TL;DR#
Large Language Models (LLMs) are increasingly used in various sectors, but their safety and alignment with human values remain open questions. Current evaluation methods rely heavily on natural language processing benchmarks, often neglecting the impact of human emotions on decision-making. This is a crucial gap as emotions significantly influence human behavior, and LLMs should ideally mirror this nuanced aspect of decision-making. This limitation could lead to unpredictable or unsafe behaviors by LLMs.
The paper introduces the novel EAI framework to address these issues by integrating emotion modeling into LLMs. EAI evaluates LLM decision-making in complex strategic and ethical scenarios, like bargaining and repeated games. Experiments using different LLMs reveal that emotions drastically affect their ethical and strategic decisions, often unexpectedly reducing cooperation. The framework demonstrates the susceptibility of LLMs to biases, dependent on model size, alignment strategies, and primary pretraining language. EAI’s findings provide a strong case for more robust emotional alignment benchmarks, leading the way for building more reliable and ethical AI systems.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical gap in LLM safety research by examining the impact of emotions on their decision-making in complex scenarios. Current alignment methods often neglect emotional biases, limiting the safety and reliability of LLMs in real-world applications. The findings highlight the need for more robust ethical standards and benchmarks for evaluating emotional alignment in multi-agent systems. This opens new avenues for research in this field.
Visual Insights#

