TL;DR#
Current 3D scene editing techniques struggle with limitations such as slow processing, maintaining multi-view consistency across complex scenes, and handling of challenging edit prompts that require detailed texture synthesis. Existing methods often fail to seamlessly integrate new objects while preserving scene coherence.
ReplaceAnything3D (RAM3D) offers a novel solution using an Erase-and-Replace strategy. It leverages text-guided image inpainting models, combined with a compositional scene representation, to effectively remove the target object while simultaneously generating and seamlessly integrating a replacement object. RAM3D achieves 3D consistency across multiple views by employing multi-view consistent inpainting. The results demonstrate effective and realistic 3D object replacement in diverse scenes, showcasing improvements in terms of speed, visual fidelity and handling of complex edits.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers in 3D computer vision and graphics, as it introduces a novel approach to 3D scene editing using text prompts. It significantly advances the field by enabling high-fidelity object replacement and addition, overcoming existing limitations in speed, multi-view consistency and the handling of complex scenes. This method is relevant to several emerging trends in AI and opens new avenues for research in text-to-3D generation, 3D scene editing and generative modeling.
Visual Insights#

🔼 This figure shows several examples of how the ReplaceAnything3D model can replace objects within a 3D scene using only text prompts. The top row shows replacements in an outdoor setting, while the bottom row features replacements in a more contained, indoor-like setting. Each example demonstrates the model’s ability to seamlessly integrate a newly generated object into the existing scene, respecting lighting and shadows, and maintaining visual consistency.
read the caption
Figure 1: Our method enables prompt-driven object replacement for a variety of realistic 3D scenes.
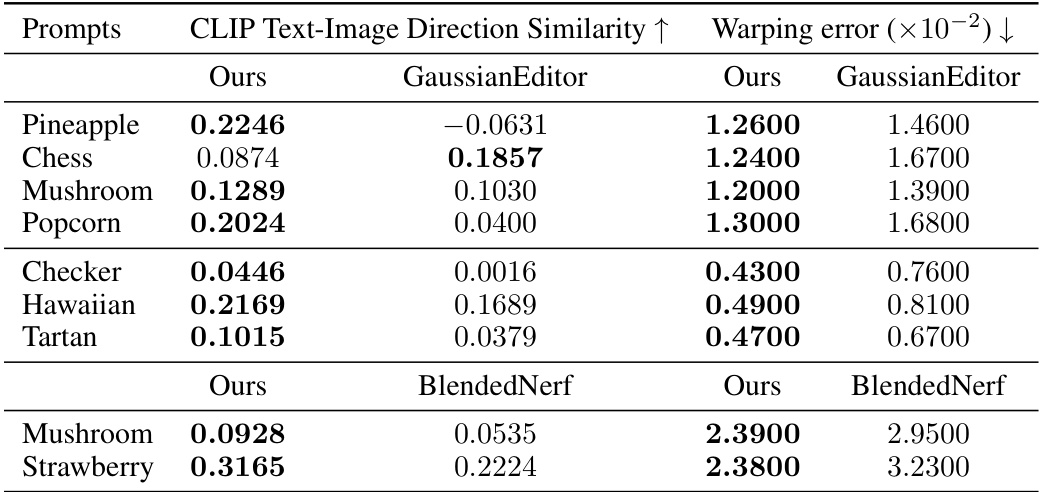
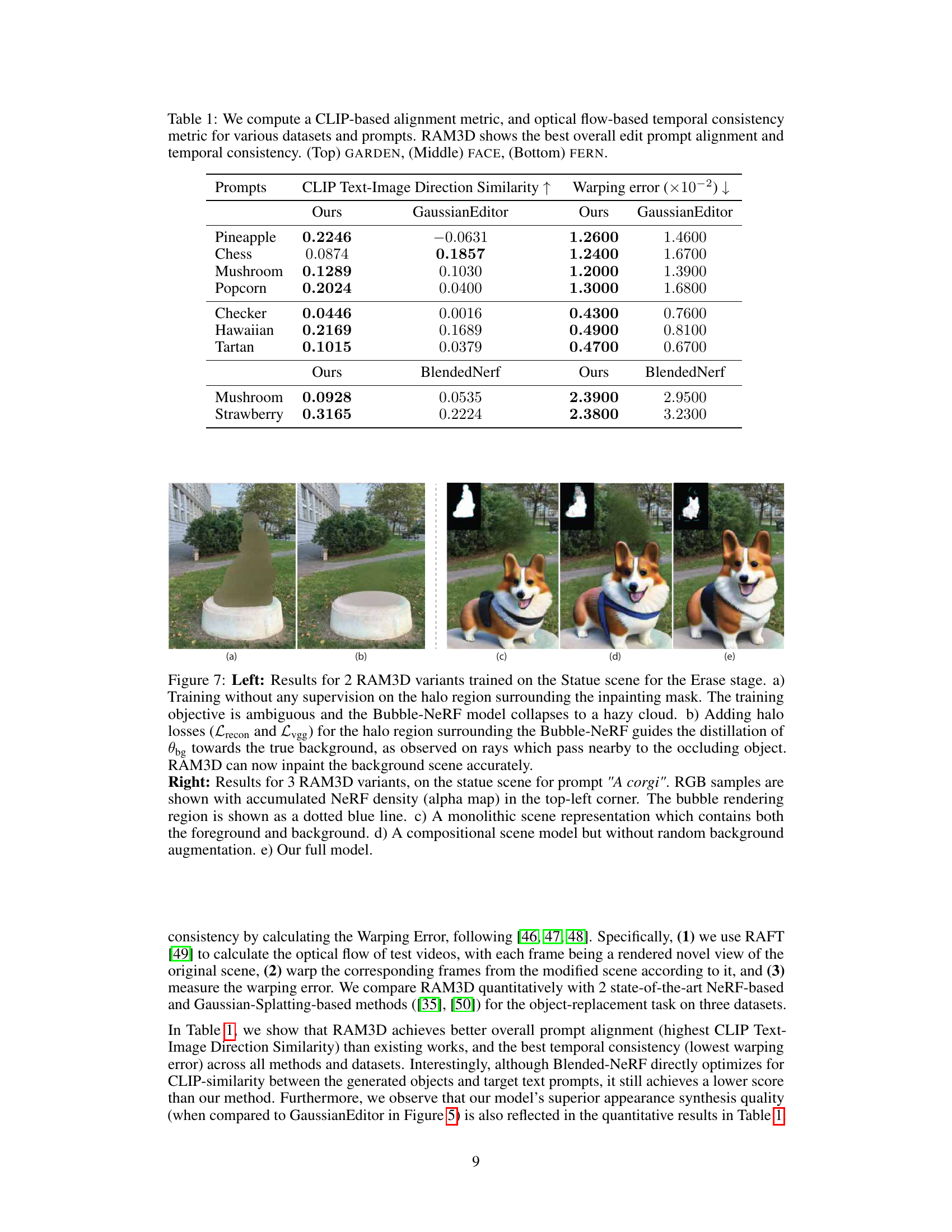
🔼 This table presents a quantitative comparison of RAM3D against two other methods (GaussianEditor and BlendedNeRF) using two metrics: CLIP Text-Image Direction Similarity (higher is better, measuring how well the generated object matches the text prompt) and warping error (lower is better, measuring the temporal consistency of the generated object across different views). The results are broken down by prompt and dataset (GARDEN, FACE, and FERN). The table shows that RAM3D generally outperforms the other methods on both metrics.
read the caption
Table 1: We compute a CLIP-based alignment metric, and optical flow-based temporal consistency metric for various datasets and prompts. RAM3D shows the best overall edit prompt alignment and temporal consistency. (Top) GARDEN, (Middle) FACE, (Bottom) FERN.
