TL;DR#
Current robotic learning struggles with handling diverse sensory inputs (multi-modality). Existing systems often focus on single-modal task specifications and observations, limiting their ability to process rich information, hindering the creation of truly generalizable robots.
Any2Policy tackles this by enabling robots to handle tasks with various modalities (text-image, audio-image, etc.). It uses a modality network to adapt to diverse inputs and policy networks for effective control. A new real-world dataset with 30 annotated tasks was created to evaluate the system, showing promising results in various simulated and real-world environments. The paper’s contributions are significant because it provides a unified approach to multi-modal robot learning, a valuable real-world dataset, and demonstrates effective generalization.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in robotics and AI due to its introduction of Any2Policy, a novel framework for building embodied agents capable of handling multi-modal inputs. It addresses a critical limitation in current robotic learning methodologies and opens avenues for creating more generalizable and robust robotic systems. The release of a comprehensive real-world dataset further enhances its significance by providing a valuable resource for future research in this area.
Visual Insights#
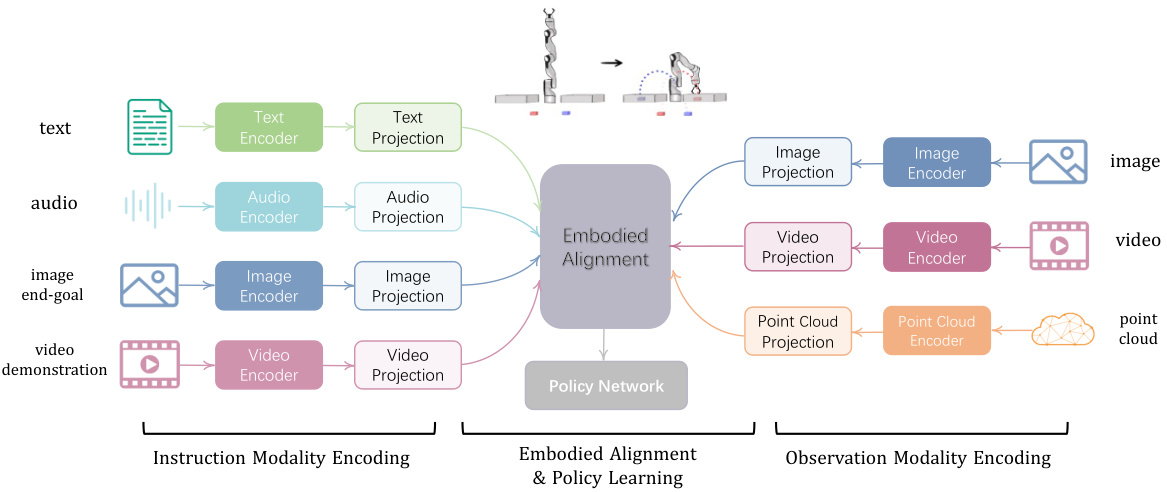
🔼 This figure illustrates the Any2Policy architecture, which processes multi-modal inputs (text, audio, image, video, point cloud) for both instruction and observation. Multi-modal encoders extract features, which are then projected into standardized token representations. An embodied alignment module synchronizes these features, and a policy network generates actions for robot control. The design ensures seamless integration of diverse input types for robust and adaptable robot behavior.
read the caption
Figure 1: The overall framework of Any2Policy. The Any2Policy framework is structured to handle multi-modal inputs, accommodating them either separately or in tandem at the levels of instruction and observation. We design embodied alignment modules, which are engineered to synchronize features between different modalities, as well as between instructions and observations, ensuring a seamless and effective integration of diverse input types.