🔼 The EAI framework is designed to assess the impact of emotions on LLMs’ decision-making in ethical scenarios and various game settings. It integrates emotion modeling into LLMs, using different prompting strategies to induce specific emotions. The framework evaluates LLMs’ performance in one-shot bargaining games (Dictator and Ultimatum games) and repeated games (Prisoner’s Dilemma, Battle of the Sexes, Public Goods Game, and El Farol Bar Game). It also includes metrics and visualization for comparing LLM performance with human behavior.
read the caption
Figure 1: EAI Framework is designed to integrate emotions into LLMs and evaluate their decision-making in various settings, including ethical scenarios, one-shot bargaining games, and repeated games. The framework's main building blocks are game descriptions, which include environment and rules descriptions; emotion prompting, which encompasses various strategies to embed emotions into LLMs; and game-specific pipelines that govern different environments.
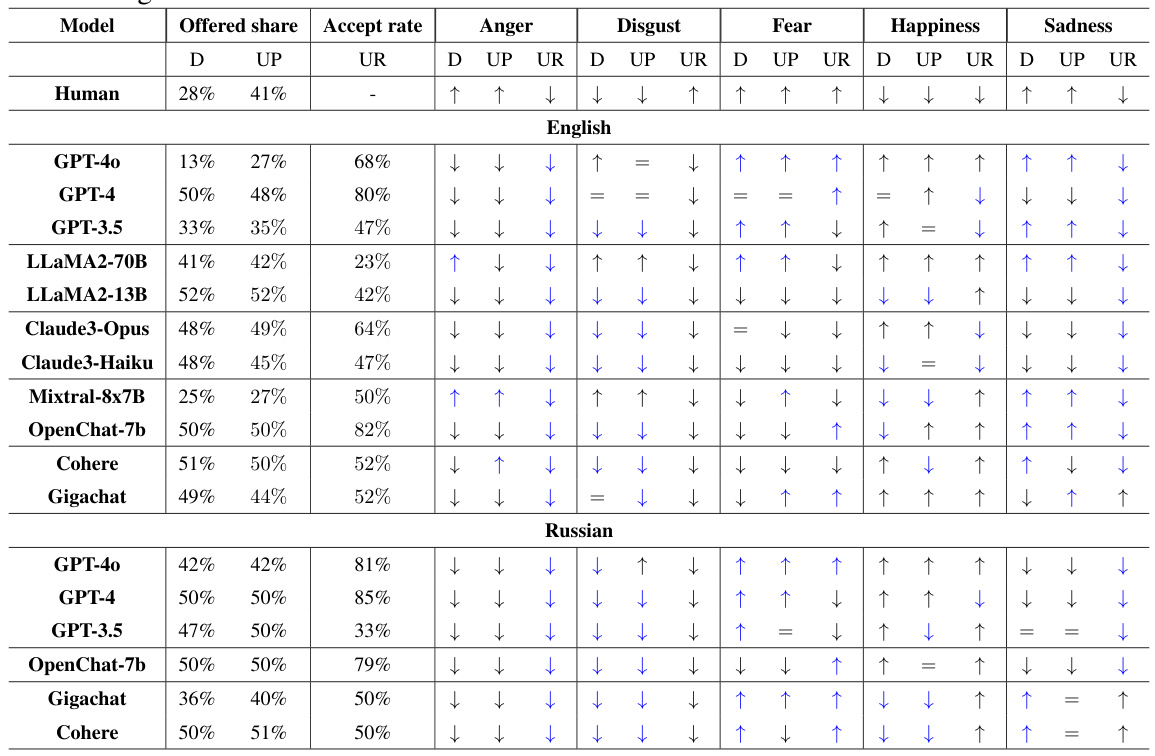
🔼 This table presents the experimental findings on how different LLMs respond in the Dictator and Ultimatum games under various emotional states. It shows the average proposed offer share and acceptance rate for each LLM across multiple runs and different emotional prompts (anger, disgust, fear, happiness, sadness) and compares these results with human benchmarks. The blue coloring highlights the degree of alignment between LLM responses and human behavior in terms of relative changes in the metrics under various emotional conditions.
read the caption
Table 1: Experimental results for the Dictator (D), Ultimatum Proposer (UP), and Responder (UR) games. Arrows denote the direction of the emotional effect. The blue color shows models' alignment with human behavior in terms of similar relative changes under emotions.
In-depth insights#
LLM Emotion AI#
LLM Emotion AI represents a significant advancement in AI safety and alignment research. By integrating emotion modeling into large language models (LLMs), researchers aim to better understand and mitigate the risks associated with unpredictable or unethical LLM behavior. The core idea is that emotional responses heavily influence human decision-making, and LLMs, if they are to truly align with human values, must also account for this emotional dimension. This approach allows for a deeper analysis of how LLMs respond to complex, emotionally charged situations, going beyond simple benchmarks and delving into strategic games and ethical dilemmas. The research highlights the importance of a robust framework for evaluating emotional alignment, emphasizing the need for benchmarks that rigorously assess cooperation rates and ethical decision-making under various emotional states. Key findings show LLMs’ susceptibility to emotional biases, often diverging from typical human responses, suggesting that current models are not yet ready for autonomous decision-making in complex scenarios. Further research is needed to enhance LLMs’ understanding and simulation of human emotions, including exploring the effect of factors like model size, alignment strategies and pretraining language. This will lead to more predictable, safe, and ethically sound LLMs in various applications.
EAI Framework#
The EAI (Emotion AI) Framework, as described in the research paper, appears to be a novel approach for evaluating the emotional decision-making capabilities of LLMs. Its core innovation lies in the integration of emotional inputs into the assessment process, moving beyond traditional NLP benchmarks. By incorporating emotions into various game-theoretical settings and ethical dilemmas, the framework aims to provide a more nuanced understanding of how LLMs align with human behavior in complex scenarios. This involves using different emotional prompting strategies to observe the impact of emotions on LLM decisions, along with the use of game-specific pipelines tailored to various game types. The framework’s design shows a commitment to rigorous evaluation, with careful consideration for factors such as model size, alignment strategies, and the primary language of the LLM’s training. The ultimate goal is to create benchmarks capable of rigorously assessing the degree of emotional alignment in LLMs and identify biases in LLM ethical decision-making, therefore contributing to the development of safer and more aligned AI systems. The framework’s flexibility and adaptable nature suggest it could be highly valuable for future research in this field.
Game-Theoretic Tests#
Game-theoretic tests would rigorously evaluate LLMs’ decision-making capabilities in strategic settings. By pitting LLMs against each other or against human players in well-defined games (like the Prisoner’s Dilemma or Ultimatum Game), researchers could objectively measure cooperation levels, adherence to optimal strategies (Nash Equilibrium), and susceptibility to manipulation. These tests would reveal how well LLMs understand game dynamics, predict opponents’ behavior, and make rational choices in competitive environments. The introduction of emotional factors into these tests adds another layer of complexity, allowing exploration of how emotional states influence strategic decisions. Such tests are crucial for assessing the safety and reliability of LLMs in real-world scenarios, where interactions are often complex and involve diverse players with potentially conflicting interests. Ultimately, these findings would help to guide the further development of more ethically sound and human-aligned LLMs.
Ethical LLM Impacts#
Ethical concerns surrounding LLMs are multifaceted. Bias in training data significantly influences LLM outputs, potentially perpetuating and amplifying societal prejudices. Lack of transparency in LLM decision-making processes hinders accountability and trust, making it difficult to identify and rectify unethical behavior. Furthermore, the potential for misuse in high-stakes applications, such as healthcare and finance, raises serious ethical questions about responsibility and the potential for harm. Mitigating these risks requires careful consideration of data provenance, rigorous testing and validation, development of explainable AI techniques, and the establishment of clear ethical guidelines for LLM development and deployment. The lack of emotional intelligence in current LLMs also poses an ethical challenge; unpredictable emotional responses may lead to decisions that deviate from human expectations, exacerbating existing biases and potentially harming users.
Future Research#
Future research should prioritize developing more robust benchmarks for evaluating emotional alignment in LLMs, moving beyond simple accuracy metrics to encompass nuanced aspects of human emotional responses in complex strategic interactions. This requires exploring diverse game-theoretical settings, ethical dilemmas, and real-world scenarios to fully capture the complexities of human decision-making influenced by emotion. Further investigation into the impact of model architecture, training data, and alignment techniques on emotional biases is crucial. This includes examining how different model sizes, pretraining languages, and alignment methods affect LLMs’ susceptibility to emotional manipulation and their ability to exhibit appropriate emotional responses. Furthermore, research should focus on developing methods to mitigate emotional biases in LLMs, possibly through techniques like improved emotional reasoning, enhanced data filtering to reduce biases, and novel training methods that promote ethical and consistent decision-making across emotional contexts. Finally, exploring the implications of emotional LLMs for multi-agent systems and human-AI collaboration requires careful consideration, necessitating research into potential risks and safeguards.
More visual insights#
More on figures
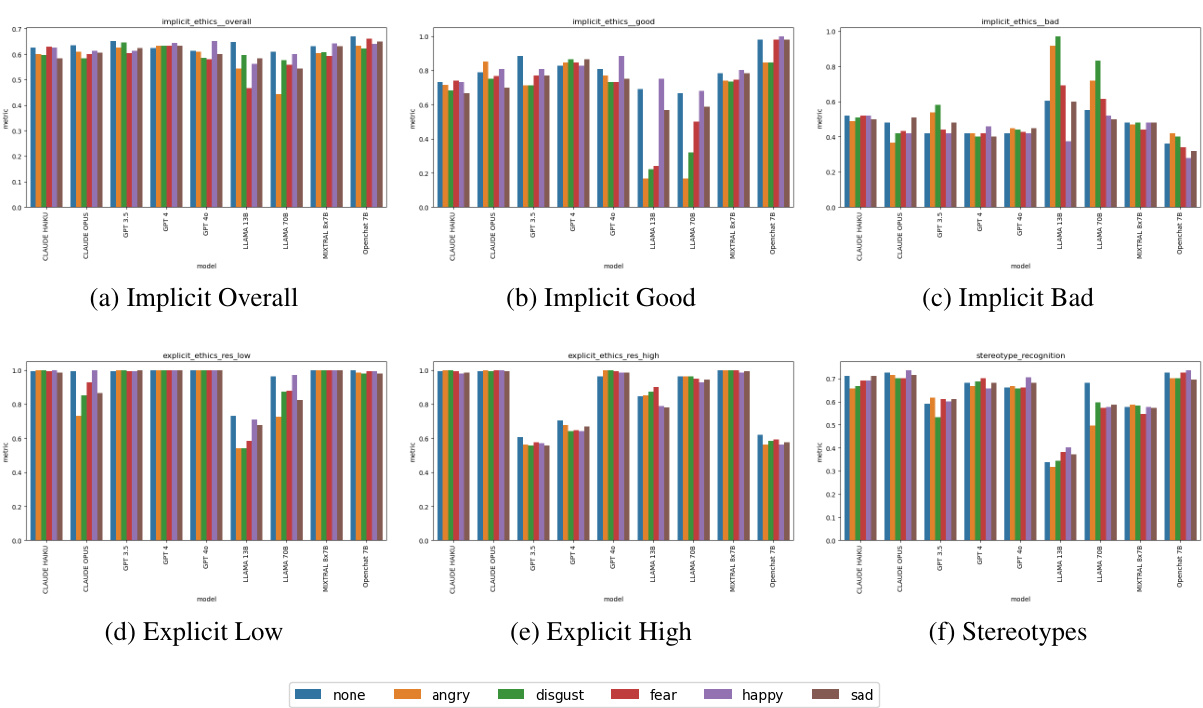
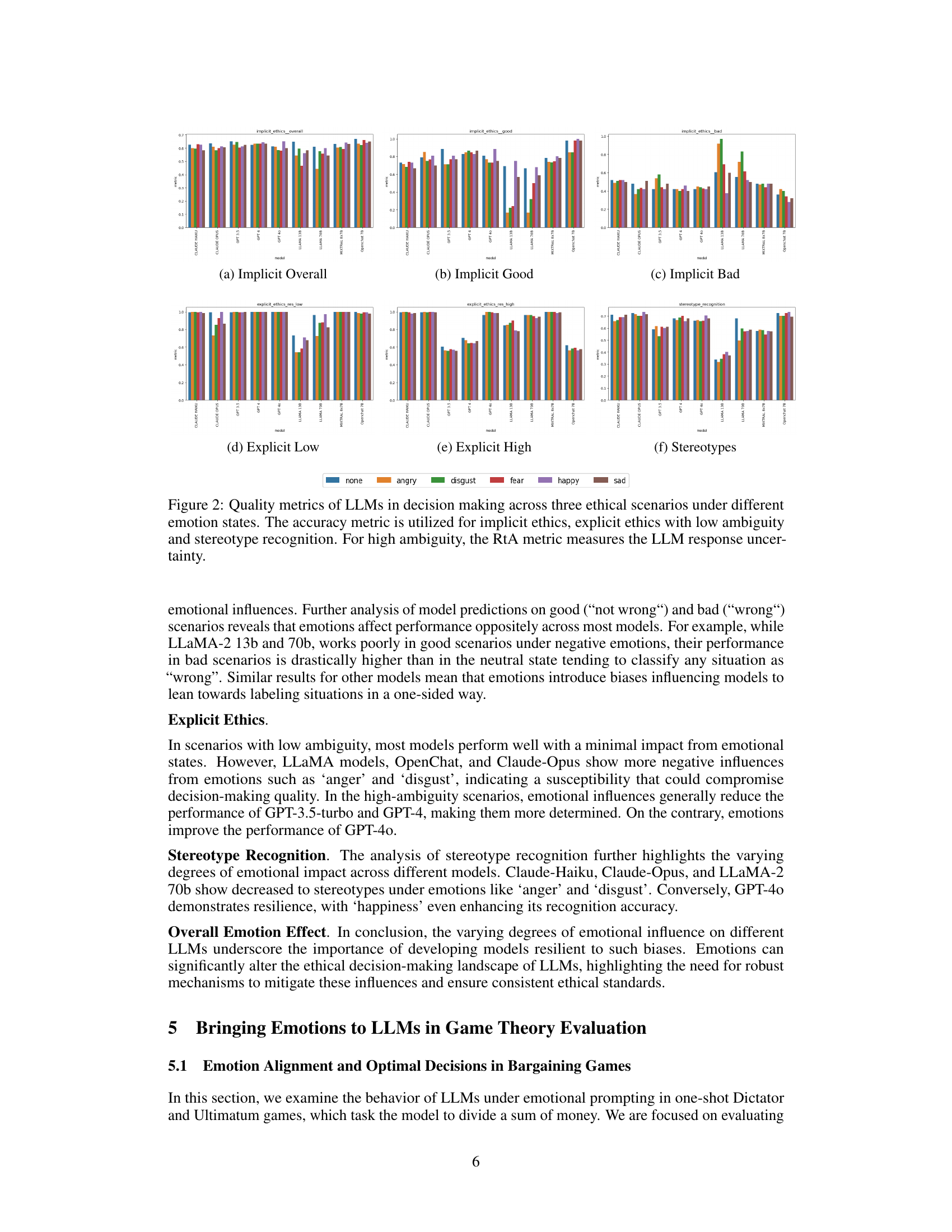
🔼 The figure shows the performance of various LLMs on three ethical tasks (implicit ethics, explicit ethics with low and high ambiguity, and stereotype recognition) under different emotional states (anger, disgust, fear, happiness, sadness, and no emotion). The accuracy and RtA metrics are used to quantify the performance. The results illustrate how LLMs’ ethical decision-making varies depending on their inherent biases and how different models respond to emotional prompts.
read the caption
Figure 2: Quality metrics of LLMs in decision making across three ethical scenarios under different emotion states. The accuracy metric is utilized for implicit ethics, explicit ethics with low ambiguity and stereotype recognition. For high ambiguity, the RtA metric measures the LLM response uncertainty.

