TL;DR#
Training reinforcement learning (RL) policies can be computationally expensive, especially when dealing with massive datasets collected from sub-optimal policies. This paper tackles this issue by introducing a novel approach called Offline Behavior Distillation (OBD), which aims to create smaller, more efficient datasets for training. The challenge lies in designing an effective objective function to guide the data distillation process. Existing methods suffer from performance guarantees with quadratic discount complexity, limiting their efficiency.
The researchers propose a new objective function called Action-value weighted PBC (Av-PBC), which is theoretically shown to achieve superior distillation guarantees with linear discount complexity. Extensive experiments on the D4RL benchmark demonstrate that Av-PBC significantly outperforms existing methods, achieving faster convergence and improved performance across different architectures and optimizers. This work has significant implications for practical applications of RL, where data efficiency and training speed are crucial.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the inefficiency of training reinforcement learning (RL) policies on massive datasets. By introducing offline behavior distillation (OBD), it offers a novel solution for synthesizing smaller, efficient datasets, thereby accelerating training and reducing computational costs. This is particularly relevant in resource-constrained settings, where access to large amounts of data or extensive computational resources may be limited. The findings have significant implications for various RL applications and open up new avenues for efficient policy learning.
Visual Insights#
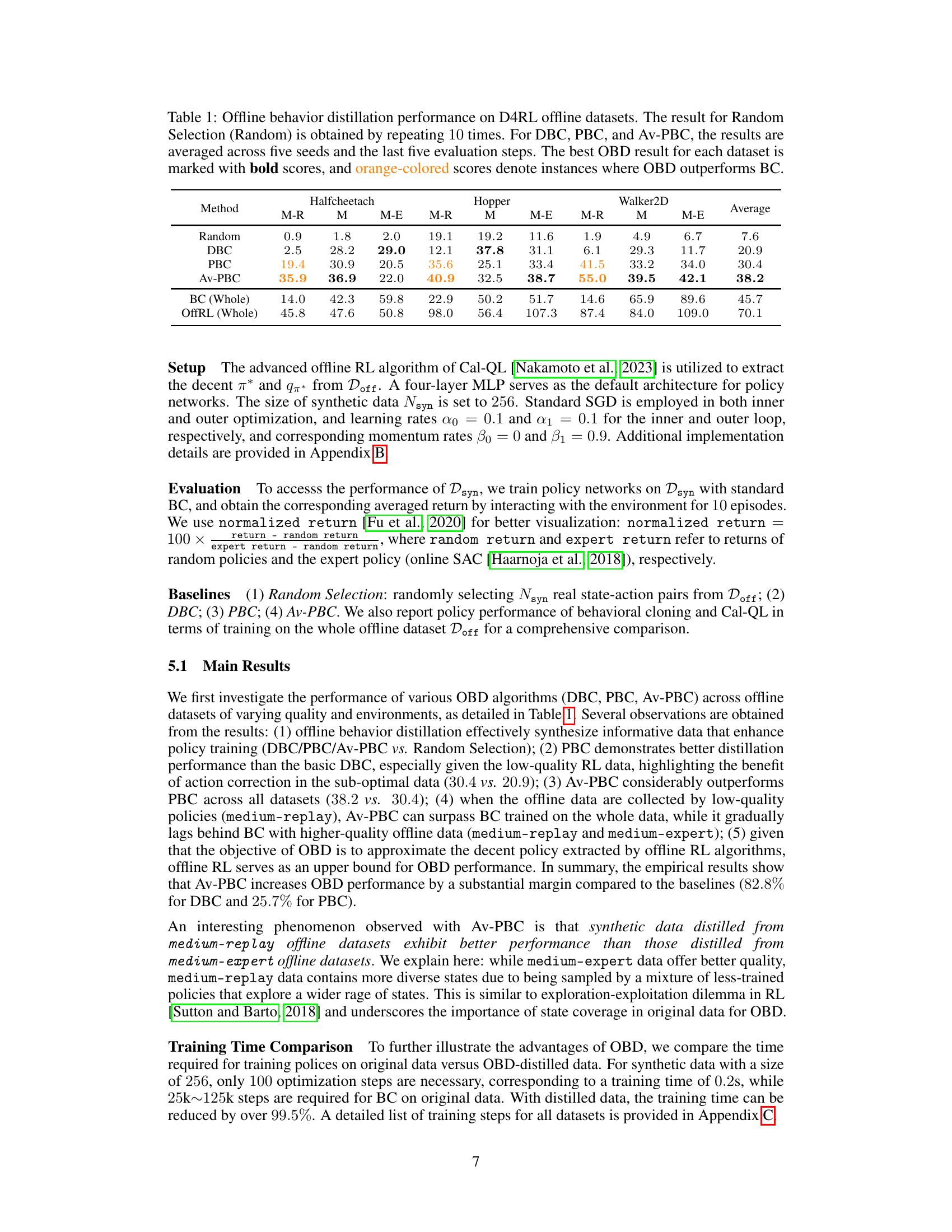
🔼 This figure visualizes the performance of Offline Behavior Distillation (OBD) methods across three different environments (Halfcheetah, Hopper, and Walker2D) and three data quality levels (medium-replay, medium, and medium-expert). The plots show the normalized returns achieved by policies trained using the synthetic data generated by different OBD algorithms (DBC, PBC, and Av-PBC) as the number of distillation steps increases. Each line represents the average performance across five different random seeds, providing insights into the convergence speed and overall performance of each method in various settings.
read the caption
Figure 1: Plots of OBD performance, represented by the normalized returns of policies trained on synthetic data, as functions of distillation steps on (a) Halfcheetah; (b) Hopper; and (c) Walker2D environment. Each curve is averaged over five random seeds.
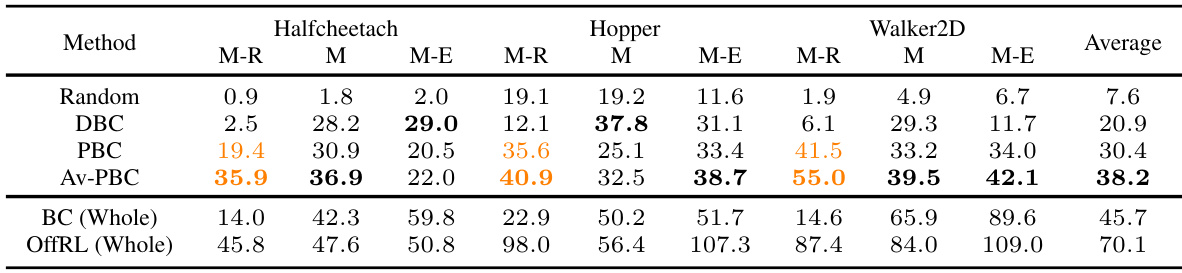
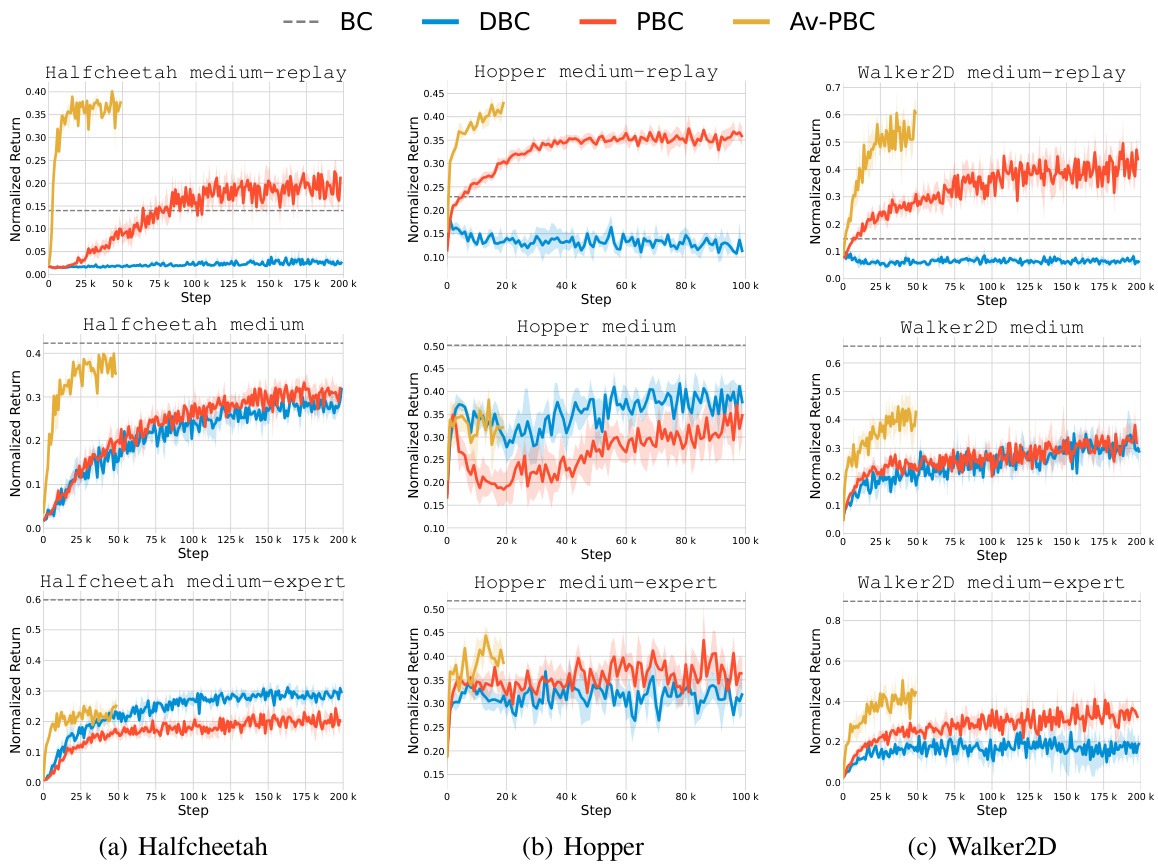
🔼 This table presents the results of offline behavior distillation experiments on nine D4RL datasets (three tasks with three data quality levels). The table compares the performance of four different methods: Random Selection (baseline), Data-based Behavior Cloning (DBC), Policy-based Behavior Cloning (PBC), and Action-Value weighted Policy-based Behavior Cloning (Av-PBC). The performance metric is normalized return, averaged over five random seeds and the last five evaluation steps. Bold numbers highlight the best performing method for each dataset. Orange highlights cases where offline behavior distillation outperforms standard Behavior Cloning.
read the caption
Table 1: Offline behavior distillation performance on D4RL offline datasets. The result for Random Selection (Random) is obtained by repeating 10 times. For DBC, PBC, and Av-PBC, the results are averaged across five seeds and the last five evaluation steps. The best OBD result for each dataset is marked with bold scores, and orange-colored scores denote instances where OBD outperforms BC.
In-depth insights#
OBD: A New Approach#
The heading “OBD: A New Approach” suggests an innovative method for offline behavior distillation. The core idea likely involves synthesizing a smaller, more informative dataset from a larger, potentially noisy offline dataset. This new approach likely addresses the inefficiencies caused by training reinforcement learning (RL) policies on massive datasets. The method’s novelty might lie in its objective function or distillation technique, possibly incorporating elements from other fields like dataset distillation. Computational efficiency is likely a key advantage, enabling faster training and deployment. The “new approach” likely offers theoretical guarantees on the synthesized data quality or policy performance, and provides empirical validation demonstrating superior performance over existing methods. Overall, the approach promises to advance offline RL by creating efficient training datasets that improve policy performance and training speed.
