TL;DR#
Vision-language models like CLIP struggle with adapting to new, unseen data (domain shift) during test time. Existing test-time adaptation (TTA) methods either require extra training (computationally expensive) or overlook information within the test samples themselves. This is problematic as retraining is not always feasible.
BoostAdapter tackles this by cleverly integrating both training-free and training-required TTA approaches. It uses a lightweight memory system to store both general information from previous test data and specific information from the current sample (via regional bootstrapping). This combined approach allows for strong generalization without the high computational cost of retraining, showcasing superior results on multiple benchmark datasets.
Key Takeaways#
Why does it matter?#
This paper is important because it proposes BoostAdapter, a novel test-time adaptation (TTA) method that significantly improves the robustness and generalization ability of vision-language models. It bridges the gap between existing training-required and training-free TTA methods, offering a more efficient and effective approach. This work is highly relevant to current research trends in vision-language understanding and opens up new avenues for improving the adaptability of these models in real-world scenarios with limited data.
Visual Insights#
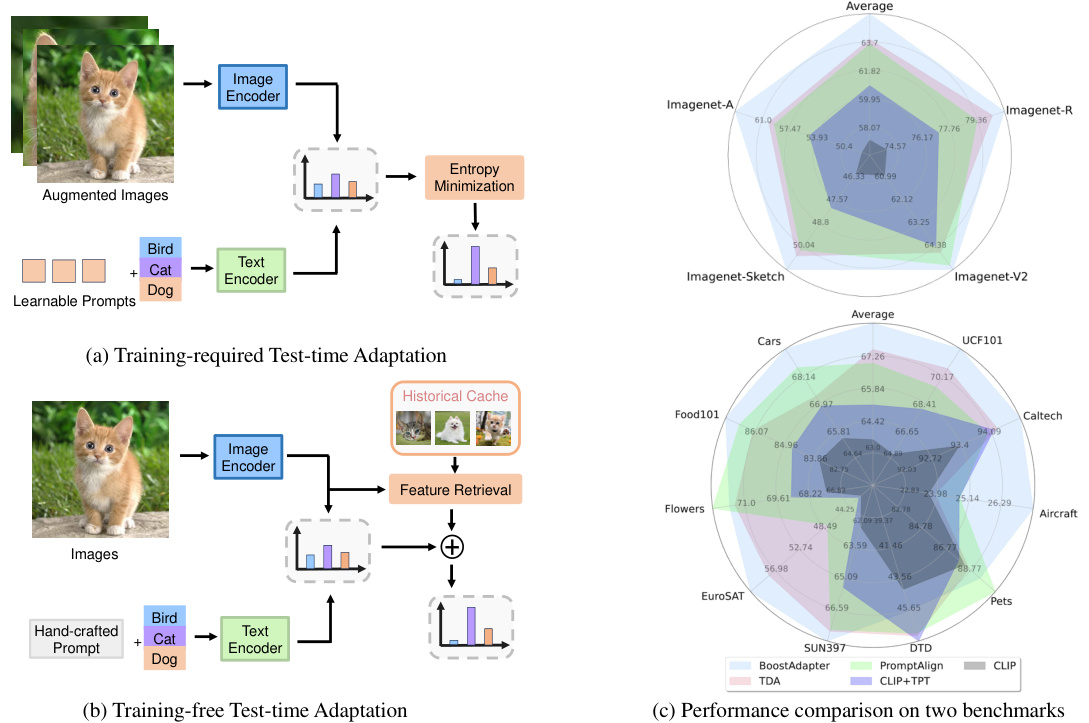
🔼 This figure shows a comparison of training-required and training-free test-time adaptation (TTA) methods. Panel (a) illustrates the typical workflow of training-required TTA, where a self-supervised objective (entropy minimization) is used to improve model generalization on downstream tasks. Panel (b) shows the typical workflow of training-free TTA, where feature retrieval from historical samples is used to adjust model predictions. Panel (c) provides a comparison of the performance of various TTA methods, including BoostAdapter (the proposed method), on two benchmark datasets: Out-of-Distribution and Cross-Datasets.
read the caption
Figure 1: (a) Existing training-required TTA methods utilize self-supervised objective like entropy minimization for better generalization. (b) Existing training-free TTA methods perform feature retrieval on the historical samples to adjust the model prediction. (c) Performance comparison on the Out-of-Distribution benchmark and Cross-Datasets benchmark.
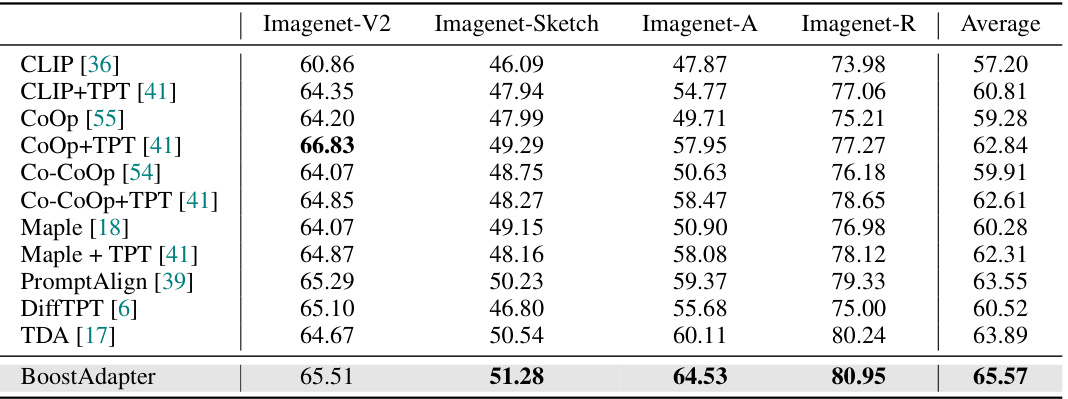
🔼 This table presents the results of the proposed BoostAdapter method and several baseline methods on the Out-of-Distribution (OOD) benchmark using the ViT-B/16 backbone. The OOD benchmark consists of four datasets: ImageNet-V2, ImageNet-Sketch, ImageNet-A, and ImageNet-R. For each dataset and each method, the top-1 accuracy is reported, representing the percentage of correctly classified images. An ‘Average’ column provides the mean accuracy across all four datasets, offering a summarized performance comparison across different OOD settings.
read the caption
Table 1: Full results on the OOD benchmark with ViT-B/16 backbone. We report top-1 accuracy and 'Average' is calculated by taking the mean accuracy across all four OOD datasets.
