TL;DR#
Current controllable image generation methods heavily rely on supervised learning and annotated data, limiting scalability. The human brain, however, naturally associates visual attributes without explicit supervision, inspiring this research. The paper aims to bridge this gap by developing more brain-like AI systems.
The proposed SCG framework introduces a modular autoencoder with an equivariance constraint to enable spontaneous functional specialization, mimicking the brain’s modularity. This, combined with a self-supervised pattern completion training approach, enables zero-shot generalization and superior performance in high-noise scenarios compared to existing supervised methods. The results demonstrate the successful emergence of associative generation capabilities without external supervision, offering a promising direction for building more robust and scalable AI models.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel self-supervised approach to controllable image generation, addressing the limitations of existing supervised methods. This opens new avenues for research in more scalable and robust AI models, potentially impacting various fields that utilize image generation.
Visual Insights#
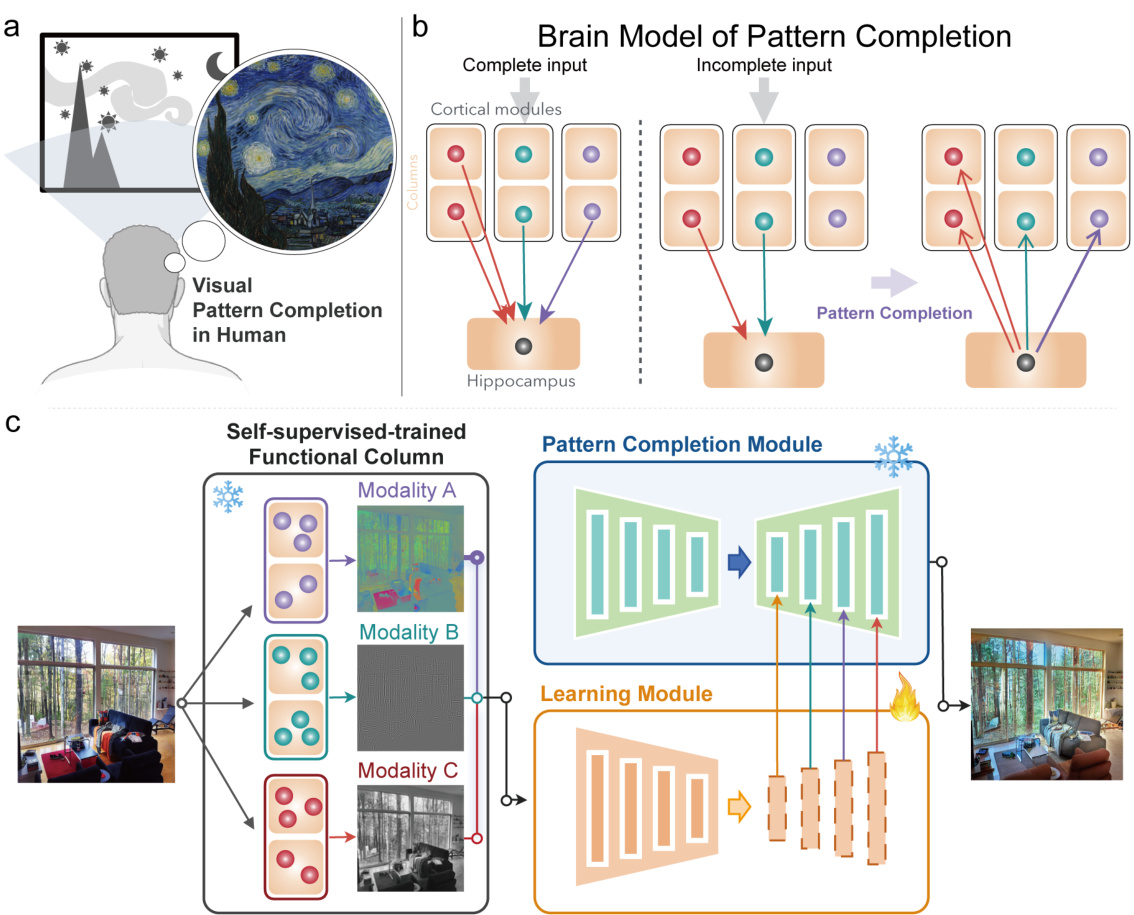
🔼 This figure illustrates the framework of the Self-supervised Controllable Generation (SCG) method. It highlights the two main components: 1) A modular autoencoder that promotes spontaneous functional specialization in different modules through an equivariance constraint, and 2) a self-supervised pattern completion approach for controllable generation. The illustration shows how the network is designed to mimic the brain’s modularity and pattern completion capabilities for associative generation, making it capable of self-supervised learning.
read the caption
Figure 1: Framework of SCG. SCG has two components. One is to promote the network to spontaneously specialize different functional modules through our designed modular equivariance constraint; The other is to perform self-supervised controllable generation through pattern completion.

🔼 This table presents a quantitative evaluation of the Self-supervised Controllable Generation (SCG) model and ControlNet on the MS-COCO dataset. It compares the performance of both models across various metrics, including Peak Signal-to-Noise Ratio (PSNR) for both gray and color images, Structural Similarity Index (SSIM) for gray and color images, Fréchet Inception Distance (FID), and CLIP score. The higher PSNR and SSIM values indicate better image quality, while a lower FID indicates better semantic similarity and a higher CLIP score represents better visual quality. The table also shows the winning rates for fidelity and aesthetics in subjective evaluations.
read the caption
Table 1: Qualitative evaluation on MS-COCO. ↑ means that higher is better, and ↓ means the opposite. g and c means gray images and color images, respectively.
