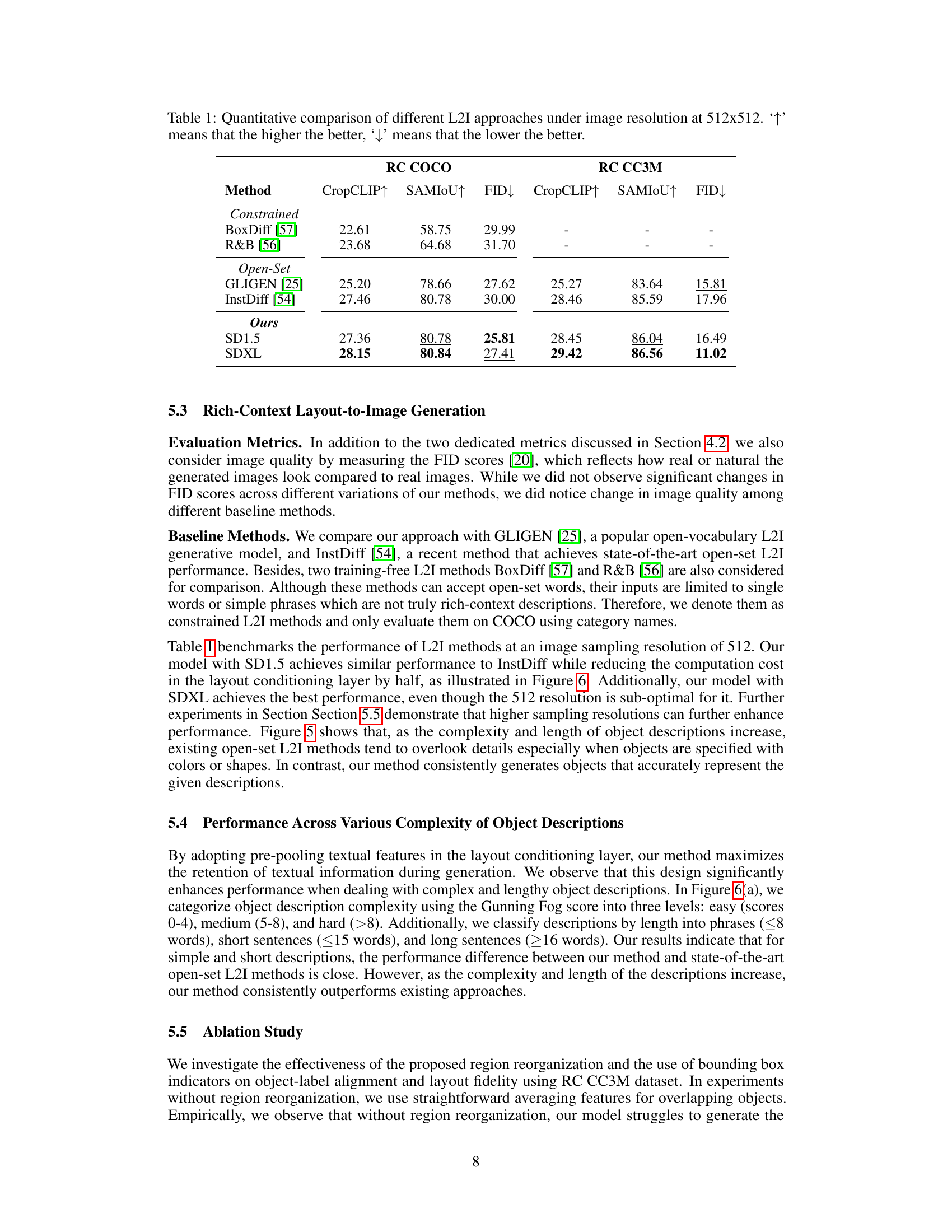
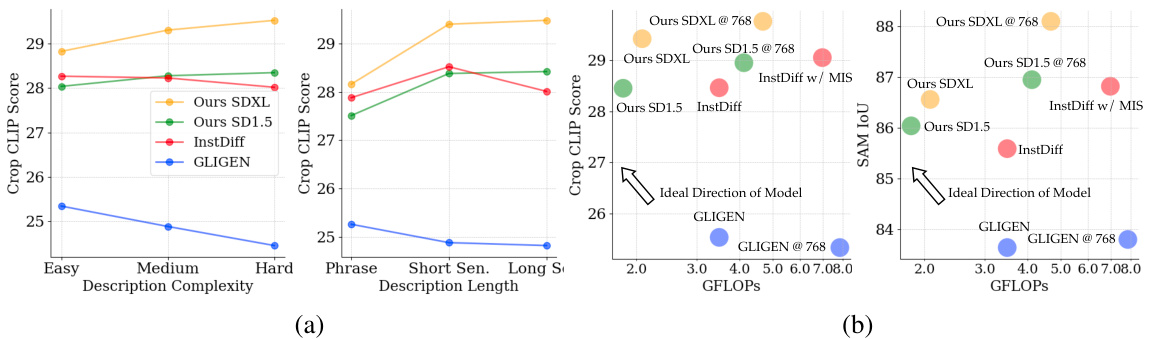
🔼 This table presents a quantitative comparison of various layout-to-image (L2I) generation methods on two datasets, RC COCO and RC CC3M. The comparison is based on three metrics: CropCLIP (object label alignment), SAMIOU (layout fidelity), and FID (image quality). The table includes both constrained and open-set methods, showing the performance of each method across the two datasets. Higher CropCLIP and SAMIOU scores are better, while a lower FID score is better. The results are specifically for images generated at a 512x512 resolution.
read the caption
Table 1: Quantitative comparison of different L2I approaches under image resolution at 512x512.‘↑’ means that the higher the better, ‘↓’ means that the lower the better.
In-depth insights#
Rich-Context L2I#
Rich-Context Layout-to-Image (L2I) generation presents a significant challenge in AI, pushing the boundaries of image synthesis. The core difficulty lies in handling complex and detailed textual descriptions associated with each object within a predefined layout. Existing methods often struggle with this richness, simplifying descriptions and leading to inaccuracies in the generated images. A key innovation to address this is the use of regional cross-attention modules. This approach allows for a more nuanced interaction between text and image features, enabling a finer level of control. The effectiveness of this is also heavily reliant on the quality of the training data. Since high-quality, richly-annotated datasets are scarce, synthetic data generation techniques become crucial, but careful consideration must be given to the complexity, diversity, and accuracy of the synthetic descriptions to avoid introducing biases. Finally, evaluating performance in this context demands more robust metrics than those traditionally used for simpler L2I tasks. The development of open-vocabulary