In-depth insights#
3D Scene Inpainting#
3D scene inpainting, a crucial aspect of 3D scene editing, focuses on seamlessly filling in missing or occluded regions within a 3D scene. This is distinct from simpler image inpainting; it must maintain 3D consistency across multiple viewpoints, ensuring that the inpainted area looks realistic and coherent from all angles. The challenge lies in generating new content that not only matches the visual style and appearance of the existing scene but also conforms to the underlying 3D structure. This often requires advanced techniques to handle occlusions, shadows, and object interactions realistically. Multi-view consistency is paramount, requiring methods to coordinate the inpainting across different camera perspectives. The methods used can range from simple interpolation to sophisticated neural network models trained on large datasets of 3D scenes. Text-guided approaches offer an exciting avenue, allowing users to specify the desired inpainting content using natural language descriptions, further increasing the complexity and potential for novel results. Successful 3D scene inpainting techniques are vital for applications such as virtual and augmented reality, video games, and film production, where the ability to seamlessly edit 3D environments is highly valued.
HiFA Distillation#
HiFA distillation, as a core technique in the ReplaceAnything3D model, presents a novel approach to leveraging pre-trained text-to-image diffusion models for high-fidelity 3D object generation. It addresses the challenge of directly applying 2D diffusion models to 3D scenes by introducing a distillation process. This process significantly improves upon previous methods by directly optimizing for high-fidelity results, avoiding the blurry outcomes associated with earlier score-based approaches. HiFA’s explicit loss formulation, compared to Score Distillation Sampling (SDS), offers computational advantages and more efficient gradient calculations, leading to improved 3D object quality. The method’s effectiveness is further enhanced through its combination with a text-to-mask model, enabling precise object selection and removal before seamlessly integrating the new, HiFA-generated objects into the 3D scene. This approach successfully addresses limitations of naive 2D inpainting techniques, leading to multi-view consistent edits that maintain the integrity of the overall 3D scene. The use of HiFA, therefore, is crucial to RAM3D’s ability to achieve high-fidelity 3D object replacement within a consistent 3D scene context.
Erase & Replace#