In-depth insights#
Modular Autoencoder#
The modular autoencoder is a crucial component, designed to mimic the human brain’s modularity. Its core innovation is the incorporation of an equivariance constraint during training. This constraint promotes functional specialization by encouraging inter-module independence and intra-module correlation. The result is an autoencoder where each module spontaneously develops distinct functionalities (e.g., processing color, brightness, edges), resembling the specialized processing observed in the brain’s visual cortex. This functional specialization is not explicitly programmed but rather emerges from the constraint itself, which significantly improves the network’s ability to perform pattern completion. The modular design not only leads to brain-like features such as orientation selectivity but also enhances the model’s robustness and scalability for controllable generation tasks.
Equivariance Constraint#
The heading ‘Equivariance Constraint’ likely describes a method used to encourage specific properties within a neural network architecture. Equivariance, in this context, means the network’s output changes predictably when the input undergoes a transformation (e.g., rotation, translation). The constraint enforces this predictable change, potentially leading to improved robustness and generalization. By imposing such a constraint, the authors likely aimed to achieve functional specialization within modular components of the network, mimicking aspects of the brain’s modular structure. This is a significant aspect because specialized modules might lead to more efficient learning and better performance on various tasks by promoting independence between modules while enhancing inter-module collaboration. The effectiveness of this constraint is likely demonstrated through experiments showing the network’s capacity to learn features with desirable properties, resulting in improvements in image generation and other downstream tasks. Overall, the ‘Equivariance Constraint’ section likely represents a key methodological contribution, showcasing how to leverage mathematical properties to improve AI model design and behavior.
Self-Supervised SCG#
The proposed “Self-Supervised SCG” framework represents a significant advancement in controllable image generation. By mimicking the brain’s associative capabilities, it departs from the limitations of supervised methods like ControlNet, which heavily rely on annotated data. SCG leverages a modular autoencoder with an equivariance constraint, promoting functional specialization within modules and achieving brain-like characteristics such as orientation selectivity. This modularity, coupled with a self-supervised pattern completion approach, allows SCG to spontaneously emerge with associative generation capabilities. The zero-shot generalization to various tasks, such as super-resolution and dehazing, and its superior robustness in high-noise scenarios, highlight the potential of this self-supervised framework. Its scalability and potential for broader applications make it a promising direction for future research in controllable image generation.
Brain-like Features#
The concept of “Brain-like Features” in AI research aims to imbue artificial systems with functionalities mirroring the human brain’s processing capabilities. This involves emulating aspects such as modularity, where specialized processing units handle distinct tasks, mimicking the brain’s cortical areas. Orientation selectivity, a key feature of the visual cortex, can be replicated in AI models through the design of specialized modules that respond preferentially to certain orientations. Similarly, color antagonism, a phenomenon of opponent processes in color perception, may be modeled by creating modules that exhibit contrasting responses to different color channels. Center-surround receptive fields, crucial for edge detection and contrast enhancement, can be implemented in convolutional neural networks to achieve similar capabilities. Replicating these brain-inspired mechanisms holds significant promise in improving AI’s performance on complex tasks such as image processing and object recognition, potentially leading to more robust and efficient models that are less reliant on large datasets for training. The success of such an approach depends on effectively capturing the intricate interplay and interactions between these diverse features within the network architecture. Furthermore, zero-shot generalization capabilities are often highlighted as a hallmark of brain-like AI, where the system can effectively perform novel tasks it has not been explicitly trained on, demonstrating an impressive level of adaptability and learning.
Zero-Shot Abilities#
Zero-shot capabilities in AI models represent a significant advancement, enabling them to perform tasks unseen during training. This is particularly valuable in scenarios with limited labeled data or where adapting to new tasks quickly is crucial. The absence of task-specific training distinguishes zero-shot learning from traditional supervised approaches, making it more efficient and scalable. However, the performance of zero-shot models often relies on the richness and quality of their pre-training data. A robust pre-training phase is essential to equip the model with sufficient knowledge to generalize to novel tasks effectively. Furthermore, the success of zero-shot methods depends significantly on the similarity between the pre-training and the zero-shot tasks. The greater the overlap, the better the model’s performance is likely to be. Finally, while zero-shot learning offers remarkable potential, it often struggles with complex tasks requiring nuanced understanding and reasoning abilities. Therefore, careful consideration of the model’s limitations and the appropriateness of the zero-shot approach for the specific application is crucial for successful implementation.
More visual insights#
More on figures

🔼 This figure details the architecture of the Modular Autoencoder, a key component of the Self-Supervised Controllable Generation (SCG) framework. The latent space is divided into modules, each with its own learnable codebook (M(i)). A prediction matrix M(i)(δ) connects the latent space representations of input image pairs (I and I’), where I’ is a transformed version of I (e.g., translated or rotated). This design promotes intra-module correlation and inter-module independence, encouraging functional specialization within the modules.
read the caption
Figure 2: Detail architecture of proposed Modular Autoencoder. The latent space is divided into several modules. We use a prediction matrix M(i)(δ) to build relationship on latent space between input image pairs. M(i) is the learnable codebooks for each modules.