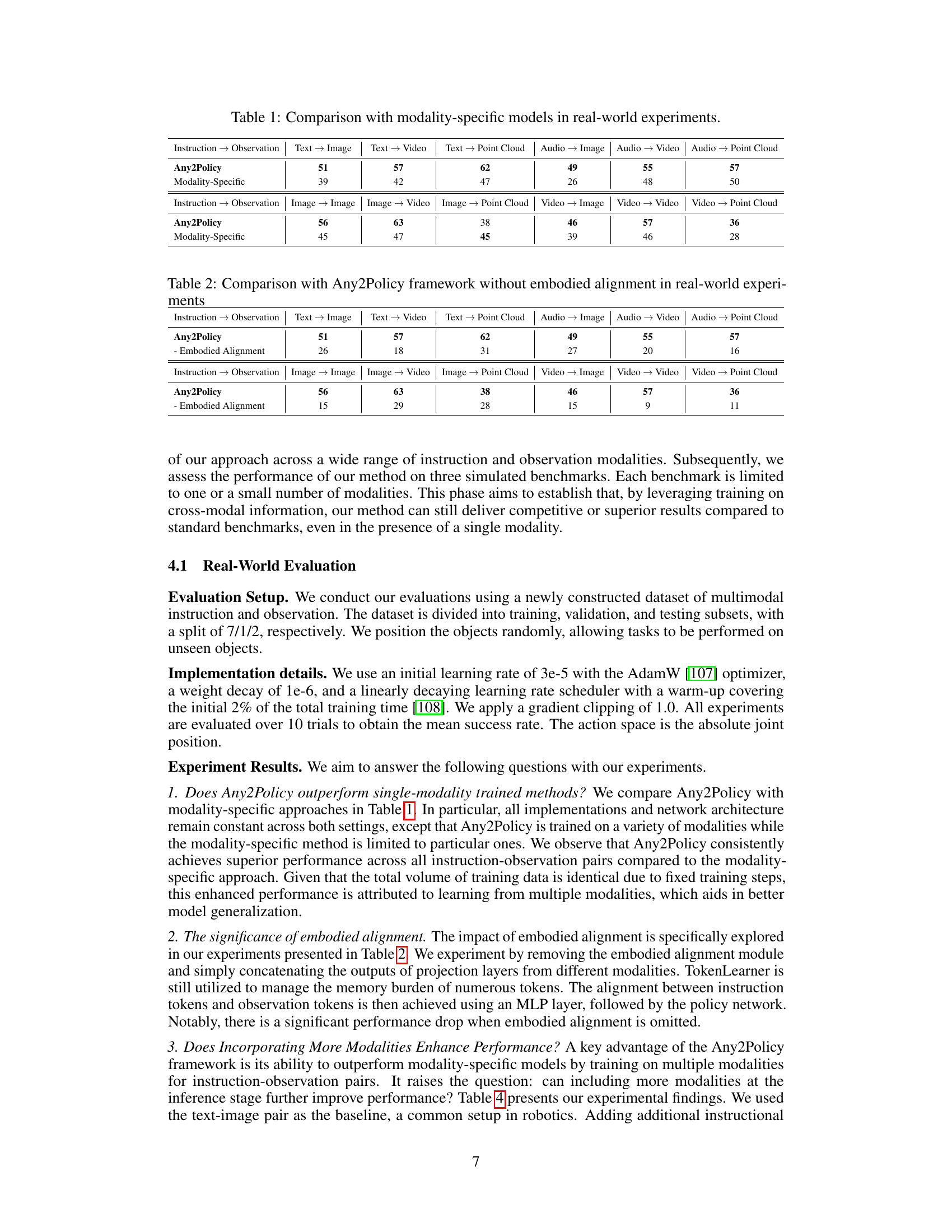
🔼 This table presents a comparison of the Any2Policy framework’s performance against modality-specific models. The experiment was conducted in a real-world setting using various combinations of instruction and observation modalities. The results show Any2Policy’s superior performance across different modality combinations, highlighting its ability to handle diverse multi-modal inputs effectively.
read the caption
Table 1: Comparison with modality-specific models in real-world experiments.