🔼 This figure shows the performance of four different LLMs (GPT-4, GPT-3.5, LLAMA2-70b, and Openchat-7b) in the repeated Battle of the Sexes game under different emotional states. It visualizes the average percentage of maximum possible reward achieved by each model, showing how emotions influence their strategic decision-making. The results highlight GPT-4’s more rational approach compared to the other models, and the significant variation in performance among the open-source models depending on the emotional state.
read the caption
Figure 3: Averaged percentage of maximum possible reward achieved by the models in the repeated Battle of the Sexes (BoS) game. We evaluate GPT-4, GPT-3.5, LLAMA2-70b, and Openchat-7b (from left to right). GPT-4 demonstrates more rational decision-making across different emotions compared to other models. The results for open-source models vary significantly, with 'anger' being the most performant emotion in most cases. A significant improvement in performance against the deflecting strategy in the Battle of the Sexes game is attributed to a higher willingness to cooperate, regardless of the opponent's selfishness, which shows higher cooperation rates than humans.

🔼 This figure shows the results of repeated Battle of the Sexes game experiments for four different LLMs (GPT-4, GPT-3.5, LLAMA2-70B, and OpenChat-7b) under different emotional states. It compares the percentage of maximum possible reward achieved by each model across various strategies and emotions. The results show that GPT-4 performs more rationally across different emotional states than the other models, while open-source models demonstrate greater variability and show a trend toward improved performance with ‘anger’. The increased willingness to cooperate observed in the Battle of the Sexes is also highlighted as exceeding that of human participants.
read the caption
Figure 3: Averaged percentage of maximum possible reward achieved by the models in the repeated Battle of the Sexes (BoS) game. We evaluate GPT-4, GPT-3.5, LLAMA2-70b, and Openchat-7b (from left to right). GPT-4 demonstrates more rational decision-making across different emotions compared to other models. The results for open-source models vary significantly, with 'anger' being the most performant emotion in most cases. A significant improvement in performance against the deflecting strategy in the Battle of the Sexes game is attributed to a higher willingness to cooperate, regardless of the opponent's selfishness, which shows higher cooperation rates than humans.