evaluation metrics that capture both object-label alignment and layout fidelity is critical for accurately assessing progress in this area. Future research should focus on further enhancing the capabilities of regional cross-attention and developing even more sophisticated evaluation methodologies.
Cross-Attention#
Cross-attention, in the context of a layout-to-image generation model, is a powerful mechanism to effectively integrate textual descriptions with visual features. Unlike self-attention which focuses solely on relationships within a single modality, cross-attention allows for a direct mapping between the textual information describing an object and the corresponding visual features in the image. This is particularly crucial in scenarios involving complex layouts, where objects might overlap or have intricate relationships. By employing cross-attention, the model can accurately associate detailed textual descriptions with their designated visual regions, leading to improved accuracy in object generation and placement. A key advantage is the ability to handle rich descriptions, including complex and lengthy sentences, without information loss, something self-attention often struggles with due to its aggregation of textual information into single vectors. Regional cross-attention, further refines this process, applying cross-attention to individual object regions. This approach ensures locality by focusing each textual token on its corresponding layout region, maintaining global consistency while simultaneously addressing the challenges of object overlap and complex scene descriptions. The effectiveness of cross-attention relies heavily on the quality of textual and visual encodings. A well-designed grounding encoding process, capable of representing both textual content and spatial information accurately, is essential for the success of cross-attention in achieving high-quality layout-to-image generation.
