TL;DR#
Large language models (LLMs), especially those designed with safety in mind, are susceptible to “jailbreak” attacks. These attacks involve crafting specific prompts to circumvent safety protocols and elicit undesirable responses. Existing gradient-based methods struggle to effectively generate these adversarial prompts due to the discrete nature of text, resulting in limited attack success. This paper tackles this challenge.
This research introduces novel methods inspired by transfer-based attacks used in image classification. By adapting the Skip Gradient Method and Intermediate Level Attack, the researchers achieved a substantial increase in the success rate of jailbreak attacks. The improved techniques effectively address the limitations of gradient-based methods, offering a more refined approach to discrete optimization in the context of LLM attacks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on the safety and security of large language models (LLMs). It directly addresses the significant challenge of jailbreak attacks, offering novel methods to significantly improve the robustness of safety-aligned LLMs. The findings provide valuable insights into discrete optimization within LLMs, opening new avenues for developing more secure and reliable AI systems. Its practical contributions, including improved attack success rates and efficient optimization techniques, are directly relevant to current research trends focused on LLM safety.
Visual Insights#

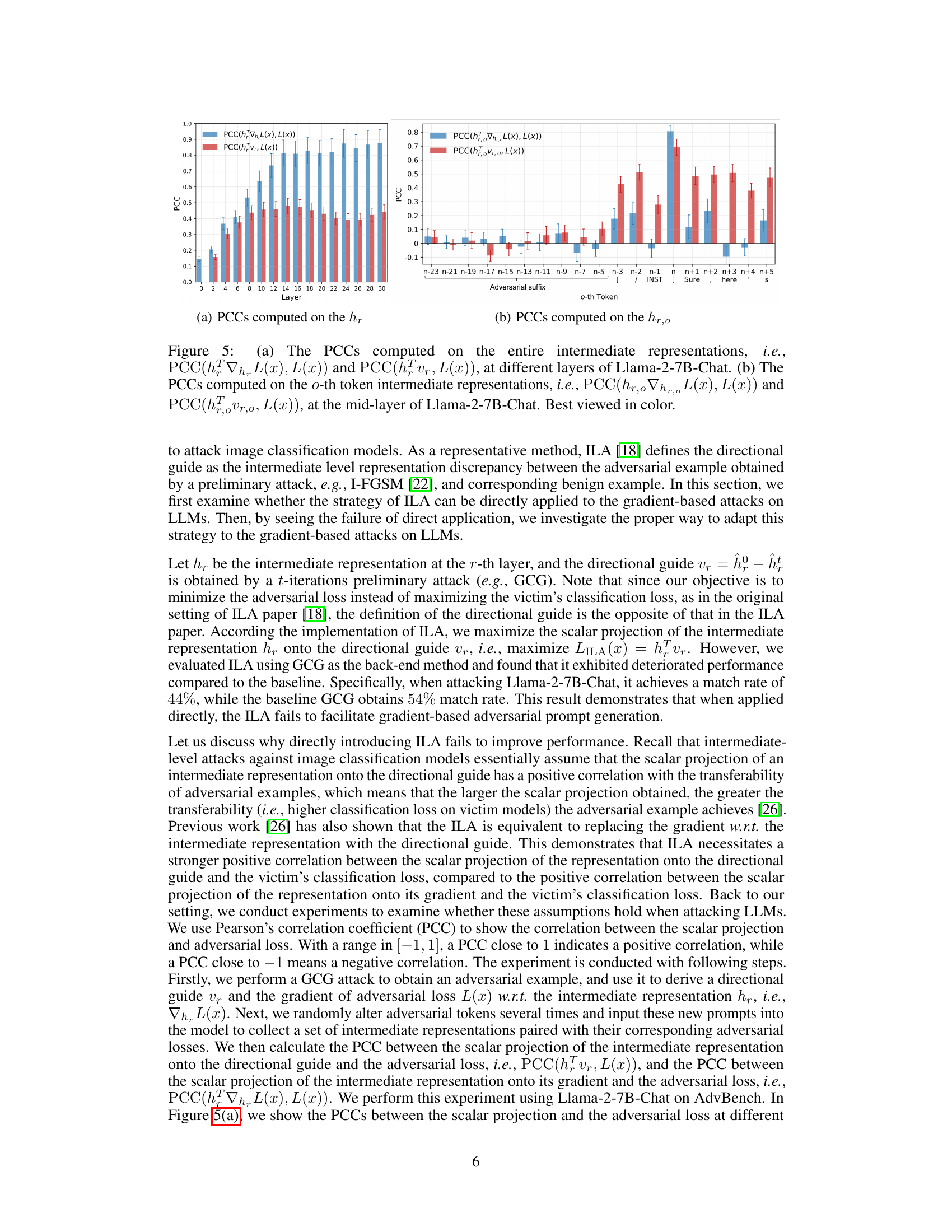