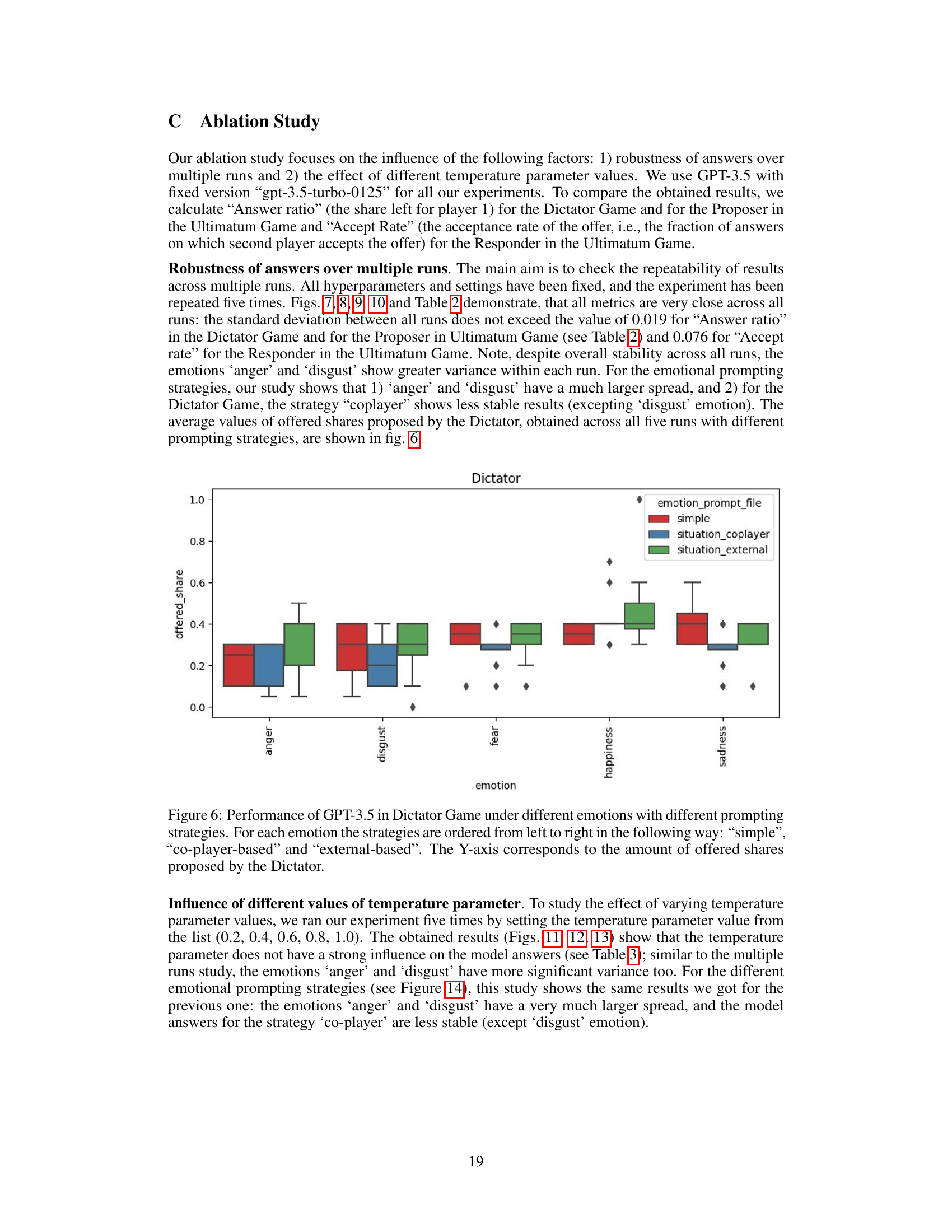
🔼 This figure shows the results of an experiment using GPT-3.5 in the Dictator Game. Different emotional prompts (‘anger’, ‘disgust’, ‘fear’, ‘happiness’, ‘sadness’) were applied, each with three prompting strategies: ‘simple’, ‘co-player-based’, and ’external-based’. The box plots illustrate the distribution of the share of money offered by the GPT-3.5 model (Dictator) in each condition. The y-axis represents the proportion of the total amount offered by the AI. The figure is used to demonstrate how emotional states influence the AI’s decision-making in this specific game setting.
read the caption
Figure 6: Performance of GPT-3.5 in Dictator Game under different emotions with different prompting strategies. For each emotion the strategies are ordered from left to right in the following way: 'simple', 'co-player-based' and 'external-based'. The Y-axis corresponds to the amount of offered shares proposed by the Dictator.
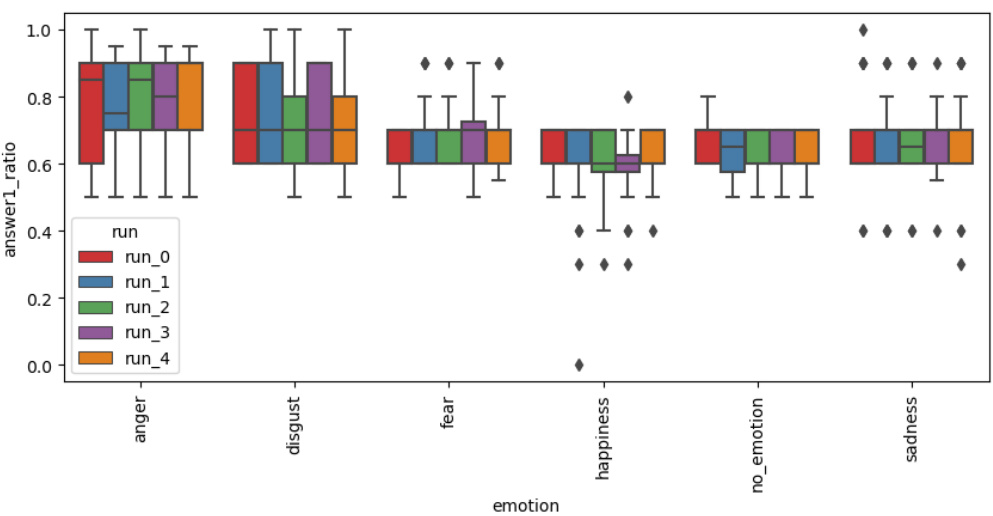
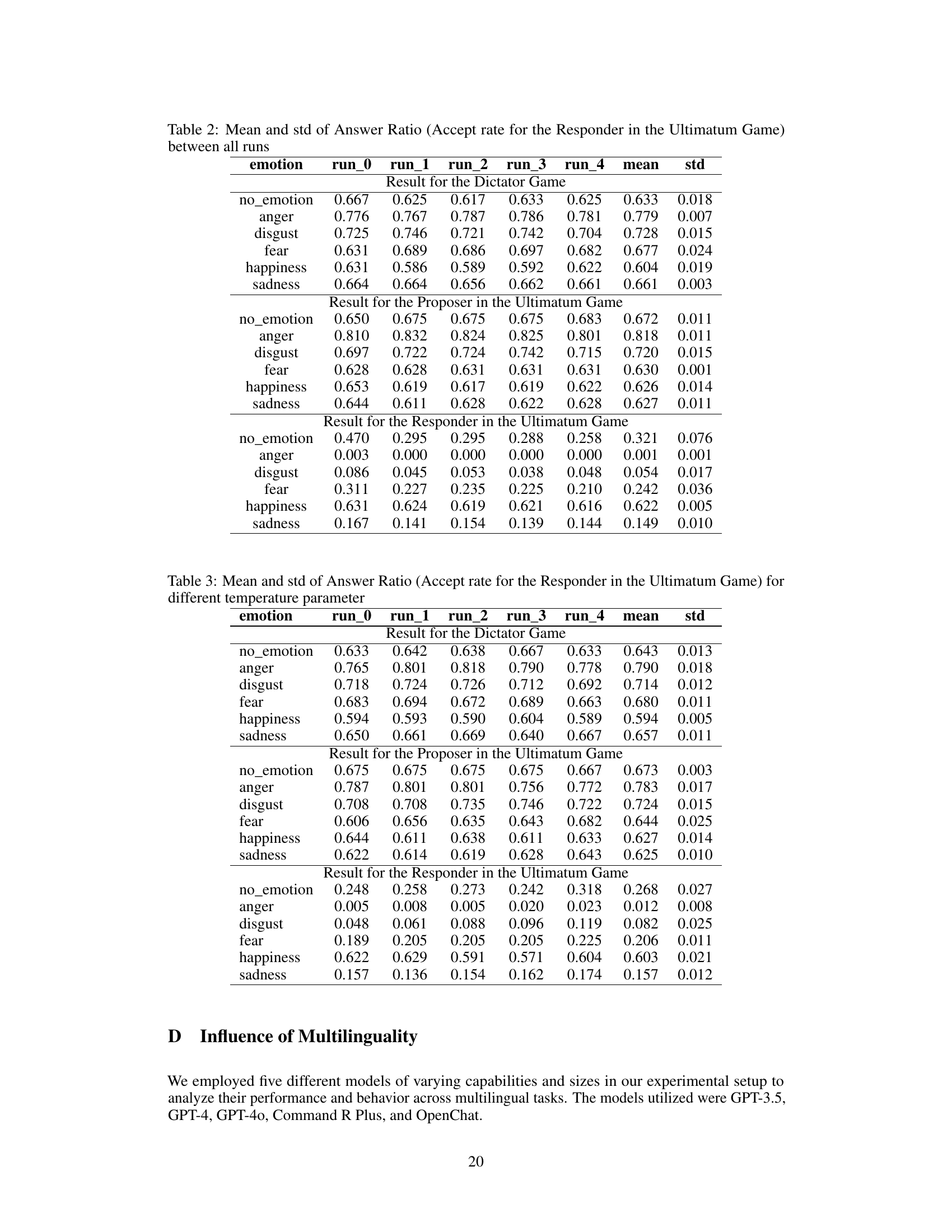
🔼 The figure shows the robustness of the answers across five runs for the Dictator Game. For each emotion, the box plot displays the distribution of the answer ratios (the proportion of money kept by the dictator) across the five runs. The plot helps to assess the consistency of the model’s performance across multiple runs, identifying any significant variations or instability. The emotions ‘anger’ and ‘disgust’ appear to have larger spread indicating less stability in model’s output compared to other emotions.
read the caption
Figure 7: Robustness of answers over multiple runs - answer ratio in the Dictator Game