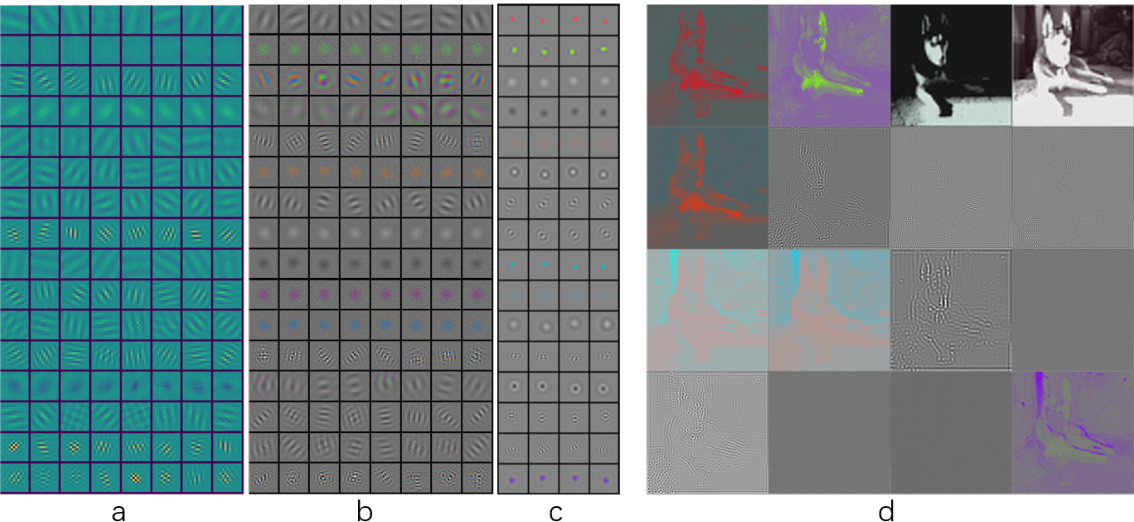
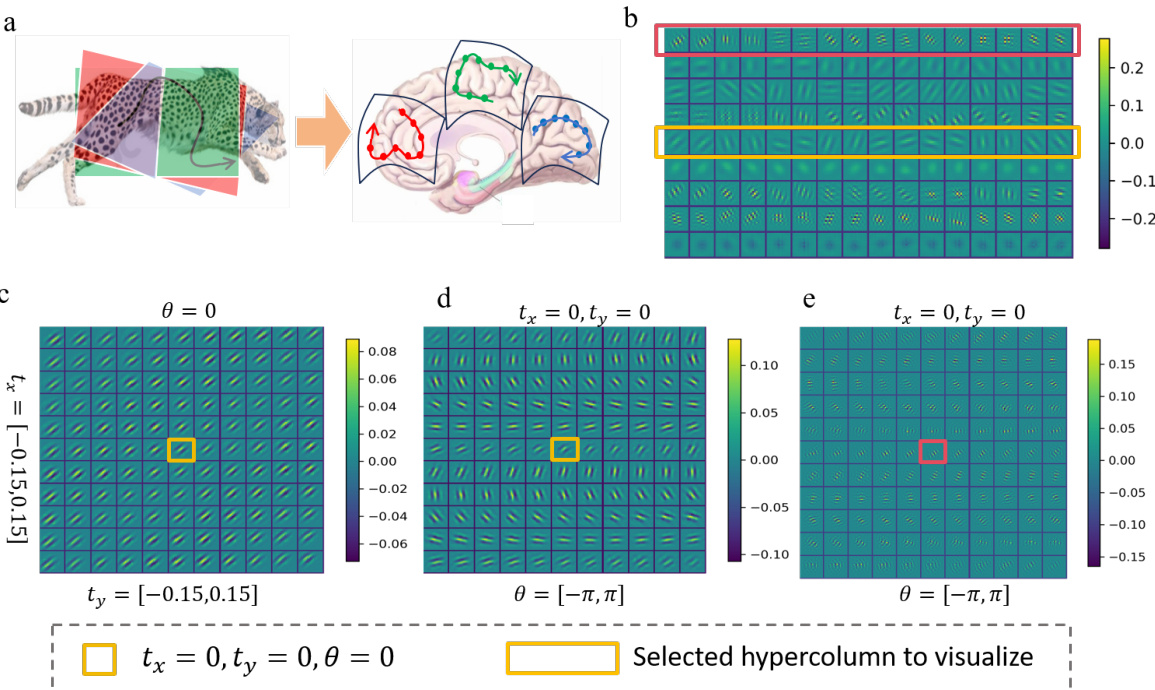
🔼 This figure visualizes the features learned by a modular autoencoder trained with an equivariance constraint. The autoencoder is trained on MNIST and ImageNet datasets. (a) and (b) show the features learned with a translation-rotation equivariance constraint on MNIST and ImageNet, respectively. (c) shows the features learned on ImageNet with an additional translation equivariance constraint. (d) shows reconstructed images using features from (c), demonstrating functional specialization of the modules.
read the caption
Figure 3: Feature Visualization of modular autoencoder. Each panel shows all features learned by an individual model with multiple modules (one module each row). We trained modular autoencoder with a translation-rotation equivariance constraint on a)MNIST and b)ImageNet, respectively. c) On ImageNet, we also train an autoencoder with an additional translation equivariance constraint besides the translation-rotation equivariance constraint on each module. d) We visualize reconstructed images by features of each module in c.

🔼 This figure shows examples of images generated using the Self-Supervised Controllable Generation (SCG) method on the MS-COCO dataset. The top row displays a randomly chosen image and its corresponding text prompt. Below, the second row presents the condition images derived from specialized modules (HC0-HC3) of the modular autoencoder. These modules capture different aspects of the image, such as color, brightness, and edges. The third row shows the images generated by SCG using each condition image. For comparison, the far-right column displays an image generated by the ControlNet method conditioned using a Canny edge map. The bottom section provides more examples of generated images using different input conditions and modules.
read the caption
Figure 4: Images generated by SCG in MS-COCO. The upper part shows an image randomly selected in MS-COCO with a text prompt. On the right show the condition images extracted from our modular autocoder and the corresponding generated images. The last column is a generated image by ControlNet conditioned by the canny edge. The bottom part shows more generated images. The three row images are original, condition and generated images, respectively. (See more in Figure S7 and S6)
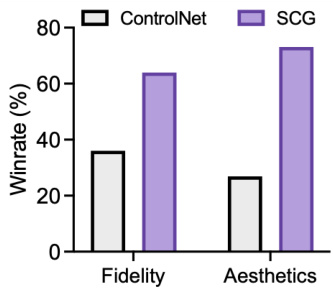
🔼 This figure shows the results of a subjective evaluation comparing ControlNet and SCG on zero-shot oil painting association generation. The winning rates for both fidelity and aesthetics are displayed for each method. The bars represent the percentage of times participants preferred ControlNet (gray bars) or SCG (purple bars) for each aspect. The results show that SCG has a significantly higher winning rate in aesthetics and comparable results in fidelity, indicating that SCG generates more aesthetically pleasing results while maintaining comparable fidelity to the original oil paintings.
read the caption
Figure 5: Subjective evaluation on zero-shot oil painting association generation.