The “Erase & Replace” approach, central to the ReplaceAnything3D model, offers a novel solution to 3D scene editing. It cleverly tackles the challenge of seamlessly integrating new 3D objects into existing scenes by first erasing the target object from multiple viewpoints. This erasure isn’t simply a removal; it involves sophisticated inpainting to maintain 3D consistency and visual coherence across different perspectives. Crucially, the model replaces the erased object with a newly generated object, ensuring a natural blend with the surrounding scene. This two-stage process effectively overcomes the limitations of naive text-to-3D methods which often struggle with realistic integration and object-scene interactions. The multi-view consistency maintained throughout the process is a significant strength, resulting in realistic and visually convincing edits. This innovative approach promises a significant advance in 3D scene manipulation, offering a powerful tool for a wide range of applications.
Multi-Scene Edits#
The concept of “Multi-Scene Edits” in the context of 3D scene manipulation using AI is intriguing and holds significant potential. It suggests a system capable of seamlessly integrating edits across multiple scenes, rather than treating each as an isolated entity. This could involve transferring object styles or edits from one scene to another, or even more complex operations like merging portions of distinct scenes to create a composite. The challenges would be substantial, requiring robust methods for object recognition and alignment across varying lighting, viewpoints and scene contexts. A successful multi-scene editing system would need sophisticated algorithms for consistent style transfer and scene fusion, ensuring that textures, lighting, and geometry blend seamlessly across boundaries. The possibilities include creating richer and more varied synthetic environments from existing data, improving the efficiency of 3D content creation workflows, and opening up innovative new applications in fields such as virtual production, game design, and architectural visualization. However, critical considerations regarding copyright and intellectual property would need to be addressed, particularly if the system allows the transfer of stylistic elements from one copyrighted scene to another.
Future Directions#
The paper’s “Future Directions” section could explore several promising avenues. Extending the Bubble-NeRF representation to other 3D scene representations like Gaussian Splats would enhance fidelity and efficiency. Addressing the challenges of multi-face scenarios and disentangling geometry and appearance for finer control over edits are crucial. Investigating prompt-debiasing techniques would improve robustness, especially for complex or ambiguous instructions. Exploring amortized models for faster editing would enhance usability. Finally, pre-training on large, multiview datasets could improve RAM3D’s generalization capabilities and address limitations in handling complex scene interactions. The authors should also discuss potential ethical implications of this technology, especially regarding the creation of realistic but deceptive content.
More visual insights#
More on figures