Av-PBC Algorithm#
The Av-PBC algorithm, a core contribution of the research paper, presents a novel approach to offline behavior distillation (OBD). It addresses the limitations of previous methods like DBC and PBC by incorporating action-value weights into the policy-based BC objective. This crucial modification significantly improves the distillation performance guarantee, reducing the complexity from quadratic to linear. By weighting the decision difference between a near-optimal policy and the learned policy with action-values, Av-PBC focuses on optimizing areas of the state-action space that contribute most to the expected return, thus accelerating the learning process and improving the efficiency of the OBD process. The algorithm’s effectiveness is demonstrated through extensive experiments, showcasing superior performance and faster convergence compared to existing techniques. Theoretical analysis provides a rigorous foundation for its enhanced performance guarantees, highlighting its advantages in terms of both empirical results and theoretical soundness. The algorithm’s robustness is further emphasized by its cross-architecture/optimizer generalization, suggesting its broader applicability across different RL problem settings. Overall, Av-PBC offers a compelling solution for effectively distilling large, sub-optimal offline RL datasets into smaller, high-performing synthetic datasets, thereby enabling efficient and effective policy learning.
OBD Performance#
The OBD (Offline Behavior Distillation) performance is a crucial aspect of the research, evaluated across multiple offline RL datasets and various metrics. Significant improvements in OBD performance are reported using the proposed Av-PBC (Action-value weighted PBC) objective compared to baseline methods like DBC and PBC. These improvements are observed in terms of normalized return, demonstrating faster convergence speeds and robust generalization across different network architectures and optimizers. The effectiveness of Av-PBC is particularly notable in datasets with lower-quality data, surpassing even the performance of BC (Behavioral Cloning) trained on the entire original dataset. However, the study also acknowledges the computational cost of Av-PBC, suggesting future work could focus on further efficiency gains. The results strongly support the theoretical analysis showcasing Av-PBC’s superior distillation guarantee, but highlight a continued need for investigation into the trade-offs between performance and computational efficiency within the context of the OBD task.
OBD Limitations#
Offline Behavior Distillation (OBD) faces limitations primarily concerning its computational cost and performance gap relative to training on the full offline dataset. The bi-level optimization inherent in OBD is computationally expensive, requiring substantial time for convergence, even with the improved Av-PBC objective. This significantly impacts scalability and practical applicability. Furthermore, a performance gap exists between policies trained on distilled data and those trained on the full offline dataset. While Av-PBC significantly reduces this gap compared to other methods, it persists, especially in scenarios with lower-quality offline data. The reliance on behavioral cloning (BC) for training on the distilled data restricts the applicability of OBD, as BC may not be suitable for all RL tasks or settings. Finally, the distilled data, being 2-tuples (state, action) without reward information, restricts the use of traditional RL algorithms based on Bellman backups, limiting flexibility in downstream applications.
Future of OBD#
The future of Offline Behavior Distillation (OBD) looks promising, with several avenues for improvement. Improving the efficiency of the bi-level optimization process is crucial; current methods are computationally expensive. Exploring alternative optimization strategies or approximation techniques could significantly speed up the distillation process. Enhancing the quality of the distilled data is another key area. While Av-PBC shows marked improvement, further research into more effective objective functions that better capture the nuances of policy performance is needed. Extending OBD to handle more complex RL environments and tasks will be essential for broader applicability. Investigating the effectiveness of OBD in multi-agent settings or continuous control problems would be particularly valuable. Finally, addressing the limitations of relying solely on behavior cloning (BC) for policy training post-distillation is important. Developing hybrid approaches that combine BC with other offline RL algorithms could potentially further enhance performance and robustness. Ultimately, the success of OBD depends on balancing data efficiency with the ability to learn effective and generalizable policies.