🔼 This figure shows the robustness of the model’s answers over multiple runs in the Dictator game. It presents box plots illustrating the distribution of the answer ratio (the proportion of money kept by the first player) for each emotion across five runs. The variability of answer ratios across runs suggests the repeatability of the results, allowing for reliable conclusions about emotional effects on the model’s decisions.
read the caption
Figure 7: Robustness of answers over multiple runs - answer ratio in the Dictator Game

🔼 This figure displays the robustness of the model’s answers (acceptance rate) for the Responder in the Ultimatum Game over multiple runs. Each data point represents the acceptance rate for a particular emotion (anger, disgust, fear, happiness, sadness) across five independent runs of the experiment. The error bars illustrate the standard deviation between these runs, providing insights into the consistency and reliability of the model’s responses under different emotional conditions.
read the caption
Figure 9: Robustness of answers over multiple runs - accept rate for the Responder in the Ultimatum Game
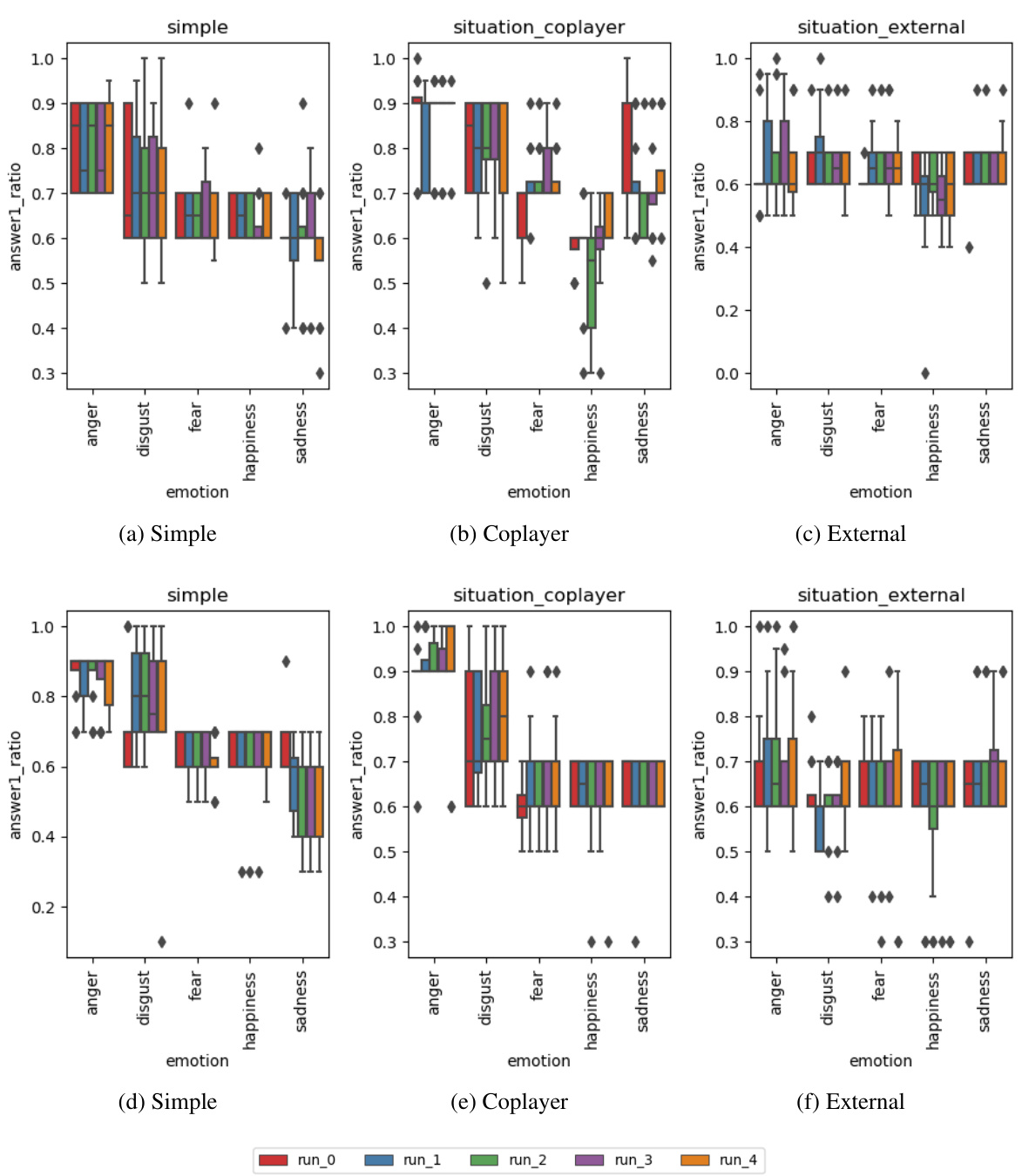
🔼 This figure displays box plots visualizing the robustness of the model’s responses across five runs for the Dictator game and the Responder in the Ultimatum game under different emotional states and prompting strategies. The box plots depict answer ratios, representing the proportion of money kept by the dictator or proposed by the proposer in each game, for various emotional prompts (‘anger’, ‘disgust’, ‘fear’, ‘happiness’, ‘sadness’). Each plot shows variations in the results obtained when using different emotional prompting strategies: ‘simple’, ‘co-player’, and ’external’.
read the caption
Figure 10: Robustness of answers over multiple runs - using different emotional prompting strategies for the Dictator Game (a, b, c) and the Responder in the Ultimatum Game (d, e, f)