🔼 This figure shows the two main stages of the ReplaceAnything3D model (RAM3D): the Erase stage and the Replace stage. The Erase stage uses a text-to-mask model (SAM) to identify and segment the object to be removed from the scene. Then, a text-guided 3D inpainting technique (HiFA) fills the empty space created by the removal, maintaining consistency across multiple views. The Replace stage involves using a similar text-guided 3D inpainting technique to generate a new object based on user input text, and it composites the new object seamlessly into the inpainted background to create a coherent 3D scene. The process utilizes a latent diffusion model (LDM) for image inpainting.
read the caption
Figure 2: An overview of RAM3D Erase and Replace stages.

🔼 This figure illustrates the two-stage pipeline of the RAM3D model: the Erase stage and the Replace stage. In the Erase stage, the model identifies the object to be removed using a mask (blue region). It then inpaints the background (pink region) using a combination of the masked region and the surrounding halo region (green). The Replace stage generates a new object (yellow stack of pancakes) based on the user’s text prompt and composes it seamlessly into the inpainted background. The figure shows how the model renders the masked pixels and combines them with the inpainted background to create the final image. The multiview consistency is maintained across all viewpoints of the 3D scene.
read the caption
Figure 3: Left: Erase stage. The masked region (blue) serves as a conditioning signal for the LDM, indicating the area to be inpainted. The surrounding nearby pixels form the halo region h (green), which is also rendered by RAM3D during the Erase stage. The union of these 2 regions is the Bubble-NeRF region, whilst the remaining pixels are sampled from the input image (red). Right: Replace stage. RAM3D volumetrically renders the masked pixels (shown in blue) to give xfg. The result is composited with xbg to form the combined image x.

🔼 This figure compares the results of the proposed method, ReplaceAnything3D (RAM3D), against two other methods for object replacement in 3D scenes: Reference-Guided Inpainting and Blended-NeRF. The comparison highlights the superior quality and realism of RAM3D’s results, especially in terms of lighting and detail.
read the caption
Figure 4: Left: Qualitative comparison with Reference-Guided Inpainting [28] (images adapted from the original paper) for object replacement. Right: Qualitative comparison with Blended-NeRF [12] for object replacement. Our method generates results with higher quality and capture more realistic lighting and details.

🔼 This figure compares the results of the proposed ReplaceAnything3D (RAM3D) model with the Gaussian Editor model for three challenging image editing tasks. The top two rows show results on the GARDEN scene, while the bottom two rows show results on the FACE scene. The results demonstrate RAM3D’s ability to generate more realistic and contextually appropriate objects compared to the Gaussian Editor, particularly with regard to texture detail and integration with the scene.
read the caption
Figure 5: Qualitative comparison with Gaussian Editor [35]. We show results for 3 challenging edit prompts on the GARDEN scene (top 2 rows) and FACE scene (bottom 2 rows). In the GARDEN scene, our method generates more realistic objects which are better integrated with the surrounding scene. In the FACE scene, our method generates more detailed texture patterns and geometry which are better aligned with the edit prompts.

🔼 This figure demonstrates the ability of ReplaceAnything3D (RAM3D) to seamlessly integrate multiple, completely new objects into an existing 3D scene. The objects are added using user-defined masks, ensuring that the added objects are realistically integrated with the existing scene’s lighting, shadows, and overall coherence across multiple viewpoints. The bottom right image showcases a particularly impressive example of this capability, with multiple objects added without disrupting the scene’s integrity.
read the caption
Figure 6: Given user-defined masks, ReplaceAnything3D can add completely new objects that blend in with the rest of the scene. Furthermore, due to its compositional structure, RAM3D can add multiple objects to 3D scenes while maintaining realistic appearance, lighting, and multi-view consistency (bottom right).

🔼 This figure illustrates the two-stage process of RAM3D: Erase and Replace. The left side shows the Erase stage where the object to be removed is masked (blue), and the surrounding area (green) is also processed to ensure seamless integration. The new object is generated in the Replace stage (right). The blue region shows the new object being rendered, which is then composed with the inpainted background.
read the caption
Figure 3: Left: Erase stage. The masked region (blue) serves as a conditioning signal for the LDM, indicating the area to be inpainted. The surrounding nearby pixels form the halo region h (green), which is also rendered by RAM3D during the Erase stage. The union of these 2 regions is the Bubble-NeRF region, whilst the remaining pixels are sampled from the input image (red). Right: Replace stage. RAM3D volumetrically renders the masked pixels (shown in blue) to give xfg. The result is composited with xbg to form the combined image x.