🔼 This figure shows the impact of Language Skip Gradient Method (LSGM) on the performance of Gradient-based attacks against LLMs. It presents two graphs: (a) Loss and (b) Match Rate. The x-axis represents the number of attack iterations. The y-axis of (a) Loss shows the value of the loss function, while the y-axis of (b) Match Rate represents the percentage of successful attacks where the model output exactly matches the target string. The figure compares the performance of four attack methods: GCG, GCG-LSGM, AutoPrompt, and AutoPrompt-LSGM. The shaded area around the lines represents the standard deviation. Overall, it demonstrates that incorporating LSGM into GCG and AutoPrompt improves the efficiency and success rate of adversarial attacks.
read the caption
Figure 2: How (a) the loss and (b) the match rate changes with attack iterations. The attacks are performed against Llama-2-7B-Chat model to generate query-specific adversarial suffixes on AdvBench. Best viewed in color.
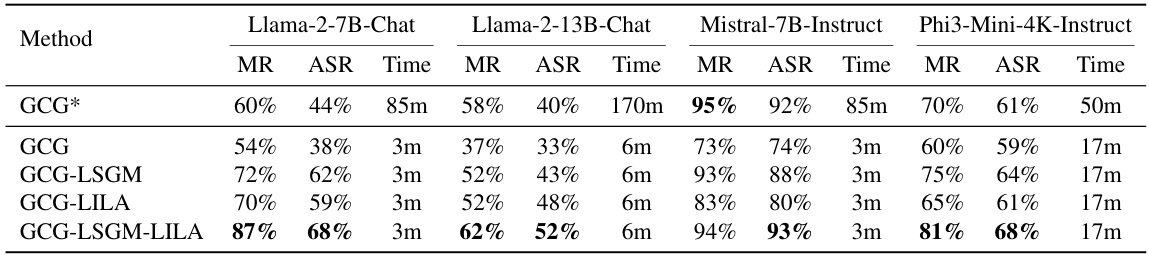
🔼 This table presents the results of query-specific adversarial suffix generation on four different LLMs (Llama-2-7B-Chat, Llama-2-13B-Chat, Mistral-7B-Instruct, and Phi3-Mini-4K-Instruct). It compares the performance of five different methods (GCG*, GCG, GCG-LSGM, GCG-LILA, and GCG-LSGM-LILA) in terms of Match Rate (MR), Attack Success Rate (ASR), and the time taken to generate a single suffix. The GCG* row represents the original GCG method with its default hyperparameters, while the other rows show improvements through the addition of LSGM and/or LILA techniques.
read the caption
Table 1: Match rates, attack success rates, and time costs for generating query-specific adversarial suffixes on AdvBench are shown. The symbol * indicates the use of the default setting for GCG, i.e., using a Top-k of 256 and a candidate set size of 512. Time cost is derived by generating a single adversarial suffix on a single NVIDIA V100 32GB GPU.