Open-Vocab Metrics#
The concept of “Open-Vocab Metrics” in the context of a layout-to-image generation research paper is crucial. It addresses the limitations of traditional, closed-vocabulary evaluation methods. Closed-vocabulary methods typically assume a fixed set of object categories, making them unsuitable for evaluating models handling diverse and unseen objects. Open-vocab metrics aim to overcome this by assessing the model’s capability to generate images accurately for any description, regardless of whether the object categories were seen during training. This requires innovative approaches that move beyond simple classification accuracy. The development and validation of these metrics are vital for a fair and comprehensive evaluation of open-vocabulary layout-to-image models. Key challenges in developing these metrics include handling the ambiguity of natural language descriptions, designing metrics robust to variations in object appearance and visual context, ensuring consistency with human judgment, and considering the computational cost of evaluation. The paper should thoroughly justify the chosen metrics, demonstrating their validity and reliability through rigorous analysis and comparison with human evaluations. Ultimately, the success of open-vocabulary layout-to-image generation hinges on establishing robust and reliable open-vocab metrics that accurately reflect the model’s performance in real-world scenarios.
Dataset Synthesis#
In many research papers, especially those focused on computer vision or machine learning, a significant portion is dedicated to the details of the dataset used. The heading ‘Dataset Synthesis’ implies a methodology where the dataset is not sourced from a readily available, pre-existing collection but rather is constructed from scratch. This approach is often necessary when dealing with specialized or nuanced research questions for which no suitable public dataset exists. The creation process may involve several steps, such as generating synthetic data using algorithms, augmenting existing datasets in novel ways, or even curating a collection based on specific criteria. The specifics of dataset synthesis are crucial, as the characteristics of the synthetic data (e.g., distribution, complexity, biases) directly impact the validity and generalizability of the research findings. A thorough explanation of the dataset synthesis is therefore essential to ensure that the research is reproducible, understandable, and credible. The rationale behind choosing a synthetic dataset over a natural one needs careful justification, highlighting the advantages (e.g., complete control over data characteristics, ability to generate large-scale data, avoidance of biases present in real-world data). The paper should also address potential limitations that might arise from using synthetic data (e.g., the dataset might not accurately reflect the real-world distribution, potentially leading to overfitting or inaccurate conclusions).