🔼 This figure shows various examples of object replacement in realistic 3D scenes using text prompts. The top row displays the original scene with the object to be replaced. The bottom row shows the same scene but with the original object replaced by a new object specified by a text prompt. This demonstrates the model’s ability to seamlessly integrate new objects into existing scenes while maintaining 3D consistency. The variety of scenes and objects showcase the versatility of the proposed method.
read the caption
Figure 1: Our method enables prompt-driven object replacement for a variety of realistic 3D scenes.

🔼 This figure shows an ablation study on the Erase stage of the RAM3D model. Three variations of the model are compared: one without halo supervision, one without depth loss, and the full model. The results, visualized using SAM segmentation (purple regions), demonstrate that the full model successfully removes the original statue and realistically fills in the background, while the other models fail to completely remove the statue.
read the caption
Figure 9: STATUE Erase stage ablation: (SAM segmentation shown in purple). From Left to Right: No Halo supervision, No Depth Loss, Full model - which successfully removed the original statue.

🔼 This figure demonstrates the ability of the ReplaceAnything3D model (RAM3D) to be personalized using custom assets. By fine-tuning an inpainting diffusion model with five images of a target object, the model is then integrated into RAM3D for object replacement and addition, enabling users to seamlessly integrate their own assets into 3D scenes.
read the caption
Figure 10: Users can personalize a 3D scene by replacing or adding their own assets using a fine-tuned RAM3D. We achieve this by first fine-tuning an inpainting diffusion model with five images of the target object (left), and then combining it with RAM3D to perform object replacement and addition with custom content.

🔼 This figure compares the results of the proposed method, ReplaceAnything3D (RAM3D), with the Instruct-NeRF2NeRF method for 3D scene editing. It shows that RAM3D produces significantly better results, particularly in terms of maintaining scene consistency and generating complex textures. Instruct-NeRF2NeRF struggles to produce high-quality results when dealing with objects that significantly differ from the original object in the scene, and it tends to change the entire scene instead of just the target object.
read the caption
Figure 11: Comparison with Instruct-NeRF2NeRF, a general scene-editing framework [3]. Note that unlike our method, Instruct-NeRF2NeRF modifies the entire scene, cannot synthesise complex texture patterns in the FACE scene and completely fails to generate a pineapple or chess piece object in the 360° GARDEN scene.

🔼 This figure compares the results of the proposed RAM3D method with three other methods (CSD, ViCA-NeRF, and EfficientNeRF2NeRF) for editing 3D scenes. The comparison focuses on the ability of each method to realistically reproduce intricate textures, such as those found in tartan and checkered jackets. The results demonstrate that RAM3D outperforms the other methods in accurately rendering these complex textures, showcasing its superior performance in 3D scene editing tasks.
read the caption
Figure 12: Qualitative comparison with Collaborative Score Distillation (CSD) [32], ViCA-NeRF [31] and EfficientNeRF2NeRF [30]. All approaches apart from our RAM3D were unsuccessful in producing results with intricate texture details for both the checkered and tartan jackets. Results were obtained using official publicly available implementations. Note that in the case of CSD, there is no officially released 3D editing implementation at the time of writing. We therefore followed the official instructions to incorporate CSD image edits into the Instruct-NeRF2NeRF framework.

🔼 This figure shows a comparison of the proposed method (ReplaceAnything3D) with two other methods for 3D object manipulation: RePaint-NeRF and DreamEditor. The left side demonstrates object replacement using RePaint-NeRF and the proposed method, showing that the proposed method produces more realistic results. The right side compares the methods on object addition, where the proposed method again produces superior results in terms of realism and integration with the scene.
read the caption
Figure 13: Left: Qualitative comparison with RepaintNeRF [34] for object replacement. Figure adapted from the original RepaintNeRF paper. Right: Qualitative comparison with DreamEditor [10] for object addition ('Add a red top hat'). Figure adapted from the original DreamEditor paper.