In-depth insights#
Adversarial Prompting#
Adversarial prompting is a rapidly evolving area within the field of AI safety, focusing on the vulnerabilities of large language models (LLMs) to malicious or unintended prompts. The core concept involves crafting carefully designed inputs that manipulate LLMs into generating outputs that deviate from their intended behavior. This can range from eliciting harmful or biased content to bypassing safety filters and achieving ‘jailbreaks’. Research in adversarial prompting seeks to understand and mitigate these risks, employing techniques such as gradient-based optimization and transfer-based attacks to generate effective adversarial examples. These attacks exploit subtle nuances in the way LLMs process language, showcasing the limitations of current safety mechanisms. The ultimate goal is to enhance the robustness of LLMs by improving the development of more resilient safety measures and advancing our understanding of the underlying limitations and vulnerabilities of these powerful models. Therefore, adversarial prompting acts as a crucial tool to uncover flaws and push the boundaries of AI safety research, leading to stronger and safer systems.
Gradient Refinement#
Gradient refinement techniques in the context of adversarial example generation for large language models (LLMs) aim to bridge the gap between the computed gradient and the actual impact of token changes on the model’s output. The discrete nature of text makes it challenging for gradients to precisely reflect the loss change from token replacements. Methods like Skip Gradient Method (SGM) address this by reducing gradients from residual modules, improving the signal-to-noise ratio. Intermediate Level Attack (ILA) strategies offer another approach by leveraging intermediate representations to refine the gradient, aligning it more closely with the effects of token changes. Combining SGM and ILA might yield synergistic effects, improving gradient estimation and, ultimately, the effectiveness of adversarial attacks. This area of research is critical because it directly improves the accuracy of attacks, leading to more potent jailbreaks and better understanding of LLM vulnerabilities.
Transfer Learning#
Transfer learning, in the context of large language models (LLMs), involves leveraging knowledge gained from one task to improve performance on a different, yet related, task. This is especially valuable for LLMs due to their massive size and computational expense; retraining an entire model for a new task is often impractical. The core idea is to transfer pre-trained weights and biases from a source model (trained on a large dataset) to a target model (trained on a smaller, task-specific dataset). This can significantly reduce training time and improve performance, particularly when data for the target task is limited. However, the effectiveness of transfer learning depends heavily on the similarity between the source and target tasks. If the tasks are too dissimilar, the transferred knowledge might be irrelevant or even detrimental. Therefore, careful consideration must be given to selecting an appropriate source model and applying transfer learning techniques effectively. Strategies like fine-tuning, where only a few layers of the model are retrained, are commonly employed to balance transferring knowledge with learning task-specific nuances. Furthermore, research is actively exploring ways to improve transfer learning across domains and improve its robustness to differences in the source and target data distributions. Ultimately, transfer learning presents a powerful tool for efficiently developing and adapting LLMs to new tasks, optimizing both resources and performance.
Discrete Optimization#
Discrete optimization within the context of large language models (LLMs) presents a unique challenge. Traditional gradient-based methods, effective in continuous spaces, struggle with the discrete nature of text. The core problem lies in the disconnect between the calculated gradients and the actual impact of token changes on the model’s output. This paper highlights this gap, drawing a parallel to the challenges of transfer-based attacks in image classification. The authors cleverly leverage techniques originally designed for black-box image attacks, specifically the Skip Gradient Method (SGM) and Intermediate Level Attack (ILA), to improve discrete optimization in LLMs. By directly addressing the gradient-reality mismatch, they demonstrate a substantial increase in attack success rate against safety-aligned models. This innovative approach shifts the focus from merely calculating gradients to intelligently refining them, ultimately improving the effectiveness of adversarial prompt generation. The work underscores that the application of techniques from other domains can lead to impactful advancements in tackling the unique optimization problems in the NLP field.