In-depth insights#
Any-Modality Policy#
The concept of ‘Any-Modality Policy’ in robotics represents a significant advancement toward creating truly versatile and adaptable robots. It signifies a shift away from single-modality approaches (e.g., relying solely on visual input) towards a system that can seamlessly integrate and process information from various sources, such as text, audio, images, and point clouds. This approach mimics human capabilities, where multiple sensory inputs enhance understanding and task execution. The key advantage lies in enhanced robustness and generalizability. A robot equipped with an any-modality policy can adapt to diverse and unpredictable environments, handling tasks even when some sensory information is unavailable or unreliable. This adaptability is crucial for deploying robots in real-world settings, which are inherently complex and uncertain. Challenges remain in effectively fusing information across different modalities, and creating efficient architectures capable of handling high-dimensional data streams from varied input sources, but the potential benefits of an any-modality approach are undeniable, pointing towards a future where robots are capable of performing complex tasks with unprecedented flexibility and resilience.
Embodied Alignment#
The concept of “Embodied Alignment” in the context of multi-modal embodied agents is crucial for bridging the semantic gap between different modalities of instruction and observation. It tackles the challenge of synchronizing features from various input sources (text, audio, images, video, point clouds) to ensure that the robot’s perception aligns with its instruction. The core innovation lies in using a transformer-based architecture to handle this alignment, enabling a unified processing framework for different modalities. A key aspect is the efficient handling of varying token counts across modalities (e.g., images require more tokens than text), which is addressed through token pruning techniques to minimize computational costs while retaining crucial information. The use of cross-attention mechanisms further enhances alignment by explicitly linking instruction tokens with observation tokens, establishing a direct connection between the command and the perceived world. This approach surpasses simple concatenation methods by enabling context-aware fusion and facilitating a richer, more robust understanding of the task before generating appropriate actions. In essence, embodied alignment is not merely a technical step, but a fundamental architectural design that allows the agent to perceive and act in a truly multi-modal manner, enhancing generalization and potentially leading to more sophisticated and adaptable robotic systems.
Multimodal Encoding#
Multimodal encoding in robotics research is crucial for enabling robots to understand and interact with the world in a more human-like way. It involves integrating various data sources, such as images, text, audio, and sensor readings, into a unified representation. Effective multimodal encoding is challenging because different modalities have distinct characteristics and may require specialized processing techniques. A common approach is to use separate encoders for each modality, extracting relevant features from the raw data before combining them in a shared embedding space. This embedding space should capture the relationships between different modalities, enabling the robot to interpret their combined meaning. The choice of encoders is crucial, with common options including convolutional neural networks (CNNs) for images, recurrent neural networks (RNNs) for audio, and transformer networks for text. The fusion strategy for combining these modal-specific encodings is another key challenge. Simple concatenation might not capture the complex interactions between modalities, hence more sophisticated methods like attention mechanisms or multimodal transformers are often employed. The ultimate goal is to generate a robust and informative representation that can be used by downstream tasks, such as action planning and decision making. The performance of a multimodal encoding scheme depends heavily on the specific application and dataset. Future research should focus on developing more efficient and generalizable multimodal encoding methods that can adapt to diverse robotic tasks and environments.
Real-World Dataset#
A robust real-world dataset is crucial for evaluating the effectiveness of embodied agents. A key strength of this research is the creation of a comprehensive dataset encompassing 30 robotic tasks, each richly annotated across multiple modalities (text, audio, image, video, point cloud). This multi-modal annotation is particularly valuable, as it moves beyond the limitations of single-modality datasets that often restrict the generalizability of learned policies. The inclusion of diverse modalities enables a more thorough evaluation of the agent’s ability to process and integrate information from various sources, mirroring human perception. Furthermore, the dataset’s real-world nature ensures that the learned policies are tested in scenarios relevant to practical robotic applications. This contrasts with many existing studies that primarily rely on simulated environments, which may not accurately reflect the complexities of real-world interactions. By providing a benchmark with real-world complexity, this research provides a significant contribution to the field, facilitating more meaningful comparisons between different embodied AI approaches and fostering advancements in more generalizable and robust robotic systems. The dataset’s availability should accelerate the development of more capable multi-modal robots.