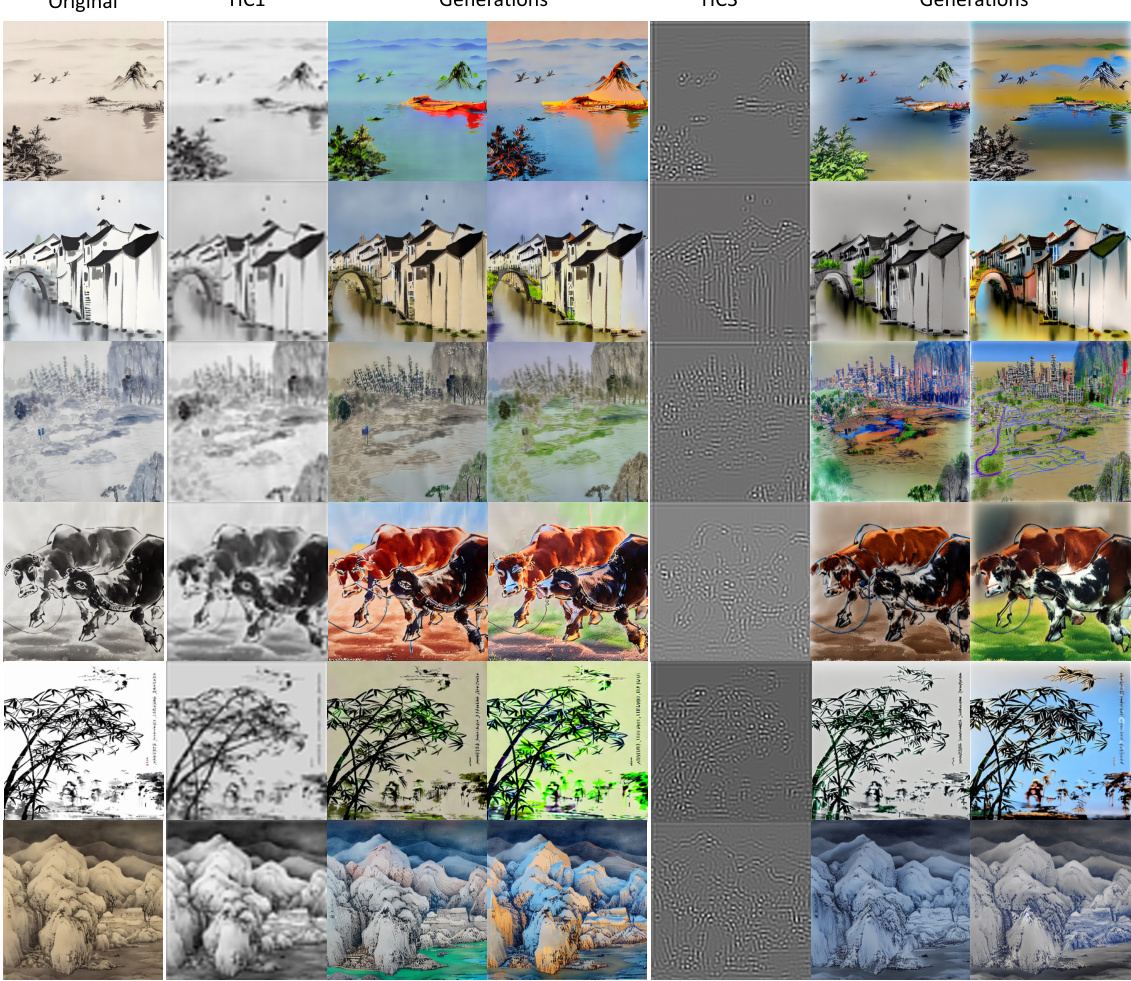
🔼 This figure shows a comparison between ControlNet and the proposed SCG method on associative generation tasks using manual sketches. The first row displays the original sketches, which are taken from the ControlNet paper. The second row presents the results generated by ControlNet, using the Canny edge detector as a condition. The third row illustrates the results generated by the SCG approach, employing HC3 (one of its specialized modules) as the condition. The figure highlights the capability of SCG to perform associative generation by associating sketches with photorealistic images, indicating its potential for zero-shot generalization.
read the caption
Figure 6: Association generation on manual sketches. The original sketches are from ControlNet[55].

🔼 This figure demonstrates the model’s ability to perform associative generation, specifically associating sketches with realistic images. The top row shows the results for oil paintings and the bottom row shows the results for wash and ink paintings. Each set shows the original image, the generated image by ControlNet using Canny edge detection, and two generated images by the proposed SCG method using different modules (HC1 and HC3) as conditions. The results illustrate the model’s capability to handle diverse artistic styles and generate images with high fidelity and aesthetics.
read the caption
Figure 7: Associative generation on oil painting (top) and wash and ink painting (bottom). (See more generation results in Figure S10 and Figure S9)

🔼 This figure presents a comparison of associative generation results on ancient rock graffiti between ControlNet and the proposed SCG method. The left column shows the original graffiti, the middle column shows the results using ControlNet conditioned by the Canny edge detector, and the right column shows results from SCG using module HC3 (sensitive to brightness) as the condition. Below each set of image results are bar charts showing the win rates (in percent) for fidelity and aesthetics for each method as determined by human evaluators. The figure demonstrates that SCG’s results are more visually appealing and faithful to the original image compared to ControlNet, particularly when dealing with the inherent noise present in the ancient graffiti.