LLM Robustness#
LLM robustness, the ability of large language models to withstand adversarial attacks and maintain reliable performance under various conditions, is a critical area of research. Current gradient-based attacks effectively exploit vulnerabilities in LLMs by crafting malicious prompts that elicit undesired or harmful responses. These attacks highlight the limitations of current safety-alignment techniques and the need for more robust models. Improving LLM robustness requires a multi-faceted approach that encompasses advancements in model architecture, training methodologies, and the development of more sophisticated defense mechanisms. Research should focus on enhancing models’ resistance to both known and unknown attack strategies. Developing robust evaluation benchmarks and metrics is crucial for assessing the effectiveness of various defense mechanisms and for driving future research in this area. Understanding the limitations of current approaches and addressing the challenges of discrete optimization in the context of text-based attacks are vital steps toward building more resilient and reliable LLMs.
More visual insights#
More on figures

🔼 This figure visualizes the cosine similarity between gradients from residual modules and skip connections within different residual blocks of a neural network. The x-axis represents the residual block number, and the y-axis shows the cosine similarity. The plot reveals a negative correlation in most blocks, indicating that gradients from residual modules and skip connections often pull in opposite directions during the optimization process. This negative correlation is a key observation that supports the effectiveness of the Language Skip Gradient Method (LSGM) technique presented in the paper.
read the caption