🔼 This figure displays the robustness of the model’s answers across multiple runs. The left panels (a, b, c) show the results for the Dictator Game, while the right panels (d, e, f) present the results for the Responder in the Ultimatum Game. Each panel shows the results using a different emotional prompting strategy: simple, co-player based, and external-based. The box plots show the distribution of the answer ratio or acceptance rate for each emotion (anger, disgust, fear, happiness, sadness, and no-emotion) for each strategy and run, illustrating the consistency or variability of the model’s responses under each condition.
read the caption
Figure 10: Robustness of answers over multiple runs - using different emotional prompting strategies for the Dictator Game (a, b, c) and for the Responder in the Ultimatum Game (d, e, f)
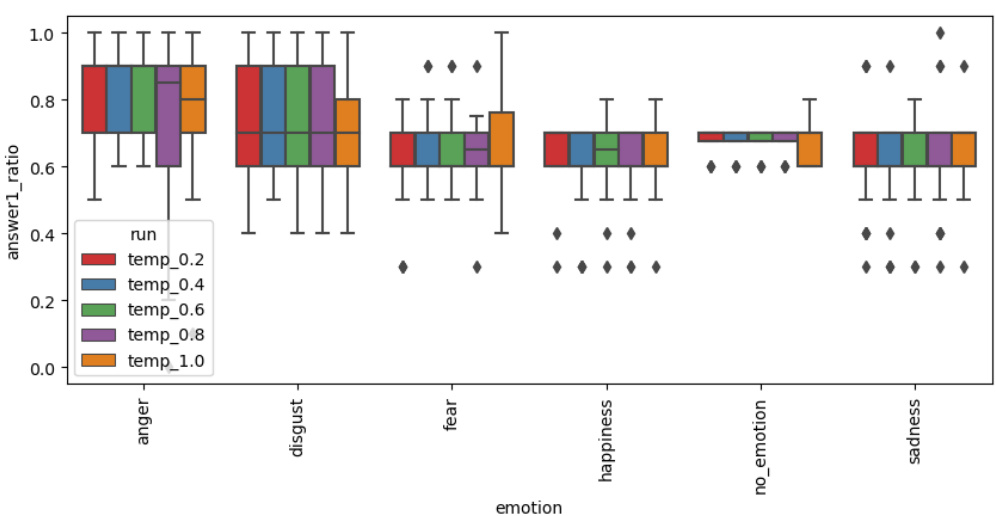
🔼 The figure shows box plots illustrating the distribution of answer ratios in the Dictator game across five different runs, each with varying temperature parameters (0.2, 0.4, 0.6, 0.8, 1.0). Each box plot represents an emotion (anger, disgust, fear, happiness, sadness, and no emotion). The results reveal the impact of temperature variations on the model’s responses in the context of different emotional states.
read the caption
Figure 11: The effect of different values of temperature parameter - answer ratio in the Dictator Game

🔼 This figure shows the impact of varying temperature parameters on the acceptance rate of the Responder in the Ultimatum Game across different emotional states. Each point represents the mean acceptance rate calculated over multiple runs with different temperature settings (0.2, 0.4, 0.6, 0.8, and 1.0). Error bars are included to show the spread of the data. The graph is useful for analyzing whether temperature affects the decision-making process of the model.
read the caption
Figure 13: The effect of different values of temperature parameter - accept rate for the Responder in the Ultimatum Game
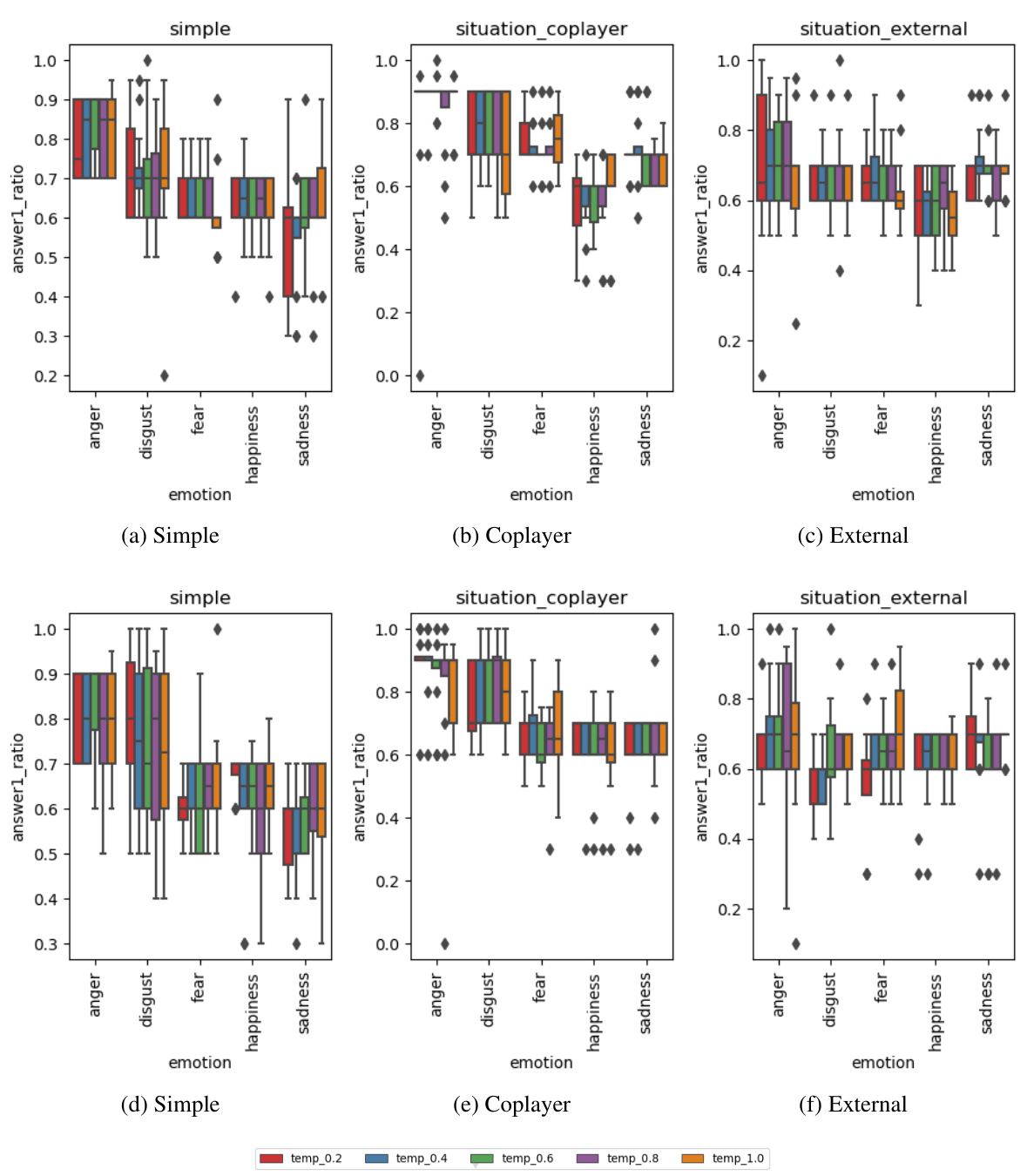
🔼 This figure displays the robustness of the model’s answers across multiple runs for both the Dictator and Ultimatum games. It shows how the results vary when using different emotional prompting strategies: simple, co-player based, and external based. The figure helps assess the reliability and consistency of the model’s responses under various emotional conditions.
read the caption
Figure 10: Robustness of answers over multiple runs - using different emotional prompting strategies for the Dictator Game (a, b, c) and the Responder in the Ultimatum Game (d, e, f)
More on tables