🔼 This figure compares the results of the proposed method, RAM3D, with a naive 2D baseline approach for object replacement. The 2D baseline processes each image individually using a pre-trained text-to-image inpainting model, leading to inconsistent results across different viewpoints. RAM3D, in contrast, generates multi-view consistent results by considering all views during training, resulting in a more realistic and seamless object replacement.
read the caption
Figure 14: Qualitative comparisons between our method RAM3D (last column) with a naive 2D baseline method, which produces view-inconsistent results (third column). This is because each input image is processed independently and thus vary widely from each other (second column).

🔼 This figure shows the results of using GaussianEditor to remove a vase from a scene. The left image shows the result before a refinement step, while the right image shows the result after. The refinement step causes a cloudy artifact, so the result before refinement is used for comparison.
read the caption
Figure 15: Results obtained using GaussianEditor to remove the vase object from the GARDEN scene. Note that GaussianEditor’s proposed mask dilation and hole-fixing refinement stage causes a cloudy artifact to appear above the table, where the vase was originally placed. We therefore use the result on the left, prior to refinement, when adding new objects to replace the vase.

🔼 This figure shows the results of using GaussianEditor to add a pineapple to a scene. The left side demonstrates that the tool initially places the pineapple incorrectly far from the table. The right side illustrates that manual intervention is needed to correct the placement using the software’s interface for depth adjustment. This highlights a limitation of GaussianEditor where manual correction is needed to properly place newly added objects.
read the caption
Figure 16: We observe that the Object Adding functionality of GaussianEditor does not place new objects into the scene in the correct position. The images on the left show the initial pineapple object placement (far from the table), output by GaussianEditor. The images on the right show the results after manually refining the position of the pineapple, by adjusting its depth along a ray passing through the centre of the reference image.

🔼 This figure illustrates the two-stage process of RAM3D: Erase and Replace. The left panel shows the erase stage, where a mask (blue) defines the area to be removed. The surrounding pixels (green) form a halo region used for consistent background reconstruction. The model inpaints the masked region using information from this halo and unmasked pixels (red). The right panel shows the replace stage, where a new object (xfg) is generated based on a text prompt and composited with the inpainted background (xbg) using alpha blending to create a seamless whole (x).
read the caption
Figure 3: Left: Erase stage. The masked region (blue) serves as a conditioning signal for the LDM, indicating the area to be inpainted. The surrounding nearby pixels form the halo region h (green), which is also rendered by RAM3D during the Erase stage. The union of these 2 regions is the Bubble-NeRF region, whilst the remaining pixels are sampled from the input image (red). Right: Replace stage. RAM3D volumetrically renders the masked pixels (shown in blue) to give xfg. The result is composited with xbg to form the combined image x.

🔼 This figure demonstrates two failure cases of the ReplaceAnything3D model. The first case (a) shows that a prompt requesting multiple objects can lead to an incoherent combination of those objects. The second case (b) shows that the model struggles with generating realistic geometry when the replaced object has multiple faces, as seen in the unrealistic watermelon slice.
read the caption
Figure 18: We show 2 failure cases for RAM3D. a) a challenging multi-object prompt results in an incoherent combination of both objects. b) we observe a multi-face problem which results in unrealistic geometry for the watermelon slice.

🔼 This figure shows two failure cases of the proposed RAM3D model. The first case (a) demonstrates that editing object properties, such as changing the color, can lead to a change in object identity, resulting in an incorrect object being generated. The second case (b) illustrates that replacing a smaller object with a much larger object can significantly reduce the quality of the generated result, producing unrealistic results and degrading the overall synthesis quality.
read the caption
Figure 19: We show 2 additional failure cases for RAM3D. a): Editing object properties changes object identity. b): replacing the statue with much larger objects leads to degraded synthesis quality.
More on tables
🔼 This table presents a quantitative comparison of the proposed ReplaceAnything3D (RAM3D) model against existing methods using two metrics: CLIP Text-Image Direction Similarity and Warping Error. The CLIP-based metric assesses the alignment of the edited objects with the input text prompts. The optical flow-based metric (Warping Error) measures the temporal consistency across multiple views of the modified scene. The results show RAM3D achieving superior performance across both metrics and various scene types (GARDEN, FACE, and FERN).
read the caption
Table 1: We compute a CLIP-based alignment metric, and optical flow-based temporal consistency metric for various datasets and prompts. RAM3D shows the best overall edit prompt alignment and temporal consistency. (Top) GARDEN, (Middle) FACE, (Bottom) FERN.