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a layout-to-image generation model, this might involve disabling the regional cross-attention module, removing bounding box indicators, or simplifying the object description processing. By comparing model performance with and without these components, researchers can isolate the impact of each part. A well-designed ablation study helps determine which components are essential and how different parts interact. For instance, a significant performance drop when removing regional cross-attention would strongly support the claim that this module is crucial for handling complex layout and textual descriptions. Conversely, minimal performance change upon removing a feature would suggest that it’s less critical or redundant. The results guide future model improvements, allowing researchers to focus on optimizing key features or replacing less effective ones. The ablation study should include quantitative results (e.g., precision, recall, F1 score) and qualitative comparisons (e.g., generated images), providing a comprehensive picture of each component’s role in the overall system.
More visual insights#
More on figures
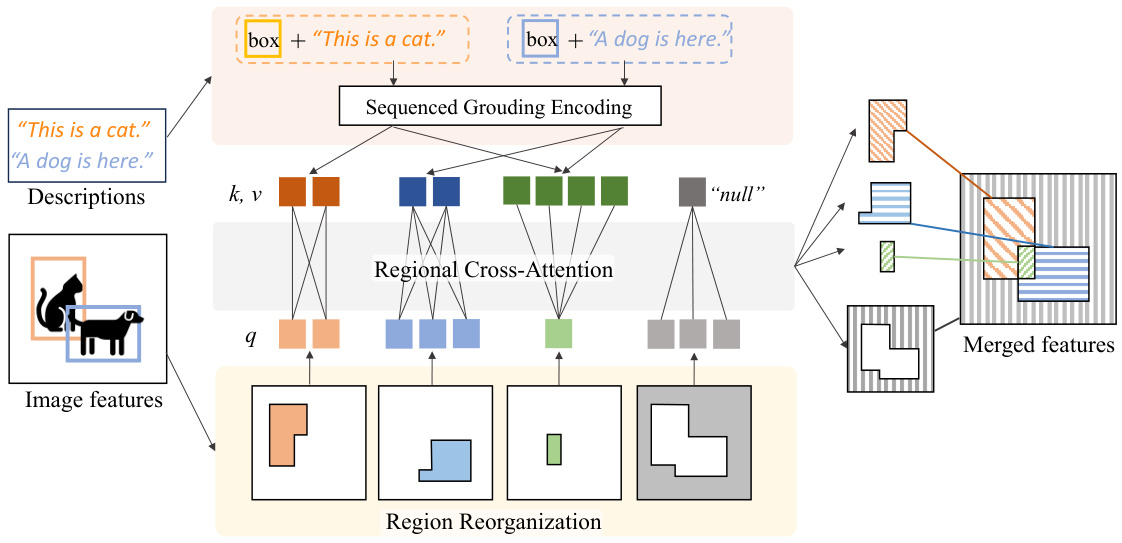
🔼 This figure illustrates the Regional Cross-Attention mechanism with two overlapping objects. Each object’s bounding box is processed individually. The textual description for each object is used in a cross-attention process with the corresponding image region. Where bounding boxes overlap, the cross-attention mechanism considers both overlapping object’s descriptions. Regions without any objects attend to a ’null’ token. This process ensures that each object’s description is accurately reflected in the generated image while handling overlapping objects.
read the caption
Figure 2: An example of regional cross-attention with two overlapping objects. Cross-attention is applied to each pair of regional visual and grounded textual tokens. The overlapping region cross-attends with the textual tokens containing both objects, while the non-object region attends to a learnable “null” token.

🔼 This figure illustrates the Sequenced Grounding Encoding (SGE) process. The input is a sequence of text tokens representing object descriptions, such as ‘This is a cat; A dog is here.’ These tokens are processed by a text encoder. Simultaneously, positional encoding is applied to bounding box coordinates, represented as numerical vectors. These coordinate vectors are then concatenated with the text embeddings to create ‘grounding tokens’. Each grounding token combines the textual description with its corresponding object’s spatial location. This combined representation is then used in the regional cross-attention mechanism.
read the caption
Figure 3: Sequenced Grounding Encoding with box coordinates as indicators.

🔼 This figure presents a statistical comparison of synthetic object descriptions generated by three different methods: GLIGEN, InstDiff, and the proposed method in the paper. Four metrics are used for comparison: average caption length, Gunning Fog Score (complexity), unique words per sample (diversity), and object-label CLIP alignment score. The results demonstrate that the descriptions generated by the proposed method are more complex, diverse, and better aligned with the objects compared to the other two methods.
read the caption
Figure 4: Statistical comparisons between the synthetic object descriptions generated by GLIGEN [25], InstDiff [54], and our method. We measure the 1) average caption length, 2) the Gunning Fog Score, which estimates the text complexity from the education level required to understand the text, 3) the number of unique words per sample which indicates the text diversity, and 4) the object-label CLIP Alignment Score to measure object-label alignment. The results show that the pseudo-labels generated for our dataset are more complex, diverse, lengthier, and align better with objects, compared to those generated by GLIGEN and InstDiff.