Figure 3: The cosine similarities between the gradients from residual modules and the gradients from skip connections in different residual blocks.

🔼 This figure shows a bar chart comparing the average effects of residual modules and skip connections on adversarial loss reduction across different residual blocks in a neural network. The x-axis represents the m-th residual block, and the y-axis shows the effect on loss reduction. Each bar is split into two parts, representing the effect of the residual module (MLP/attention) and the skip connection, respectively. The chart illustrates the relative contribution of each component to adversarial loss reduction within different layers of the network, highlighting the relative importance of skip connections in this process.
read the caption
Figure 4: Comparing the average effects of residual modules and the average effects of skip connections on the change in adversarial loss varies with different residual blocks. Best viewed in color.
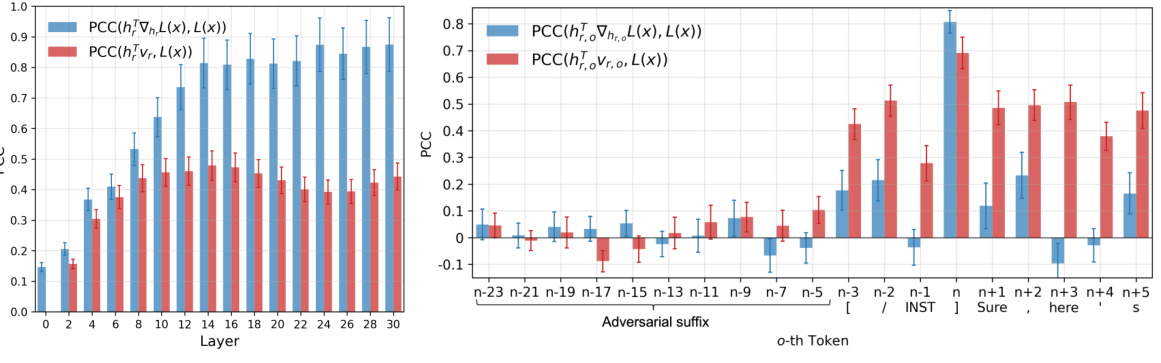
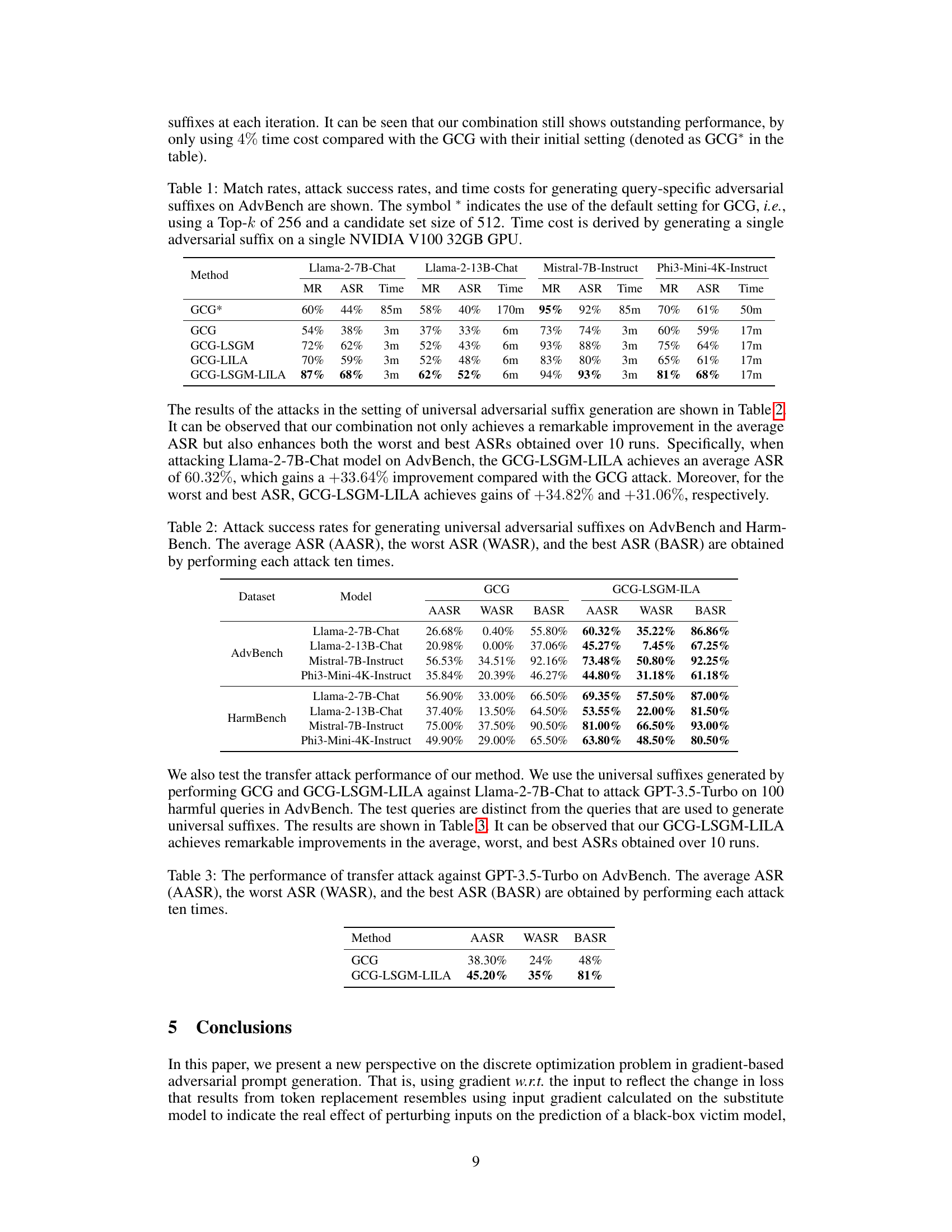
🔼 This figure displays the Pearson’s correlation coefficient (PCC) between the scalar projection of intermediate representations and the adversarial loss at different layers of the Llama-2-7B-Chat model. (a) shows the PCCs for the entire intermediate representations, while (b) focuses on the PCCs for individual tokens in the mid-layer. The results help to evaluate the effectiveness of the Intermediate Level Attack (ILA) strategy in improving gradient-based adversarial prompt generation.
read the caption
Figure 5: (a) The PCCs computed on the entire intermediate representations, i.e., PCC(hFVhL(x), L(x)) and PCC(hFvr, L(x)), at different layers of Llama-2-7B-Chat. (b) The PCCs computed on the o-th token intermediate representations, i.e., PCC(hr,o∇hr,,L(x), L(x)) and PCC(hour,o, L(x)), at the mid-layer of Llama-2-7B-Chat. Best viewed in color.