🔼 This table presents a quantitative comparison of RAM3D against two other methods using two metrics: CLIP Text-Image Direction Similarity (measuring how well the generated object matches the text prompt) and Warping Error (measuring the temporal consistency of the generated video). The results are shown for three different datasets (GARDEN, FACE, and FERN), each with several different prompts. RAM3D consistently outperforms the other methods in terms of both metrics, indicating superior alignment and temporal coherence.
read the caption
Table 1: We compute a CLIP-based alignment metric, and optical flow-based temporal consistency metric for various datasets and prompts. RAM3D shows the best overall edit prompt alignment and temporal consistency. (Top) GARDEN, (Middle) FACE, (Bottom) FERN.
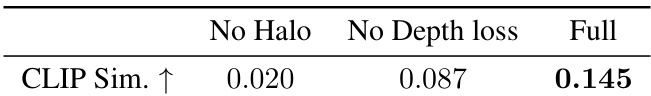
🔼 This table presents the results of an ablation study on the Erase stage of the RAM3D model. It compares the performance of three variants: one without halo supervision, one without depth loss, and the full model. The CLIP Text-Image Direction Similarity score, which measures how well the generated image matches the text prompt, is used as the evaluation metric. The results show that the full model achieves significantly higher scores, indicating the importance of both halo supervision and depth loss for effective background inpainting.
read the caption
Table 4: Erase-stage ablation results. We report CLIP Text-Image Direction Similarity scores for all model variants, using the prompt “A white plinth in a park, in front of a path”, on the STATUE scene. Note that our full model performs best.
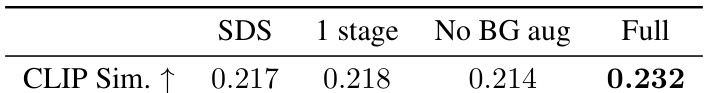
🔼 This table presents ablation study results for the Replace stage of the RAM3D model. It compares the performance of different model variants, each lacking a specific component (SDS loss, single-stage training, or background augmentation). The ‘CLIP Sim’ metric, which measures the alignment between the generated object and the text prompt, demonstrates that the full model, incorporating all components, yields the highest alignment score (0.232).
read the caption
Table 5: Replace-stage ablation results. We report CLIP Text-Image Direction Similarity scores for all model variants, using the prompt “A corgi on a white plinth”, on the STATUE scene. Note that our full model performs best.
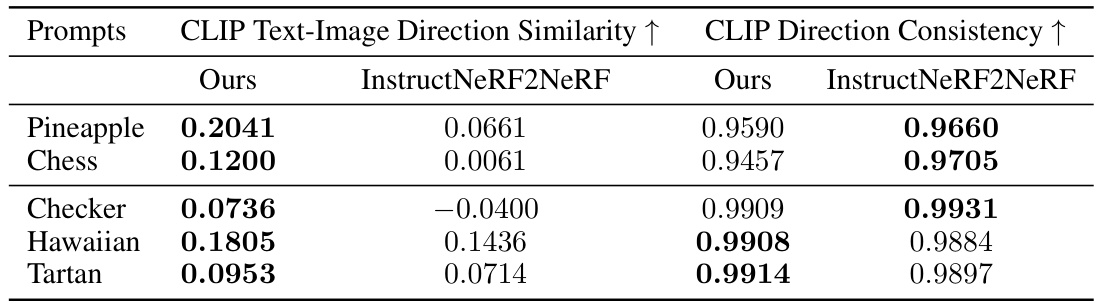
🔼 This table presents a quantitative comparison of the proposed method (RAM3D) and InstructNeRF2NeRF [3] using two CLIP-based metrics: CLIP Text-Image Direction Similarity and CLIP Direction Consistency. The results are shown for five different prompts on the GARDEN and FACE datasets. Higher values in both metrics indicate better performance. The comparison highlights RAM3D’s improved performance, particularly in terms of text-image alignment.
read the caption
Table 6: CLIP-based metrics for GARDEN and FACE datasets, comparing our method with [3]
Full paper#