read the caption
Figure 8: Association generation on ancient graffiti on rock. (See more generations in Figure S8)
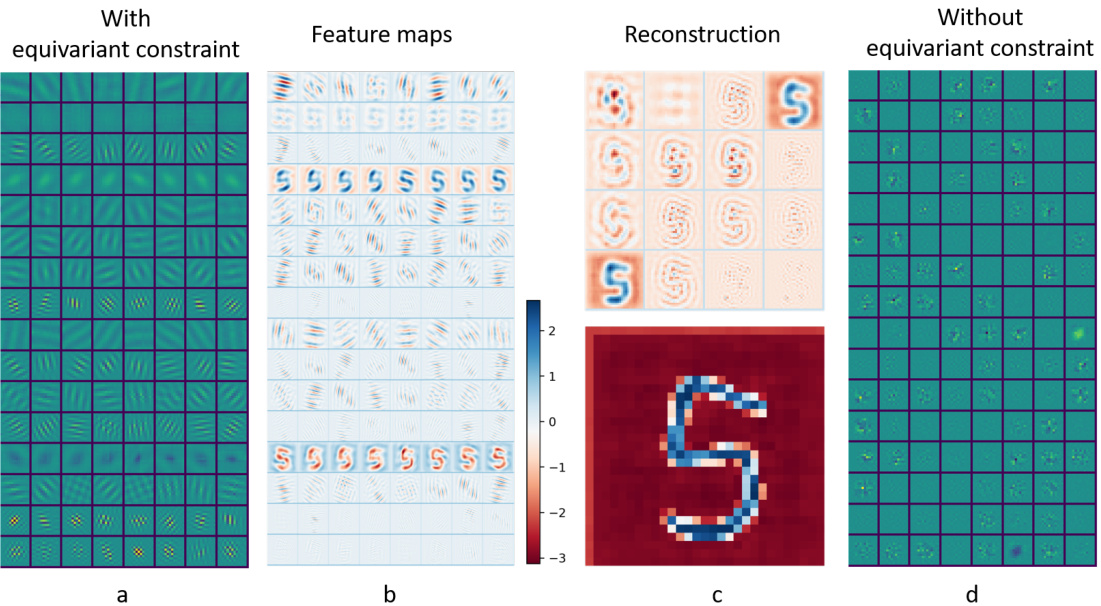
🔼 This figure shows the ablation study on the effect of the equivariance constraint on the modular autoencoder. The left panel (a) shows the feature maps and reconstruction results obtained with the equivariance constraint. The learned features exhibit clear functional specialization, with each module focusing on different aspects of the input image (e.g., orientation, frequency). The right panel (d) shows the results without the equivariance constraint, illustrating a lack of functional specialization and less organized feature representation. The middle panels (b, c) provide a more detailed view of the feature maps and reconstructions from one of the hypercolumns for better understanding. This demonstrates that the equivariance constraint plays a crucial role in enabling the network to spontaneously specialize different functional modules.
read the caption
Figure S1: Ablation study on equivariance constraint.