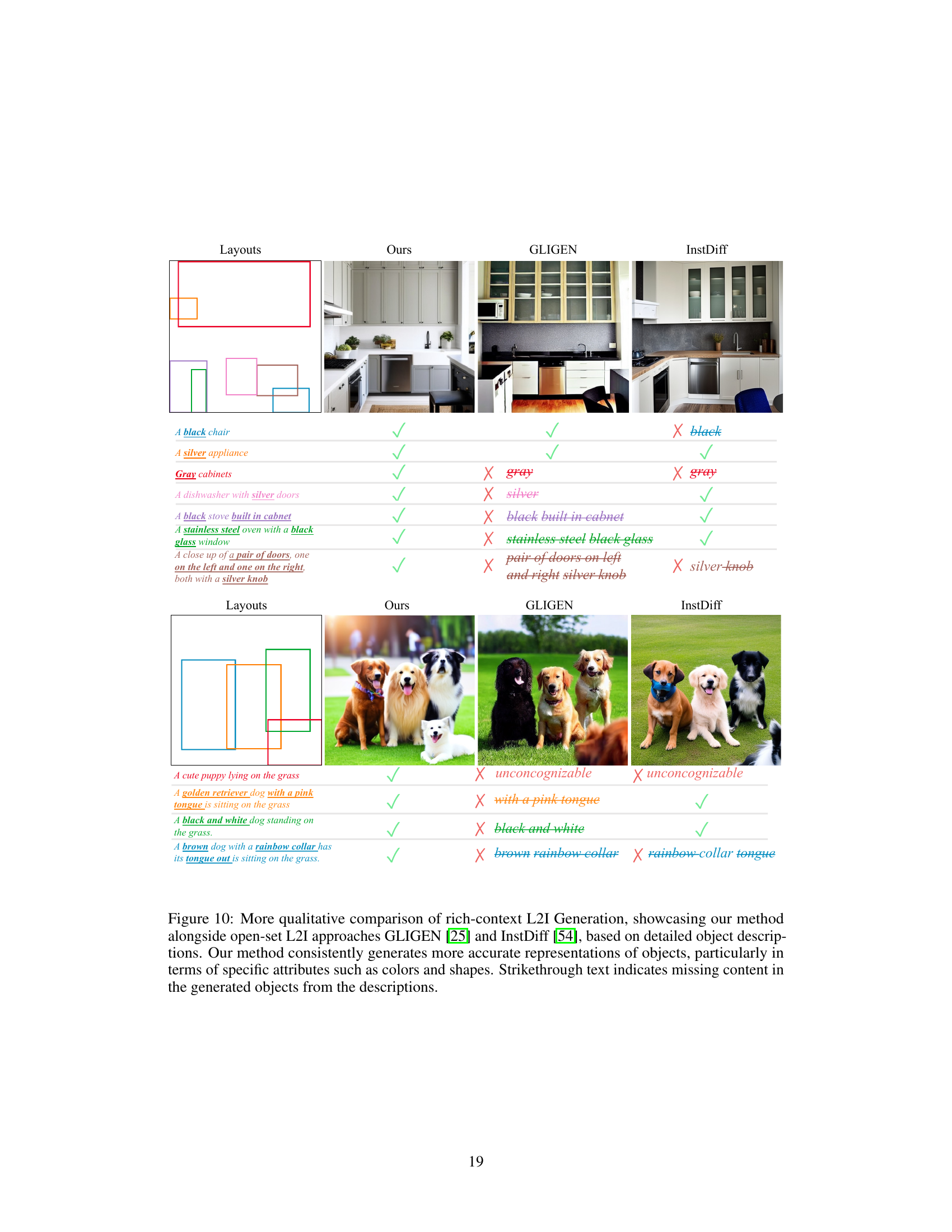
🔼 This figure compares the results of three different layout-to-image (L2I) generation methods: the proposed method and two existing open-vocabulary methods, GLIGEN and InstDiff. Each method is given the same complex, detailed description of objects to generate. The figure visually demonstrates the superiority of the proposed method, which accurately generates objects with the correct attributes (e.g., color, shape), while the other two methods often omit details or generate inaccurate representations.
read the caption
Figure 5: Qualitative comparison of rich-context L2I generation, showcasing our method alongside open-set L2I approaches GLIGEN [25] and InstDiff [54], based on detailed object descriptions. Our method consistently generates more accurate representations of objects, particularly in terms of specific attributes such as colors and shapes. Strikethrough text indicates missing content in the generated objects from the descriptions.
🔼 This figure presents a statistical comparison of synthetic object descriptions generated by three different methods: GLIGEN, InstDiff, and the proposed method. Four metrics are used for comparison: average caption length, Gunning Fog Score (text complexity), unique words per sample (diversity), and object-label CLIP alignment score (alignment accuracy). The results demonstrate that the proposed method generates more complex, diverse, and longer descriptions that align better with the objects compared to the other two methods.
read the caption
Figure 4: Statistical comparisons between the synthetic object descriptions generated by GLIGEN [25], InstDiff [54], and our method. We measure the 1) average caption length, 2) the Gunning Fog Score, which estimates the text complexity from the education level required to understand the text, 3) the number of unique words per sample which indicates the text diversity, and 4) the object-label CLIP Alignment Score to measure object-label alignment. The results show that the pseudo-labels generated for our dataset are more complex, diverse, lengthier, and align better with objects, compared to those generated by GLIGEN and InstDiff.