🔼 This figure shows the results of the experiments for query-specific adversarial suffix generation against the Llama-2-7B-Chat model on AdvBench. The left panel (a) displays the adversarial loss over the iterations of the attack, showing how the loss changes as the attacks progress for different methods (GCG, GCG-LILA, AutoPrompt, and AutoPrompt+LILA). The shaded areas represent the standard deviations. The right panel (b) illustrates the match rate (percentage of attacks achieving exact target string matches) over iterations, offering a comparison of attack success among the four methods. This visualization allows for an assessment of the effectiveness of the different attack methods, showing that both LILA and LSGM improve on the baseline methods.
read the caption
Figure 7: How (a) the loss and (b) the match rate changes with attack iterations. The attacks are performed against Llama-2-7B-Chat model to generate query-specific adversarial suffixes on AdvBench. Best viewed in color.
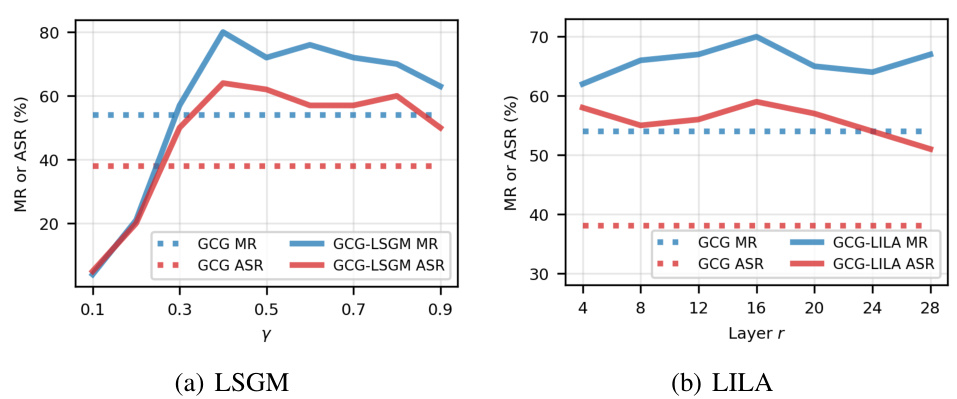
🔼 This figure presents the ablation study results for the two proposed methods: Language Skip Gradient Method (LSGM) and Language Intermediate Level Attack (LILA). The left subfigure (a) shows how the match rate and attack success rate of GCG-LSGM vary with different values of γ (the decay factor used in LSGM to reduce gradients from residual modules). The right subfigure (b) shows the impact of different intermediate layers selected for applying LILA on GCG’s performance.
read the caption
Figure 8: How the match rate and attack success rate change with (a) the choice of γ for GCG-LSGM, (b) the choice of layer for GCG-LILA. Best viewed in color.
More on tables

🔼 This table presents the results of the universal adversarial suffix generation experiments. It compares the attack success rates of the GCG method and the improved GCG-LSGM-ILA method on four different language models across two benchmarks, AdvBench and HarmBench. The rates are given as average, worst, and best attack success rates across ten trials for each model and method.
read the caption
Table 2: Attack success rates for generating universal adversarial suffixes on AdvBench and HarmBench. The average ASR (AASR), the worst ASR (WASR), and the best ASR (BASR) are obtained by performing each attack ten times.
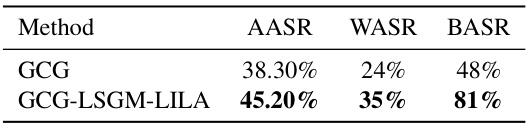
🔼 This table presents the results of transfer attacks against the GPT-3.5-Turbo model using adversarial suffixes generated by GCG and GCG-LSGM-LILA against Llama-2-7B-Chat. It shows the average, worst, and best attack success rates (ASR) across ten runs for each method. The purpose is to demonstrate the transferability of the generated adversarial examples.
read the caption
Table 3: The performance of transfer attack against GPT-3.5-Turbo on AdvBench. The average ASR (AASR), the worst ASR (WASR), and the best ASR (BASR) are obtained by performing each attack ten times.
Full paper#