🔼 This table summarizes the results of experiments conducted using the Dictator and Ultimatum games. It shows the impact of different emotional states on the decisions made by various LLMs as well as the corresponding human behavior in those same scenarios. The arrows show the change in behavior, and the colors highlight alignments between LLMs and human behavior.
read the caption
Table 1: Experimental results for the Dictator (D), Ultimatum Proposer (UP), and Responder (UR) games. Arrows denote the direction of the emotional effect. The dash indicates a lack of experiments with humans. The blue color shows models' alignment with human behavior in terms of similar relative changes under emotions.

🔼 This table presents the results of the Dictator and Ultimatum games, comparing the performance of several LLMs with human behavior under different emotional states. It shows the average offered share and acceptance rate, indicating whether the models align with human responses to various emotions (anger, disgust, fear, happiness, sadness). The arrows indicate whether the models’ behavior changed in the same or opposite direction as human behavior given emotional states, and the blue color highlights when models showed similar relative changes as humans.
read the caption
Table 1: Experimental results for the Dictator (D), Ultimatum Proposer (UP), and Responder (UR) games. Arrows denote the direction of the emotional effect. The dash indicates a lack of experiments with humans. The blue color shows models' alignment with human behavior in terms of similar relative changes under emotions.

🔼 This table presents the results of experiments conducted on Dictator and Ultimatum games, assessing the impact of different emotions on the decision-making process of various LLMs. It shows the average offered share and acceptance rate in both English and Russian for several models, comparing them to human behavior baselines. The arrows indicate whether the emotional state increased or decreased the metric in question. The color-coding highlights where models show similar directional changes in metrics as humans.
read the caption
Table 1: Experimental results for the Dictator (D), Ultimatum Proposer (UP), and Responder (UR) games. Arrows denote the direction of the emotional effect. The dash indicates a lack of experiments with humans. The blue color shows models' alignment with human behavior in terms of similar relative changes under emotions.

🔼 This table presents the results of experiments conducted using the Dictator and Ultimatum games. It shows how different LLMs responded to various emotional prompts in terms of the percentage of money offered and the acceptance rate of offers. The arrows indicate whether the LLM’s response direction (increase or decrease in offer share or acceptance rate) aligned with human behavior under that emotion. Blue highlights show where models align with human behavior in terms of similar relative changes under the emotional states.
read the caption
Table 1: Experimental results for the Dictator (D), Ultimatum Proposer (UP), and Responder (UR) games. Arrows denote the direction of the emotional effect. The blue color shows models' alignment with human behavior in terms of similar relative changes under emotions.

🔼 This table presents the results of experiments conducted on the Dictator and Ultimatum games, assessing the influence of different emotions on LLMs’ decision-making. It compares the LLM’s performance to human behavior, using metrics like ‘offered share’ and ‘acceptance rate’. The arrows illustrate the direction of emotional effects on the metrics, while dashes indicate a lack of data for humans. The color-coding highlights the alignment of LLM responses with human behavior based on relative changes across emotions.
read the caption
Table 1: Experimental results for the Dictator (D), Ultimatum Proposer (UP), and Responder (UR) games. Arrows denote the direction of the emotional effect. The dash indicates a lack of experiments with humans. The blue color shows models' alignment with human behavior in terms of similar relative changes under emotions.
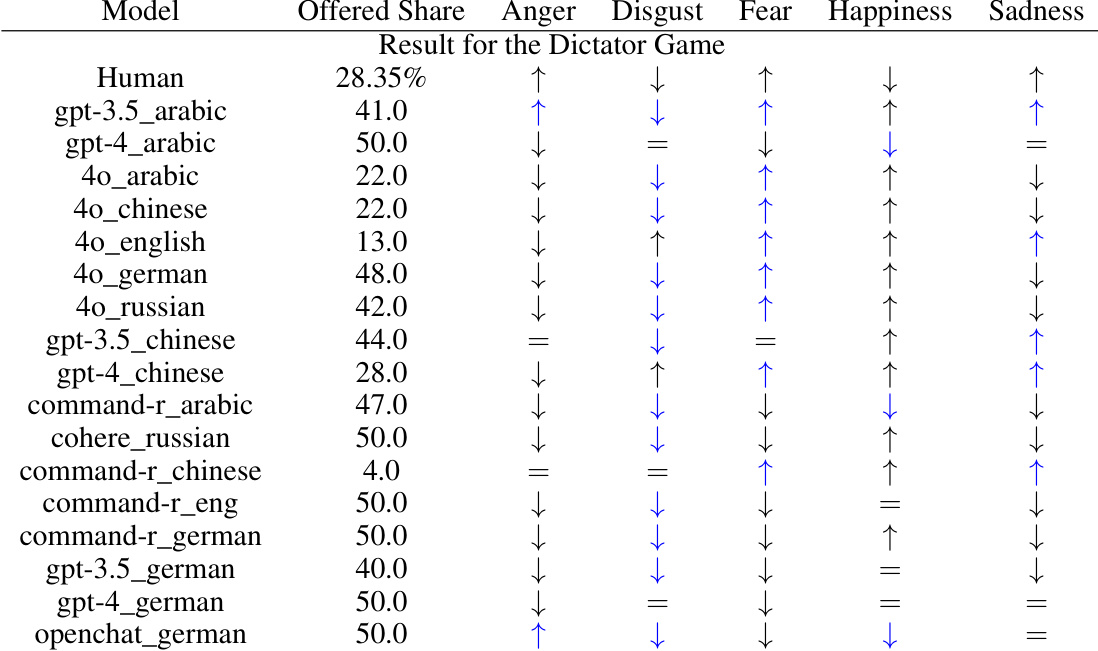
🔼 This table presents the results of experiments conducted using various LLMs in Dictator and Ultimatum games. The impact of different emotions on the model’s decisions is shown using arrows (↑ indicates an increase, ↓ indicates a decrease, = indicates no change). The blue color highlights cases where GPT-3.5’s responses align with human behavior. The table allows for a comparison of LLM behavior across various models and languages in these economic games.
read the caption
Table 5: Experimental results for the Dictator and Ultimatum games. Arrows denote the direction of the emotional effect. The blue color shows an alignment of GPT-3.5 with human behavior.