In-depth insights#
TTA Methodologies#
Test-Time Adaptation (TTA) methodologies represent a crucial area of research within the field of machine learning, especially concerning vision-language models. The core goal of TTA is to improve the performance of pre-trained models on unseen downstream tasks without requiring any additional training data from the target domain. This is particularly relevant in situations where obtaining labeled target data is expensive, time-consuming, or simply impossible. The paper explores two main categories of TTA: training-required and training-free methods. Training-required methods typically involve fine-tuning model parameters or prompts using self-supervised objectives, often entailing computational cost. Training-free approaches, on the other hand, focus on efficiently leveraging information from the test samples themselves or a limited historical cache of previously seen samples to adapt the model’s predictions. The paper proposes a novel method that bridges the gap between these two paradigms by combining the strengths of both, offering theoretical justifications and demonstrating improved empirical results across various benchmarks.
BoostAdapter Design#
BoostAdapter’s design cleverly integrates training-required and training-free test-time adaptation (TTA) methods. It uses a lightweight key-value memory to store both instance-agnostic historical samples (filtered from the test stream to capture the target distribution) and instance-aware boosting samples. These boosting samples, created via regional bootstrapping and entropy filtering of augmented test samples, provide crucial intra-sample information. This dual approach effectively mines information from both the target distribution and the test sample itself, bridging the gap between existing TTA methods. The theoretical justification and empirical results demonstrate its effectiveness across different scenarios, showcasing the synergy between historical knowledge and self-bootstrapping for improved robustness and performance in real-world applications.
Empirical Validation#
An Empirical Validation section in a research paper would rigorously test the proposed methods. It should present results on multiple datasets, possibly including both in-distribution and out-of-distribution data, to demonstrate generalizability. The evaluation metrics should be clearly defined and appropriate for the task. Crucially, the results should be compared against existing state-of-the-art methods, highlighting any significant improvements or limitations. Furthermore, a robust empirical validation would incorporate ablation studies to isolate the impact of different components, and error analysis to understand the reasons behind successes and failures. Statistical significance of results should be properly reported and discussed to avoid spurious conclusions. Finally, visualization of results, particularly using graphs, would significantly enhance the clarity and impact of the findings. A strong Empirical Validation section is crucial for establishing the credibility and practical significance of any research claims.
Theoretical Analysis#
A theoretical analysis section in a research paper would ideally delve into a rigorous examination of the proposed method’s underlying principles. This would likely involve deriving mathematical bounds or guarantees on performance metrics, providing a formal justification for design choices, and potentially comparing the method’s theoretical properties to existing approaches. Key aspects would involve clearly stating any assumptions made, demonstrating the rationality of the method, and discussing its limitations within the defined theoretical framework. This might entail proving convergence, establishing error bounds, or analyzing computational complexity. A strong theoretical analysis is critical to establish the method’s validity and generalizability, thus enhancing the paper’s overall contribution.
Future Works#
Future research directions stemming from this work could explore several promising avenues. Extending BoostAdapter to handle more complex downstream tasks, beyond binary classification, is crucial for showcasing its broader applicability. A thorough investigation into the impact of different data augmentation strategies on the performance and robustness of BoostAdapter is needed. Analyzing the interplay between the size of the historical and boosting caches and its effect on both efficiency and accuracy would provide valuable insights for optimization. Finally, a comprehensive study comparing BoostAdapter’s performance against other state-of-the-art TTA methods on a wider range of datasets is essential for establishing its overall effectiveness and identifying potential limitations.
More visual insights#
More on figures

🔼 This figure illustrates the connection between cross-entropy optimization and cache classifier methods when dealing with well-clustered data points. It shows how, during cross-entropy optimization, the classifier weights are adjusted to pull closer samples of the same class and push apart those of different classes. Because the features are clustered, these weights converge towards the centroid of each feature cluster. The cache classifier, by contrast, directly utilizes the centroid as a basis for classification, leading to similar results.
read the caption
Figure 2: Connection between cross-entropy optimization and cache classifier over well-clustered samples with a frozen feature encoder. With optimization of cross-entropy, samples will pull the classifier weights closer of the same class while pushing them away from different class weights. Since the feature space is well-clustered, the classifier weights will ultimately converge near the feature center of the samples. Finally, the optimal classifier achieved through cross-entropy minimization will exhibit similar behavior with the cache classifier.