🔼 This figure compares the throughput (images per second) of different layout-to-image generation methods (ours, GLIGEN, InstDiff, and baselines using Stable Diffusion 1.5 and 1.5 XL) across varying numbers of objects in a scene. The results demonstrate that the proposed method’s throughput is not significantly impacted by the increased number of objects compared to baseline methods. While GLIGEN uses Stable Diffusion 1.4, its architecture and throughput are virtually identical to Stable Diffusion 1.5.
read the caption
Figure 7: All methods are tested with float16 precision and 25 inference steps. The results are averaged over 20 runs. Notably, the overall throughput of our method is not significantly hampered. In a typical scenario with 5 objects, the throughput of our method exceeds 60% of the throughput of the original backbone model. Please note that while the official backbone of GLIGEN is SD1.4, its network structure and throughput are identical to those of SD1.5.
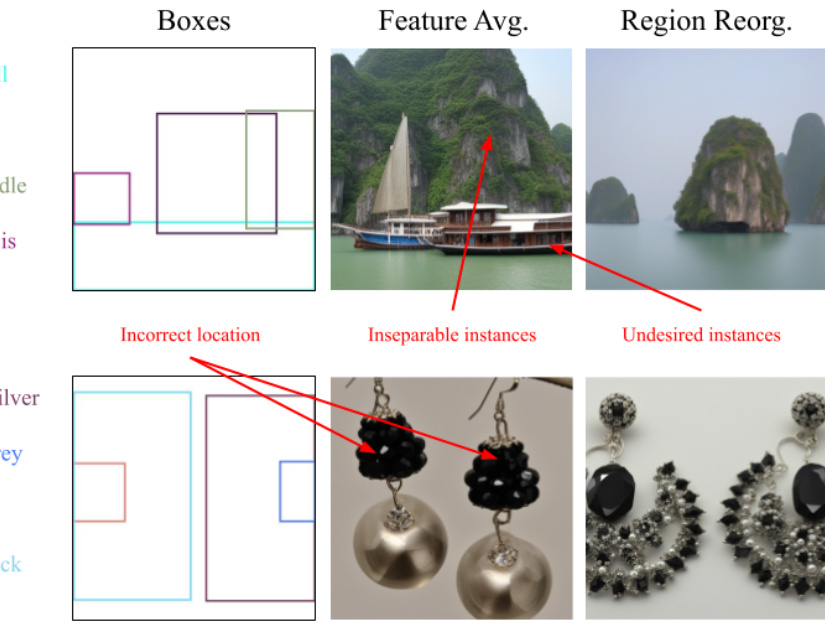
🔼 This figure compares the results of layout-to-image generation using two different methods: feature averaging and region reorganization. The top row shows the layout boxes for two example scenarios (a seascape and a pair of earrings). The middle row shows the results using feature averaging, where the model struggles with overlapping objects. For the seascape, the boat is incorrectly positioned, and for the earrings, the two earring instances are inseparable. The bottom row illustrates the superior performance of region reorganization, generating accurately positioned and distinct objects for both examples.
read the caption
Figure 8: The model with region reorganization can accurate generated objects that better align with the designated layouts, while the feature averaging solution can result in objects in incorrect location, generating undesired instances or making the overlapping instances inseparable.

🔼 This figure illustrates the regional cross-attention mechanism used in the proposed model. It shows how cross-attention is applied separately to different regions of an image based on object bounding boxes. For regions containing multiple objects (overlapping boxes), the cross-attention considers the textual tokens related to all intersecting objects. Regions not containing any objects attend to a learned ’null’ token. The figure highlights the model’s ability to handle complex object relationships and rich textual descriptions.
read the caption
Figure 2: An example of regional cross-attention with two overlapping objects. Cross-attention is applied to each pair of regional visual and grounded textual tokens. The overlapping region cross-attends with the textual tokens containing both objects, while the non-object region attends to a learnable 'null' token.