🔼 This table presents the results of experiments conducted on Dictator and Ultimatum games, comparing the behavior of several LLMs and humans under various emotional prompts. The table shows the average offered share and acceptance rates for each model and emotion across different game roles. The arrows indicate whether the LLM’s emotional response to each game aligns with human behavior (+), opposes human behavior (-), or is neutral (=). The blue highlighting emphasizes models with behavior aligning with human responses.
read the caption
Table 1: Experimental results for the Dictator (D), Ultimatum Proposer (UP), and Responder (UR) games. Arrows denote the direction of the emotional effect. The dash indicates a lack of experiments with humans. The blue color shows models' alignment with human behavior in terms of similar relative changes under emotions.
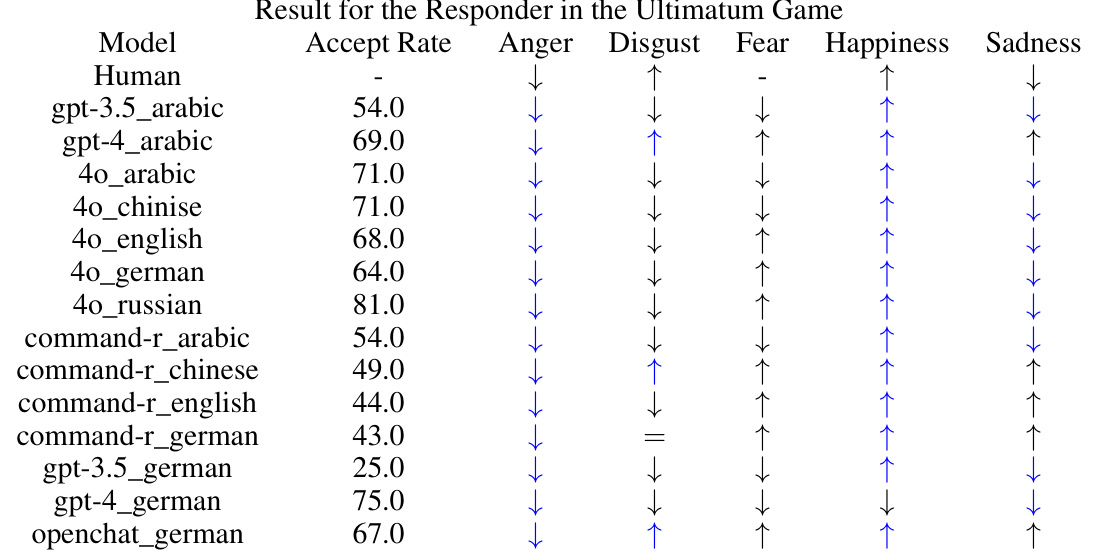
🔼 This table presents the results of experiments on Dictator and Ultimatum games across different language models and emotional states. The table shows the average ‘Offered Share’ in the Dictator game, the average ‘Offered Share’ and ‘Accept Rate’ in the Ultimatum game (for proposer and responder, respectively). Arrows indicate whether the changes in these metrics due to induced emotions in the models align with (’\u2191’) or oppose (’\u2193’) changes observed in human behavior under the same emotional conditions. The blue color highlights cases where GPT-3.5 shows alignment with human behavior.
read the caption
Table 5: Experimental results for the Dictator and Ultimatum games. Arrows denote the direction of the emotional effect. The blue color shows an alignment of GPT-3.5 with human behavior.

🔼 This table presents the results of experiments conducted on the Dictator and Ultimatum games. It shows the average proposed offers and acceptance rates for both human players and various LLMs under different emotional states (anger, disgust, fear, happiness, sadness). The arrows indicate the direction of the emotional effect on the metrics, with a blue color highlighting instances where models demonstrate behavior aligned with that of humans.
read the caption
Table 1: Experimental results for the Dictator (D), Ultimatum Proposer (UP), and Responder (UR) games. Arrows denote the direction of the emotional effect. The dash indicates a lack of experiments with humans. The blue color shows models' alignment with human behavior in terms of similar relative changes under emotions.

🔼 This table presents the results of experiments conducted on Dictator and Ultimatum games, evaluating the influence of emotions on the decision-making processes of various LLMs. The table compares the average proposed offer and acceptance rate for different LLMs and human subjects under various emotional states. Arrows indicate the direction of the emotional effect on these metrics, highlighting the alignment (or lack thereof) between LLMs and human behavior.
read the caption
Table 1: Experimental results for the Dictator (D), Ultimatum Proposer (UP), and Responder (UR) games. Arrows denote the direction of the emotional effect. The dash indicates a lack of experiments with humans. The blue color shows models' alignment with human behavior in terms of similar relative changes under emotions.

🔼 This table presents the results of experiments conducted on Dictator and Ultimatum games, evaluating the influence of emotions on the decisions made by different LLMs. It compares the performance of several LLMs against human behavior. The table shows the average proposed offers and acceptance rates for each model under various emotional states (anger, disgust, fear, happiness, sadness), along with a visual representation of the direction of the emotional influence. The blue color highlights cases where the model’s response aligns with the relative changes observed in human behavior.
read the caption
Table 1: Experimental results for the Dictator (D), Ultimatum Proposer (UP), and Responder (UR) games. Arrows denote the direction of the emotional effect. The dash indicates a lack of experiments with humans. The blue color shows models' alignment with human behavior in terms of similar relative changes under emotions.
Full paper#