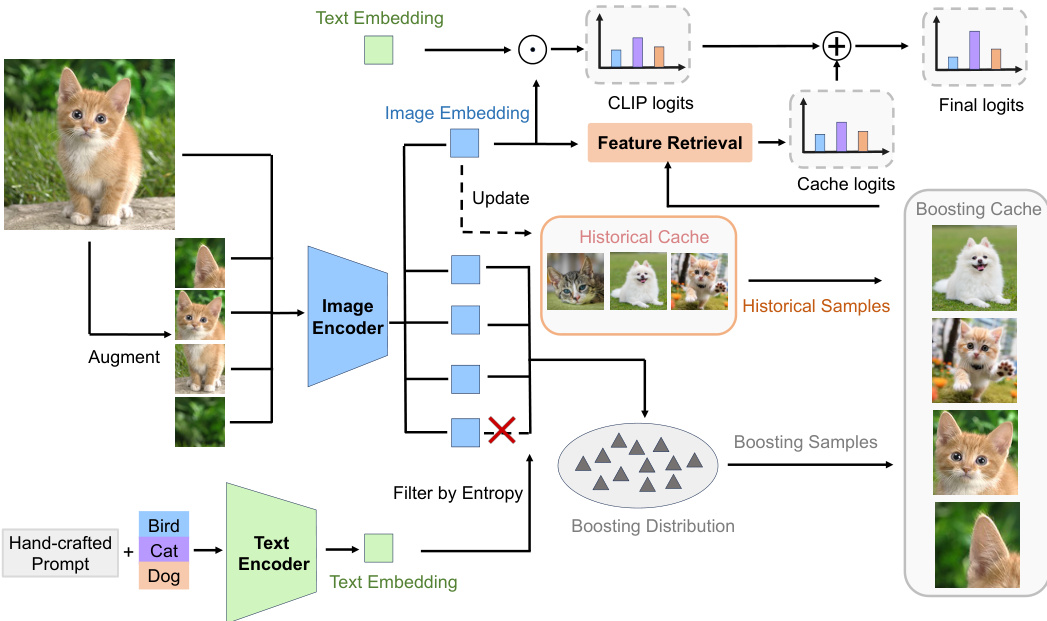
🔼 This figure illustrates the architecture of the BoostAdapter model. The model takes an image as input and augments it to create multiple versions of the image. These augmented images are passed through an image encoder to produce image embeddings. The image embeddings are used for feature retrieval from two caches: a historical cache (containing instance-agnostic historical samples from the test data stream), and a boosting cache (containing instance-aware boosting samples created using a self-bootstrapping method from the test sample itself). The outputs from both caches and the original CLIP logits are combined to produce the final logits, which represent the model’s prediction. A key component is the filtering step that uses entropy to select high-quality boosting samples from the augmented image versions.
read the caption
Figure 3: Overall architecture of BoostAdapter. BoostAdapter leverages knowledge from the target domain and employs self-bootstrapping with historical and boosting samples in the boosting cache, respectively.
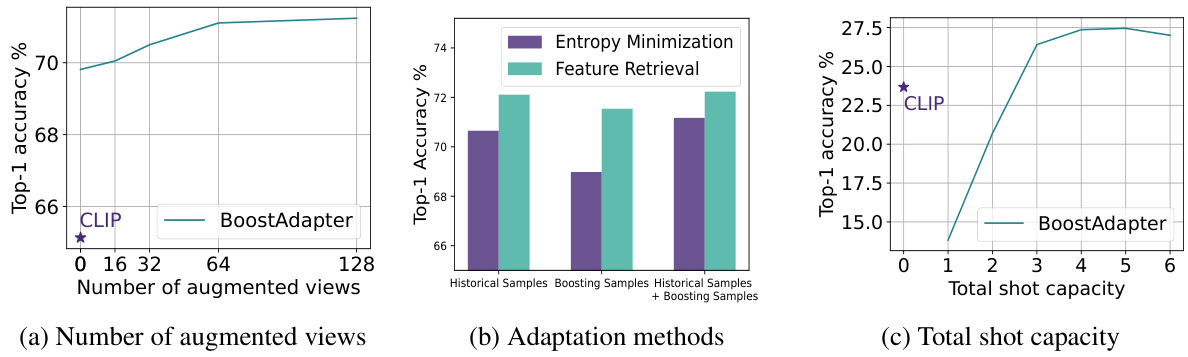
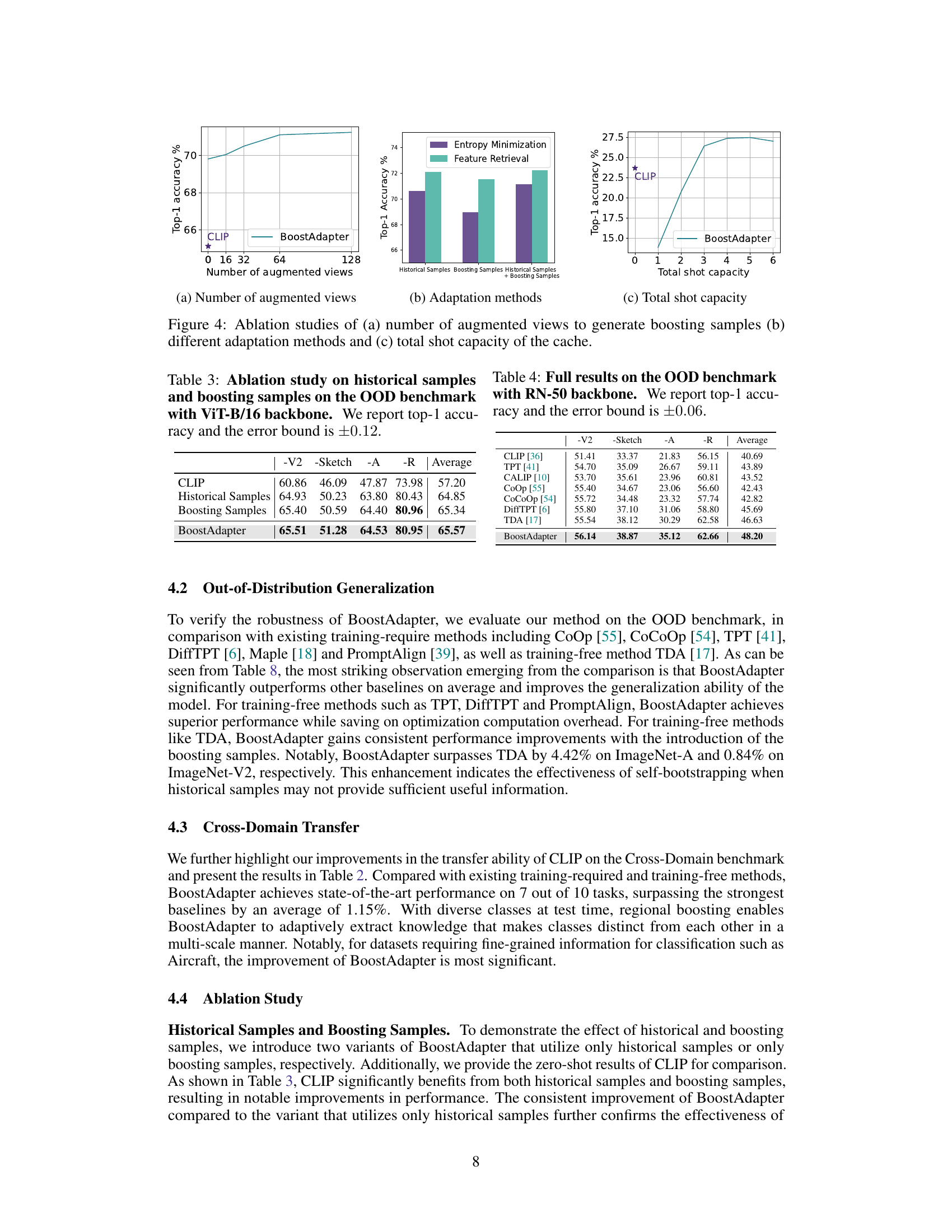
🔼 This figure presents the results of ablation studies conducted to analyze the impact of different factors on the BoostAdapter model. Panel (a) shows how the number of augmented views used to create boosting samples affects the model’s performance. Panel (b) compares the performance of BoostAdapter using only historical samples, only boosting samples, and both historical and boosting samples, illustrating the contribution of each component. Panel (c) demonstrates the effect of varying the total shot capacity (the number of samples stored in the cache) on the model’s accuracy. Each panel provides insights into the optimal configuration of the BoostAdapter for improved performance.