Future Directions#
Future research could explore several promising avenues. Expanding the dataset to encompass a wider variety of tasks, environments, and robot morphologies would significantly enhance the model’s generalizability and robustness. Improving the embodied alignment module to handle even more complex scenarios where instruction and observation modalities are poorly correlated remains a key challenge. This could involve incorporating more sophisticated attention mechanisms or developing novel methods for cross-modal feature fusion. Exploring different policy architectures beyond the transformer-based approach used in Any2Policy is warranted. Investigating the efficacy of alternative architectures, such as graph neural networks, could lead to performance improvements, particularly for tasks requiring complex reasoning or planning. Investigating the transfer learning capabilities of the proposed framework across different robot platforms would demonstrate its practical value. A final area for future work is developing more efficient methods for multi-modal data processing. The computational cost of processing diverse modalities can be substantial, particularly for real-time applications. Optimizations are needed to allow the Any2Policy framework to scale to even more complex and challenging robotic tasks.
More visual insights#
More on figures
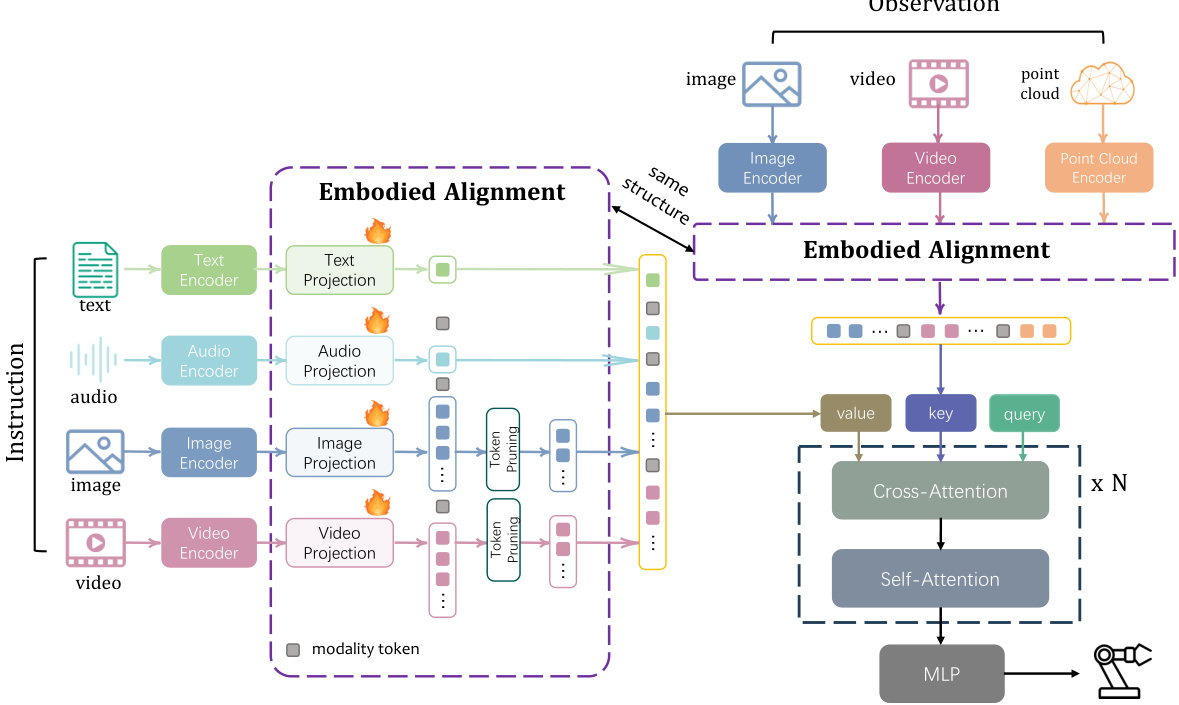
🔼 The figure illustrates the architecture of the embodied alignment and policy network in Any2Policy. It shows how multi-modal instructions (text, audio, image, video) and observations (image, video, point cloud) are processed. Each modality is first encoded using modality-specific encoders and then projected into a unified representation. A token pruning technique reduces the dimensionality of visual data. Then, embodied alignment, a transformer-based architecture employing cross-attention and self-attention, synchronizes instruction and observation tokens. Finally, a policy network generates actions for robot control. The diagram highlights the key components of the system’s multi-modal integration, feature alignment, and action generation.
read the caption
Figure 2: The architecture of embodied alignment and policy network.