🔼 This figure illustrates the regional cross-attention mechanism used in the proposed layout-to-image generation model. It shows how the model handles overlapping objects by applying cross-attention to both the overlapping and non-overlapping regions. Specifically, the overlapping region attends to textual tokens describing both objects, while non-overlapping regions attend to tokens related to only one object, or a special ’null’ token if no object is present in that region. This ensures that the model accurately represents the objects and their relationships in the generated image.
read the caption
Figure 2: An example of regional cross-attention with two overlapping objects. Cross-attention is applied to each pair of regional visual and grounded textual tokens. The overlapping region cross-attends with the textual tokens containing both objects, while the non-object region attends to a learnable 'null' token.
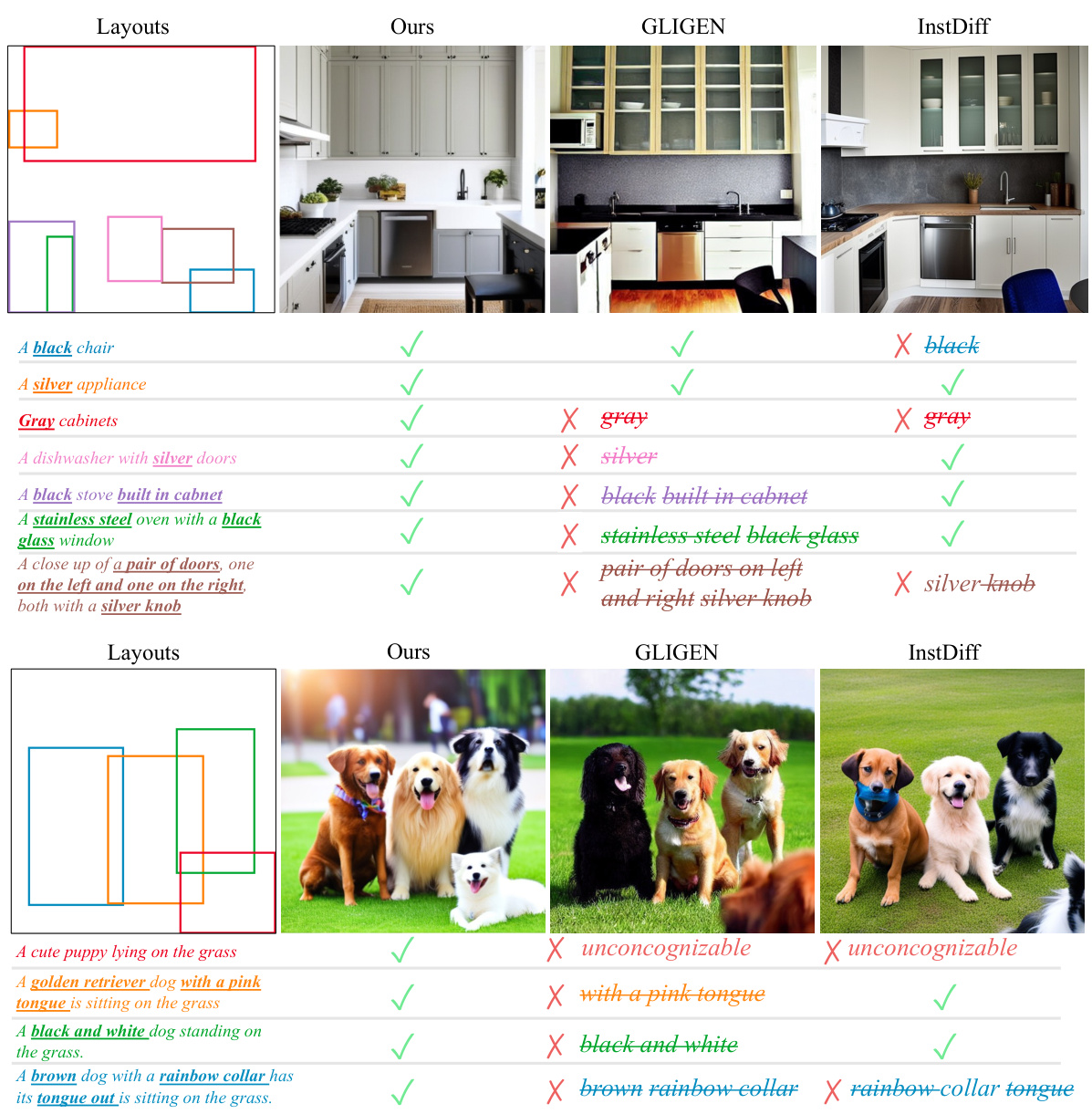
🔼 This figure compares the results of three different layout-to-image generation methods (the proposed method, GLIGEN, and InstDiff) on several complex object descriptions. Each row shows a layout (top) with the desired object location and descriptions, and then the generated images by each method. The proposed method demonstrates superior accuracy in capturing the detailed descriptions, while the other methods often miss key details or generate incorrect objects. Strikethroughs in the comparison highlight features missing from the other methods’ generated images.