read the caption
Figure 4: Ablation studies of (a) number of augmented views to generate boosting samples (b) different adaptation methods and (c) total shot capacity of the cache.

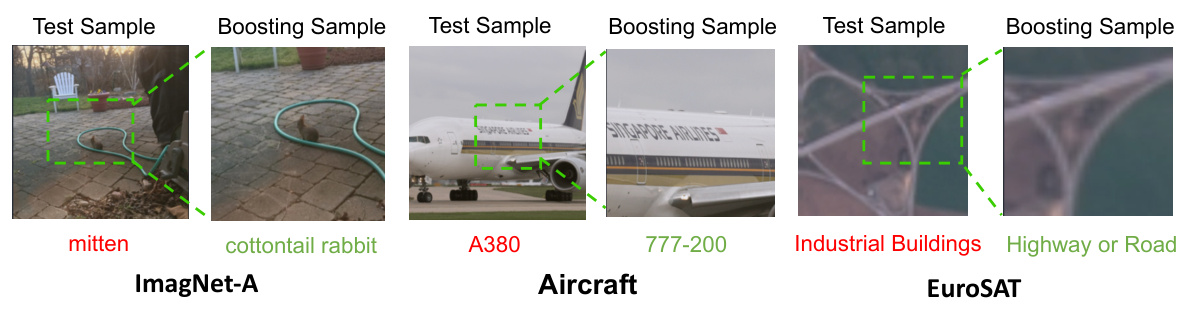
🔼 This figure shows four examples of qualitative results using the BoostAdapter method. Each example displays a test image and its corresponding boosting sample. The boosting samples were obtained through regional bootstrapping and filtering based on entropy. In each pair of images, the text below indicates the model’s predictions for both the test image and the boosting sample. The goal of the figure is to visually demonstrate how BoostAdapter uses boosting samples to improve prediction accuracy, especially on finer details or distinguishing features.
read the caption
Figure 5: Qualitative results. The model predictions are provided below the images. Boosting samples with low entropy improves information extraction from the test sample and helps the model to distinguish better.
🔼 BoostAdapter’s architecture is shown, highlighting its use of two types of samples: historical samples and boosting samples. Historical samples are filtered from the test data stream and are used for feature retrieval. Boosting samples are created via regional bootstrapping from the test sample itself using augmentation and entropy filtering to select high-quality samples. These samples are stored in a boosting cache and utilized along with historical samples in a key-value memory for improved feature retrieval and prediction.
read the caption
Figure 3: Overall architecture of BoostAdapter. BoostAdapter leverages knowledge from the target domain and employs self-bootstrapping with historical and boosting samples in the boosting cache, respectively.
More on tables
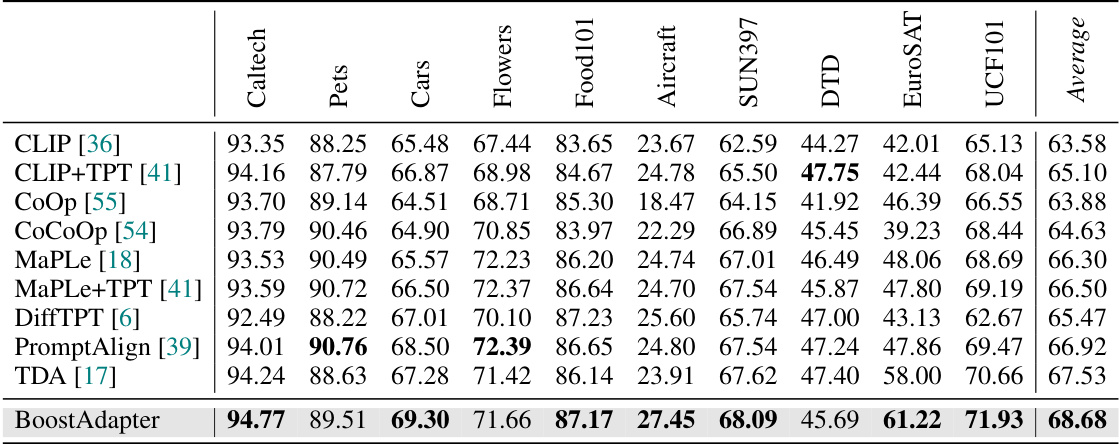
🔼 This table presents the performance comparison of different vision-language models on ten cross-domain datasets using the ViT-B/16 backbone. The models compared include CLIP, CLIP+TPT, CoOp, CoCoOp, Maple, Maple+TPT, DiffTPT, PromptAlign, TDA and BoostAdapter. The ‘Average’ column shows the mean accuracy across all ten datasets. The error bound of ±0.17 indicates the uncertainty in the reported results.
read the caption
Table 2: Full results on the Cross-Domain Benchmark with ViT-B/16 backbone. We report top-1 accuracy and 'Average' is calculated by taking the mean accuracy across all ten datasets. The error bound is ±0.17.