🔼 This figure presents an ablation study on the modular autoencoder, showing the effects of removing the equivariance constraint, rotation, translation, and symmetry loss. It compares the learned features with those obtained using PCA, demonstrating the effectiveness of the proposed equivariance constraint in achieving functional specialization and the importance of each component in the modular autoencoder architecture.
read the caption
Figure S2: Ablation study on Modular Autoencoder.
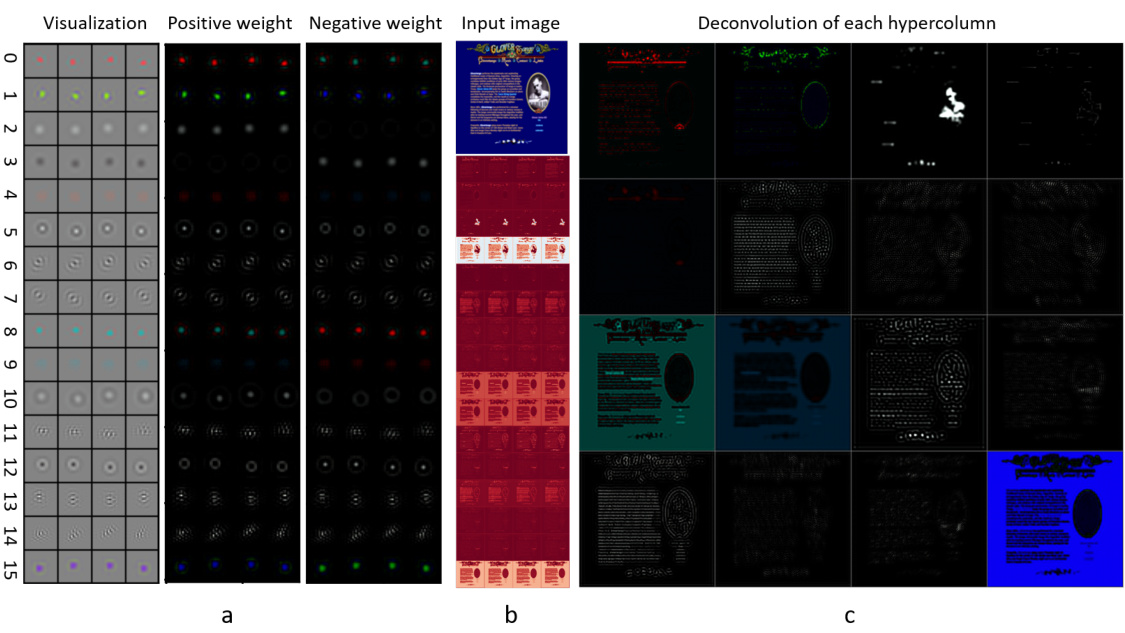
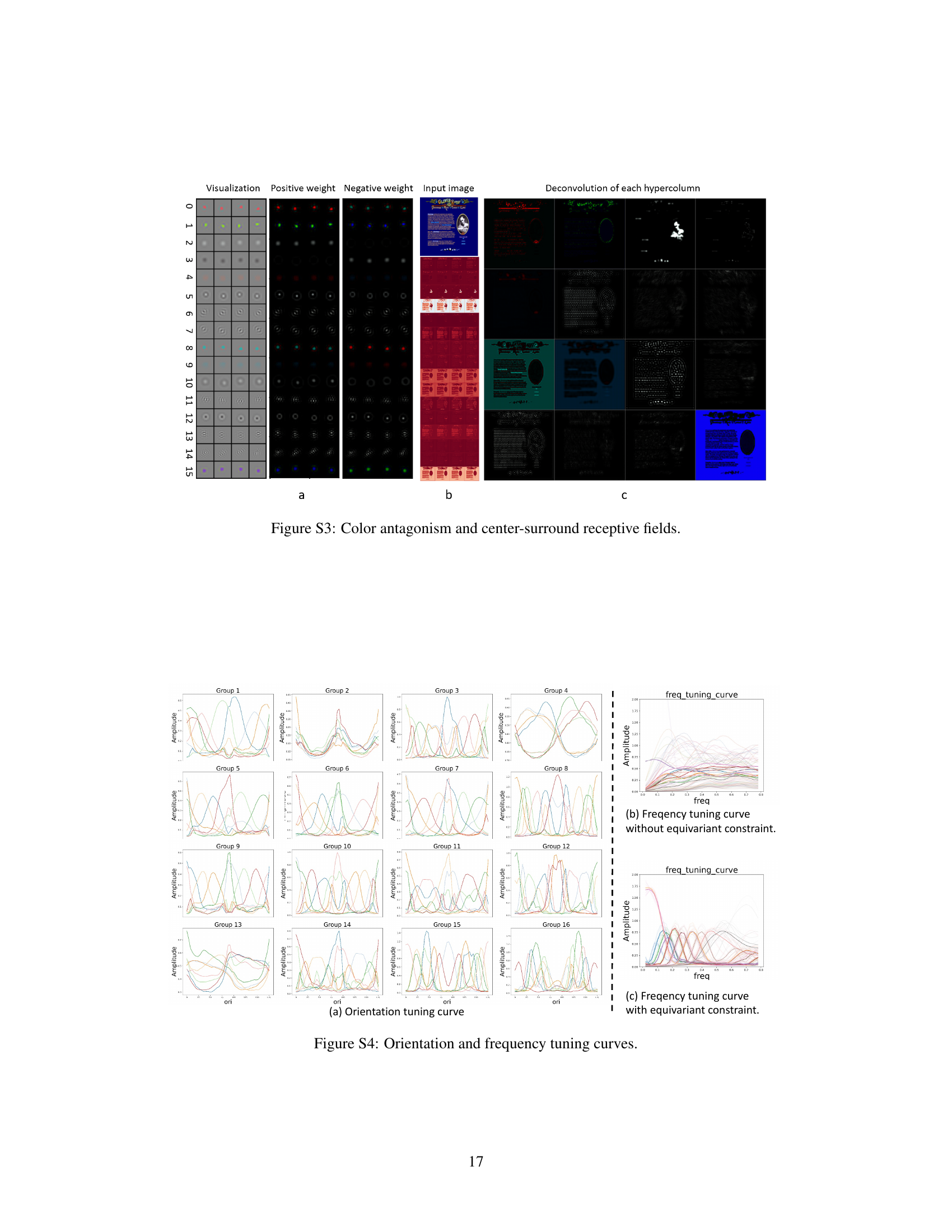
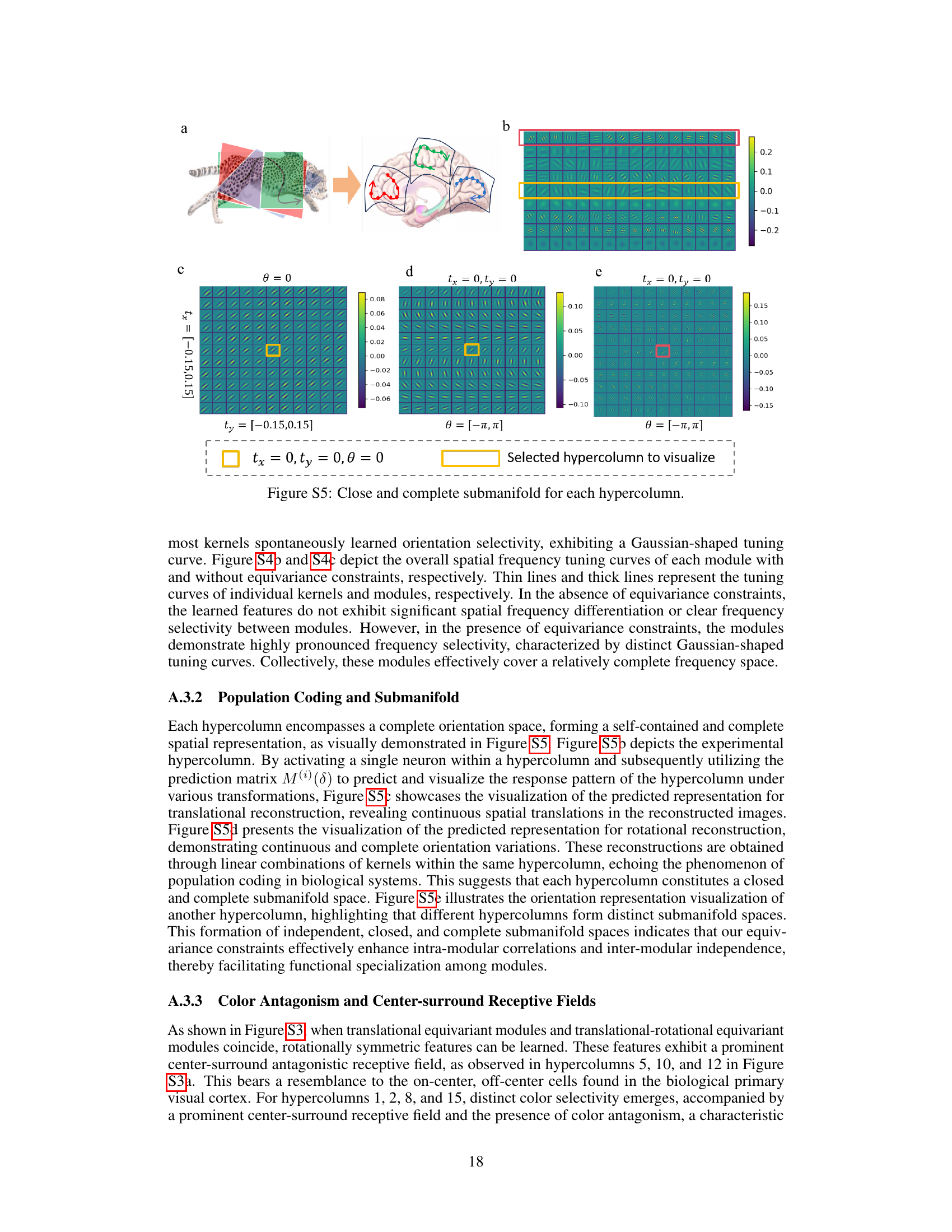
🔼 This figure visualizes the color antagonism and center-surround receptive fields found in the learned features of the modular autoencoder. It shows visualizations of positive and negative weights, along with the input image and the deconvolution of each hypercolumn. The results demonstrate brain-like features such as color antagonism and center-surround receptive fields, which contribute to the model’s robustness to noise.
read the caption