read the caption
Figure 5: Qualitative comparison of rich-context L2I generation, showcasing our method alongside open-set L2I approaches GLIGEN [25] and InstDiff [54], based on detailed object descriptions. Our method consistently generates more accurate representations of objects, particularly in terms of specific attributes such as colors and shapes. Strikethrough text indicates missing content in the generated objects from the descriptions.
More on tables

🔼 This table presents a quantitative comparison of various Layout-to-Image (L2I) generation approaches. The comparison is done using four metrics: CropCLIP, SAMIOU, FID, and the performance is evaluated under two datasets RC COCO and RC CC3M. The table shows the performance of different models on these datasets, highlighting the relative performance of each model based on the metrics used. The table provides a clear understanding of the relative strengths and weaknesses of the different L2I models in terms of object-label alignment and layout fidelity.
read the caption
Table 1: Quantitative comparison of different L2I approaches under image resolution at 512x512.‘↑’ means that the higher the better, ‘↓’ means that the lower the better.
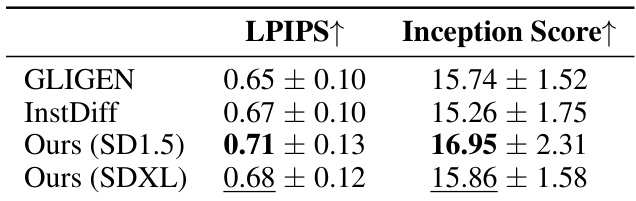
🔼 This table presents the results of evaluating the diversity of generated images by two metrics: LPIPS and Inception Score. LPIPS measures the difference in features between images generated from the same layout, with a higher score indicating more diversity. The Inception Score reflects the overall diversity of the generated images, also with a higher score representing more diversity. The results are shown for different models, including GLIGEN, InstDiff, and two versions of the proposed model (using SD1.5 and SDXL backbones).
read the caption
Table 3: For LPIPS computation, each layout is inferred twice, and the score is calculated using AlexNet. A higher LPIPS score indicates a larger feature distance between two generated images with the same layouts, signifying greater sample-wise generation diversity. A higher Inception Score suggests a more varied appearance of generated images, indicating greater overall generation diversity.

🔼 This table presents the quantitative results of different layout-to-image (L2I) generation methods using the Rich-Context CC3M (RC CC3M) dataset. It compares the performance of methods using different backbones (SDXL and SD1.5), datasets (Word/Phrase and Rich-context), and attention modules (Self-Attn, CrossAttn). The metrics used are CropCLIP and SAMIOU. The results show that even with a rich-context dataset, self-attention-based methods do not significantly outperform the proposed method.
read the caption
Table 4: The performance is evaluated on RC CC3M evaluation set and all methods are sampled under their best sampling resolution as discussed in Section 5.5. It can be noticed that even with the rich-context dataset, the performance of self-attention-based modules does not show significant improvement over their performance in the Table 1 in the paper.
Full paper#