🔼 This figure shows the workspace setup of the Franka real robot used in the experiments. It showcases examples of several tasks performed by the robot, each with a short textual description of the task’s goal, such as ‘Pick up cube place to left box’. The images illustrate the initial state and a sequence of steps for each task, providing a visual representation of the robot’s actions and the environment.
read the caption
Figure 3: This is the setup of our Franka real robot. We have compiled examples of several tasks. To facilitate better understanding for our readers, we provide only the language-based versions of these task descriptions.

🔼 This figure presents a comparison of the Any2Policy model’s performance against three state-of-the-art (SOTA) models: R3M, BLIP-2, and EmbodiedGPT, on the Franka Kitchen benchmark. Two sets of experiments are shown, one using 10 demonstrations and another using 25, to assess the impact of the number of demonstrations on the models’ performance. The results demonstrate that Any2Policy generally outperforms the SOTA methods across a range of tasks within the Franka Kitchen environment.
read the caption
Figure 4: Performance of Any2Policy in Franka Kitchen with 10 or 25 demonstration demos. Comparison with R3M, BLIP-2, and EmbodiedGPT. On all tasks except for Knobs-left with 25 demonstrations, we obtained superior performance over SOTA methods.
More on tables

🔼 This table presents a comparison of the Any2Policy framework’s performance with and without the embodied alignment module. The results, obtained from real-world experiments, demonstrate the impact of the embodied alignment on the model’s ability to handle various combinations of instruction and observation modalities. It showcases the performance across different pairings of instruction (text, audio, image, video) and observation modalities (image, video, point cloud). The significant drop in performance when the embodied alignment module is removed highlights its importance in the overall framework.
read the caption
Table 2: Comparison with Any2Policy framework without embodied alignment in real-world experiments

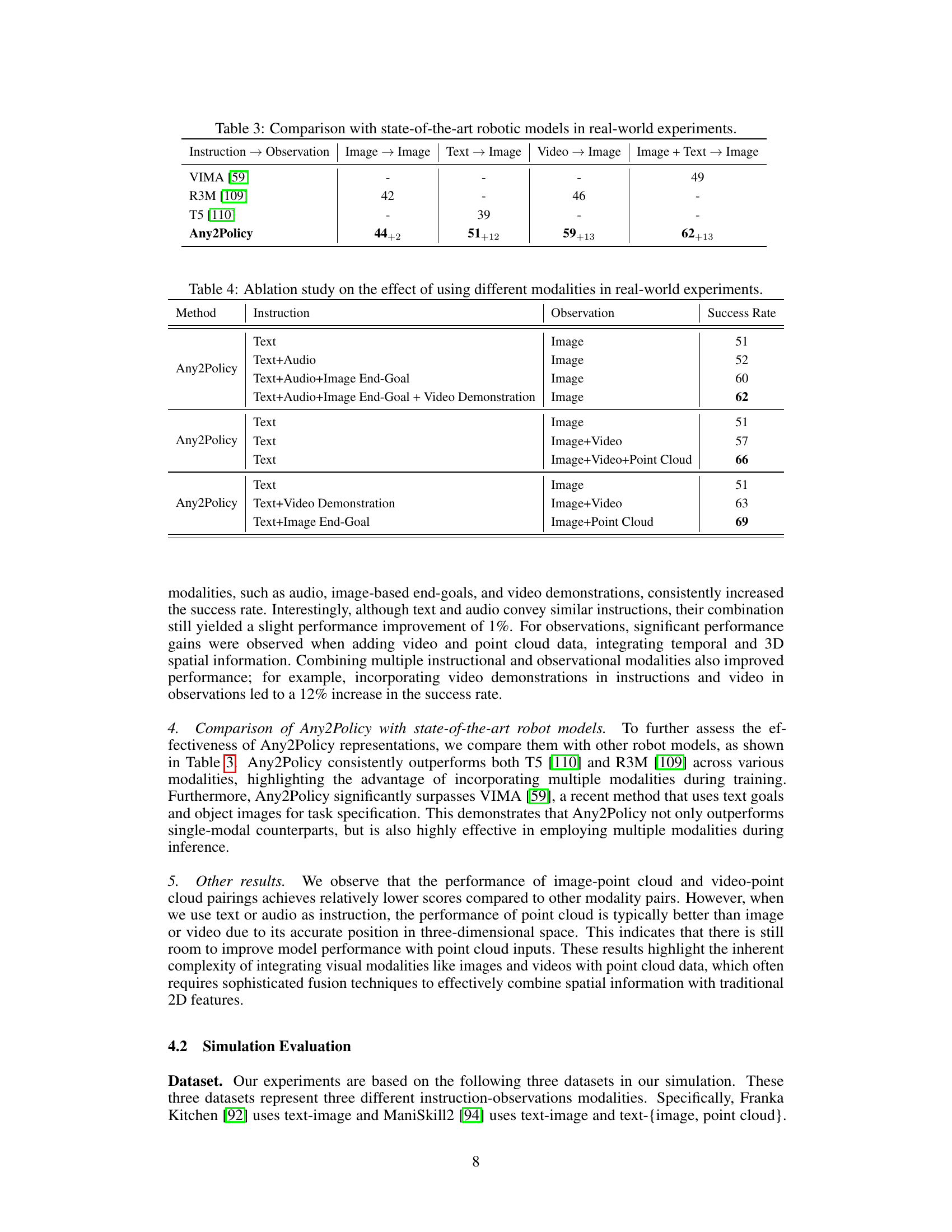
🔼 This table compares the performance of Any2Policy with three state-of-the-art robotic models (VIMA, R3M, and T5) on real-world experiments using different instruction and observation modalities. It shows Any2Policy outperforms other models across various settings, highlighting the effectiveness of its multi-modal approach.
read the caption
Table 3: Comparison with state-of-the-art robotic models in real-world experiments.
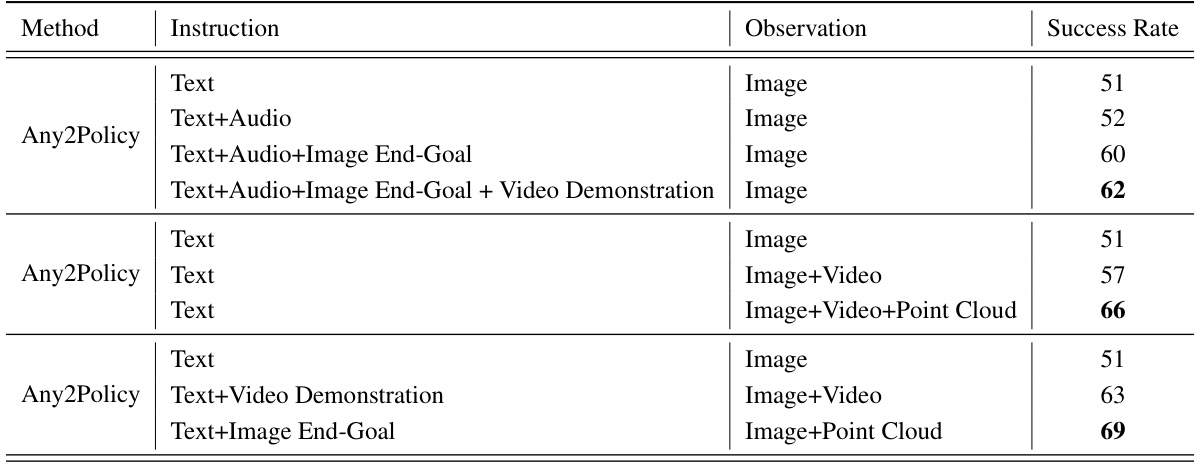
🔼 This table presents an ablation study evaluating the impact of different combinations of instruction and observation modalities on the success rate of the Any2Policy model in real-world experiments. It shows how adding various modalities (audio, image end-goals, video demonstrations) to text instructions and image observations improves the model’s performance.
read the caption
Table 4: Ablation study on the effect of using different modalities in real-world experiments.
Full paper#