Figure S3: Color antagonism and center-surround receptive fields.
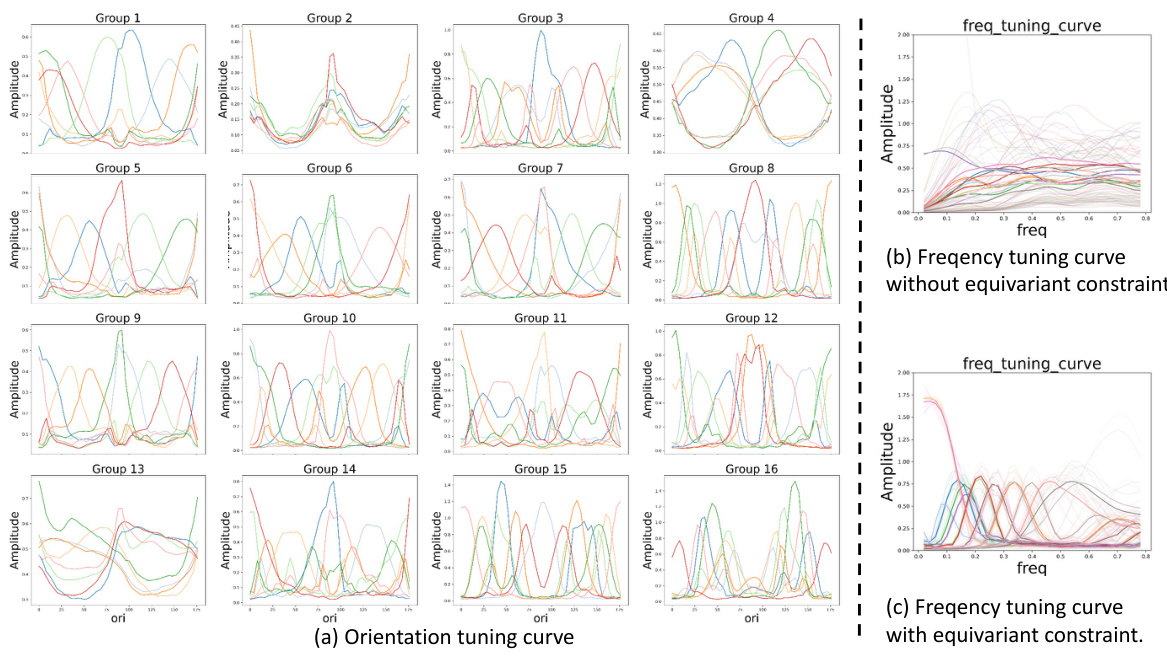
🔼 This figure visualizes the features learned by a modular autoencoder trained with different equivariance constraints. It shows how the model spontaneously develops specialized functional modules for processing various aspects of images such as orientation, color, and brightness. The visualization demonstrates brain-like characteristics such as orientation selectivity and color antagonism, highlighting the effectiveness of the proposed approach.
read the caption
Figure 3: Feature Visualization of modular autoencoder. Each panel shows all features learned by an individual model with multiple modules (one module each row). We trained modular autoencoder with a translation-rotation equivariance constraint on a)MNIST and b)ImageNet, respectively. c) On ImageNet, we also train an autoencoder with an additional translation equivariance constraint besides the translation-rotation equivariance constraint on each module. d) We visualize reconstructed images by features of each module in c.