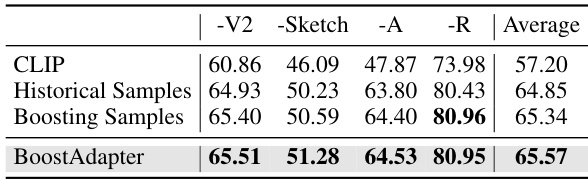
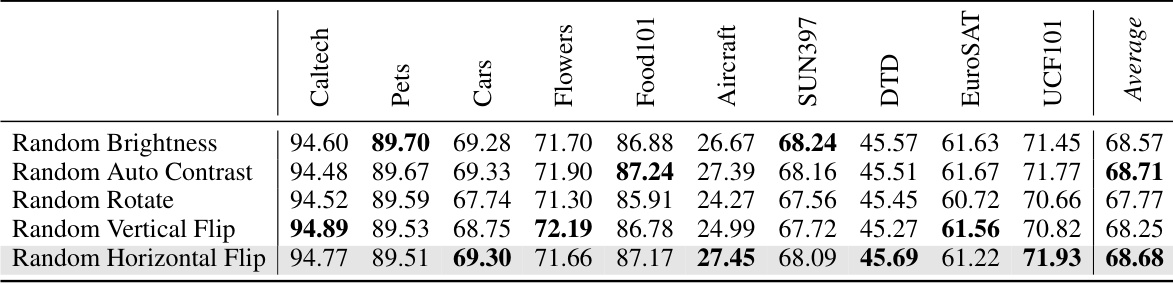
🔼 This table presents the results of an ablation study conducted on the Out-of-Distribution (OOD) benchmark using the Vision Transformer (ViT-B/16) backbone. The study compares the performance of three different approaches: using only historical samples, using only boosting samples, and using both (BoostAdapter). The top-1 accuracy and error bounds (±0.12) are reported for each method across four OOD datasets: ImageNet-V2, ImageNet-Sketch, ImageNet-A, and ImageNet-R. This table helps to demonstrate the individual and combined contributions of historical and boosting samples to the overall performance of the BoostAdapter model.
read the caption
Table 3: Ablation study on historical samples and boosting samples on the OOD benchmark with ViT-B/16 backbone. We report top-1 accuracy and the error bound is ±0.12.
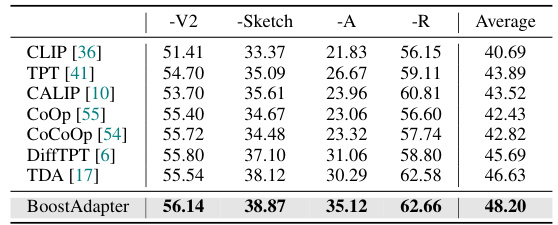
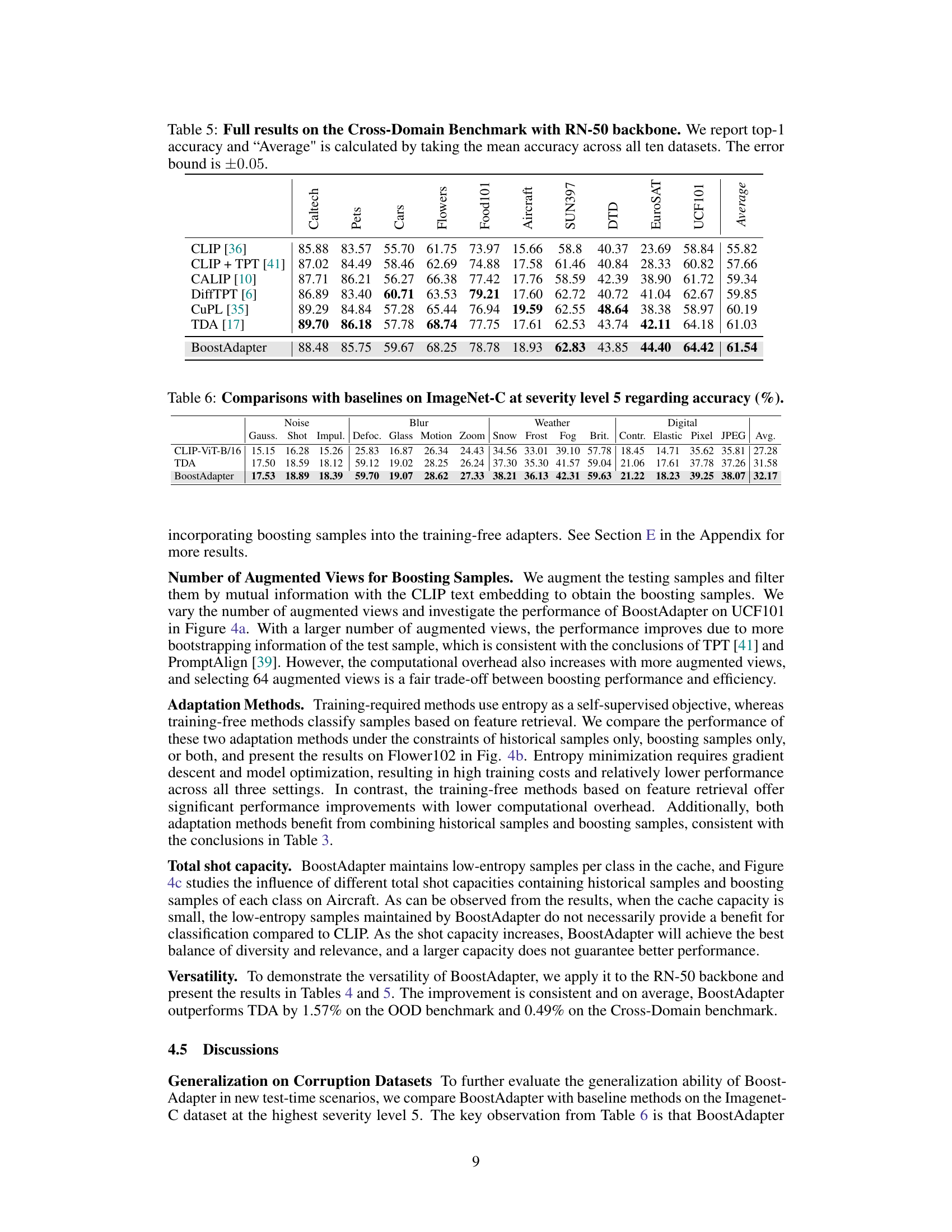
🔼 This table presents the results of the out-of-distribution (OOD) benchmark using a ResNet-50 backbone. It compares the top-1 accuracy of various vision-language models on four ImageNet variants (ImageNet-V2, ImageNet-Sketch, ImageNet-A, ImageNet-R). The error bound of ±0.06 indicates the uncertainty in the reported accuracies. The table showcases the performance of the BoostAdapter in comparison to other state-of-the-art methods.