More visual insights#
More on tables
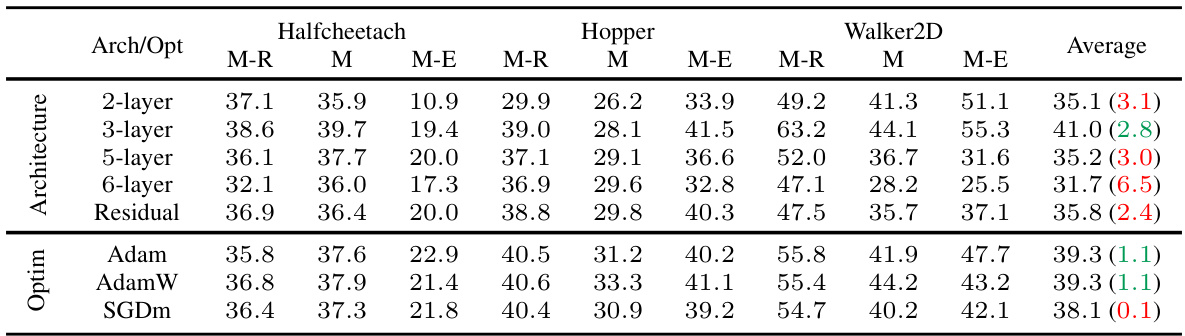
🔼 This table presents the results of offline behavior distillation using different network architectures (2-layer, 3-layer, 5-layer, 6-layer, Residual) and optimizers (Adam, AdamW, SGDm) across three D4RL environments (Halfcheetah, Hopper, Walker2D) and three dataset qualities (M-R, M, M-E). The average performance across all settings is shown, with red indicating performance worse than the default and green indicating better performance.
read the caption
Table 2: Offline behavior distillation performance across various policy network architectures and optimizers (Optim). Red-colored scores and green-colored scores in brackets denote the performance degradation and improvement, respectively, compared to the default training setting. The results are averaged over five random seeds and the last five evaluation steps.

🔼 This table shows the offline behavior distillation performance on D4RL datasets using ensemble methods. It compares three different methods (DBC, PBC, and Av-PBC) across multiple environments and data qualities. The improvement in performance due to ensembling is highlighted with green-colored scores. The results are averaged over five random seeds and the last five evaluation steps.
read the caption
Table 3: Offline behavior distillation performance on D4RL offline datasets with ensemble num of 10. Green-colored scores in brackets denote the performance improvement compared to the non-ensemble setting. The results are averaged over five random seeds and the last five evaluation steps.

🔼 This table shows the size of the original offline datasets used for training in millions of data points and the number of training steps required for convergence for each dataset and environment. It also includes the size and number of steps for the synthetic dataset generated using the Av-PBC method.
read the caption
Table 4: The size and required training steps for convergence for each offline dataset. M denotes the million for simplicity. The size and step for synthetic data (Synset) are listed in the last column.
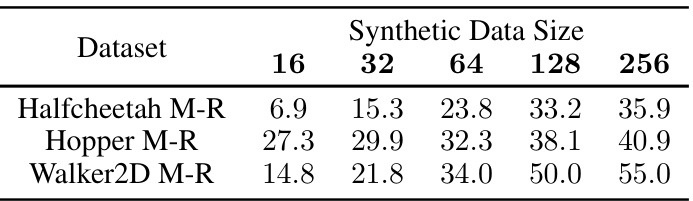
🔼 This table shows how the performance of the Av-PBC method changes when using different sizes of synthetic data. The results are presented for three different D4RL datasets (Halfcheetah M-R, Hopper M-R, Walker2D M-R), each tested with five different sizes of synthetic data (16, 32, 64, 128, 256). The numbers in the table represent the performance of the Av-PBC method under these conditions, allowing for an assessment of the impact of synthetic data size on performance.
read the caption
Table 5: The Av-PBC performance on D4RL offline datasets with different synthetic data sizes.
Full paper#