🔼 This figure illustrates the framework of the Self-supervised Controllable Generation (SCG) method proposed in the paper. SCG comprises two main components: 1. Modular Equivariance Constraint: This component aims to encourage the network to automatically develop specialized functional modules. The design uses an equivariance constraint to achieve this spontaneous specialization. 2. Self-Supervised Pattern Completion: This component employs a self-supervised learning approach that leverages pattern completion for controllable generation. It doesn’t rely on annotated training data, making it more scalable.
read the caption
Figure 1: Framework of SCG. SCG has two components. One is to promote the network to spontaneously specialize different functional modules through our designed modular equivariance constraint; The other is to perform self-supervised controllable generation through pattern completion.

🔼 This figure illustrates the framework of the Self-Supervised Controllable Generation (SCG) method. SCG consists of two main parts: a modular autoencoder which encourages functional specialization in its various modules via an equivariance constraint and a pattern completion module, which leverages a pre-trained diffusion model to perform controllable generation in a self-supervised manner (without the need for labeled data). The modular autoencoder is designed to separate the input image’s features (modalities) into independent modules, mimicking the brain’s modular structure. These specialized modules then serve as inputs or conditions for the pattern completion module, which completes the input image.
read the caption
Figure 1: Framework of SCG. SCG has two components. One is to promote the network to spontaneously specialize different functional modules through our designed modular equivariance constraint; The other is to perform self-supervised controllable generation through pattern completion.

🔼 This figure visualizes the features learned by a modular autoencoder trained with an equivariance constraint. It shows how different modules specialize in different aspects of image features (MNIST and ImageNet are used). The results demonstrate that the modules develop orientation selectivity, color antagonism, and center-surround receptive fields, similar to those observed in the visual cortex. The additional translation equivariance constraint on ImageNet leads to improved feature specialization, as visualized by reconstructed images from individual modules.
read the caption
Figure 3: Feature Visualization of modular autoencoder. Each panel shows all features learned by an individual model with multiple modules (one module each row). We trained modular autoencoder with a translation-rotation equivariance constraint on a)MNIST and b)ImageNet, respectively. c) On ImageNet, we also train an autoencoder with an additional translation equivariance constraint besides the translation-rotation equivariance constraint on each module. d) We visualize reconstructed images by features of each module in c.

🔼 This figure compares the results of ControlNet and SCG on generating images based on ancient graffiti. The top row shows an example of ancient graffiti depicting a horse, followed by the results from ControlNet using a Canny edge detector as a condition, and then the results from SCG using its learned modules as conditions. The bottom row shows a similar comparison but with a different piece of ancient graffiti. The figure highlights the superior robustness of SCG in generating high-fidelity and aesthetically pleasing images compared to ControlNet, especially when dealing with the noise inherent in ancient rock art.
read the caption
Figure 8: Association generation on ancient graffiti on rock. (See more generations in Figure S8)
🔼 This figure demonstrates the zero-shot generalization capabilities of the proposed SCG framework on associative generation tasks. The top row shows examples of associative generation applied to Western-style oil paintings. The original oil painting is shown, along with a Canny edge map (used as a condition in ControlNet), and the generated images from both ControlNet and SCG (using HC1 as a condition). The bottom row shows a similar experiment, but with Eastern-style wash and ink paintings. This section highlights the SCG’s superior performance, particularly in handling the complexities and noise often present in oil paintings, where ControlNet struggles to maintain fidelity and aesthetics due to the Canny edge map’s inability to accurately represent texture and detail.
read the caption
Figure 7: Associative generation on oil painting (top) and wash and ink painting (bottom). (See more generation results in Figure S10 and Figure S9)

🔼 This figure demonstrates the performance of the Self-supervised Controllable Generation (SCG) framework on the MS-COCO dataset. The top row shows example images from MS-COCO with accompanying text prompts. The middle row displays the control images generated by the modular autoencoder, representing different features (color, brightness, edges). The bottom row shows the images generated by SCG using these control images as conditions and compares the outcome to an image generated by ControlNet which used Canny edge detection as a control condition. The figure illustrates the SCG’s ability to perform zero-shot conditional image generation, by successfully reconstructing images from partial or incomplete information.
read the caption
Figure 4: Images generated by SCG in MS-COCO. The upper part shows an image randomly selected in MS-COCO with a text prompt. On the right show the condition images extracted from our modular autocoder and the corresponding generated images. The last column is a generated image by ControlNet conditioned by the canny edge. The bottom part shows more generated images. The three row images are original, condition and generated images, respectively. (See more in Figure S7 and S6)

🔼 This figure illustrates the framework of the Self-supervised Controllable Generation (SCG) method. It highlights two key components: 1. Modular Equivariance Constraint: This component focuses on promoting spontaneous specialization within the network’s functional modules. This specialization is achieved through a modular design and the application of an equivariance constraint. 2. Self-supervised Controllable Generation: This component uses a pattern completion approach to generate controllable images. This self-supervised learning method is designed to avoid the need for labeled training data and enables the model to associate different visual attributes in a brain-like manner.
read the caption
Figure 1: Framework of SCG. SCG has two components. One is to promote the network to spontaneously specialize different functional modules through our designed modular equivariance constraint; The other is to perform self-supervised controllable generation through pattern completion.

🔼 This figure demonstrates the zero-shot generalization capabilities of the Self-supervised Controllable Generation (SCG) model on various tasks such as LineArt, Super-resolution, Dehazing and Sketch. For each task, the top row shows the input condition (e.g., a line drawing, a low-resolution image, a hazy image, or a sketch) and the bottom row presents the corresponding generated high-quality images by SCG. The green boxes highlight the input conditions while the red boxes indicate the generated outputs. The results visually showcase SCG’s ability to perform different tasks without explicit training for each.
read the caption
Figure S12: Zero-shot conditional generation of SCG on more tasks. With green box are conditions and with red box are generated images.
Full paper#