read the caption
Table 4: Full results on the OOD benchmark with RN-50 backbone. We report top-1 accuracy and the error bound is ±0.06.
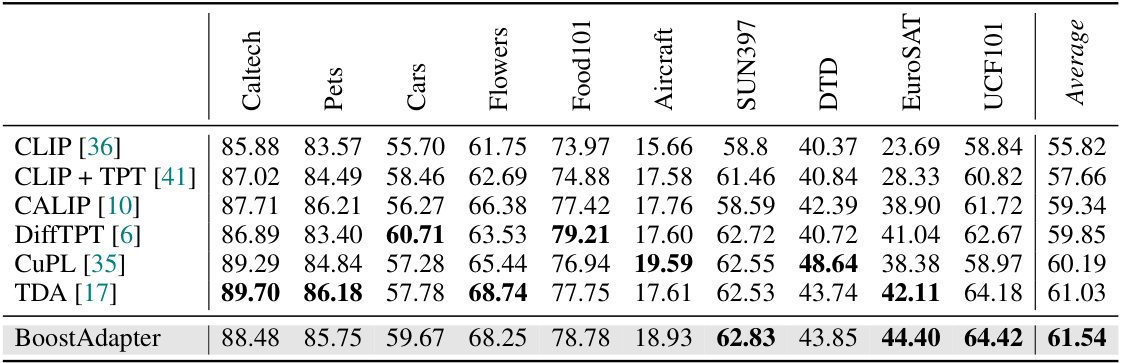
🔼 This table presents the results of the proposed BoostAdapter method and several baseline methods on a cross-domain benchmark using the ViT-B/16 backbone. The benchmark consists of ten different datasets, evaluating the model’s ability to generalize across various domains. Top-1 accuracy is reported for each dataset, along with the average accuracy across all datasets. The error bound provides a measure of uncertainty in the reported results.
read the caption
Table 2: Full results on the Cross-Domain Benchmark with ViT-B/16 backbone. We report top-1 accuracy and 'Average' is calculated by taking the mean accuracy across all ten datasets. The error bound is ±0.17.

🔼 This table compares the performance of BoostAdapter with other baseline methods on ImageNet-C dataset at severity level 5. ImageNet-C is a dataset that evaluates the robustness of image classifiers to various corruptions. The results show BoostAdapter’s performance in handling different types of corruptions, indicating its superior generalization capability compared to existing methods.
read the caption
Table 6: Comparisons with baselines on ImageNet-C at severity level 5 regarding accuracy (%).

🔼 This table presents the efficiency comparison of different test-time adaptation methods. It shows the inference speed in frames per second (fps) and the memory consumption in gigabytes (GB) for each method on a single NVIDIA 3090 24GB GPU. The methods compared include CLIP, TPT, DiffTPT, TDA, and BoostAdapter. The table also includes the augmentation strategy and number of views used for each method. Finally, the table provides the OOD (Out-of-Distribution) and cross-domain results for context.
read the caption
Table 7: Efficiency analysis. We evaluate different methods on a single NVIDIA 3090 24GB GPU and report the frames per second (fps) and memory cost (GB).
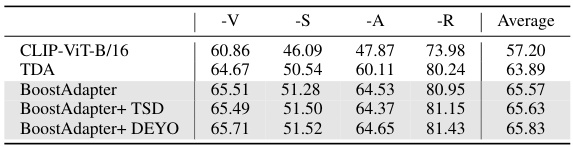
🔼 This table presents the top-1 accuracy results for different vision-language models on four out-of-distribution (OOD) benchmark datasets: ImageNet-V2, ImageNet-Sketch, ImageNet-A, and ImageNet-R. The models evaluated include CLIP, CLIP with Test-Time Prompt Tuning (TPT), CoOp, CoOp+TPT, CoCoOp, CoCoOp+TPT, Maple, Maple+TPT, PromptAlign, DiffTPT, TDA, and BoostAdapter. The ‘Average’ column represents the mean accuracy across the four datasets. This table demonstrates the performance of BoostAdapter compared to state-of-the-art methods in handling OOD generalization.
read the caption
Table 1: Full results on the OOD benchmark with ViT-B/16 backbone. We report top-1 accuracy and 'Average' is calculated by taking the mean accuracy across all four OOD datasets.
🔼 This table presents the results of the out-of-distribution (OOD) benchmark experiments using the Vision Transformer (ViT-B/16) backbone. The benchmark evaluates the robustness of several vision-language models to distribution shifts. The table shows the top-1 accuracy achieved by various models on four ImageNet variants (ImageNet-V2, ImageNet-Sketch, ImageNet-A, and ImageNet-R). The ‘Average’ column represents the average top-1 accuracy across these four datasets. The table provides a quantitative comparison of the models’ performance in handling out-of-distribution data.
read the caption
Table 1: Full results on the OOD benchmark with ViT-B/16 backbone. We report top-1 accuracy and 'Average' is calculated by taking the mean accuracy across all four OOD datasets.

🔼 This table presents the ablation study on using independent cache for boosting samples in the OOD (Out-of-Distribution) benchmark. It compares the performance of BoostAdapter using an independent cache for boosting samples against the original BoostAdapter which uses a joint cache for both historical and boosting samples. The results are presented in terms of top-1 accuracy for four different datasets: Imagenet-V2, Imagenet-Sketch, Imagenet-A, and Imagenet-R, along with their average accuracy.
read the caption
Table 10: Independent cache for boosting samples on the OOD benchmark.

🔼 This table presents the results of the Cross-Domain benchmark using an independent cache for boosting samples. It compares the performance of BoostAdapter using a joint cache (historical and boosting samples) with a setup using independent caches for historical and boosting samples. The results are shown for various image classification tasks, and the ‘Average’ column shows the mean accuracy across all ten datasets.
read the caption
Table 11: Independent cache for boosting sample on the Cross-Domain Benchmark.

🔼 This table presents the top-1 accuracy results of different vision-language models on four Out-of-Distribution (OOD) benchmark datasets: ImageNet-V2, ImageNet-Sketch, ImageNet-A, and ImageNet-R. The models evaluated include CLIP, CLIP+TPT, CoOp, CoOp+TPT, Co-CoOp, Co-CoOp+TPT, Maple, Maple+TPT, PromptAlign, DiffTPT, TDA, and the proposed BoostAdapter. The ‘Average’ column shows the mean accuracy across all four datasets, providing a comparative overview of the models’ performance in handling OOD scenarios.
read the caption
Table 1: Full results on the OOD benchmark with ViT-B/16 backbone. We report top-1 accuracy and 'Average' is calculated by taking the mean accuracy across all four OOD datasets.
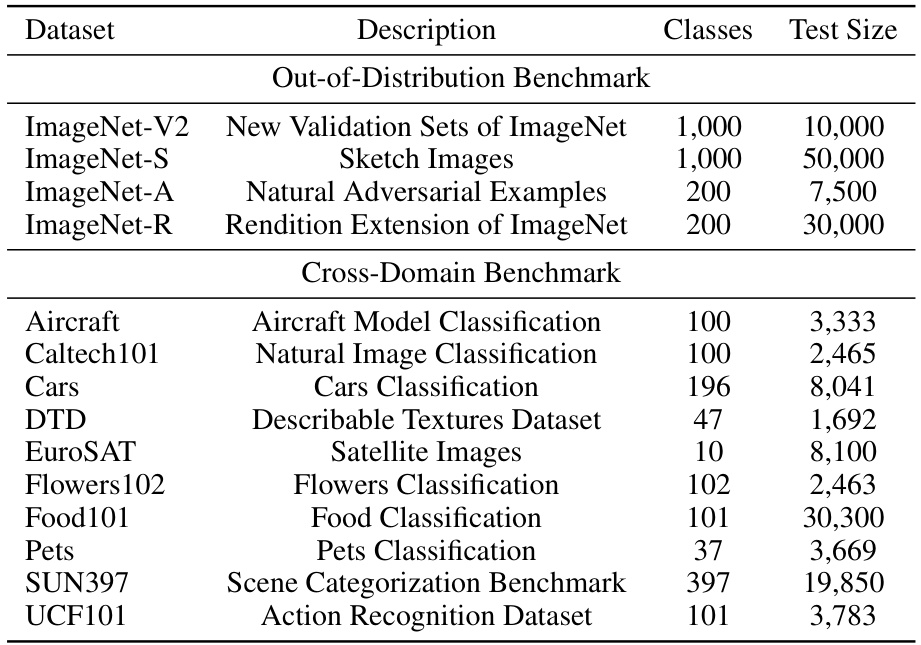
🔼 This table presents a comparison of different data augmentation techniques used for generating boosting samples in the BoostAdapter model. The augmentations tested are Random Brightness, Random Auto Contrast, Random Rotate, Random Vertical Flip, and Random Horizontal Flip. The table shows the top-1 accuracy achieved by BoostAdapter on various datasets in the Cross-Domain benchmark using each augmentation strategy. The default augmentation setting (Random Horizontal Flip) is highlighted in gray for easy identification.
read the caption
Table 13: Comparison of different augmentations on the Cross-Domain Benchmark. Default settings are marked in gray
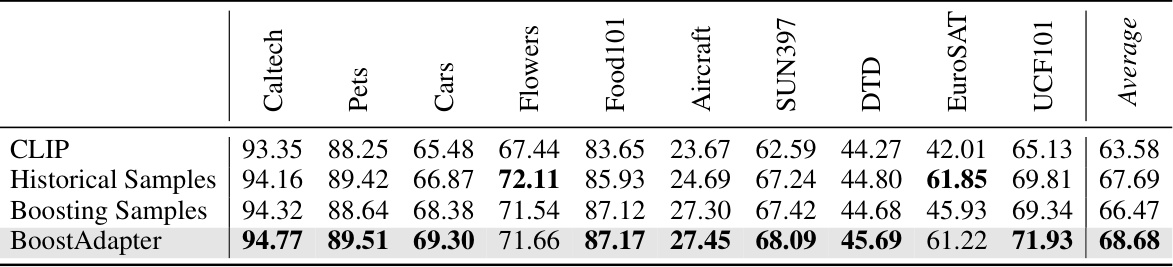
🔼 This table presents the ablation study results on the Out-of-Distribution (OOD) benchmark using the Vision Transformer (ViT-B/16) backbone. It compares the performance of using only historical samples, only boosting samples, and both in the BoostAdapter method. The top-1 accuracy and an error bound of ±0.12 are reported for each configuration. The results show how each component contributes to the overall performance of the BoostAdapter.
read the caption
Table 3: Ablation study on historical samples and boosting samples on the OOD benchmark with ViT-B/16 backbone. We report top-1 accuracy and the error bound is ±0.12.

🔼 This table presents the results of an ablation study on the number of augmented views used to generate boosting samples in the BoostAdapter method. The study was conducted on the Out-of-Distribution (OOD) benchmark, which consists of four ImageNet variants: ImageNet-V2, ImageNet-Sketch, ImageNet-A, and ImageNet-R. The table shows that increasing the number of augmented views generally improves performance, with the best results obtained using 64 augmented views. The default settings are highlighted in gray.
read the caption
Table 15: Results of different views on the OOD benchmark. Default settings are marked in gray
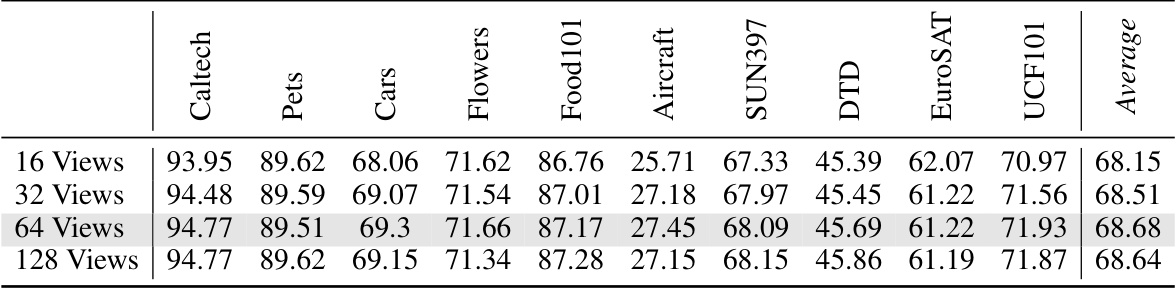
🔼 This table presents the results of an ablation study on the number of augmented views used to generate boosting samples within the BoostAdapter method. The study evaluates the impact on the model’s performance across ten different datasets in a cross-domain benchmark. The ‘Default settings’ refers to the configuration used in the main experiments of the paper. The table shows how the top-1 accuracy varies as the number of views increases, providing insight into the tradeoff between computational cost and improved performance.
read the caption
Table 16: Results of different views on the Cross-Domain Benchmark. Default settings are marked in gray.
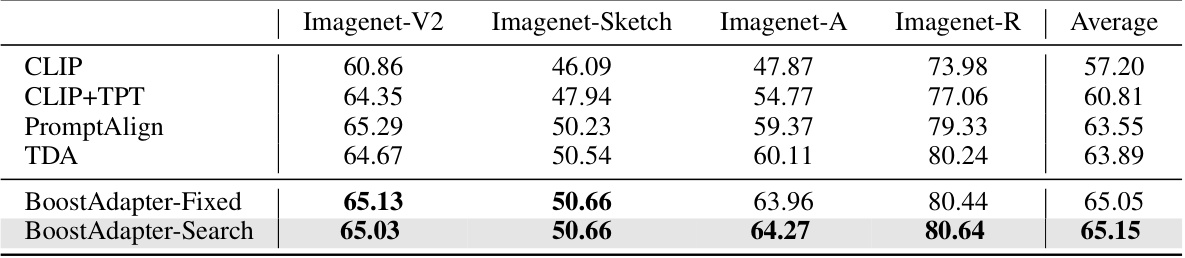
🔼 This table presents the results of the out-of-distribution (OOD) benchmark experiments using the ViT-B/16 backbone. The benchmark evaluates the model’s robustness to distribution shifts across four ImageNet variants: ImageNet-V2, ImageNet-Sketch, ImageNet-A, and ImageNet-R. The table shows the top-1 accuracy for each dataset and the average accuracy across all four datasets for various vision-language models: CLIP, CLIP+TPT, CoOp, CoOp+TPT, Co-CoOp, Co-CoOp+TPT, Maple, Maple+TPT, PromptAlign, DiffTPT, TDA, and BoostAdapter. This allows comparison of the performance of different models on challenging OOD data.
read the caption
Table 1: Full results on the OOD benchmark with ViT-B/16 backbone. We report top-1 accuracy and 'Average' is calculated by taking the mean accuracy across all four OOD datasets.
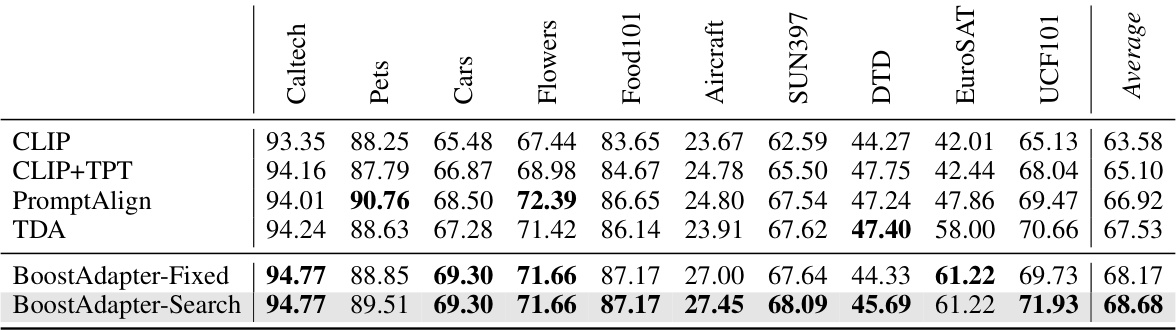
🔼 This table presents the results of the proposed BoostAdapter and other comparative methods on a cross-domain benchmark using the ViT-B/16 backbone. Top-1 accuracy is reported for ten different datasets, along with an average accuracy across all datasets. The error bound of ±0.17 indicates the uncertainty in the reported accuracy values.
read the caption
Table 2: Full results on the Cross-Domain Benchmark with ViT-B/16 backbone. We report top-1 accuracy and 'Average' is calculated by taking the mean accuracy across all ten datasets. The error bound is ±0.17.
Full paper#